📸 Image Classification(이미지 분류)(3)- 👨🏫Transfer learning, Knowledge distillation, Noisy Student까지 | 내가보려고정리한AI🧐
DeepLearning

Preview
질 좋은 데이터셋은 매우 비싸고 얻기에 매우 힘들다. 이번 장에서는 질 좋은 데이터셋으로 학습된 모델을 Transfer 해서 small dataset으로 학습하는 Transfer learning와, Knowledge distillation 방법을 알아보고, 이를 이용한 Noisy Student 모델을 탐구해보겠다.
Transfer learning
Supervised learning(지도학습)은 매우 큰 스케일의 데이터셋을 요구한다. 하지만 새로운 Task에 적용 시 raw data를 Annotating 하는 것은 매우 비싸다.
또한 데이터가 적으므로 데이터 구축 시 사람이 클래스를 구분하여 학습데이터를 만들면 사람의 편향이 들어가 퀄리티가 높지 않은 데이터가 나올 확률이 높으므로 좋은 퀄리티를 만들어내는 것도 쉽지 않다.
🆀 유사한 데이터셋은 공통의 정보를 공유하고 있지 않을까? 또한 다른 Task여도 같은 이미지이지 공통점이 있지 않을까?
🅰 질 좋은 유사한 데이터셋으로 학습된 모델을 활용하면 우리는 쉽고 경제적으로 우리가 다루고 있는 task에 모델을 적용할 수 있을 것이다. 또한 성능도 어느정도 보장할 수 있을 것이다.
Transfer learning 방법론
-
Transfer knowledge from a pre-trained task to a new task
