Grokking the Machine Learning Interview - Recommendation System (5) Candidate Generation
Recommendation System
Grokking the Machine Learning Interview - Recommendation System
5. Candidate Generation
-
추천 후보자 생성 기술
- 협업 필터링 (Collaborative filtering)
- 방법 1: 가장 가까운 이웃 (Nearest neighborhood)
- 방법 2: 행렬 분해 (Matrix factorization)
- 콘텐츠 기반 필터링 (Content-based filtering)
- 신경망/딥러닝을 사용하여 임베딩 생성
- 해당 기술의 강점과 약점
이번 장에서는 사용자와 시스템의 과거 상호 작용을 기반으로 사용자 관심 사항에 맞는 미디어 후보를 생성하는 몇 가지 기술을 살펴본다.
- 협업 필터링 (Collaborative filtering)
Candidate generation techniques (후보 생성 기술)
추천 후보 생성 기술은 다음과 같다.
(1) 협업 필터링 - Collaborative filtering
(2) 콘텐츠 기반 필터링 - Content-based filtering
(3) 임베딩 기반 유사성 - Embedding-based similarity
각 방법에는 좋은 후보자를 선택하는 데 있어 고유한 장점이 있으며,
순위에 전달하기 전에 모든 방법을 결합하여 완전한 목록을 생성한다.
(더 자세한 사항은 순위 강의(rank chapter)에서 언급)
Collaborative filtering (협업 필터링)
- 이 기술은 액티브한 사용자와 유사한 사용자를 찾아서, 그들의 과거 시청 이력의 교집합을 기반으로 한다. 그런 다음 아래와 같이 유사한 사용자와 협력하여 액티브 사용자를 위한 후보 미디어를 생성합니다.
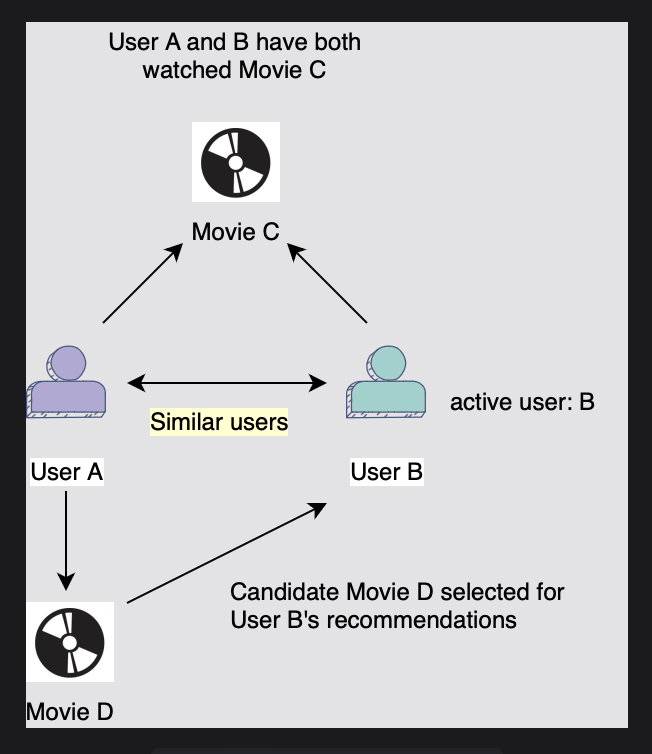
- 사용자가 영화의 하위 집합에 대해 사용자 그룹과 유사한 취향을 공유하는 경우,
무작위로 선택된 사람의 취향과 비교 시 다른 영화에 대해 비슷한 의견을 가질 가능성이 있다.
협업 필터링을 수행하는 방법은
(1) Nearest neighborhood (가장 가까운 이웃)
(2) Matrix factorization (행렬 분해)
두 가지가 있다.
Method [1] Nearest neighborhood
- 사용자 A는 영화 인셉션과 인터스텔라를 본 사용자 B 및 사용자 C와 유사하다.
따라서 사용자 A의 가장 가까운 이웃은 사용자 B와 사용자 C라고 말할 수 있다.
사용자 B와 C가 좋아하는 다른 영화를 사용자 A의 추천 후보로 살펴볼 수 있다.
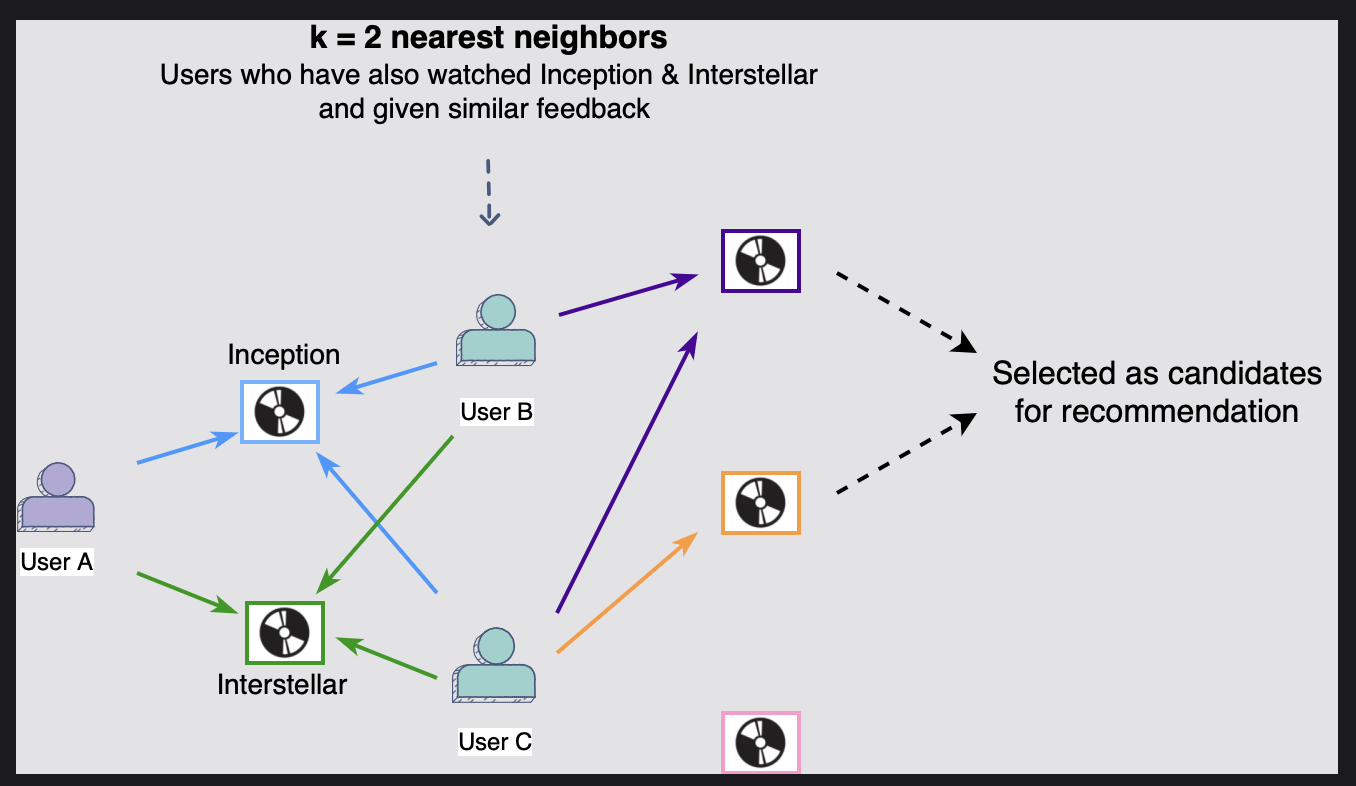
위 그림은 k=2로 두어, 유저 A와의 가장 가까운 이웃(nearset neighbors)를 2명으로 산정했다.
