모델 평가, 분류모델 평가지표, Thresholds(임계값), ROC, AUC
모델 평가
개념
- 데이터 수집/가공/변환 ▶ 모델 학습/예측 ▶ 모델 평가 ▶ 데이터 수집/가공/변환 (반복)
- 모델을 좋다, 나쁘다 등으로 평가할 방법은 없다.
- 다만, 대부분의 다양한 모델, 다양한 파라미터를 두고 상대적으로 비교.
- 회귀모델 (Regression Model) : 회귀모델 평가는 다소 간단하다.
-
개념
회귀모델은 연속적인 값을 예측하는 모델입니다. 즉, 예측 결과가 숫자로 나옵니다. 예를 들어, 주택 가격 예측, 주식 가격 예측, 체중, 온도 등의 값을 예측할 때 사용됩니다. -
사용 사례
주택 가격 예측
주식 시장 가격 예측
온도 예측
농작물 수확량 예측 -
주요 평가 지표
MSE (평균 제곱 오차), MAE (평균 절대 오차), R² Score 등
- 분류모델 (Classification Model) : 분류모델의 평가 항목은 조금 복잡하다.
-
개념
분류모델은 범주형 값을 예측하는 모델입니다. 즉, 예측 결과가 클래스나 범주(카테고리)로 나옵니다. 예를 들어, 이 메일이 스팸인지 아닌지, 또는 어떤 동물이 사진에 있는지 등을 예측할 때 사용됩니다. -
사용 사례
스팸 메일 분류
질병 진단 (예: 암이냐 아니냐)
이미지 분류 (예: 고양이, 개, 새 등)
고객 이탈 예측 (예: 고객이 이탈할지 말지) -
주요 평가 지표
정확도 (Accuracy), 정밀도 (Precision), 재현율 (Recall), Confusion Matrix(오차행렬), F1 Score, ROC-AUC Curve
분류모델 평가지표
- 또 분류 모델 중에서 이진 분류 모델도 존재한다.
1. Accuracy

2. Precision (정밀도)
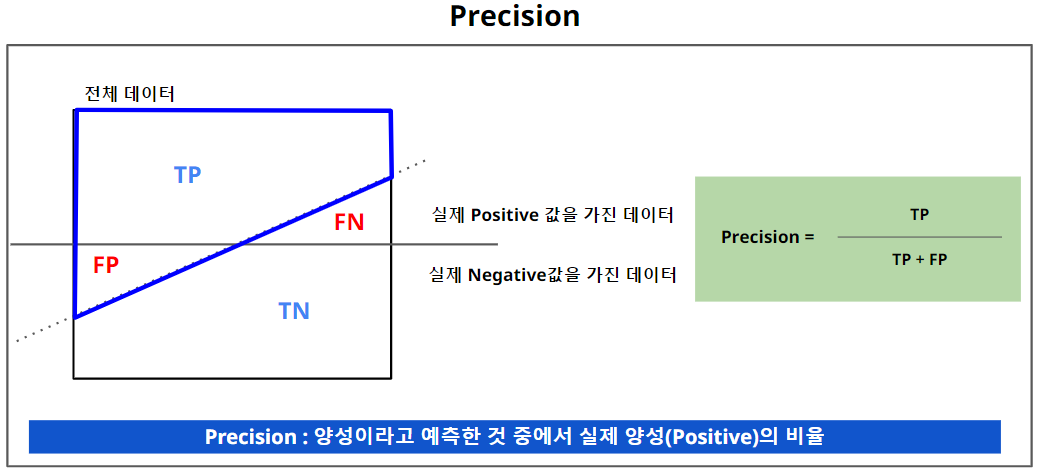
- 스팸메일에서 주로 적용된다.
- 스팸메일이라고 예측한 것 중에서, 실제 스팸이 아닌 메일이 있으면 안되기 때문에 이럴 경우 예측모델 평가 시, Precision으로 평가한다.
3. Recall (TPR : True Positive Ratio)

- Recall의 경우, 실패해서는, 놓쳐서는 안되는 경우에 대하여 주로 사용된다.
- 예를 들어 병원에서 암 진단을 하는 경우, 암에 걸렸지만, 암이 아니라고 진단하게 되면 RISK가 커진다. 이런 경우 예측모델의 평가 시 RECALL 방법을 적용한다.
