label Encoder and scaler(min, max, standard, robust)
sklearn
Label Encoder
- Scikit learn 라이브러리에 포함된 함수
- 어떠한 Data에 '
문자'가 포함된 경우, 이를 일정한 class로 분류하여 각 class에 대해 '숫자'로 변환시키는 함수 - 주로 Machine learning에서는 '문자'는 계산되지 않기에, '문자'를 '숫자'로 변환하는 과정에 많이 사용된다.
- ex) 타이타닉 데이터 → survived = 1, Not Survived = 0 / first class = 0, 2nd = 1, .. 등등
- 사용 예시
1. 예시데이터 생성 (df)
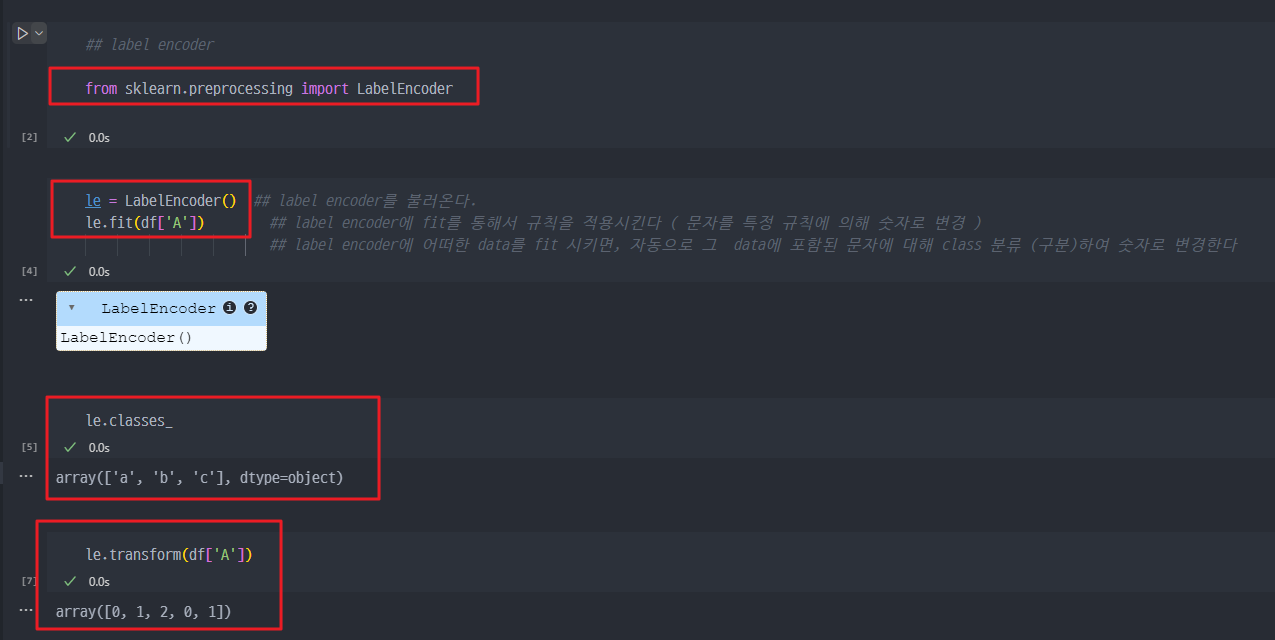
2. sklearn에 있는 labelEncoder 적용 (fit) → df 'A'행의 [a, b, c] 문자가 [0, 1, 2] 로 class분류 및 변경
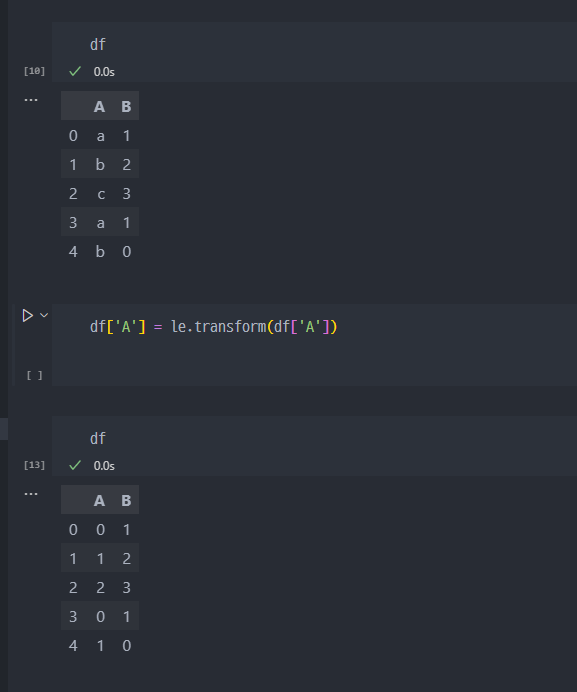
3. '숫자'로 변경 (transform)
4. 참고사항 ( 한번에 fit 과 transform을 하거나 혹은 반대로 '숫자'를 다시 '문자'로 변환하는 것

Scaler
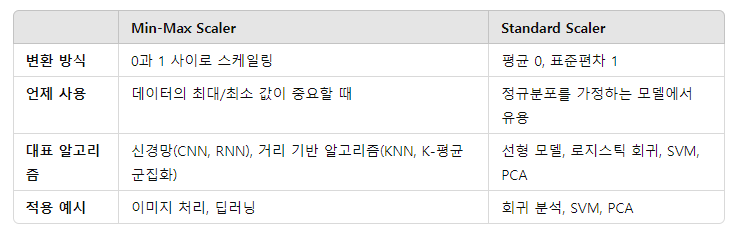
Min-max Scaling
Min-Max Scaling은 데이터 정규화 방법 중 하나로, 데이터의 값을 0과 1 사이로 변환하는 스케일링 기법입니다. 이를 통해 각 피처가 동일한 범위 내에서 나타나게 하여, 머신러닝 모델이 특정 피처에 과도하게 의존하지 않도록 합니다. 공식적으로는 다음과 같이 정의됩니다:
