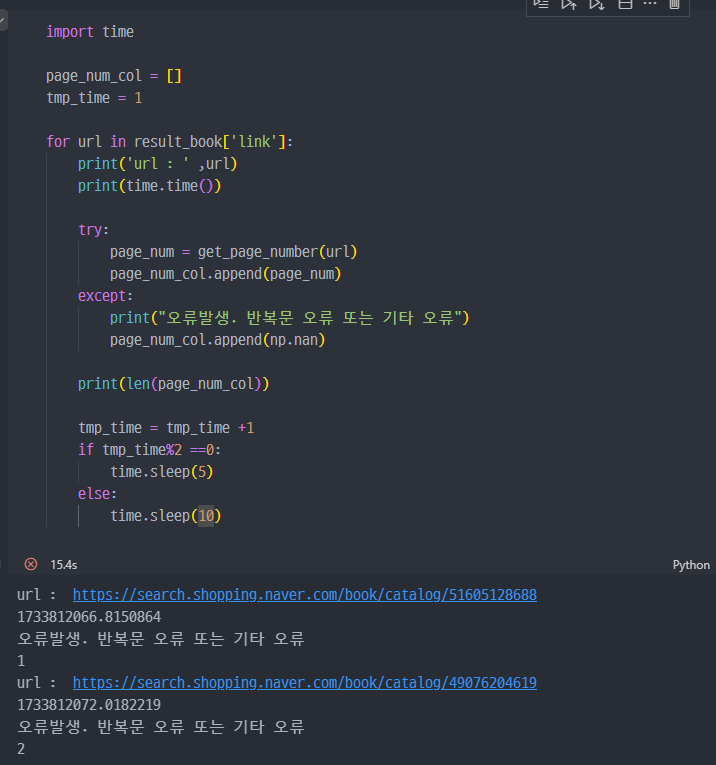
책 가격 회귀 분석
책 가격 회귀분석
네이버 API 이용 (기본설정)
네이버 API 적용 및 URL 만드는 함수 설정
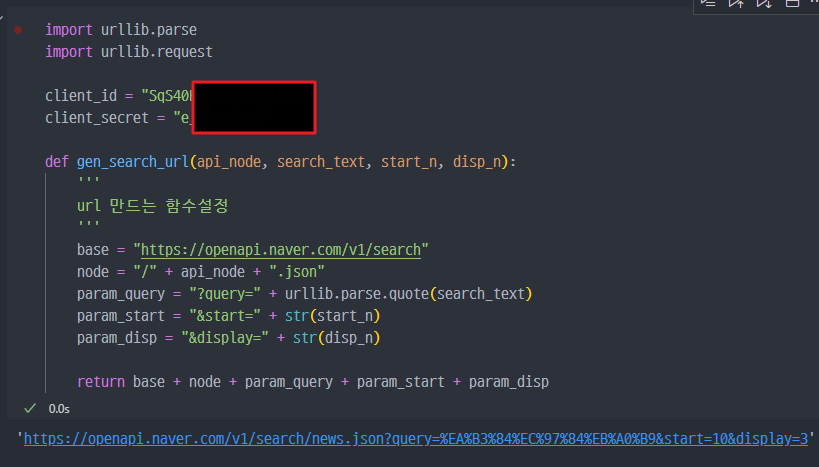
- 코드해설
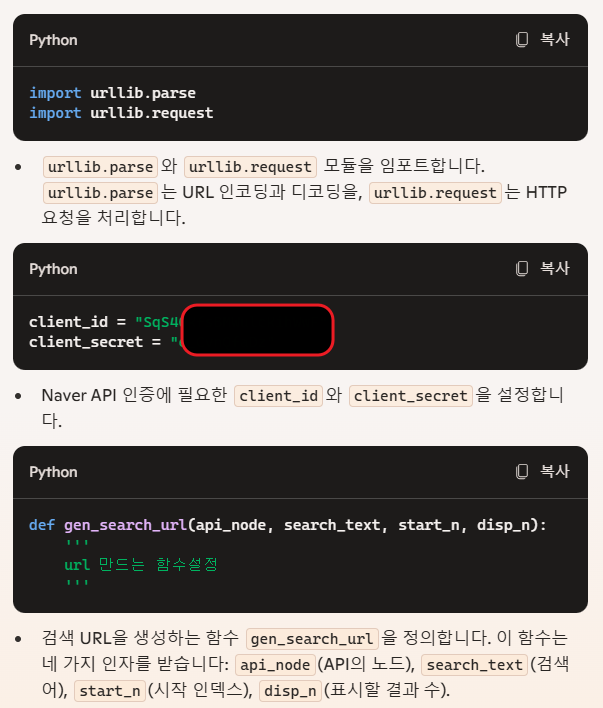
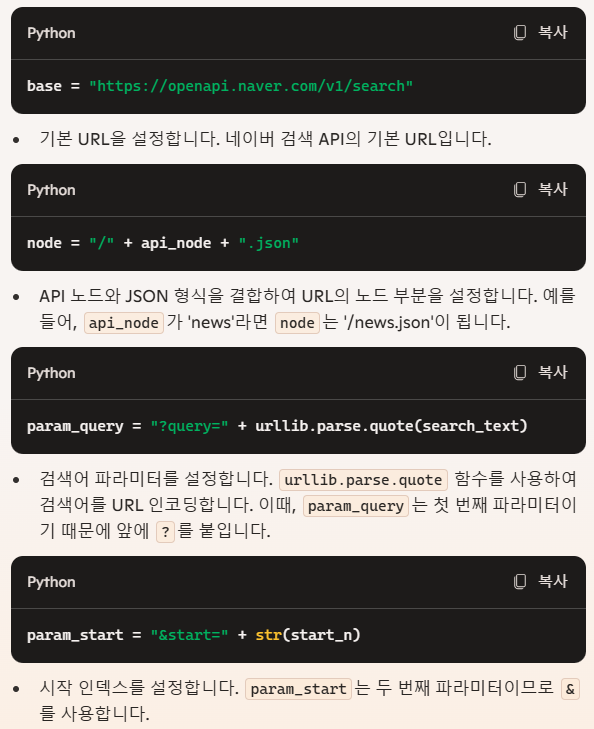
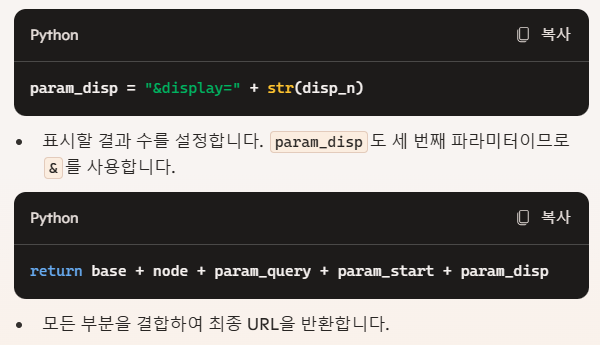
질문에 대한 답변
1. param_query에서 왜 "?query=" 이렇게 입력하는거야? 나머지는 "&start=" 이런건데?
- 첫 번째 파라미터는 URL의 쿼리 문자열이 시작되는 부분입니다. 쿼리 문자열은
?로 시작하고, 이후의 파라미터들은&로 구분됩니다. 따라서 첫 번째 파라미터에는?를 붙이고, 그 이후에는&를 사용하여 구분합니다.
2. param_start 와 param_disp의 숫자는 제한이 없어? 입력값으로 막 100이나 1000 같은 숫자를 넣어도 작동이 되는거야?
- 네이버 검색 API에는 각 파라미터에 대한 제한이 있을 수 있습니다. 예를 들어, display 파라미터는 한 번에 표시할 수 있는 최대 결과 수가 정해져 있을 수 있습니다. 이러한 제한 사항은 네이버 API의 공식 문서를 참조하여 확인하는 것이 좋습니다. 너무 큰 값이 입력되면 API 요청이 실패할 수 있습니다.