-
Fine-tuning the whole model
-
Teacher-student learning(Knowledge distillation)
Transfer knowledge
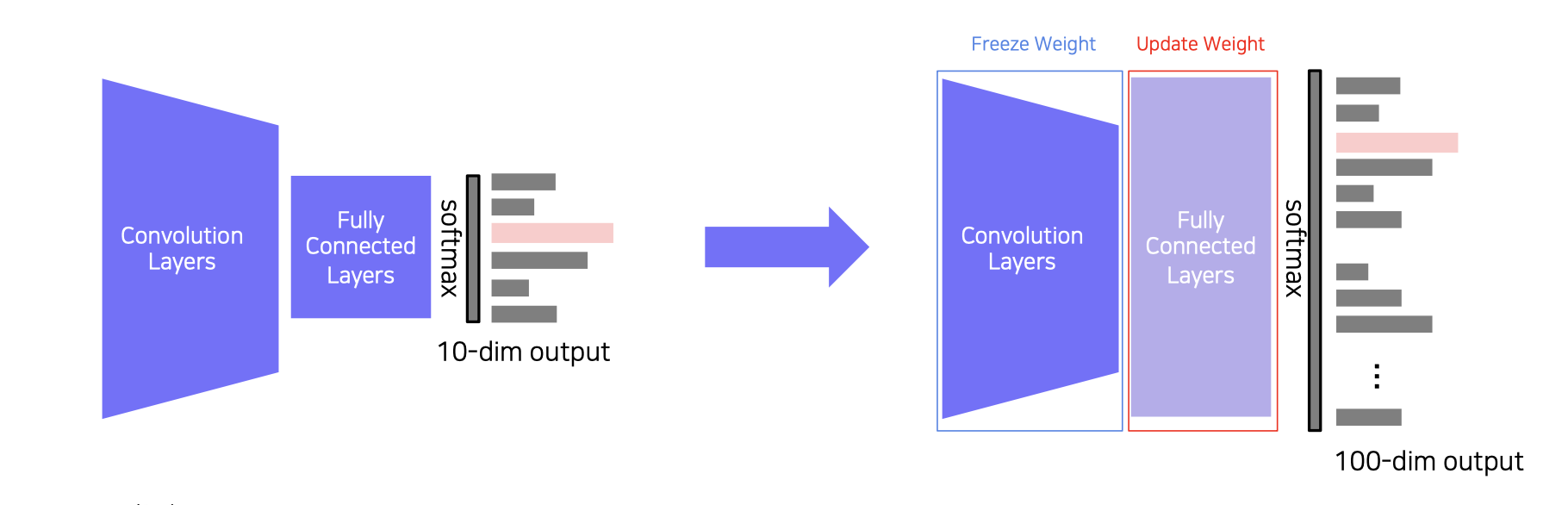
- Chop off the final layer of the pre-trained model,add and only re-train a new FClayer
- Extracted features preserve all the knowledge from pre-training
- 학습된 task를 새로운 Task로 지식을 이전 하기
- 하나의 데이터셋을 미리 학습한 모델의 FC layers에 새로운 테스크의 FC layers만 새로 붙이고 FC layers만 학습시킴
Fine-tuning
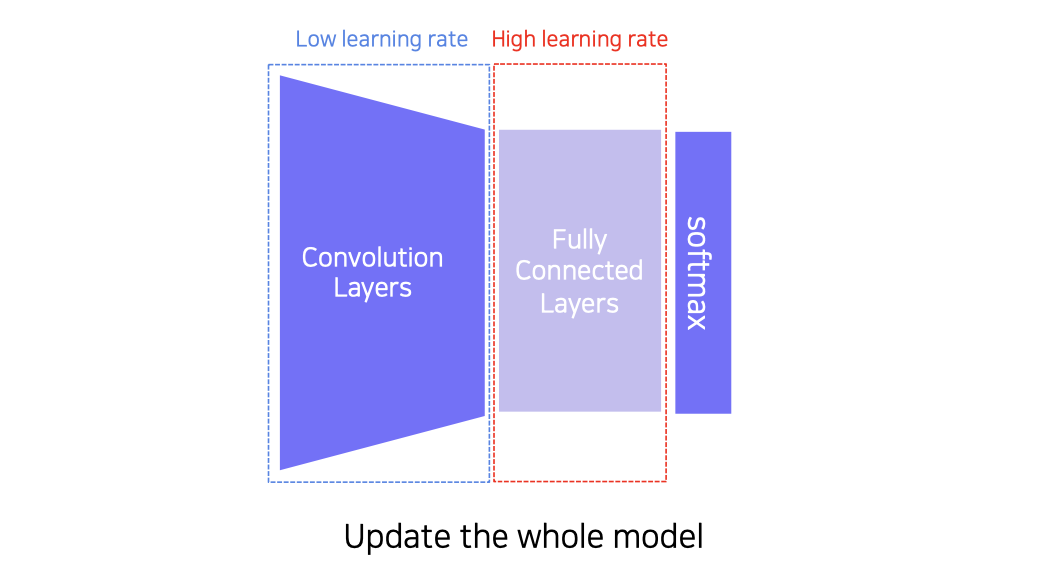
- 하나의 데이터셋을 미리 학습한 모델의 FC layers에 새로운 테스크의 FC layers만 새로 붙이고 FC에는 높은 학습률, Conv에는 낮은 학습률로 진행
- Replace the final layer of the pre-trained model to a new one,and re-train the whole model
- Set learning rates differently
Knowledge distillation
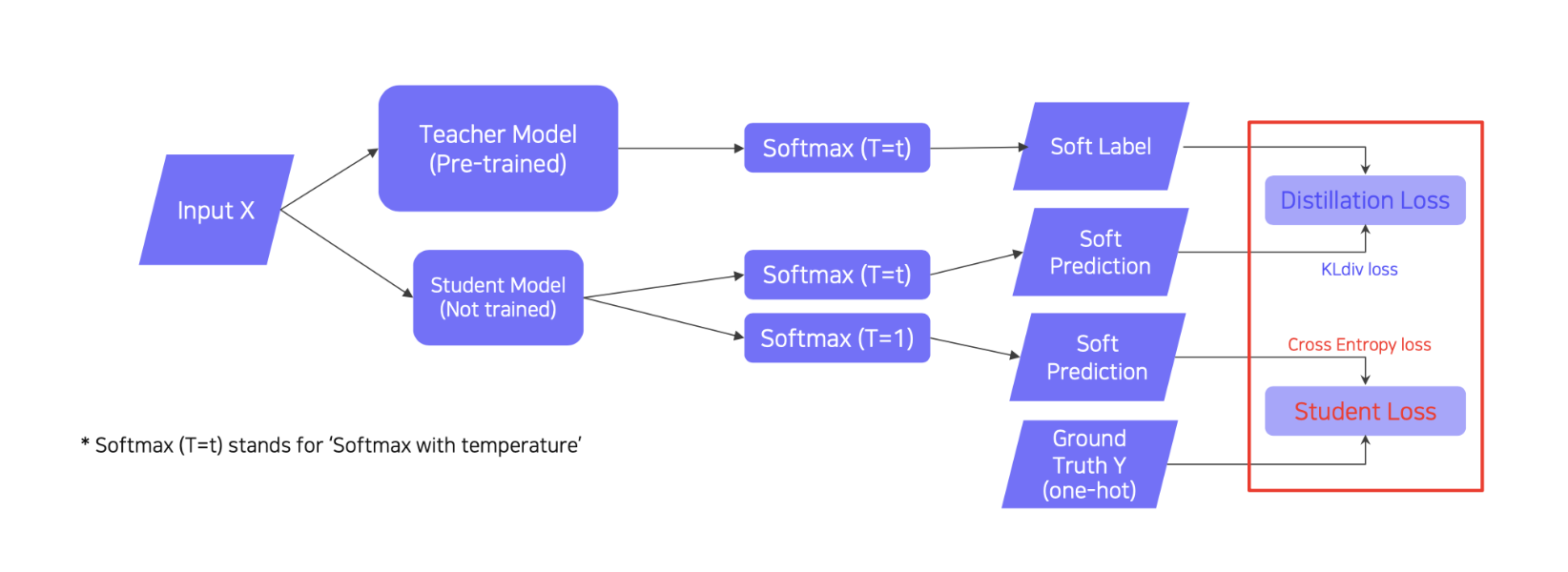
