
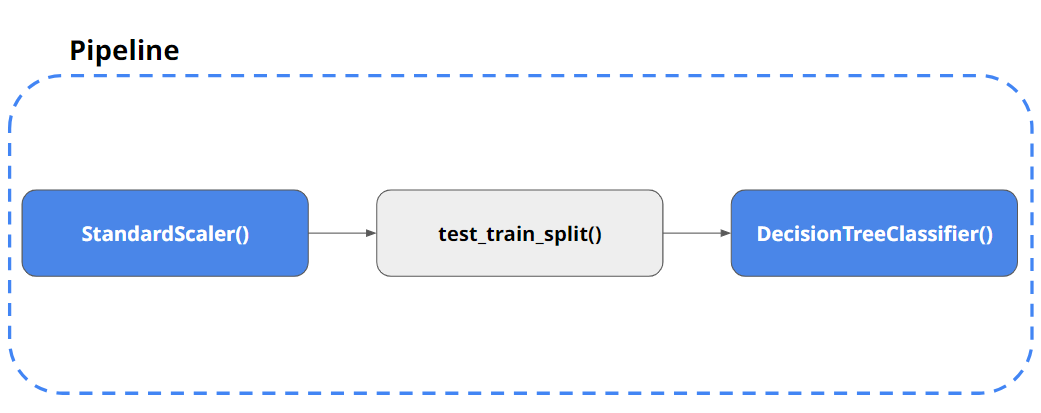
pipeline
Pipeline
- wine 데이터나, Iris 데이터를 통해서 데이터 전처리와 여러 알고리즘 반복실행, 파라미터 튜닝과정을 하다보면 혼돈이 있을 수 있다. 이 때 통상 이를 클래스(class), 함수로 만들어서 진행한다고 생각할 수 있다.
- 하지만 scikit-learn에서는 그럴 필요 없이 준비된 기능이 존재한다. → Pipeline
Pipeline 정의
- ChatGPT가 설명하는
pipeline이란?
Pipeline 은 Scikit-Learn에서 데이터 전처리와 모델 학습을 체계적으로 연결해주는 도구입니다. 데이터 분석과 머신러닝 프로세스는 여러 단계를 포함하는데, 각 단계를 하나하나 실행하면 번거롭고 코드가 복잡해질 수 있습니다. 이때 Pipeline을 사용하면 각 단계를 체계적으로 연결하여 코드의 가독성과 재사용성을 높일 수 있습니다.
- Pipeline의 구성 요소
- 변환기 (Transformers): 데이터를 변환하는 단계입니다. 예를 들어, 데이터 정규화, 결측치 처리, 범주형 변수 인코딩 등이 있습니다.
- 추정기 (Estimator): 모델 학습을 수행하는 단계입니다. 예를 들어, 선형 회귀, 결정 트리, 랜덤 포레스트 등이 있습니다.
- 파라미터 그리드 (Parameter Grid): Pipeline 내에서 여러 단계의 하이퍼파라미터를 조정할 수 있게 도와줍니다.
- Pipeline 사용 예시
아래는 데이터 전처리와 모델 학습을 포함한 간단한 예제입니다.
여기서는 스케일링과 로지스틱 회귀 모델을 포함한 Pipeline을 사용합니다.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# 1. 데이터 로드
data = load_iris()
X = data.data
y = data.target
# 2. 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 3. Pipeline 구성
pipeline = Pipeline([
('scaler', StandardScaler()), # 스케일링 단계
('logistic_regression', LogisticRegression()) # 로지스틱 회귀 모델])
# 4. 모델 학습
pipeline.fit(X_train, y_train)
# 5. 모델 평가
accuracy = pipeline.score(X_test, y_test)
print(f"Test Accuracy: {accuracy:.2f}")- 코드 설명
- 데이터 로드: Iris 데이터셋을 불러옵니다.
- 데이터 분할: 데이터를 훈련 세트와 테스트 세트로 나눕니다.
- Pipeline 구성: 스케일링 단계와 로지스틱 회귀 모델을 포함하는 Pipeline을 정의합니다.
- 모델 학습: fit 메서드를 사용하여 훈련 데이터를 통해 모델을 학습합니다.
- 모델 평가: 테스트 데이터를 사용해 모델의 정확도를 평가합니다.
- 장점
- 가독성: 데이터 처리 및 모델 학습 과정을 한 곳에 모아서 관리할 수 있어 코드가 더 깔끔해집니다.
- 재사용성: 한번 정의한 Pipeline은 다양한 데이터에 쉽게 재사용할 수 있습니다.
