
타이타닉 생존자 예측
타이타닉 생존자 예측
개요
- 타이타닉은 영국에서 미국 뉴욕으로 가는 국제선
- 이로 인해, 탑승자들의 정보가 많이 남아있다.
- Machine Learning 학문에서
타이타닉 데이터는 연습문제 1번과 같은 느낌.
EDA
- EDA 진행 전에, 필요한 모듈 install
plotly_express- pandas를 통해서 엑셀을 불러들이고, 데이터 탐색 진행
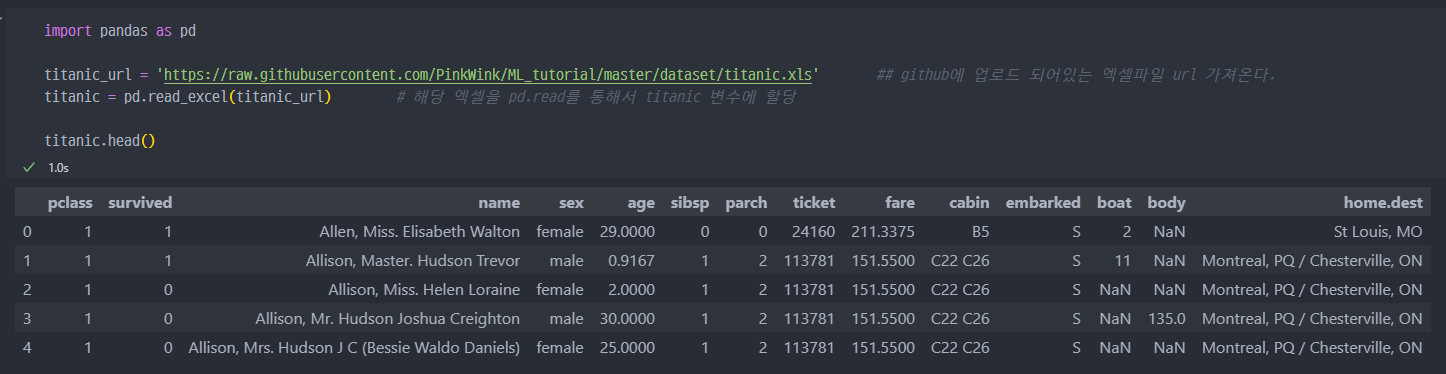
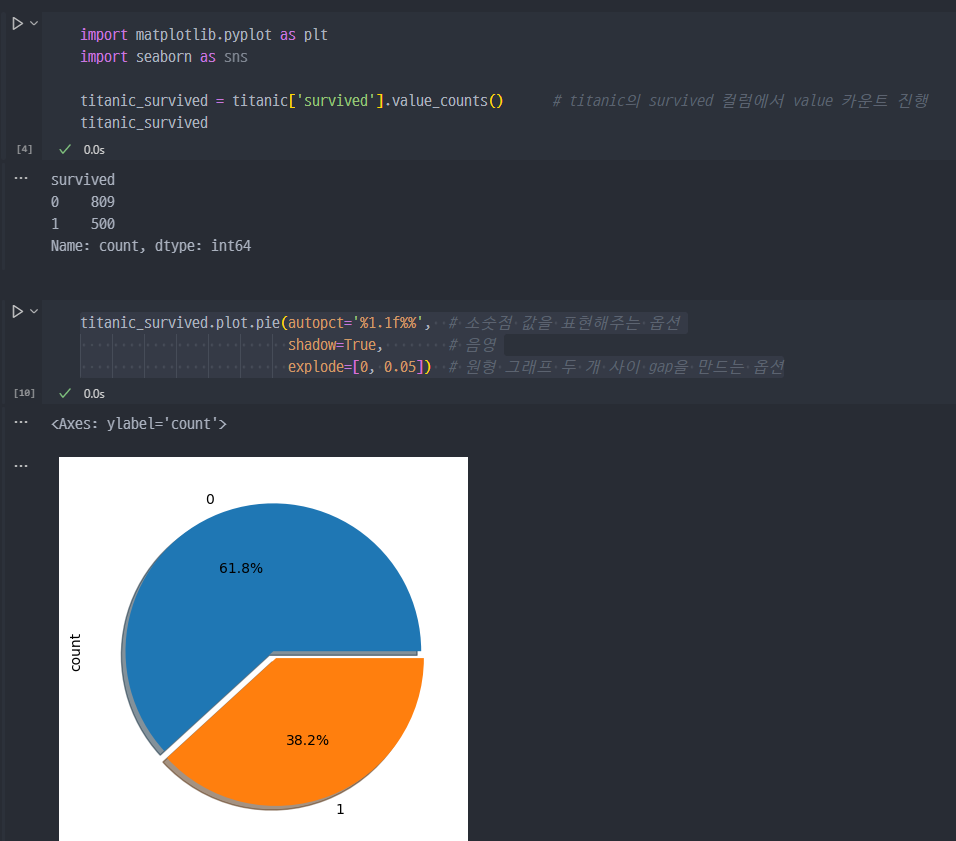
생존자 비율, 인원에 대한 그래프
- 탐색한 데이터에 대하여, 생존자 현황 그래프로 그리기
- seaborn 과 matplotlib 사용
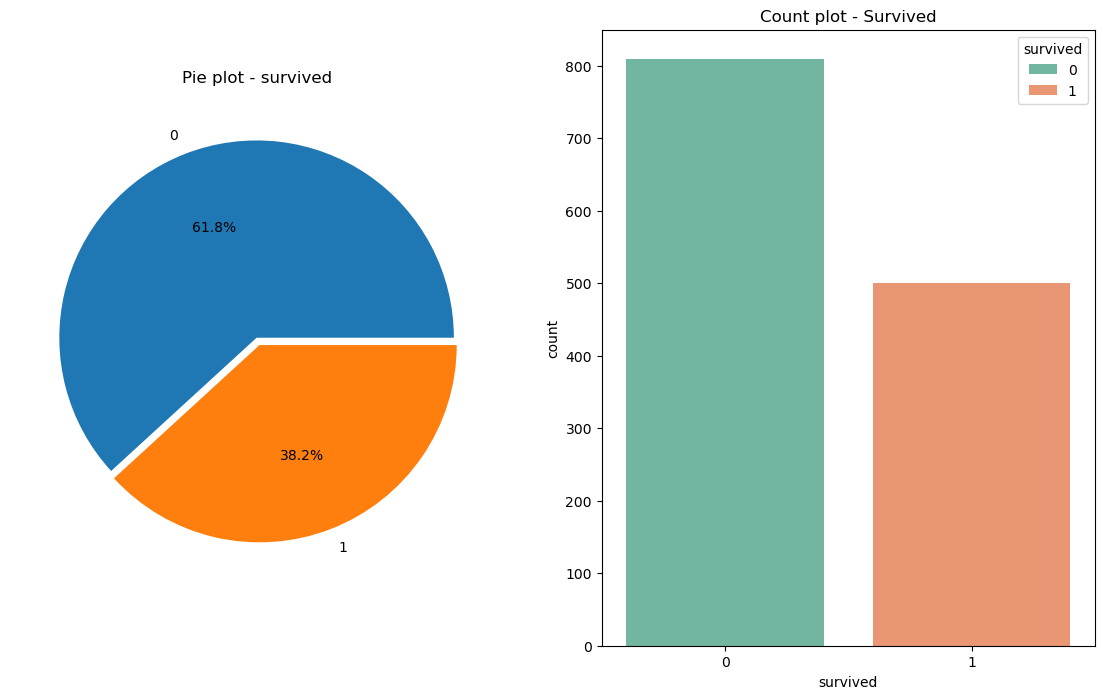
- 두 개의 그래프를 그려서 비교하기
성별에 따른 생존자
- 성별에 따른 그래프 작성
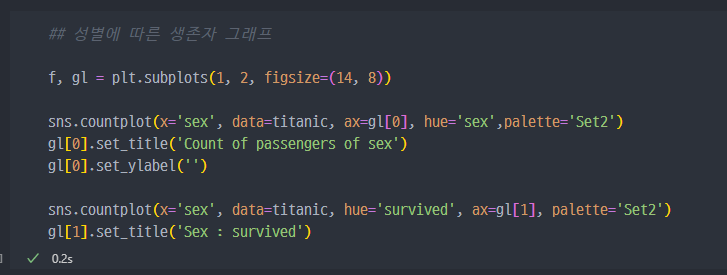
→ 결과를 보면, 남자의 생존률이 더 낮다. 탑승객은 남자가 약 840명, 여자는 약 450명 탑승한 것으로 보인다. 그렇지만, 생존자 수는 여성이 더 많다.