- knowledge distillation -> Teacher-student learning
- 미리 학습된 large 모델의 지식을 학습되지 않은 small 모델로 가져오는 것이다.
Used for model compression (Mimicking what a larger model knows)
Also,used for pseudo-labeling(Generating pseudo-labels for an unlabeled dataset)
The student network learns what the teacher network knows
The student network mimics outputs of the teacher network
Unsupervised learning, since training can be done only with unlabeled data
When labeled data is available, can leverage labeled data for training (StudentLoss)
Distillation loss to ‘predict similar outputs with the teacher model’
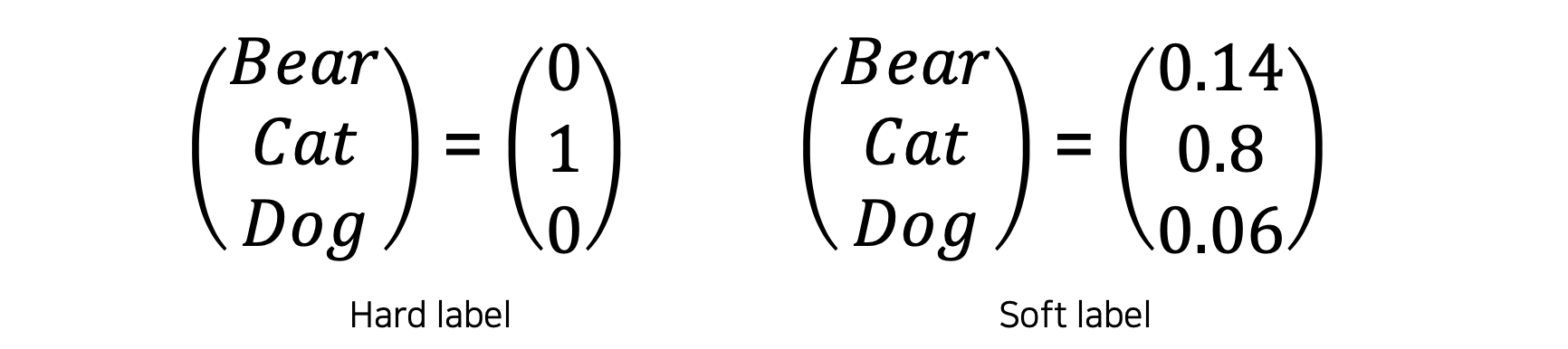
💁♀️ hard label vs soft label
hard label : 원-핫 벡터,소프트맥스를 지나 각 레이블별 값이 아닌 하나의 값만 존재
soft label : 소프트 맥스를 지나기전 값과 유사하다, 각 레이블별 확률값이 존재함.