인셉션과 인터스텔라를 시청하고 비슷한 피드백을 준 유저 B,C이다.
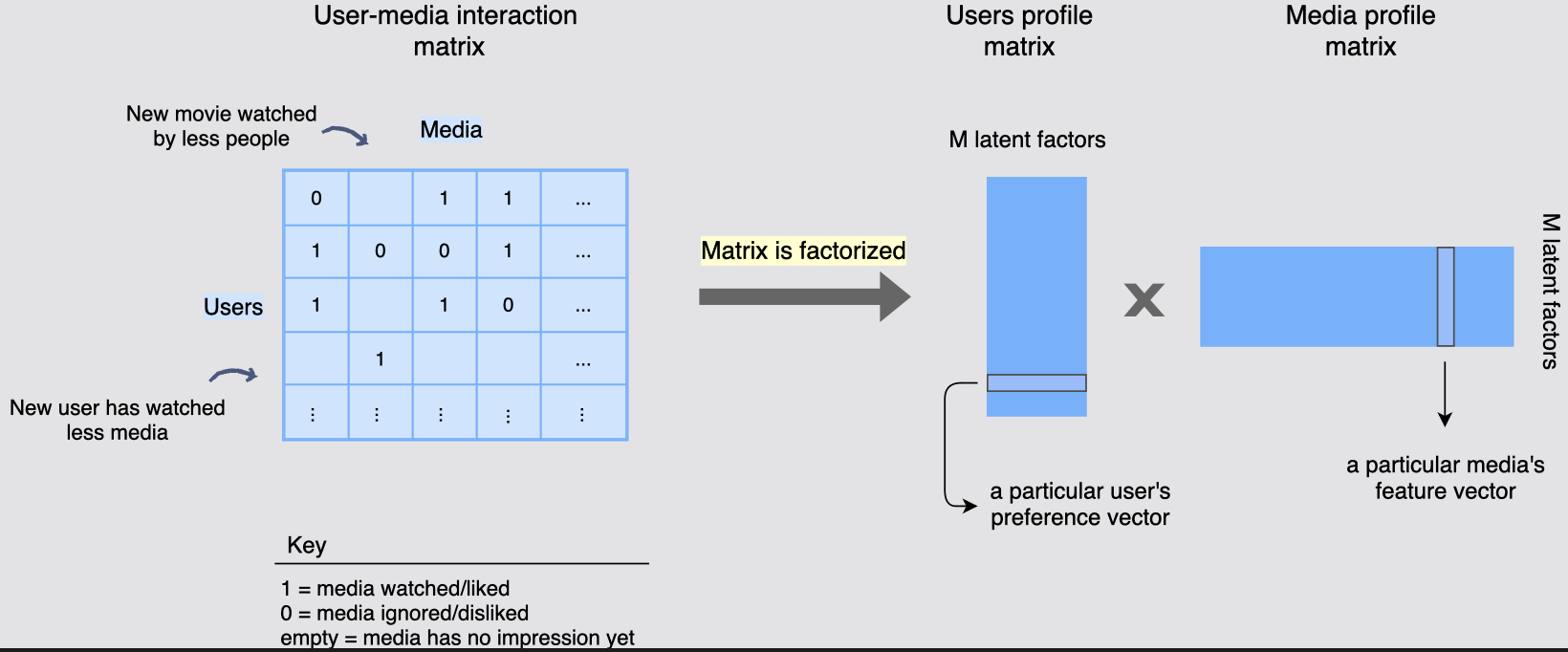
위 개념은 사용자 ui(i=1, .. n)와 영화 mj(j=1 .. m) 이라고 할 때 (n x m) 행렬이 만들어 지고, 각 행렬 요소는 사용자 i가 영화 j에 제공한 피드백을 나타낸다.
빈 셀은 사용자 i가 영화 j를 시청하지 않았음을 의미한다.
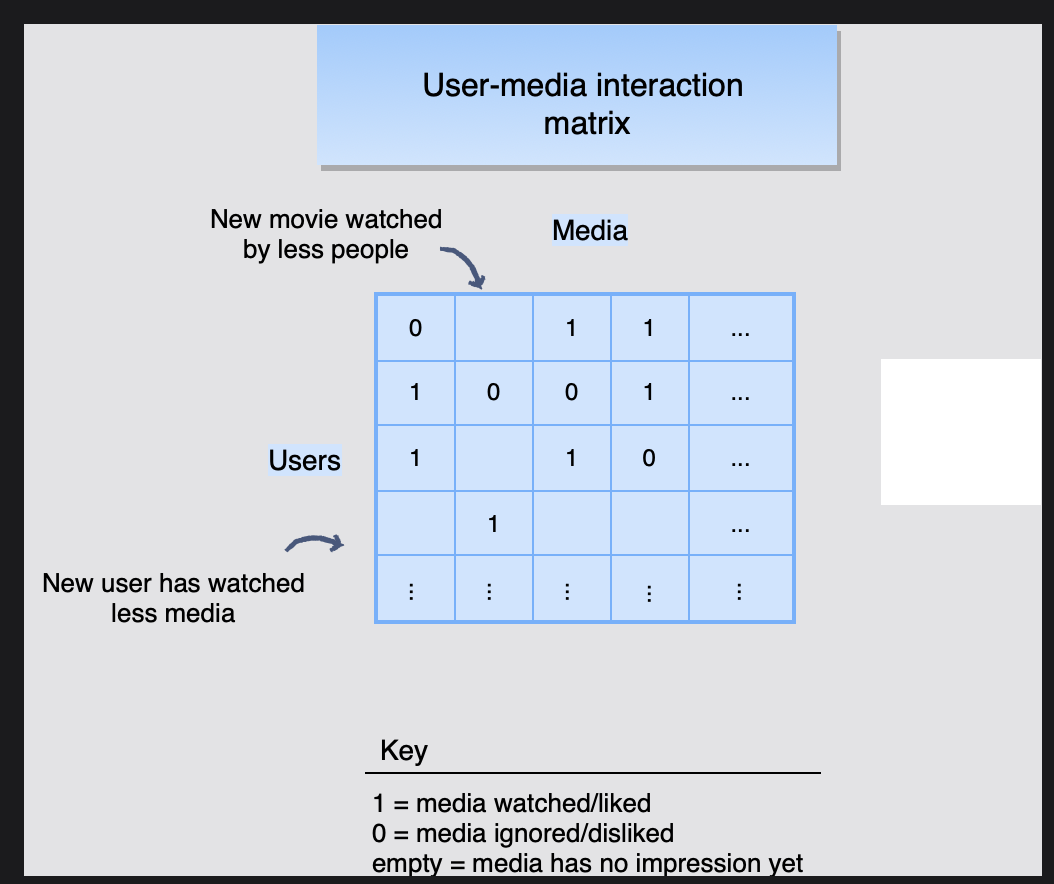
위 그림에서의 더 적은 사람들이 보는 새로운 영화(New movie watched by less people),
미디어를 적게 시청한 유저(New user has watched less media) 이고,
key는 1 : 미디어를 시청하거나 좋아함 0 : 미디어를 보지않았거나 싫어함
비어있음 : 평가 받지 않은 미디어 라고 보면 된다.