- 수정코드 ( gpt )

탑승 등급에 따른 생존
- 1등실의 생존 가능성이 아주 높다
- 위에서 보듯이 여성의 생존률도 높다
- 그렇다면, 1등실에는 여성이 많이 존재하였는가 ?
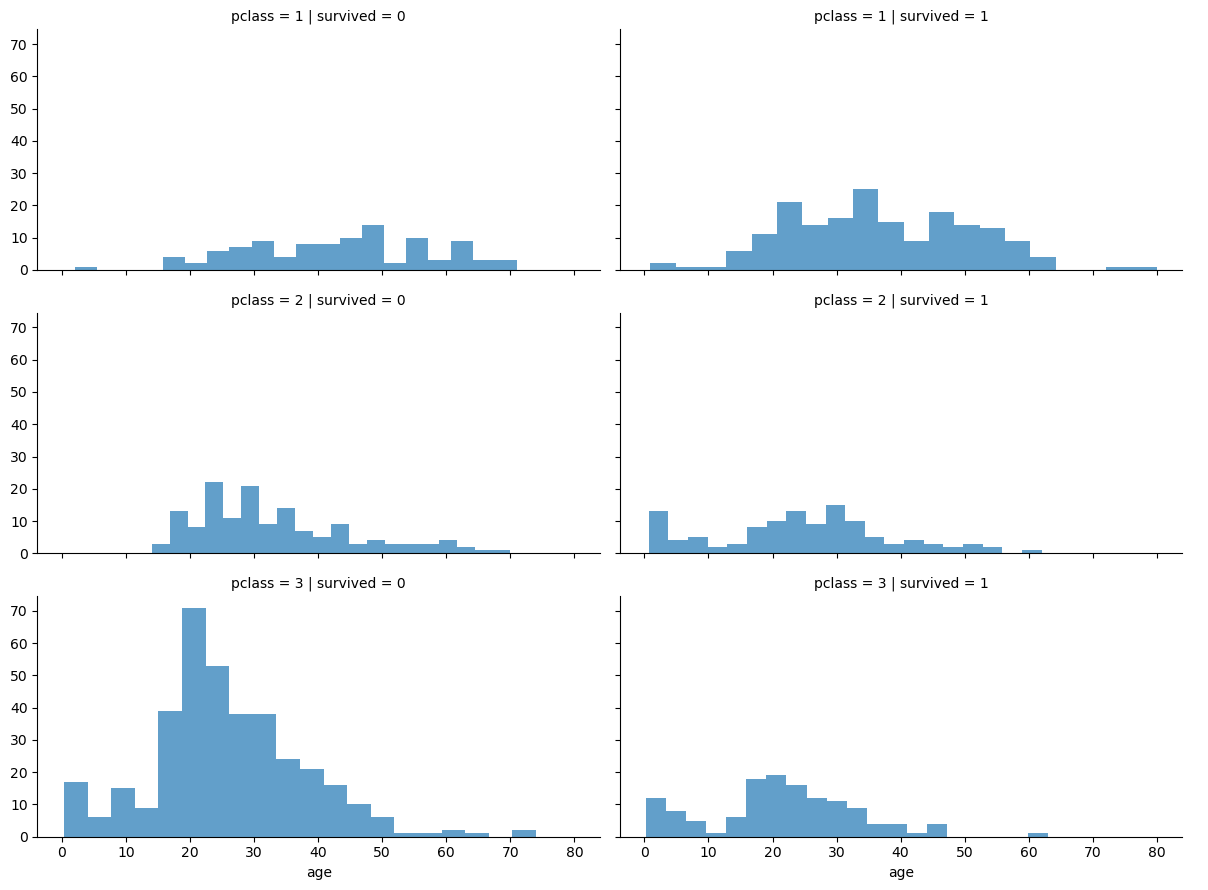
- FacetGrid 기능 활용하여 그래프 작성
- 남여 나누고, pclass(탑승 등급)별로 나누고, 나이에 대하여 히스토그램으로 그래프 작성
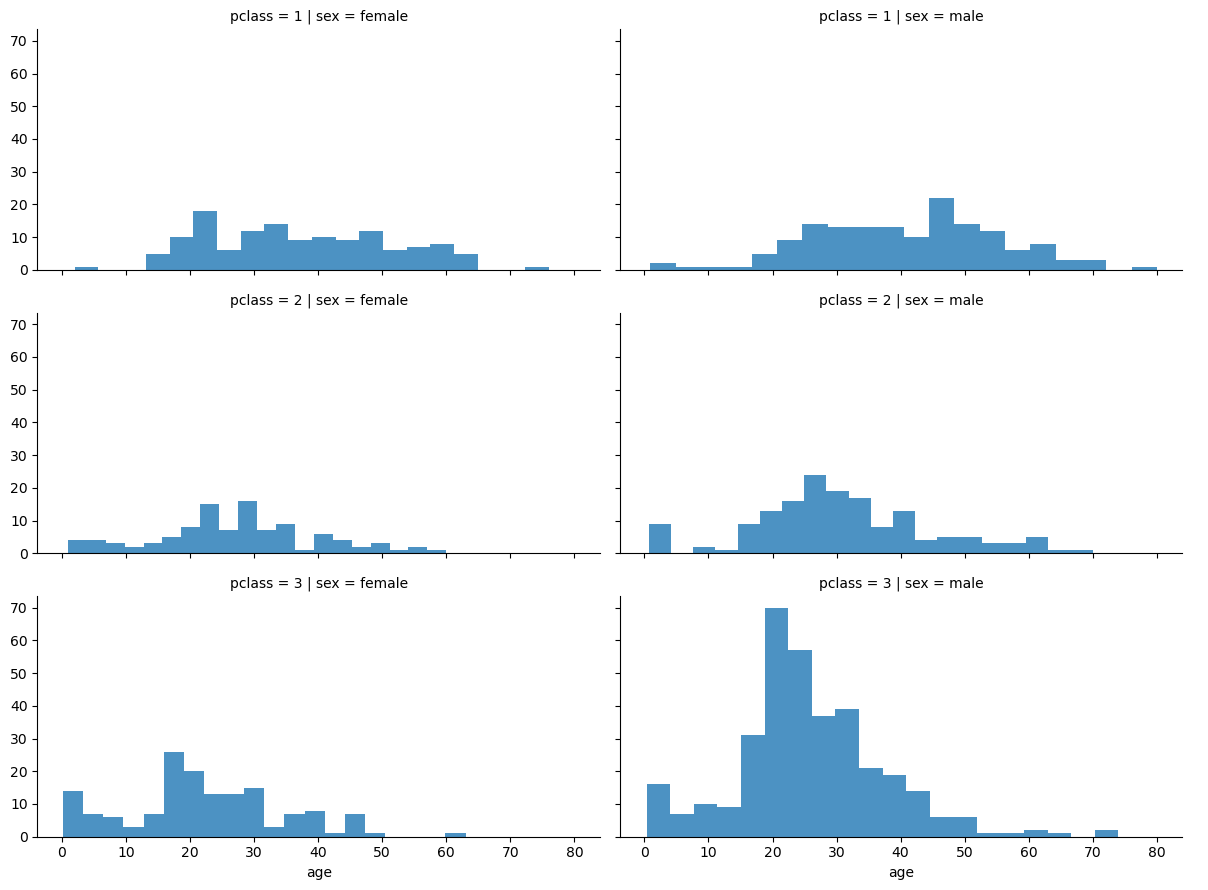
