Gradient Descent with Momentum
- Momentum은 관성처럼 과거의 방향을 유지하면서
학습을 더 빠르고 안정적으로 만드는 방법이다.
Momentum 수식
-
Velocity 업데이트
- : 현재 속도(velocity)
- : momentum 계수 (보통 0.9)
- : gradient
-
파라미터 업데이트
- : learning rate
- : momentum이 적용된 gradient
GD vs Momentum
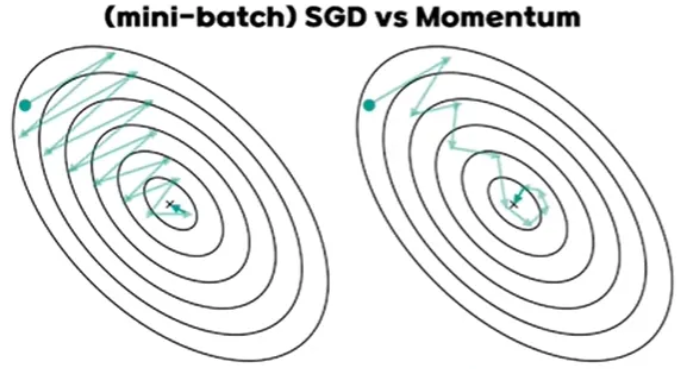
-
Gradient Descent
-
Momentum
-
Gradient Descent는 현재 gradient만 사용하여 업데이트한다.
그러나 Momentum은 과거 gradient들의 지수 가중 평균(EWA)인 를 사용하여 일관된 방향은 강화하고, 진동 성분은 상쇄한다.
출처 및 참고 자료
- Andrew Ng, Improving Deep Neural Network, DeepLearningAI
- 혁펜하임, Easy! 딥러닝