여기서,
- x는 원래의 값,
- min(x)는 해당 피처의 최소값,
- max(x)는 해당 피처의 최대값입니다.
- x′는 스케일링된 값으로, 0과 1 사이에 위치하게 됩니다.
Min-Max Scaling의 의미
- Min-Max Scaling은 각 피처의 최소값을 0, 최대값을 1로 변환하여, 데이터 값들이 동일한 스케일에서 분포하도록 만드는 기법입니다. 이 과정을 통해 모델의 학습이 특정 피처에 치우치지 않게 합니다.
왜 중요한가?
- 많은 머신러닝 알고리즘(특히 거리 기반 알고리즘)은 피처의 크기에 민감합니다. 피처 스케일링이 없는 경우, 값의 범위가 큰 피처가 모델의 성능에 지나치게 큰 영향을 미칠 수 있습니다.
언제 사용되는가?
-
Min-Max Scaling은 다음과 같은 경우에 유용합니다.
-
① 거리를 기반으로 하는 알고리즘
예: K-최근접 이웃(K-NN), SVM, K-평균 군집화와 같은 알고리즘에서 피처의 스케일이 모델 성능에 큰 영향을 미칩니다. 데이터의 범위가 다르면 유클리디안 거리 계산에서 왜곡이 생길 수 있습니다. -
② 신경망(Neural Networks)
신경망은 가중치 업데이트가 활성화 함수(예: 시그모이드, 하이퍼볼릭 탄젠트)를 거쳐 작은 값으로 나오는 경우 학습 속도가 느려질 수 있습니다. 이때 Min-Max Scaling을 적용하면 학습 속도가 향상됩니다. -
③ 이미지가 주로 사용되는 모델
픽셀 값이 0~255 범위로 되어 있을 때, 이를 0과 1 사이로 스케일링하여 계산의 효율성을 높이고 모델의 성능을 개선합니다.
