0. reference
1. methodology
- 파란색(초록색 형광펜): 제안 기술 1
patch merging - 주황색: 제안 기술 2
shift windows transformer
- 파란색(초록색 형광펜): 제안 기술 1
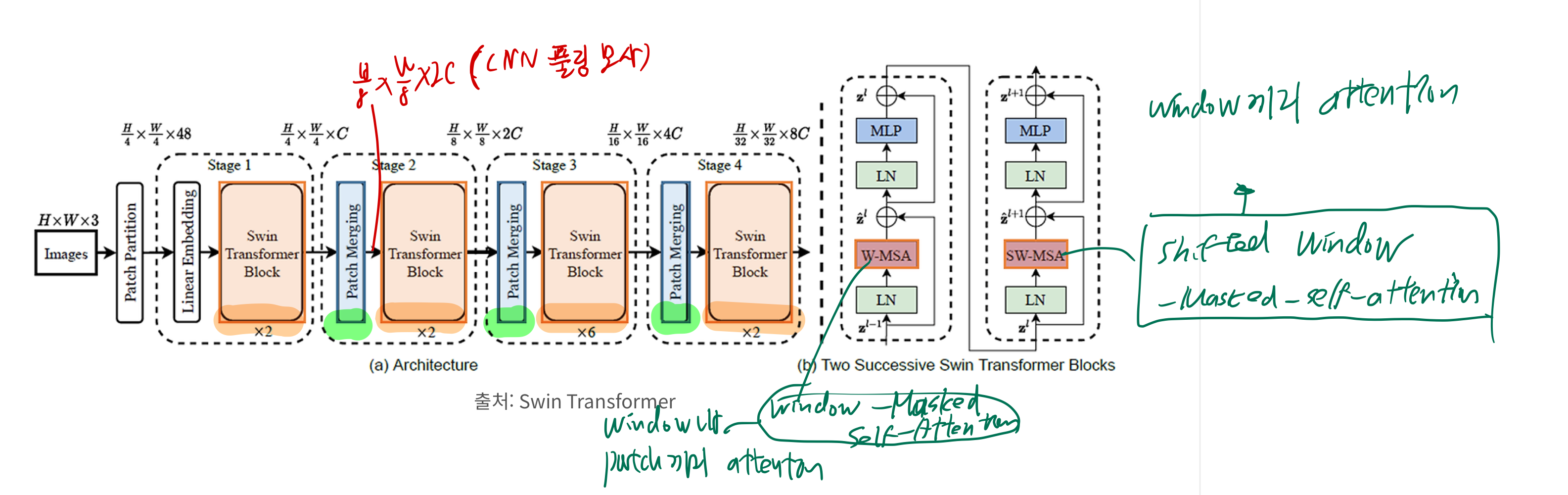
1.1. 제안 기술 1: patch merging
- CNN은 계층적으로 깊어지면서, 이미지의 해상도는 줄어들고 receptive field(네트워크의 특정 뉴런이, 입력 이미지에서 영향을 받는 영역)은 커짐.
