
2024.11.10
- Boosting 기법에서 GBM, XGBoosting, LightGBM
- GridSearchCV 정의
앙상블 기법 관련 내용
Boosting 개요 관련 내용
GBM - Gradient Boosting Machine
GBM 개요
-
Boosting Algorithm은 여러 개의약한 학습기(week learner)를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치를 부여해서 오류를 개선시키며 분류하는 방식 -
그 중에서 →
GBM은 가중치를 업데이트할 때경사 하강법(Gradient Descent) 을 이용하는 것이 큰 차이
데이터 불러오기
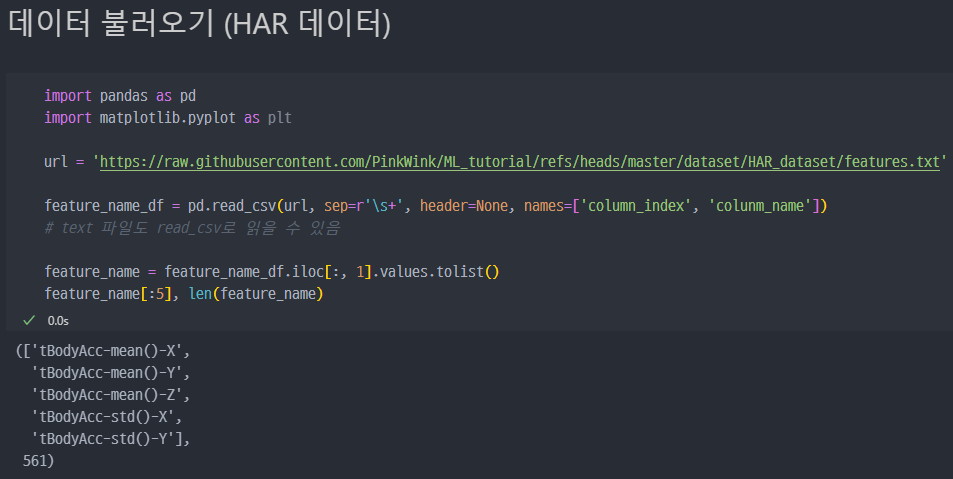
feature_name이라는 변수에 특성의 이름을 list 형태로 저장한다. 총 561개의 특성 이름(featurenames
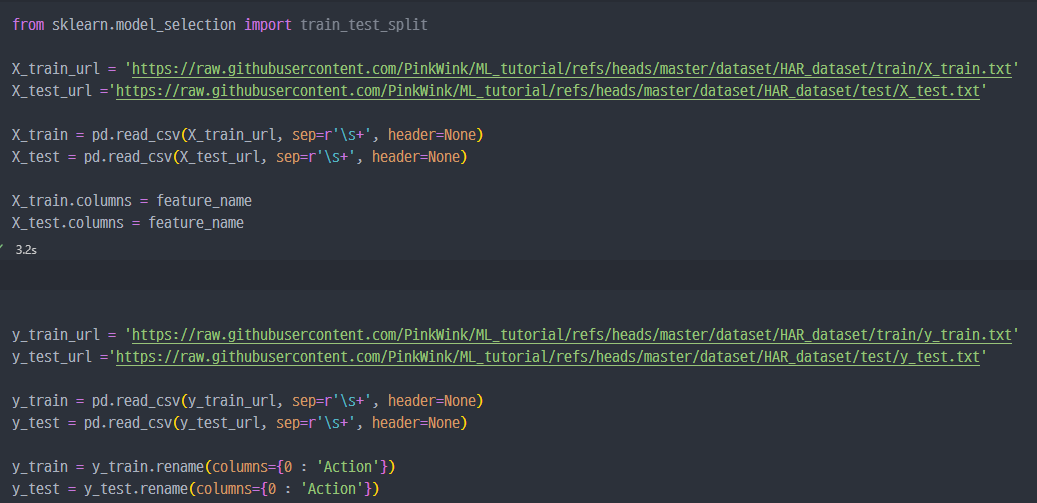
- X, y의 각각의
train및test데이터를 분류하려 저장.- X 데이터는 각 컬럼의 이름에
feature_name변수를 할당해서 저장하며, y 데이터는Action이라는 이름을 컬럼에 부여

X_train,y_train데이터 확인
GBM 진행
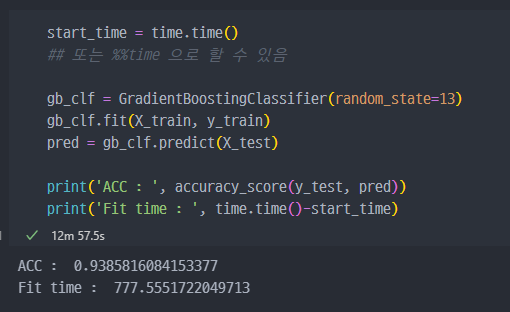
acc는 93% 정도로 성능이 우수하다.- 일반적으로
GBM이 성능자체는Random Forest보다 좋다고 알려져 있음.sckit-learn의GBM속도가 아주 느린것으로 알려져 있음.
