
2024.11.08
1. 지난번의 앙상블 기법와 연결되는 내용
2. kNN : k Nearest Neighber 기법
앙상블 기법
- 앙상블은 전통적으로
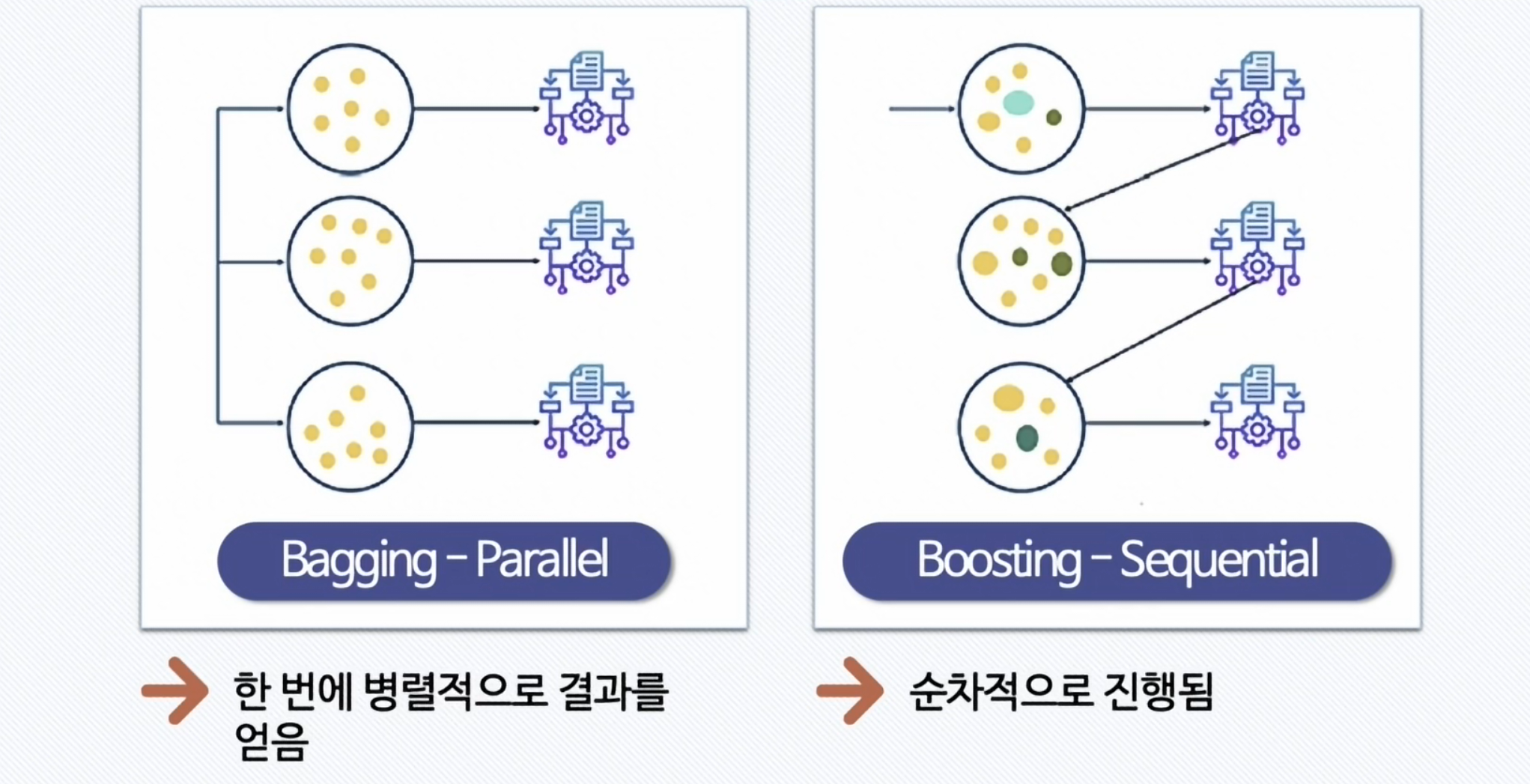
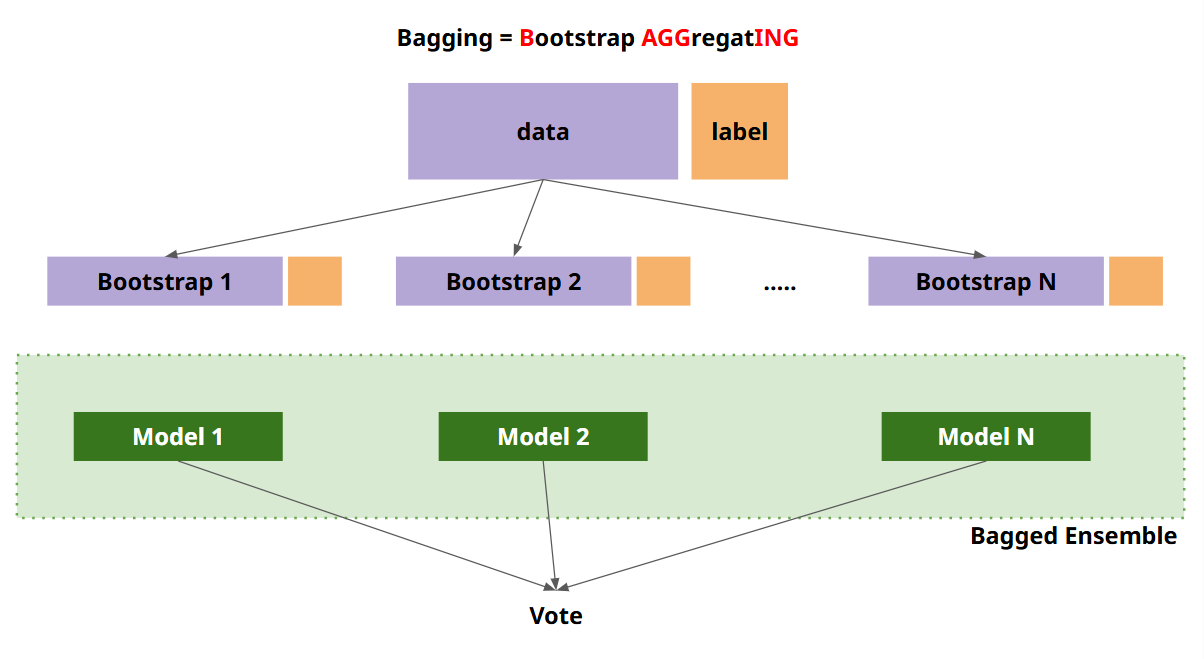
Voting,Bagging,Boosting, 스태깅 등으로 나눔 Voting과Bagging은 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식Voting과Bagging의 차이점은Voting은 각각 다른 분류기,Bagging은 같은 분류기를 사용- 대표적인