- 이러한 계층적 pooling 구조를 Transformer에 도입한 것이 SWIN에서 주장하는 첫번째 기술
- 도입 목적/효과/이유
- 계층이 깊어질수록 -> 줄어든 해상도에서 attention을 수행하기 떄문에, 속도에 이점이 있다. (계산효율성 증대, 메모리 사용량 감소)
- 계층별로 다양한 Representations을 학습할 수 있음
- 디테일 위주 -> 큰 그림 위주
- 위 그림에서, patch merging 맨 왼쪽 블럭의 input은
h/4 * w/4 * C이고, output은h/8 * w/8 * 2C 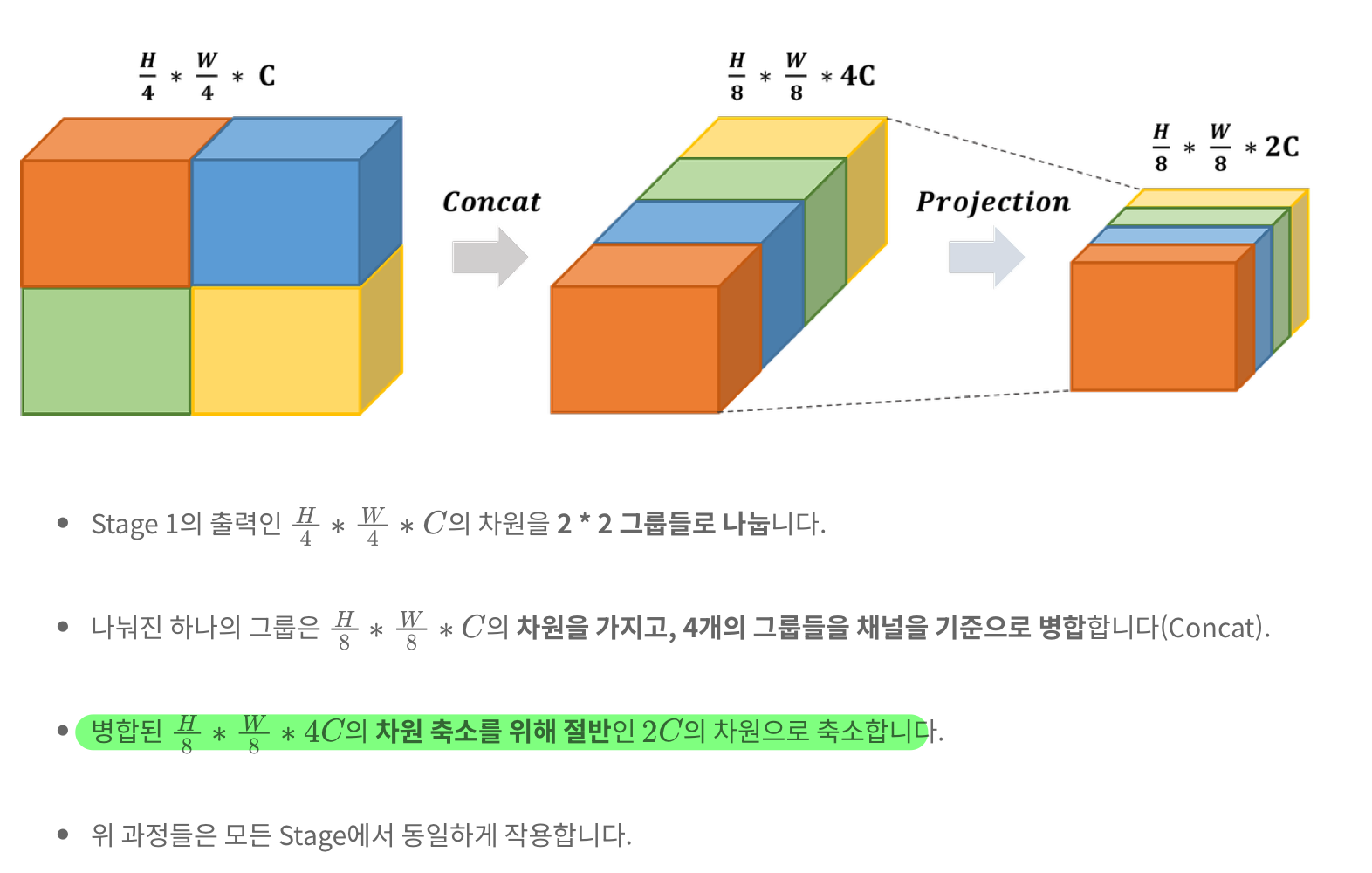
1.2. 제안 기술 2: shift windows transformer
- ViT는 patch 단위로, patch끼리 attention을 수행하기 때문에, attention 연산량이 너무 큼
- swin transformer은, window개념(M by M 개의 patch)를 도입하여, 연산량을 줄였다고 함.
- window 내에서 patch끼리 attention을 수행한 후,
- 위 그림에서
W-MSA
- 위 그림에서
- window끼리 attention을 추가로 수행 (이 떄, shift window 기법 사용)
- 위 그림에서,
SW-MSA - 모든 window 끼리의 attention을 의미하는 것은 아니다.
- 위 그림에서,
- window 내에서 patch끼리 attention을 수행한 후,
- 아래 그림은, 빨간색 영역 내(window 내)에서만 attention을 수행한다고 이해하면 됨.
