
PCA eigenface
Olivetti 데이터
- Olivetti 데이터는
얼굴 인식용으로 사용하는 데이터셋 이다.
Olivetti
데이터 읽기
sklearn에서 기본으로 제공하는 datasets이 있다.
key값들을 보면 어떤 항목으로 데이터들이 저장되어 있는지 확인할 수 있다.

image에 저장된 픽셀값들을imshow보면.. 위와 같다.
target값은 0에서 39까지의 숫자로 이루어진 데이터이다.images에 저장된 데이터는 사진의 픽셀값이다.
target이 20 인 데이터의 images 값만 추출하면..
imshow 확인
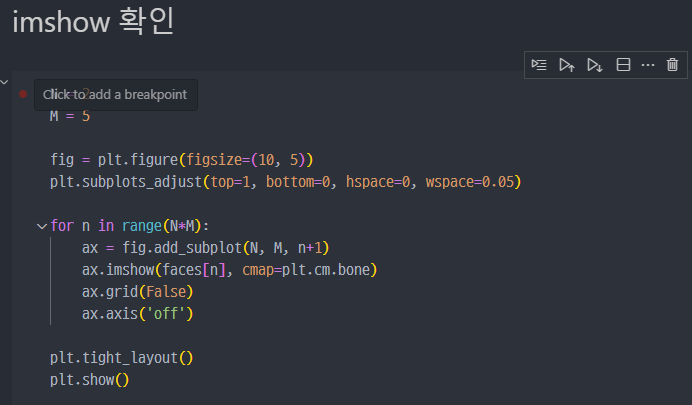

subplot과 imshow 간단설명




PCA 진행
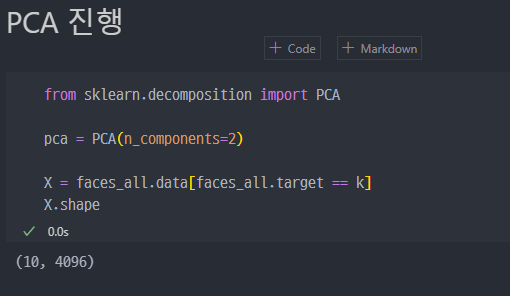
faces_alldatasets에서data와image의 차이는 shape만 차이가 있고 저장된 데이터는 동일하다.X.shape에서 (10, 4096)은 10개의 열과 4096개의 컬럼으로 이루어진 shape을 의미한다. 즉 사진 10장과 각 사진이 64X64 픽셀로 이루어져 있다는 사실.
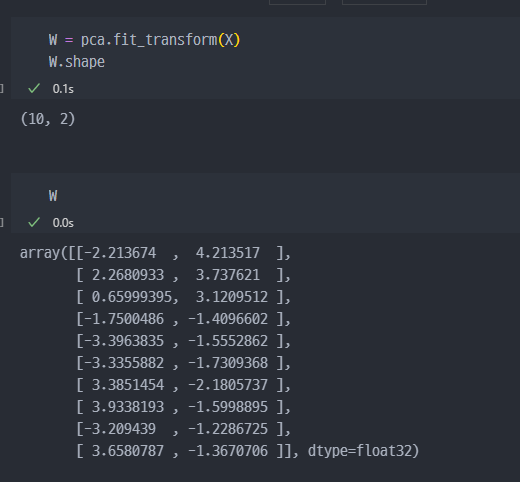
PCA진행하게 되면,feature가 축소되어 주성분이 2개로 지정된다.- 다만, 아래와 같이 2X10으로는 imshow를 진행할 수 없다. 그렇기때문에
pca진행된W데이터를inverse_transform진행하여 복원한다.
다시 imshow
- 당초
faces데이터의 shape을 확인하고 이와 동일하게 X_inv를reshape하여야 한다.
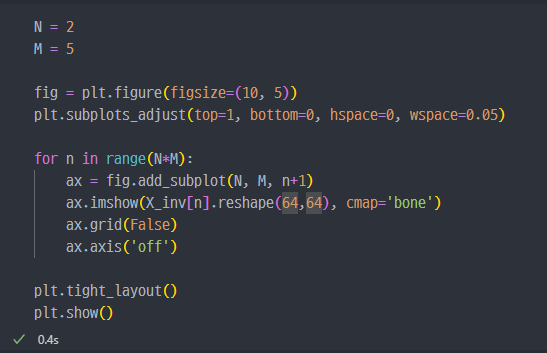