4. FALL-OUT (FPR : False Position Ratio)
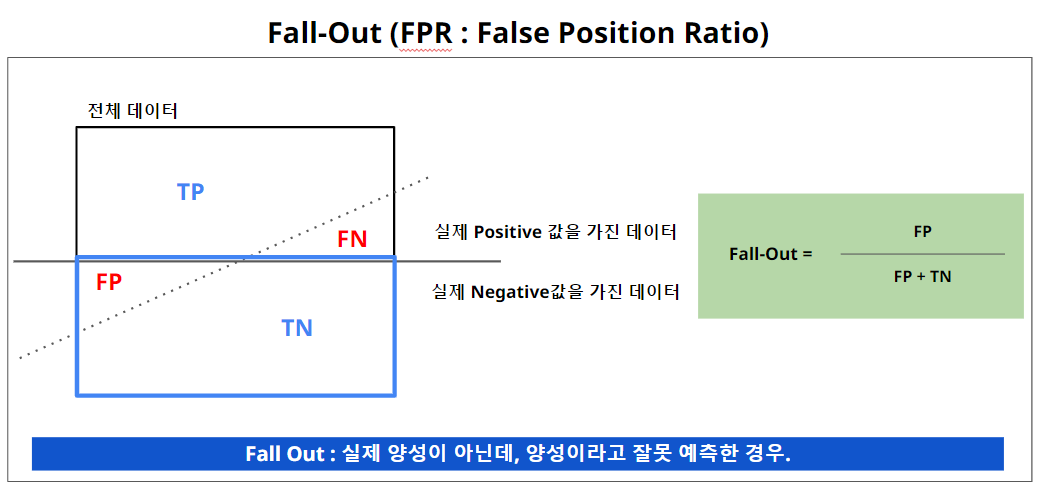
Threshold (임계값)
Threshold(임계값)는 이진 분류모델에서 매우 중요한 개념입니다. 분류모델은 보통 어떤 데이터가 특정 클래스에 속할 확률을 예측합니다. 이때 이 확률을 기반으로 "어떤 값 이상이면 '1'(참)로 분류하고, 그 이하면 '0'(거짓)로 분류하겠다"라고 설정하는 기준이 바로 Threshold 입니다.
쉽게 말해, Threshold는 예측 확률을 이진(0 또는 1)으로 변환하는 기준입니다.
1. Threshold의 기본 개념
-
이진 분류모델은 주어진 데이터가 특정 클래스(예: '스팸' 또는 '암')에 속할 확률을 예측합니다. 예를 들어, 특정 이메일이 스팸일 확률이 0.7로 예측된다면, 이 이메일이 스팸일지 아닐지를 결정해야 합니다. 이때 사용하는 기준이 Threshold입니다.
- Threshold를 0.5로 설정: 보통 기본값은 0.5입니다. 즉, 모델이 예측한 확률이 0.5 이상이면 '1'(참, 스팸)으로 분류하고, 그 미만이면 '0'(거짓, 스팸 아님)으로 분류합니다.
- Threshold가 낮을 때 (예: 0.3): 더 많은 데이터를 '1'(참)로 분류하게 됩니다. 즉, 스팸으로 분류되는 이메일이 많아집니다.
- Threshold가 높을 때 (예: 0.7): 더 많은 데이터를 '0'(거짓)으로 분류하게 됩니다. 즉, 스팸이 적게 분류됩니다.
2. Threshold와 평가 지표의 관계
-
Threshold에 따라 정밀도(Precision), 재현율(Recall), F1 Score 같은 평가 지표가 달라집니다. 그 이유는 임계값에 따라 예측 결과가 달라지기 때문입니다.
-
Threshold가 낮으면 (예: 0.3) : 모델이 더 많은 데이터를 1로 예측할 확률이 높아집니다. 재현율(Recall)은 높아지지만, 정밀도(Precision)는 낮아질 수 있습니다.
- 예를 들어, 암 환자를 놓치지 않기 위해 많은 환자를 '암 환자'로 분류하지만, 그만큼 정상인도 잘못 암 환자라고 할 확률이 증가함.
