preview
- 이전 장에서 딥러닝과 딥러닝의 주요 요소에 대해 알아보았다면 이번 장에서는 딥러닝의 주요 요소 중 model에 대해 알아보려고 한다.
- 인공신경망의 시초가 되는 모델인 perceptron에 대해 알아보고 여러 Layer를 거치며 딥 해진 Multi-Layer Perceptron을 pytorch로 구현해보자!
- 퍼셉트론(Perceptron)이란?
- 다층퍼셉트론(Multi Layer Perceptron)이란?
- Pytorch로 Multi Layer Perceptron 구현해보기
퍼셉트론(Perceptron)이란?
뉴런이 하나뿐인 가장 간단한 형태의 신경망이다. 인간의 뉴런과 비슷하게 작동하도록 고안된 방법이다.
🆀 퍼셉트론은 인간의 뉴런과 비슷하게 작동한다고 하였는데 인간의 뉴런은 어떤 방식으로 작동할까?
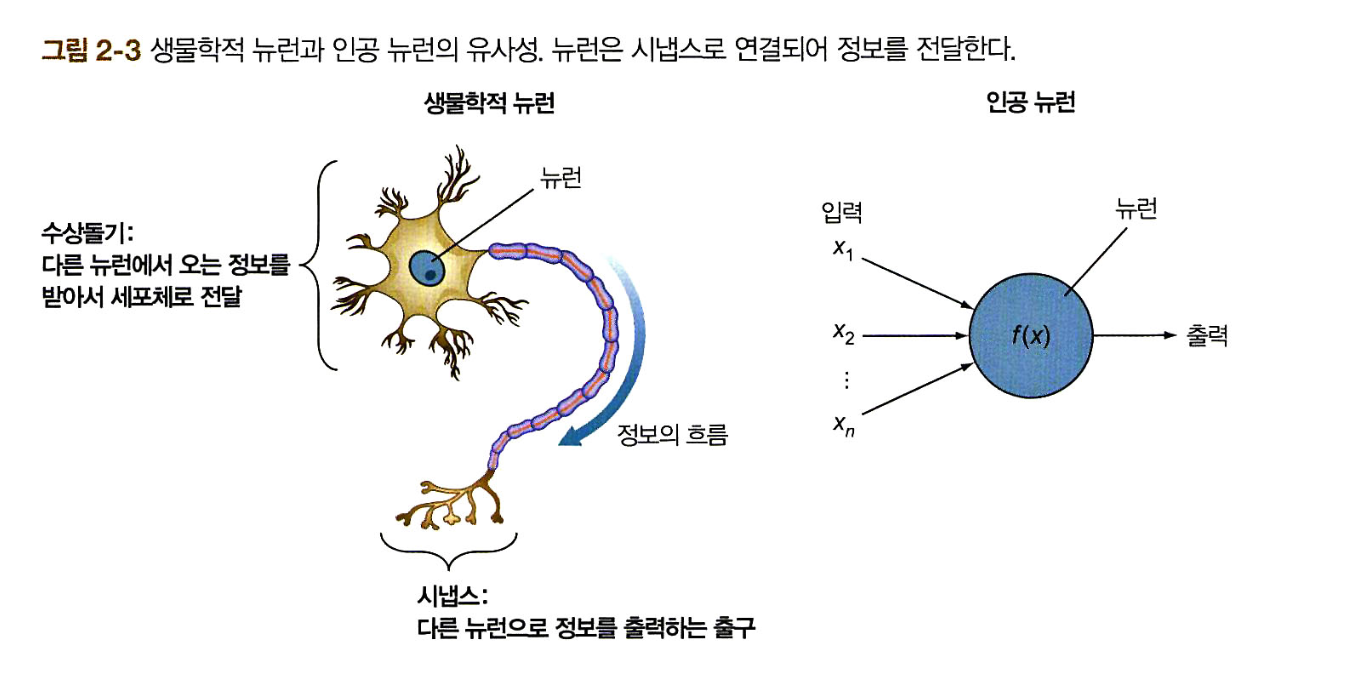
🅰 생물학적 뉴런은 여러 개의 수상돌기가 서로 다른 세기의 전기적 신호를 받고 이 신호 세기의 합이 정해진 임곗값을 넘으면 시냅스를 통해 출력 신호를 본낸다.