→ 1등실의 경우, 남여 및 노소 큰 차이 없이 균등 분포
→ 2등실의 경우, 남여차이는 별로 없지만, 영유아가 일부 존재
→ 3등실의 경우, 여성대비 남성의 수가 매우 많으며, 전체적으로 연령대가 낮음.
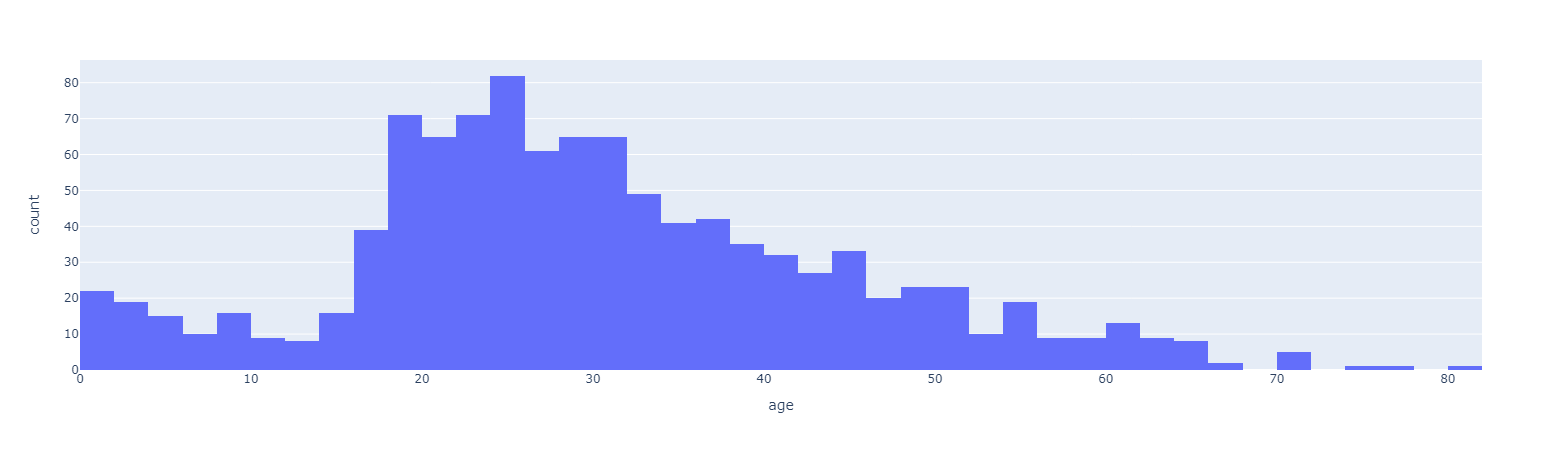
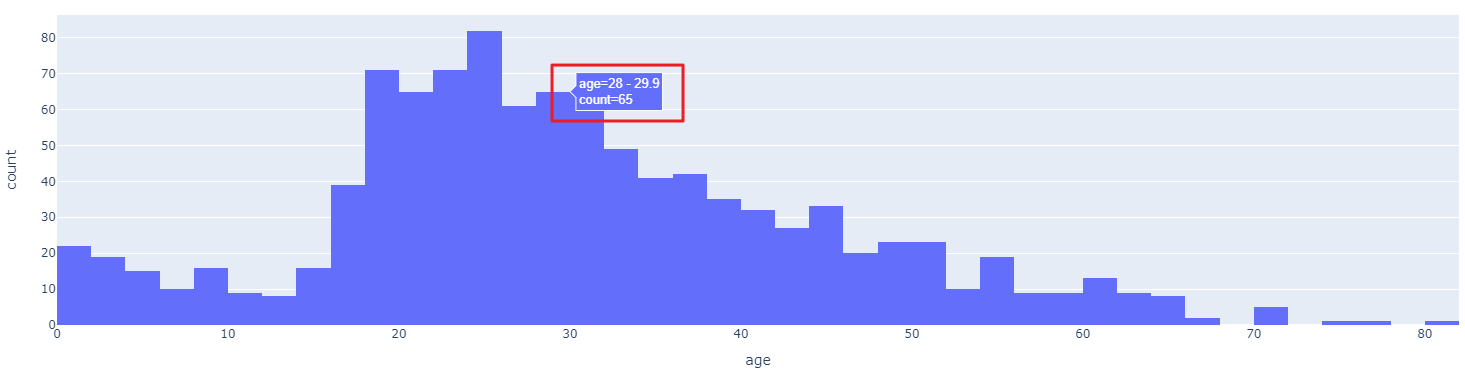
나이별 승객 현황
- plotly_express 를 통해서 그래프 작성
- 그래프 위 마우스오버하게 되면 정확한 데이터를 알려주는 기능 포함되어 있다.