-
Threshold가 높으면 (예: 0.7) : 모델이 더 적은 데이터를 1로 예측하게 됩니다. 정밀도(Precision)는 높아지지만, 재현율(Recall)은 낮아질 수 있습니다.
- 예를 들어, 실제로 암 환자일 가능성이 매우 높은 경우에만 암 환자라고 예측하지만, 그만큼 암 환자를 놓칠 가능성도 높아집니다.
3. Threshold 선택의 중요성
Threshold는 데이터의 특성, 문제의 중요도에 따라 조정될 수 있습니다.
-
민감도가 중요한 문제 : 예를 들어, 암 진단이나 사기 탐지 같은 경우에는 실제 암 환자나 사기 건을 놓치는 것이 치명적이므로, 재현율(Recall)이 중요합니다. 이런 경우에는 Threshold를 낮추어 더 많은 것을 '1'(암 환자, 사기)로 분류하게 만듭니다.
-
정확도가 중요한 문제 : 반대로, 스팸 필터에서 스팸이 아닌 메일을 스팸으로 분류하는 것은 큰 손해가 될 수 있습니다. 이 경우에는 정밀도(Precision)가 중요하므로, Threshold를 높게 설정해 스팸으로 분류되는 메일의 수를 줄입니다.
4. Threshold와 ROC 곡선
Threshold는 ROC 곡선(Receiver Operating Characteristic curve)에서 시각적으로 이해할 수 있습니다.
-
ROC 곡선은 다양한 Threshold 값을 기준으로 참 양성 비율(TPR, True Positive Rate)과 거짓 양성 비율(FPR, False Positive Rate)의 변화를 보여주는 그래프입니다.
-
AUC (Area Under Curve) 값은 모델 성능을 평가하는 지표로, AUC가 1에 가까울수록 좋은 모델입니다.
Threshold가 바뀌면 ROC 곡선에서 점들이 이동하며, 어떤 Threshold가 최적의 성능을 내는지 확인할 수 있습니다.
5. Threshold를 쉽게 비유하면
-
스팸 필터로 예를 들면: Threshold는 스팸 메일이 될 확률을 몇 %로 잡을지 결정하는 기준입니다. 확률이 50%만 넘으면 스팸으로 분류할지, 70% 이상이어야 스팸으로 분류할지 선택하는 것이죠.
-
문을 지키는 경비원으로 비유하자면: Threshold는 경비원이 몇 %의 확신을 가질 때 사람을 문 안으로 들여보낼지를 정하는 것과 같습니다. 경비원이 50%의 확신만 있어도 사람을 들여보낸다면, 많은 사람이 들어오겠지만 위험한 사람도 더 많이 들어올 수 있습니다. 반면에 90%의 확신이 있어야 들여보낸다면, 안전은 더 보장되지만 많은 사람이 거절당할 수 있습니다.
요약
- Threshold는 이진 분류에서 예측 확률을 0 또는 1로 변환하는 기준입니다.
- Threshold가 낮으면 더 많은 데이터를 '1'로 예측하고, 높이면 더 적은 데이터를 '1'로 예측합니다.
- Threshold 설정에 따라 정밀도, 재현율 등 평가 지표가 달라지며, 문제의 특성에 따라 최적의 값을 선택하는 것이 중요합니다.
