
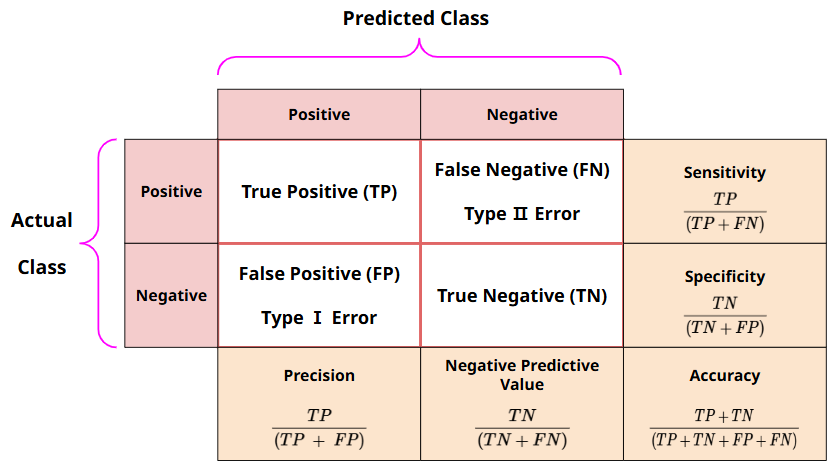
정밀도(Precision)와 재현율(Recall)
앙상블 기법
2024.11.01
※ 개념정리
-
Accuracy(정확도) : 전체 데이터 중 맞게 예측한 것의 비율
- 전체 데이터 中 1을 1로, 0을 0으로 예측한 것 →
-
Precision(정밀도) : 양성이라고 예측한 것 중에서 실제 양성(1로 예측한 것 중 1인 비율)의 비율
- 1이라고 예측한 것 中 실제 1인 것 →
-
Recall(재현율) : 실제 참인 데이터 중에서 참이라고 예측한 것
- 실제 1인 값 中 1이라고 예측한 비율 →
-
Fall-Out : 실제 양성이 아닌데, 양성이라고 잘못 예측한 경우
- 실제 1이 아닌데, 0인데 이를 1로 잘못 예측한 비율→
- Threshold (임계값) : "어떤 값 이상이면 '1'(참)로 분류하고, 그 이하면 '0'(거짓)로 분류하겠다"라고 설정하는 기준이 바로 Threshold 이다.
정밀도와 재현율의 트레이드오프
Wine Data Logistic Regression
- 이전 과정과 모두 동일하게
logistic regression을 통한예측모델생성 (wine data사용)
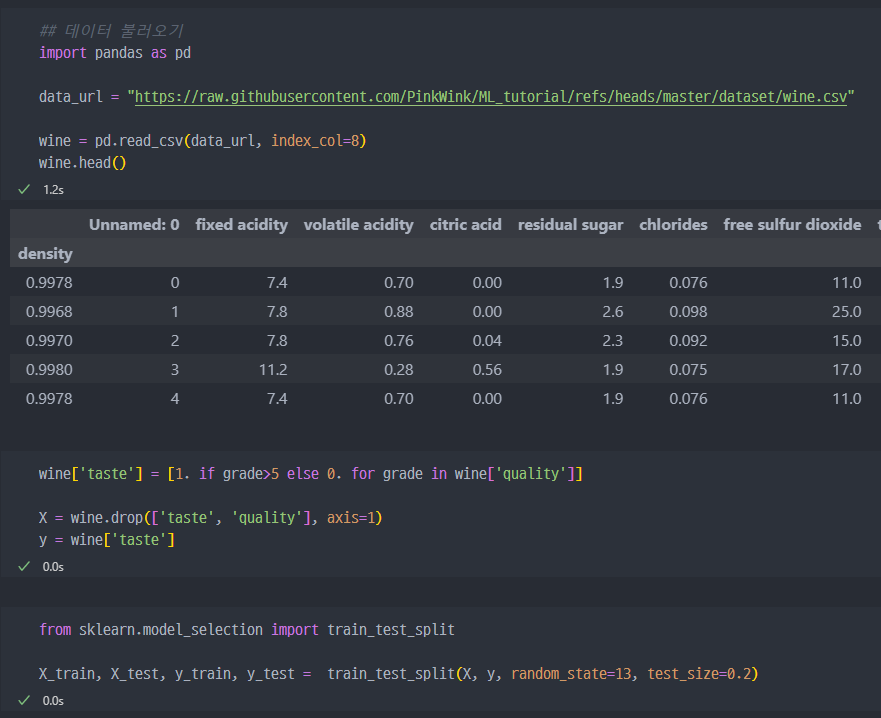

wine data에 대하여,train,test데이터 분리 및logistic regression을 통한 예측모델 학습 진행
Classification report
-
Classification_report: 분류 모델의 성능을 요약하여 평가하는 데 사용 -
Precision (정밀도): 모델이 예측한 양성 클래스 중 실제로 양성인 비율입니다. 양성 클래스 예측의 정확도를 의미하며, 낮으면 False Positive가 많다는 뜻입니다.