등급(등실)별 생존률 현황
등급, 등실별 생존률 현황 시각화
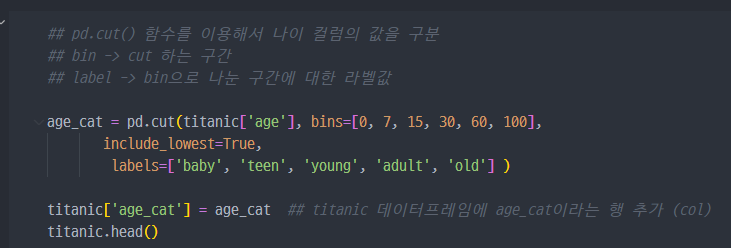
나이의 범위가 너무 많으니, pandas의 cut 함수를 이용해서 구분 진행.

subplot, barplot 활용하여 그래프 비교
- 참고사항 ( subplot 그래프 기본사항 )
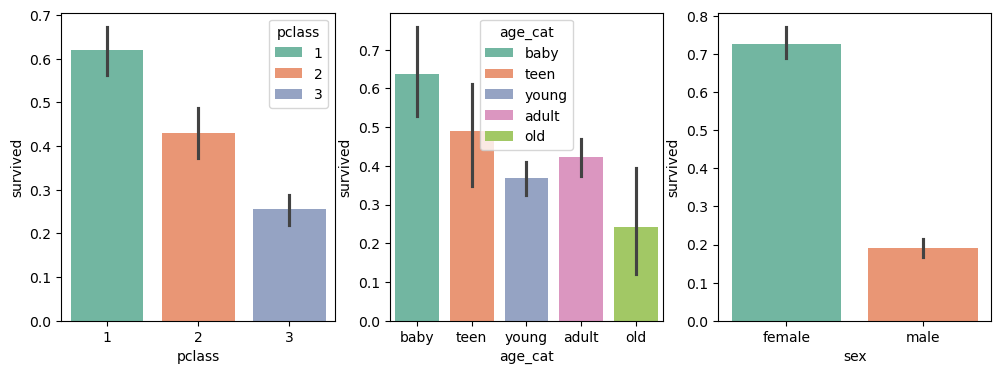
- subplot과 barplot활용하여, 클래스별, 나이별, 성별 생존률 나타내기.
타이타닉 생존상황
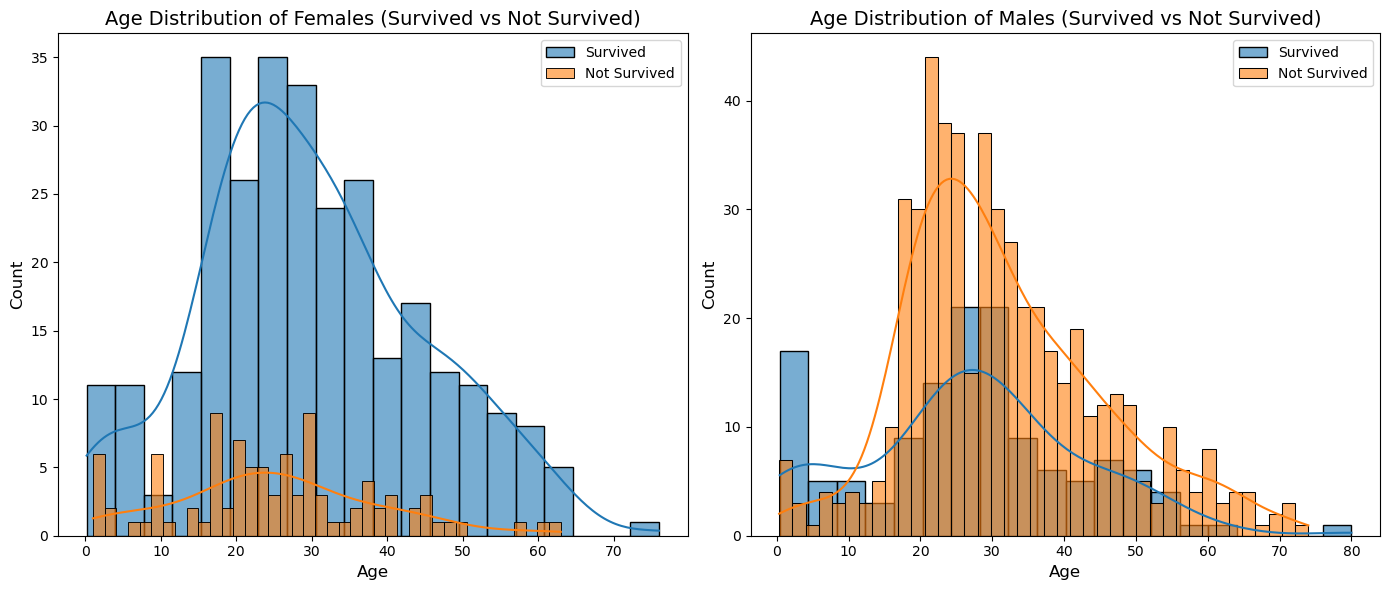
남여, 나이별 상황 시각화
- subplot과 histplot 사용.

- chatGPT 변경 (alpha 옵션 -> 투명도 )
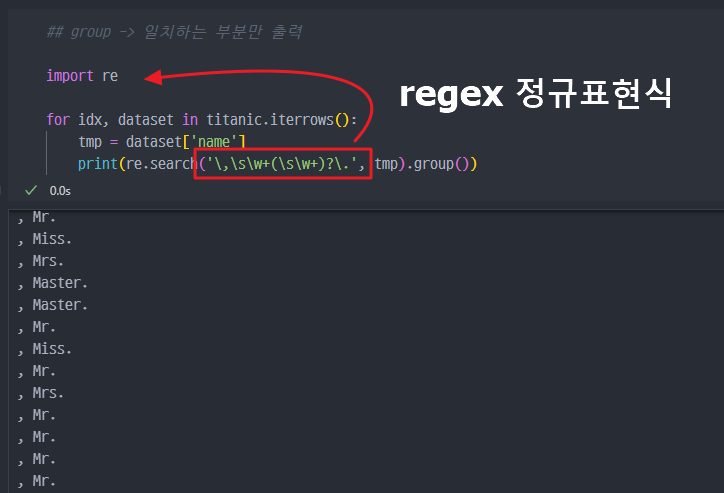
탑승객 이름을 통한 신분정보 습득
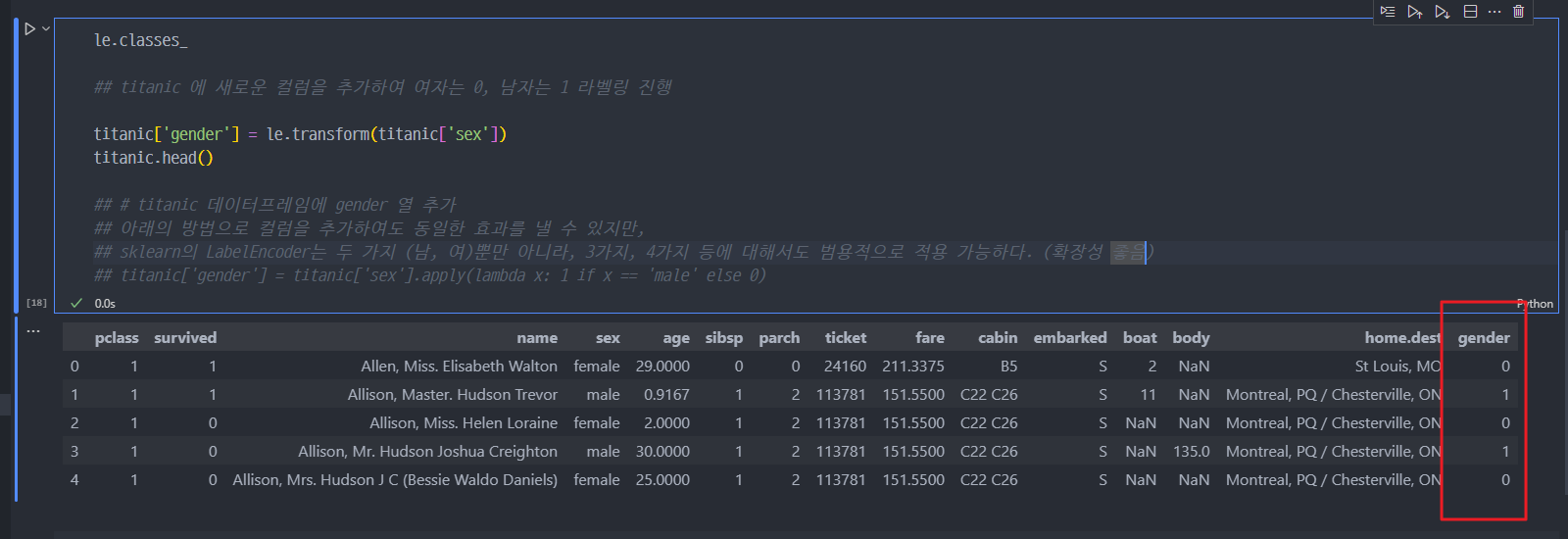
- regex (정규표현식)을 이용해서, 이름의 Mrs, Miss 등 중간 부분만 추출한다.
