Vanishing Gradients
- Layer가 많으면 입력층에 가까울 수록 미분이 사라진다.
- 주범은 sigmoid다.
- 최대 기울기가 0.25이기 때문임.
- 출력층과 가까운 층은 update가 잘 되고 입력층과 가까운 층은 update가 거의 안된다.
- n번째 층은 결국 n-1번째 층의 출력을 입력으로 사용하기 때문에, 입력층에 가까운 층이 제대로 학습되지 않으면 그 영향이 뒤쪽 층에도 누적되어 Loss를 충분히 줄이기 어렵게 된다.
- 재료 손질 -> 요리 -> 플레이팅에서 재료 손질을 망쳐버리면 음식의 퀄리티가 좋을 수가 없다.
해결방법
- ReLU를 사용하여 Vanishing Gradient를 해결하였다.
- 그냥 linear activation을 사용하지 않는 이유는 비선형성을 확보하기 위해서다.
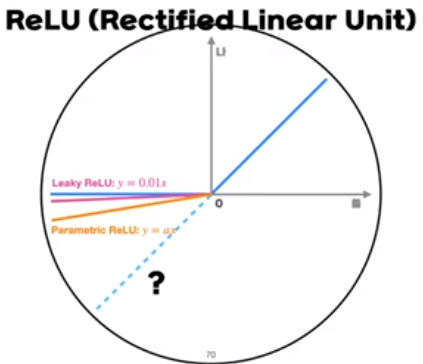
- 그냥 linear activation을 사용하지 않는 이유는 비선형성을 확보하기 위해서다.
- 노드 수가 많은 NN에서 ReLU의 진가가 발생함.
출처 및 참고 자료
- Andrew Ng, Improving Deep Neural Network, DeepLearningAI
- 혁펜하임, Easy! 딥러닝
