[22][1010] VideoMAE : Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
action recognition in videos
1. info
- 2022, 1010회 인용
- 논문: https://proceedings.neurips.cc/paper_files/paper/2022/file/416f9cb3276121c42eebb86352a4354a-Paper-Conference.pdf
- 보충자료: https://proceedings.neurips.cc/paper_files/paper/2022/file/416f9cb3276121c42eebb86352a4354a-Supplemental-Conference.pdf
- https://github.com/MCG-NJU/VideoMAE
- 1400 star
참고 자료
- ImageMAE: https://velog.io/@hsbc/MAE-Masked-Auto-Encoding-are-scalable-Vision-Learner
- VideoMAE2: https://velog.io/@hsbc/VideoMAE-V2-Scaling-Video-Masked-Autoencoders-with-Dual-Masking
논문 4줄 요약
- Video masked self-supervised pretraining 방법을 제시했는데,
90-95% 정도pixelcube masking을 진행하여 input으로 주고, 마스킹된 픽셀들을 복원하는 방식. (라벨이 없는 비디오 데이터셋으로 학습하는 방법) - 위와 같이 pretraining한 네트워크를, action clasffication 등의 downstream task를 위한 fine-tuning 시 시작 weight으로 활용하는게 유용하려면 -> pretraining 시 사용한 데이터셋과 같거나 거의 유사한 데이터 셋에 대해서만, 유효한 결과를 냈다. (SSV2로 pre-training한 네트워크를 기반으로 kinetics 데이터셋 이용 fine-tuning을 하니 성능이 좋지 않았다)
- 비디오 frames를 input으로 넣을 때는
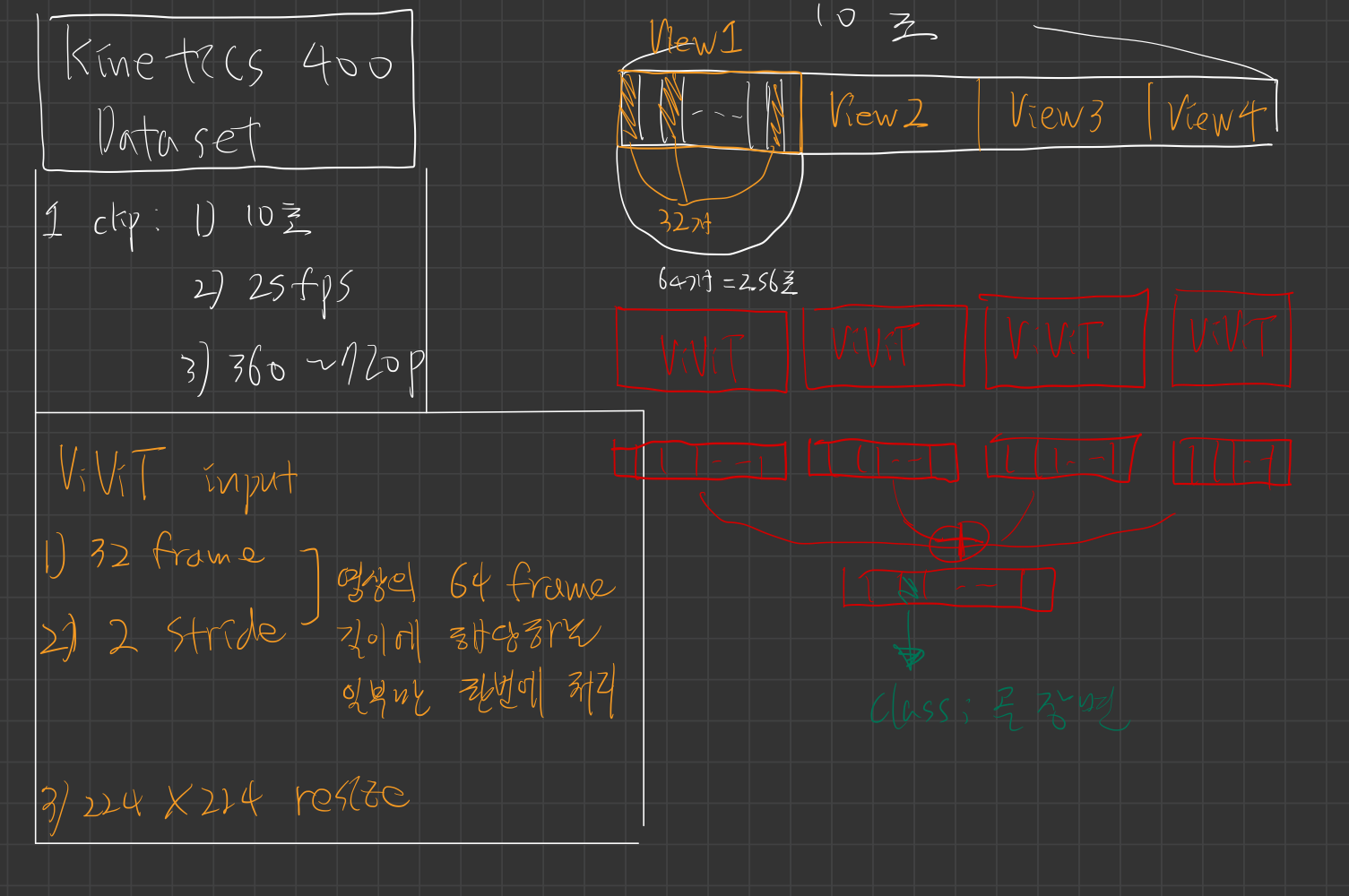
720 by 1080이미지 원본을 ->256 by 384~320 by 480로 리사이징 한 후 -> 리사이징 이미지를 224 by 224 로 crop(좌 or 중앙 or 우 영역)해서 최종적으로 인풋으로 활용함 - 비디오 frames를 input으로 넣을 때 fps, stride, 총 몇 frames를 넣는지는 아래 그림을 보면 잘 설명되어 있습니다. (각 프레임 간 시간 간격은 1/6.25 ~ 1/6 초로 거의 비슷) (한번에 넣는 비디오가 커버하는 시간 길이도 2.56~2.66초로 거의 비슷)
2. Introduction