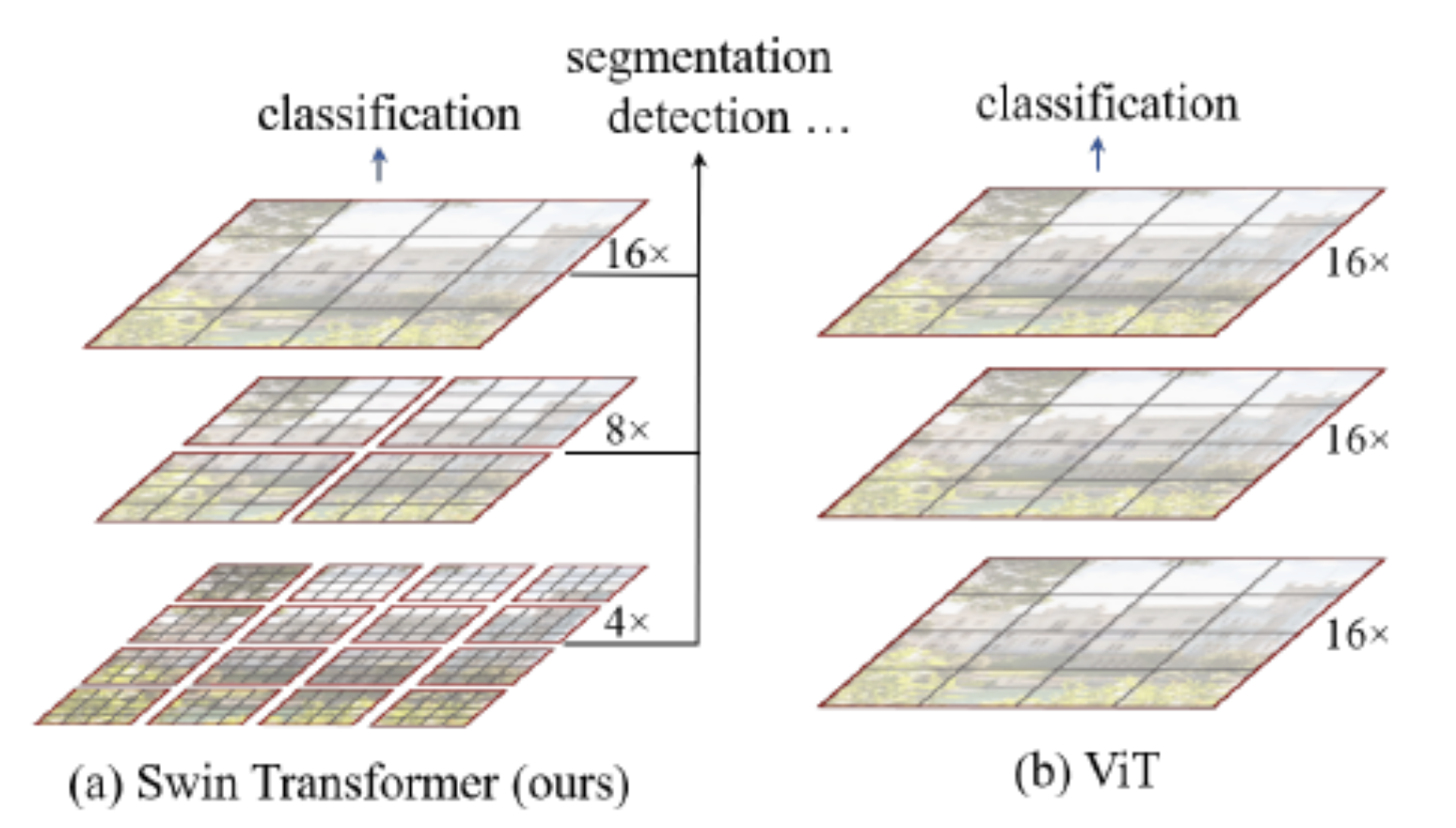
- 아래 왼쪽 그림은, 계층적 구조(제안 기술1)를 나타내기도 함
- 아래 왼쪽 그림은,
W-MSA만 표시했고,SW-MSA는 표시하지 않은 그림으로 추측됨
1.2.1. shift window?