-
Recall (재현율): 실제 양성 샘플 중에서 모델이 양성으로 올바르게 예측한 비율입니다. 실제 양성 샘플을 놓치지 않는 능력을 의미하며, 낮으면 False Negative가 많다는 뜻입니다.
-
F1-score: Precision과 Recall의 조화 평균으로, 두 지표의 균형을 측정합니다. F1-score가 높을수록 성능이 좋은 모델로 평가합니다.
-
Support: 각 클래스의 샘플 수를 나타내며, 모델이 각 클래스에 대해 얼마나 잘 예측했는지를 평가하는 데 참고됩니다.
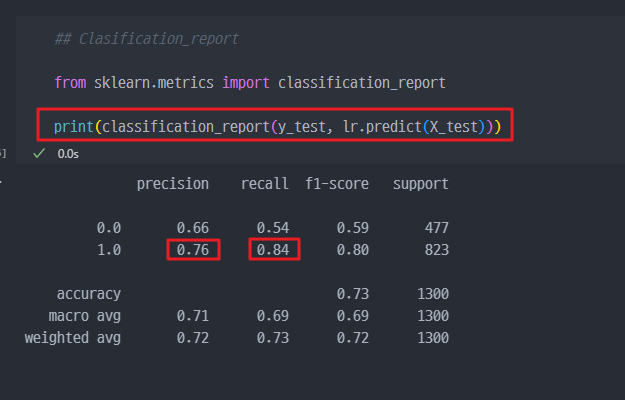
Precision(정밀도): 1이라고 예측한 것 중 실제 1인 것 → 76%Recall(재현율): 실제 1인 데이터 중 1이라고 예측한 것 → 84%Support: 전체 데이터의 수macro avg: 각 클래스 (precision, recall...) 의 평균값
- Precision에서 보면, ( 0.66 + 0.76 ) / 2 = 0.71
weighted avg: 클래스별 데이터 개수의 비중을 반영한 평균
- Precision에서 보면, 0.66 x ( 477/1300 ) + 0.76 x ( 823/1300 ) = 0.72
Confusion Matrix
Confusion matrix: 분류 모델의 성능을 평가하기 위해 실제 클래스와 예측한 클래스를 비교하여, 분류 결과를 표 형태로 요약한 것. 이 행렬은 모델이 얼마나 잘 분류했는지, 어떤 유형의 오류가 발생했는지를 직관적으로 보여줍니다.
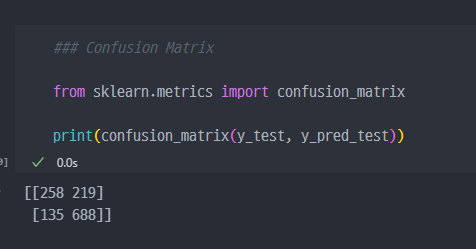

[[258 219]→ 전체0중에서258개를0이라 예측하고,219개를1이라 예측
[135 688]]→ 전체1중에서135개를0이라 예측하고,688개를1이라 예측
Precision_recall Curve
-
Precision_recall Curve: 이 그래프는 모델이양성 클래스(positive class)를 얼마나 잘 식별하는지에 대한 정보를 제공Precision (정밀도): 양성 클래스로 예측한 사례 중에서 실제로 양성인 비율입니다. False Positive가 적을수록 높아집니다.Recall (재현율): 실제 양성 클래스 중에서 모델이 올바르게 예측한 비율입니다. False Negative가 적을수록 높아집니다.