GridSearchCV로 조금 더 진행
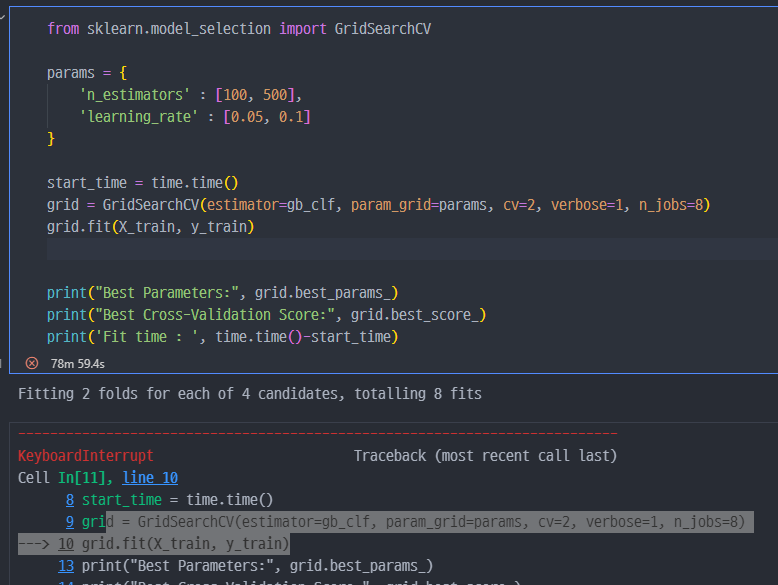
- 시간이 너무 오래걸려서, 중단함.
XGBoost
XGBoost 개요
XGBoost는 트리 기반 앙상블 학습에서 가장 각광받는 알고리즘 중 하나GBM기반의 알고리즘인데,GBM의 느린 속도를 다양한 규제를 통해서 해결함.- 특히 병렬 학습이 가능하도록 설계됨.
XGBoost는 반복 수행시마다, 내부적으로 학습데이터와 검증데이터를 교차검증 수행- 교차검증을 통해 최적화되면,반복을 중단하는 조기 중단 기능을 가지고 있음
conda가상환경에서Package설치
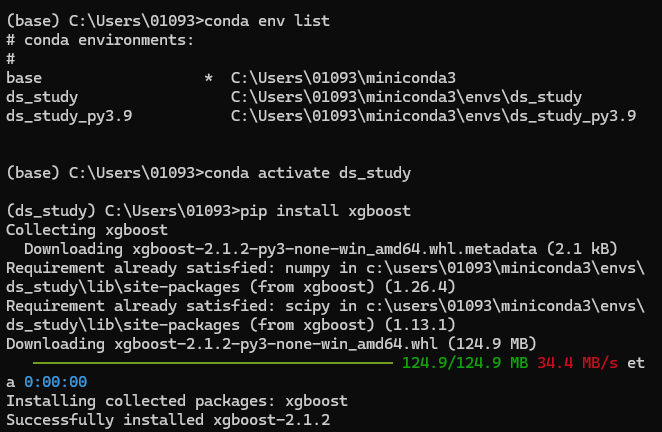
- 주요
Parameternthread: CPU의 실행 스레드 개수 조정, 디폴트는 CPU 전체 스레드를 사용하는 것eta: GBM 학습률num_boost_rounds: n_estimators와 같은 파라미터max_depth
XGBoost 실행
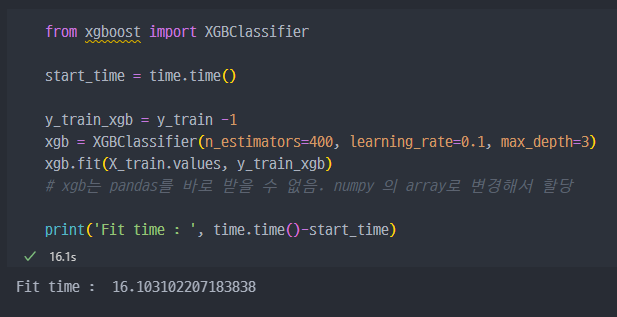
- GBM 대비 다소 빠르게 실행되었다. GBM은 50분 정도 기다리다가 중단함.