1.2.1.1. naive shifted window
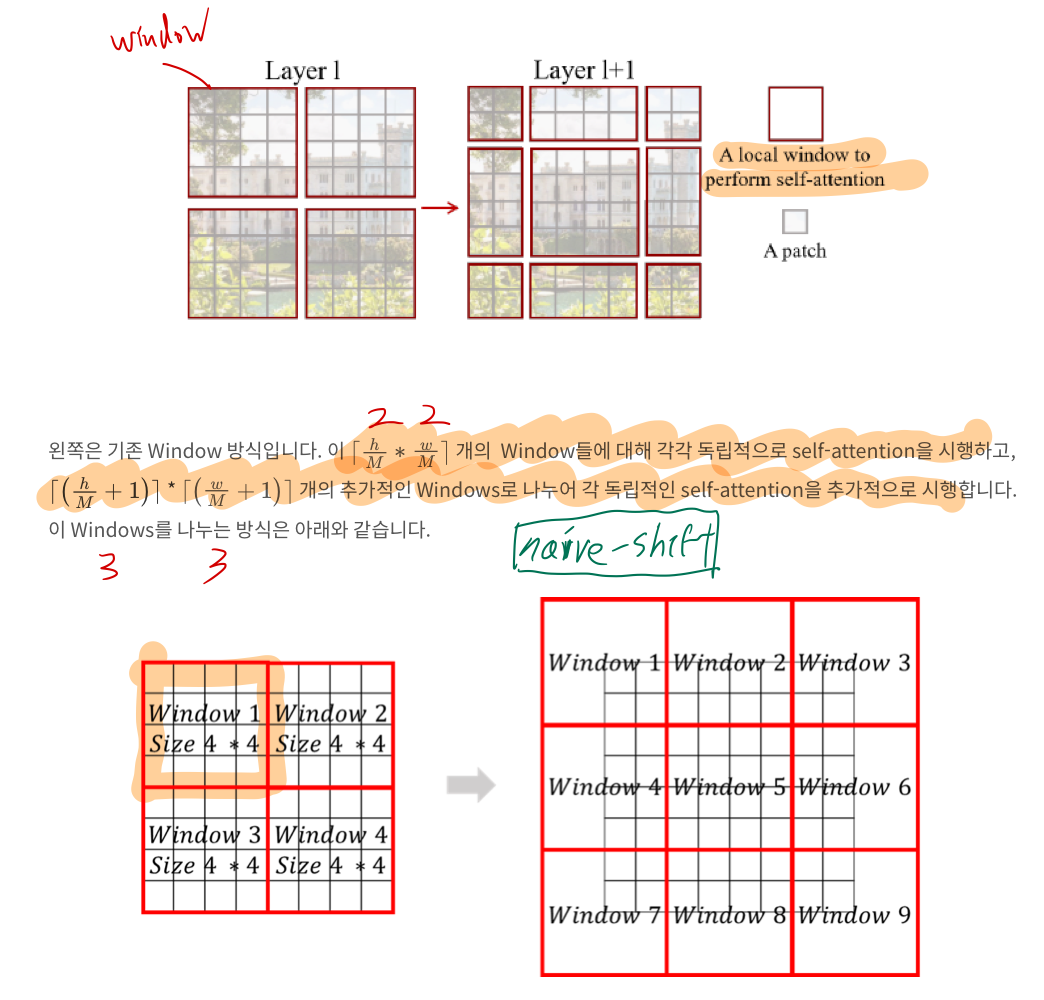
- 분할되는 기준: 먼저 중앙에 하나의 window를 배치
- 이 방식을 좀 더 개선하면 -> 계산량을 더 줄일 수 있을 것 같아!
