Grokking the Machine Learning Interview - Recommendation System (4) Feature Engineering
Recommendation System
Grokking the Machine Learning Interview - Recommendation System
4. Feature Engineering
추천 후보 생성 및 순위 모델을 위한 피처 엔지니어링
- 영화 추천 플랫폼에서 피처 엔지니어링 프로세스를 시작하려면 먼저 영화/쇼 추천 프로세스의 주요 요소를 식별한다.
(1) 로그인한 사용자
(2) 영화/쇼 콘텐츠
(3) 상황(예: 계절, 시간 등)

<그림> 미디어 추천 시스템에서의 주요 요소들 (로그인한 유저, 추천될 미디어, 상황(유저가 로그인한 장치, 시간)
Features
- 위의 주요 요소를 기반으로 피처를 생성하는데 피처들은 다음과 같은 범주로 분류할 수 있다.
(1) user-based feature (유저 기반 피처)
(2) context-based featue (상황 기반 피처)
(3) media-based featrue (미디어 기반 피처)
(4) media-user cross features (미디어-사용자 교차 특성)
이러한 피처의 하위 집합은 아래와 같다.

(1) user-based feature
- 추천 모델에 유용한 피처로 작용할 수 있는 유저 기반 피처이다.
크게 age(나이), gender(성별), language(언어), country(국가),
average_session_time(평균 체류 시간), last_genre_watched(마지막으로 본 장르)
[1] 나이 (age)
- 이 피처를 통해 모델은 다양한 연령대에 적합한 콘텐츠 종류를 학습하고 그에 따라 미디어를 추천할 수 있다.
[2] 성별 (gender)
- 모델은 성별에 따른 선호도를 학습하고 이에 따라 미디어를 추천할 수 있다.
모델은 성별에 따른 선호도를 학습하고 이에 따라 미디어를 추천합니다.
[3] 언어 (language)
- 이 피처는 사용자의 언어를 기록해서, 영화가 사용자와 친숙한 동일한 언어로 되어 있는지 확인하기 위해 모델에서 사용될 수 있다.
[4] 국가 (country)
- 이 피처는 사용자의 국가를 기록해서, 다양한 지역의 사용자들은 콘텐츠의 선호도가 다르기 때문에 모델이 지리적 선호도를 학습해서 이에 따라 권장 사항을 조정하는데 도움이 될 수 있다.
[5] 평균 세션/체류 시간 (average session time)
- 이 피처는 사용자가 긴 영화/쇼를 보는 것을 좋아하는지 아니면 짧은 영화/쇼를 보는 것을 좋아하는지 알 수 있다.
[6] 마지막 봤던 장르 (last genre watched)
- 유저가 마지막으로 본 영화의 장르는 사용자가 다음에 보고 싶어할 만한 영화에 대한 힌트가 될 수 있다. 모델이 스릴러나 로맨틱 영화를 보는 것을 좋아하는 패턴을 발견할 수도 있다.
(1)-a. sparse한 user-based feature
다음은 희소하게 나타나는 과거 상호작용 패턴에서 발생할 수 있는 일부 사용자 기반 피처들이다.
모델은 이러한 피처를 사용해 사용자 선호도를 파악할 수 있다.
[1] user_actor_histogram (사용자 활동 히스토그램)
- 이 피처는 넷플릭스 미디어의 활성 사용자와 모든 배우들과의 과거 상호 작용을 보여주는 히스토그램이다. 각 배우가 캐스팅된 미디어를 사용자가 시청한 미디어의 비율을 기록한다.