🆀 퍼셉트론은 어떻게 인간의 뉴런을 모방하였을까?
🅰 퍼셉트론은 전체 입력 신호 세기의 합을 구하는 선형결합(linear combination)과 입력의 신호 세기의 합이 임곗값을 초과할 때만 출력 신호를 보내는 활성화 함수(activate function)를 통해 인간의 뉴런을 모형화한다.
👉 선형결합(linear combination)이란?
-
입력값의 각각 가중치를 곱한 값들의 합에 bias(편향)을 더한 값으로 정의된다.
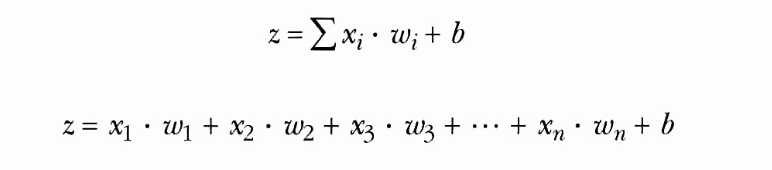
-
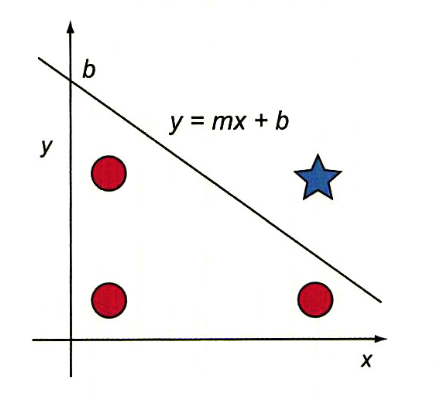
이때 편향을 더해주는 이유는 가중합을 함수로 정의하면 편향은 y절편으로 볼 수 있으며 편향을 조정해서 데이터에 대한 예측이 더욱 정확하도록 직선의 위치를 위아래로 조절할 수 있다.
-
즉, 편향이 없다면 직선은 항상 원점을 지나므로 그만큼 부정확한 예측 결과를 얻게 된다
👉 활성화 함수(activate function)이란?
- 활성화 함수는 뇌에서 결정을 내리는 역할로 입력을 선형결합한 가중합이 정해진 임계값보다 크면 뉴런을 활성화시킨다
👉 퍼셉트론의 학습 방법
- 뉴런이 입력을 선형결합하여 가중합을 계산한 뒤 활성화 함수에 입력해서 예측값 ^y을 결정한다. 이 과정을 순전파라고 한다
- 예측값과 실제값을 비교해 오차를 계산한다
- 오차에 따라 가중치를 조정한다. 예측값이 너무 높으면 예측값이 낮아지도록 조정하고, 예측값이 너무 낮으면 예측값이 높아지도록 가중치를 조정한다
- 이 과정을 반복하며 오차가 0에 가깝도록 가중치를 조정한다.
🆀 하나의 뉴런으로 구성된 퍼셉트론을 알아봤는데 세상의 복잡한 문제들을 하나의 뉴런만으로 해결가능할까?
🅰 퍼셉트론은 결국 선형함수로 학습된 뉴련이 데이터를 나누는 경계가 직선으로 복잡한 문제들인 비선형 데이터를 정확하게 분리할 수 없다. 따라서 하나의 뉴런보단 여러개의 뉴런을 추가해야 비선형데이터에 더 적합한 경계를 얻을 수 있다.