soft label는 모델이 어떻게 생각하는지 얻기 좋다
💁♀️ Knowledge distillation시 Semantic information is not considered in distillation
-
Distillation Loss
-
KLdiv(Soft label,Soft prediction)
-
Loss = difference between the teacher and student network’s inference
-
Learn what teacher network knows by mimicking
-
Student Loss
-
Cross Entropy(Hard label,Soft prediction)
Loss = difference between the student network’s inference and true label -
Learn the “right answer”

Softmax with temperature (𝑇)
Softmax with temperature : controls difference in output between small & large input values
A large 𝑇 smoothens large input value differences
Useful to synchronize the student and teacher models’ outputs
Recap
Recap란
2019년 11월, ImageNet 데이터셋에 대해 State-of-the-art를 갱신한 논문이다.
Image recognition(classification) 분야는 AlexNet, VGG, ResNet 부터 시작해서 NASNet 최근에는 EfficientNet 등 많은 연구가 진행되며 발전해왔다. 이 모델들은 supervised learning으로 큰 labeled images를 필요로 한다. 하지만 unlabeled images를 이용하지는 않았다. 이 논문은 ImageNet에 속하지 않은 unlabeled images 까지 이용하여 ImageNet 정확성의 SOTA를 갱신하며, robustness 성능 까지 높이는 방법에 대해 설명한다.
Recap의 특징
- data augmentation
- Augment a dataset to make the dataset closer to real data distribution
- knowledge distillation
- Train a student network to imitate a teacher network
- Transfer the teacher network’s knowledge to the student network
- semi-supervied learning(Pseudo label-based method)
- Pseudo-label an unlabeled dataset using a pre-trained model,then use for training
- Leveraging an unlabeled data set for training!
data augmentation
💁♀️ data augmentation은 이미지를 자르거나, 밝기를 높이가 회전하기 등을 통해 실제 데이터와 간격을 줄이는 데이터 증강 방법이다.
💁♀️ 자세한 내용은 따로 정리하였다 -> Data augmentation(데이터 증강) - Image편
knowledge distillation
- knowledge distillation란 Teacher-student learning 방식으로
- large model의 지식을 모방하기 위해 model compression(압축)한다
- 레이블이 없는 데이터셋에 pseudo labels(가짜 레이블)을 생성해 사용한다
semantic information를 학습하는 것이 아님 하나하나의 값들이 중요한것이 아닌 전체 값이 중요
semi-supervied learning
💁♀️ Semi-supervised learning이란 training위해 leveraging unlabeled dataset을 통해 성능을 leveraging 하는 것이다.
🆀 왜 unlabeled data을 사용했을까?
🅰 labeled 데이터는 큰 데이터셋을 만들기 어렵고, unlabeled data를 사용하면 온라인상 모든 데이터를 사용할수 있기 때문에 많은 데이터 사용 가능하기 때문이다.
즉, semi- supervised learning이란 unsupervied + supervied 것이다.