threshold 값의 변화
- threshold 값에 따른 변화
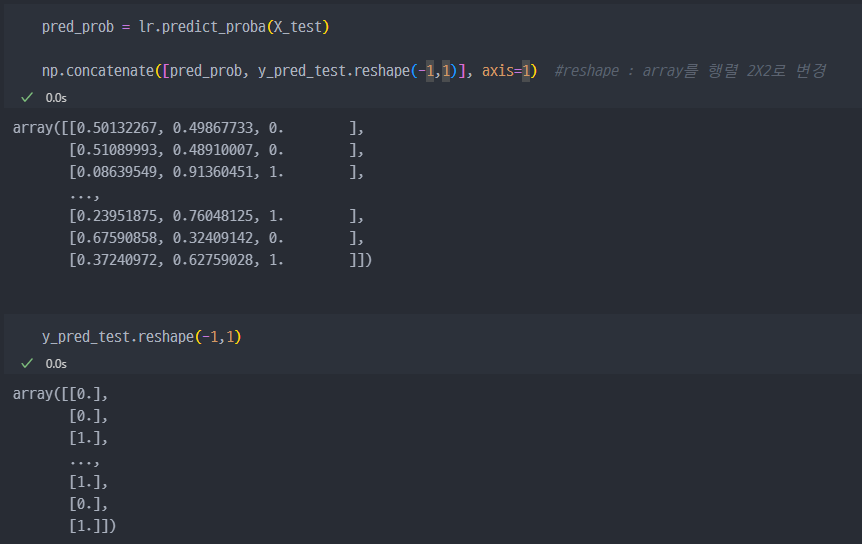
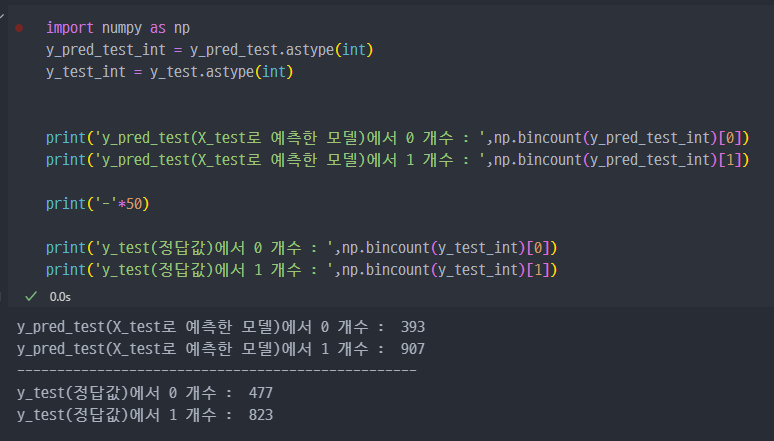
X_test 데이터를 이용해서, 예측모델을 생성하고, 0과 1일 확률을 반환하는 함수를 걸어서 (redict_proba) 변수 pred_prob에 저장한다.
y_pred_test ( lr.predict(X_test) 즉, X_test 데이터를 예측모델에 넣어서 반환된 예측정답값 ) 값을 reshape을 통해서 concat 진행

위 그래프와 마찬가지로 ,
precision은 올라가고,recall은 떨어졌다. (1에 대한 확률에서)
앙상블 기법
앙상블 학습을 통한 분류: 여러 개의 분류기를 생성하고, 그 예측을 결합하여 정확한 최종 예측을 기대하는 기법앙상블 학습의 목표: 다양한 분류기의 예측 결과를 결합함으로써, 단일 분류기보다 신뢰성이 높은 예측값을 얻는 것
" 현재 정형데이터를 대상으로 하는 분류기에서는 앙상블 기법이 뛰어난 성과를 보여주고 있음 "
앙상블 기법中Voting기법 : 전체Data Set에서 각각 다른 알고리즘 예측 진행
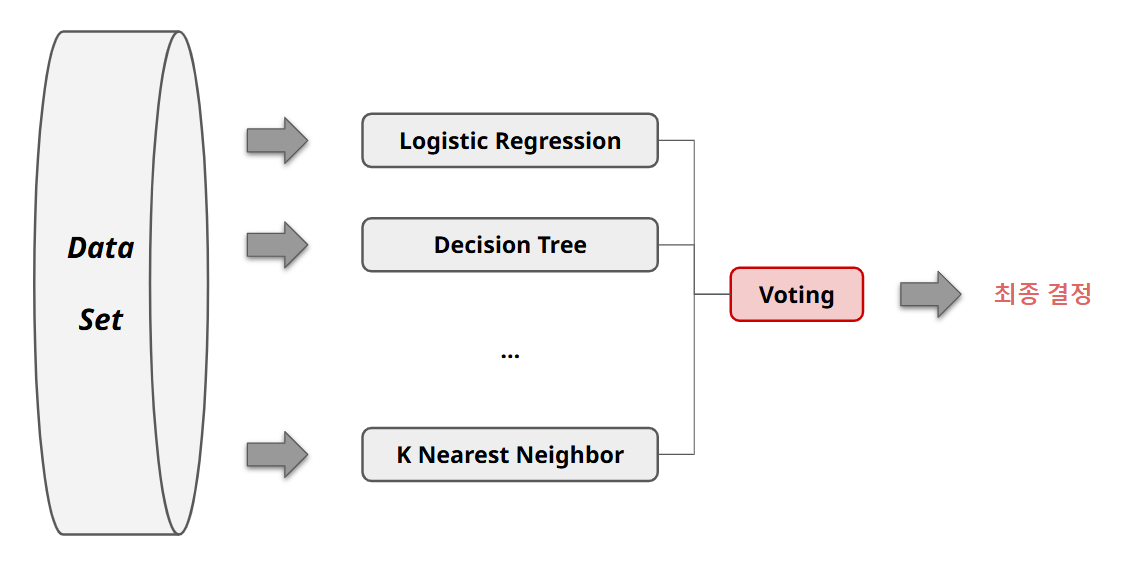
- Voting 기법으로, 즉 최종 결정 기법으로
소프트 보팅과하드보팅이 있음
