Normalizing traing sets
- 딥러닝이나 머신러닝 모델을 학습할 때 입력 데이터의 스케일(scale)은 매우 중요하다.
입력 값들의 범위가 서로 크게 다르면 학습 속도가 느려지거나 최적화가 비효율적으로 진행될 수 있다. - 해결하기 위해 사용하는 기법이 바로 입력 정규화(Input Normalization)이다.
Why need to nomalizing input?
-
예를 들어 두 개의 feature가 있다고 가정해보자.
- 키: 150 ~ 190
- 연봉: 3,000 ~ 100,000
-
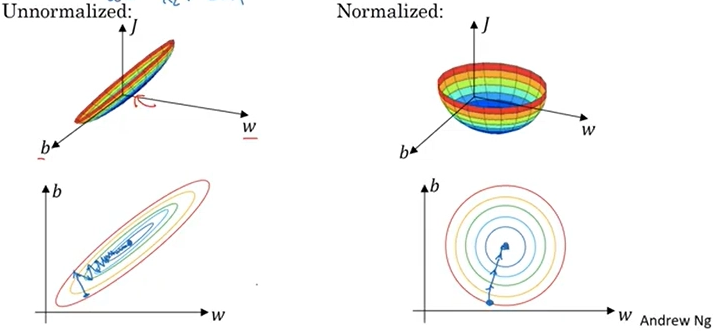
이처럼 feature마다 값의 범위가 다르면, 비용 함수(cost function)의 등고선이 한쪽으로 길게 늘어진 타원 형태가 된다.
- 이 경우 Gradient Descent는 지그재그로 이동하면서 매우 느리게 수렴하게 된다.
-
반면, 입력을 정규화하면 등고선이 보다 원형에 가까워지고, 최적점으로 훨씬 빠르게 수렴할 수 있다.
Example of Normalizing
- X는 2차원 vector
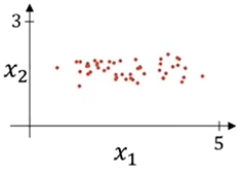
- X의 평균값을 구한 후, X에 평균값을 빼주어 mean값을 0으로 만든다.
- 표준 편차를 구한 후 분산을 1로 만든다.
출처 및 참고 자료
- Andrew Ng, Improving Deep Neural Network, DeepLearningAI
