Preview
학습 데이터는 세상의 모든 데이터와 항상 같을까? 학습 데이터는 현실 데이터의 부분이다. 즉, 학습데이터는 항상 현실 데이터와 차이가 있을 수 밖에 없다.
이런 차이를 Data augmentation를 통해서 줄여나갈 수 있다. 이번 장에서는 Image Data의 augmentation을 알아보겠다.
Data Augmentation
train data는 real data가 아니다. 세상 모든 데이터는 수집할 수 없기 때문에 train data는 샘플링한 데이터이다.
train data는 real data를 샘플링 한 것처럼 편향되어 있다.
Image train data는 선명한 데이터, 잘리지 않고 여백이 적은 이미지만 실제 이미지 데이터는 그렇지 않다.
💁♀️ Data Augmentation이란 그런 편향된 데이터와 실제 데이터 간의 간격을 줄이기 위한 방법론이다.
💁♀️ Image Data Augmentation은 이미지를 자르거나, 밝기를 높이가 회전하기 등등 실제 데이터와 간격을 줄이는 등으로 수행한다.
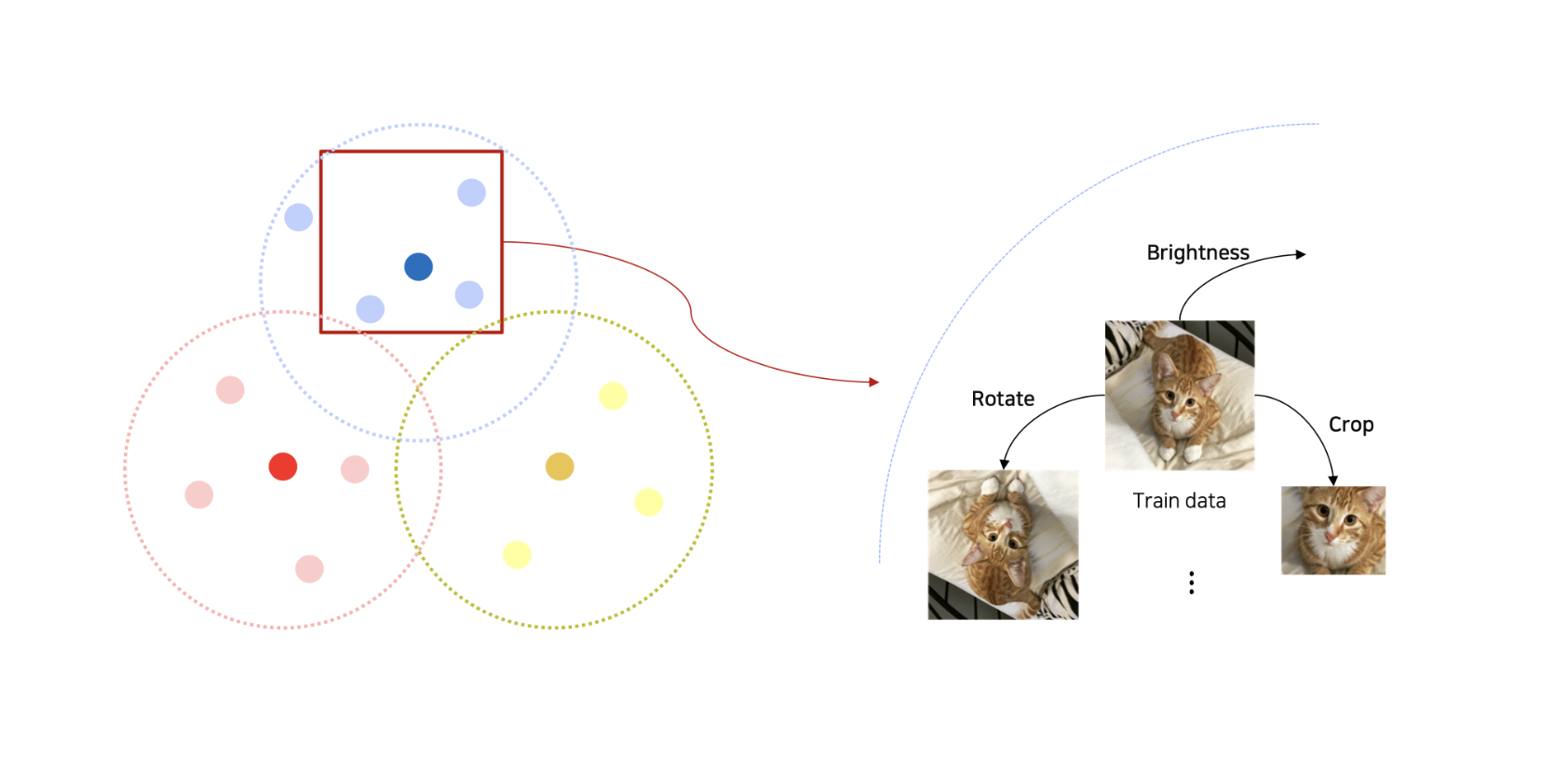
Image Data Augmentation 종류
crop
- 이미지를 잘라준다