- 테스트 진행 시,
start_num은 큰 상관없지만,disp_num의 경우 100개가 최대값.
생성된 url에 따라서 Request하고 정보를 얻는 함수
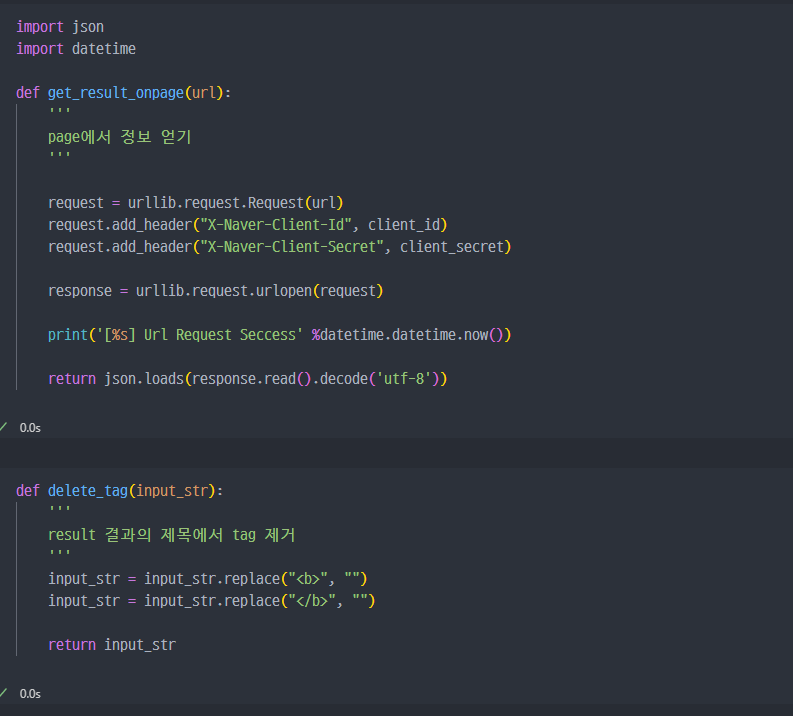
- 코드해설


API를 이용한 정보수집
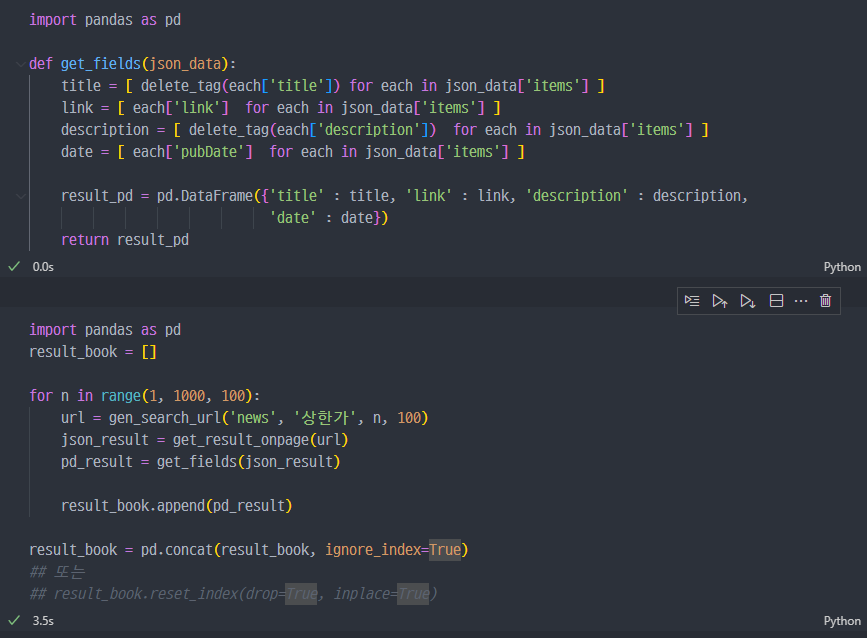
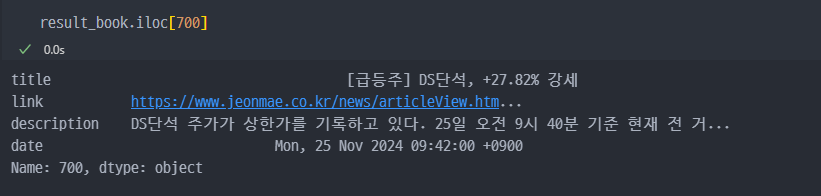
다시 강의로..(책 가격 정보)
각 함수에서 book에 대한 정보에 맞게 파라미터 등 수정진행
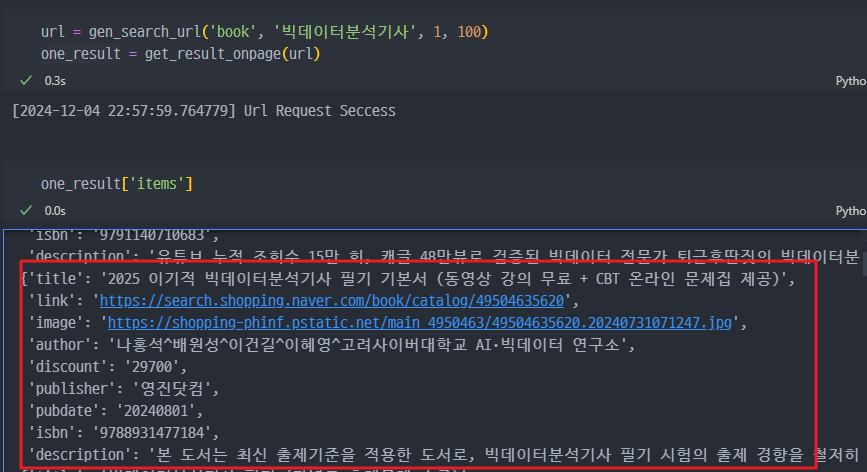
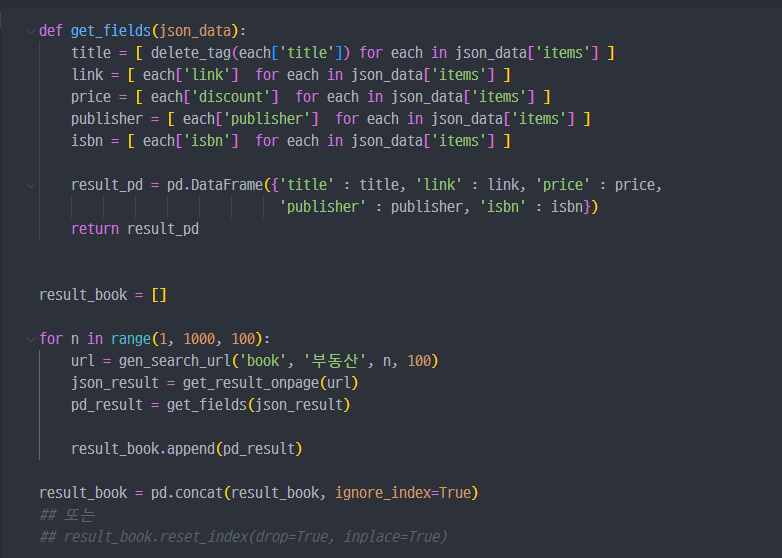
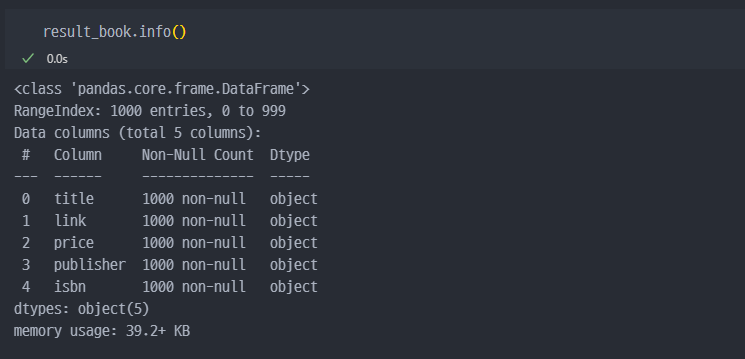
한 페이지에 대한 테스트