- 사용자 i에 대한 추천을 생성하려면 사용자 i가 시청하지 않은 모든 영화에 대한 피드백을 예측해야 한다. 이 프로세스를 위해 사용자 i와 유사한 사용자를 찾는데, 사용자 i가 보지 않은 영화에 대한 평가는 유사한 사용자가 좋아하는 영화들로부터 소스를 제공받을 수 있다.
따라서 사용자 i와 다른 사용자의 유사성(예: 코사인 유사성)을 계산한 다음 상위 k개의 유사한 사용자/가장 가까운 이웃(KNN(ui))을 선택한다. 그러면 사용자 i는 보지 못한 영화 j에 대한 피드백(fij)를 예측할 수 있게 된다. 여기서 가장 가까운 이웃의 피드백은 사용자 i와의 유사성에 따라 가중치가 부여된다.
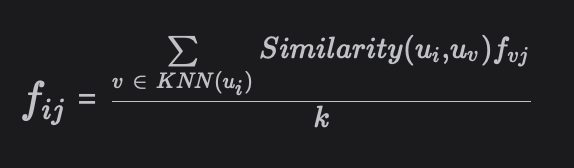
예측 피드백이 좋은 미공개 영화가 사용자 i의 추천 후보로 선택된다.
위의 과정들은 유사한 사용자를 식별하는 협업 필터링(CF)의 사용자 기반 접근 방식(user-based approach)이다.
- 후보를 생성하기 위해 아이템(영화/쇼)의 유사성을 살펴보는 아이템 기반 접근 방식(item-based approach)로 알려진 또 다른 접근 방식이 있다.
먼저, 사용자의 유사한 피드백을 기반으로 아이템의 유사성을 계산한다.
그러면 사용자 A가 이미 시청한 미디어와 가장 유사한 미디어가 사용자 A의 추천 후보로 선택된다.
사용자 기반 접근 방식은 시간이 지남에 따라 사용자 선호도가 변하는 경향이 있으므로 확장하기가 더 어려운 경우가 많다. 반면 아이템은 변경되지 않으므로 아이템 기반 접근 방식은 일반적으로 오프라인으로 계산할 수 있으며 빈번한 재학습 없이 제공될 수 있다.
- 사용자 수와 영화 수가 증가함에 따라 이 프로세스의 계산 비용은 많이 들게 된다.
- 이 행렬의 희소성은 어떤 사용자도 영화를 평가하지 않았거나 새로운 사용자가 영화를 많이 본 적이 없는 경우에도 문제가 발생할 수 있다.
Method [2] Matrix factorization (행렬분해)
- 확장이 가능하면서 희소성을 처리하는 방식으로 사용자-미디어 상호 작용 행렬을 표현해야 하는데, 여기서 Factorization matrix(행렬 인수분해)은 이 행렬을 두 개의 저차원 행렬로 분할한다.
(1) 사용자 프로필 행렬(n x M)
- 사용자 프로필 행렬의 각 사용자는 M 차원의 잠재 벡터인 행으로 표시된다.
(2) 미디어 프로필 행렬(M x m) - 영화 프로필 행렬의 각 영화는 M 차원의 잠재 벡터인 열로 표시된다.
차원 M은 사용자-미디어 피드백 행렬를 추정하는 데 사용하는 잠재 요인의 수(latent factor)이다. M은 실제 사용자 수와 미디어 수에 비해 훨씬 적다.
-사용자와 미디어를 잠재적 요소의 벡터 형태로 표현한 것은 사용자가 특정 미디어에 대한 피드백을 설명한다. 잠재 벡터는 영화나 사용자의 특징으로 생각할 수도 있는데, 예를 들어, 아래 다이어그램에서 두 가지 잠재 요인은 대략적으로 코미디와 참신함의 정도로 볼 수 있다.
📝 각 차원이 무엇을 의미하는지 정확히 알지 못하기 때문에 잠재 요인에 대해 "might"
및 "loosley"라는 단어를 사용한다. 잠재 요인은 우리에게 "숨겨져" 있다.
""" latent factor가 "might" 하다는 표현은 "잠재적 요소가 어떤 의미를 가질 수 있다" 또는 "잠재적 요소가 어떤 영향을 줄 수 있다"는 것을 의미한다고 보고 "loosley"는 해당 latent factor가 정확하게나 명확하게 정의되지 않거나 구체적으로 정해지지 않았다는 의미로 보면 될 것 같다. """
예를 들어 사용자 A의 벡터에는 "코미디"에 대한 1과 "참신함"에 대한 0의 선호도가 있다.
영화 B의 벡터에는 영화의 두 가지 요소(예: 1과 0)의 유무가 포함되어 있고,
이 두 벡터의 내적은 영화 B가 사용자 A의 선호도와 얼마나 일치하는지 알려준다. (사용자 피드백)
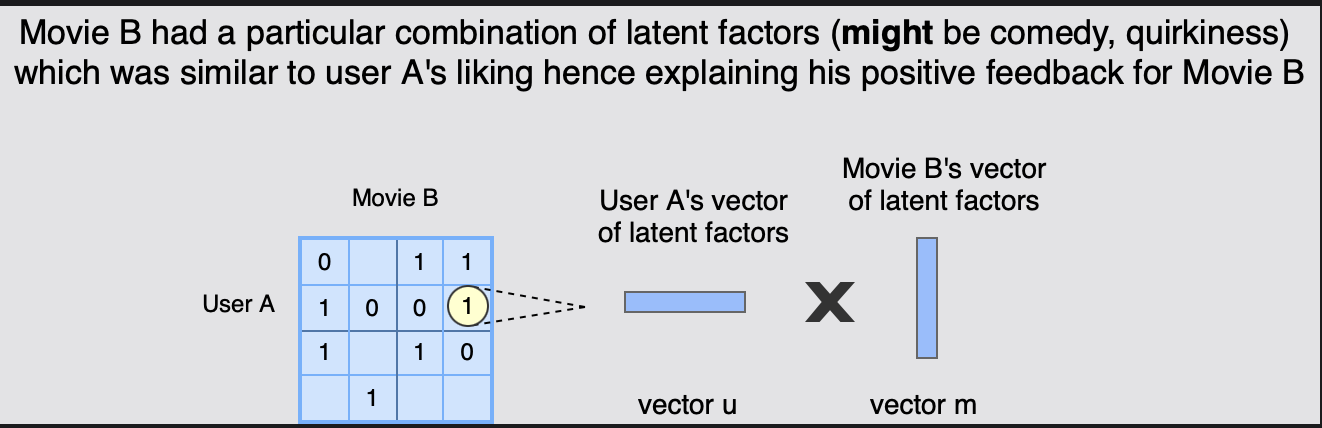
영화 B에는 사용자 A의 취향과 유사한 특정 잠재 요인(코미디, 참신함) 조합이 있어 영화 B에 대한 긍정적인 피드백을 설명하고 있다.