brightness
- rgb 값에 숫자를 더해주거나 스케일링을 통해 가능하다.

rotate, flip
- pytorch- transformation, cv2.rotate, 등을 통해 수행할 수 있다.

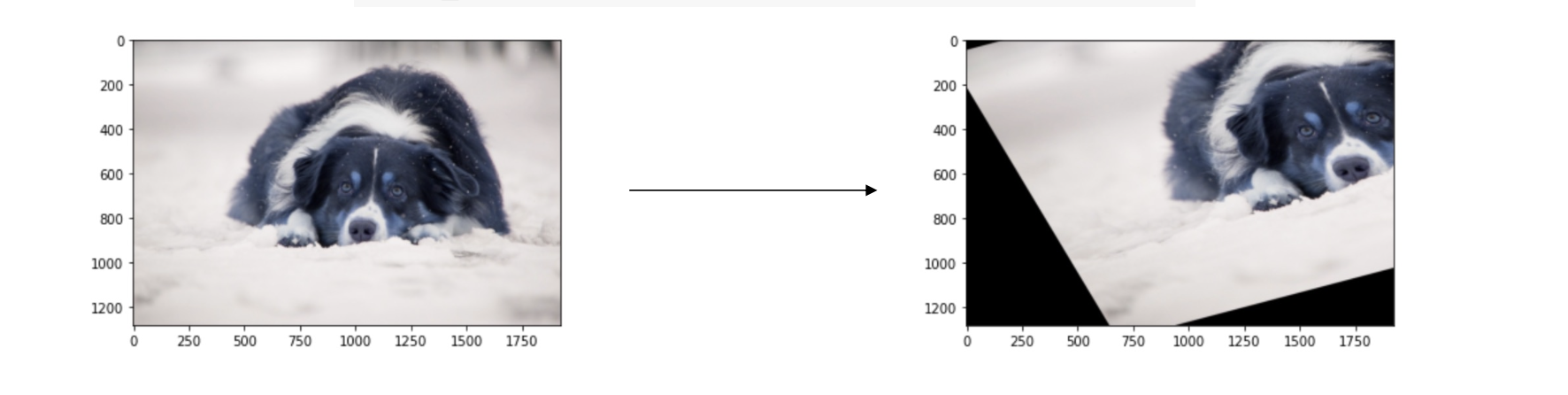
affine transformation
- 직사각형을 평행사변형으로 변환 해주는 등의 작업을 해준다
- -> cv2.warpAffine, cv2.getAffineTransform ...
cutmix
- 두 개 이미지를 잘라서 합치고, 클래스가 다르면 라벨도 합성해준다
- 모델이 물체 위치를 더 잘 찾도록 해주는 효과가 있다.