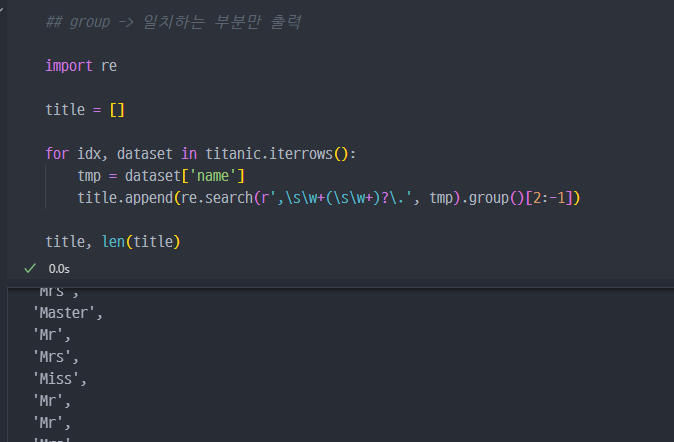
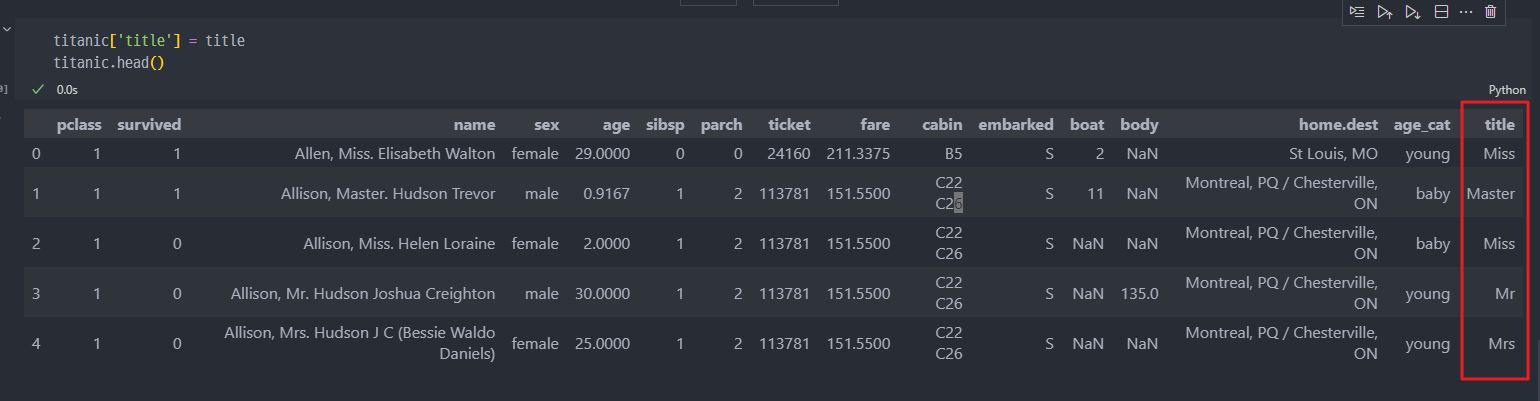
- 해당 title을 titanic에 행(컬럼) 추가 진행.
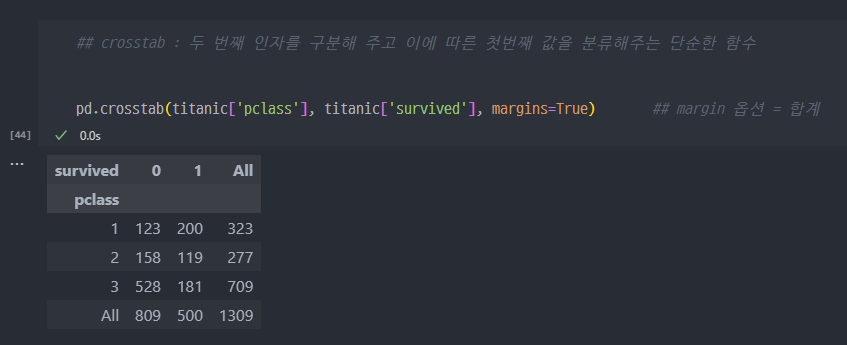
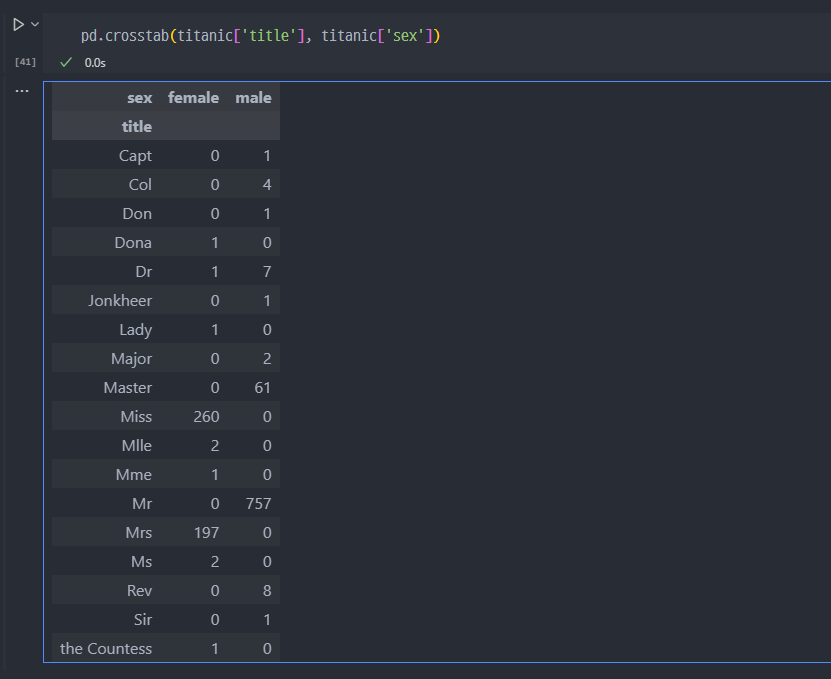
- crosstab 함수를 이용하여, 데이터 점검
-
남성, 여성을 지칭하는 호칭 구분 가능하다.