Soft Voting: 여러 결과값에서 확률의 평균을 비교하여 선택Hard Voting: 여러 결과값 중 다수결로 선택
앙상블 기법中bagging기법 : 전체Data Set에서 랜덤하게Sampling하여 각각의 예측모델에 다른 데이터를 주입

bagging의 경우 데이터 중복을 허용해서 샘플링하고, 그 각각의 데이터에 같은 알고리즘을 적용해서 결과를 투표로 결정함- 각각의 분류기에 데이터를 각각 샘플링해서 추출하는 방식을 부트스트래핑(bootstrapping) 분할방식 이라고 함.
Random Forest:bagging기법의 대표적인 방법
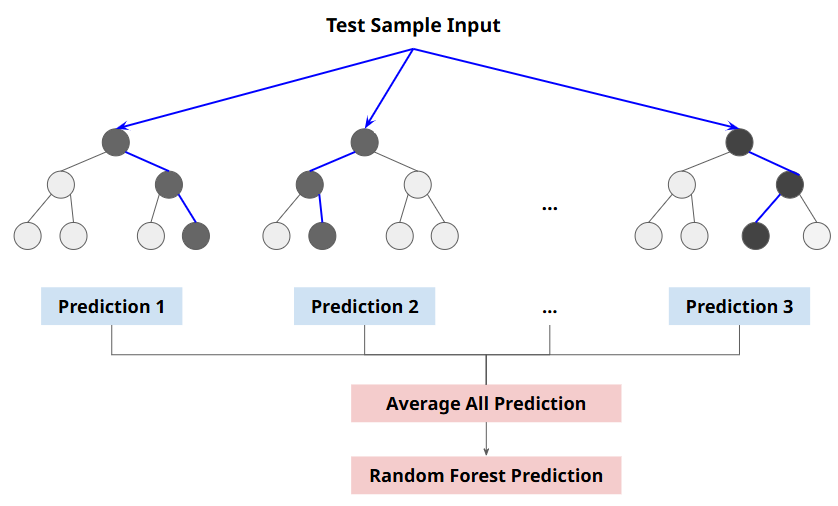
- 양상블 방법중에서 비교적 속도가 빠르며, 다양한 영역에서 높은 성능을 보여줌
부트스트래핑은 여러 개의 작은 데이터 셋을 중헙을 허용해서 만드는 것
- 랜덤 포레스트는 결정나무(Decision Tree)를 기본으로 함
부트스크래핑으로 샘플링 된 데이터마다결정나무가 예측한 결과를소프트보팅으로 최종 예측 결론을 얻음
HAR, Human Activity Recognitio (앙상블기법 예제)
ML을 이용한 행동인식연구 관련
데이터 소개
1) UCI HAR 데이터셋은 스마트폰을 장착한 사람의 행동을 관찰한 데이터임
- 실험대상 : 19 ~ 48세 연령의 30명 자원봉사자 모집
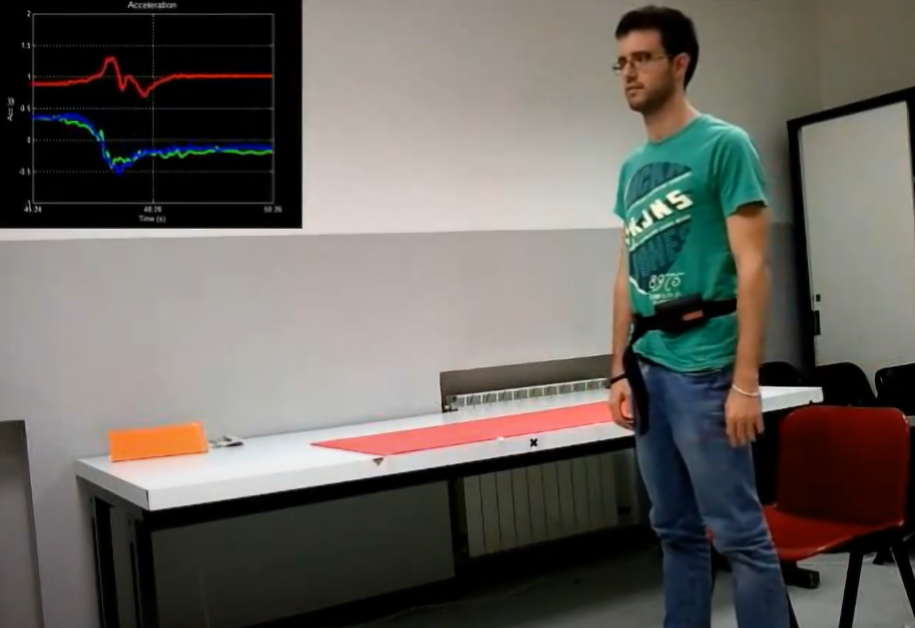
2) 허리에 스마트 폰 (Samsung Galaxy S Ⅱ)을 착용하여 50Hz 주파수로 데이터를 얻음
