COMEDIAN: Self-Supervised Learning and Knowledge Distillation for Action Spotting using Transformers
action recognition in videos
목록 보기
7/24
- Temporal Action detection
- Temporal Action Localization
- Temporal Action Localization aims to detect activities in the video stream and output beginning and end timestamps. It is closely related to Temporal Action Proposal Generation.
- https://paperswithcode.com/task/action-recognition
- Temporal Action Proposal Generation
Figures
Overall
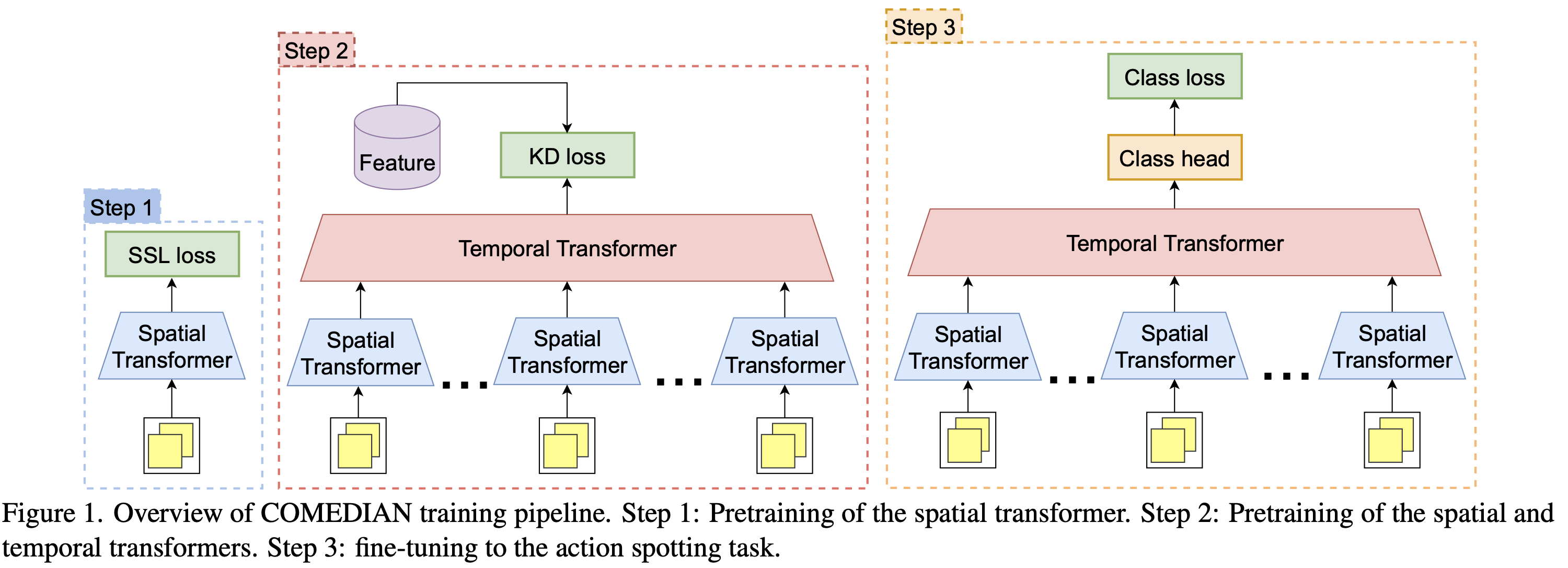
Pretraining Spatial Transformer (Contrastive Learning을 통해)
