과적합
-
알고리즘이 학습 데이터에 과하게 적합한 상태이거나 정확하게 일치할 때 발생하며 그 결과 모델이 학습 데이터가 아닌 다른 데이터에서 정확한 예측을 생성하거나 결론을 도출할 수 없게 됨
-
새로운 데이터를 효과적으로 일반화할 수 없게됨 ➡️ 의도한 분류,예측 수행 불가
💡왜 문제가 될까?
- 모델이 샘플 데이터를 너무 오래 학습하거나 복잡하면 '노이즈' 또는 관련 없는 정보를 학습할 수 있는데 이때 모델이 노이즈를 기억하고 학습세트에 과하게 적합한 상태면
과적합이 됨
- 모델이 복잡해지면
가짜패턴까지 학습하게 됨
가짜패턴: 학습데이터에만존재하는 패턴, 다른셋에서 성능저하
Underfitting & Overfitting
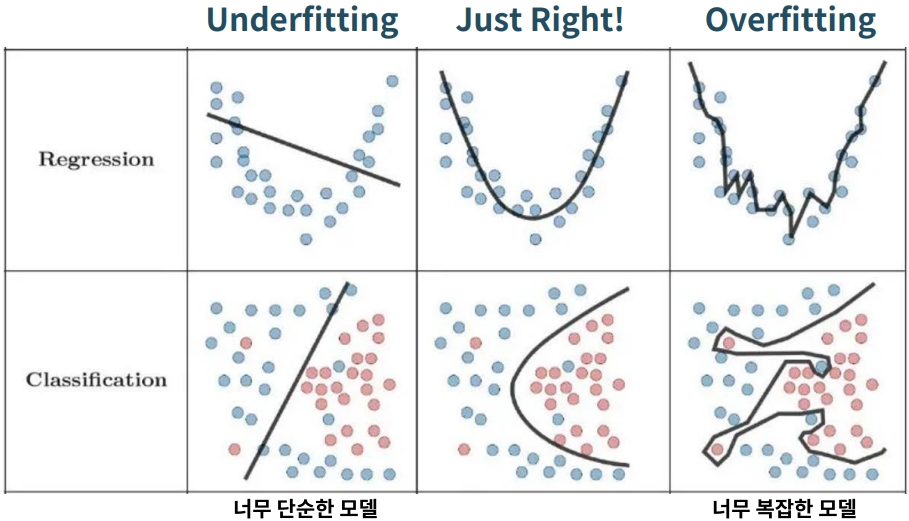
Underfitting: 너무 일찍 종료하거나 중요한 특징을 너무 많이 제외했을때 발생
모델 성능 높이기
모델링의 목적
- 학습용 데이터에 있는 패턴으로, 모집단 전체 데이터를 적절히 예측한 후에 학습한 모델은 모집다의 다른 데이터(val, test)도 잘 예측해야함
성능 최적화와 과적합의 관계
- 모델의 복잡도 : 학습용 데이터의 패턴을 반영하는 정도
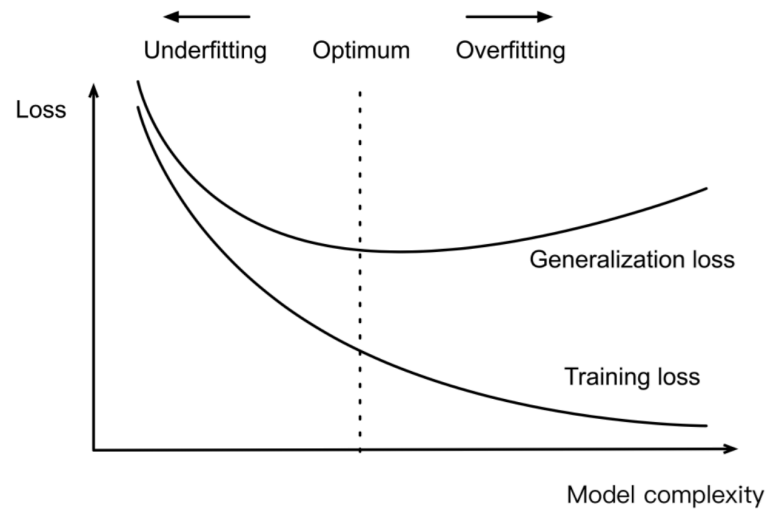
- 너무 단순한 모델 : train, val 성능이 떨어짐
- 적절히 복잡한 모델 : 적절한 예측력
- 너무 복잡한 모델 : train 성능 높고, val 성능 떨어짐
적절한 모델 만들기
- 적절한 복잡도 지점 찾기 ➡️ 하이퍼파라미터 조정
- Train error와 Validation error를 측정하고 비교 (관점은 Validation error!)