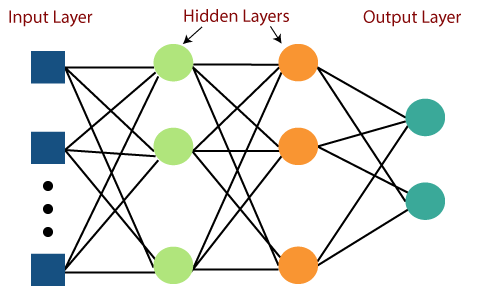
다층 퍼셉트론(Multi Layer Perceptron)이란?
다층퍼셉트론(Multi Layer Perceptron)은 퍼셉트론을 이루어진 층(Layer) 여러 개를 순차적으로 붙여 높은 형태 이다.
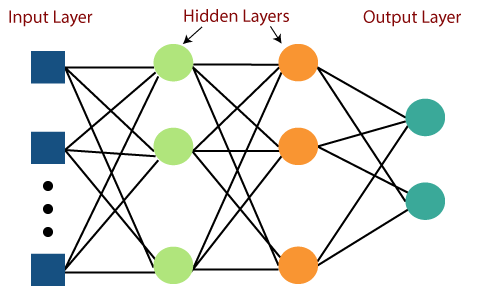
Pytorch로 Multi Layer Perceptron 구현하기
- pytorch를 이용하여 실제 Multi Layer Perceptron을 구현해보자
- 해당 내용은 네이버부스트캠프AITech에서 제공한 코드를 기준으로 재가공하여 만들어진 코드이다.
- 필자는 M1 사용자로서 M1의 GPU를 사용하는 코드를 추가 하였다.
1. 필요한 패키지 import 및 device 할당
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
%matplotlib inline # 셀에 그래프 출력하도록 설정
%config InlineBackend.figure_format='retina' # 레티나 설정 - 폰트 주변이 흐릿하게 보이는 것을 방지해 글씨가 좀 더 선명하게 보임
print ("PyTorch version:[%s]."%(torch.__version__)) # 토치 버전 확인
# device에 일반 GPU or M1 GPU or CPU를 할당해주는 코드
if torch.cuda.is_available() : # 일반 GPU 사용시
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
elif torch.backends.mps.is_available(): # 맥 M1 GPU 사용시
device = torch.device('mps:0' if torch.backends.mps.is_available() else 'cpu')
else:
device = torch.device('cpu')
print ("device:[%s]."%(device))
'''
<셀 출력>
PyTorch version:[1.12.1].
device:[mps:0].
'''
- 필자는 vscode에서 해당 코드를 실행하였으며 device에 M1 GPU를 할당하였다
2.MNIST 데이터셋로 DataLoader 생성하기
# MNIST 데이터셋 다운로드
from torchvision import datasets,transforms
mnist_train = datasets.MNIST(root='./data/',train=True,transform=transforms.ToTensor(),download=True)
mnist_test = datasets.MNIST(root='./data/',train=False,transform=transforms.ToTensor(),download=True)
# DataLoader 생성
BATCH_SIZE = 256
train_iter = torch.utils.data.DataLoader(mnist_train,batch_size=BATCH_SIZE,shuffle=True,num_workers=1)
test_iter = torch.utils.data.DataLoader(mnist_test,batch_size=BATCH_SIZE,shuffle=True,num_workers=1)
- 배치사이즈는 256, suffle은 True이므로, 다운로드 받은 MNIST를 랜덤으로 256개씩 추출해 줄 것이다.