- 일관성: 모든 단계를 일관되게 처리하여 실수할 가능성을 줄입니다.
이처럼 Scikit-Learn의 Pipeline 기능을 활용하면 데이터 전처리와 모델링을 간편하게 처리할 수 있습니다. 더 자세한 정보는 Scikit-Learn 공식 문서에서 확인할 수 있습니다.
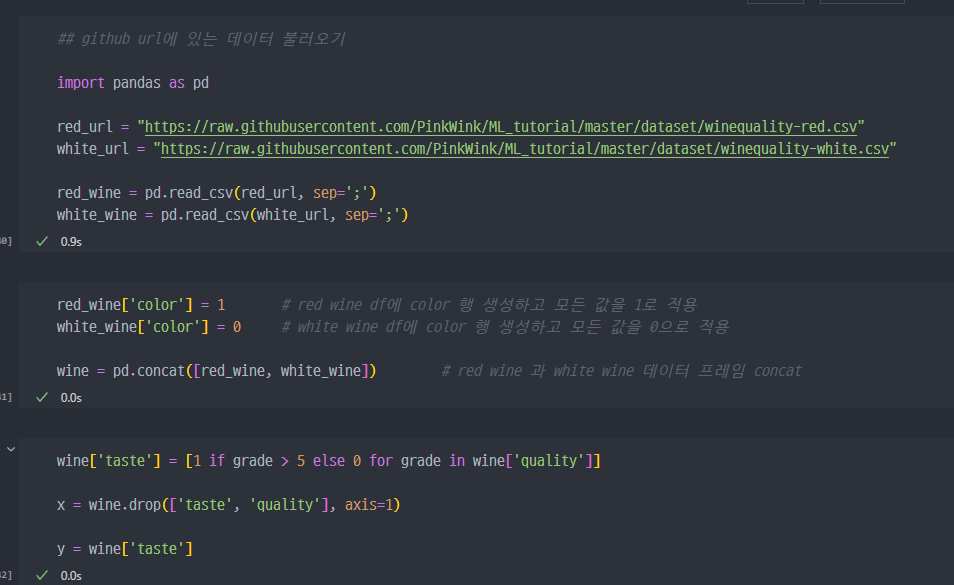
wine data에 pipeline 적용
- 와인 데이터 불러오고 데이터 셋팅 진행

- red/white wine Decision Tree action Process
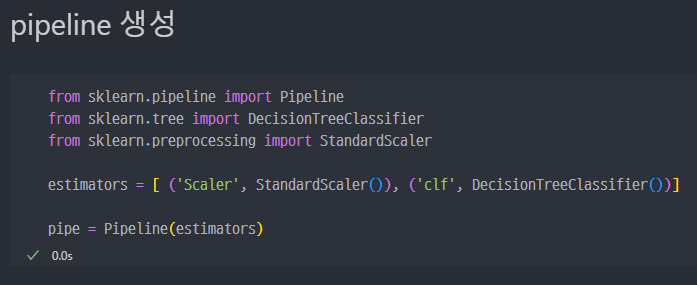
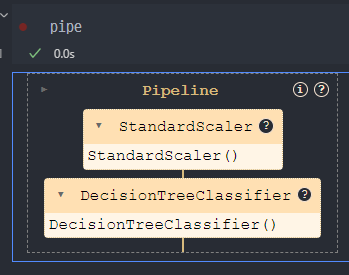
- pipeline의 구성된 steps 조회

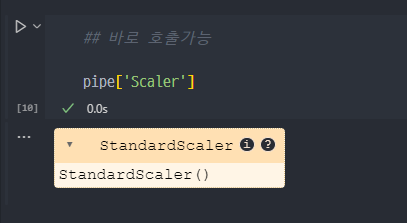
- set Params : step 이름 ( clf ) + 언더바 두개 _ _ + 속성 이름
