
2024.12.10
군집 : 비지도 학습
군집의 평가
지도학습, 비지도 학습
- 지능이 케이크라면, 비지도 학습은 케이크의 빵, 지도 학습은 케이크 위의 크림, 강화학습은 케이크 위의 체리
- 이 말은 비지도학습의 무궁무진한 가능성에 대한 업근 (얀 르쿤 - 인공지능 4대 선구자 중 1인)
군집 (Clustering)
- 군집 (clustering) : 비슷한 샘플을 모음
- 이상치 탐지 ( Outlier detection ) : 정상 데이터가 어떻게 보이는지 학습, 비정상 샘플을 감지
- 밀도 추정 : 데이터셋의 확률 밀도 함수 ( Probability Density Funcion, PDF )를 추정, 이상치 탐지 등에 사용
K-Means
- 군집 (clustering) 중 가장 일반적인 알고리즘.
- 군집 중심(Centroid)이라는 임의의 지점을 선택해서 해당 중심에서 가장 가까운 포인트들을 선택하는 군집화
- 일반적인 군집화에서 가장 많이 사용되는 기법
- 거리 기반 알고리즘으로 속성의 개수가 매우 많을 경우 군집화의 정확도가 떨어짐

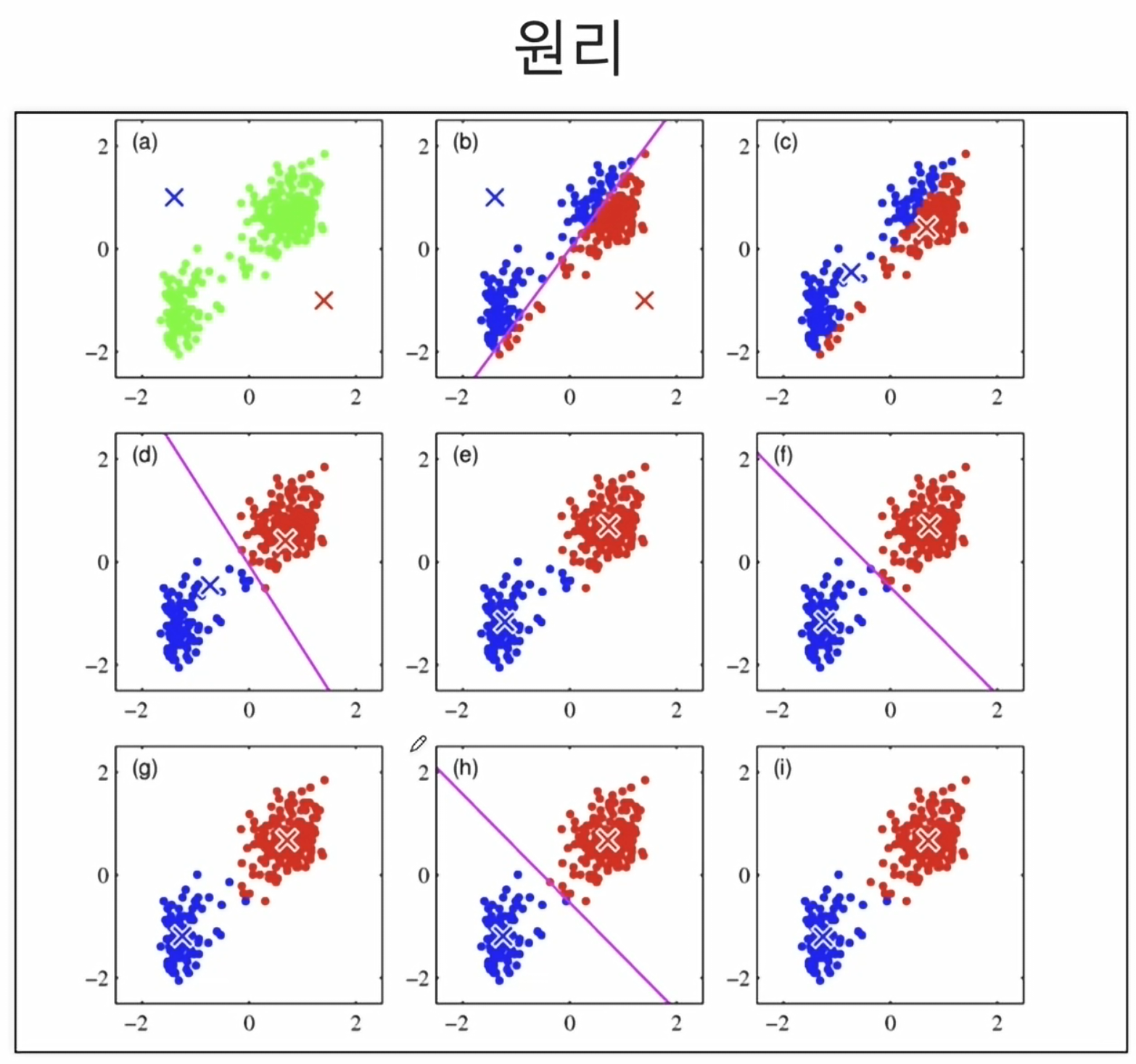
- 원리
그림(a): 데이터에 두 개의 점을 임의로 지정한다.그림(b): 해당 임의의 두 점의 사이값, 중심값값에 직선을 긋는다.그림(b): 해당 직선으로 인해 데이터들은 두 그룹으로 나누어 진다. (파란색, 붉은색)그림(c): 나누어진 데이터 그룹(2개)에서 각 중심값을 찾는다.그림(d): 찾아진 두 개의 중심값을 다시 처음의 임의의 값처럼 인식하여 다시 중심선을 긋는다.- 이렇게 계속 반복하며 더 이상 중심값이 변하지 않을 때 중단된다.
k-Means : iris 데이터 실습
관련 라이브러리 및 데이터 읽기
- 편의상 두 개의 특성만 추출하여 다룰예정 (feature 값 두개만 진행)
군집화 진행
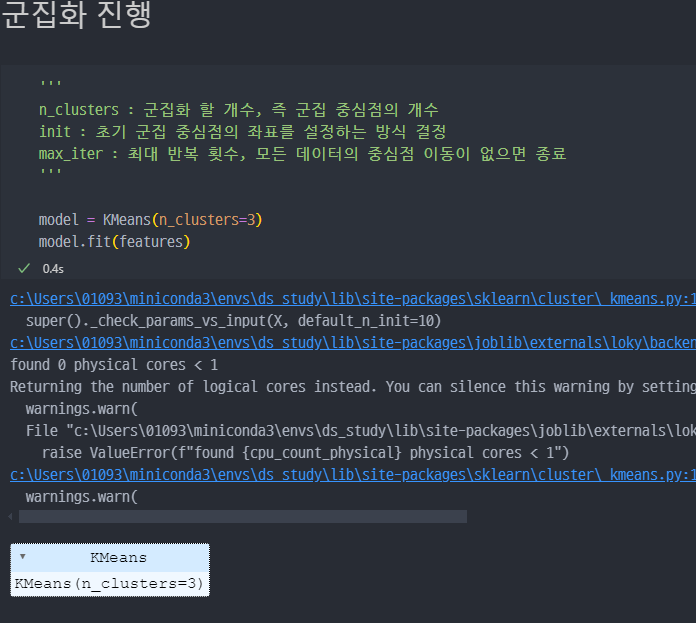
- 군집화는 비지도 학습 이므로, 기존에 진행했던
ML과 다르게정답값,y값이 없다.- 즉, 정답값 없이 해당 데이터만으로 데이터 분류하도록
fit( )진행하는게 특징이다.
