Optimizer
- Loss function을 최적화하는 담당, 최소값을 찾는 알고리즘을 optimizer라고 부름
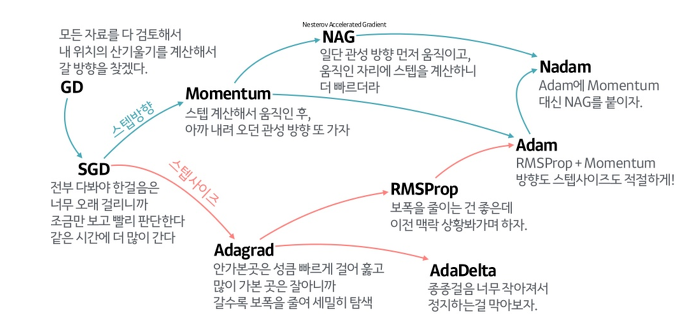
GD (Gradient Descent)
-
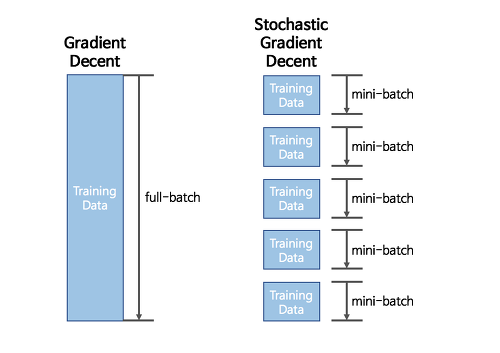
한 번 학습 시 모든 데이터셋을 사용하여 가중치 갱신
-
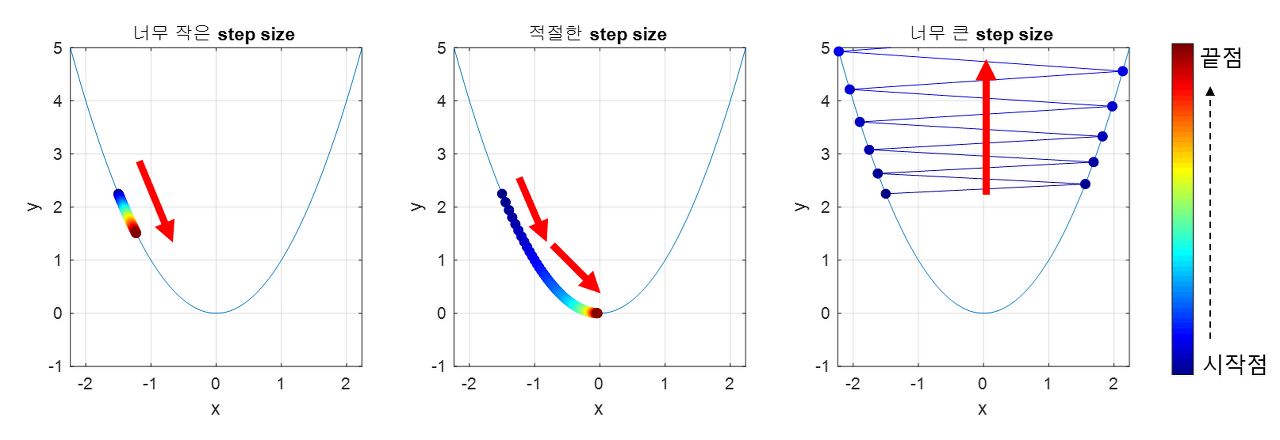
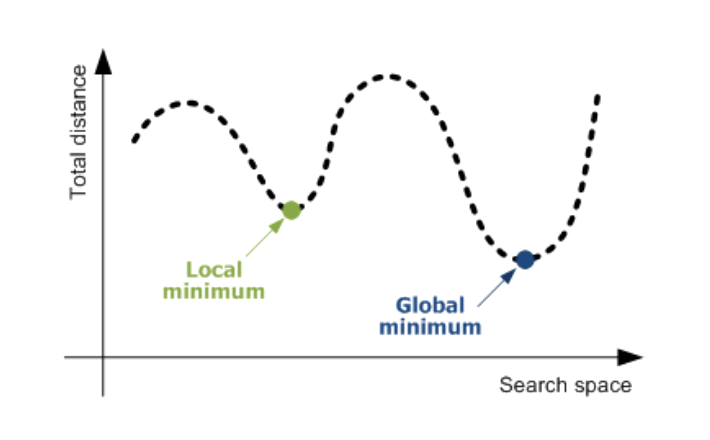
단점: 학습이 굉장히 오래 걸림, LR이 너무 크면 발산하게 되고, 너무 작으면 학습이 오래 걸리게 됨, Local Minima에 갇힐 수도 있음, 전체 데이터셋을 한 번에 학습해야 하므로 메모리가 부족할 수도 있음
SGD (Stochastic Gradient Descent)
-
-
GD의 단점 보완, Mini Batch로 데이터셋을 나눠 여러 번 가중치를 갱신
-
단점: LR 설정 문제, Local minima 문제, osicillation 문제 그대로 존재
Momentum
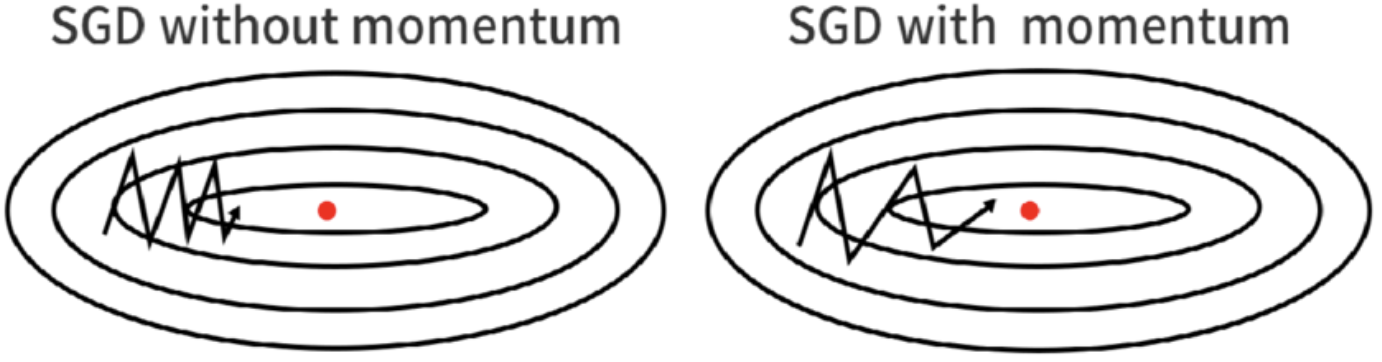
-
빠른 학습 속도와 local minima 문제를 개선하고자 SGD에 관성의 개념을 적용
-
-
-
이전 이동 거리와 관성계수 m에 따라 가중치를 갱신, m은 일반적으로 0.9
-
단점: global minima에서도 관성이 작용되어 벗어날 가능성 존재
Adagrad (Adaptive Gradient Algorithm)
-
기존 optimizer들의 단점 중 하나는 LR이 모든 파라미터에 매 번 똑같이 고정되어 있다는 것, Adagrad는 각 파라미터에 적용되는 LR과 각 갱신 때마다의 LR을 조절
-
G 값을 도입, 현재까지 각 변수가 이동한 gradient의 제곱근의 합, 파라미터를 G에 반비례한 크기로 갱신
-
학습을 진행하며 많이 변화한 파라미터는 step size를 작게, 조금 변화한 파라미터는 step size를 크게하자는 아이디어
-
단점: 학습이 오래 진행될 경우 학습률이 너무 작아져 거의 갱신되지 않게 됨, global minima에 도달하기 전 LR이 0에 수렴할 수도 있음