-
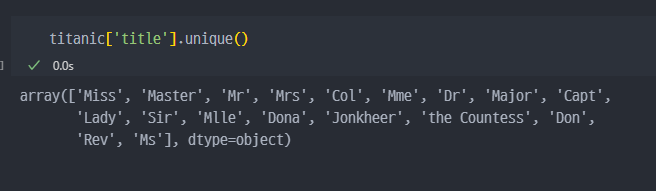
unique() 함수를 통해서 점검
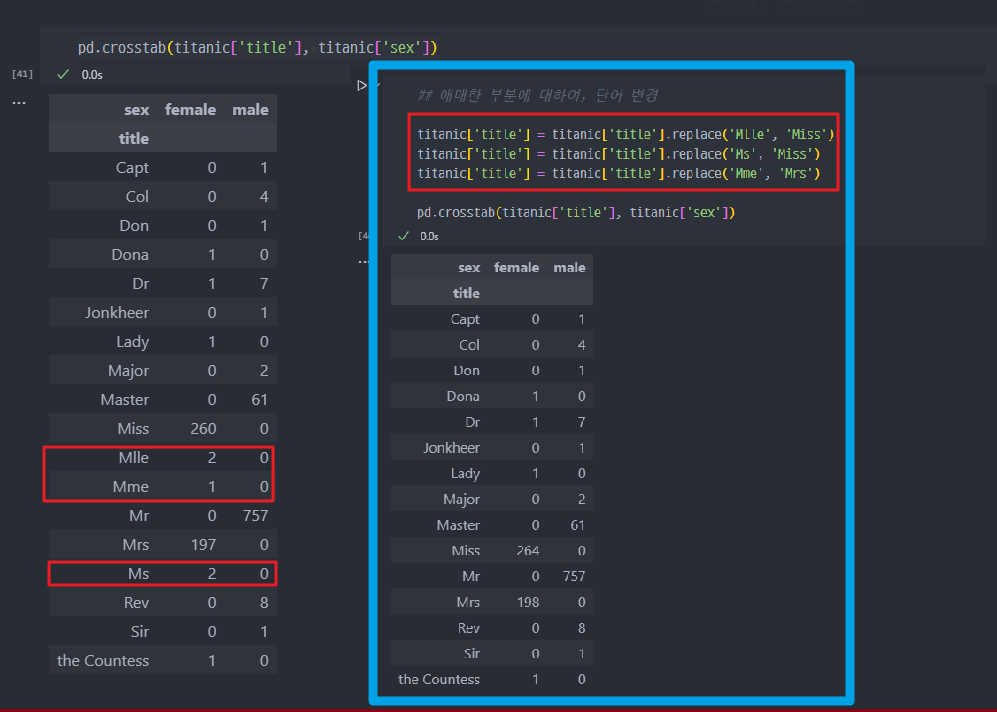
- 애매한 단어, 간헐적으로 사용되는 단어를 Mr 또는 Miss 등으로 변경한다.
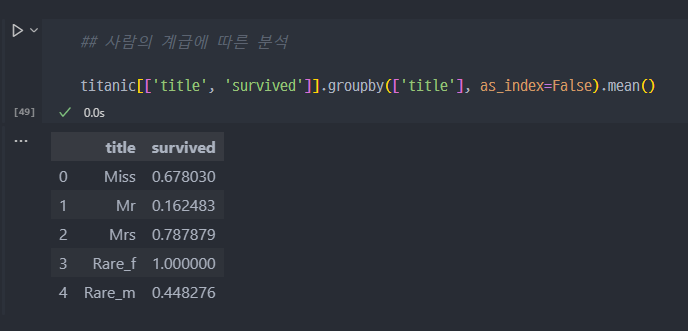
- 나머지 부분에 대하여, Mr/Miss/Mrs 와 또는 Rare_f / Rare_m 으로 구분한다.

- 사람의 계급, 계층에 따른 생존률 분석
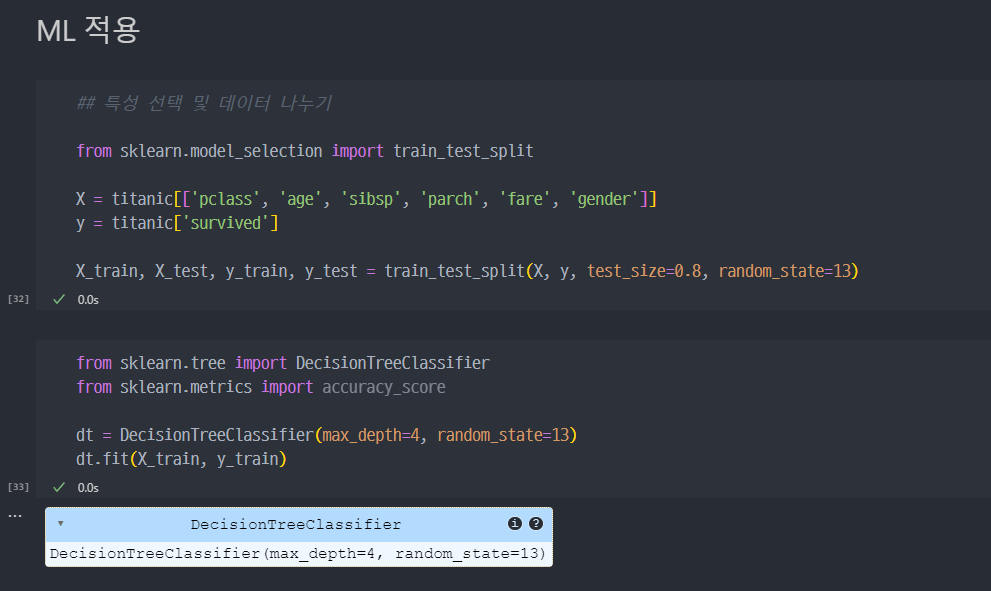
ML 이용한 Titanic 생존자 예측
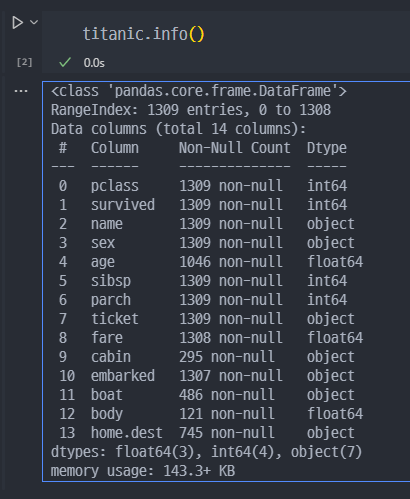
간단한 구조 확인
- 기본 데이터프레임의 구조 확인.