3. MLP 모델 생성하기
class MultiLayerPerceptronClass(nn.Module):
"""
Multilayer Perceptron (MLP) Class - nn.Module을 상속하는 클래스임
__init__ : 변수 초기화
name : 모델명
xdim : input 데이터 크기
hdim : 히든레이어 크기
ydim : output 데이터 크기
lin_1 : input - hidden1 선형변환
lin_2 : hidden1 - output 선형변환
init_param : 파라미터 초기화
init_param : 파라미터 초기화
nn.init.kaiming_normal_(weight) : 가중치 텐서에 정규분포 N(0, std^2) 를 따르는 He 초기화를 실행함
nn.init.zeros_(bia) : 편향 텐서에 스칼라 0으로 채움
forward : 순전파 실행
input - 선형변환1 - 활성화함수(렐루) - 선형변환2 - output
"""
def __init__(self,name='mlp',xdim=784,hdim=256,ydim=10):
super(MultiLayerPerceptronClass,self).__init__()
self.name = name
self.xdim = xdim
self.hdim = hdim
self.ydim = ydim
self.lin_1 = nn.Linear(self.xdim, self.hdim)
self.lin_2 = nn.Linear(self.hdim, self.ydim)
self.init_param() # initialize parameters
def init_param(self):
nn.init.kaiming_normal_(self.lin_1.weight)
nn.init.zeros_(self.lin_1.bias)
nn.init.kaiming_normal_(self.lin_2.weight)
nn.init.zeros_(self.lin_2.bias)
def forward(self,x):
net = x
net = self.lin_1(net)
net = F.relu(net)
net = self.lin_2(net)
return net
M = MultiLayerPerceptronClass(name='mlp',xdim=784,hdim=256,ydim=10).to(device)
loss = nn.CrossEntropyLoss() # 교차 엔트로피 손실
optm = optim.Adam(M.parameters(),lr=1e-3) # 옵티마이저 : 아담, 학습률 1e-3
- MultiLayerPerceptronClass라는 이름의 클래스를 생성하였고 해당 클래스는 nn.Module을 상속한다.
- init_param 함수에서는 파라미터를 초기화하는데 가중치 텐서에는 He 초기화 초기화를 실시하고, 편향은 0으로 채워주었다
- forward 함수에서 Layer1 - 렐루함수 - Layer2를 거처 output이 나오도록 하였다
- 변수 M에 생성한 모델을 할당하였고, loss는 교차 엔트로피 손실함수를 사용하고, 옵티마이저로 아담, 학습률을 1e-3으로 지정해주었다
4. 학습할 클래스를 만들었으니 평가해줄 함수도 생성해보자
def func_eval(model,data_iter,device):
'''
model
모델 변수 지정
data_iter
torch.utils.data.DataLoader로 지정된 변수 지정
device
GPU or CPU 지정
'''
with torch.no_grad():
# with torch.no_grad()의 주된 목적은 autograd을 끔으로서 메모리 사용량 줄이고 연산속도 향상시킴
model.eval() # evaluate (affects DropOut and BN)
n_total,n_correct = 0,0
for batch_in,batch_out in data_iter:
# 데이터셋을 batch_size 갯수만큼 feed -> X.shape : (256,1,28,28), Y.shape : (256)
y_trgt = batch_out.to(device)
model_pred = model(batch_in.view(-1,28*28).to(device))
# model(x값) (256, 1*28*28)으로 변환, 1,28,28인 데이터를 한줄로 펼친다고 생각하면 된다
_,y_pred = torch.max(model_pred.data,1)
# 예측값 중 가장 높은 값 1개를 반환
n_correct += (y_trgt == y_pred).sum().item()
# 정답과 예측값이 경우만 카운트
n_total += batch_in.size(0)# feed된 데이터 수 카운트
val_accr = (n_correct/n_total) # 정확도 : 일치값 수 / feed된 데이터 수
model.train() # back to train mode -> 역전파실행
return val_accr
- 위 코드 중 변수 model_pred에 batch_in.view(-1,28*28) input된 데이터를 부분에 관한 설명을 덧붙이자면 아래와 같다
# batch_in.view(-1,1*28*28) 예시
num = [1,2,3,4,5,6,7,8]
tensor = torch.tensor(num)
a = tensor.view(-1,1,2,2) # a.shape : (2, 1, 2 ,2)
print('변환 전')
print(a)
print('변환 후')
a.view(-1,2*2*1)
'''
<출력>
변환 전
tensor([[[[1, 2],
[3, 4]]],
[[[5, 6],
[7, 8]]]])
변환 후
tensor([[1, 2, 3, 4],
[5, 6, 7, 8]])
'''
- 전체 데이터가 shape이 (1,1,2,2)인 1개 데이터가 2개 있는 형태라고 할 때
- 각 데이터를 한줄로 펼치면 최종 shape이 (2, 4)가 되는 것이다
5. 학습 진행
print ("Start training.")