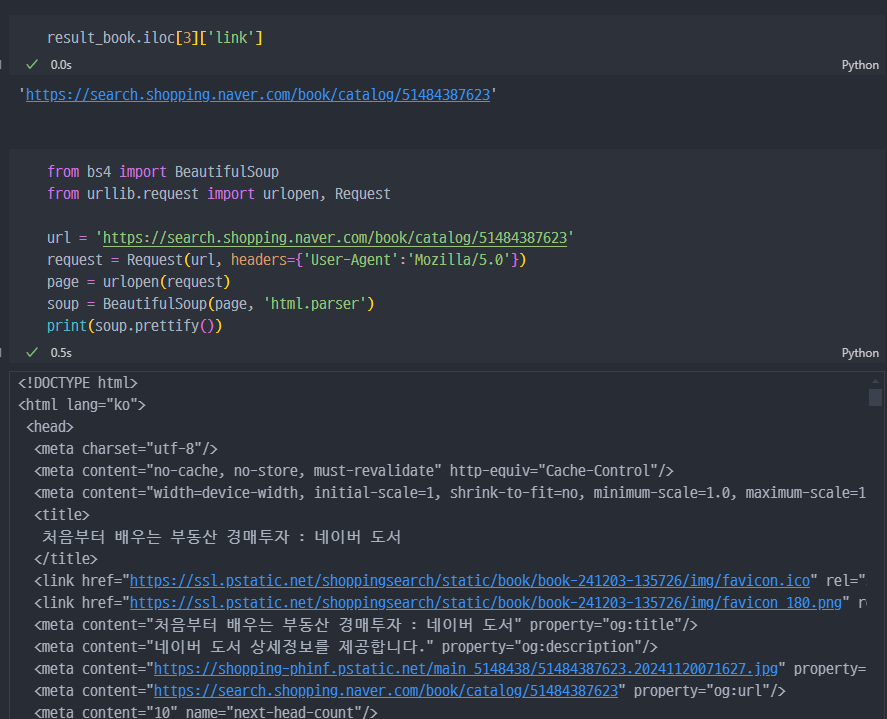
코드 설명
1. from bs4 import BeautifulSoup
BeautifulSoup 라이브러리에서 BeautifulSoup 클래스를 가져옵니다.
이 라이브러리는 HTML 및 XML 파일을 파싱(구문 분석)하여 데이터를 구조화된 형태로 처리할 수 있도록 돕습니다.
2. from urllib.request import urlopen, Request
urlopen과 Request를 가져옵니다.
Request: HTTP 요청을 보낼 때 헤더나 추가 데이터를 설정하기 위해 사용합니다.urlopen: HTTP 요청을 보내고 응답을 받아오는 함수입니다.
3. url = 'https://search.shopping.naver.com/book/catalog/51484387623'
요청할 URL을 문자열로 정의합니다.
이 URL은 네이버 쇼핑 페이지의 특정 책에 대한 정보를 나타냅니다.
4. request = Request(url, headers={'User-Agent':'Mozilla/5.0'})
Request객체 생성: 요청에 포함할 헤더를 설정합니다.User-Agent: 클라이언트(브라우저 또는 스크립트)의 정보를 서버에 전달합니다.Mozilla/5.0: 은 일반적인 웹 브라우저처럼 보이도록 하는 값을 설정한 것입니다.
일부 웹사이트는 스크립트 요청을 차단하기 때문에, 브라우저 요청처럼 보이게 만들어야 합니다.
5. page = urlopen(request)
- HTTP 요청 전송: request 객체를 통해 HTTP 요청을 보내고 응답을 받아옵니다.
이 응답은 웹페이지의 HTML 데이터로 구성되어 있습니다.