2.1. 연구의 Motivation
- ViT는 학습을 잘 시키기 위해서, 데이터도 많이 필요하고, 학습 시간이 오래 걸림.
- Video ViT (like ViViT )는
이미지(예: ImageNet)로 사전 학습된 ViT를 기반으로 학습해야, 성능이 어느정도 나온다는 문제점이 있었음- 비디오 데이터를 가지고도,
Video Vision Transformer을 scratch 방식으로 학습할 수 있는 연구가 필요했음!
- 비디오 데이터를 가지고도,
- 하지만, 비디오 데이터의 양은 일반적으로 이미지 데이터에 비해 적은 경우가 많아,
- Video VisionTransformer을 scratch 부터 학습 시키는 것이 어려운 상황이었음.
MAE를 Video ViT에 적용함으로써, 적은 비디오 데이터로부터 scratch 부터 학습시키는 것을 가능하게 했음(3000~4000개 비디오로 도 충분했다)self supervised learning적용함3000 ~ 4000 개의 비디오 클립 만으로도 유의미한 성과를 냈습니다.
- Self-Supervised Vidoe Pretraining (SSVP) 을 위해서는, data 품질이 data 수 보다 더 중요하더라.
- 데이터 품질(quality):
데이터가 실제로 모델이 학습해야 하는 다운스트림 태스크와 얼마나 밀접하게 연관되어 있는지, 혹은 데이터가 얼마나 정보량이 풍부하고 노이즈가 적은지를 의미 - 데이터 양(quantity): 단순히 데이터셋에 포함된 비디오의 총 개수를 의미
- 데이터 품질(quality):
- pre-training 데이터셋와 target dataset의 domain shift가 중요한 고려 요소이더라.
- 예를 들어, Kinetics-400(일반적인 행동 인식 데이터셋)과 Something-Something V2(일상적 상호작용을 포함한 데이터셋)는 도메인이 다릅니다.
- 도메인이 다를 경우, 사전 학습된 모델이 특정 도메인에서 학습한 특징을 다운스트림 태스크에 일반화하기 어려워집니다.
- 요약하면, 내가
Kinetics-400데이터셋으로 엄청난 양으로 SSVP를 해도, Something-Something V2 다운스트림 테스크에서는 잘 작동하지 않을 수 있다는 의미- 그래서, pre-training 할 떄, 이미지 품질이 좋은 데이터셋으로 학습해야 -> zero-shot transfer 성능이 좋아집니다.
- VideoMAE의 대응 방식:
- VideoMAE는 높은 마스킹 비율(90~95%)을 통해 모델이 데이터의 핵심적인 특징만 학습하도록 유도합니다.
- 이는 특정 도메인에 지나치게 의존하지 않고 일반적인 시공간적 패턴을 더 잘 학습하게 만들어 도메인 차이에 대한 민감도를 줄입니다.
2.2. 비디오 데이터와 이미지 데이터의 차이
- 비디오 데이터가 30fps면, 인접한 프레임끼리는 별 차이가 없음.