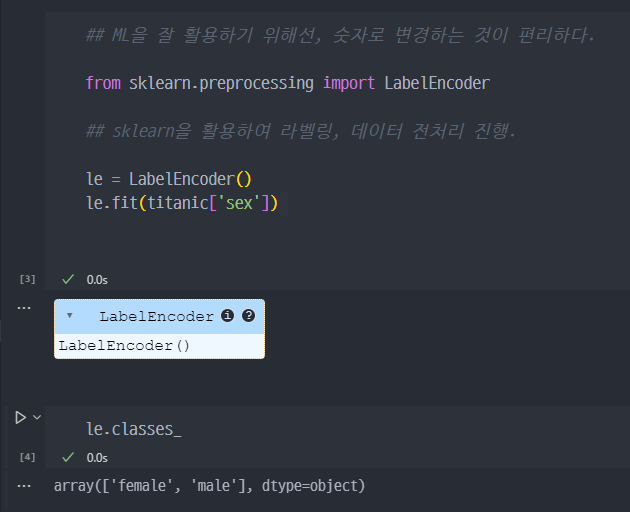
- ML을 활용하기 위해서는 기본적으로 숫자로 각 행이 이루어져 있는것이 편리하다.
- sklearn의 LabelEncoder() 활용하여 라벨링 진행.
결측치(NULL) 확인
- 전체 데이터프레임에서 NULL 이 포함된 것 같은 컬럼 확인하기.
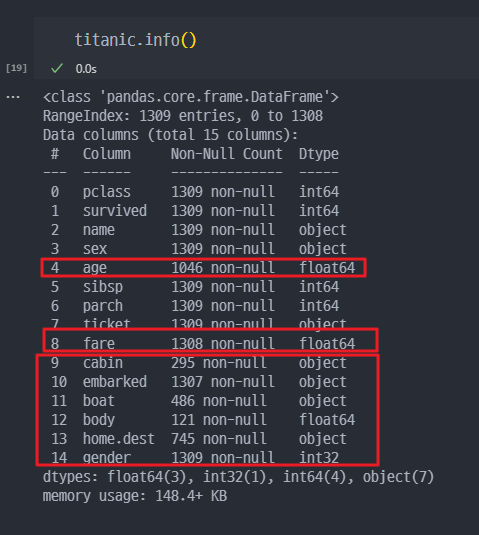
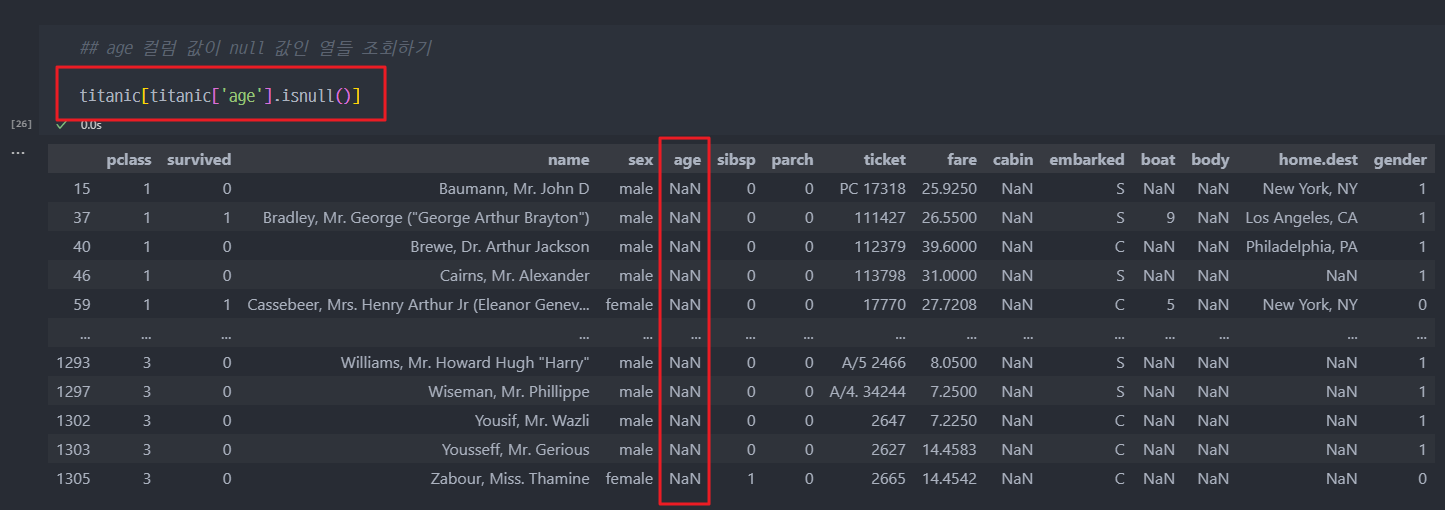
- 'age'컬럼에서 NULL인 row 들만 마스킹하여 조회하기
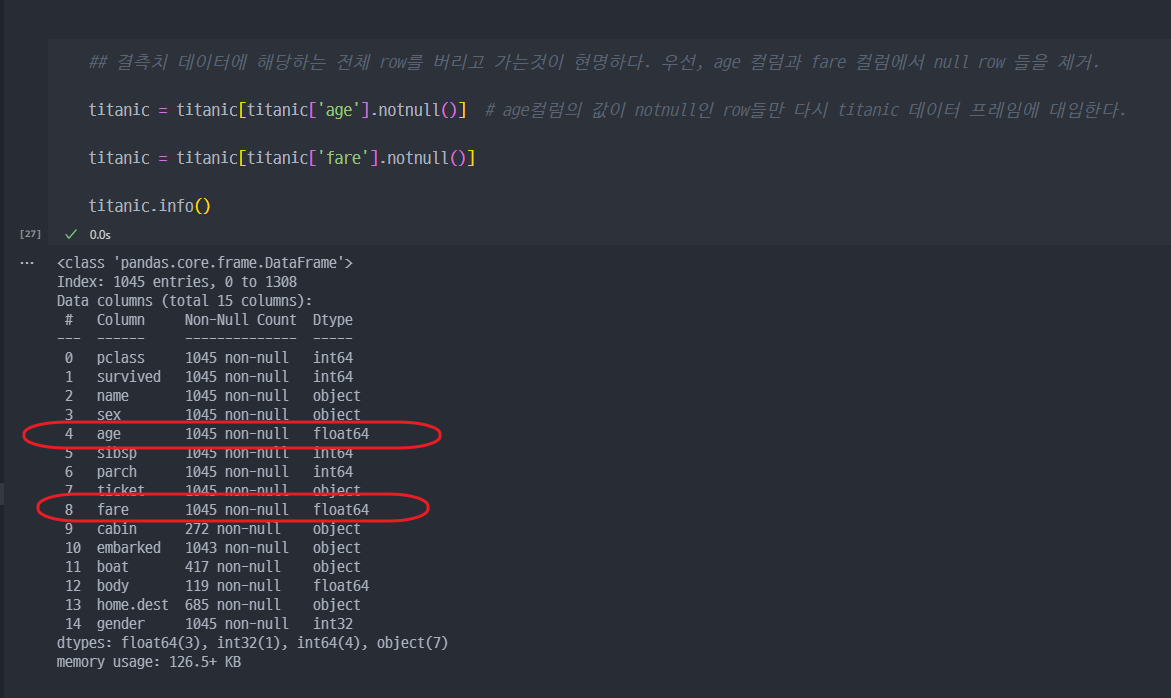
- 'age' 컬럼과 'fare'컬럼에서 결측치 포함된 rows 들 제거하기