- 6가지 활동 수행
- Walking
- Walking_upstairs
- Walking_Downstairs
- Sitting
- Standing
- Laying
- 내장 된
가속도계와자이로스코프를 사용하여 50Hz의 일정한 속도로 3축 선형가속 및 3축 각속도 캡쳐
3) 실험은 데이터를 수동으로 라벨링하기 위해 비디오로 기록
- 획득한 데이터 세트는 무작위로 두 세트로 분할
- 훈련 데이터 생성을 위해 자원 봉사자의 70%가 선택되었고, 테스트 데이터는 30% 선정
4) 중력 및 신체 운동 성분을 갖는 센서 가속 신호는 버터 워스 저역 통과 필터를 사용하여 신체 가속 및 중력 으로 분리
- 중력은 저주파 성분만을 갖는 것으로 가정하고 0.3Hz 차단 주파수를 가진 필터가 사용
5) 데이터 특성
- 가속도계로부터의 3축 가속도 (총 가속도) 및 추정된 신체 가속도
- 자이로스코프의 3축 각속도
- 시간 및 주파수 영역 변수가 포함된 561 기능 벡터
- 활동 라벨
- 실험을 수행한 대상의 식별자
6) 데이터 클래스
- Walking
- Walking_upstairs
- Walking_Downstairs
- Sitting
- Standing
- Laying
7) 데이터 수집
1. 데이터 불러오기
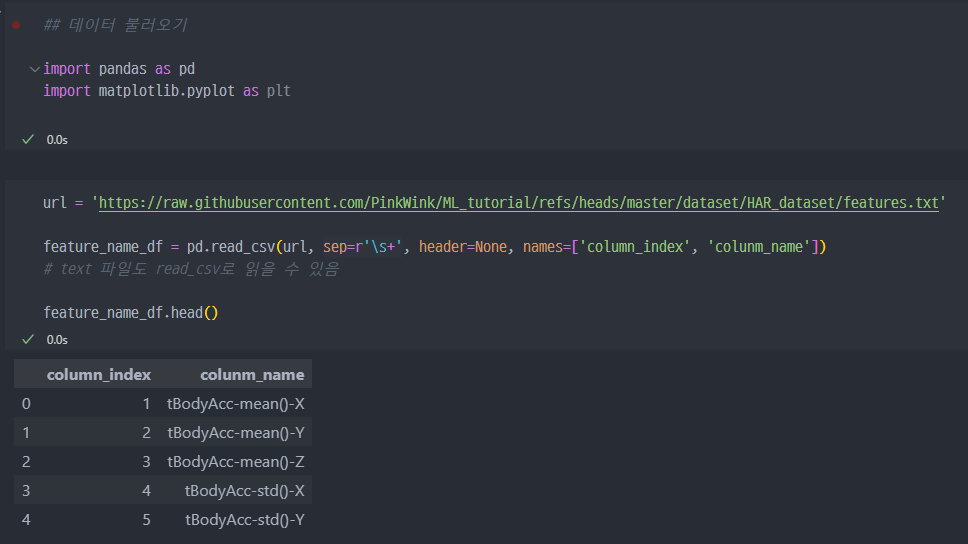
txt 파일도
pd.read_csv로 읽을 수 있음.