[그림] 영화 B에 대한 사용자 A의 피드백은 A의 선호도와 B의 특성을 일치시키는 형태임
- 첫 번째 단계는 사용자 프로필과 영화 프로필 행렬을 만드는 것이다.
그런 다음, 보지 못한 영화에 대한 사용자 피드백을 예측하여 좋은 영화 추천 후보를 생성한다.
이 예측은 사용자 벡터와 영화 벡터의 내적을 계산함으로써 간단하게 이뤄진다.
사용자와 미디어에 대한 잠재요인행렬을 학습하는 과정을 살펴보면,
먼저, 사용자 및 동영상 벡터를 무작위로 초기화한다.
각각의 알려진/과거 사용자 영화 피드백 값 (fij)에 대해 해당 사용자 프로필 벡터 (ui)와 영화 프로필 벡터 (mj)의 내적을 취하여 영화 피드백을 예측한다.
실제 피드백(fij)과 예측 피드백(ui.mj)의 차이가 오류(eij)가 된다.
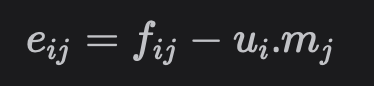
- 확률적 경사하강법을 사용하여 오류 값을 기반으로 사용자 및 영화 잠재 벡터를 업데이트한다. 사용자 및 영화 잠재 벡터를 계속 최적화하면 사용자와 영화에 대한 의미론적 표현을 얻을 수 있으므로 해당 공간에 더 가까운 새로운 추천을 찾을 수 있다.
📝 사용자 프로필 행렬은 사용자가 피드백을 제공한 영화를 기반으로 만들어진다.
마찬가지로 미디어/영화 프로필 행렬은 사용자 피드백을 기반으로 만들어진다.
이러한 사용자 및 영화 프로필 행렬을 활용하여 보지 못한 영화에 대한 예측 피드백을 기반으로 특정 사용자에 대한 추천 후보를 생성한다.
Content-based filtering (콘텐츠 기반 필터링)
- 콘텐츠 기반 필터링을 통해 사용자가 이미 상호작용한 미디어의 특성이나 속성을 기반으로 사용자에게 추천을 제공할 수 있다.
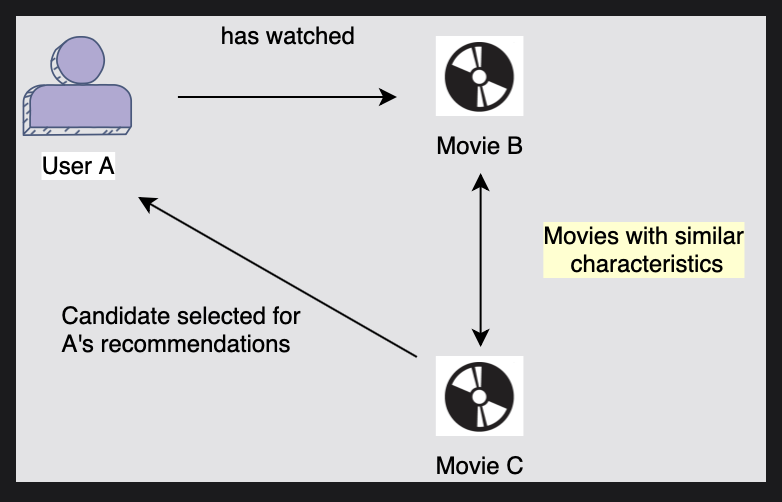
위 그림에서 사용자 A가 이전에 영화 B를 본 기록이 있을 때,
영화 B와 영화 C가 유사한 특성을 가지고 있다면 영화 C를 사용자 A의 추천 후보로 올린다.
[그림] 콘텐츠 기반 필터링
- 따라서 추천은 사용자의 관심과 관련이 있는 경향이 있다.
피처는 메타데이터(예: 장르, 영화 출연자, 시놉시스, 감독 등) 정보와
Netflix 태거와 같은 수동으로 할당된 미디어 설명 태그(예: 시각적으로 눈에 띄는 것, 향수를 불러일으키는 것, 마법의 생물, 캐릭터 개발, 겨울 시즌, 기발한 인디 로맨스 등) 등이다. 미디어는 해당 속성의 벡터로 표현된다.
다음 설명은 이해를 돕기 위해 속성의 하위 집합을 보여준다.
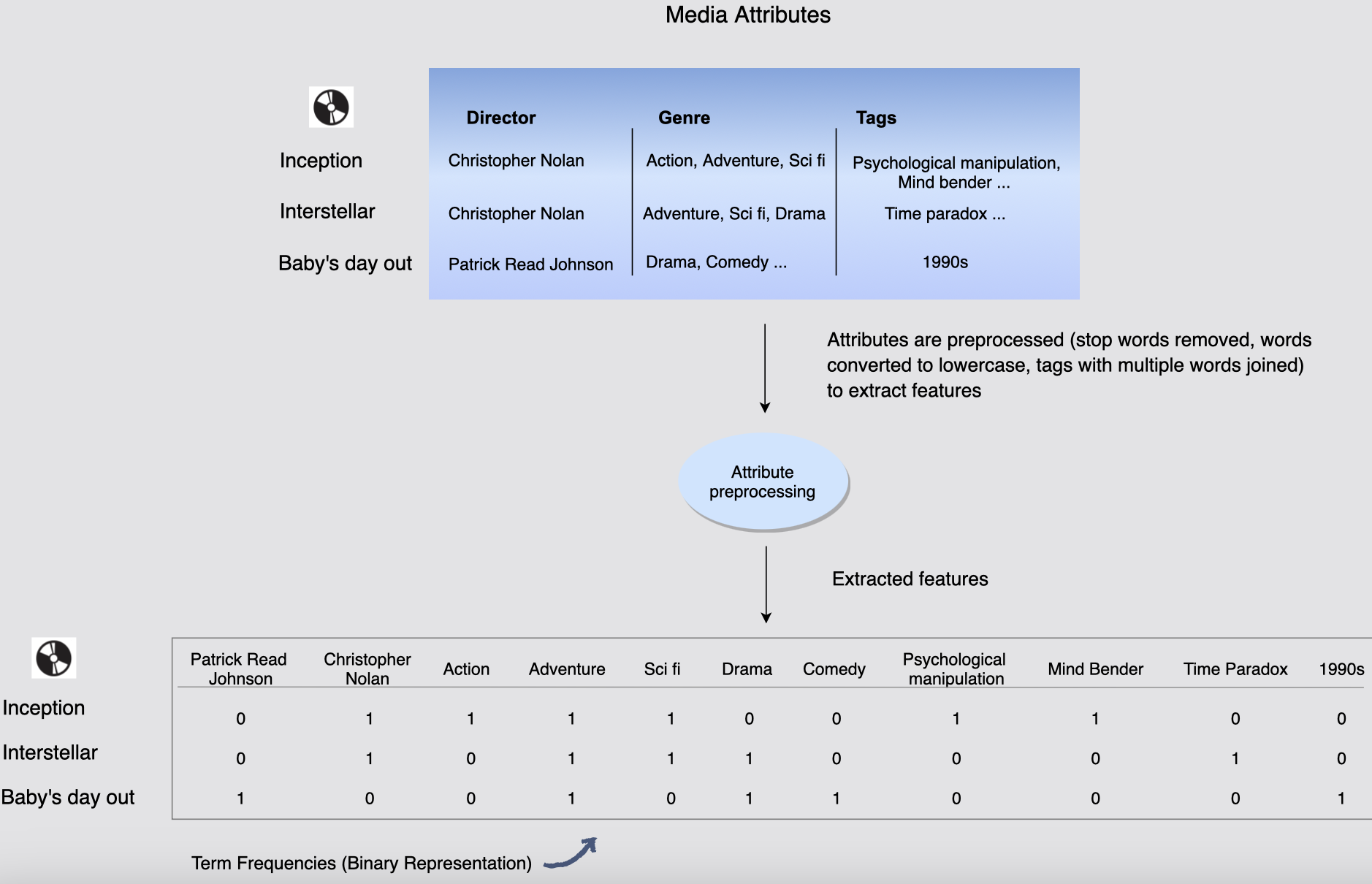
위 그림에서 영화는 인셉션, 인터스텔라, 베이비스 데이 아웃이 있고
각 미디어의 속성으로 감독/장르/태그 등이 존재한다.