Threshold 변경에 따른 모델 평가지표 관찰
1. Threshold = 0.3 일 때
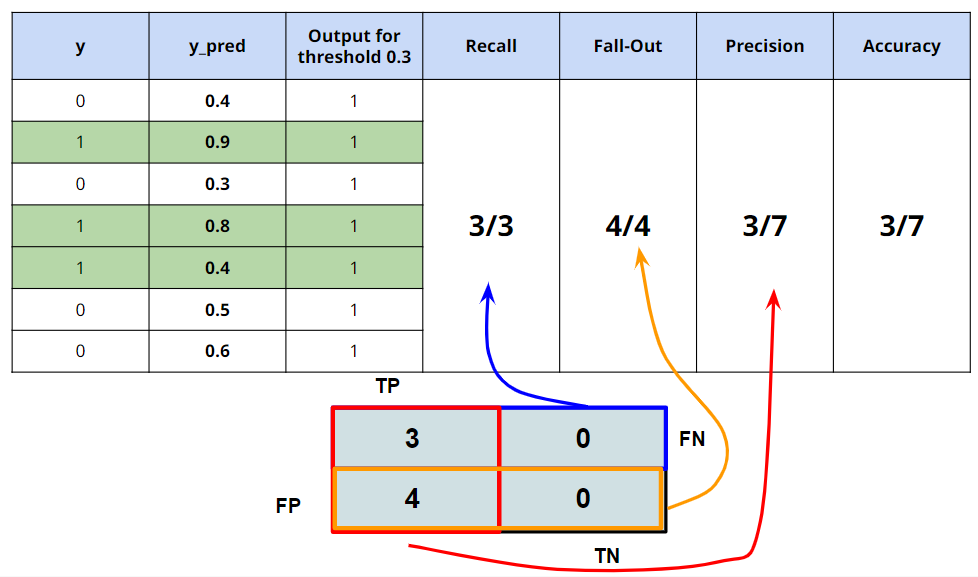
-
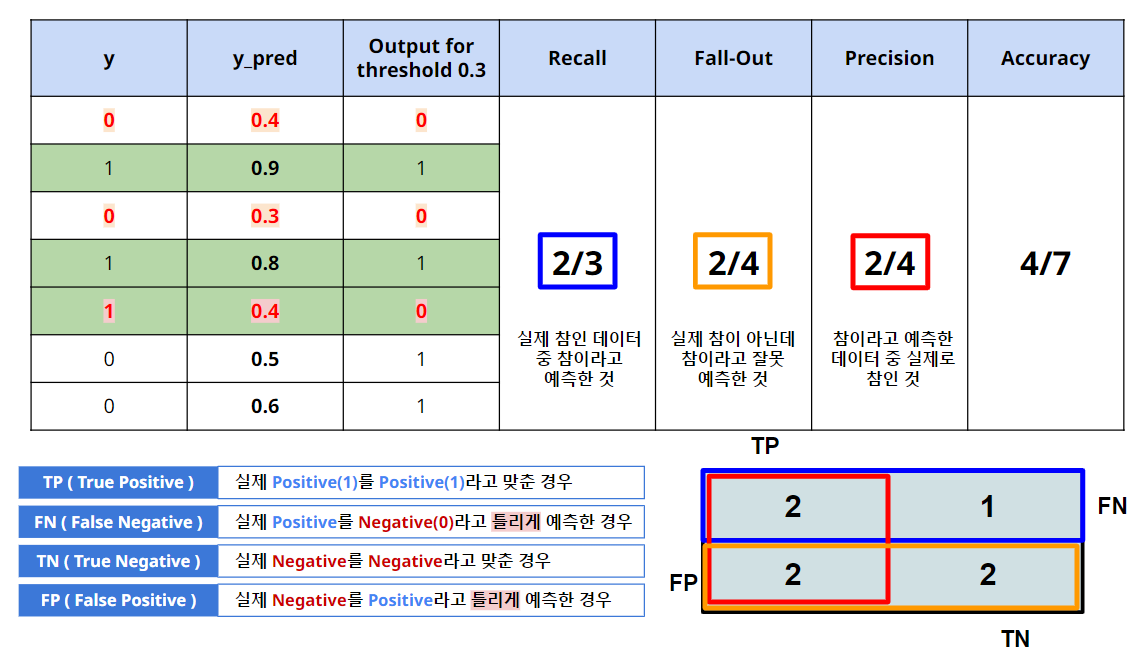
Threshold 가 0.3 이며, y_pred의 모든 값이 0.3 이상이므로, 1으로 예측.
-
해당 결과를 보면, 1을 1로 맞춘 것은 3개이며, 0을 1로 잘못 맞춘것은 4개이다.
-
RECALL으로 평가 시 높은 평가를 받지만, Precision으로 평가 시 낮은 점수를 받는다.
-
즉, 암 진단에서 사용하기 좋지만, 스팸메일 분류 모델로 적용하기에는 좋지 않다.
