Exponentially Weighted Averages
-
EWA의 정의
- : 시점 에서의 지수 가중 평균
- : 시점 의 실제 값
- : decay rate (보통 0.9 ~ 0.99)
-
EWA는 최근 값일수록 더 큰 가중치를 갖는다.
-
유효 Window 크기
- 약 10 step 평균
- 약 100 step 평균
-
Bias Correction
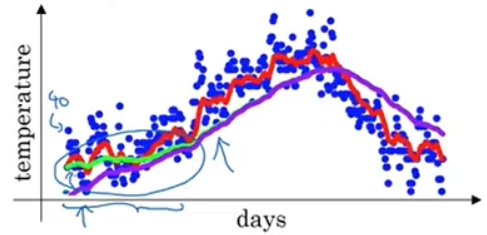
- 초기값을 으로 두면, 초기 단계에서 값이 작게 편향된다.
- 보라색 Line을 보면 엄청 낮은 곳에서 시작함. 귀납적으로 이어나가, 초반에 좋지 못한 추정을 하게됨.
- 이를 보정하기 위해 밑의 식을 사용함.
- 초기값을 으로 두면, 초기 단계에서 값이 작게 편향된다.
-
왜 산술 평균을 안 쓰고 EMA를 쓸까?
- 산술 평균이 다 더하고 나누는 것이기에 EMA보다 정확하다. 하지만 많은 리소스를 잡아먹기에 EMA에 더 효율적이다.
출처 및 참고 자료
- Andrew Ng, Improving Deep Neural Network, DeepLearningAI
