Dropout regularization
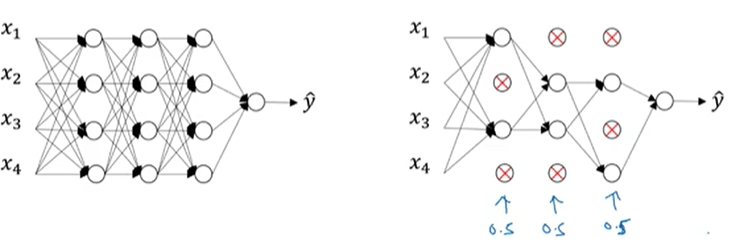
- 노드를 삭제할 확률을 설정 후, 노드를 삭제. 그 후 노드에 들어가는 링크나 나가는 링크를 모두 삭제함.
- 네트워크에 통과 시킬 때마다 죽일 노드를 다시 선택함.
- 더 작고 간소화된 네트워크가 만들어짐.
- Dropout이 왜 효과가 있는가?
- random으로 노드를 삭제 시키기에, 하나의 특성에 의존하지 못하게 만듬. 가중치가 다른 곳으로 분산함.
- 노드가 필요 이상으로 많다면 loss를 잘 줄이지만 기계적으로 정답을 맞추는 경향이 있음. Dropout을 적용하여 각 노드가 의미있는 특징을 뽑을 수 있도록 함.
- 우선적으로 cost function이 좋은 함수인지 확인 해야 한다. 따라서 우선 drop out을 사용하지 않고, cost function이 단조 감조인지 확인 후에 사용해야 한다.

- Train 할 때만 Drop out을 사용하고, Test 할 때는 Drop out을 사용하지 않는다 !
Implementing dropout (”Inverted dropout”)
- drop out vector of layer 3 ⇒ d3
- d3 = np.random.rand(a3.shape[0],a3.shape[1]) < keep.prob
- keep.prob가 0.8이면 node가 삭제될 확률은 0.2다.
- a3 = np,multply(a3,d3)
- d3를 곱해서 a3의 몇개의 원소를 0으로 만듬.
- a3 /= keep.prob
- a3의 기대값을 유지시키는 것
- 이전 layer의 뉴런의 0.5 확률로 꺼졌다면.. 현재 layer의 neuron들이 받는 입력 또한 반으로 줄었을 것. 따라서 남은 neuron들의 출력을 2배 scaling 하여 입력 값을 유지.
- d3 = np.random.rand(a3.shape[0],a3.shape[1]) < keep.prob
출처 및 참고 자료
- Andrew Ng, Improving Deep Neural Network, DeepLearningAI
- 혁펜하임, Easy! 딥러닝