각 미디어의 특성을 추출하기 위해 속성을 전처리한다.(불용어 제거, 단어를 소문자로 변환, 여러 단어를 조합한 태그)
속성을 전처리한다음 피처를 추출한다.
피처는 그림과 같이 감독 a, 감독 b, 감독 c, 장르 a, 장르 b, 태그 a, 태그 b 등 으로 나눈다. 각 피처는 발생 빈도로 바이너리로 표현한다.
[그림] 미디어를 나타내는 벡터 속성
- 처음에는 원시 형식의 미디어 속성이 있고, 특징을 추출하려면 그에 따라 전처리가 필요하다.
예를 들어 중복을 방지하려면 불용어(stopwords)를 제거하고 속성 값을 소문자로 변환한다. 또한 크리스토퍼라는 이름을 가진 감독이 두 명 있을 수 있으므로 고유한 인물을 식별하려면 감독의 이름과 성을 결합해야 한다. 태그에도 유사한 전처리가 필요하다. 그런 다음, 용어 빈도(TF, 속성의 존재(1) 또는 부재(0)의 이진 표현)를 묘사하는 요소가 있는 속성의 벡터로 영화를 표현할 수 있다.
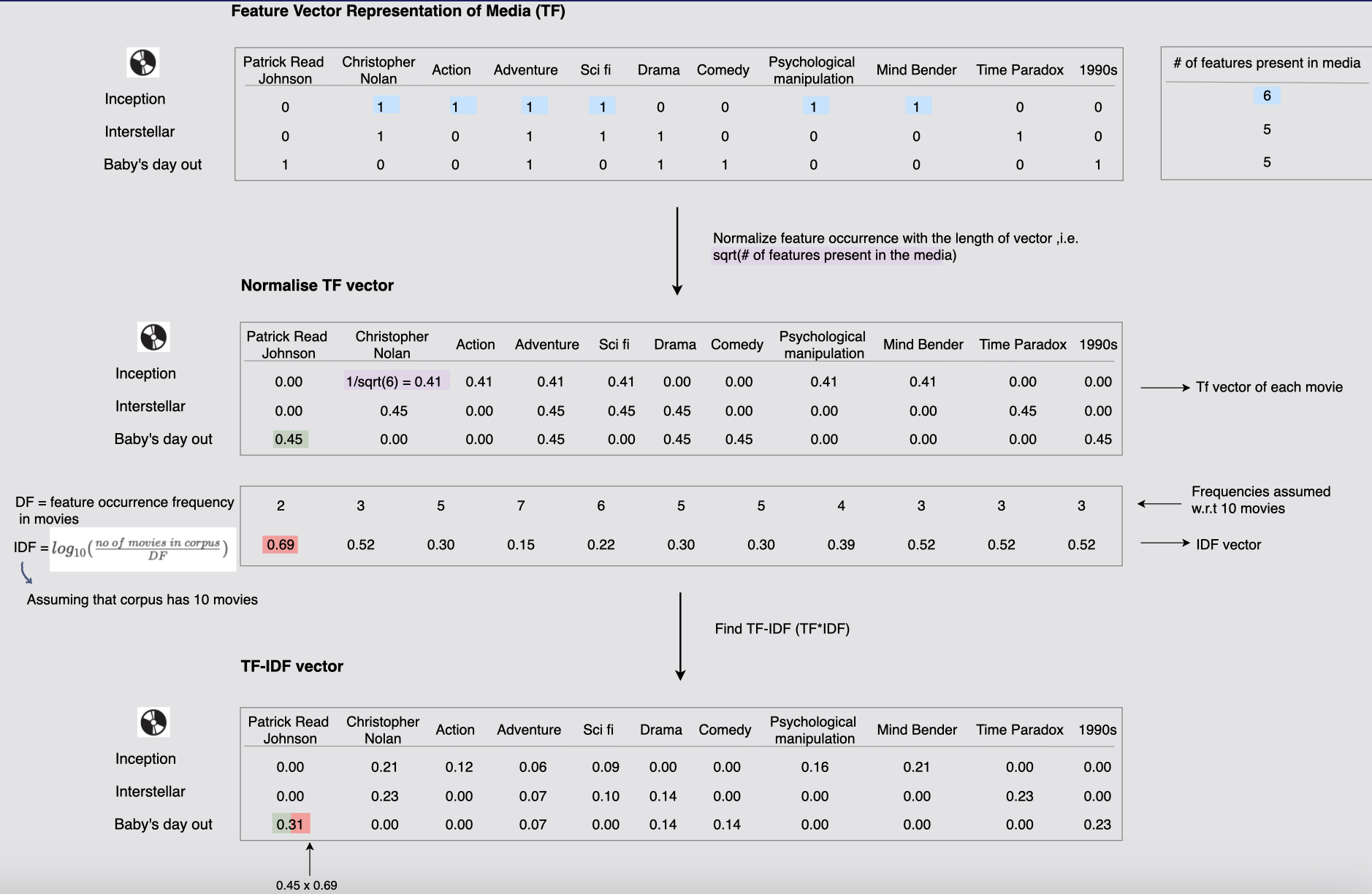
처음에 나오는 표는 각 영화에 따라서 각 TF (Feature Vector Representation of Media, 미디어의 특징 벡터)를 나타낸 것이다.
위에서 추출했던 피처인 감독의 이름들, 장르의 종류, 키워드 등의 단어들에 대해 포함되어 있는지에 대해서 바이너리로 나타낸다. 그리고 해당 영화에서의 피처의 수를 각 오른쪽에 나타낸 것이다.
그리고 두번째 표는 위에서 미디어에 있는 피처의 수를 벡터의 길이로 정규화한 것이다. 1/벡터의 길이에 sqrt(제곱근)을 취한 값이다.
세번째 표는 각 10개의 영화에서 DF(feature occurrence frequency in movies, 영화 피처 발생 빈도)를 나타낸 것이다. 각 피처에 대해 2, 3, 5, 7, .. 3 으로 나타나있다.
그리고 IDF(Inverse Docummenet Frequency)로, DF 값을 역수를 취한다. 흔하게 나타나는 피처일 수록 IDF 값은 낮아지고 드물게 나타나는 피처일 수록 IDF 값은 높아진다. IDF는 로그를 취해 주로 스케일을 조정한다.
위에서의 DF값을 IDF으로 나타낸 값들은 0.69, 0.52, 0.30 ... 0.52 이다.