Bagging방식이Random Forest
Boosting
Boosting 개요
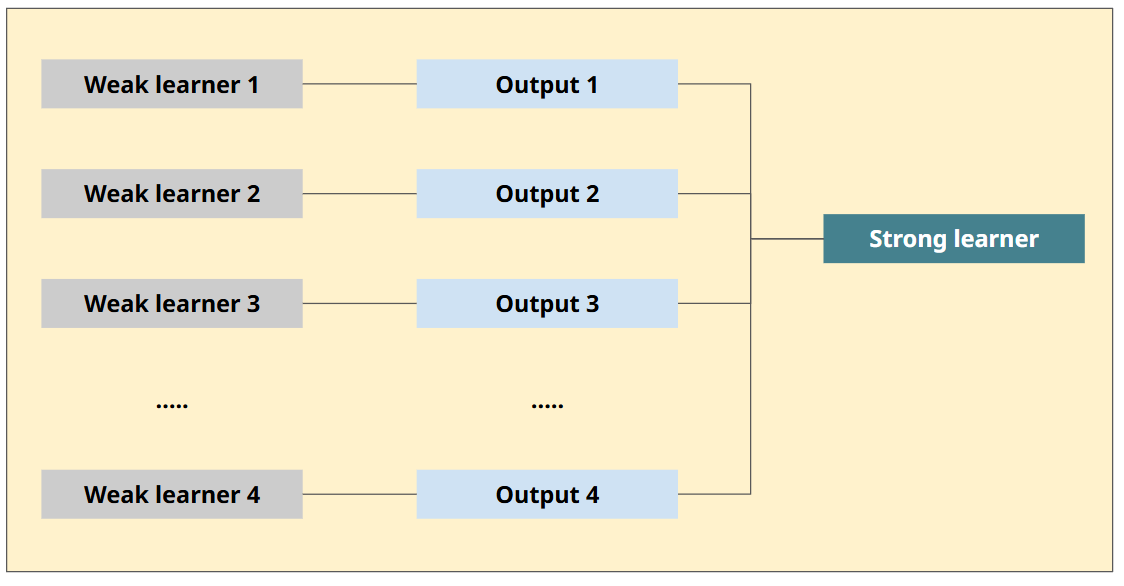
- 여러 개의 (약한) 분류기가 순차적으로 학습을 하면서, 앞에서 학습한 분류기가 예측이 틀린 데이터에 대해 다음 분류기가 가중치를 인가해서 학습을 이어 진행하는 방식
- 예측 성능이 뛰어나서 앙상블 학습을 주도하고 있음
→ 그래디언부스트, XGBoost(eXtra Gradient Boost), LightGBM(Light Gradient Boost) 등이 있음