-
1. 간단한 데이터 예시
예를 들어, 주택 가격 예측 문제에서 가격 피처가 10만 ~ 100만 범위에 있다고 가정할 때, 아래와 같이 Min-Max Scaling을 적용합니다:
| 원래 값 | Min-Max Scaling 후 값 |
|---|---|
| 100,000 | 0 |
| 300,000 | 0.25 |
| 500,000 | 0.5 |
| 700,000 | 0.75 |
| 900,000 | 1 |
2. sklearn 사용 예시
from sklearn.preprocessing import MinMaxScaler
# 데이터 예시
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
# MinMaxScaler 생성 (기본은 0 ~ 1 사이로 스케일링)
scaler = MinMaxScaler()
# 데이터 변환
scaled_data = scaler.fit_transform(data)
print(scaled_data)
-
이 코드를 실행하면 data 값들이 0과 1 사이로 변환된 결과가 출력됩니다.
-
정리
Min-Max Scaling은 값의 범위를 0과 1 사이로 맞추어 데이터의 스케일을 조정하는 방법입니다. 이는 특히 거리 기반 알고리즘, 신경망, 그리고 다양한 모델에서 학습 속도와 성능을 향상시키기 위해 사용됩니다.
min-max scaling 실습
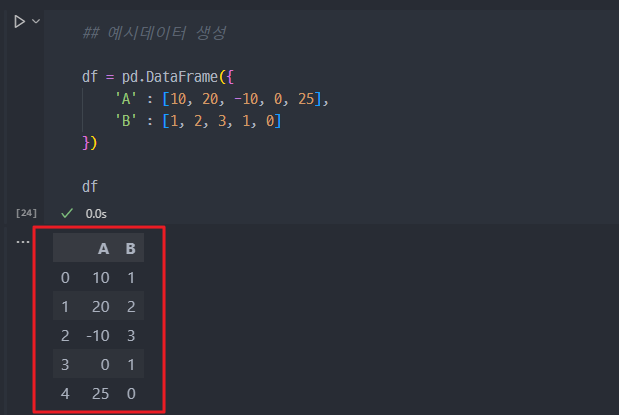
1. 예시 데이터 생성 (df)
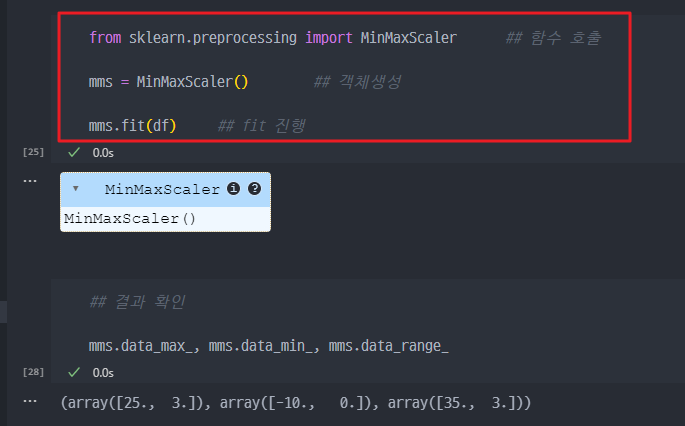
2. 함수호출 및 min-max scaling fit 진행
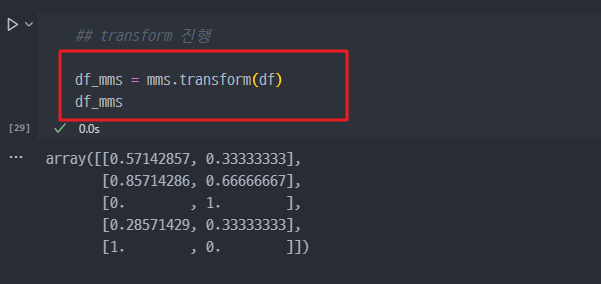
3. transform 진행
- 데이터의 값이 0과 1사이 값으로 스케일 변경
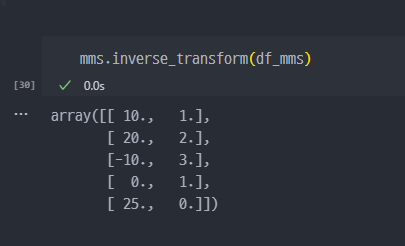
- 참고 (iverse) / fit_transform도 마찬가지로 적용 가능.