마지막으로 TF-IDF 값을 구하는데, TF-IDF 값은 TF에 IDF 값을 곱하여 얻는다. 즉 특정 피처가 특정 영화에서 자주 등장하지만, 다른 영화에서 그렇지 않다면 해당 피처의 TF-IDF 값은 높아진다고 볼 수 있다. 특정 영화에 대한 해당 피처의 중요성을 평가할 때 사용된다.
즉, 위 그림에서 Baby's day out의 Partick Read Johnson의 TF-IDF 값은 0.31이 나왔는데, 정규화시킨 TF 값 0.45에 IDF 값인 0.69를 곱해 나온 것이다.
TF-IDF vector를 봤을 때 Baby's day out에서 Partick Read Johnson의 TF-IDF 값이 상대적으로 높은 것을 볼 수 있는데 즉 'Partick Read Johnson' 피처가 'Baby's day out'에서 중요한 피처라고 평가할 수 있다.
[그림] 미디어(영화)의 TF-IDF 벡터 표현 만드는 방법
- 모든 속성의 TF(용어/속성 빈도)를 포함하는 벡터로 표현된 영화가 있게되고, 그런 다음 벡터의 길이로 빈도항을 정규화한다. 마지막으로 영화의 정규화된 TF 벡터와 IDF 벡터를 요소별로 곱하여 영화에 대한 TF-IDF 벡터를 만든다.
- TF-IDF는 문서 간의 유사성을 고려하여 말뭉치 전체에서 피처의 희귀성을 고려함으로써 문맥을 보여준다.
각 영화/쇼의 TF-IDF 표현을 고려하면 사용자에게 미디어를 추천하는 두 가지 옵션이 있다.
[1] 상호작용 했던 기록과의 유사성
과거에 상호작용(본)했던 영화와 유사한 영화를 사용자에게 추천할 수 있다.
이는 영화의 내적을 계산하여 유사도를 구한다.
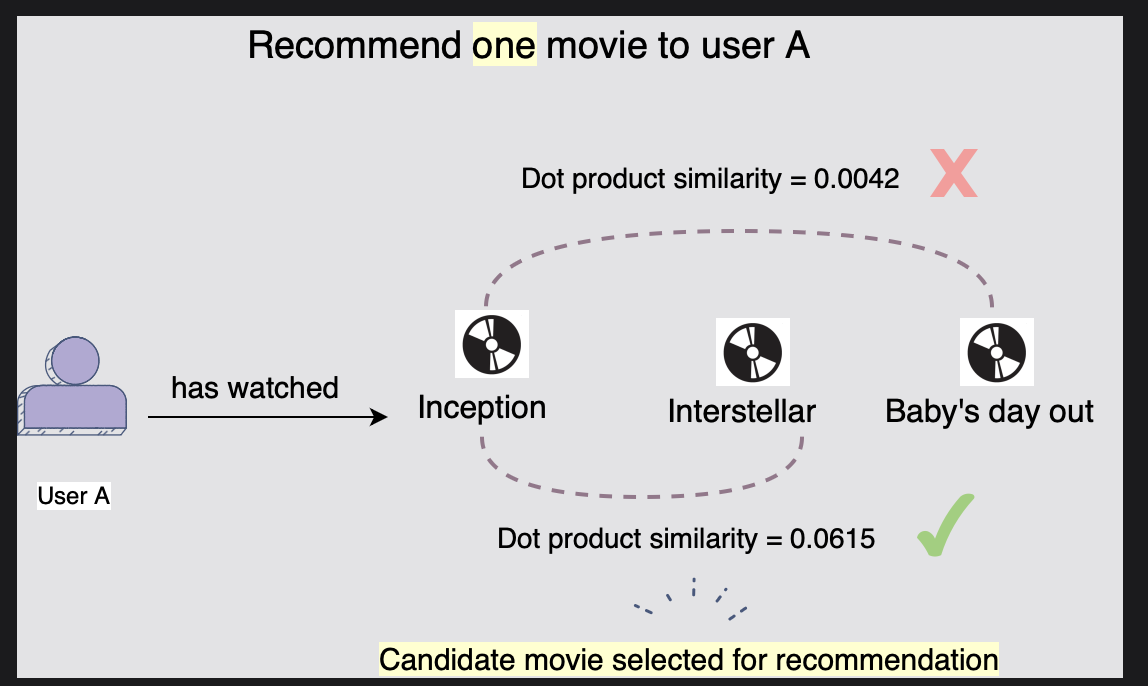
그림에서 인터스텔라는 인셉션을 기반으로 내적의 유사도를 기반으로 더 높기 때문에 사용자 A에게 추천 후보로 선정되었다.
[2] 미디어와 사용자 프로필의 유사성
미디어의 TF-IDF 벡터는 프로필로 볼 수도 있다.
미디어와의 과거 상호 작용에서 볼 수 있는 사용자 기본 설정을 기반으로 아래와 같이 사용자 프로필을 구축할 수 있다.
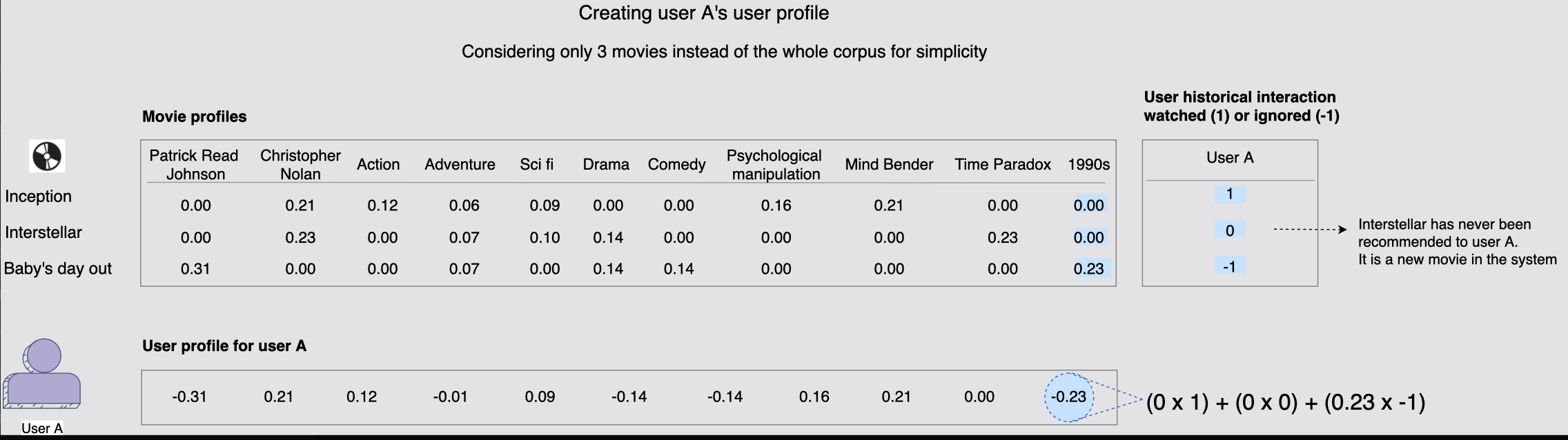
위 그림에서는때 TF-IDF 벡터로 나타냈던 영화 profile 을 유저의 과거 히스토리( user A가 봤던 영화를 1, 무시한 영화를 -1로 표현하고, 새롭게 출시되어 아직 보지 않은 영화를 0으로 표현)와 계산해 사용자의 프로필을 구축할 수 있다.