6. soup = BeautifulSoup(page, 'html.parser')
HTML 파싱: BeautifulSoup을 사용하여 받은 HTML 데이터를 파싱(구문 분석)합니다.'html.parser': 기본 파서로 HTML을 처리하는 모드입니다.
다른 파서 옵션으로 lxml 또는 html5lib 등이 있습니다.
7. print(soup.prettify())
- HTML 출력: soup.prettify()는 HTML 코드를 보기 좋게 들여쓰기하여 문자열로 반환합니다.
이를 출력하여 HTML 구조를 확인합니다.
BeautifulSoup 라이브러리 설명
1. BeautifulSoup이란?
BeautifulSoup은 웹 스크래핑을 쉽게 할 수 있도록 HTML과 XML 파일을 파싱하고 탐색할 수 있는 Python 라이브러리입니다.
HTML 문서를 객체 구조로 변환하여 태그, 속성, 텍스트 등을 쉽게 추출할 수 있도록 돕습니다.
2. 주요 특징
파싱: HTML/XML 데이터를 파싱하여 계층적 구조로 변환합니다.검색: 특정 태그, 속성, 또는 텍스트를 빠르게 검색할 수 있습니다.변환: 문서의 구조를 재구성하거나, HTML을 수정할 수 있습니다.다양한 파서 지원: 기본 제공되는 html.parser 외에도 더 빠른 lxml, 호환성이 높은 html5lib를 지원합니다.
3. 장점
문법적으로 잘못된 HTML도 자동으로 처리할 수 있습니다.
간단한 API를 제공하여 HTML 탐색 및 데이터 추출이 매우 쉽습니다.
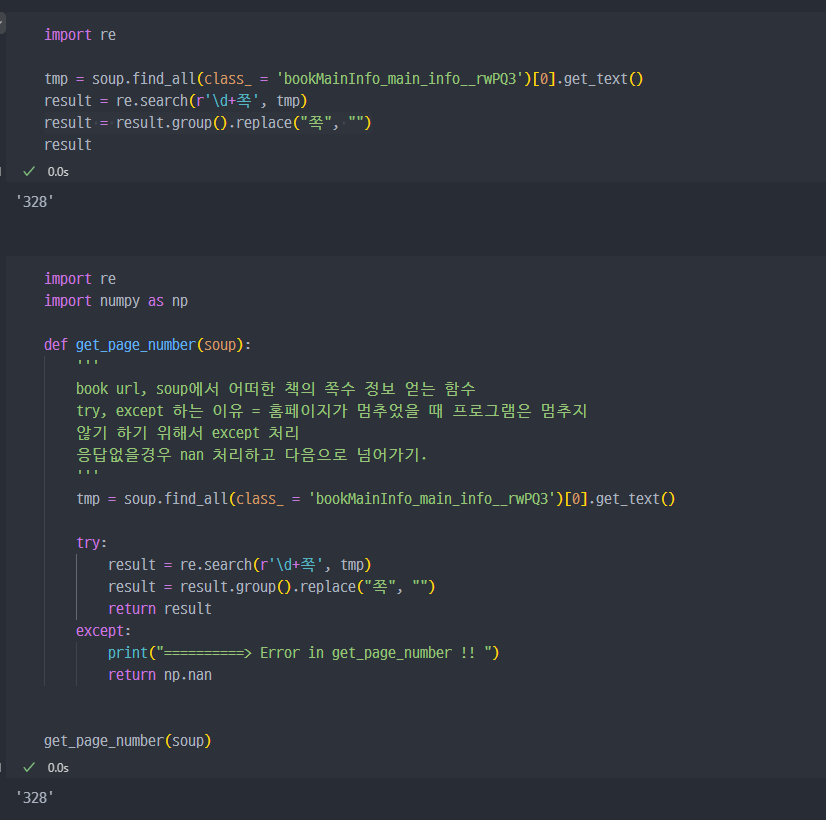
지속진행하려 했지만, 네이버에서 크롤링을 자동으로 차단하는 기능으로 인해 강의와 같이 1000개의 데이터 크롤링은 진행 불가능.