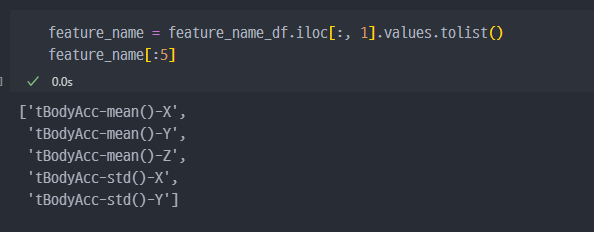
feature_name 데이터 생성 → 추후
train,test데이터셋의column name으로 사용

X_train,X_test데이터 불러오기 및column name설정
y_train,y_test데이터 불러오기 및shape확인. 컬럼 이름 설정
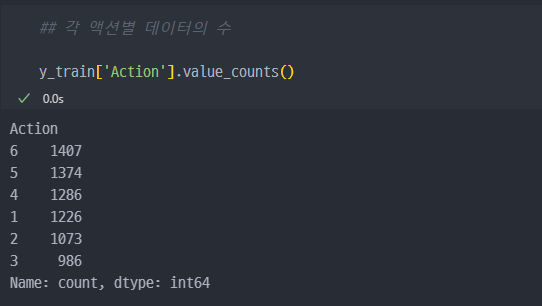
각 액션별 데이터의 수 확인
2. Decision Tree 진행
Decision Tree이용하여fit( )진행 (train data)
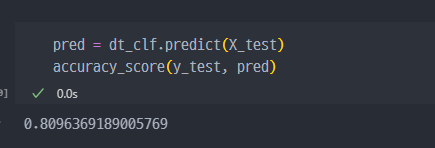
acc_score는 80% 정도로 나쁘지 않은 편
max_depth를 4로 설정하고fit( )진행했는데, 좀 다양하게 하기 위해서GridSearchCV이용


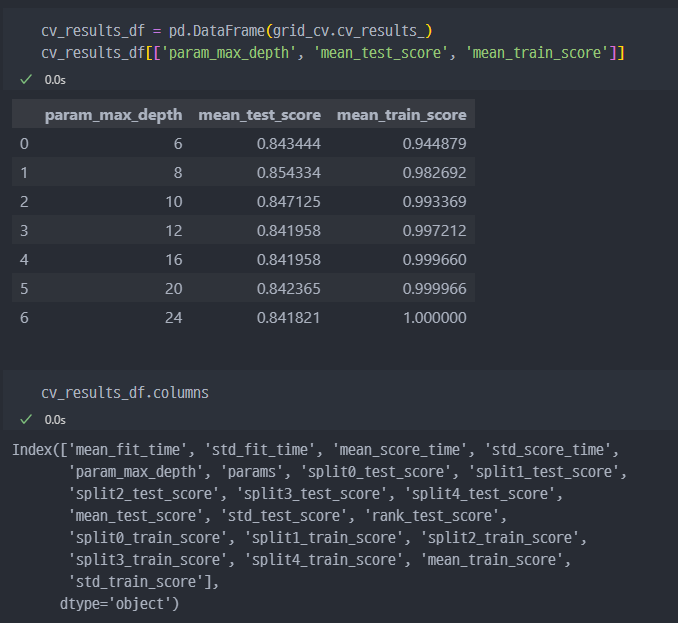
GridSearchCV이용 시max_depth가 8인 경우best
3. test 데이터에서 acc 확인
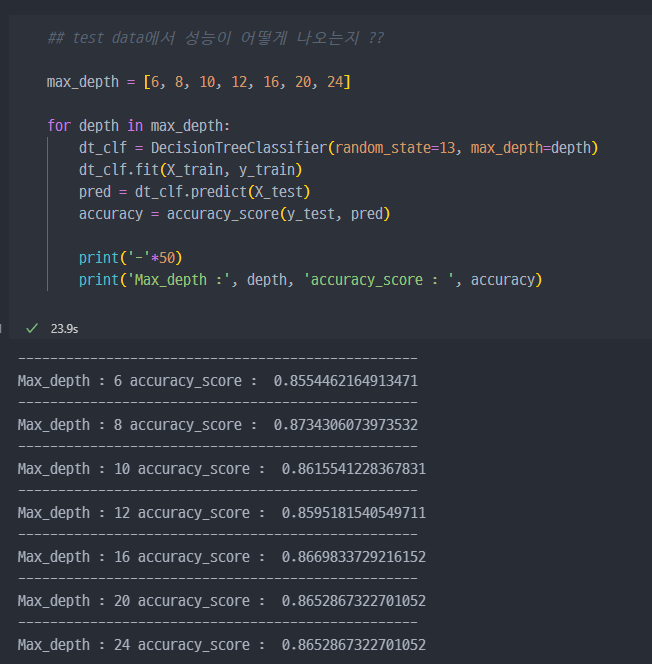
X_test데이터로 모델fit( )이후acc확인 진행.X_test데이터로 진행해도Max_depth가 8이 가장 좋아보인다.