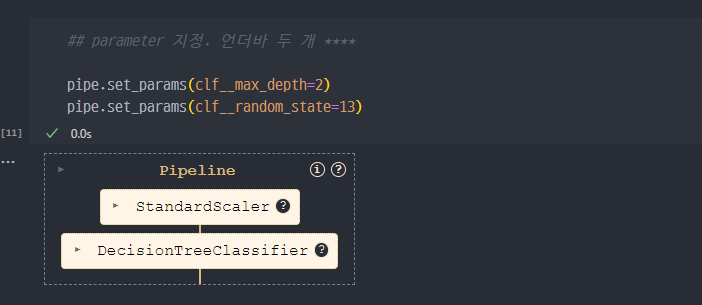
분류기 (clf) 생성
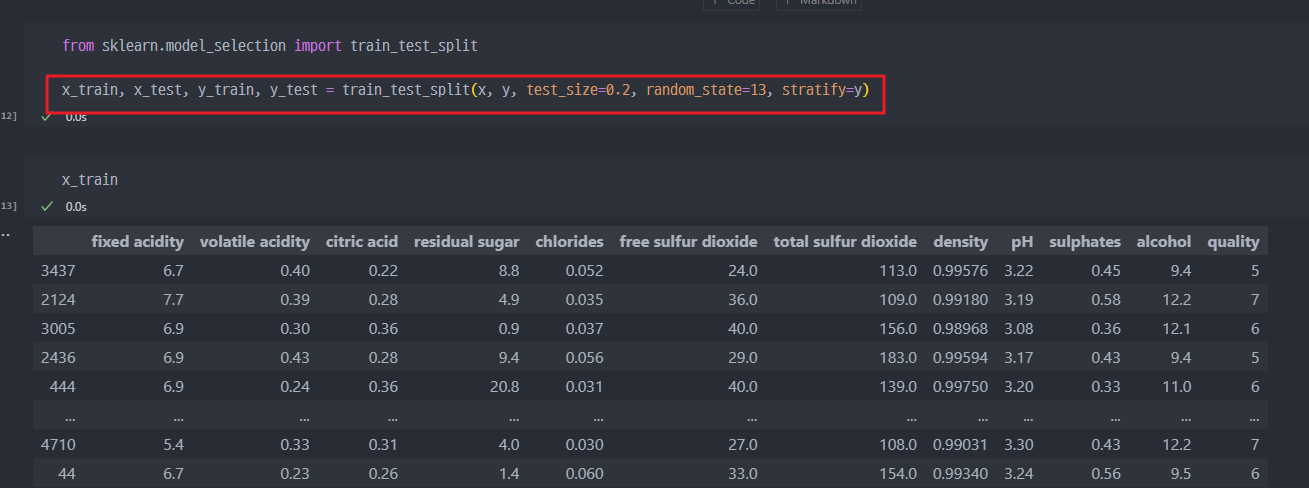
- 학습할 데이터 정리 및 생성
- Scaler 과정과 더불어, 아래의 과정이 pipeline을 통해서 생략
생략과정1)

생략과정2)
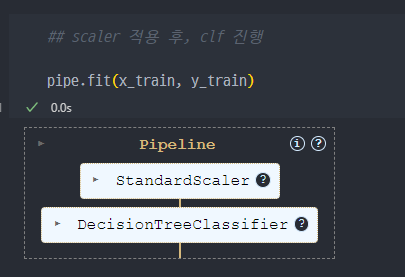
- pipeline 적용
- acc 확인
교차검증 & 하이퍼파라미터 튜닝
교차검증
- 이전에 나왔던 개념을 다시 살펴보면,
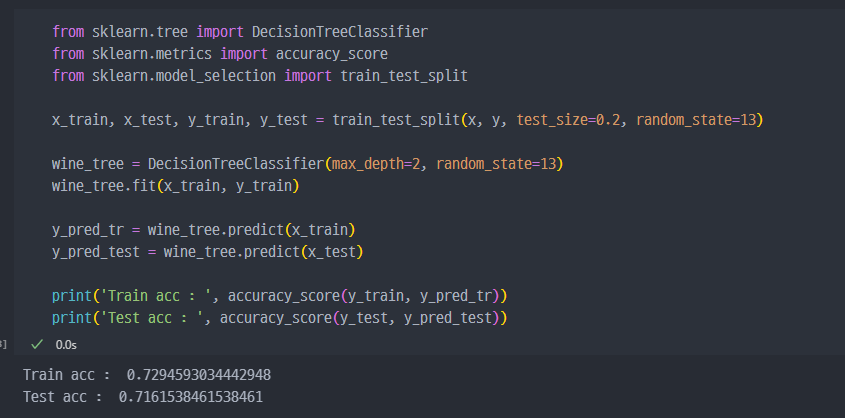
- 과적합 : 모델이 학습 데이터에만 과도하게 최적화된 현상. 그로 인해 일반화된 데이터에서는
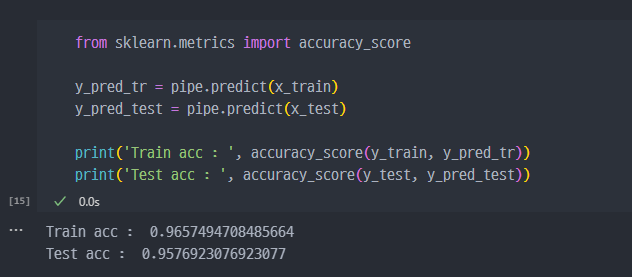
예측성능이 과하게 떨어지는 현상. - 지난번 wine data의 맛 평가에서 훈련용 데이터의 Accuracy는 72%, Test 데이터는 Acc가 71% 였는데, 이게 정말 괜찮은가?