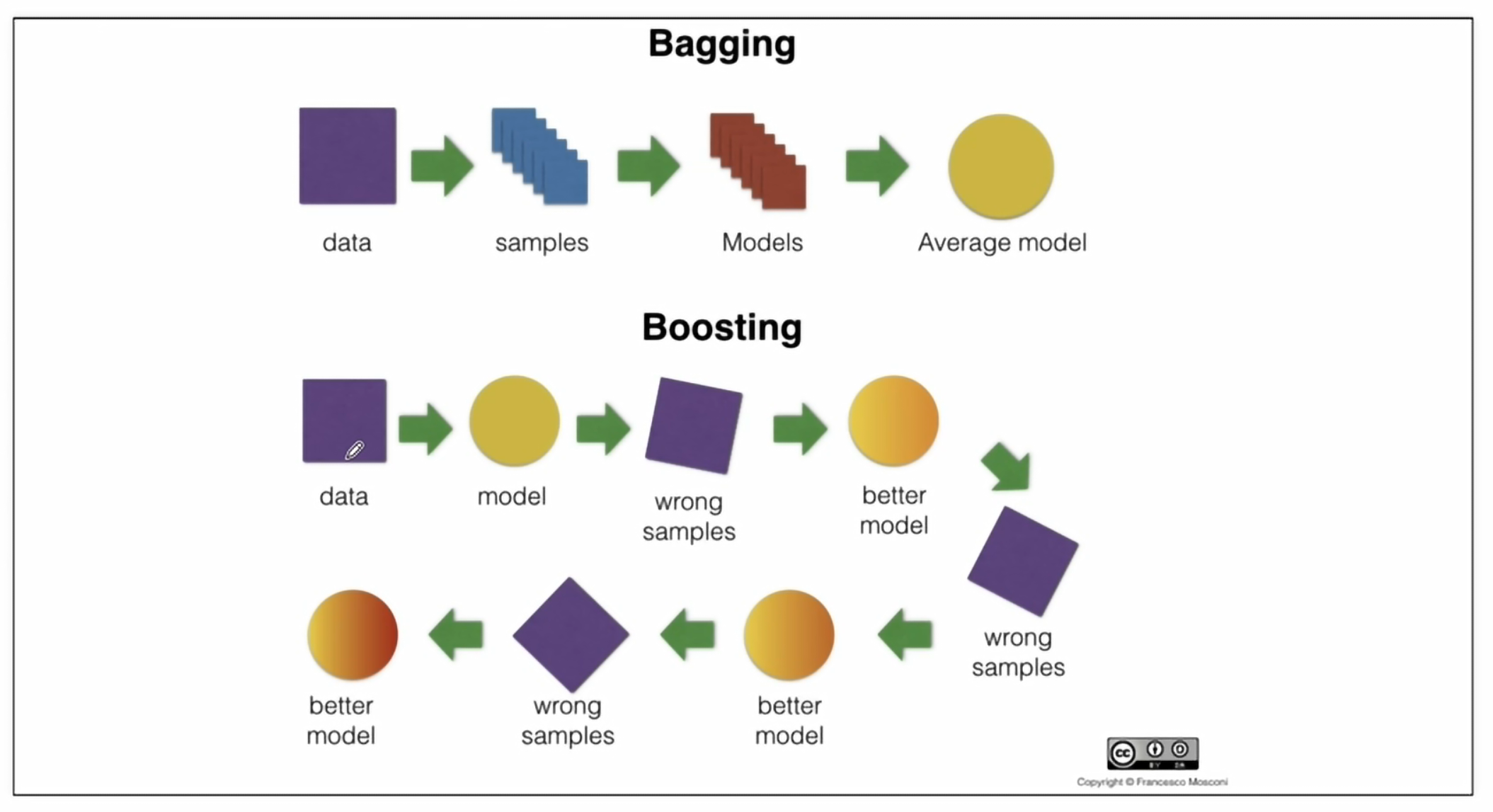
Bagging과 Boosting 차이
Boosting 기법
GBM(Gradient Boosting Machine) :AdaBoost기법과 비슷하지만, 가중치를 업데이트할 때, 경사하강법 (Gradient Descent)을 사용XGBoost(eXtra Gradient Boost) :GBM에서 PC의 파워를 효율적으로 사용하기 위한 다양한 기법에 채택되어 빠른 속도와 효율을 가짐. GPU 사용가능하도록 설정LightGBM:XGBoost보다 빠른 속도를 가짐