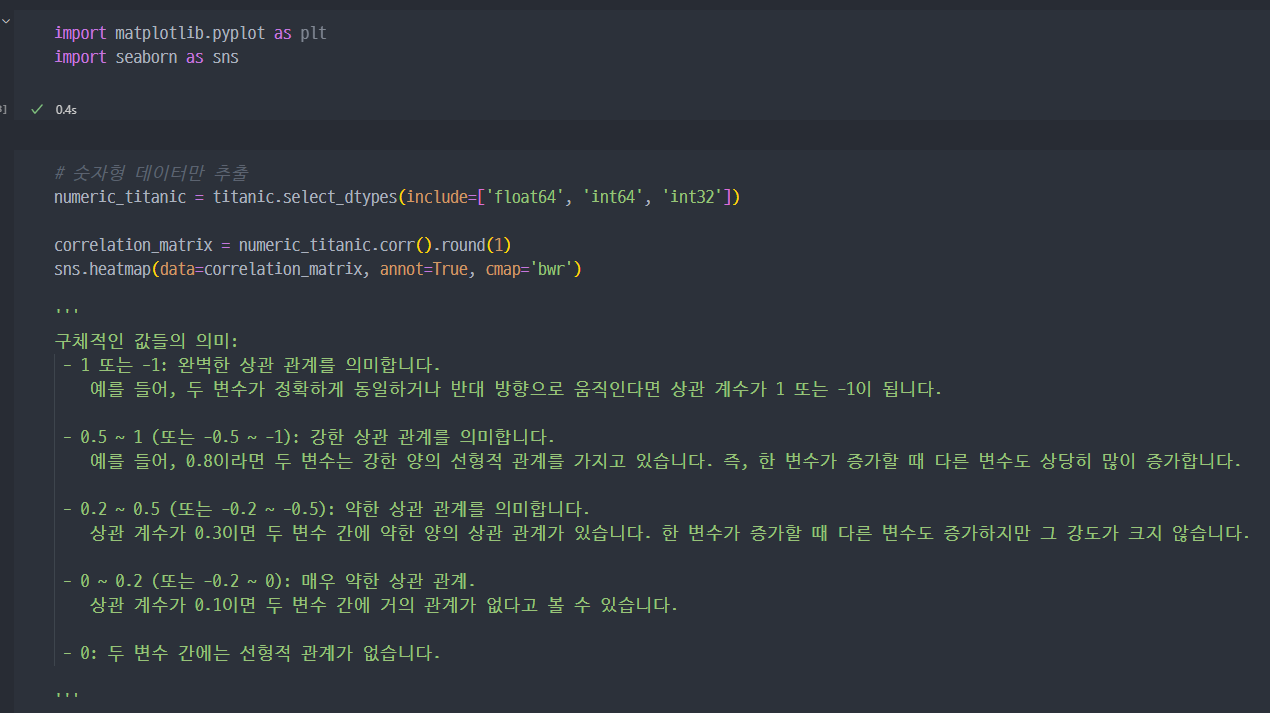
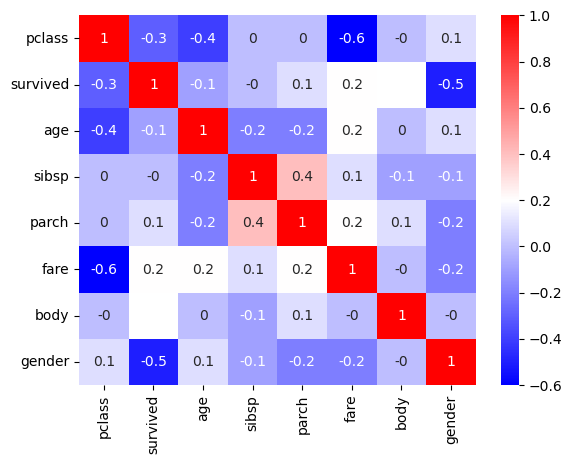
상관관계 확인
ML 적용
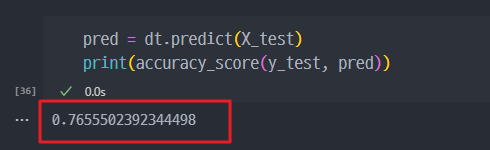
- 디카프리오 데이터를 대입하여 생존률 예측
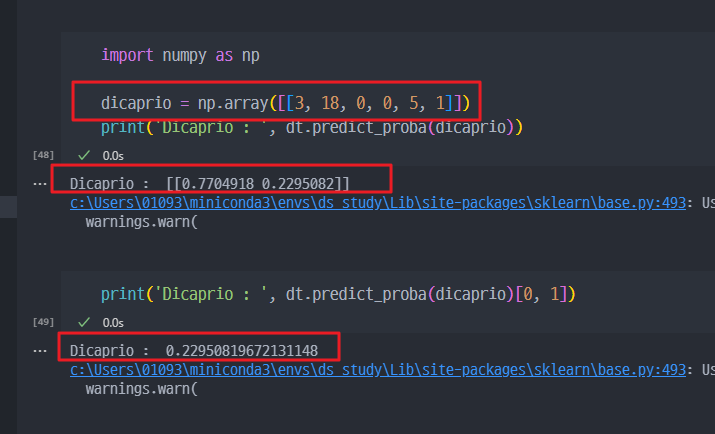
- 하단의 경고가 발생하는 원인은
- 예측 데이터 형식 문제: 예를 들어, 모델을 훈련할 때는 pandas.DataFrame을 사용하고 열 이름이 포함된 데이터프레임을 사용했지만, 예측할 때는 numpy.array와 같은 열 이름이 없는 데이터 구조를 사용할 때 발생할 수 있습니다.

(hellow. world)