- 1 이 암 이라면, 모든 1은 1로 예측함. 암을 예측하는 모델로 적합 (병원)
- 1 이 스팸메일이라면, 스팸메일이 아닌 0에 대하여 모두 스팸메일로 분류함. 부적합
2. Threshold = 0.4 일 때
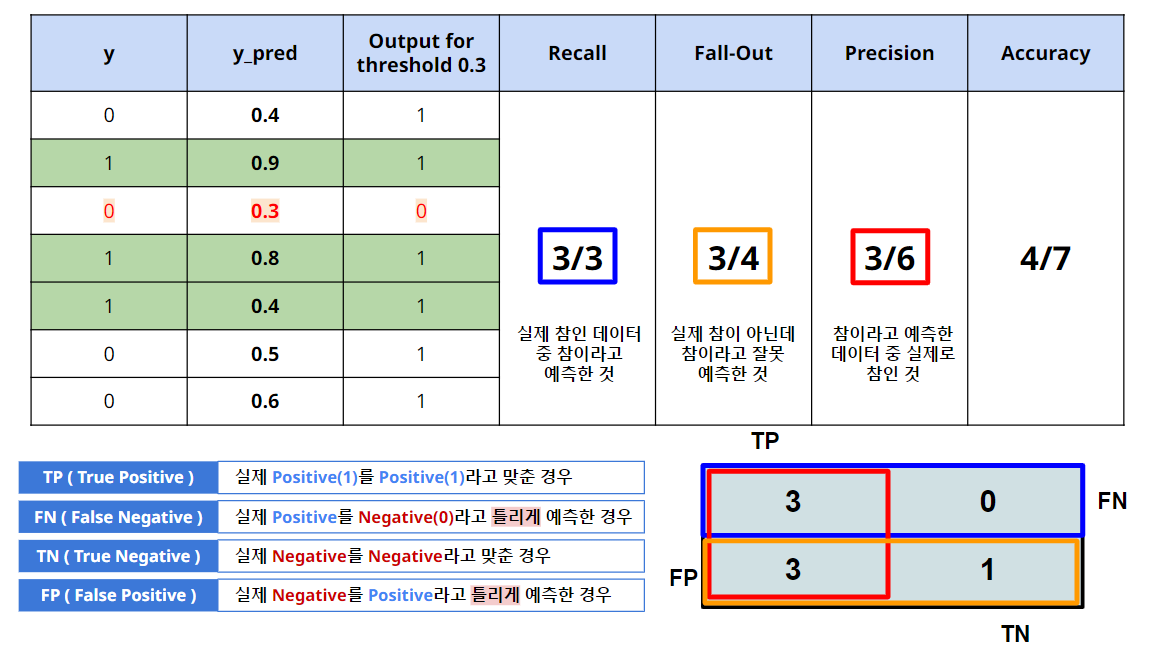
-
y_pred 가 0.3인 데이터는 False(0)으로 예측.
-
Recall 은 Threshold가 0.3인것 대비하여 그대로이다. → 실제 1인 데이터에서 1이라고 맞춘 비율
└ 즉, 실제 1은 3개이며, 1이라고 맞춘 데이터도 3개이므로 3/3 -
Precision 항목은 개선됨. → 1이라고 예측한 것(6개소)에서 1인 것(3개소) → 3/6
-
Fall-Out역시 감소됨.
3. Threshold = 0.5 일 때
4. Threshold = 0.8 일 때

- Threshold 가 0.8인 경우, 실제 0인 값들은 다 0으로 예측함.
- Precision은 크게 개선됨.
5. Threshold에 대한 정리
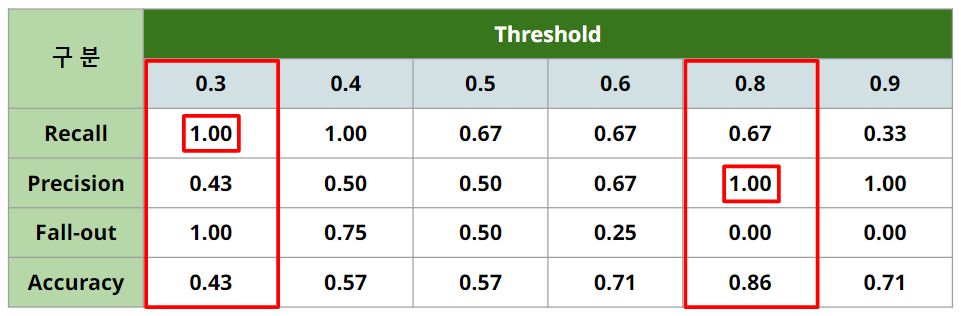
-
실제 양성인 데이터를 음성이라고 판단하면 안되는 경우라면, Recall이 중요하고, 이 경우는 Threshold를 0.3 또는 0.4로 선정해야 함 (eg. 암환자 판별)
-
실제 음성인 데이터를 양성이라고 판단하면 안되는 경우라면, Precision이 중요하고 이 경우는 Threshold를 0.8 혹은 0.9로 선정해야 함. (eg. 스팸메일 판별)
F1-Score
- F1-Score는 Recall과 Precision을 결합한 지표
- Recall과 Precision이 어느 한쪽으로 치우치지 않고 둘다 높은 값을 가질수록 높은 값을 가짐
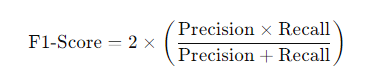
- 이를
조화평균이라고도 함.