💁♀️ Semi-supervised learning방법
1. labeled dataset 로 학습
2. unlabed 데이터의 label을 예측함(Pseudo-labeling)
3. 두개 데이터를 합쳐서 재학습함
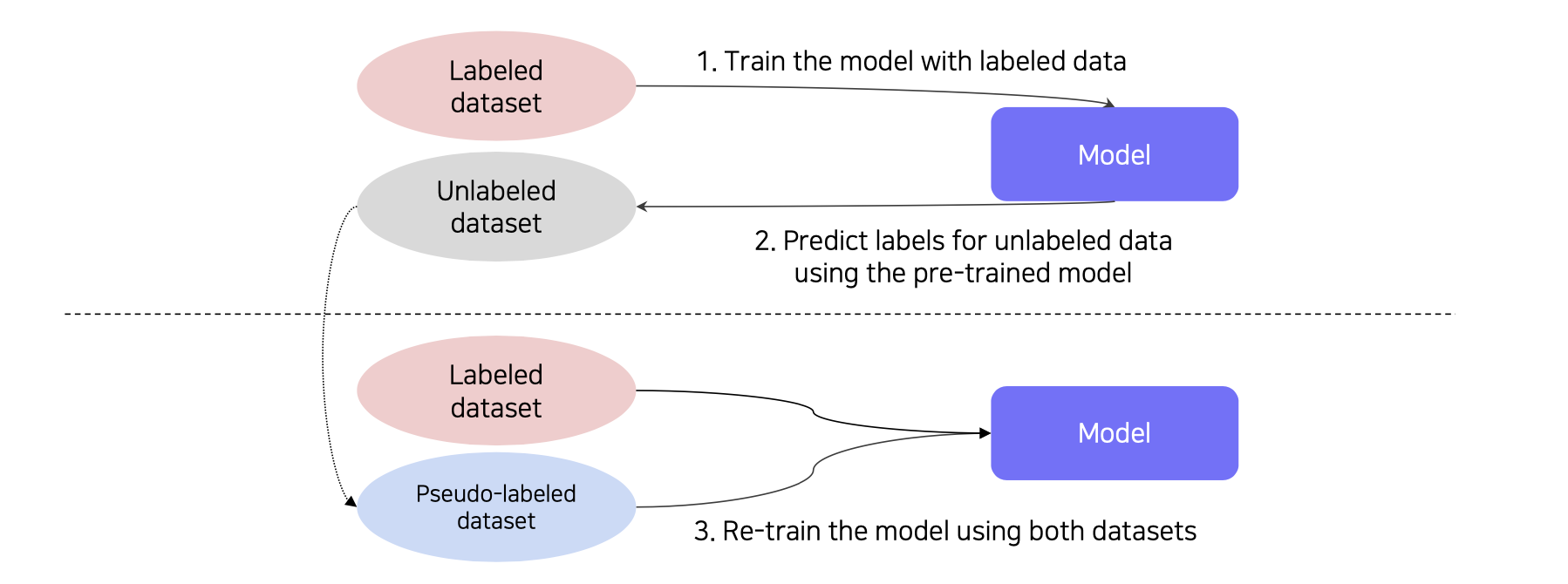
Recap의 구조
💁♀️ self-training
1. ImageMet 1M을 학습시킴 -> Teacher Model