조절할 대상 : Epoch, learning_rate
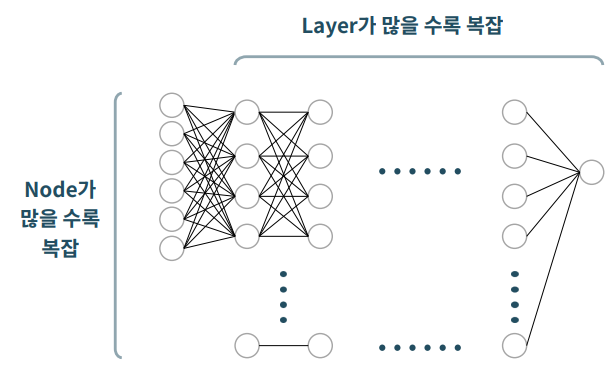
모델 구조 : hidden layer수, node 수
Early Stopping
Dropout
가중치 규제(Regularization)
hidden layer 수, node 수
Early Stopping
- 모델의 훈련을 조기에 중단하는 기법
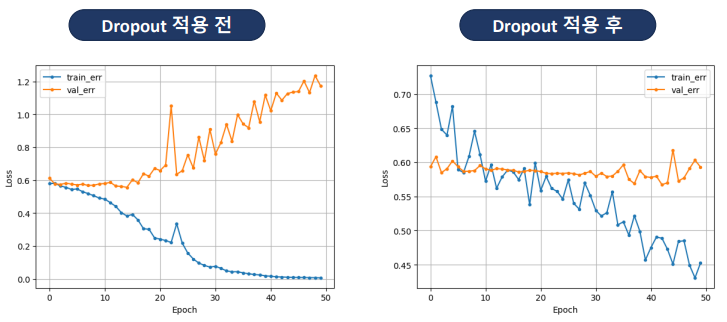
- epoch가 많으면 과적합 될 수 있다.
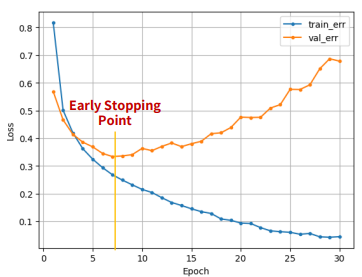
- 횟수가 증가할 수록 val error가 줄어들다가 어느 순간부터 증가하는 시점
Early Stopping 옵션
monitor: 기본값 val_loss
min_delta: 오차의 최소값에서 변화량이 몇 이상 돼야하는지 지정
patience: 오차가 줄어들지 않는 상황을 몇 번 기다려줄 건지 지정
# EarlyStopping 설정 ------------------
from keras.callbacks import EarlyStopping
es = EarlyStopping(monitor = 'val_loss', min_delta = 0.001, patience = 5)
# fit안에 지정
hist = model.fit(x_train, y_train, epochs = 100, validation_split=0.2, callbacks = [es]).historyDropout
- 레이어의 가중치 일부를 사용하지 않는 방법
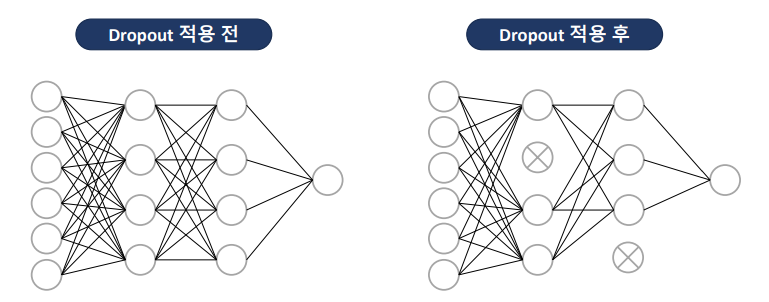
hidden layer 다음에 dropout layer 추가
0.4: hidden layer노드 중 40% 임의로 제외 시킴 (보통 0.2 ~ 0.5 사이)
feature가 적을 경우 rate를 낮추고, 많을 경우 rate를 높이는 시도