- 30fps로 두고 SSVP을 수행하면, static or slow motion의 특징에 집중한 embedding을 생성해버리는 위험성이 있음
- 그래서, 논문에서는 4 stride(Kinetics), 2 stride(SSV2)로 비디오 원본 데이터에서 샘플링함.
3. Method
3.1. 네트워크 구조
- DeepSpeed framework를 사용함 (faster training을 위함)
- ImageMAE와 다르게, VideoMAE는 성능을 위해 deep decoder (4 block) 가 필요했음.
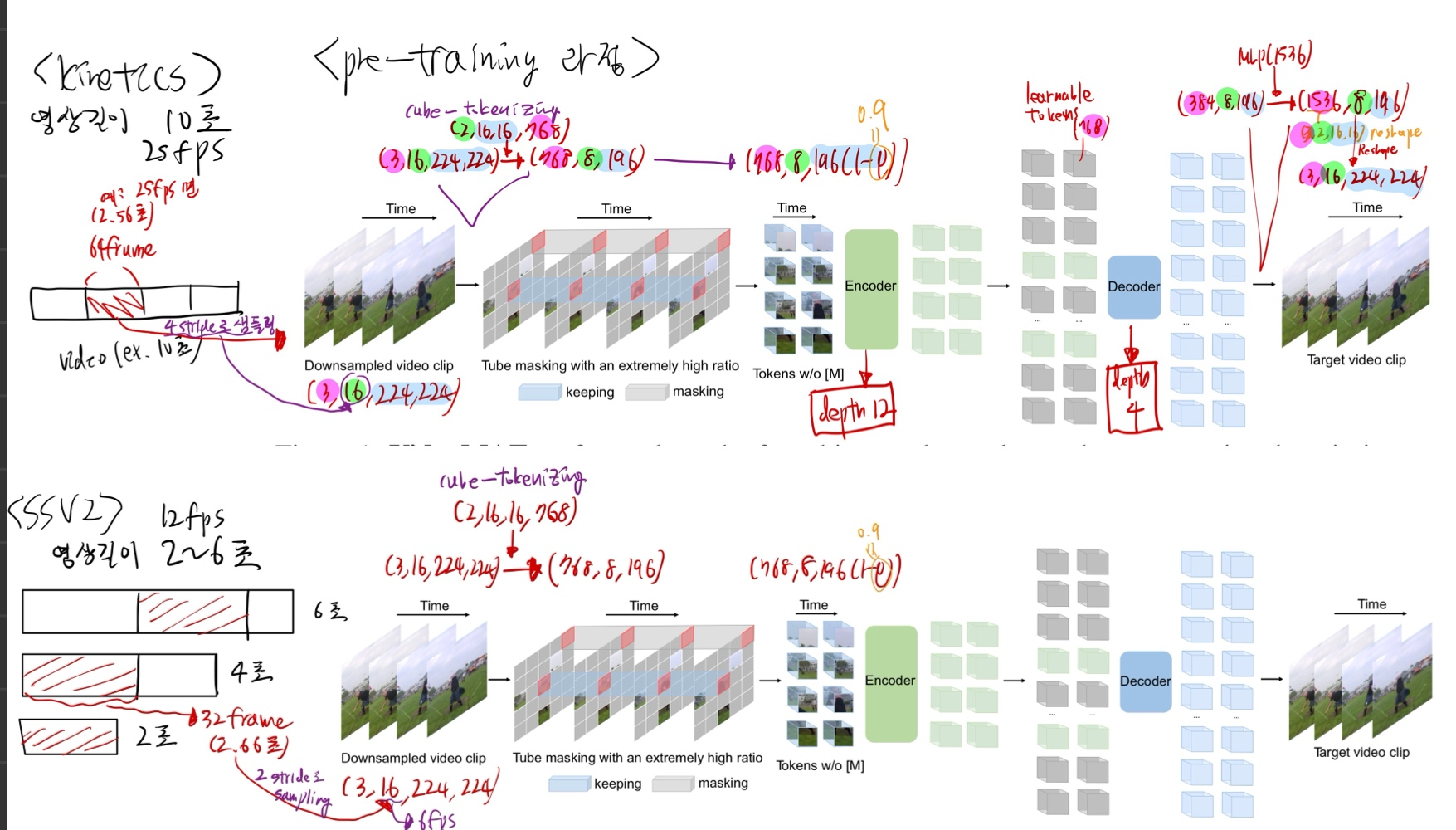
3.2. Pre-training 과정
"Strided temporal sampling strategy"
Formally, one video clip consisting of t consecutive frames is first randomly sampled from the original video V .
We then use temporal sampling to compress the clip to T frames, each
of which contains H × W × 3 pixels.