이제 새로운 콘텐츠를 추천하기 위해 과거 시청목록을 사용하는 대신 사용자 프로필과
보지 못한 영화의 미디어 프로필 간의 유사성(내적)을 계산하여 사용자 A의 추천에 대한 관련 후보를 생성할 수 있다.

위 그림에서 구한 유저 profile vector를 새로운 영화들의 profile과 내적하여 추천할 영화를 선택한다.
[그림] 사용자 A의 프로필을 기반으로 두 개의 후보 영화 선택
Generate embedding using neural networks/deep learning (뉴럴 네트워크/딥러닝을 사용한 임베딩 생성)
과거 피드백(u,m), 즉 영화 m에 대한 사용자 u의 피드백이 주어지면 딥러닝을 사용하여 영화와 사용자 모두를 나타내는 잠재 백터/임베딩을 생성할 수 있다.
벡터를 생성한 후에는 KNN(k 최근접 이웃)을 활용하여 사용자에게 추천하고 싶은 영화를 찾는다.
이 방법은 행렬 분해에서 본 잠재 벡터 생성과 유사하지만 뉴럴 네트워크를 사용하면 데이터의 모든 희소한 피처 및 밀집된 피처를 사용하여 사용자 및 영화 임베딩을 생성할 수 있기 때문에 훨씬 더 강력하다.
임베딩 생성(embedding generation)
- 네트워크를 구성할 때 네트워크의 구성 요소중 하나는 미디어의 희소하고 밀집된 피처를 제공하고, 다른 하나는 사용자 전용 희소하거나 밀집된 피처를 공급하는 것으로 설정한다.
- 첫 번째 네트워크 요소의 마지막 레이어가 활성화되면 미디어의 벡터 임베딩(m)이 형성된다. 마찬가지로 두 번째 네트워크 요소의 마지막 레이어가 활성화되면 사용자의 벡터 임베딩(u)이 형성된다.
- 상단의 결합된 최적화 기능은 u와 m의 내적(예측 피드백)과 실제 피드백 라벨 사이의 거리를 최소화하는 것을 목표로 한다.
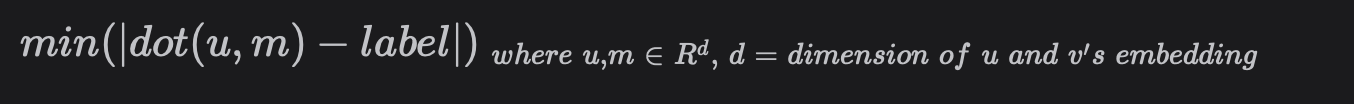
- 위의 비용 함수를 직관적으로 보자면, 실제 피드백 라벨은 미디어가 사용자 선호도와 일치하면 긍정적이고(1) 그렇지 않으면 부정적으로 인식한다.(0)
예측된 피드백이 동일한 패턴을 따르도록 하기 위해 네트워크는 사용자가 이 미디어를 좋아하면 거리가 최소화되고 사용자가 미디어를 좋아하지 않으면 최대화되는 방식으로 사용자와 미디어 임베딩을 학습한다.
📝 결과적으로 얻을 수 있는 사용자의 벡터 표현은 사용자가 좋아하거나 시청할 영화 종류에 가장 가깝다.
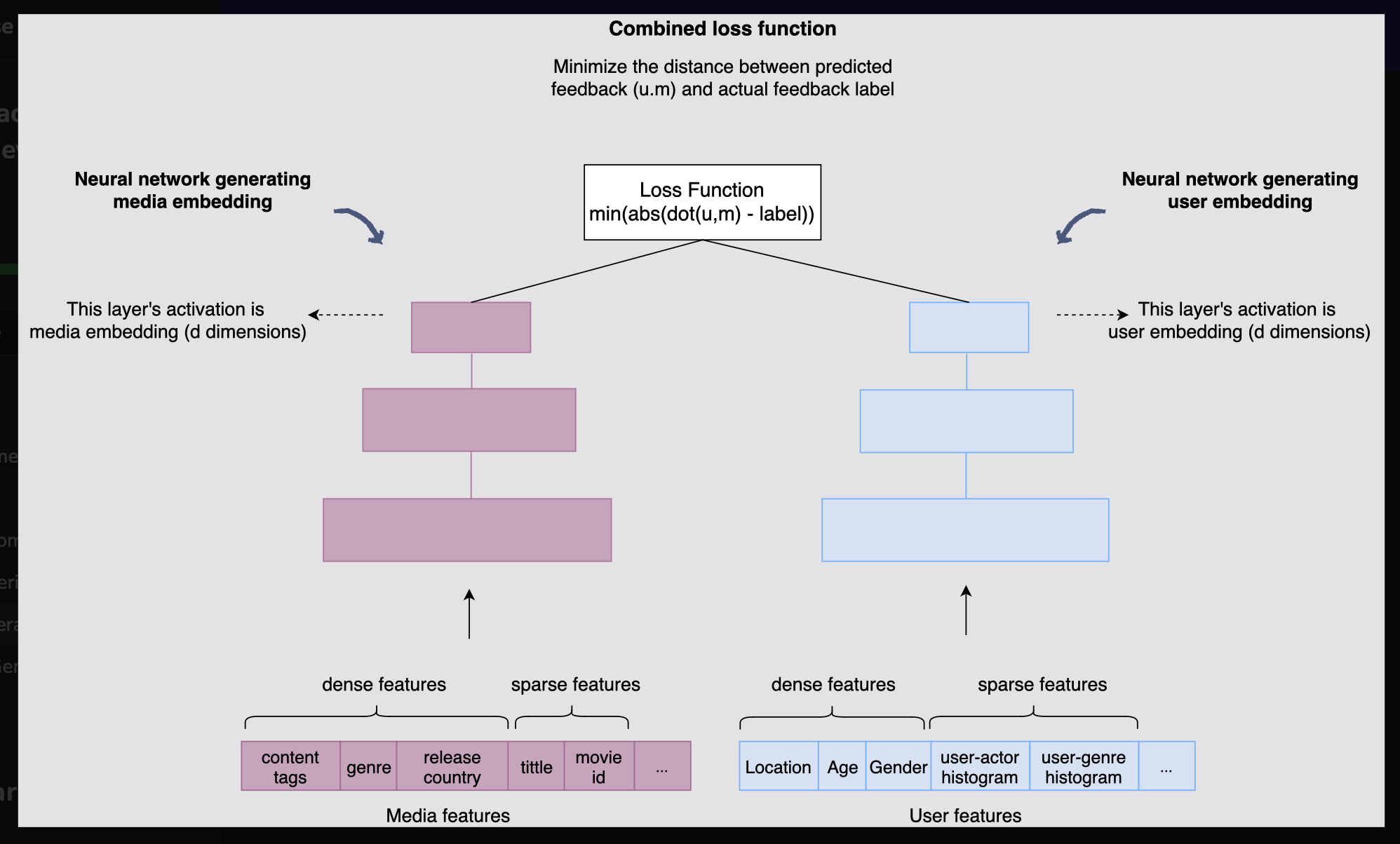
[그림] 손실 함수가 결합된 신경망을 통해 사용자 및 영화 임베딩 생성
📝 사용자-배우 히스토그램 기능은 특정 배우(캐스트)가 포함된 미디어를 사용자가 시청한 비율을 보여준다. 예를 들어, 사용자가 본 콘텐츠의 2%에는 브래드 피트가 포함되어 있고, 5%에는 레오나르도 디카프리오가 포함되어 있다고 가정해본다.