결국 교차검증 이란 데이터에 적용한 예측모델 의 성능을 정확히 표현하기 위해서 유용한 기능이다.
- 기존에 Train data와 Test데이터를 통해서 Accuracy를 검증했던 방법. → holdout 방법

- 기존과 다른 k-fold cross Validation(검증) → 각각의 Validation에서 나온 Acc의 평균을 전체 Acc로 본다.
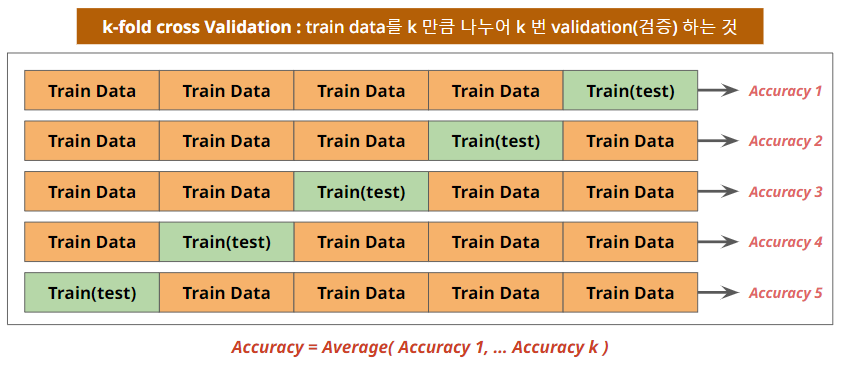
- 전체 진행 프로세스는 아래와 같다.

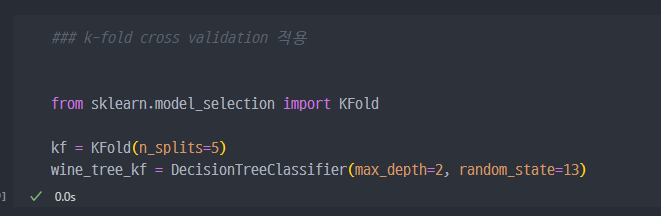
교차검증 구현하기
- 필요한 라이브러리 Import 및 샘플데이터 생성 (array )
