Decision Tree를 이용한 와인 데이터 분석
- UCI라는 홈페이지에 와인 품질 데이터 有
- 또는 github에서 다운가능
데이터 읽어보기
- github 상에 업로드되어 있는 url 정보를 통해서 데이터 불러오기
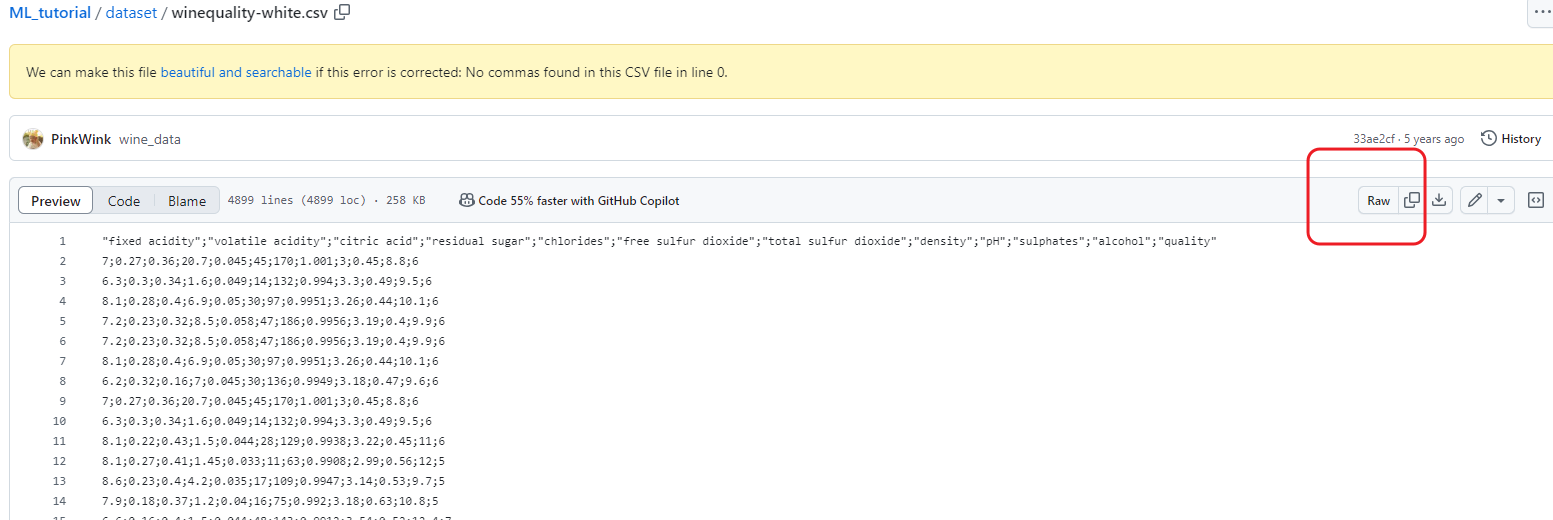
- 위 주소 불러오는 방법 :
github 접속→ 해당 데이터가 있는Repository,directory접속 →raw클릭 후 url 복사
- 동일한 구조의 두가지 데이터 확인

데이터 합치기 (concat)
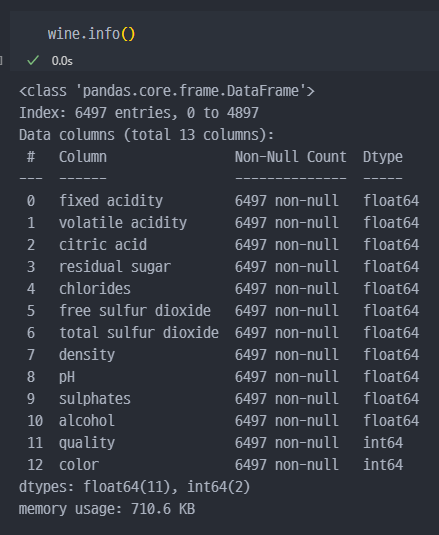
- concat으로 데이터 합치는 경우, 중복은 제거되지 않는다. 또한 행의 구조와 개수가 동일한 경우 사용가능.
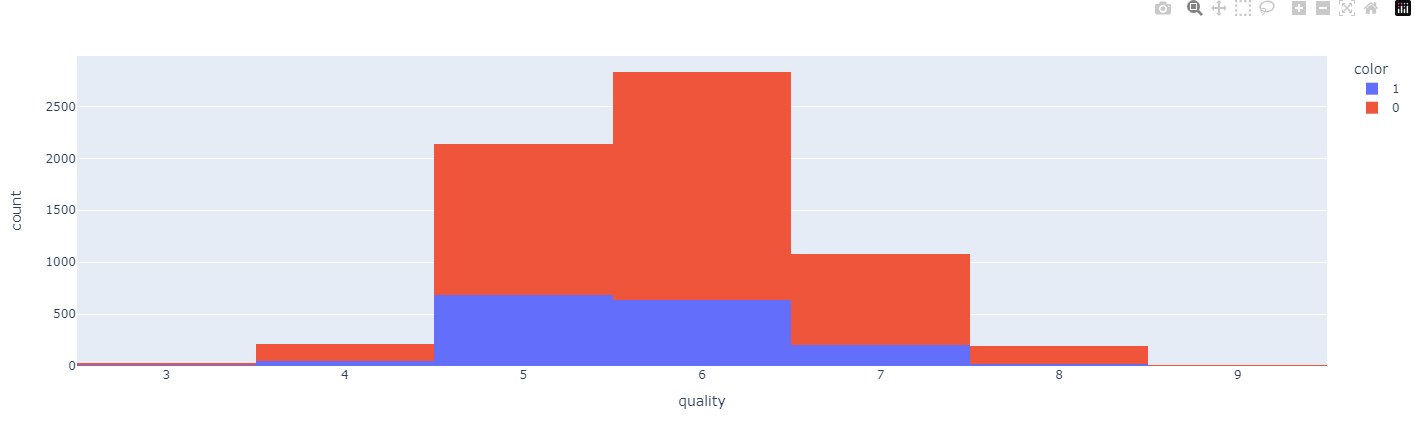
histogram
- 하나로 만든 데이터를 간단한 histogram으로 둘러보기. (plotly.express 사용)
plotly.express: 줌인, 줌아웃, 툴팁 등을 포함한 대화형 기능을 자동으로 제공하므로, 데이터를 직관적으로 분석 가능
train, test 데이터 나누기
- x, y 데이터 생성하여 train 진행.