Boosting 실습 (wine data)
데이터 읽어오기
- 데이터 불러오기.
Github참조

StandardScaler진행 및train_test_split진행

- 컬럼별 히스토그램 확인
- 잘 분포되어 있는 컬럼이 좋을때가 많다 (pH 같은 컬럼)
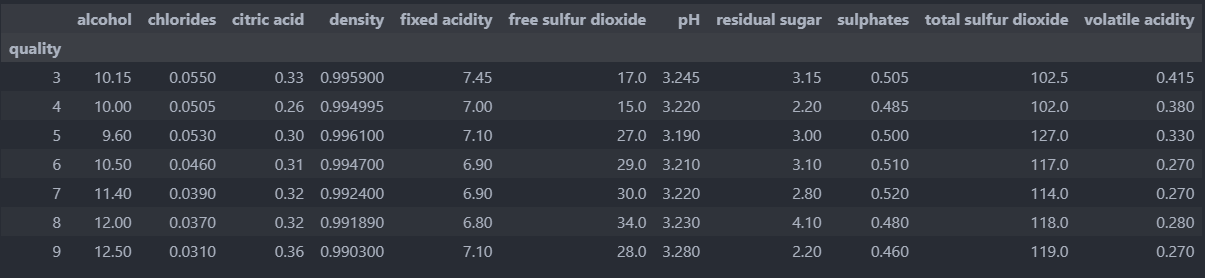
quality가 높아질수록,alcohol과dioxide값이 일부 높아지는 것
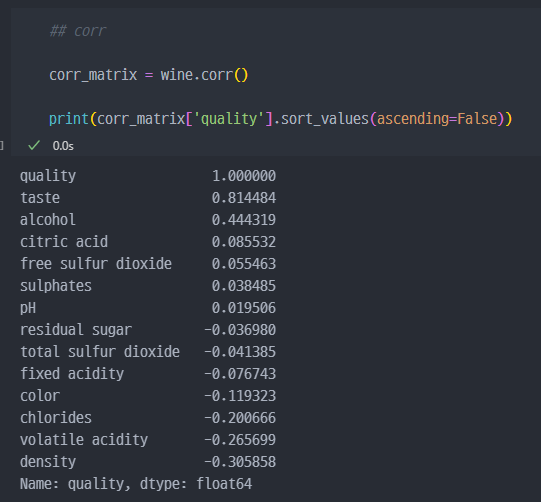
taste를 제외하면 가장 영향이 있는건alcohol로 보인다.