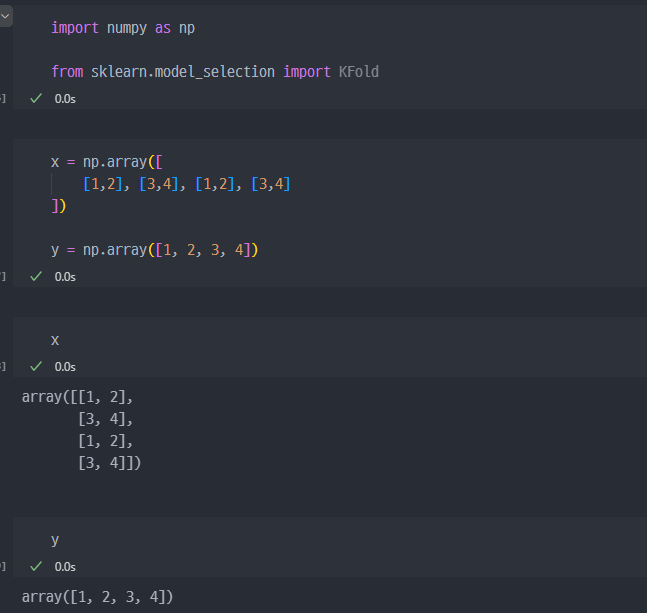
- 데이터를 splits = 2로 분할, 즉 k-fold에서 k = 2
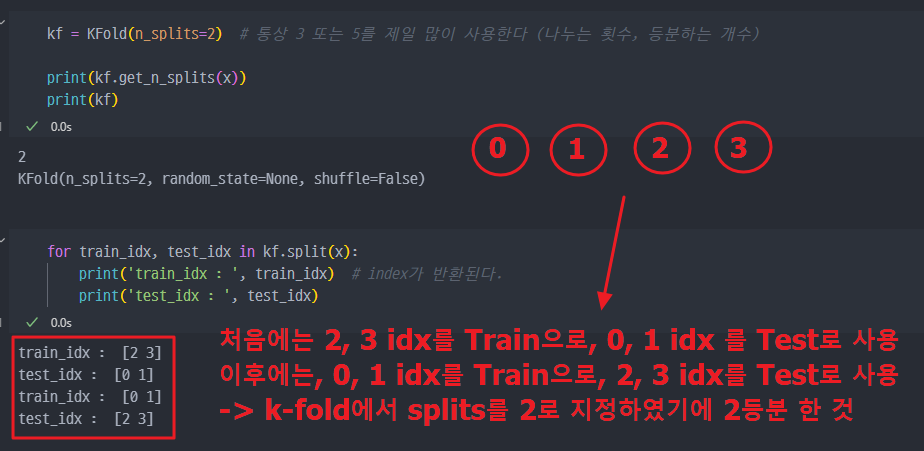
- 세부적으로 다시 출력해보면,
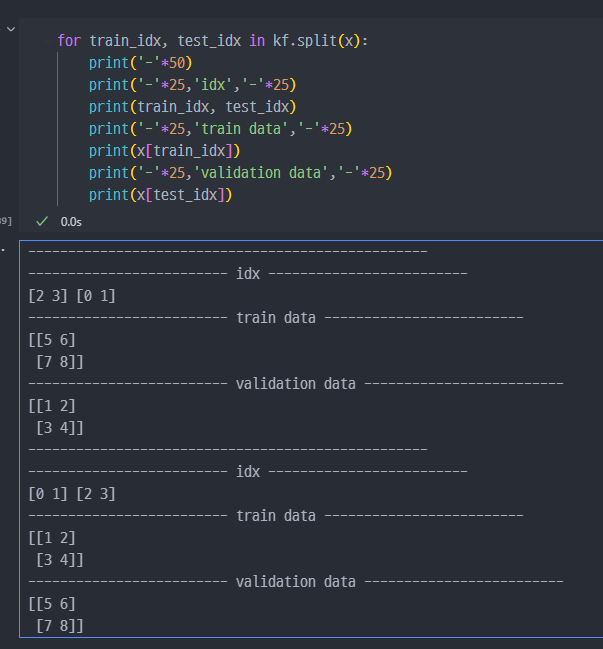
wine data에 적용
- 데이터 불러오기 및 분할
- 기존 진행한 과정 (holdout 방법)
- 그럼, k-fold cross validation 방법으로 진행하면 ?
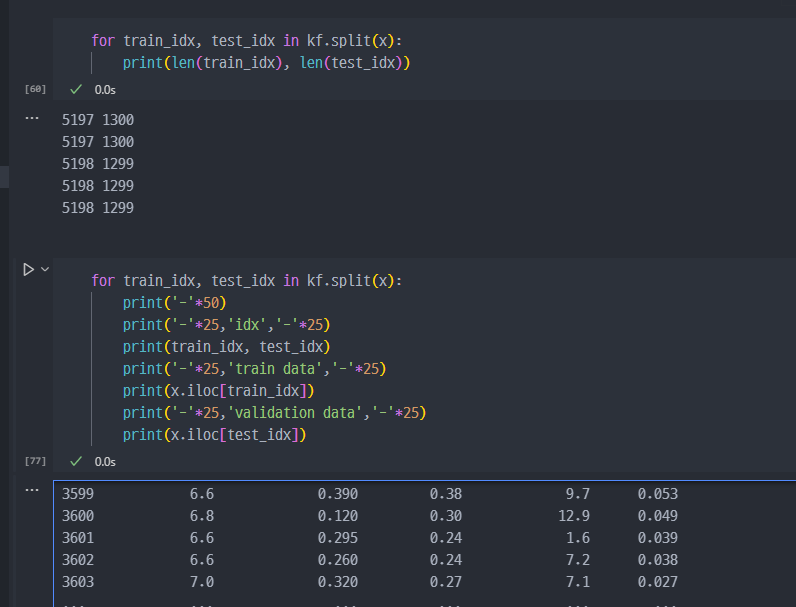