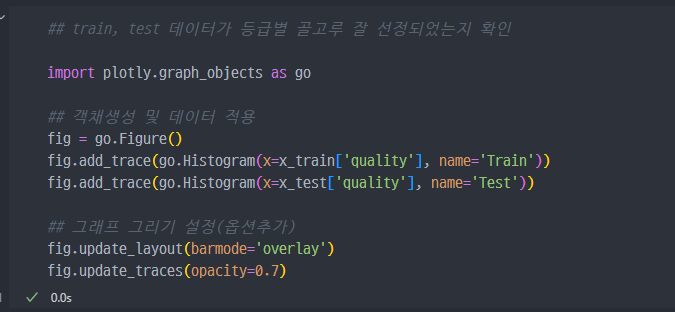
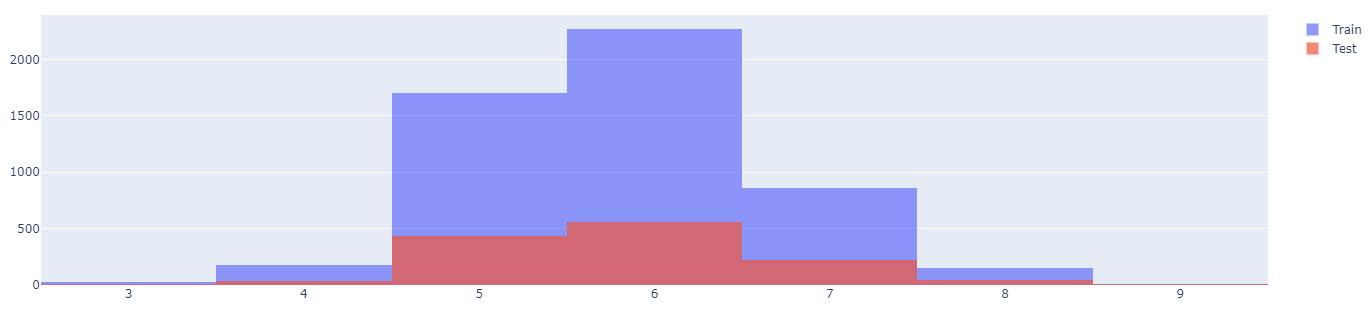
- test와 train 데이터가 와인의 등급별로 골고루 잘 분포되었는지 확인
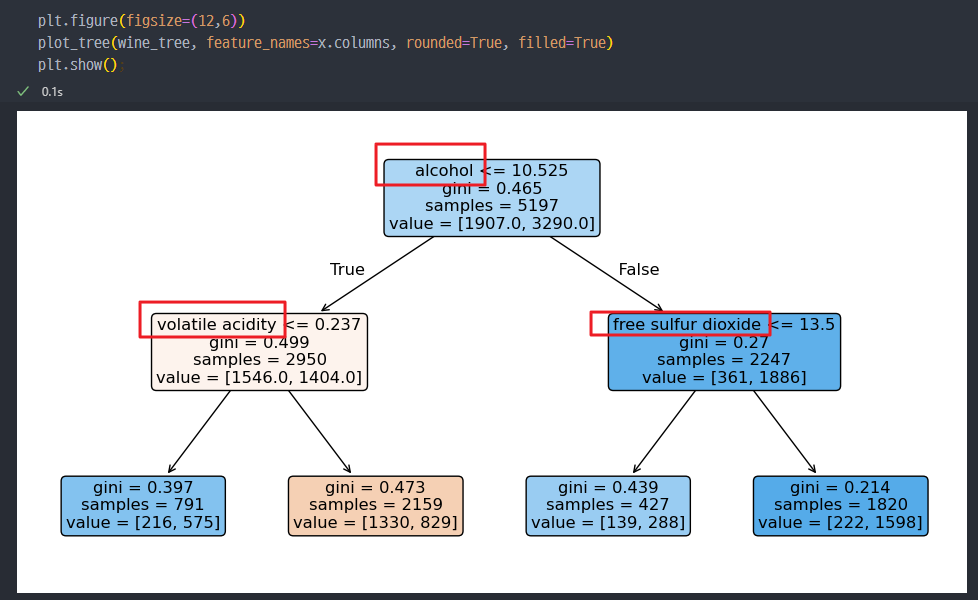
Decision Tree 훈련
- wine_tree 객체 생성하여 fit 진행, 이후 accuracy 확인

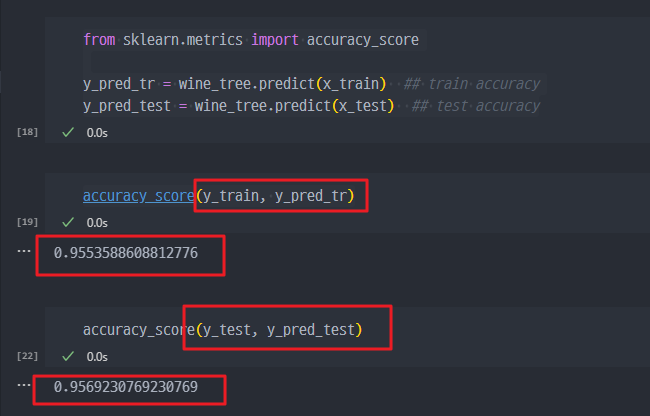
train 데이터의 정답지(y_train)와 test 데이터의 정답지 (y_test)를 활용하여 accuracy 조회
※ 코드에 대한 세부 설명
1. 데이터 준비
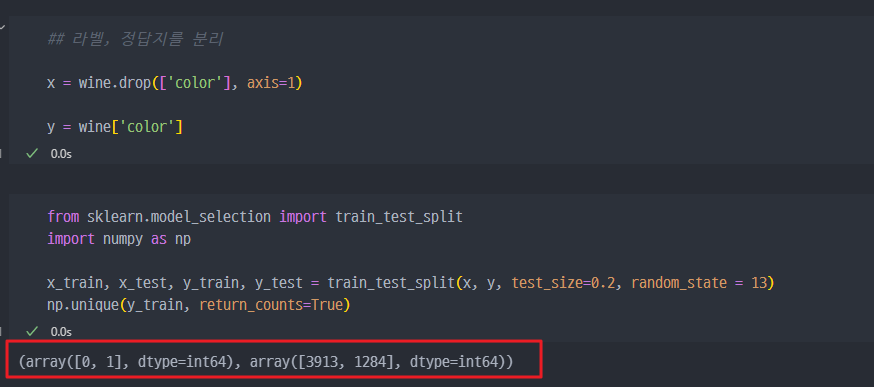
먼저, color 컬럼을 예측해야 하는 타깃(정답) 값(y)으로 설정하고, 나머지 모든 컬럼들을 입력 데이터(x)로 설정합니다.
x = wine.drop(['color'], axis=1) # color 컬럼을 제외한 나머지를 특징(입력값)으로