1.2.1.2. cycling shifted window
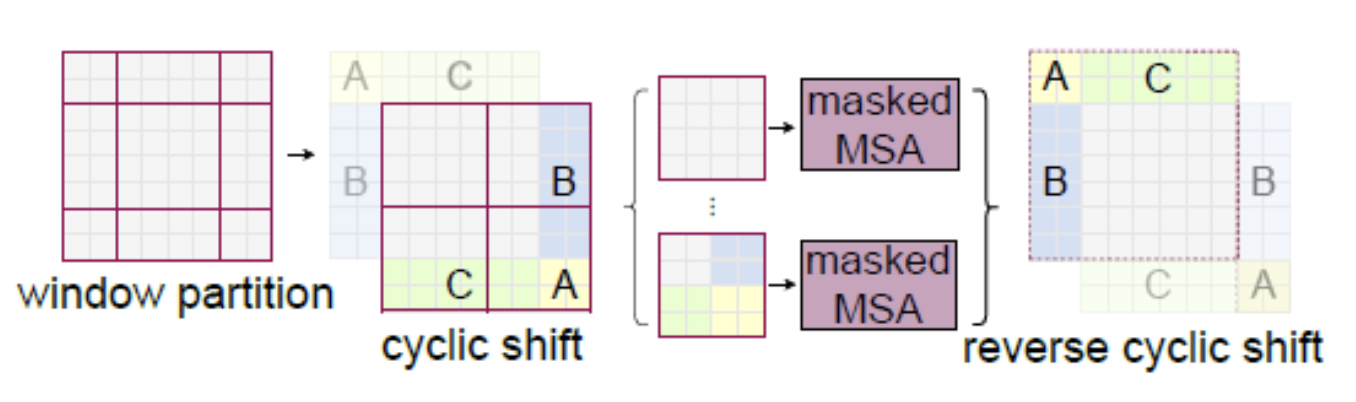
- 위 그림의 좌상단 partition 부분을, 우하단으로 cycling shifting
- masking
- 전 단계(
W-MSA)에서 self-attention 진행한 부분은, 중복 수행하지 않기 위해 masking을 수행합니다.- TODO: 이 부분 필요하면 좀 더 공부?
- 전 단계(
1.3. 제안기술 3: Relative position bias
- 개요
- 각 self-attention 단계 시(
W-MSA던,SW-MSA던), query와 key를 곱해서 attention score을 계산해야 함. - 그 경우, relative position bias를
attention score에 더해줌으로써, ViT의 posotional encoding을 대체하면서도, 성능을 높임.
- 각 self-attention 단계 시(
- 왜 필요해?
- 기존
- 기존의 Transformer는 위치 정보를 직접적으로 처리하지 않으므로, 입력 순서나 위치에 대한 정보를 추가로 제공해야 합니다.
- 이를 해결하기 위해 다양한 위치 인코딩 기법이 사용됩니다. (예: positional encoding)
- 단점: 그러나 절대 위치 인코딩은 입력 시퀀스의 길이가 변하거나, 패치가 이동할 때 위치 정보를 유연하게 반영하지 못할 수 있음 (예: vision transformer)
- 예: ViT는 fine tuning 시, input-image의 해상도가 학습했을 떄와 달라지면, positional encoding을 interpolation 해줘야 합니다.
- https://velog.io/@hsbc/Vision-Transformer
- 제안
- 위 단점을 극복하고, 성능까지 올립니다.
- 기존
- 한 window(M by M개의 patch) 관점에서 보겠습니다.