k-fold 에서 k 는 통상 3, 5를 주로 사용하며, 현재 5 적용. 아직 진행된 건 아닌상황
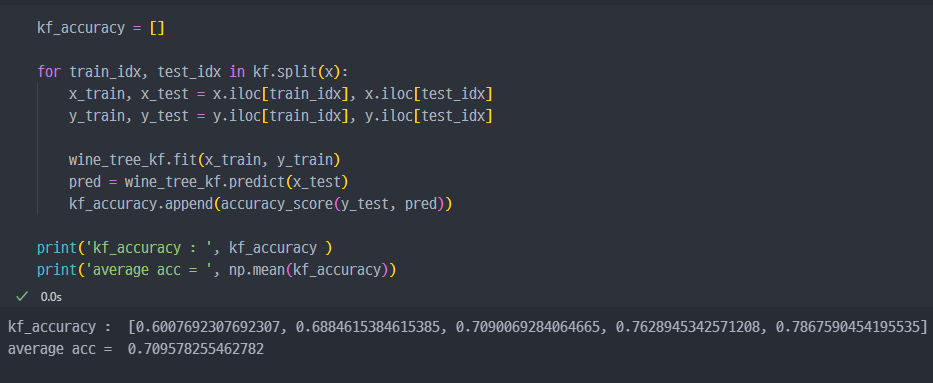
- 학습 진행
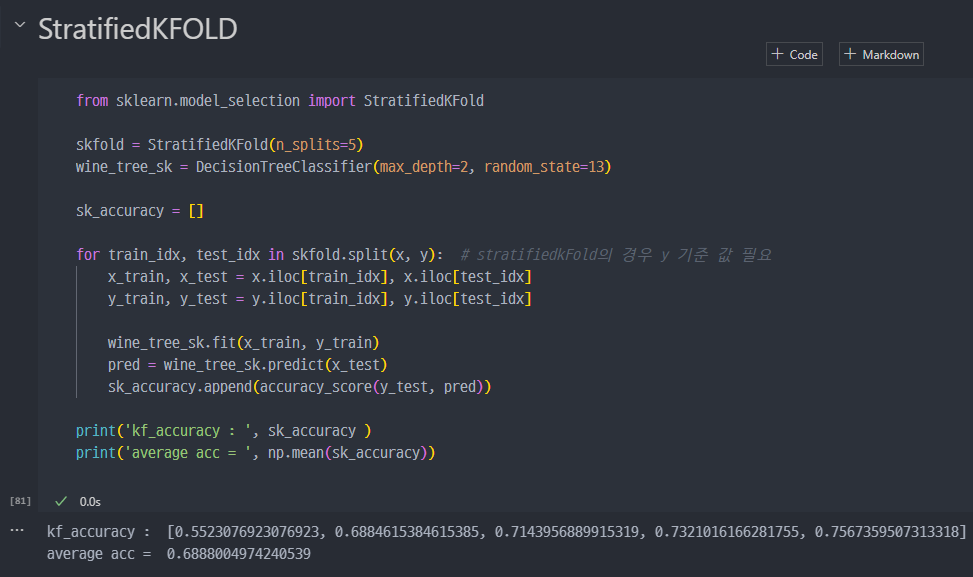
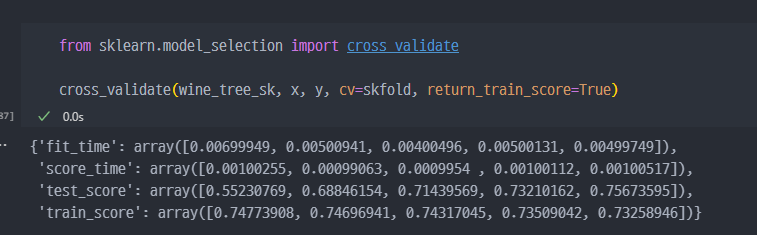
- 참고 (Stratified kFold, cross_val_sscore)
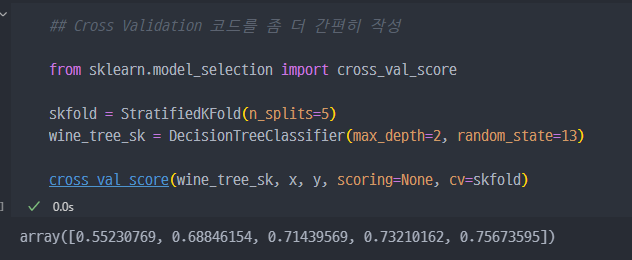
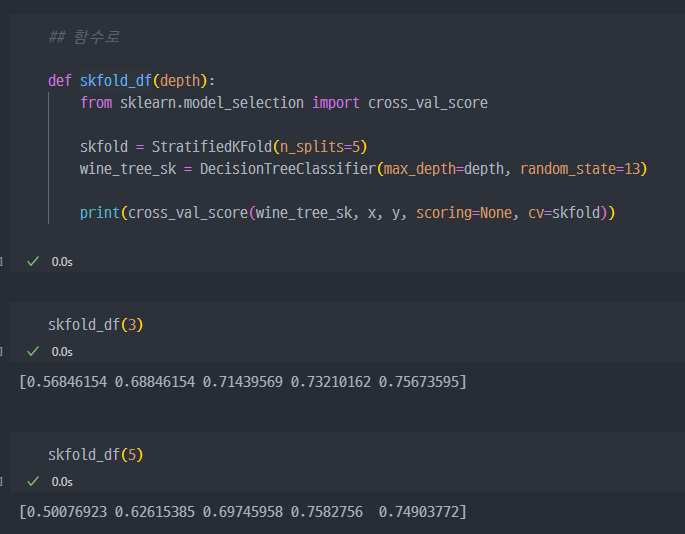
- 참고 : train, test validation data 조회
하이퍼파라미터 튜닝