원인
XGBClassifier는 클래스 레이블이0부터 시작하는 연속된 정수로 구성되어 있어야 합니다. 그러나y_train에 클래스 레이블이1부터 시작해서 문제가 발생한 것입니다.
해결 방법
클래스 레이블을0부터 시작하도록 조정해야 합니다. 이를 위해y_train과y_test에 있는 클래스 레이블에서1을 빼는 방법이 있습니다.
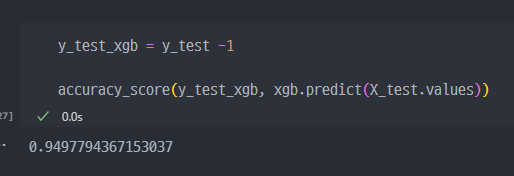
- XGBoost 성능 확인 ( 약 94% )
XGBoost 조기종료 설정
- 일단
xgboost에서early_stoppint_rounds함수가 작동되지 않아서, 현재conda에 install 되어있는2.1 ver의 최신버전xgboost를 제거하고1.5.0 verxgboost설치 및 실행예정
xgboost1.5.0 ver 에서 진행

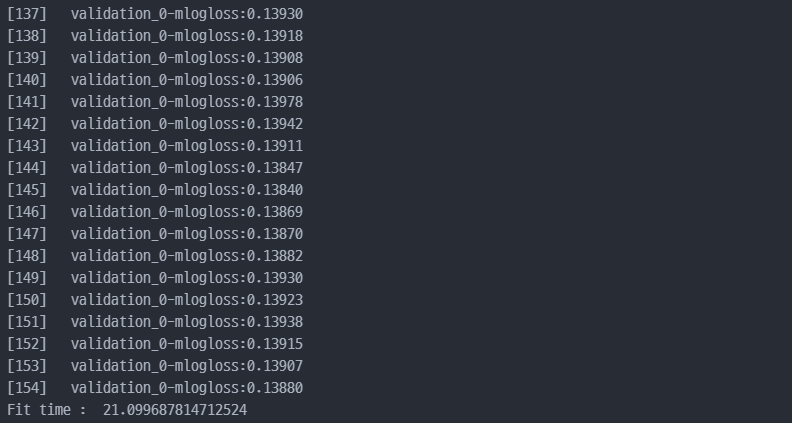
- 약 21초만에 멈춘것을 확인할 수 있다.
GBM으로 진행 시 777초 정도 나온것 대비하여 , XGBoost가 훨씬 더 빠르게 진행된 것을 알 수 있다.
- 조기종료 옵션(
early_stopping_rounds) 미선택 시, 33초, 선택 시 약 21초가 나왔다.- 지금 보면, 조기종료 옵션을 살리기 위해서
xgboost의 최신버전 (2.1 ver)이 아닌 과거버전 (1.5.0 ver)을 사용- 최신버전에서 조기종료 옵션이 불가능한 건 ...
LightGBM
LightGBM 개요
LightGBM은XGBoost와 함께 부스팅 계열에서 가장 각광받는 알고리즘LGBM의 큰 장점은 역시 속도- 단, 적은 수의 데이터에는 어울리지 않음 ( 일반적으로 10000건 이상의 데이터가 필요하다고 함 )
- GPU 버전도 존재함.