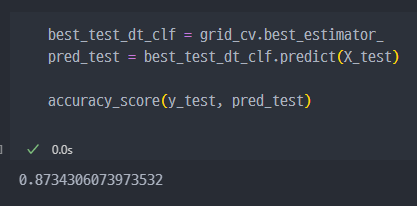
반복문 없이, 앞에서 생성했던
grid_cv이용해서 바로best_accuracy_score구하기
4. Random Forest 적용
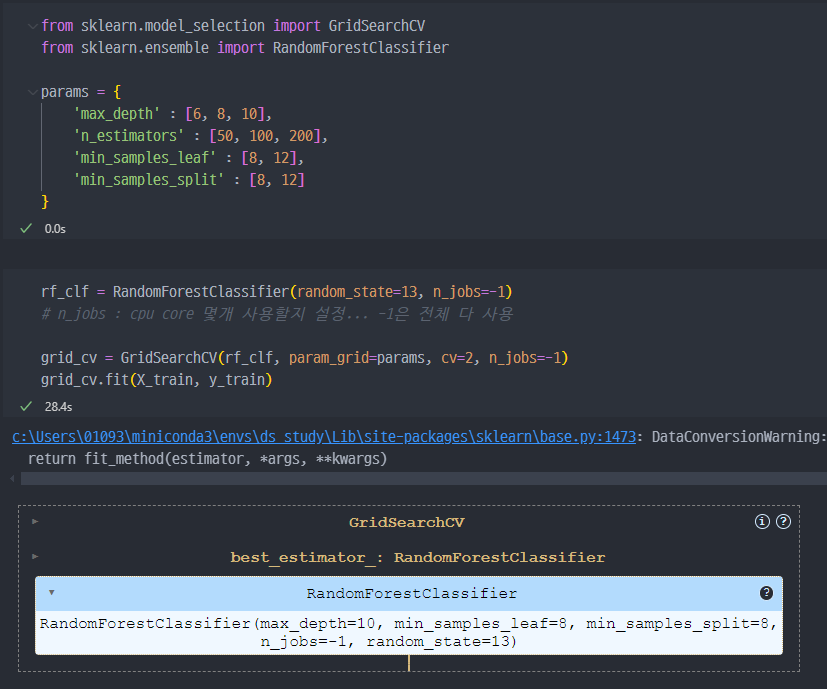

- cpu 사용설정이 가능해서 인지 모르겠지만, 일단 GridSearchCV보다 2배이상 빠르다.