M.init_param() # initialize parameters
M.train()
EPOCHS,print_every = 10,1 # 학습 횟수, 출력 조건
for epoch in range(EPOCHS):
loss_val_sum = 0
for batch_in,batch_out in train_iter:
# batch_in - X, batch_out - Y
# Forward path
y_pred = M.forward(batch_in.view(-1, 28*28).to(device)) # 예측값 추출
loss_out = loss(y_pred,batch_out.to(device)) #정답값과 예측값의 loss 계산
# Update - backward path
optm.zero_grad() # reset gradient - 새로 계산한 미분값을 넣어주기 전에 기존에 구한 미분값을 reset
loss_out.backward() # backpropagate - 미분값 계산
optm.step() # optimizer update - 구해진 미분값으로 가중치 업데이트
# loss 저장
loss_val_sum += loss_out
loss_val_avg = loss_val_sum/len(train_iter)
# print_every 단위로 loss와 정확도 Print
if ((epoch%print_every)==0) or (epoch==(EPOCHS-1)):
train_accr = func_eval(M,train_iter,device)
test_accr = func_eval(M,test_iter,device)
print ("epoch:[%d] loss:[%.3f] train_accr:[%.3f] test_accr:[%.3f]."%
(epoch,loss_val_avg,train_accr,test_accr))
print ("Done")
'''
<출력>
Start training.
epoch:[0] loss:[0.387] train_accr:[0.941] test_accr:[0.941].
epoch:[1] loss:[0.173] train_accr:[0.963] test_accr:[0.960].
epoch:[2] loss:[0.123] train_accr:[0.972] test_accr:[0.967].
epoch:[3] loss:[0.094] train_accr:[0.979] test_accr:[0.971].
epoch:[4] loss:[0.076] train_accr:[0.983] test_accr:[0.974].
epoch:[5] loss:[0.062] train_accr:[0.987] test_accr:[0.976].
epoch:[6] loss:[0.051] train_accr:[0.989] test_accr:[0.978].
epoch:[7] loss:[0.042] train_accr:[0.991] test_accr:[0.978].
epoch:[8] loss:[0.035] train_accr:[0.993] test_accr:[0.979].
epoch:[9] loss:[0.030] train_accr:[0.995] test_accr:[0.979].
Done
'''
- 총 10번의 학습을 진행해 보았다
- 학습은 순전파와 역전파를 반복하면서 loss를 줄여나간다
6. Test 데이터로 모델 성능 확인하기
# test 데이터셋에서 랜덤으로 25개를 추출
n_sample = 25
sample_indices = np.random.choice(len(mnist_test.targets), n_sample, replace=False)
test_x = mnist_test.data[sample_indices]
test_y = mnist_test.targets[sample_indices]
# 랜덤추출한 test 데이터셋 예측값 추출
with torch.no_grad():
y_pred = M.forward(test_x.view(-1, 28*28).type(torch.float).to(device)/255.)