y = wine['color'] # color 컬럼을 타깃(출력값)으로 설정2. 데이터셋 분리
train_test_split 함수를 사용하여 데이터셋을 학습용(train)과 테스트용(test)으로 나눕니다. 여기서는 데이터의 80%를 학습용으로, 20%를 테스트용으로 나누고, random_state=13을 사용하여 결과가 매번 동일하게 나오도록 합니다.
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=13)이 코드로 다음이 이루어집니다:
x_train, y_train: 학습에 사용할 데이터 (80%)
x_test, y_test: 테스트에 사용할 데이터 (20%)
또한 np.unique(y_train, return_counts=True)는 y_train에서 각 값이 몇 번 나타나는지를 확인하는데, 이는 데이터 분포를 파악하는 데 유용합니다.
3. 결정 트리 모델 생성 및 학습
결정 트리 모델(DecisionTreeClassifier)을 사용하여 학습합니다. 여기서 트리의 최대 깊이를 2로 설정하여 모델이 너무 복잡해지지 않도록 합니다.
from sklearn.tree import DecisionTreeClassifier
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13) # 최대 깊이 2
wine_tree.fit(x_train, y_train) # 모델을 학습 데이터로 학습4. 예측 및 정확도 평가
훈련된 모델을 사용하여 학습 데이터와 테스트 데이터에 대한 예측을 수행한 후, accuracy_score를 이용해 정확도를 계산합니다.
from sklearn.metrics import accuracy_score
y_pred_tr = wine_tree.predict(x_train) # 학습 데이터에 대한 예측
y_pred_test = wine_tree.predict(x_test) # 테스트 데이터에 대한 예측각각의 예측에 대해 정확도를 계산합니다:
accuracy_score(y_train, y_pred_tr) # 학습 데이터에 대한 정확도5. 예측모델의 사용