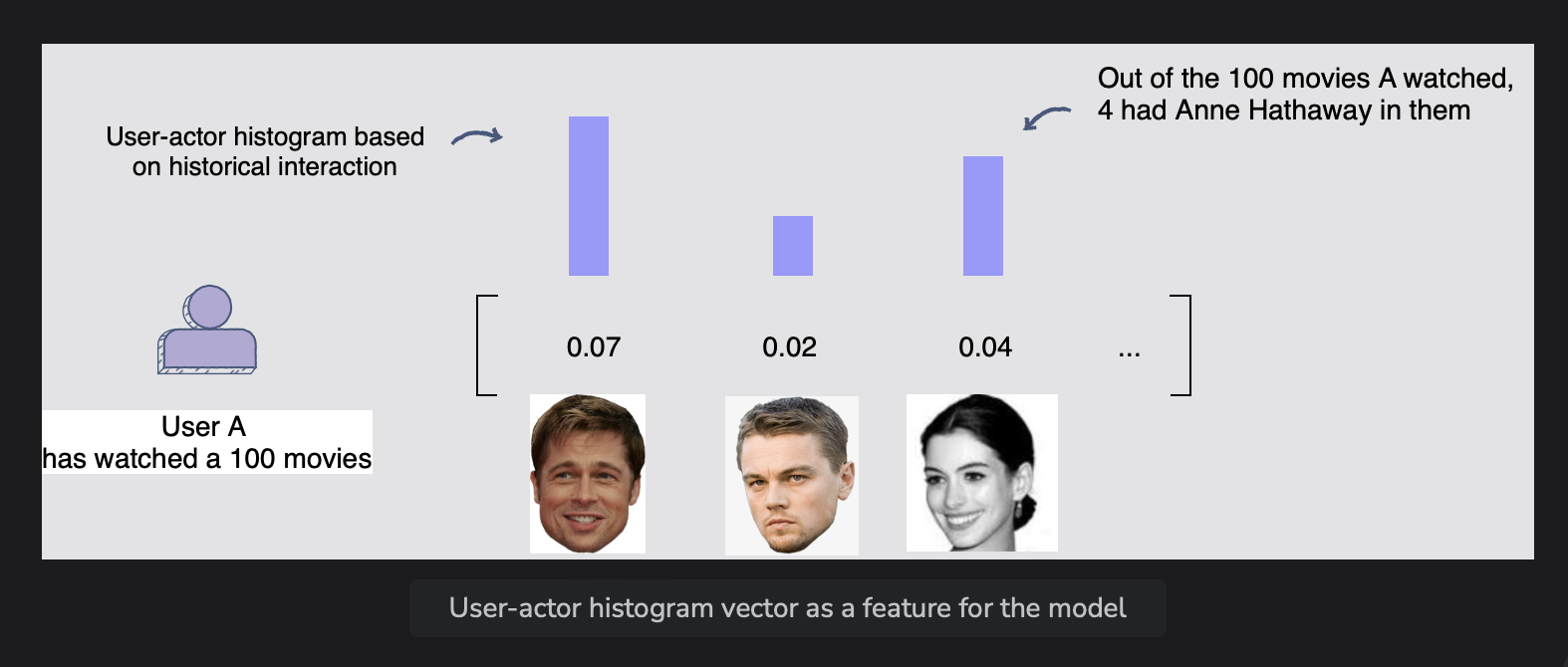
[2] user_genre_histogram (사용자 장르 히스토그램)
- 이 피처는 액티브한 (활동한) 사용자와 넷플릭스 미디어에서의 모든 장르간의 과거 상호 작용을 보여주는 히스토그램을 기반으로 하는 벡터이다.
각 장르에 속하는 사용자가 시청한 미디어의 비율을 기록한다.
[3] user_language_histogram (사용자 언어 히스토그램)
- 이 피처는 액티브한 (활동하는) 사용자와 넷플릭스 미디어의 모든 언어 간의 과거 상호작용을 보여주는 히슽토그램을 기반으로 하는 벡터이다.
사용자가 시청한 각 언어의 미디어 비율을 나타낸다.
(2) context-based feature
- 콘텍스트(상황)에 맞는 추천을 하면 사용자 경험이 향상될 수 있다.
- 다음은 상황별 정보를 캡처하는 것을 목표로 하는 몇 가지 피처이다.
[1] 계절 (season of the year)
- 사용자 선호는 사계절에 따라 패턴화 될 수 있다.
이 피처는 개인이 미디어를 시청한 시즌을 기록한다. - 예를 들어 한 사용자가 여름 시즌에 '여름' 태그가 지정된 영화를 봤다고 가정할 때, 모델은 열므 시즌에 '여름' 영화를 선호한다는 것을 학습할 수 있다.
[2] 다가오는 휴일 (upcoming holiday)
- 이 피처는 다가오는 휴일을 기록한다.
- 사람들은 휴일이 다가올수록 휴일을 주제로 한 콘텐츠를 시청하는 경향이 있다.
- 예를 들어 넷플릭스는 크리스마스 휴가 전 18일 동안 매일 53명이 영화 '크리스마스 왕자'를 시청했다고 트위터에 올렸다. 휴일은 지역별로도 다르다.
[3] 다가오는 휴일까지의 남은 일수 (days to upcoming holiday)
- 휴일이 시작되기 며칠 전에 사용자가 휴일 테마 콘텐츠를 시청하기 시작했는지 확인하는 것도 유용하다.