2. Teacher Model로 300M의 unlabeld data를 예측함 -> pseudo-labeled data
3. 생성된 pseudo-labeled data를 ImageMet 1M과 함께 RandAugment를 적용해 Student Model을 학습함
4. 기존 Teacher Model을 날리고 학습된 Student Model를 Teacher Model로 replace함
5. 2~5부터 반복, 이때 Student Model는 조금씩 커짐
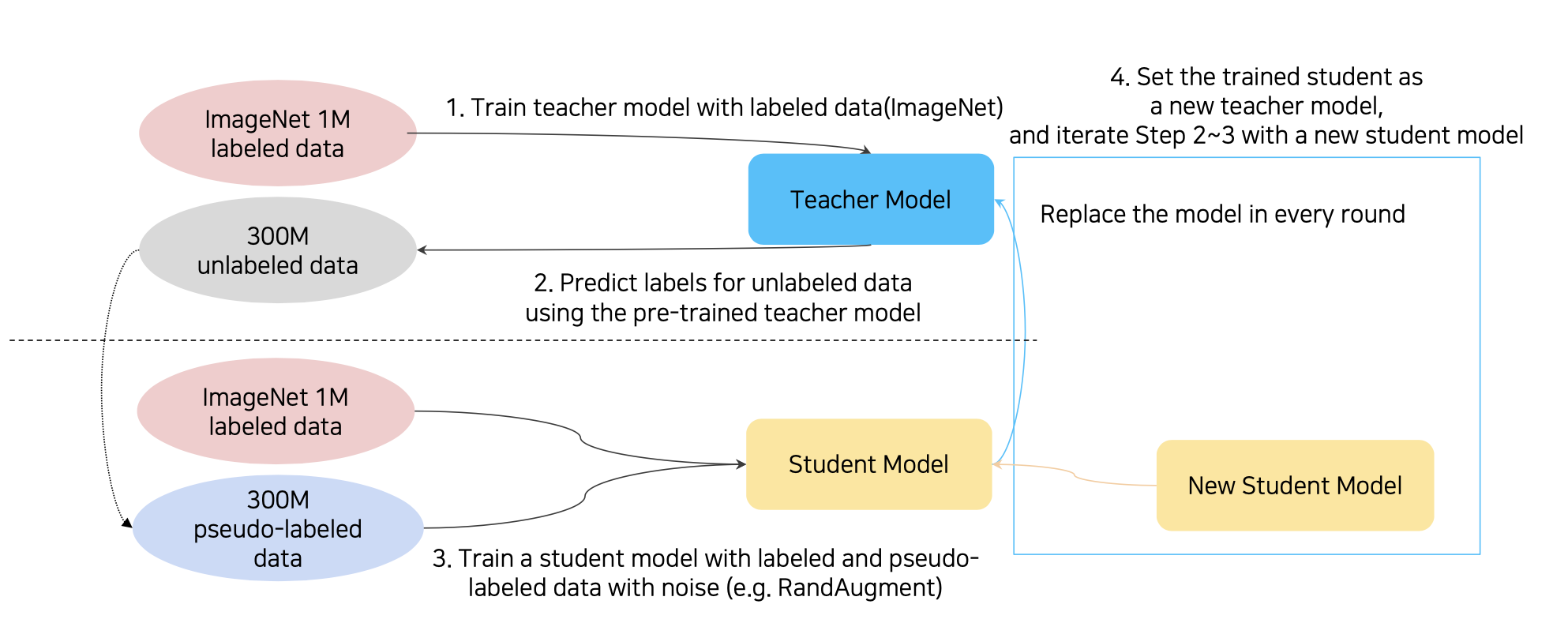
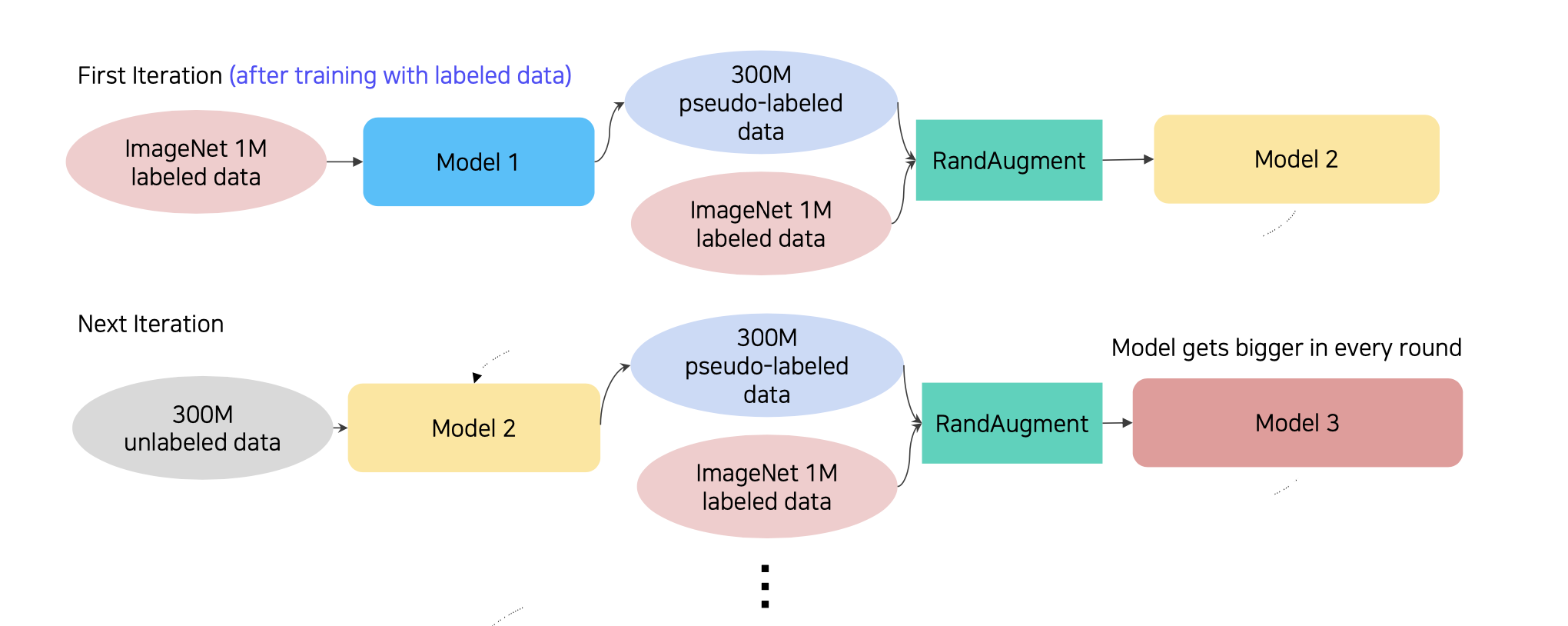
Recap의 성능
- ImageNet 2012 ILSVRC validation set accuracy
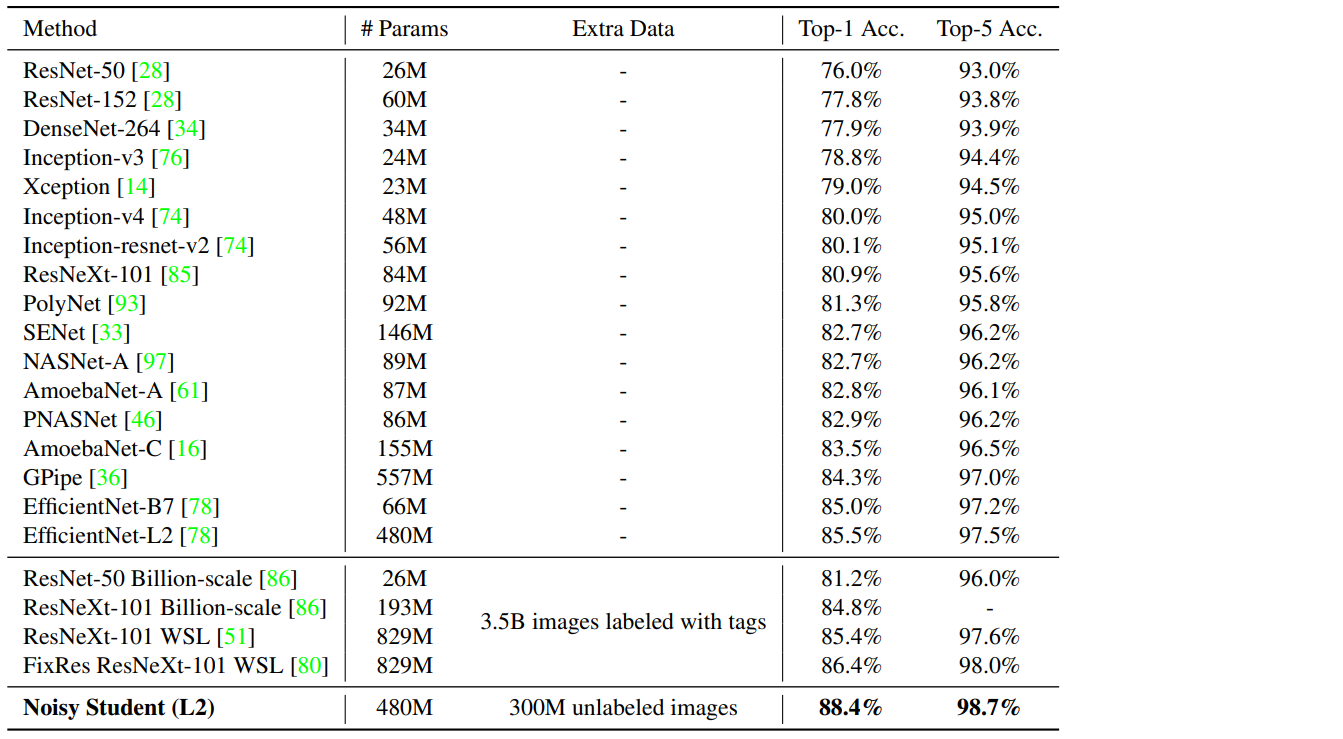
Noisy Student(EfficientNet-L2)가 88.4% top-1 accuracy로 SOTA를 갱신하였다.