원본과 PCA진행 - 복원한 데이터에서 사진비교
- 원본
PCA진행 후 복원하여imshow
확실히.. 원본의 사진들이 표정이나 디테일이 다양한 것.. 다만 큰 맥략에서는 둘 다 유사해보인다.
eigen face
pca를 진행하게 되면,component에는 벡터값이 저장되어 있다.- 따라서,
component에 저장된 벡터값으로imshow를 진행해본다.
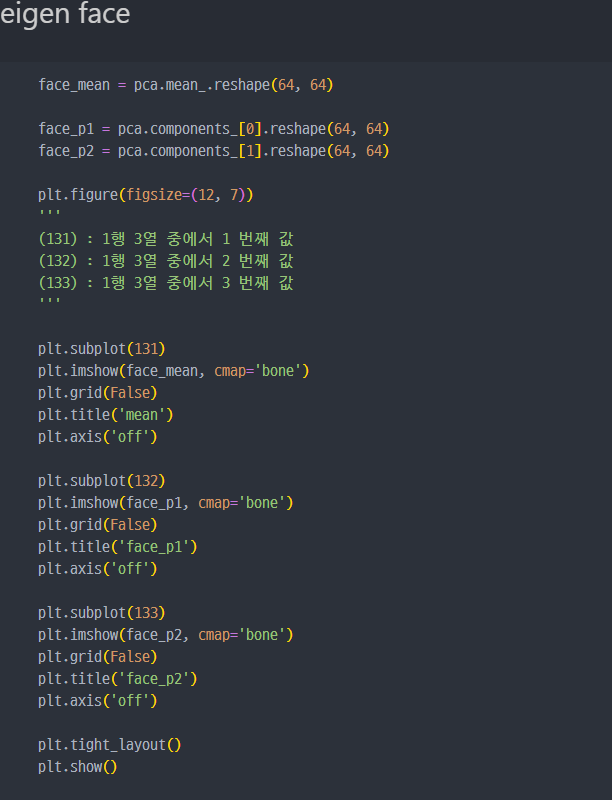

결국
mean값이 평균값으로 전체 사진데이터에서 평균을 이루는 형태라고 볼 수 있다.
각각의 두 벡터값으로 그린 사진은 평균에서 각 사진으로 변화한다고 볼 수 있다.
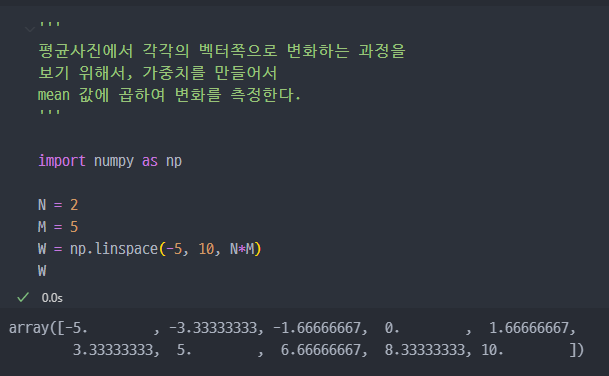
변화하는 형태를 아래의 사진으로 보면..
- mean 값에 변화량(가중치)를 먼저 만들면
- face_p1, face_p2의 각각에 해당하는 그림을 보면
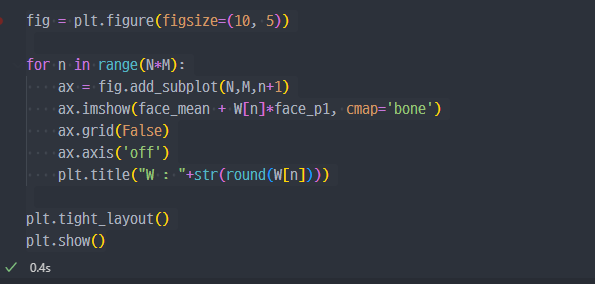

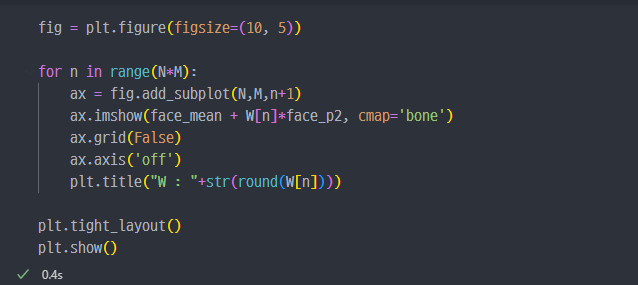

- 결국 각각의 벡터 방향으로 갈 수록 사진이 아래와 같이 변화한다.


(hellow. world)