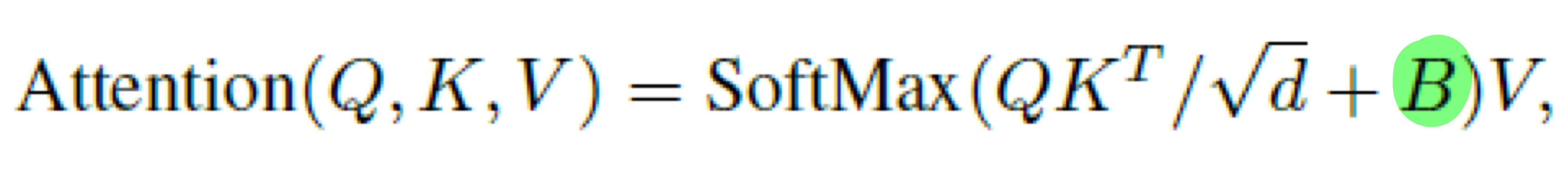
- 위 식의 B를 더해주는 것이 최종 결과물입니다. 여기서 B는
relative position bias입니다. - 이
relative position bias은relative position index와learnable bias matrix을 통해 구해집니다. relative position index
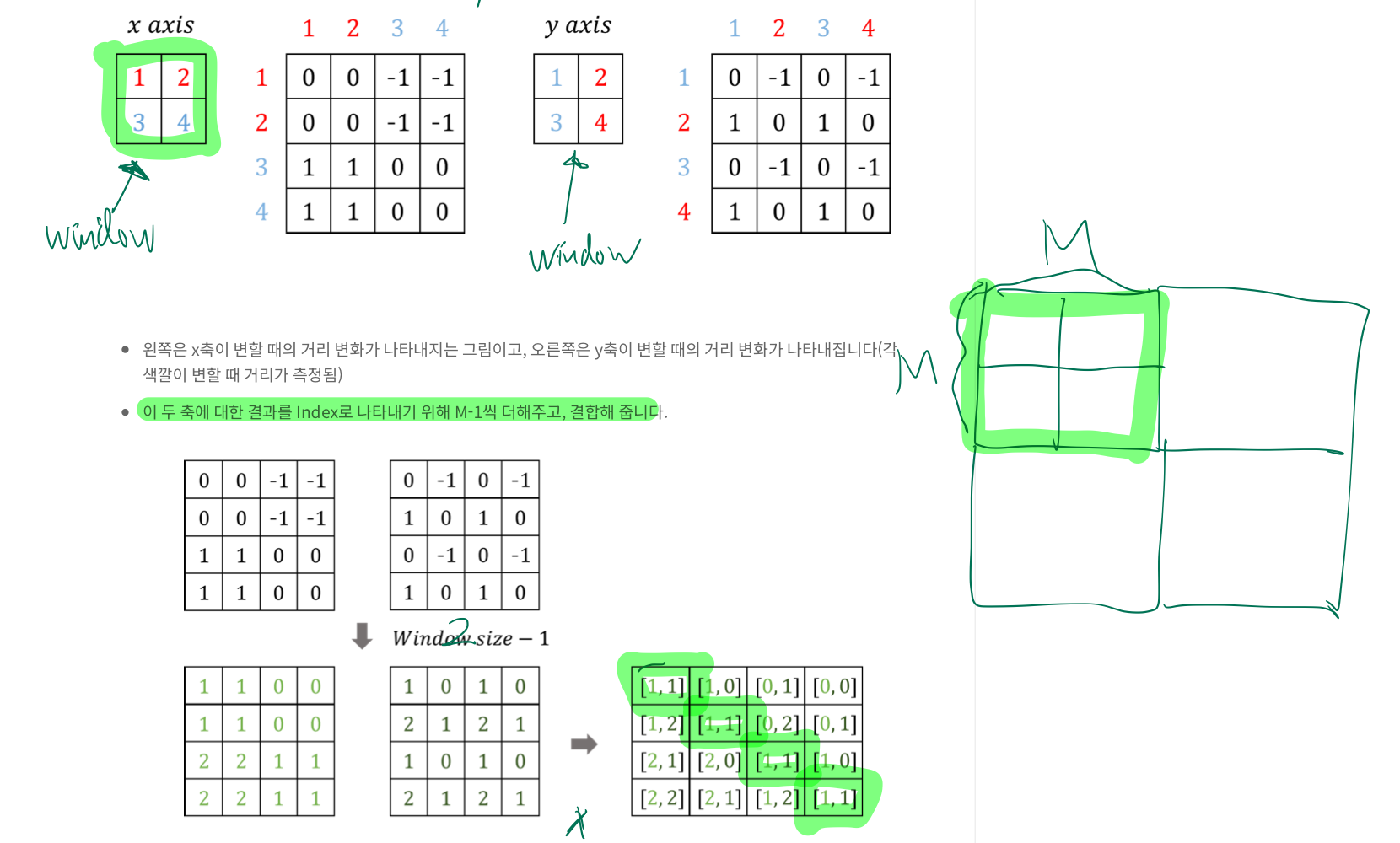
- 한 window 내에서, M by M개의 patch는 각 패치별로 관계를 맺을 것이고, 그러면 총
M^2 by M^2의 관계가 형성됩니다. (attention score을 떠올리면 이해가 쉬워짐) - 각 patch별로, 나머지 patch들과의 물리적 거리를 나타내는 것이
M^2 by M^2shape의relative position index입니다. - 아래 그림을 보면서 이해합니다.