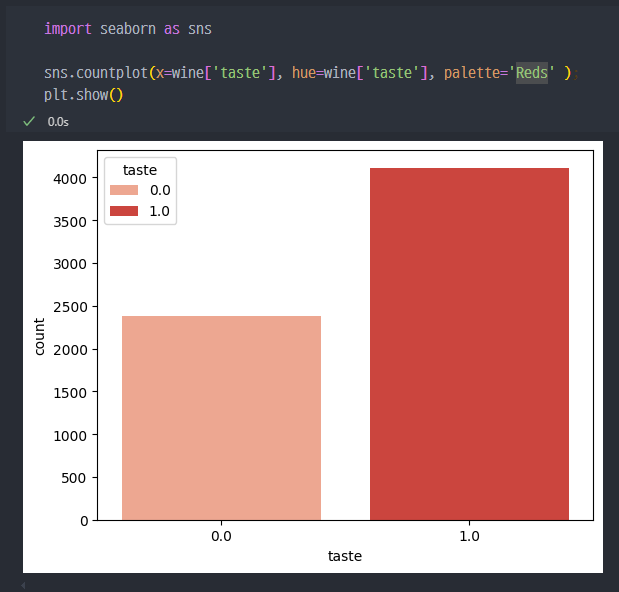
taste컬럼에서 0과 1의 개수
다양한 모델을 한번에 테스트
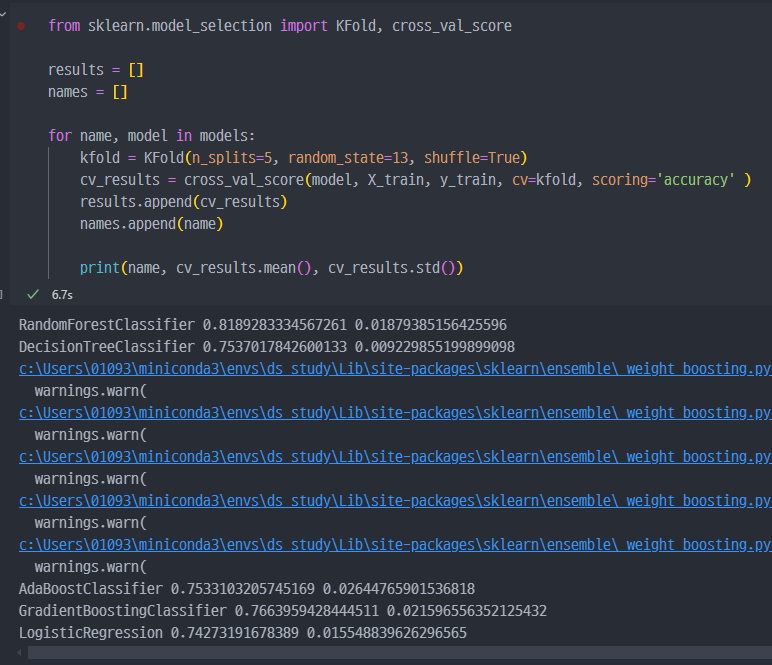
그래프로 결과 확인하기
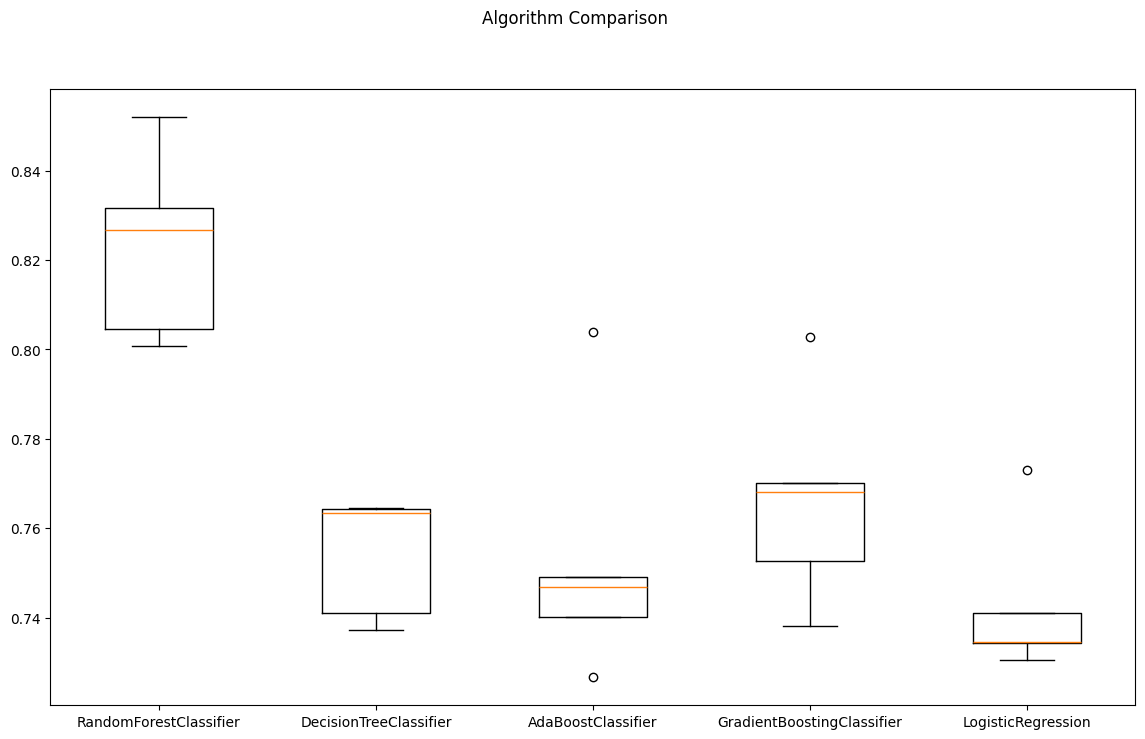
- boxplot의 형태로 비교하여 확인하기
- 사실 결과는 데이터의 형태, 양상마다 다를 수 있다. 현재의
wine data에서는Random Forest가 가장 좋은것처럼 보인다.
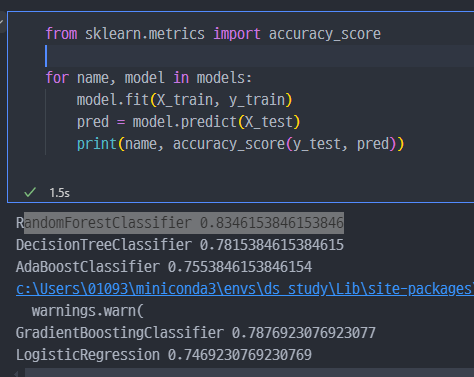
train데이터로 학습하고,test데이터로 예측하였을 때 성능도Random Forest가 가장 좋아보인다.