- F1-Score의 특성
- 균형 잡힌 평가 : Precision과 Recall 사이의 균형을 맞추어 모델의 전반적인 성능을 평가합니다.
- 불균형 데이터셋에 유리 : 클래스 불균형이 심한 데이터셋에서도 효과적으로 모델을 평가할 수 있습니다.
- 값의 범위 : F1-Score는 0에서 1 사이의 값을 가지며, 1에 가까울수록 모델의 성능이 우수함을 나타냅니다.
분류모델의 평가(2) : ROC, AUC
ROC
- ROC 곡선(Receiver Operating Characteristic Curve)은 이진 분류 모델의 성능을 평가하고 비교하는 데 사용되는 그래프로, 다양한 임계값(threshold)에서의 참 양성 비율(True Positive Rate, TPR)과 거짓 양성 비율(False Positive Rate, FPR)을 시각화합니다.
- ROC 곡선은 모델의 분류 능력을 직관적으로 이해하는 데 도움을 주며, 특히 클래스 불균형 문제에서 유용하게 사용됩니다.
ROC의 개념
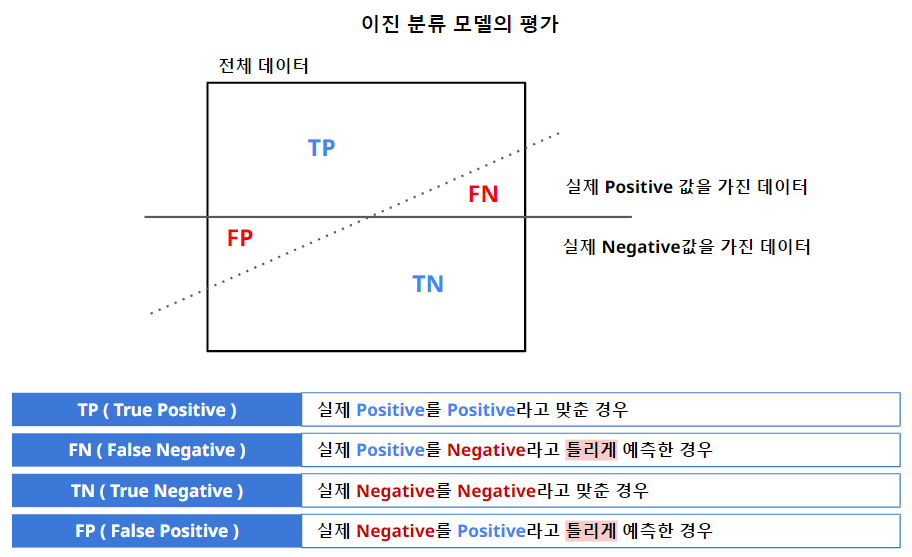
- 이진 분류 문제에서의 예측
- 참 긍정(True Positive, TP): 실제 긍정 클래스인 데이터를 정확히 긍정으로 예측.
- 거짓 긍정(False Positive, FP): 실제 부정 클래스인 데이터를 잘못 긍정으로 예측.
- 참 부정(True Negative, TN): 실제 부정 클래스인 데이터를 정확히 부정으로 예측.
- 거짓 부정(False Negative, FN): 실제 긍정 클래스인 데이터를 잘못 부정으로 예측.
TPR과 FPR의 정의
- 참 양성 비율 (TPR, Recall 또는 Sensitivity)

실제 긍정 중에서 모델이 얼마나 많이 긍정으로 예측했는지를 나타냅니다.