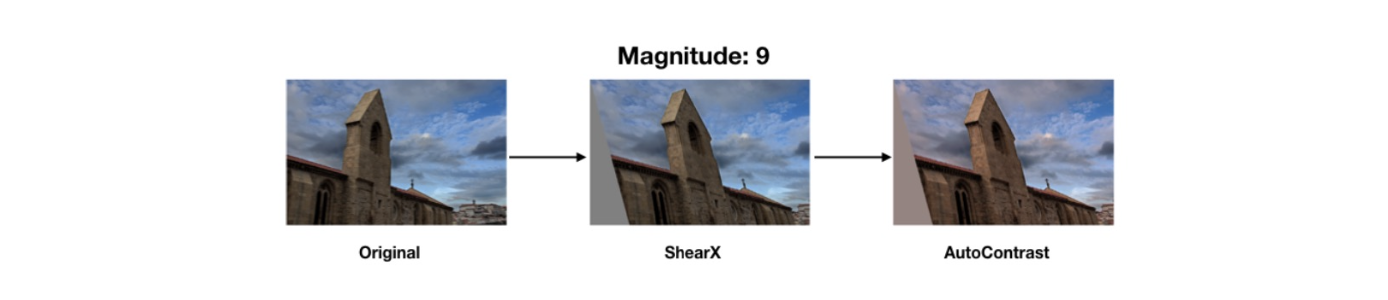
RandAugment
💁♀️ 많은 augmentation 방법이 존재하고 최고의 augmentation를 찾는 것이 힘들다
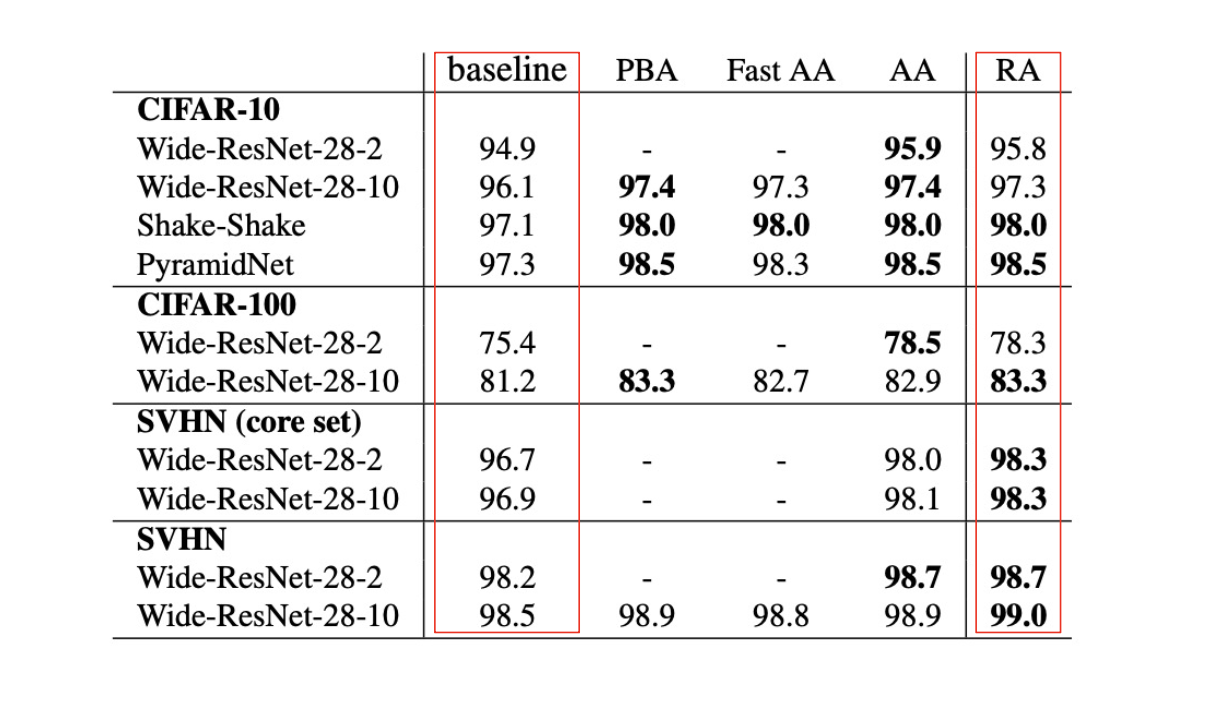
💁♀️ RandAugment는 자동적으로 최고의 augmentation 조합과 순서를 찾아주는 패키지이다
- 어떤 augmentation 사용건지, 얼마나 사용 magnitude, 어떤 순서로 할건지 의 n개 policy 중 샘플링 해준다.
- Policy={N augmentations to apply} by random sampling
- random sample -> apply -> evaluate augmentations


AI Learning, Parcelled Innovations, Carrying All