LightGBM 실행
conda install lightgbm
- Package 다운로드 방법
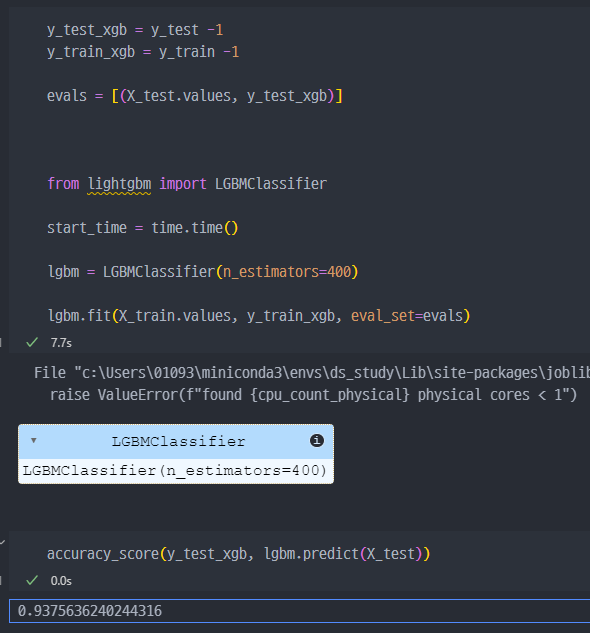
- 7.7초만에 결과가 출력되었으므로, 가장 시간이 빠르다는 것을 알 수 있다 (GBM, XGBoost 대비)
- XGBoost 와 마찬가지로 최신버전에서는
early_stopping_rounds가 작동하지 않는다.- 이유는 찾아봐야 할듯 ??
참고 : GridSearchCV 개념
GridSearchCV는 사이킷런(sklearn) 라이브러리에서 제공하는 도구로, 모델의 하이퍼파라미터를 자동으로 탐색하고 최적의 조합을 찾아주는 기능을 제공합니다.
기본 개념
모델의 성능은 하이퍼파라미터(예: 결정 트리의 깊이, SVM의 커널 종류 등)에 크게 좌우됩니다. 이러한 하이퍼파라미터를 수동으로 조정하는 것은 비효율적이고 시간이 많이 걸릴 수 있습니다. GridSearchCV는 가능한 하이퍼파라미터 조합을 모두 시도해 보고, 교차 검증(cross-validation)을 통해 최적의 조합을 찾아줍니다.
작동 방식
하이퍼파라미터 탐색 공간 정의: 사용자가 탐색하고자 하는 하이퍼파라미터의 값들을 사전 형태로 지정합니다.교차 검증 수행: 지정된 하이퍼파라미터 조합에 대해 각 조합을 교차 검증하여 성능을 평가합니다.최적의 조합 선택: 교차 검증 결과에 따라 가장 성능이 좋은 하이퍼파라미터 조합을 선택합니다.- 주요 기능
교차 검증(cross-validation) : 데이터셋을 여러 번 분할하여 학습 및 검증을 반복해 과적합을 방지하고 모델의 일반화 성능을 평가할 수 있습니다.자동 하이퍼파라미터 튜닝: 탐색 공간 내 모든 가능한 조합을 시도해 최적의 하이퍼파라미터를 자동으로 선택합니다.
사용 예제
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
# 탐색할 하이퍼파라미터의 값들을 사전 형태로 정의
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [None, 10, 20],
'min_samples_split': [2, 5, 10]
}
# 모델 생성
rf = RandomForestClassifier()
# GridSearchCV 설정
grid_search = GridSearchCV(
estimator=rf,
param_grid=param_grid,
scoring='accuracy', # 성능 평가 기준
cv=5, # 5-fold 교차 검증
n_jobs=-1 # 병렬 처리 사용 (모든 CPU 코어 사용)
)
# 학습 데이터로 적합(fit) 시도
grid_search.fit(X_train, y_train)
# 최적의 하이퍼파라미터 출력
print("Best Parameters:", grid_search.best_params_)
print("Best Cross-Validation Score:", grid_search.best_score_)
주요 속성 및 메서드
best_params_: 최적의 하이퍼파라미터 조합.best_params_: 최적의 하이퍼파라미터 조합.best_score_: 최적의 교차 검증 점수.cv_results_: 모든 하이퍼파라미터 조합의 교차 검증 결과.best_estimator_: 최적의 하이퍼파라미터로 학습된 모델 객체.
장점
- 자동화된 탐색 : 사용자가 하이퍼파라미터를 직접 조정하지 않아도 되므로 편리합니다.
- 교차 검증 포함 : 모델의 성능을 검증할 때 과적합을 방지하기 위한 교차 검증이 내장되어 있습니다.
단점
- 연산 비용 : 탐색 공간이 커지면 계산량이 기하급수적으로 증가할 수 있습니다.
- 시간 소모 : 많은 조합을 시도할 경우 실행 시간이 길어질 수 있습니다. 이를 해결하기 위해 RandomizedSearchCV를 사용해 탐색 공간의 일부만 시도하는 방법도 있습니다.
GridSearchCV는 모델의 성능을 최적화하고 안정적으로 하이퍼파라미터를 선택할 수 있도록 도와주는 강력한 도구입니다.