- 위 신경망의 경우 네트워크의 깊이와 최상위/마지막 레이어의 너비(d)가 하이퍼파라미터이다.
*candidate selection (knn)
knn으로 추천 후보자 선택하기
- 아래 다이어그램과 같이 각 사용자에 대해 두 명의 후보를 생성해야 한다고 가정할 때, 사용자 및 미디어 벡터 임베딩이 생성된 후 KNN을 적용하고 각 사용자에 대한 후보를 선택한다. 아래 다이어그램에서 볼 수 있듯이 사용자 A의 가장 가까운 이웃은 높은 벡터 유사성을 기반으로 영화 B와 영화 C이다.
반면, 사용자 B의 경우 영화 D와 영화 B가 가장 가까운 이웃이다.
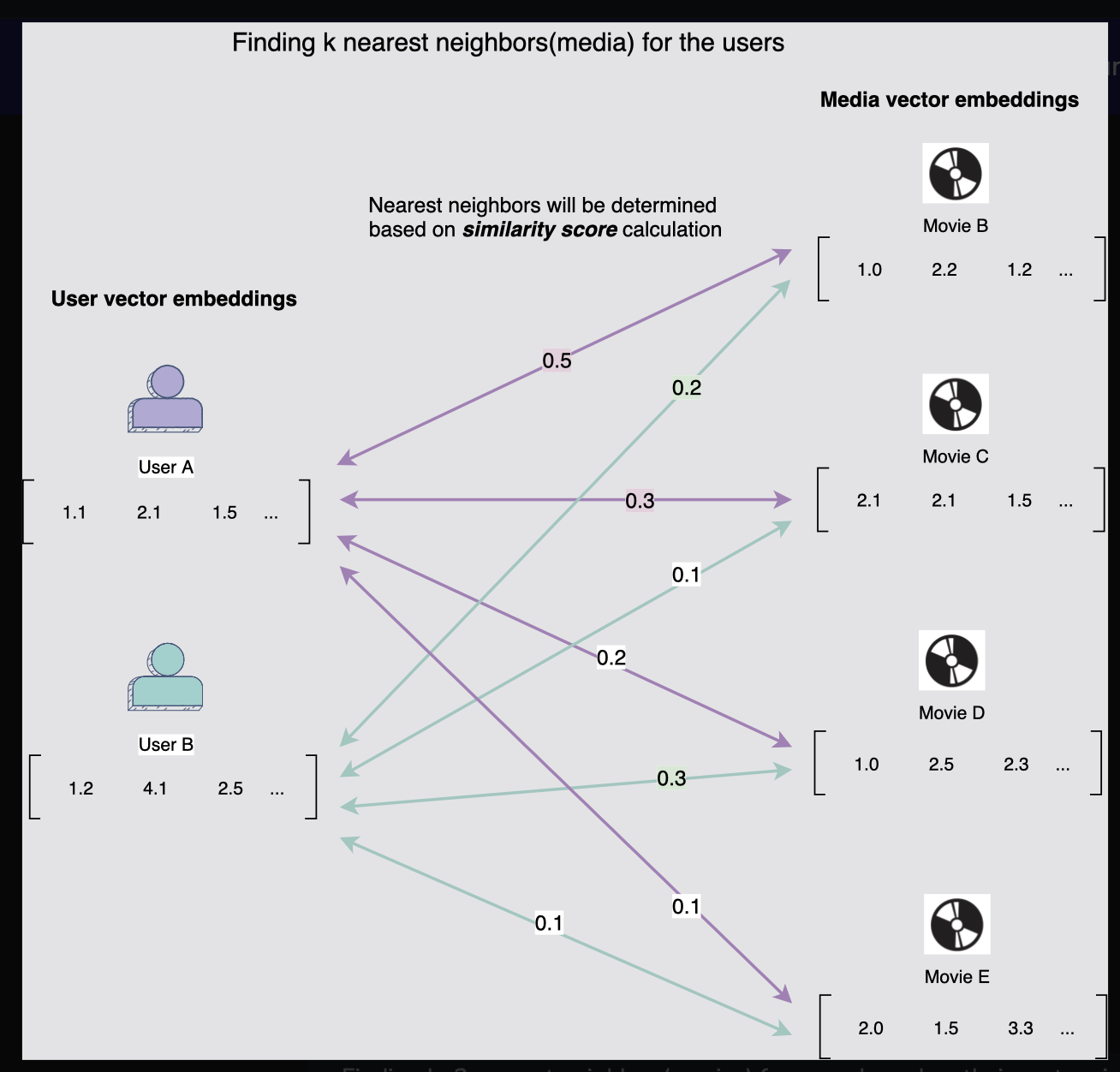
[그림] 벡터 유사성(내적)을 기반으로 사용자에 대한 k=2 가장 가까운 이웃(영화) 찾기
해당 기술들의 강점과 약점
위에서 논의한 추천 후보 생성 접근 방식의 강점과 약점은 다음과 같다.
[1] 협업 필터링 :
- 협업 필터링은 사용자의 과거 상호 작용만을 기반으로 후보를 제안할 수 있다.
콘텐츠 기반 필터링과 달리 사용자 및 미디어 프로필을 생성하는 데 도메인 지식이 필요하지 않다. 또한 콘텐츠 기반 필터링을 사용하면 파악하기 어렵고 프로파일링하기 어려운 데이터 측면을 캡처할 수도 있다. - 그러나 협업 필터링에는 콜드 스타트 문제가 있다. 과거 상호작용이 적기 때문에 시스템에서 새로운 사용자와 유사한 사용자를 찾기가 어렵다. 또한, 새로운 미디어는 피드백을 제공한 사용자가 없기 때문에 즉시 추천될 수 없다.
[2] 신경망 기술 :
- 신경망 기술에도 콜드 스타트 문제가 있다.
미디어와 사용자의 임베딩 벡터는 신경망의 학습 과정에서 업데이트된다.
그러나 영화가 새 영화이거나 사용자가 새 사용자인 경우 둘 다 수신된 피드백과 제공되는 피드백의 인스턴스가 각각 적다. - 더 나아가 이는 임베딩 벡터를 적절하게 업데이트할 만큼 충분한 훈련 예제가 부족하다는 것을 의미한다. 따라서 콜드 스타트 문제가 발생한다.
[3] 콘텐츠 기반 필터링:
- 이러한 시나리오에서는 콘텐츠 기반 필터링이 더 우수하다.
하지만 후보 생성을 시작하려면 사용자의 선호도와 관련된 일부 초기 입력이 필요하다. - 이 입력은 신규 사용자에게 선호 사항을 공유하도록 요청하는 온보딩 프로세스의 일부로 획득할 수 있다. 초기 입력이 있으면 사용자 프로필을 생성한 다음 미디어 프로필과 일치시킬 수 있다. 또한 새로운 미디어의 프로필은 수동으로 설명이 제공되므로 즉시 구축할 수 있다.
참고사이트