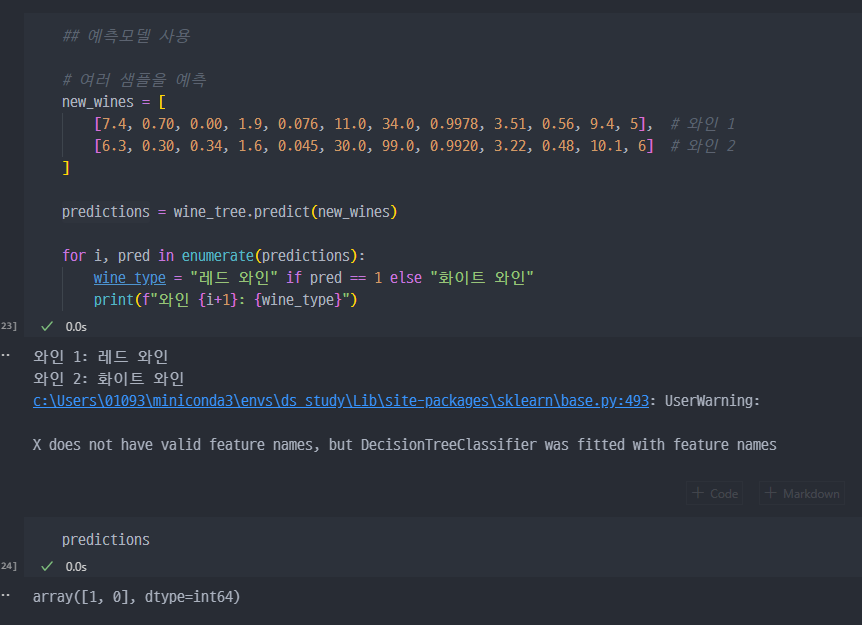
wine 데이터 전처리 (Scaler)
- x 데이터 (
color컬럼이 제거되어 있는 데이터) 몇개의 컬럼에 대한 Boxplot 그리기
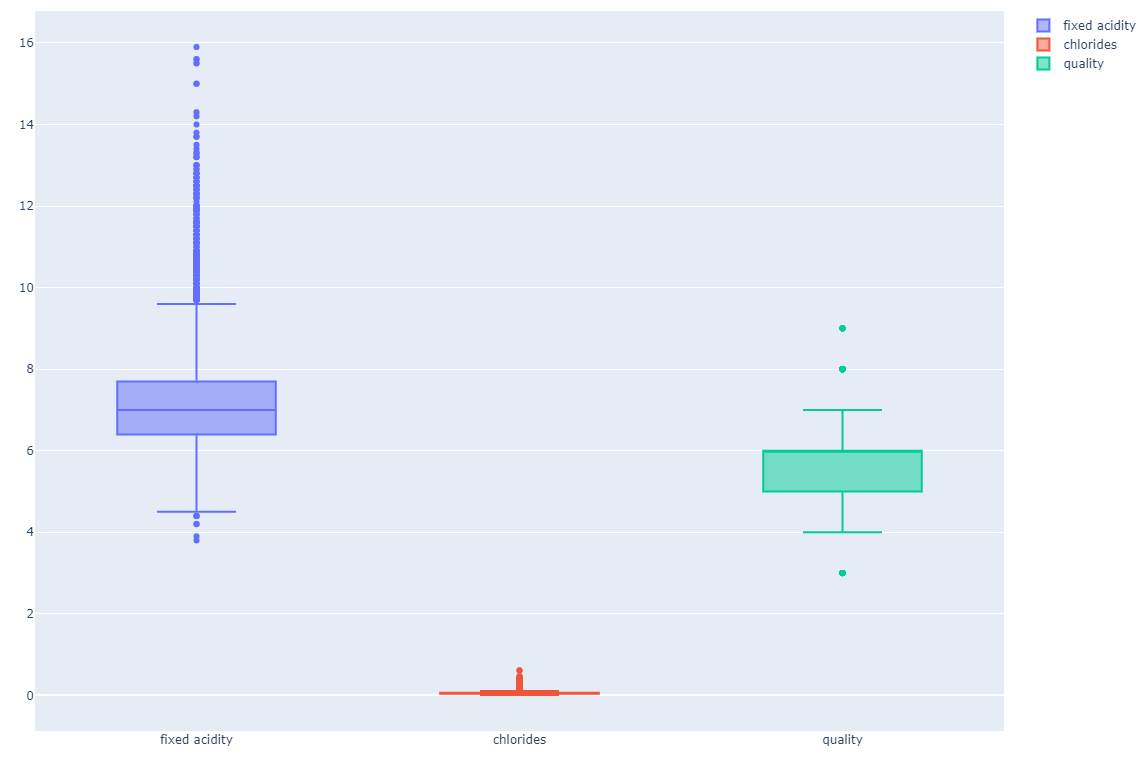
- wine 데이터를 통해서 위 3가지 컬럼이 red 냐 white 냐에 얼마나 큰 의미가 있는지 확인하는 그래프
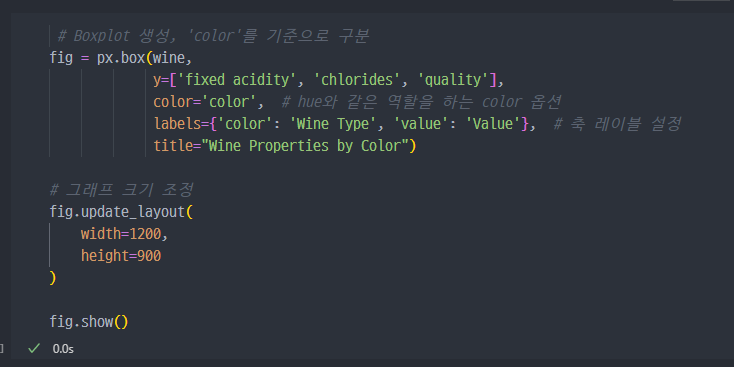
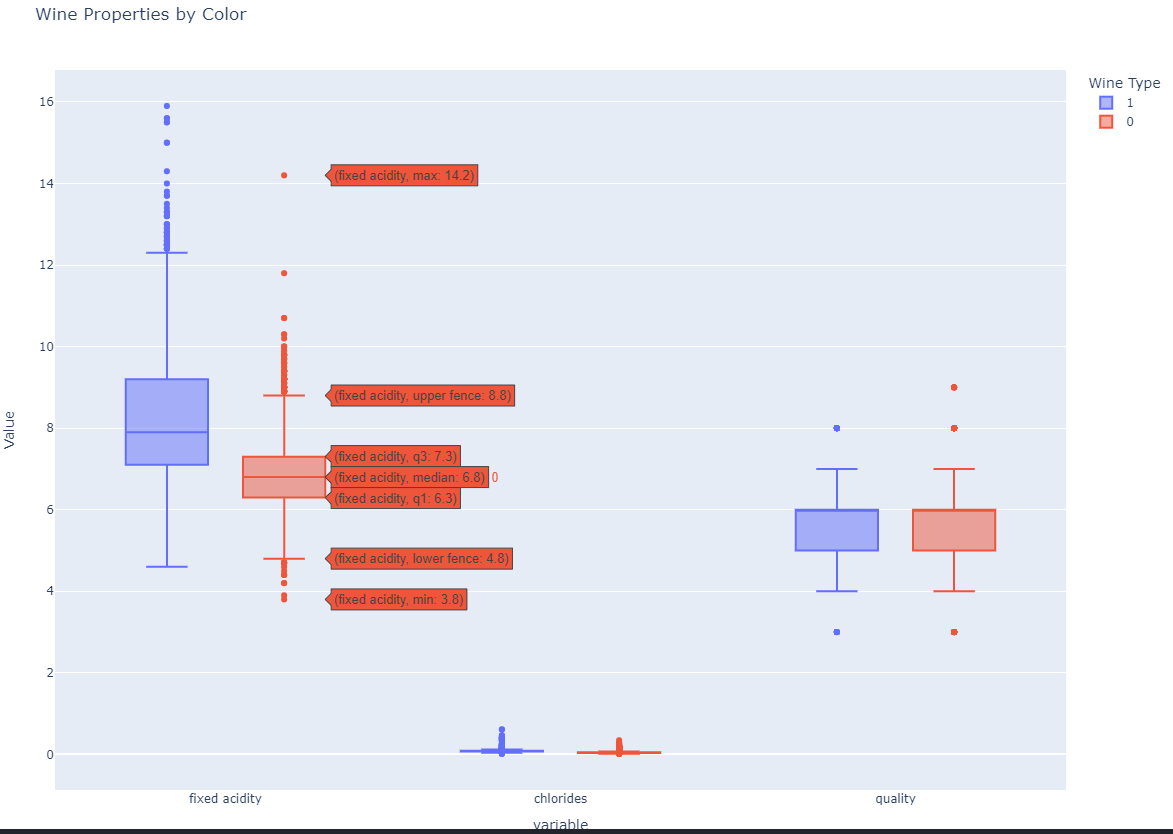
위 3가지 컬럼은.. red wine이냐 white 와인이냐를 구분하는데 큰 영향은 없어 보인다.
- wine 데이터의 모든 행에 대하여 Boxplot을 보았을때,
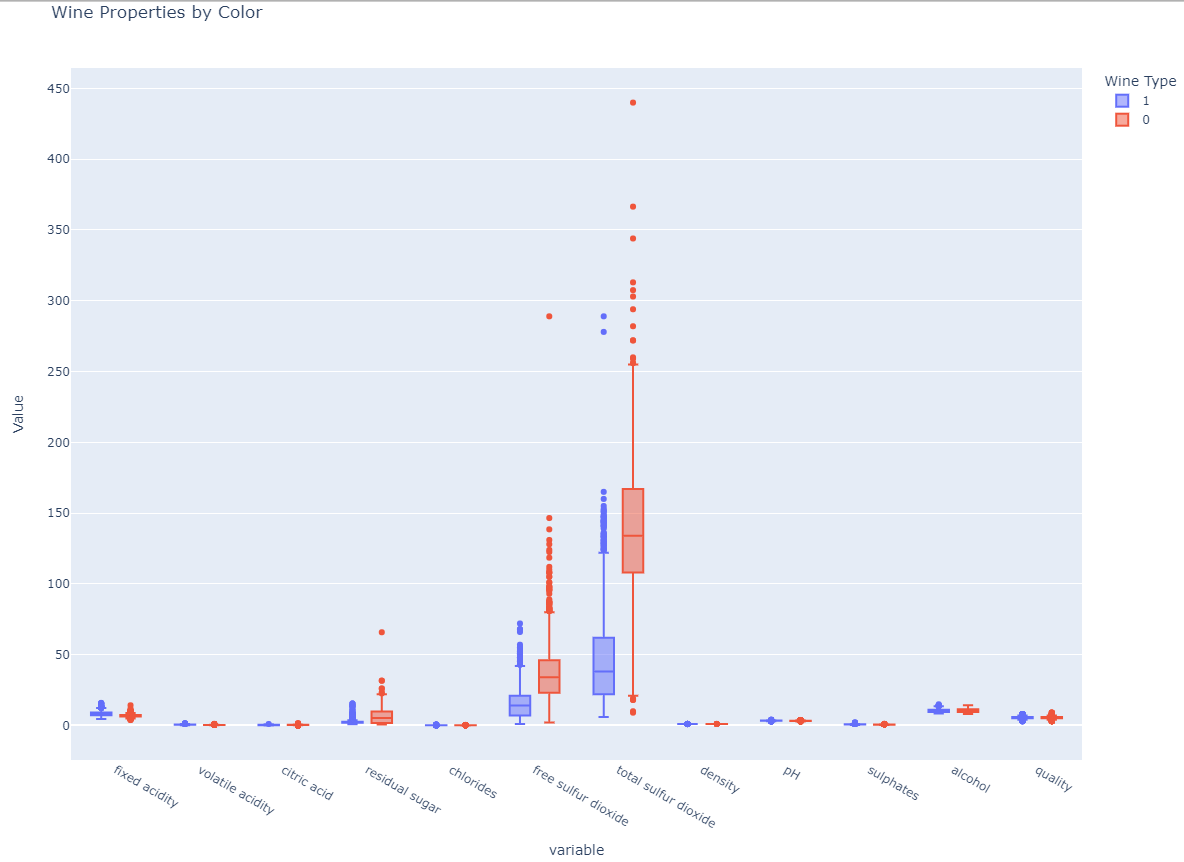
- 중간에
free sulfur dioxide,total sulfur dioxide두 가지 컬럼이 아마 와인의 종류를 구분하는데 크리티컬한 데이터 같다.현재 Scaler 조정 이전 생각.