Standard Scaler
Standard Scaler는 피처 스케일링의 한 방법으로, 데이터의 평균을 0으로, 표준편차를 1로 변환하는 기법 입니다. 이는 데이터를 정규 분포와 비슷한 분포로 맞추는 데 유용하며, 많은 머신러닝 알고리즘에서 데이터의 범위가 일관되도록 하기 위해 사용됩니다.
- Standard Scaler의 수식
Standard Scaler는 각 데이터 포인트를 다음과 같이 변환합니다:
여기서:
- x는 원래 값,
- μ는 해당 피처의 평균,
- σ는 해당 피처의 표준편차,
- x′는 스케일링된 값입니다.
변환된 데이터는 평균이 0, 표준편차가 1인 데이터가 됩니다.
-
의미
Standard Scaler는 정규화(normalization)와는 달리, 데이터를 0과 1 사이로 맞추는 것이 아니라, 데이터의 분포를 평균이 0이고, 표준편차가 1인 형태로 만듭니다. 이렇게 하면 피처의 크기 차이에 따른 불균형을 없앨 수 있으며, 많은 머신러닝 알고리즘에서 효과적입니다. -
언제 사용되는가?
-
선형 모델 : 선형 회귀, 로지스틱 회귀, 서포트 벡터 머신(SVM) 등은 스케일된 데이터에서 성능이 더 좋아집니다. 특히, L1, L2 규제(regularization)를 사용할 때 Standard Scaler가 중요합니다.
-
PCA(주성분 분석) : PCA는 데이터의 분산을 최대화하기 때문에, 피처가 다른 스케일을 가지고 있으면 PCA가 잘못된 주성분을 찾을 수 있습니다. Standard Scaler로 각 피처를 동일한 분산을 가지도록 맞추면 더 나은 결과를 얻을 수 있습니다.
-
신경망 : 신경망에서는 입력 데이터의 스케일이 클 경우 가중치 업데이트가 불안정해질 수 있습니다. Standard Scaler를 사용하여 입력 피처를 정규화하면 학습이 더 안정적으로 진행됩니다.
-
-
예시
예를 들어, 다음과 같은 데이터를 Standard Scaler로 변환한다고 가정합니다:
| 원래 값 | 평균 | 표준편차 | Standard Scaler 후 |
|---|---|---|---|
| 10 | 20 | 5 | -2 |
| 20 | 20 | 5 | 0 |
| 25 | 20 | 5 | 1 |
-
Min-Max Scaler와 비교
- Min-Max Scaler는 데이터를 0과 1 사이로 변환하는 반면, Standard Scaler는 데이터의 분포를 평균이 0, 표준편차가 1이 되도록 변환합니다.
- Standard Scaler는 정규 분포를 가정하는 모델에서 더 적합하며, Min-Max Scaler는 데이터의 최대/최소값이 중요한 경우 유용합니다.
-
정리
- Standard Scaler는 평균이 0, 표준편차가 1이 되도록 데이터를 변환하여, 모델이 피처의 크기에 덜 민감하게 만드는 스케일링 기법입니다. 이는 선형 모델, PCA, 신경망 등에서 성능을 향상시키기 위해 자주 사용됩니다.
Standard Scaler 실습
1. SS import
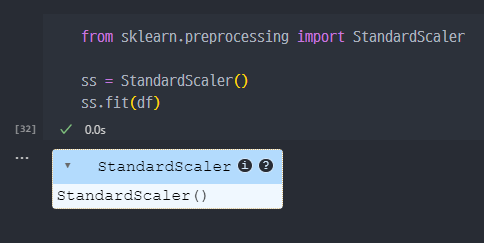
2. df 각 column의 평균(mean), 표준편차(standard deviation or scale) 조회 조회

3. transform
robust scaler
- robust scaler는 평균이 아닌 중앙값 (median)을 0으로 보고 scale을 조정하는 기법이다.