RMSProp (Root Mean Square Propagation)
-
Adagrad의 G 값이 너무 커지는 것을 해결하기 위해 지수 이동 평균을 도입, 시간이 지날수록 예전 gradient의 영향력이 줄어들게 됨
-
따로 개발 되었지만 Adadelta와 수식과 아이디어가 비슷
Adam (Adaptive Moment Esimation)
-
각 파라미터마다 다른 크기의 LR 적용, local minima를 뛰어넘을 수 있으니 속도를 조심스럽게 줄이자는 것이 아이디어, RMSProp + Momentum
-
vanishing learning rate 문제 해결, loss가 최소값으로 빠르게 수렴
-
계산 비용이 약간의 단점
AdamW (Adaptive Moment Esimation)
-
Adam + weight decay, 가중치 감쇠는 정규화 기법 중 하나, 과적합을 방지하고 모델의 일반화 성능을 향상시키기 위함
-
Loss function에 모든 가중치의 제곱항에 대한 패널티 항을 추가하여 모델의 가중치가 너무 크지 않도록 규제하는 것
-
RMSProp, Adam, AdamW 수식 기억 안남 개념만 공부 후 나중에 자세히 보기
Scheduler
- 학습 진행 중 epoch 간 LR을 규제하는 프레임워크
LambdaLR
- Epoch에 따른 가중치로 LR을 감소, (초기 LR * lambda 함수), 현재 epoch_num이 lambda 함수의 인수로 주로 사용
MultiplicativeLR
- Epoch에 따른 가중치로 LR을 감소, (이전 LR * lambda), 이전 epoch의 LR에 정해진 인수를 곱함
StepLR
- step_size 마다 gamma로 LR을 감소, (이전 LR * Gamma)
ReduceLROnPlateau
- 성능 향상이 없을 때 LR을 감소, validation loss나 metric을 인수로 사용
Conclusion
- 학습시킬 때 ReduceLROnPlateau를 제일 먼저 사용해보고 StepLR에 milestone을 줄 수 있는 스케줄러나 exponential decay 스케줄러를 주로 사용했던 것 같다.