- 또는 Scaler 조정을 통해서 도드라지지 않는 컬럼을 좀 더 deep 하게 들여볼 수 있을 것.
Scaler 적용 (MinMax, Standard Scaler)
- Minmax Scaler, Standard Scaler 적용
- 기존 그래프 (Scaler 조정 이전)
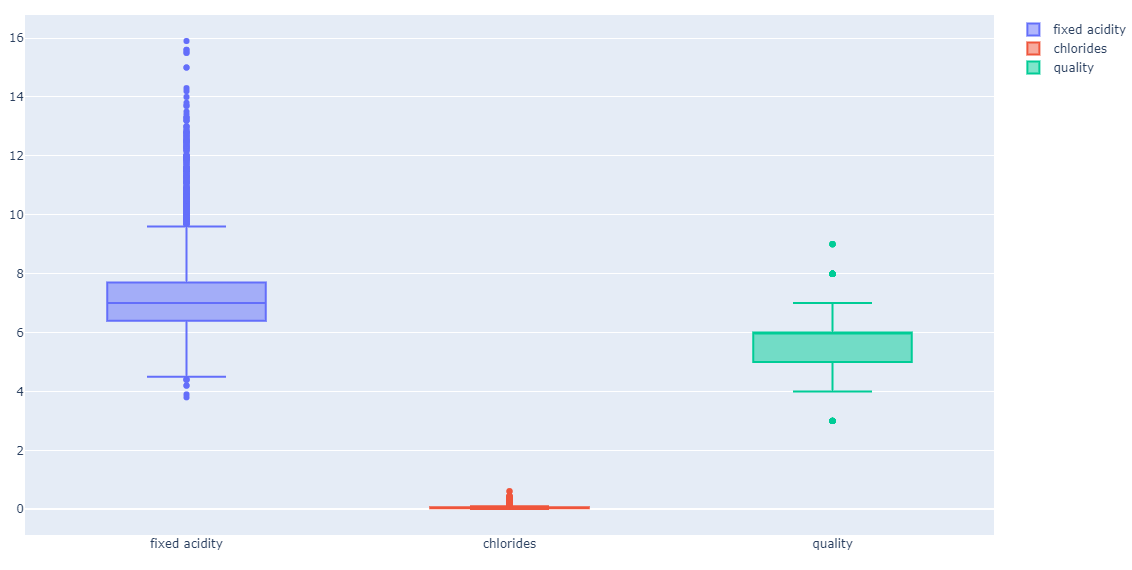
- 각 컬럼들의 최대/최소 범위가 각각 너무 다르고, 평균과 분산이 각각 다르다.
- 특성(feature)의 편향 문제는 최적의 모델을 찾는데 방해가 될 수 있다.
- Minmax Scaler 조정 그래프 ( min = 0으로, Max 값을 1로 조정 (모든 컬럼에 대하여 각각 적용되는 듯))
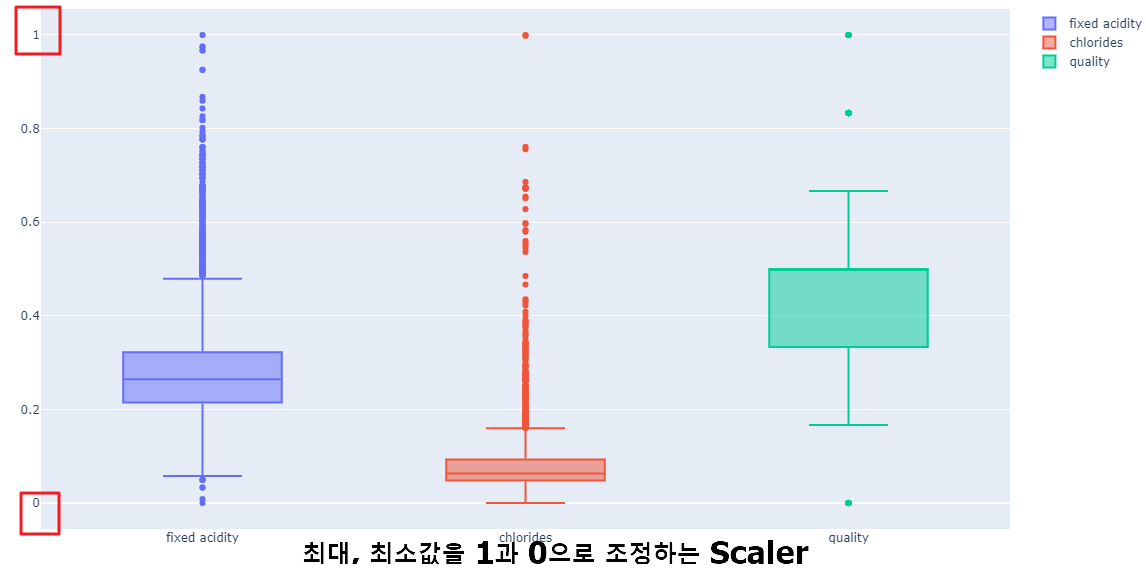
- Standar Scaler 조정 그래프 (평균을 0, 표준편차를 1로 맞추는 것)