Robust Scaler는 머신러닝에서 데이터 전처리 과정에 사용하는 스케일링 기법 중 하나입니다. 데이터의 중앙값(median)과 IQR(Interquartile Range, 사분위 범위)를 사용하여 데이터를 스케일링합니다. 이상치(outlier)에 민감한 다른 스케일링 기법과 달리, Robust Scaler는 이상치의 영향을 덜 받도록 설계되어 있습니다.
-
Robust Scaler의 작동 방식
-
중앙값(Median) 계산: 먼저 데이터의 중앙값을 계산합니다. 중앙값은 데이터셋을 크기 순으로 정렬했을 때 중간에 위치한 값입니다.
-
IQR(사분위 범위) 계산: IQR은 데이터의 1사분위수(Q1)와 3사분위수(Q3)의 차이로 계산됩니다. Q1은 하위 25%에 해당하는 값이고, Q3은 상위 25%에 해당하는 값입니다. IQR = Q3 - Q1.
-
스케일링: 각 데이터 포인트에서 중앙값을 빼고 IQR로 나눕니다. 즉, 데이터의 각 값에 대해 다음과 같은 공식을 적용합니다
-
이를 통해 데이터가 IQR에 맞춰 스케일링되며, 이상치가 있는 경우에도 그 영향을 최소화할 수 있습니다.
-
Robust Scaler의 장점
이상치에 대한 내성: 중간값과 IQR을 사용하므로 극단적인 이상치의 영향을 거의 받지 않습니다. 이는 특히 비정상적으로 큰 값이나 작은 값이 포함된 데이터에서 유리합니다.
안정적인 스케일링: Robust Scaler는 데이터의 전반적인 분포를 기반으로 하여, 극단적인 값에 덜 민감한 안정적인 스케일링을 제공합니다. -
Robust Scaler 사용 시기
이상치가 있는 데이터: 만약 데이터에 이상치가 많다면, Min-Max Scaler나 Standard Scaler는 이상치의 영향을 크게 받아서 스케일링 결과가 왜곡될 수 있습니다. 이럴 때는 Robust Scaler가 더 적합합니다.
데이터 분포가 비대칭적인 경우: 데이터가 치우쳐 있거나 분포가 균일하지 않을 때도 Robust Scaler를 사용할 수 있습니다.
※ 다른 scaler와 비교
1. Min-Max Scaler
- 정의: 데이터의 최솟값과 최댓값을 기준으로 데이터를 0과 1 사이의 값으로 스케일링합니다.
- 장점: 스케일링 후 데이터가 0과 1 사이에 위치하므로, 모든 데이터가 같은 범위에 있는 경우 유리합니다.
- 단점: 이상치에 매우 민감합니다. 이상치가 있으면 최댓값과 최솟값이 크게 왜곡될 수 있습니다.
2. Standard Scaler
- 정의: 데이터의 평균과 표준편차를 기준으로 정규화하여 데이터가 평균 0, 표준편차 1을 가지도록 스케일링합니다.
- 장점: 정규분포를 따르는 데이터에 효과적입니다. 데이터의 범위나 분포에 상관없이 모든 특성의 중요도를 동일하게 조정할 수 있습니다.
- 단점: 이상치가 있으면 평균과 표준편차가 왜곡되어 스케일링 결과가 틀어질 수 있습니다.
3. Robust Scaler
- 정의: 중앙값과 IQR을 이용해 이상치에 덜 민감한 스케일링을 수행합니다.
- 장점: 이상치의 영향을 최소화할 수 있습니다.