In experiments, the stride τ is set to 4 and 2 on Kinetics and Something-Something, respectively
- 여러 데이터셋으로 한번에 Pre-training을 하지 않았습니다!! Foundation Model이 아닙니다!!
- Attention mechanism으로는, joint space-time attention을 적용
- 시간, 공간 token들을 전부 self-attention 한다는 뜻이다.
- jointspace-time attention은 제곱의 연산량을 가져가지만, masking을 90% 정도 진행하기 때문에, attention으로부터 발생하는 cost를 줄일 수 있음
- batch size: 1024
비디오 데이터의 특성을 활용한, masking
Temporal redundancy- semantics은 시간 축에서, 매우 느리게 변화합니다.
- 프레임을 많이 보는 것은, 모델이 학습하는 입장에서 난이도가 낮으므로, 프레임을 적게 보는 것이 효과적
- masking ratio 90-95% 정도로 적용.
- image MAE는 75% 정도의 masking을 사용했었다.
- 높게 가져간 이유? Temporal redundancy 로 인해, 단일 이미지 내에서 masking을 유추하는 것보다, 참고할 수 있는 힌트 정보가 더 많으므로
Temporal correlation- 이를 극복하기 위해, tube masking을 진행해야 합니다.

데이터 전처리
- flip augmentation 수행하고, MultiScaleCrop 사용함
- MultiScaleCrop
- 원본 비디오의 가로 세로 비율을 고정한 채, 짧은 쪽 길이를 다양하게 줄이는 방식입니다.
- 그리고, 그 줄인 비디오 프레임을 224 by 224로 crop합니다.
Kinetics
- 원본 비디오에서 4 stride로 sampling (25 fps -> 6.25 fps)
- 한번에 16 frame을 input으로 넣음 (그럼
연속적인 64 frame(2.56초) 길이 짜리 view(클립))
SSV2
- 원본 비디오에서 2 stride로 sampling (12fps -> 6 fps)
- 한번에 16 frame을 input으로 넣음 (그럼
연속적인 32frame (2.66초) 길이 짜리 view(클립)
결론
- 두 데이터셋 모두, 각 프레임 간 시간 간격은 1/6.25 ~ 1/6 초로 거의 비슷함.
- 그리고 한번에 넣는 비디오가 커버하는 시간 길이도 2.56~2.66초로 거의 비슷함.
3.3. fine-tuning 과정
- 위 pre-training 아키텍쳐에서, encoder 부분만 활용합니다.
- encoder을 frozen 시키진 않고, end-to-end learning을 수행합니다.
- 100 epoch
- ViViT 과 같은 방식으로 action classification을 위한 supervised-learning을 수행합니다.
SSV2 으로 fine-tuning
- TSN[75] 기반
uniform(sparse) sampling- 영상 클립에서 고르게 떨어진 시간 간격으로 일부 프레임만 추출하는 방식. 이는 비디오 내의 빠른 동작 정보를 놓칠 가능성이 있습니다.
uniform(sparse) sampling
-
비디오 분할 (Segmentation):
긴 비디오를 총 K개의 동일한 길이의 구간(segments)으로 나눕니다. 예를 들어, 비디오가 L개의 프레임으로 구성되어 있다면, 각 구간의 길이는 약 L/K 프레임이 됩니다. -
스니펫 추출 (Snippet Extraction):
각 구간에서 하나의 스니펫(snippet)을 선택합니다. 스니펫은 단일 프레임일 수도 있고, 짧은 연속 프레임(예: 5프레임)일 수도 있습니다.
학습 단계에서는 보통 각 구간 내에서 랜덤하게 (randomly) 선택하여 다양한 temporal 변화를 학습하도록 하고,
테스트 단계에서는 보통 구간의 중앙값을 선택하는 방식(중심 샘플링)을 사용할 수 있습니다. -
Uniform Sampling의 장점:
- 전체 커버리지: 비디오 전체에서 고르게 샘플을 선택함으로써, 중요한 액션 단서가 어느 구간에 존재하더라도 포착할 수 있습니다.
- 고정된 계산 비용: 모든 비디오에서 샘플의 개수 K가 동일하므로, 비디오 길이에 상관없이 모델의 입력 크기와 계산 비용이 일정합니다.
-
위 샘플링한 것들을 network input으로 넣어줍니다.
-
Multiscale Vision Transformers 를 따라 했다고 함
Kinetics-400로 fine-tuning
- 아래 논문들에서 사용한 dense sampling을 했다고 함.
- 아마 pre-train 시 썼던 sampling 방법과 똑같은 것 같음
3.5. inference 시
- 2 clips × 3 crops on SSV2
- 5 clips × 3 crops on K400