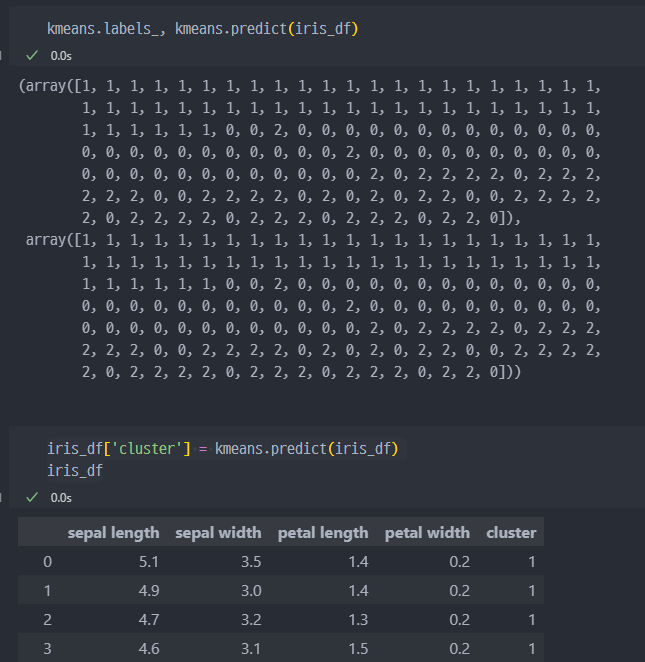
- 학습완료되고, 각 군집집단의 중심좌표
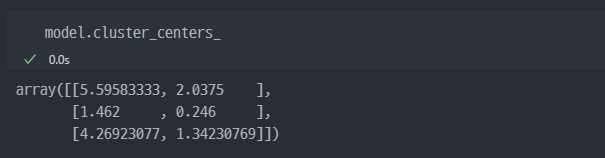
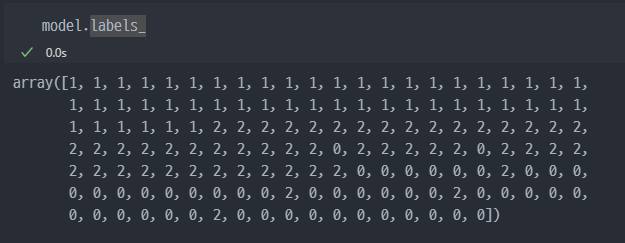
아래의
label값은 단순히 분류를 위해서kMeans모델이 임의로 배정한 숫자임.
세토사, 버지컬러 등과 관계 없는 단순 분류를 위한 숫자 0, 1, 2
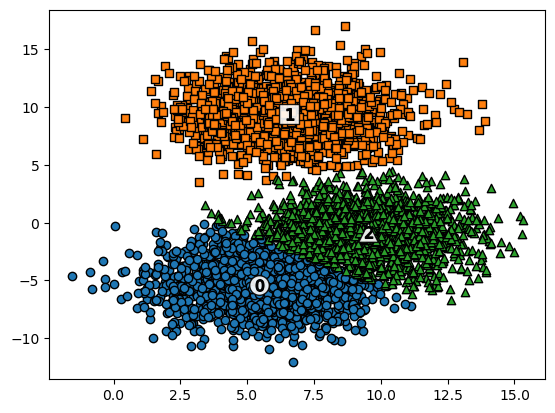
그래프 작성
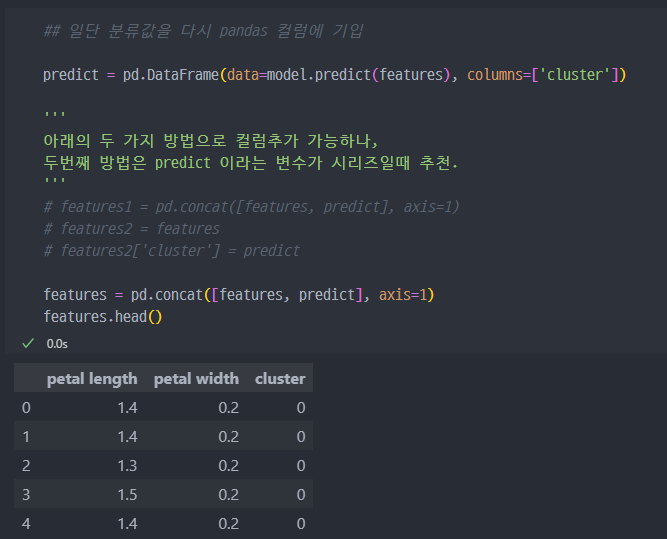