- (예측)모델의 성능을 확보하기 위해 조절하는 설정 값
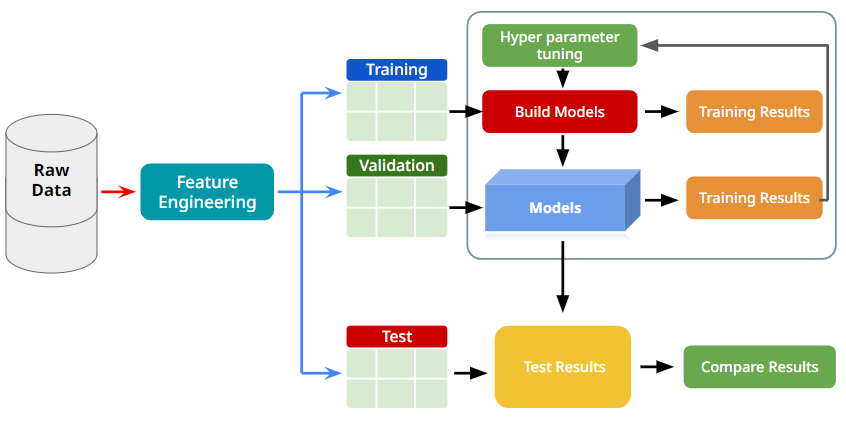
- Feature Engineering : 특성을 관찰하고 변경하는 과정.
- Test Data 는 모델이 완성 된 후 사용
- Hyper Parameter : 일일이 수정해야 하는 파라미터. max_depth 등이 있다.
- Max_depth 튜닝, GridSearchCV 적용
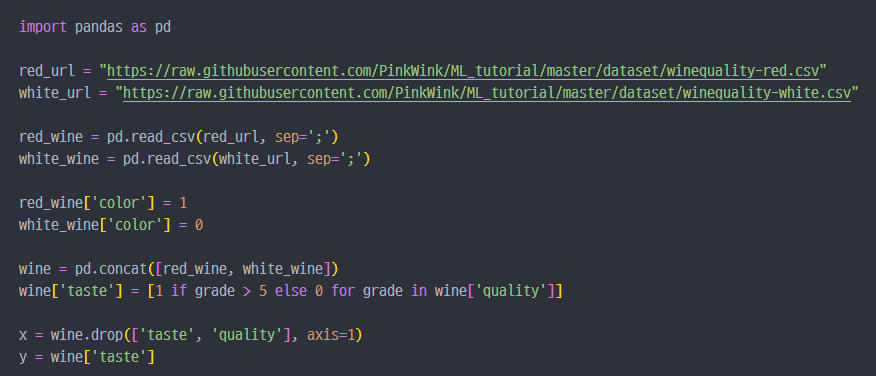
- 와인데이터 불러오고 세팅하는 코드
- GridsearchCV 적용
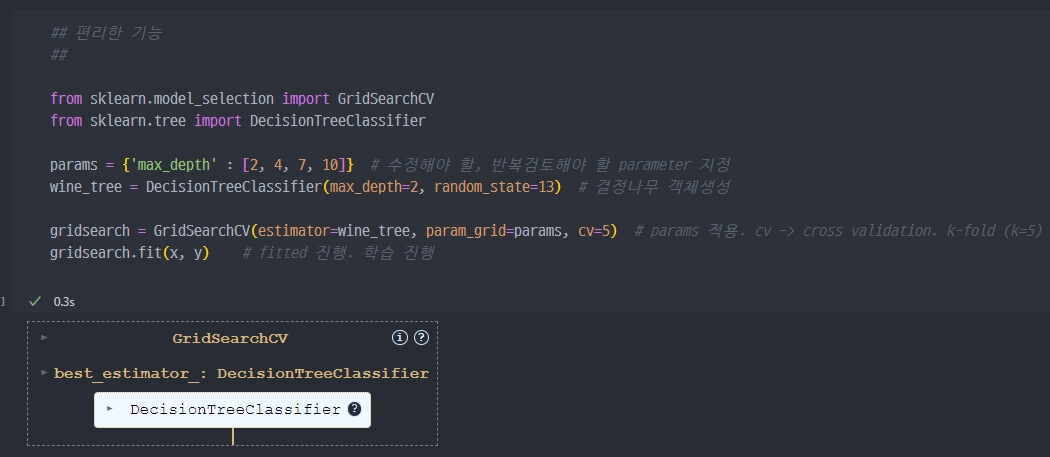