- 단점: 데이터가 정규분포를 따르는 경우 Min-Max Scaler나 Standard Scaler보다 덜 효과적일 수 있습니다.
robust scaler 실습
- 필요 라이브러리 import (Min-max scaler, Standard Scaler, Robust Scaler)
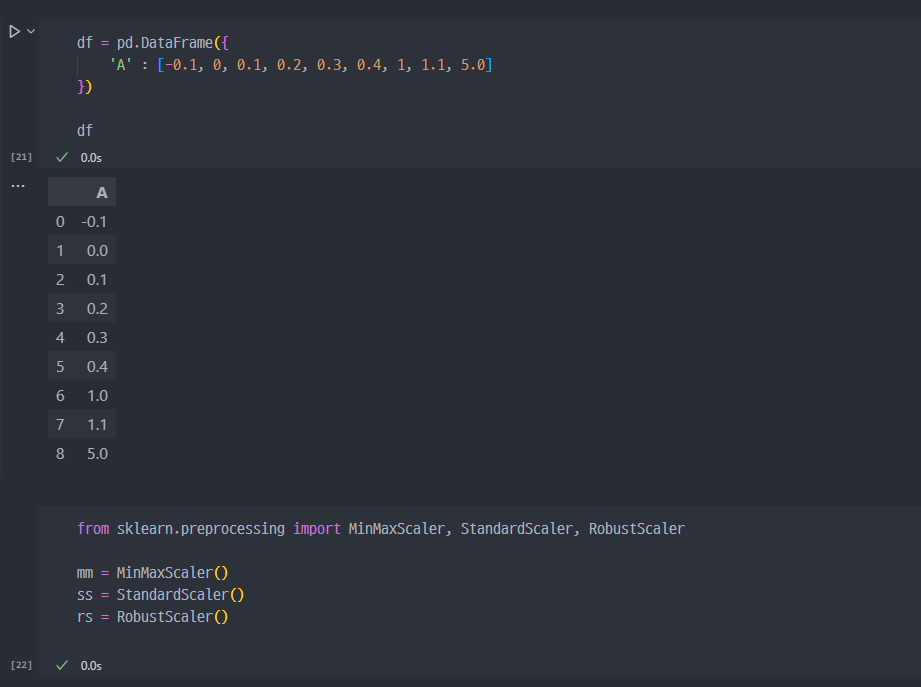