learnable bias matrix
- 위
relative position index의 각 셀의 값이 x,y Index이고,learnable bias matrix에서 그 x,y Index에 해당하는 값을 읽어서 곱해줍니다. 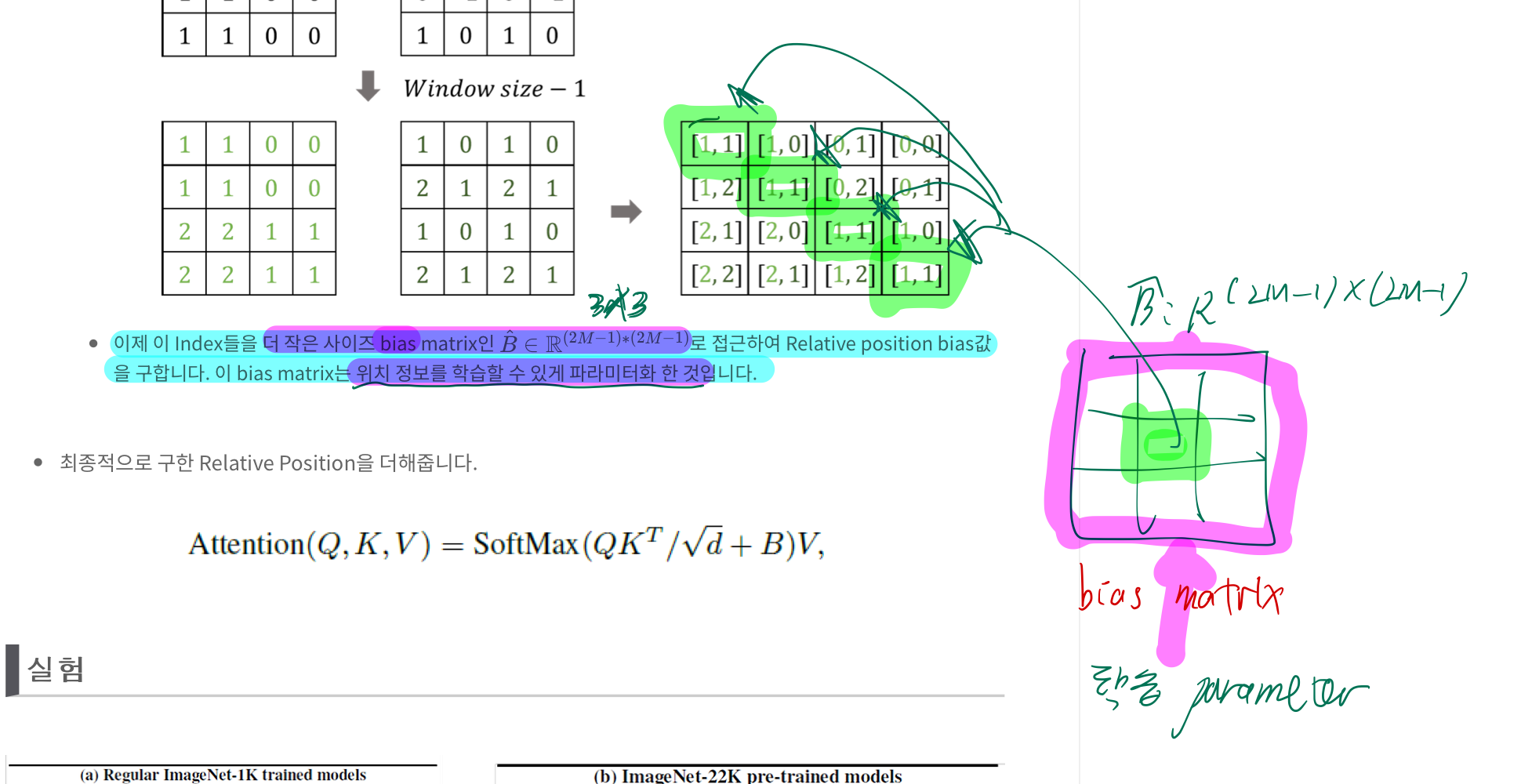

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것