kNN : k Nearest Neighber
kNN이란
- 새로운 데이터가 있을 때, 기존 데이터의 그룹 중 어떤 그롭에 속하는지
분류하는 문제 - k는 몇 번째 가까운 데이터까지 볼 것인가를 정하는 수치
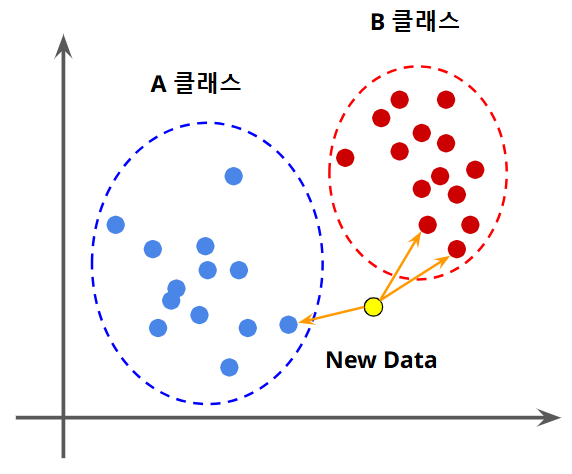
- 위 그림처럼, A 클래스와 B 클래스로 기존의 데이터가 분류되어 있을때,
New Data가 각 클래스에 속해있는 가장 가까운 (이웃하는) 데이터를 찾아 거리순으로 정렬하여 가장 가까운 데이터에 속한 클래스를 찾는 방법- 즉 데이터의 분류, 지도학습의 한 방법이다.
- parameter K 를 3으로 설정하면, 가까운 순으로 3개를 찾아서 그 중 다수결로 투표하여 분류한다.
- k 값에 따라서 결과가 바뀌는 경우가 많다.
- 단위에 따라, x, y축의 Range에 따라 값이 변경될 수 있으므로, 표준화가 필요하다.
ChatGPT선생의 정리
k-최근접 이웃(k-Nearest Neighbors, kNN)은지도 학습(supervised learning)의 한 방법으로, 데이터의 분류와 회귀에 사용되는 간단하고 직관적인 알고리즘입니다. 주요 개념과 작동 방식을 아래에 설명하겠습니다.
1. 기본 개념
- kNN은 새로운 데이터 포인트가 주어졌을 때, 해당 포인트와 가장 가까운 'k'개의 이웃을 찾아 그 이웃들의 정보를 바탕으로 예측을 수행하는 알고리즘입니다. 즉, 데이터 포인트의 클래스나 값을 결정하기 위해 주변 데이터(이웃)과의 거리를 측정해 결과를 예측합니다.
k: 가장 가까운 이웃의 개수를 의미합니다. 일반적으로 홀수 값을 사용해 동률을 피합니다.최근접: 데이터 포인트들 간의 거리를 계산하여 가까운 순으로 정렬합니다. 거리 계산은 보통 유클리드 거리(Euclidean distance)를 사용하지만, 맨해튼 거리(Manhattan distance)나 코사인 유사도(cosine similarity) 등 다른 거리 척도도 활용할 수 있습니다.
2. 작동 방식
데이터 준비: 알고리즘은 이미 분류 또는 레이블이 지정된 데이터 세트를 가지고 있어야 합니다.거리 계산: 예측하려는 새로운 데이터 포인트와 각 데이터 포인트 간의 거리를 계산합니다.가장 가까운 이웃 선택: 계산된 거리 중 가장 가까운 'k'개의 이웃을 선택합니다.예측:
분류 문제의 경우, 'k'개의 이웃 중 가장 많이 나타나는 클래스를 선택하여 새로운 데이터의 클래스를 예측합니다.
회귀 문제의 경우, 'k'개의 이웃의 평균 값을 계산해 새로운 데이터의 예측 값을 결정합니다.
결과 도출: 예측 결과를 출력합니다.
3. 장점
단순하고 직관적: 이해하기 쉽고 구현하기도 간단합니다.비선형 데이터 처리: 복잡한 데이터 구조도 비선형적으로 처리할 수 있습니다.
4. 단점
계산 비용: 새로운 데이터 포인트를 예측할 때, 모든 데이터 포인트와의 거리를 계산해야 하기 때문에 데이터가 많을 경우 시간이 많이 걸립니다.메모리 사용: 전체 데이터 세트를 저장해야 하므로 메모리 사용량이 큽니다.특성 스케일링: 거리 기반 알고리즘이기 때문에 특성의 스케일에 민감합니다. 따라서 표준화나 정규화 전처리가 필요합니다.
5. 하이퍼파라미터 튜닝
k 값 선택: 적절한k값을 선택하는 것이 중요합니다. 너무 작은 값은 모델이 과적합(overfitting)될 수 있고, 너무 큰 값은 과소적합(underfitting)될 위험이 있습니다.거리 척도: 데이터의 특성과 문제에 맞는 거리 척도를 선택하는 것도 성능에 큰 영향을 미칩니다.
