Logistic regression Regularization
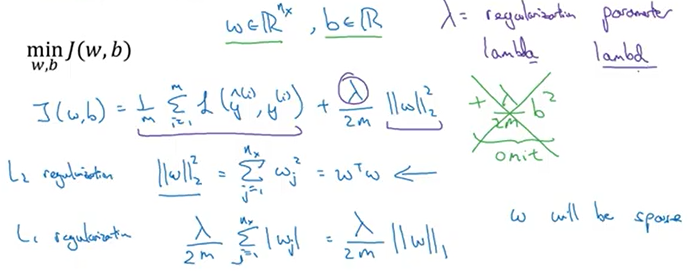
-
Loss에 Weight의 크기를 더해서 같이 고려하려고 하는 것이다.
- 대신 을 loss로 사용
- lambda도 hyperparameter임.
- weight를 줄였는데 loss가 커졌다? 그럼 중요한 weight이므로 가만히 둠.
- 대신 을 loss로 사용
-
Weight를 줄이려고 하는 이유
- Loss를 줄이는 데 별 영향이 없는 weight를 0으로 만들어 모델 경량화
- 어느정도 수렴하고 나서도 계속 학습시켜보니 weight가 자꾸 커짐
-
L1 & L2 Regularization
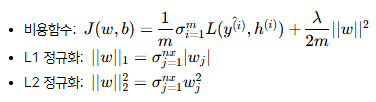
Backpropagation using regulation
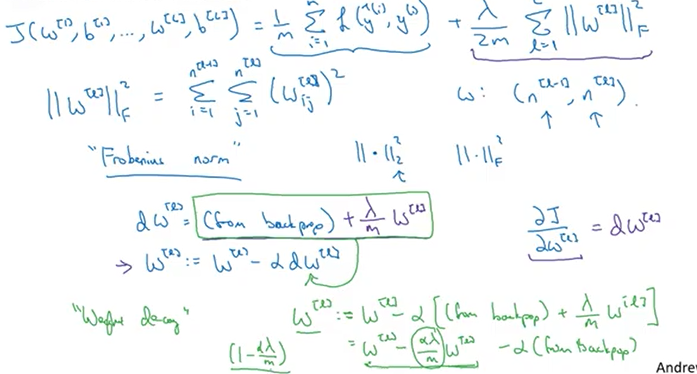
- L2 Regularization을 적용한 Cost function
- Frobenius 노름
- 가중치 행렬의 각 요소의 제곱을 합한 값이다.
- 가중치 행렬의 각 요소의 제곱을 합한 값이다.
- L2 Regularization이 Weight decay라고 불리는 이유는 weight에 1보다 작은 값인 가 곱해지기 때문이다.
출처 및 참고 자료
- Andrew Ng, Improving Deep Neural Network, DeepLearningAI
- 혁펜하임, Easy! 딥러닝