- 성능은 좋은편 (91.5%)

train데이터가 아닌test데이터로 진행해봐도 92%로 정확도가 상당히 높은편이다.Decision Tree에 비해서 상당히 좋다
5. 중요특성 확인
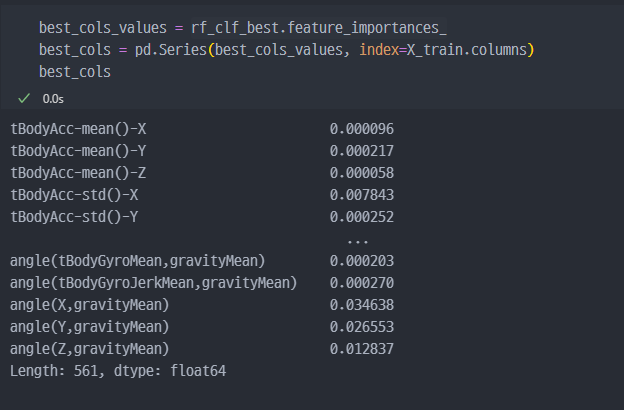
- 각 특성별 중요도 표시
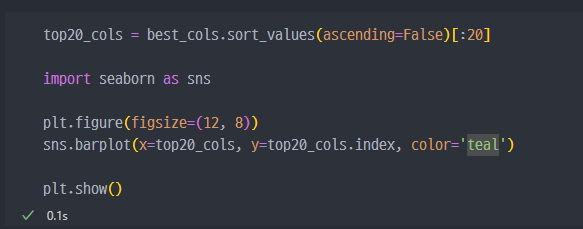
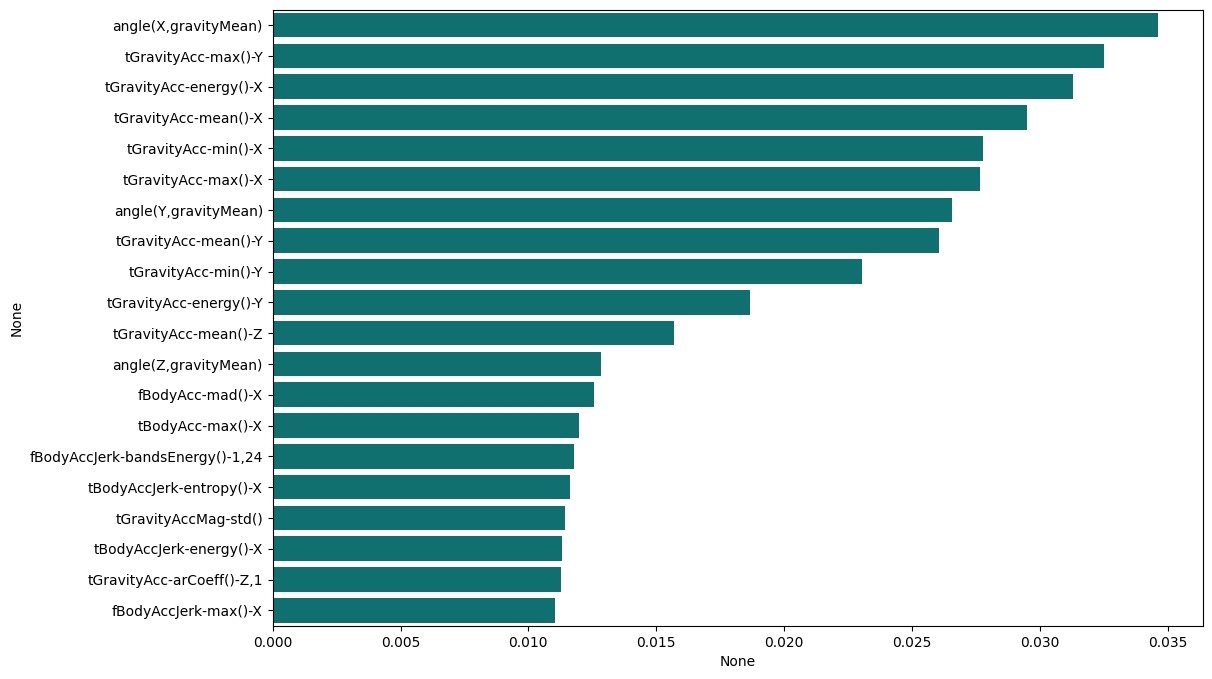
- 각 특성(
feature)에 대한 중요도를 그래프로 확인하고 사용할 특성(feature)를 선정한다.- 결국 해당 데이터의
feature는 561개로 상당히 많은데, 이를 모두 계산하는 것은 비효율적. 그래서feature중에서 중요한 것만 선정하여 진행하는 방향도 많이 선택한다.
- 이는 계산속도를 향상시키기 위한 의사결정인것으로 사료됨.
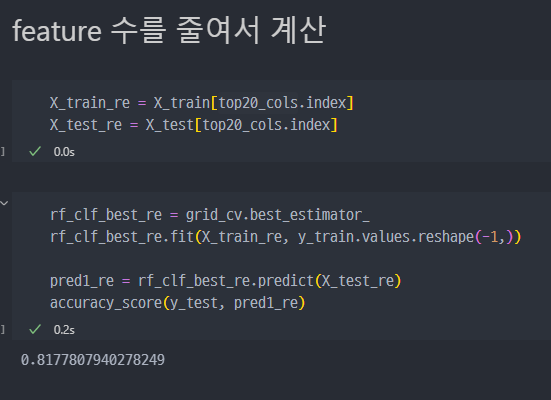
- 정확도는 조금 감소되지만 훨씬 더 빠른 속도로 연산할 수 있다.