- 거짓 양성 비율 (FPR)

실제 부정 중에서 모델이 얼마나 잘못 긍정으로 예측했는지를 나타냅니다.
- 임계값 (Threshold)
모델이 예측 확률을 기반으로 긍정 또는 부정 클래스로 분류할 때 사용하는 기준값입니다.
임계값을 변경하면 TPR과 FPR이 변하게 되며, 이를 통해 ROC 곡선이 형성됩니다.
ROC 곡선의 해석
- 좌상단 모서리에 가까울수록 좋은 모델
높은 TPR과 낮은 FPR을 의미하므로, 많은 긍정 사례를 정확히 예측하면서도 거짓 긍정을 최소화함.
- 대각선 (무작위 분류선)
FPR과 TPR이 동일하게 증가하는 선으로, 무작위로 분류할 때의 성능을 나타냄.
ROC 곡선이 이 선 위에 위치하면 모델이 무작위보다 성능이 떨어지는 것을 의미합니다.
- 곡선 아래 면적 (AUC, Area Under the Curve)
ROC 곡선 아래의 면적으로, 모델의 전반적인 성능을 수치화합니다.
AUC 값은 0과 1 사이이며, 1에 가까울수록 우수한 모델을 의미합니다.
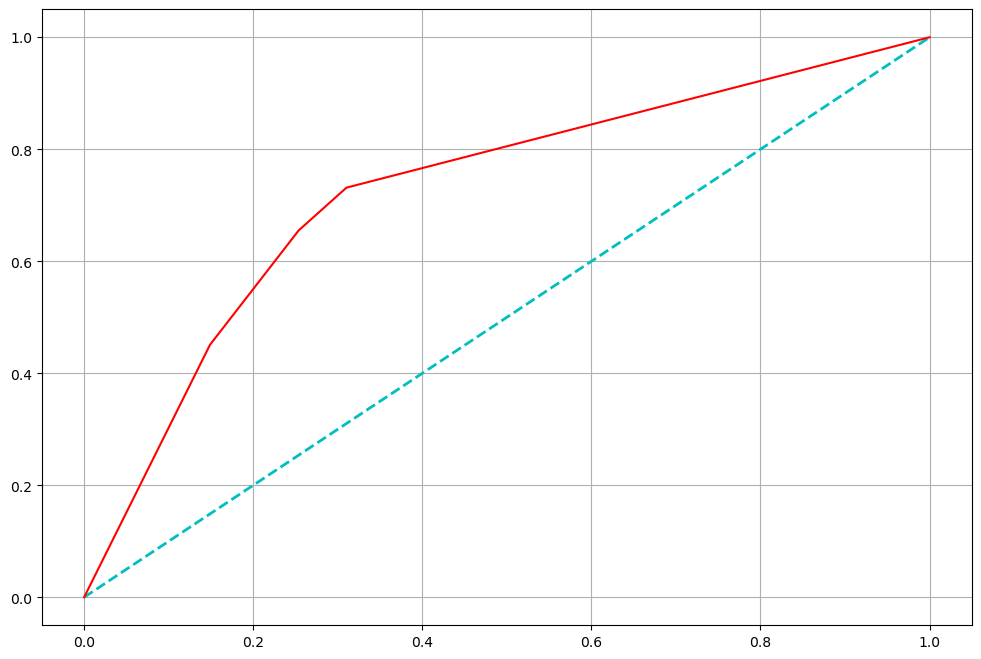
ROC 곡선
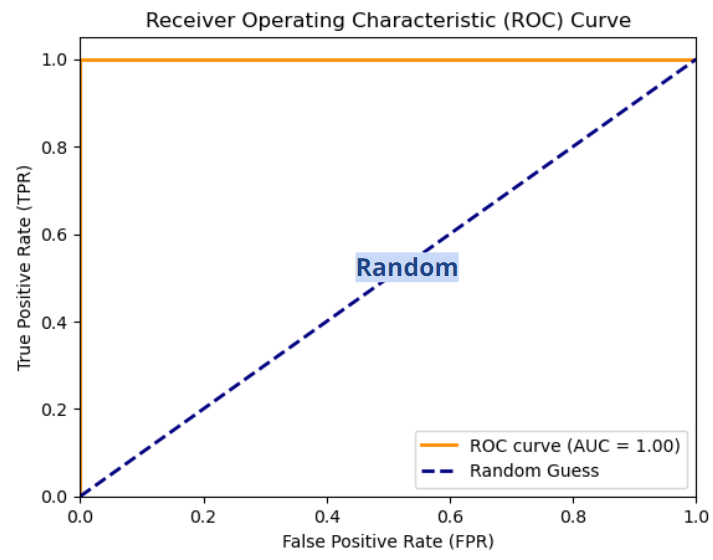
- FPR(False Positive Rate)가 변할 때, TPR(True Positive Rate)의 변화를 그린 그림
- FPR은 Fall-out으로 볼 수 있고, TPR은 Recall (sensitive)로 볼 수 있다.