기존 EfficientNet-B7에 비해 3.4% 성능 개선을 하였다.
마찬가지로 같은 구조인 EfficientNet-L2에서 Noisy Student 방법의 추가로 2.9% 성능 개선을 하였다.
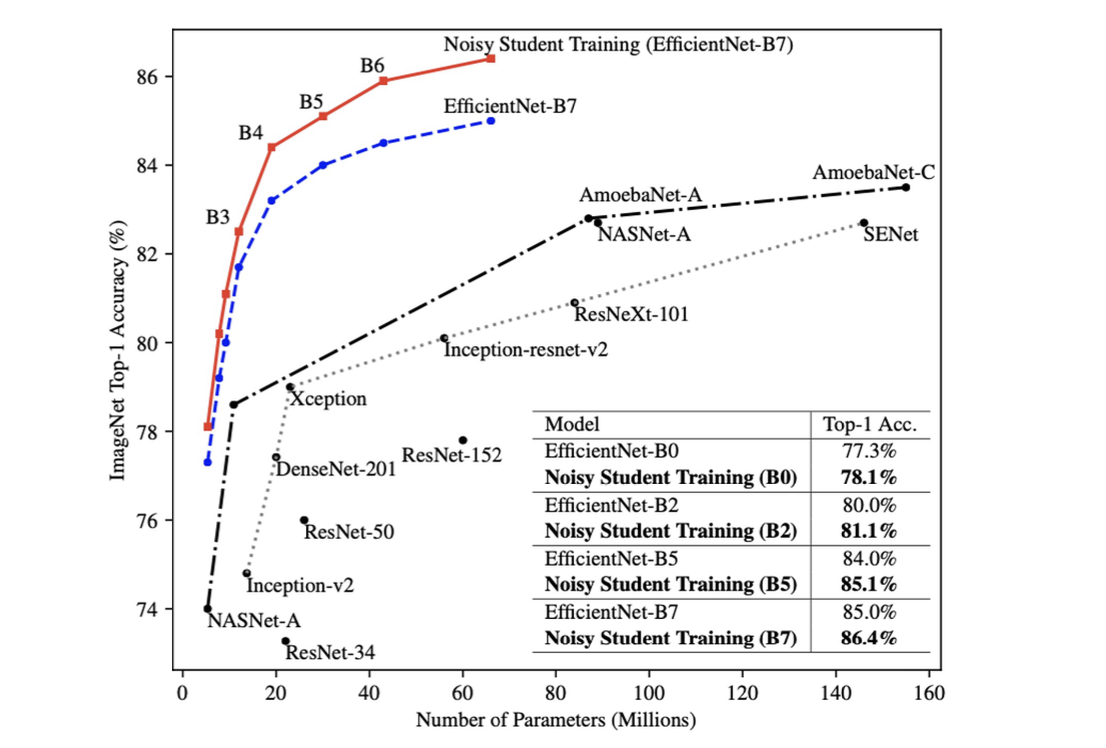
성능 향상도 향상인데 성능 자체가 압도적으로 높음을 보여주었다.
기존에 가장 성능이 좋았던 efficientNet을 이기면서 2019년 SOTA ImageNet classfication이 되었다.
-참고-
- 네이버 부스트캠프 AITech 5기
논문 리뷰 - Self-training with Noisy Student improves ImageNet classification