- GridSearchCV의 결과 출력

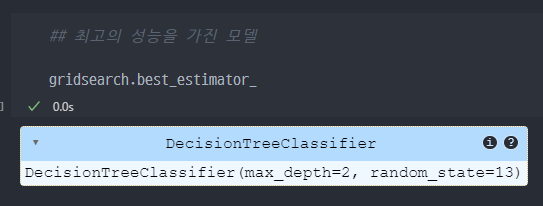
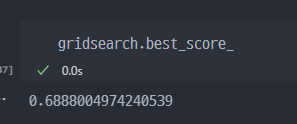
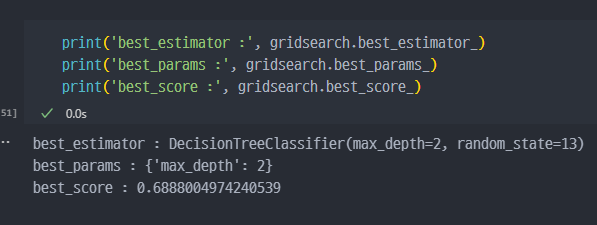
- 최고성능 모델 조회 : gridsearch.bestestimator / Best_score 조회
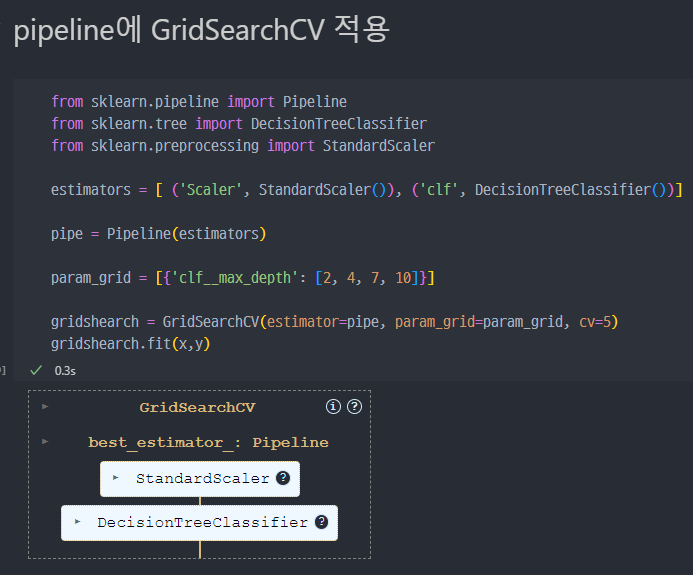
- pipeline에도 적용 ( GridSearchCV)
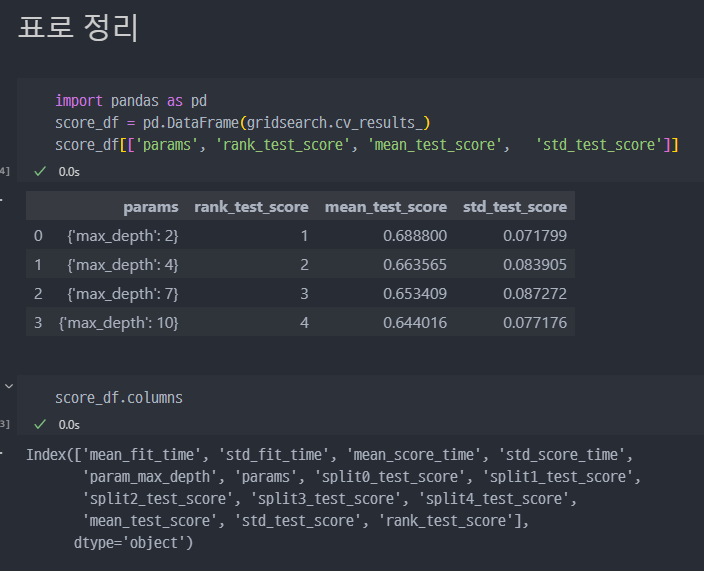
표로 정리

(hellow. world)