- df에 대하여 mm, ss, rs fit 및 transform
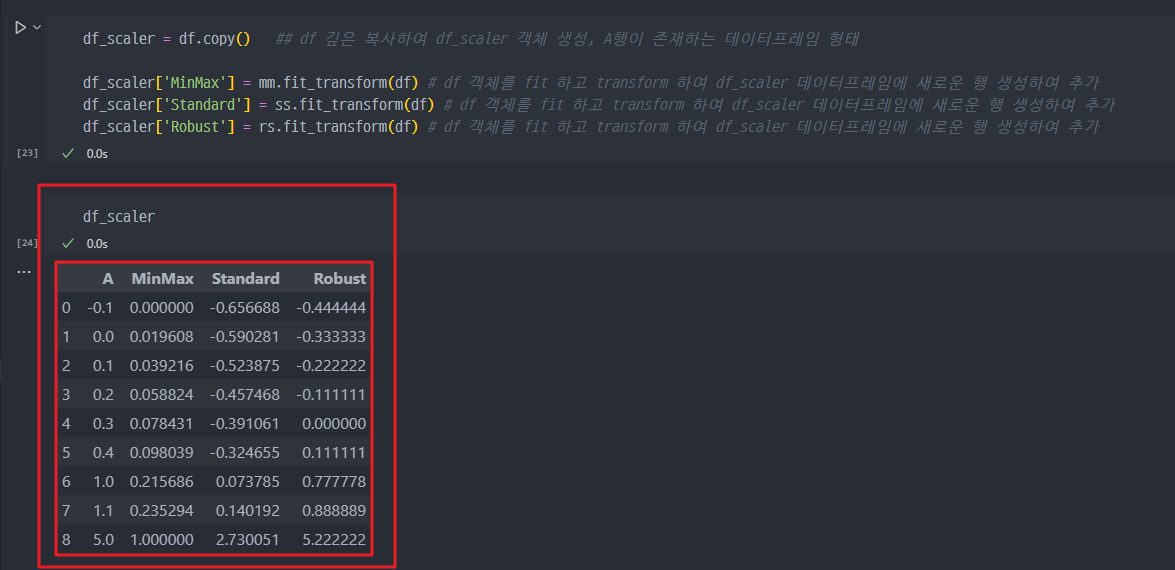
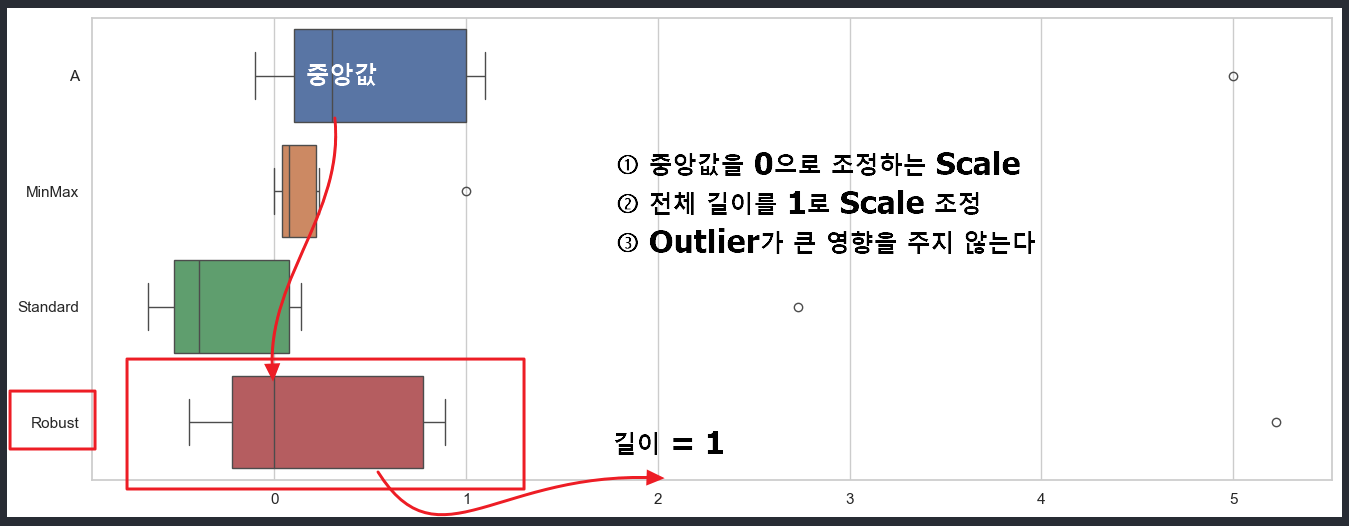
MinMax, Standard, Robust 그래프 표현
- 세가지 방법의 차이점을 알기 위해 그래프 작업 진행