6. 예시
- 만약
k=3이고, 새로운 데이터 포인트가클래스 A의이웃 2개와클래스 B의이웃 1개와 가까운 위치에 있다면, 이 데이터 포인트는클래스 A로 분류됩니다. - 이처럼 kNN은 주변 데이터의 정보를 토대로 새로운 데이터의 결과를 추론하는 매우 직관적인 알고리즘입니다.
kNN 실습 (iris data)
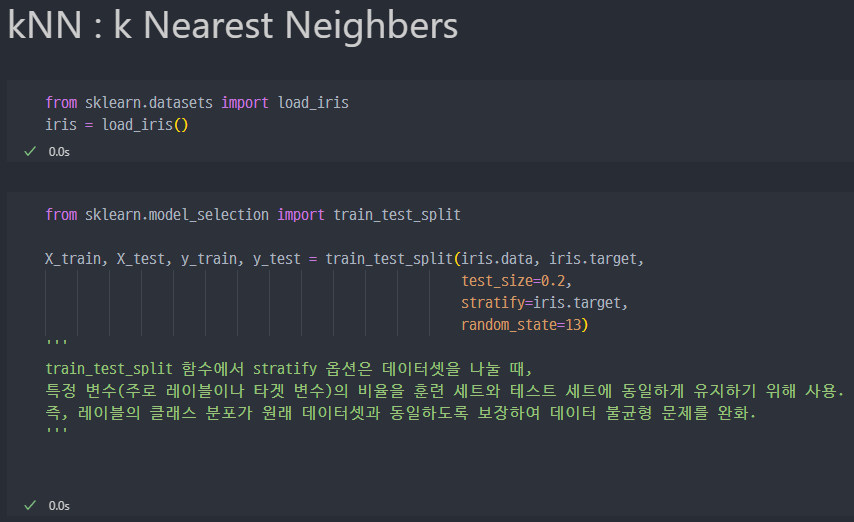
- kNN 분류모델에 대한 설정진행
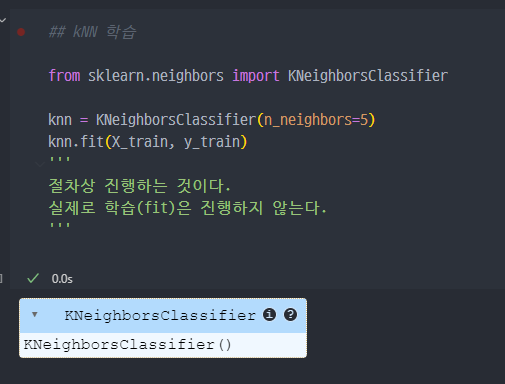
- 실제로는
fit( )을 진행하지는 않는다.
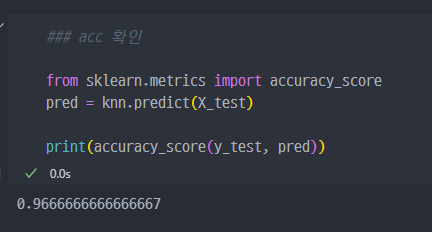
accuracy_score를 확인해보면, 실제로 성능이 좋은것은 확인할 수 있다.
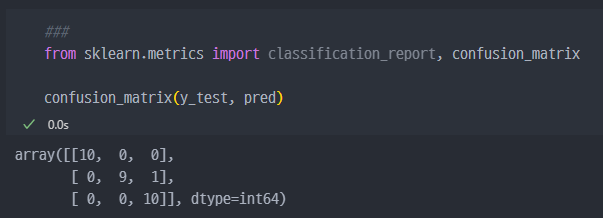

setosa는 10개 중에 10개를 바르게 예측versicolor는 10개 중에 9개를 바르게 예측했고, 1개를 잘못 예측함.virginica는 10개중에 10개를 바르게 예측

(hellow. world)