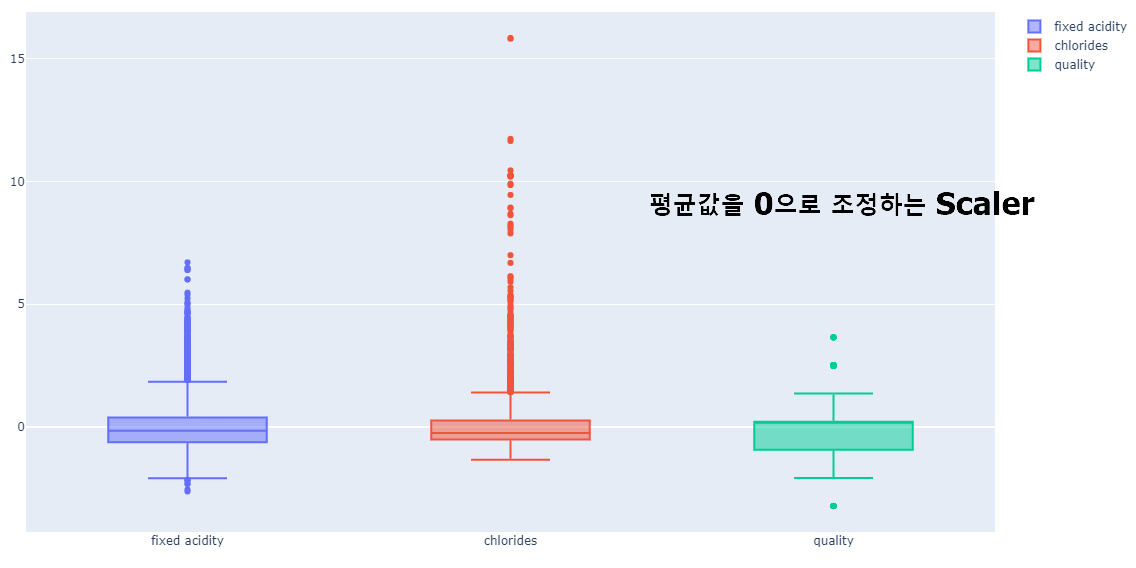
- 다만, Minmax scaler가 좋을지, Standard Scaler가 좋을지는 학습진행해 봐야 할 예상할 수 있을것.
Scaler 적용된 data에 예측모델 적용
- 기존 accuracy와 Scaler 적용 이후 accuracy 비교
기존 accuracy : train -> 0.955 , test -> 0.957

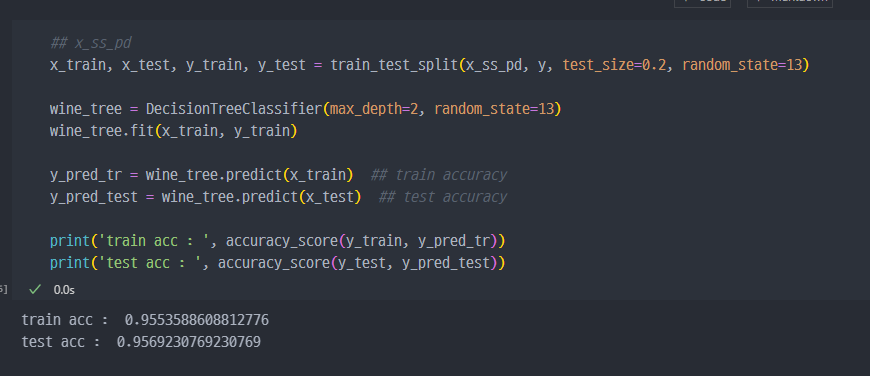
- Minmax Scaler 적용 시, Scaler 이전 데이터와 acc 값에서 큰 차이 없음
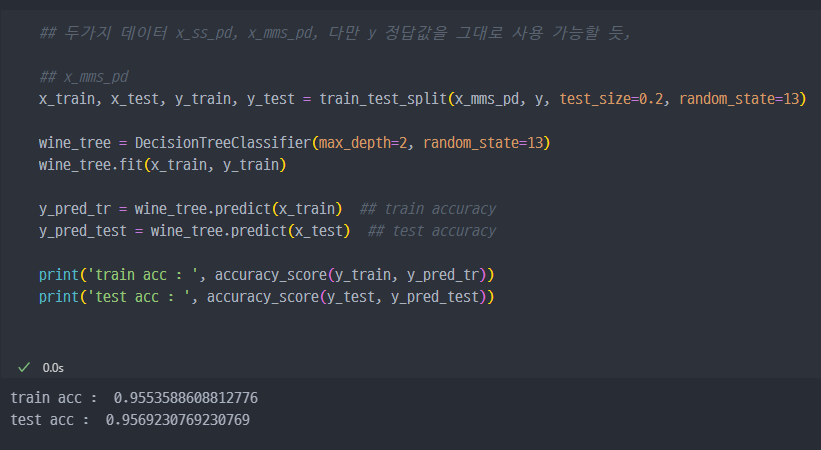
- 강사의 말이긴 하지만, Decision Tree에서는 이런 전처리는 거의 효과가 없다고 함.
- 그래도,, Standard Scaler 까지 진행. 이 경우도 큰 차이 없음.