y_pred = y_pred.argmax(axis=1)
# 정답값,예측값,이미지 시각화
plt.figure(figsize=(10,10))
for idx in range(n_sample):
plt.subplot(5, 5, idx+1)
plt.imshow(test_x[idx], cmap='gray')
plt.axis('off')
plt.title("Pred:%d, Label:%d"%(y_pred[idx],test_y[idx]))
plt.show()
print ("Done")
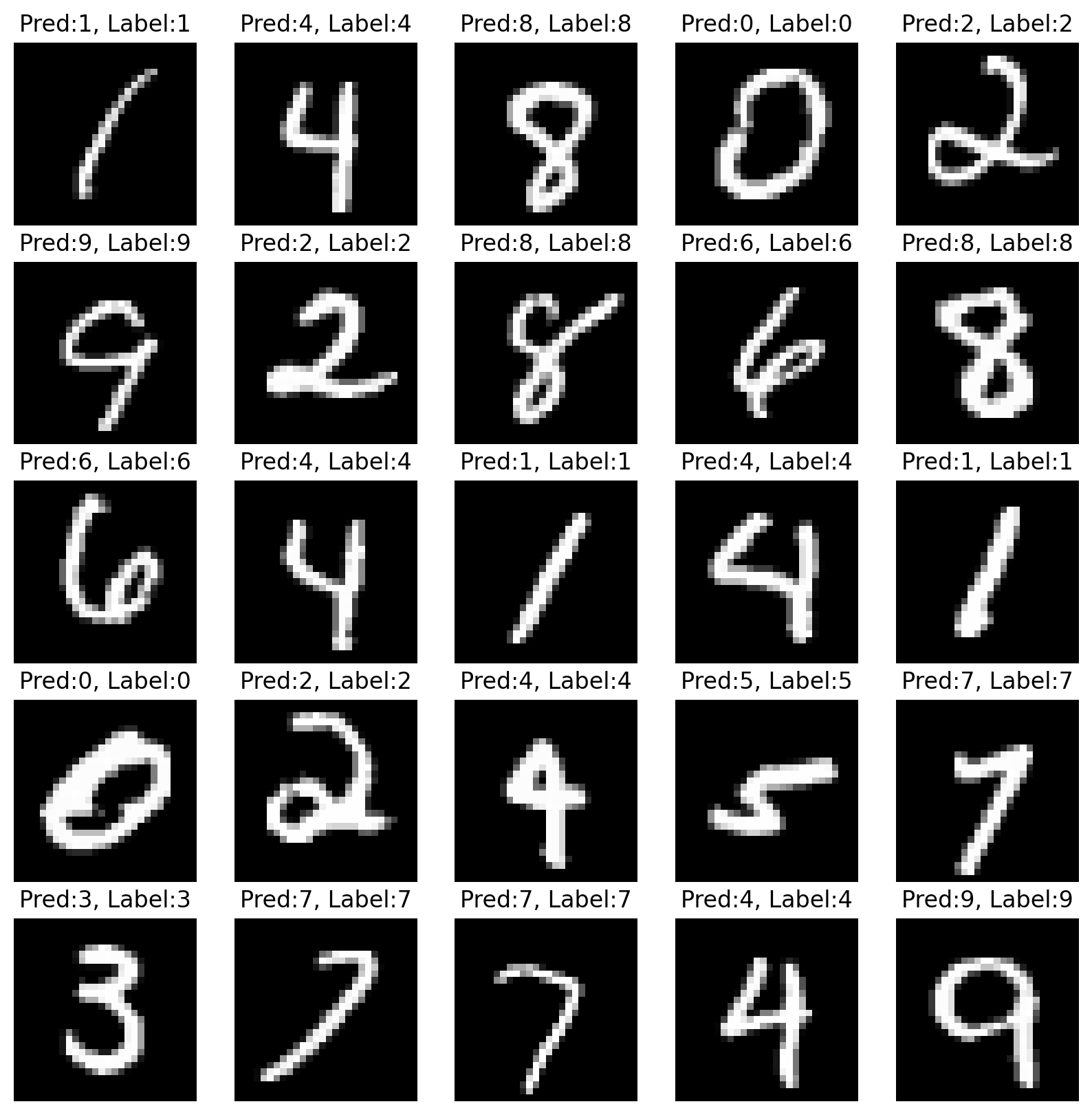
- 모델이 정확히 데이터를 맞추는 걸로 보여진다