- 모델은 특정 휴일이 시작되기 며칠 전에 사용자에게 휴일 테마 미디어를 추천해야 하는지 추론할 수 있다.
[4] 하루 중 특정 시간 (time of day)
- 사용자는 하루 중 시간에 따라 다른 콘텐츠를 시청할 수도 있다.
[5] 주의 특정 일 (day of week)
- 사용자의 시간 패턴도 주마다 달라지는 경향이 있는데, 사용자는 주중에 쇼를 시청하고 주말에는 영화를 즐기는 것을 선호하는 것으로 관찰된다.
[6] 장치 (device)
- 사용자가 콘텐츠를 보고 있는 장치를 고려하는 것도 도움이 될 수 있다.
- 사용자가 바쁠 때는 모바일에서 더 짧은 시간 동안 콘텐츠를 시청하는 경향이 있고, 대개 자유 시간이 더 길면 TV를 시청하기로 결정한다.
TV에서 더 오랫동안 연속적으로 미디어를 시청하기 때문에, 사용자가 모바일에서 로그인하면 짧은 에피소드가 포함된 프로그램을 추천하고 TV에서 로그인하면 긴 영화가 포함된 프로그램을 추천할 수 있다.
(3) Media-based features (미디어 기반 추천)
미디어의 메타데이터에서 유용한 피처들을 많이 만들 수 있다.
[1] 공식 플랫폼 평점 (public-platform-rating)
- 이 피처는 영화에 대한 IMDb/로튼 토마토 평점과 같은 대중의 의견을 고려한다.
영화는 개봉 후 한참 후에 넷플릭스에서 출시될 수 있다. 따라서 이러한 평점은 넷플릭스에서 영화를 볼 수 있게 된 후 사용자가 영화를 어떻게 받을 지 예측할 수 있다.
[2] 수익 (revenue)
- 넷플릭스에 출시되기 전에 영화에서 발생한 수익을 추가할 수 있다.
- 이 피처는 모델이 영화의 인기를 파악하는 데에도 도움이 된다.
[3] 영화 개봉일로부터 지난 시간(time passed since release date)
- 이 피처는 영화 개봉일로부터 얼마나 많은 시간이 경과했는지 알려준다.
[4] 플랫폼에 유지되고 있는 시간 (time on platform)
- 넷플릭스에 미디어가 얼마나 오랫동안 존재했는지 기록하는 것도 좋다.
[5] 미디어 시청 기록 (media watch history)
- 미디어의 시청 이력(미디어가 시청된 횟수)은 그 인기를 나타낼 수 있다.
- 일부 사용자는 트렌드에 대한 최신 정보를 유지하고 인기 있는 영화만을 시청하는 것을 선호할 수 있다. 이들은 인기 있는 미디어를 추천받을 수 있을 것이다.
다른 사람들은 덜 알려진 인디 영화를 더 선호할 수 있는데, 이들에게는 좋은 암시적 피드백(사용자가 영화를 완전히 시청하고 중간에 나가지 않음)이 있는 덜 시청된 영화를 추천할 수 있다.
이 피처의 도움을 받아 모델은 이러한 패턴을 학습할 수 있다.
모델은 이 피처를 통해 이러한 패턴을 학습할 수 있다.
다양한 시간 간격에 대한 미디어 시청 기록도 확인할 수 있어, 다음과 같은 피처를 가질 수 있다.
media_watch_history_last_12_hrs (지난 12시간 동안의 미디어 시청 기록)
media_watch_history_last_24_hrs (지난 24시간 동안의 미디어 시청 기록)
📝 위에 나열된 미디어 기반 피처는 특정 미디어가 블록버스터이며 많은 사람들이 이를 시청하는 데 관심이 있을 것임을 모델에 종합적으로 넣을 수 있다.
예를 들어, 어떤 영화가 큰 수익을 창출하고, IMDb 평가가 좋고, 24시간 전에 플랫폼에 올라왔고, 많은 사람들이 그것을 본다면 그것은 확실히 블록버스터일 것이다.
[6] 장르 (genre)
- 이 피처는 코미디, 액션, 다큐멘터리, 고전, 드라마, 애니메이션 등 주요 콘텐츠 장르이다.
[7] 영화 시간(movie duration)
- 이 피처는 영화 상영 시간이고, 모델은 다른 피처와 결합해서 사용자가 짧은 영화를 선호하는지, 긴 영화를 선호하는 지를 학습할 수 있다.