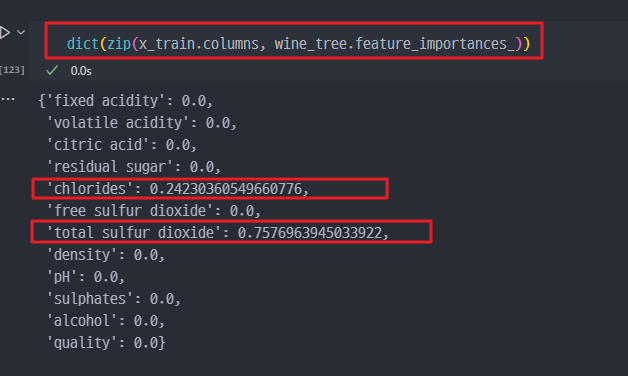
- Decision Tree의 결정요소 확인

- 또는 red ,white 구분하는 중요 특성
이진 분류
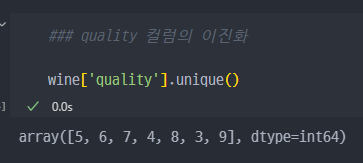
와인 맛에 대한 분류
- quality 컬럼의 이진화, quality 컬럼은 5~9 값으로 존재
- 'taste'라는 새로운 컬럼 만들어서, quality에 따른 값 분류 (0, 1)

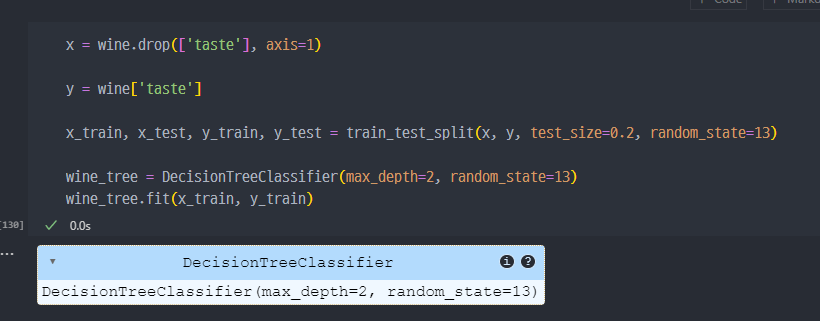
red, white 분류
- taste를 맞추는 예측모델 생성
- acc 조회
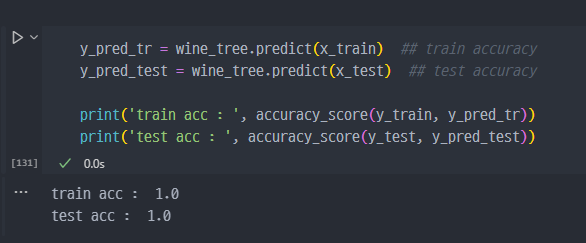
→ 일단, acc 가 100%인 것은 현실적으로 불가능한 치수. 결국 왜 100%가 나왔냐를 생각해야 한다.
→ 아래의 표와 분석을 보면, quality 컬럼이 예측모델의 결정적인 요소이나, 사실 해당 컬럼을 통해서 taste 컬럼을 생성한 것이니, taste 컬럼뿐만 아니라 quality컬럼 역시 삭제 이후, fitted 했어야 하는것이 적합하다.

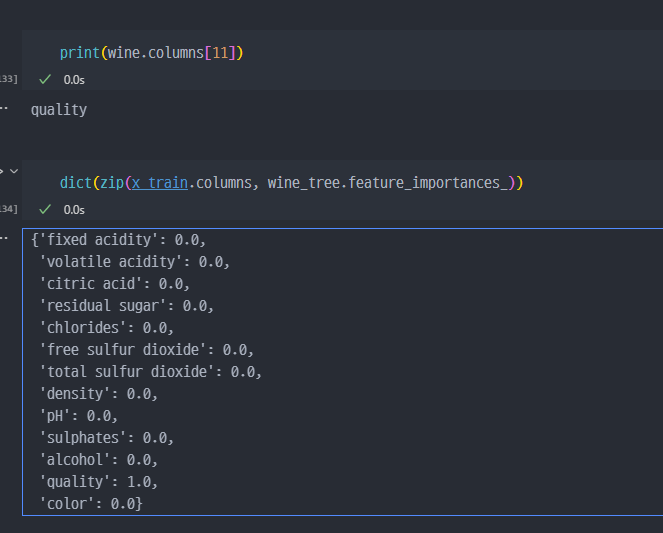
- 따라서, 다시
quality컬럼과taste컬럼 모두 삭제 이후에 예측모델 학습 진행한다.
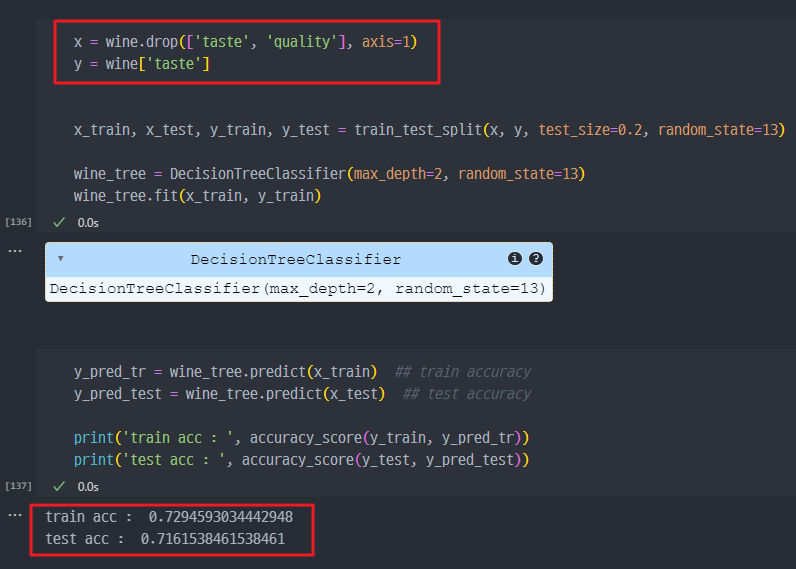
→ 화학성분으로 taste가 좋다, 나쁘다 구분하는 것은 약 70% 수준의 정확성을 보인다.
- taste 예측을 적용하는데, 기여하는 컬럼들.