- FPR을 x축, TPR을 y축으로 본다
- 직선에 가까울수록 머신러닝 모델의 성능이 떨어지는 것으로 판단한다.
모델의 성능이 완벽하다면, ROC 곡선은 직각이다. 이 경우 AUC = 1 이다.

모델이 적당히 정확하였다면.. 이 경우 AUC = 0.7 정도
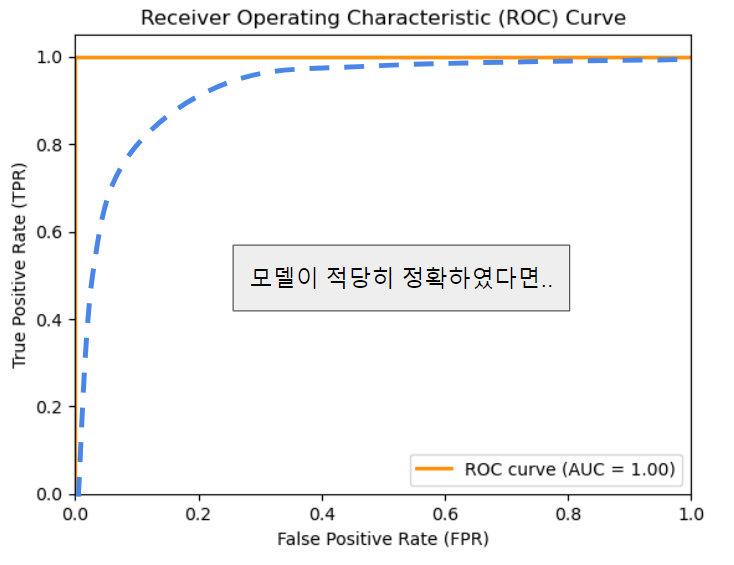
- AUC는 0.5보다 커야 일반적인 모델성능이라 볼 수 있다.
ROC 곡선 그리기 실습
- 사용하는 데이터는 wine 데이터에서
taste에 대한 예측모델을 사용한다.
1. 관련 라이브러리 import

2. ROC 커브곡선 그리기
- FPR, TPR, Thresholds를 먼저 받아온다.

- 여기서
[x_test]값에 슬라이싱 하는 이유는 아래와 같다- predict_prob는 0인 확률과 1인 확률 두가지 값을 반환. (아래와 같이)
- 0일 확률 값은 버리고, 1일 확률 값만 가지고 온다
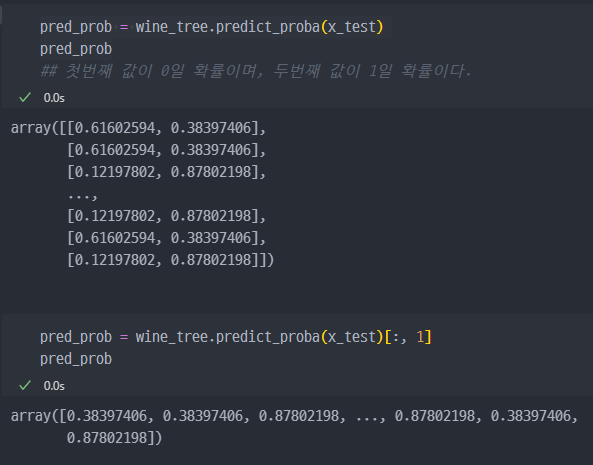
- plt.show를 이용해서 그래프 작성