[8] 영화 내의 시대적 시간(content set time)
- 이 피처는 영화/쇼가 설정된 기간을 의미한다.
예를 들어 사용자가 90년대 시대적 배경으로 한 쇼를 선호할 수 있다는 것을 알려줄 수 있다.
[9] 콘텐츠 태그(content tags)
- 넷플릭스는 콘텐츠의 뉘앙스를 포착하는 영화/쇼에 대해 매우 상세한 설명과 구체적은 태그를 만들기 위해 영화와 쇼를 시청할 사람을 고용했다.
예를 들어 미디어에 '시각적으로 인상적인 향수를 불러일으키는 영화' 와 같은 태그가 지정될 수 있는데, 이러한 태그는 모델이 다양한 사용자의 취향을 이해하고 사용자의 취향과 영화 간의 유사점을 찾는데 큰 도움이 된다.
[10] 쇼의 시즌 번호 (show season number)
- 미디어가 여러 시즌이 포함된 프로그램인 경우 이 피처는 사용자가 더 적은 시즌 또는 더 많은 시즌을 가진 프로그램을 좋아하는지 여부를 모델에 넣을 수 있다.
[11] 원산지 (country of origin)
- 이 피처에는 콘텐츠가 제작된 국가를 포함한다.
[12] 출시 국가(release country)
- 이 피처에는 콘텐츠를 제작한 국가를 포함한다.
[13] 출시 연도 (release year)
- 이 피처는 극장 개봉 연도로 원래 방송 날짜 혹은 dvd 출시 날짜를 표시한다.
[14] 릴리즈 타입 (release type)
- 이 피처는 콘텐츠가 극장, 방송, dvd 또는 스트리밍으로 출시 됐는지의 여부가 표시된다.
[15] 연령 등급 (maturity rating)
- 이 피처는 지역(지리적 지역)에 대한 미디어의 연령 등급을 포함한다.
모델은 사용자의 연령과 함께 사용해 적절한 영화를 추천할 수 있다.
(4) Media-user cross features (미디어-사용자 교차 피처)
사용자의 선호도를 학습하기 위해서는 미디어와의 상호작용을 피처로 나타내는 것이 매우 중요하다.
예를 들어, 사용자가 크리스토퍼 놀란의 영화를 많이 본다면 사용자가 어떤 종류의 영화를 좋아하는지에 대한 많은 정보를 얻을 수 있다. 이러한 상호 작용 기반 피처 중 일부는 다음과 같다.
[1] 사용자-장르 내역 상호작용 피처(user-genre historical interaction feature)
- 이 피처는 사용자가 고려 중인 영화와 동일한 장르로 시청한 영화의 비율을 나타낸다.
이 백분율은 사용자의 기본 이러한 특징은 사용자가 고려 중인 영화와 동일한 장르로 시청한 영화의 비율을 나타냅니다.이 백분율은 사용자 선호도의 동적 성격을 고려하여 다양한 시간 간격에 대해 계산된다.
-
user_genre_historical_interaction_3month
(유저와 장르의 3개월 동안의 상호 작용 기록)
지난 3개월 동안 사용자가 고려 중인 영화와 동일한 장르의 영화를 본 비율이다.
예를 들어 사용자가 지난 3개월 동안 본 코미디 영화 12편 중 6편을 본 경우 피처 값은 다음과 같다.
6/12 = 0.5 or 50%
이 피처는 다른 피처들에 비해 사용자의 장르 선호도가 보다 최근에 나타난 경향을 보여준다. -
user_genre_historical_interaction_1year
(유저와 장르의 1년 동안의 상호 작용 기록)
위와 동일한 피처지만 1년의 시간 간격으로 계산되고,사용자와 장르 간의 관계에서 보다 장기적인 추세를 보여준다. -
user_and_movie_embedding_similarity
(유저와 영화 임베딩 유사도)
텟플릭스는 영화와 프로그램을 시청할 사람을 고용해 콘텐츠의 뉘앙스를 포착하는 영화/프로그램에 대한 매우 상세하고 설명적이며 구체적인 태그를 만들었고,
미디어에서 '시각적으로 인상적인 향수를 불러 일으키는 영화' 라는 태그를 지정할 수 있다.