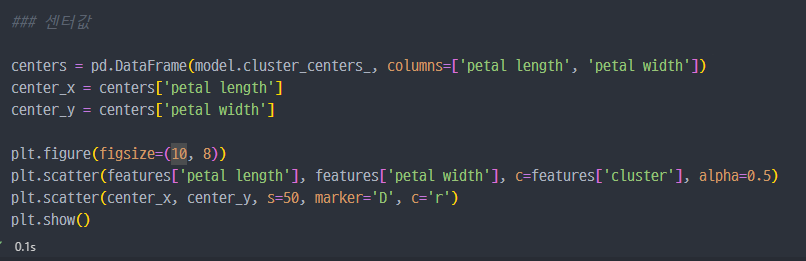
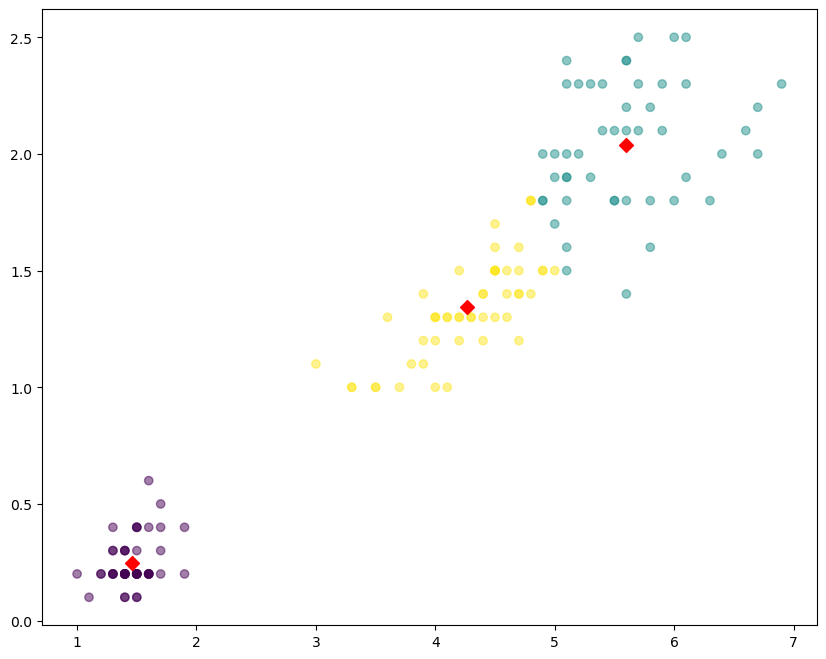
나름대로 잘 나누어진 것 같다.
make_blobs
군집공부를 위해서 데이터를 만들어 주는 형태. 군집화 연습을 위한 데이터 생성기 이다.
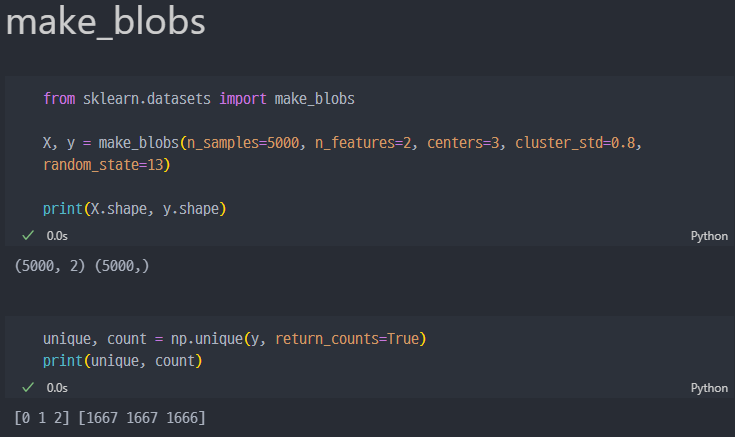
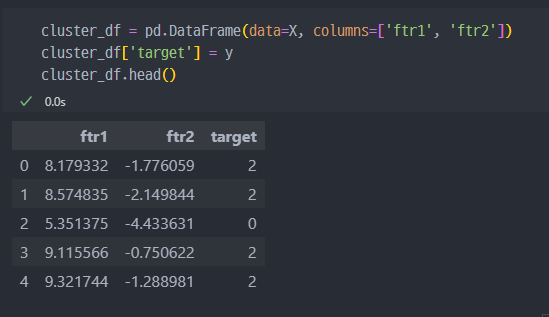


군집 평가
- 지도학습은 평가할 수 있다. 정답값, y값이 존재한다.