from keras.layers import Dropout
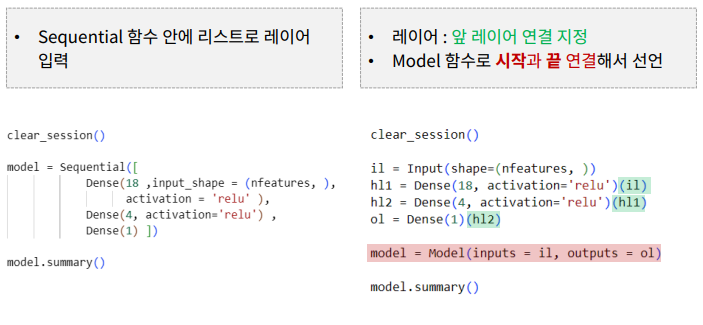
model3 = Sequential([Input(shape = (nfeatures,)),
Dense(64, activation = 'relu'),
Dropout(0.3),
Dense(16, activation = 'relu'),
Dropout(0.3),
Dense(10, activation = 'softmax')])Functional API
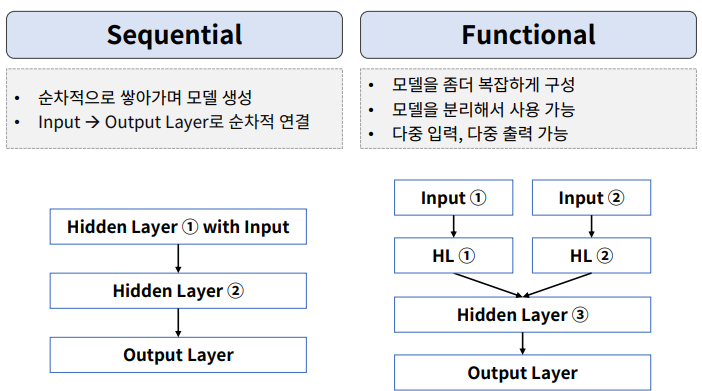
Sequential API vs Functional API
다중 입력
- 데이터 특성에 따른 서로 다른 여러개의 모델이 input으로 사용되어 하나의 output을 내는 네트워크
concatenate: 옆으로 붙이기, 하나의 레이어처럼 묶기
# 모델 구성
input_1 = Input(shape=(nfeatures1,), name='input_1')
input_2 = Input(shape=(nfeatures2,), name='input_2')
# 입력을 위한 레이어
hl1_1 = Dense(10, activation='relu')(input_1)
hl1_2 = Dense(20, activation='relu')(input_2)
# 두 히든레이어 옆으로 합치기(= pd.concat)
cbl = concatenate([hl1_1, hl1_2])
# 추가레이어
hl2 = Dense(8, activation='relu')(cbl)
output = Dense(1)(hl2)
# 모델 선언
model = Model(inputs = [input_1, input_2], outputs = output)
#모델 예측 - 리스트로 묶어서 사용
pred = model.predict([input_1, input_2])
난 성미다.