사용자와 상호작용한 영화의 태그를 기반으로 사용자를 임베딩하고 태그를 기반으로 미디어를 임베딩 하도록 할 수 있다. 두 임베딩 간의 내적 유사도를 피처로 사용할 수 있다. -
사용자-배우 (user-actor)
추천 대상인 미디어와 동일한 배우를 보유한 미디어 중 사용자가 시청한 미디어의 비율을 의미하는 피처이다. -
사용자-감독 (user_director)
이 피처는 사용자가 고려 중인 영화와 동일한 감독의 영화를 본 비율이다.
-
사용자-언어 일치도 (user_language_match)
이 피처는 사용자의 언어와 미디어와의 언어의 일치도 이다.
-
사용자-나이 매치 (user_age_match)
특정 미디어를 가장 많이 본 연령대를 기록해서 이 피처는 특정 영화/쇼를 시청하는 사용자가 동일한 연령대에 속하는지 확인한다. 예를 들어 영화 A는 대부분 (80%) 40세 이상의 사람들이 시청하면 추천 영화 A를 고려하는 동안 이 피처는 사용자가 40대 인지 여부를 확인한다.
일부 희소한 피처는 아래에 설명되는데,
각각은 해당 도메인의 인기 동향과 개발 사용자의 선호도를 보여줄 수 있다.
rank chapter에서 이러한 희소 피처들이 어떻게 사용되는지 살펴볼 수 있고, 이 희소 데이터의 벡터 표현을 생성해서 머신러닝 모델에서 사용하는 방법에 대해서는 embedding chapter를 살펴보면 된다. (rank와 embedding 장은 추후에 지속적으로 업데이트 하겠다)
일부 희소한 피처들의 예시이다.
[1] 영화_ID (movie id)
- 인기 영화 ID는 자주 반복된다.
[2] 미디어 제목 (tile of media)
- 이 피처는 영화 또는 TV 시리즈의 제목이다.
[3] 시놉시스(synopsis)
-이 피처는 시놉시스로 콘텐츠의 개요 또는 요약이다.
[4] 원본 제목 (original title)
- 이 피처는 영화의 원래 제목을 원래 제목으로 유지한다.
미디어는 국민의 선호도를 고려해서 다른 제목으로 다른 국가에 공개될 수 있는데 일본/한국의 영화 쇼는 영어 제목으로 영어권 국가에 개봉된다.
[5] 유통 업체/배포하는 사람(distributor)
- 특정 배포자는 매우 좋은 품질의 콘텐츠를 선택할 수 있으므로 사용자는 해당 배포자의 콘텐츠를 선호할 수 있다.
[6] 크리에이터 (creator)
- 이 피처는 콘텐츠 작성자를 의미한다.
[7] 원본 언어 (original language)
- 이 피처는 콘텐츠의 원본 언어로, 여러 언어인 경우 다수의 언어를 선택하여 기록한다.
[8] 감독(director )
- 이 피처는 콘텐츠의 감독을 의미한다. 이 피처는 스티븐 스필버그처럼 널리 알려진 감독을 표시할 수 있을 뿐만 아니라, 사용자 개인의 선호도를 보여줄 수도 있다.
[9] 첫 릴리즈 년도 (first_release_year)
- 이 피처는 콘텐츠가 처음 출시된 연도로, 제작 연도와는 다르다.
[10] 음악_작곡가(music composer)
- 쇼의 음악이나 영화의 음악은 스토리텔링 측면을 크게 향상시킬 수 있다.
사용자는 특정 작곡가의 작품을 좋아할 수도 있고 그들의 작품에 더 끌릴 수도 있다.
[11] 배우 (actors)
- 이 피처는 영화/쇼의 출연진이 포함된다.
유통업체(배포자) 및 시놉시스와 같은 희소 기능을 밀집 피처로 만들 수 있는데
배급사 특성의 희소 표현은 이 영화의 배급사가 상위 10개 배급사 목록에 포함됩니까?
시놉시스의 밀집 피처는 시놉시스의 텍스트 요약을 수행하여 키워드를 추출하는 것이다.
그러나 이 프로세스에는 엔지니어의 추가 노력이 필요하므로 신경망이 관계를 파악하도록 해야 한다. (이 접근 방식은 ranking 강의에서 논의된다)
일단 해당 섹션에서 추천으로 사용할 만한 아이디어를 많이 얻었다.
특히 context-based feature에 대해서는 생각하지 못했던 부분이 많았는데 추천 강의 정리가 끝나면 기존에 가지고 있던 노멀한 데이터를 가지고 context-base feature 로 피처엔지니어링을 해봐야겠다. 미쳤다 미쳤어~ 짱 재밌음
참고사이트