- 지도학습은 회귀모델과 분류모델로 크게 나눌 수 있다.
- 회귀 : 예측값과 참값 사이의 에러를 계산
- 분류 : accuracy 등으로 평가, auc 등
- 군집모델의 평가는?
- 지도학습과 다르게, 군집모델, 비지도학습은 정답값이 없다.]
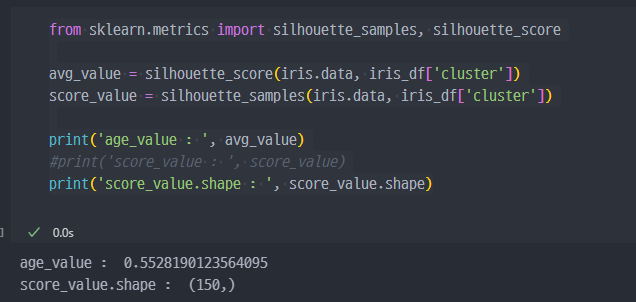
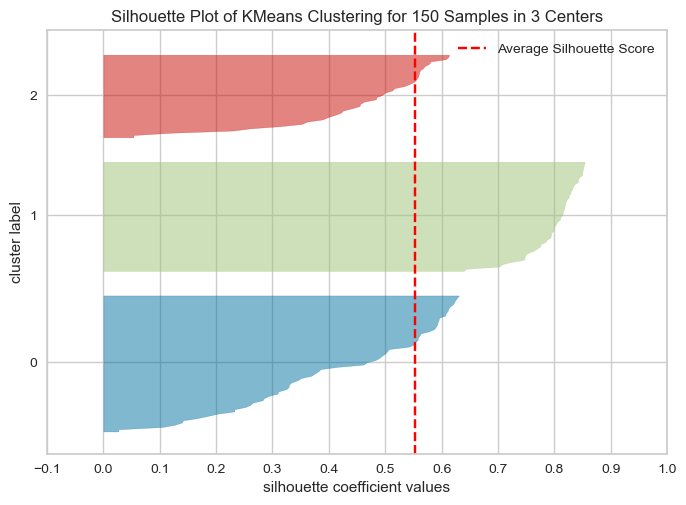
실루엣 분석 (군집모델 평가)
- 실루엣 분석은 각 군집간의 거리가 얼마나 효율적으로 분리되어 있는지 나타냄
- 다른 군집과는 거리가 떨어져 있고, 동일 군집간의 데이터는 서로 가깝게 잘 뭉쳐 있는지 확인
- 군집화가 잘 되어 있을수록 개별 군집은 비슷한 정도의 여유공간을 가지고 있음.
- 실루엣 계수 : 개별 데이터가 가지는 군집화 지표
즉, 같은 군집 내 있는 데이터와 거리 (a)와 다른 군집 중에서 가장 가까준 데이터와의 거리(b)라 할 때,
sil은 b-a/b 로 볼 수 있고, 해당 값이 음수인 경우 다른 군집과 더 가깝다는 의미이니 문제가 될 수 있다.
데이터 읽기
군집 결과 평가 작업


(hellow. world)