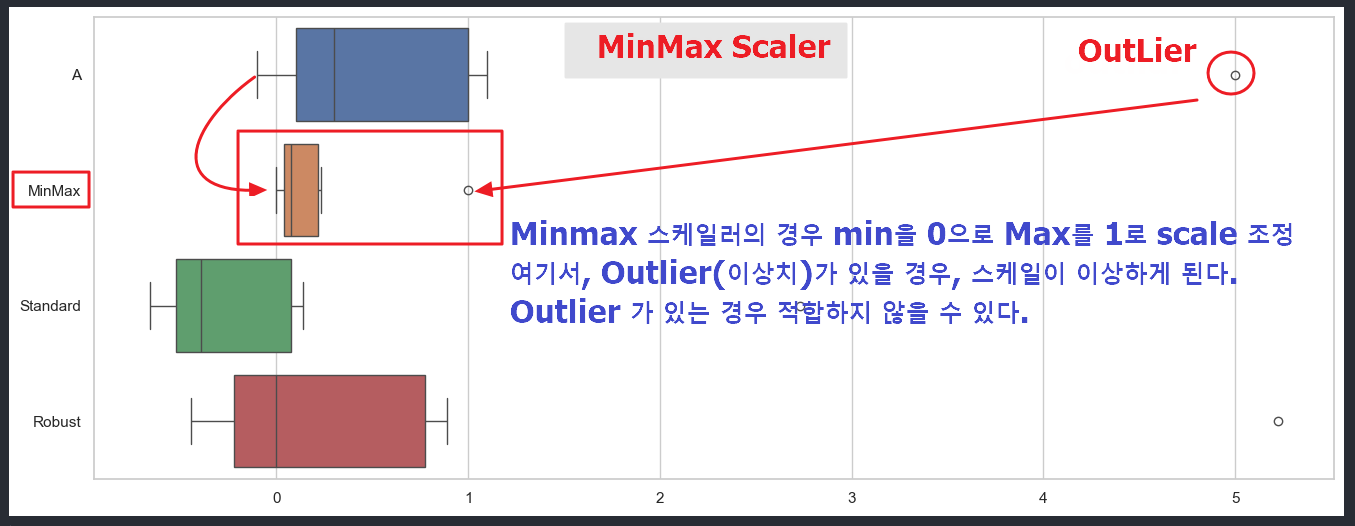
1) Minmax Scaler : Min 값을 0, Max 값을 1로 조정
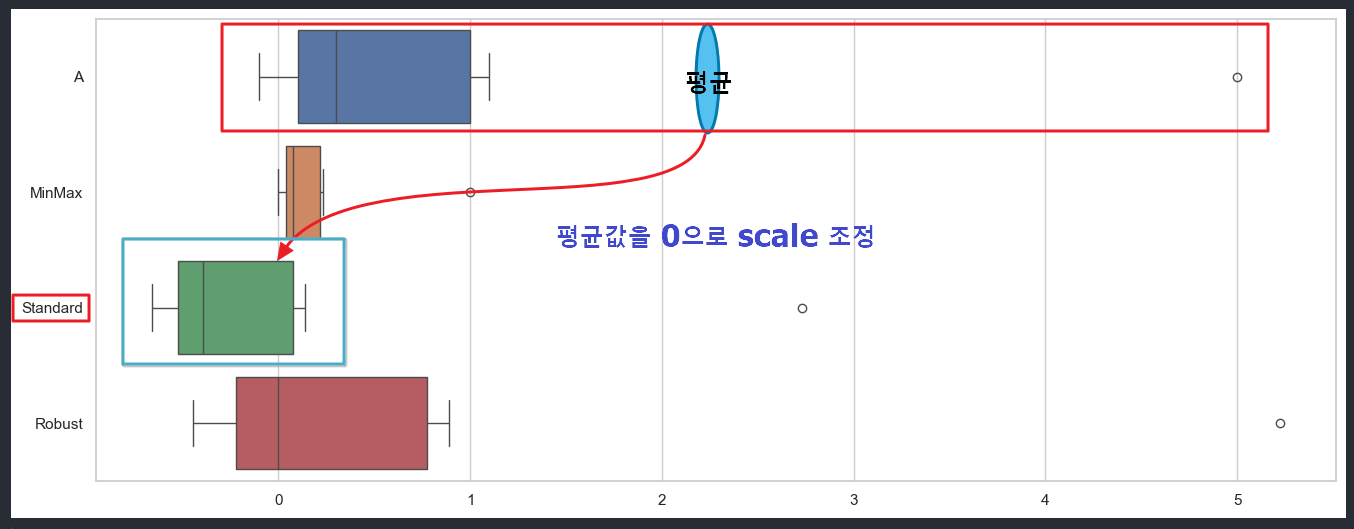
2) Standard Scaler : 평균을 0으로 조정
3) Robust Scaler : median을 0으로 조정