- MoCo: https://velog.io/@hsbc/MoCO-Momentum-Contrast-for-Unsupervised-Visual-Representation-Learning
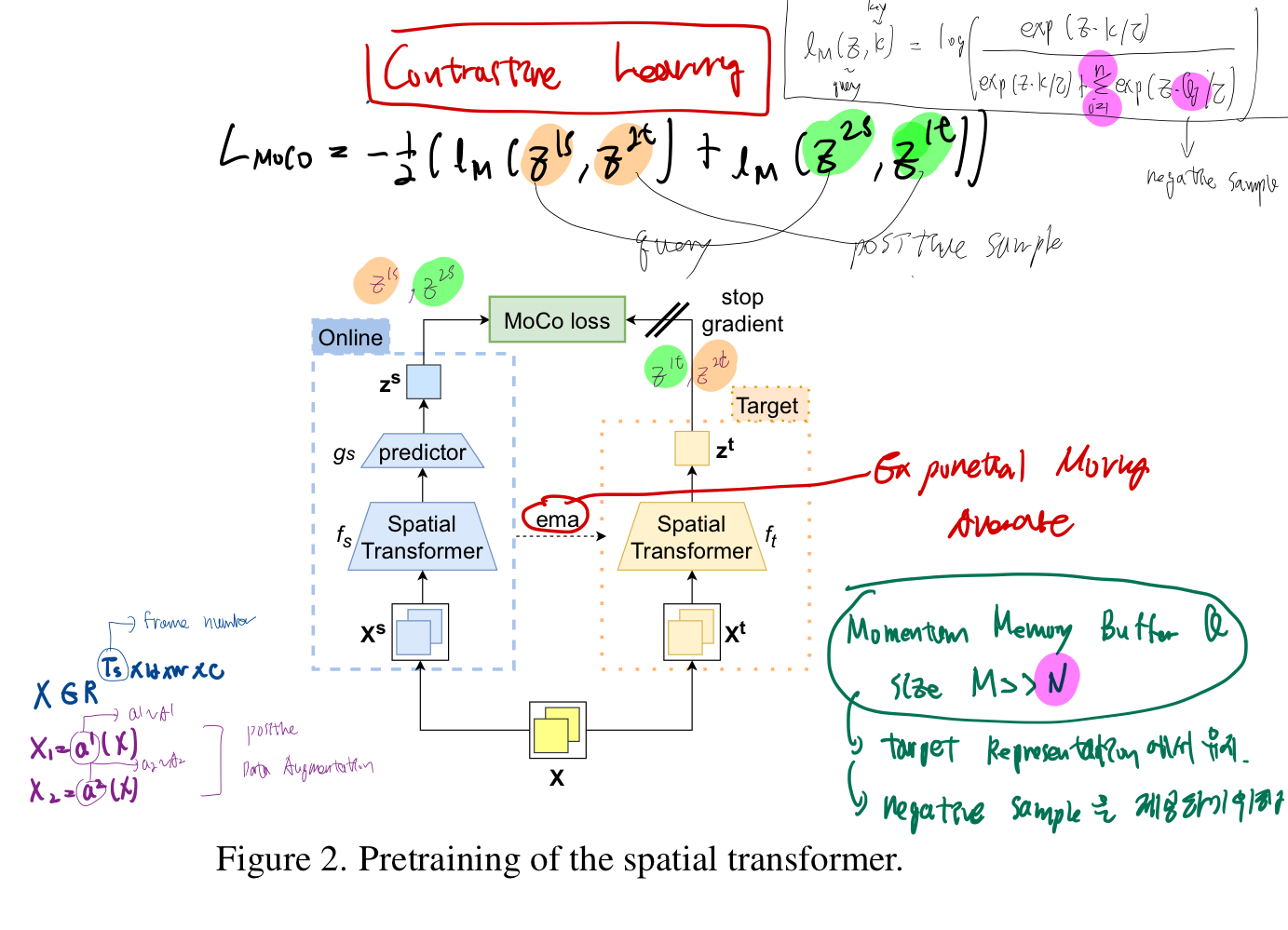
- Spatial Transformer은
small temporal widnow(예: 3초 동안의 풋살 이미지)에 대한 공간 정보를 추출 -> 하나의 token embedding으로 출력 - 그림 설명
- 먼저
small temporal widnow(예: 3초 동안의 풋살 득점 이미지)를 a1, a2 두가지 data agumentation 분포에 통과시켜, 2개의 augmented positive data input을 만듭니다. - input: 위에서 말한 positive augmented input 2가지를, Online branch에도 넣고, Target branch에도 넣음.
- 대조군은 (dictionary queue 안에서 꺼냄) (Momentum Memory Buffer이라고도 불림)
- 예: 다른 장면의 풋살 장면 연속적인 3장
- 목표: Spatial Transformer의 weight를 pre-train
- 먼저
Spatial Transformer와 Temporal Transformer을 pretraining (KD를 통해)
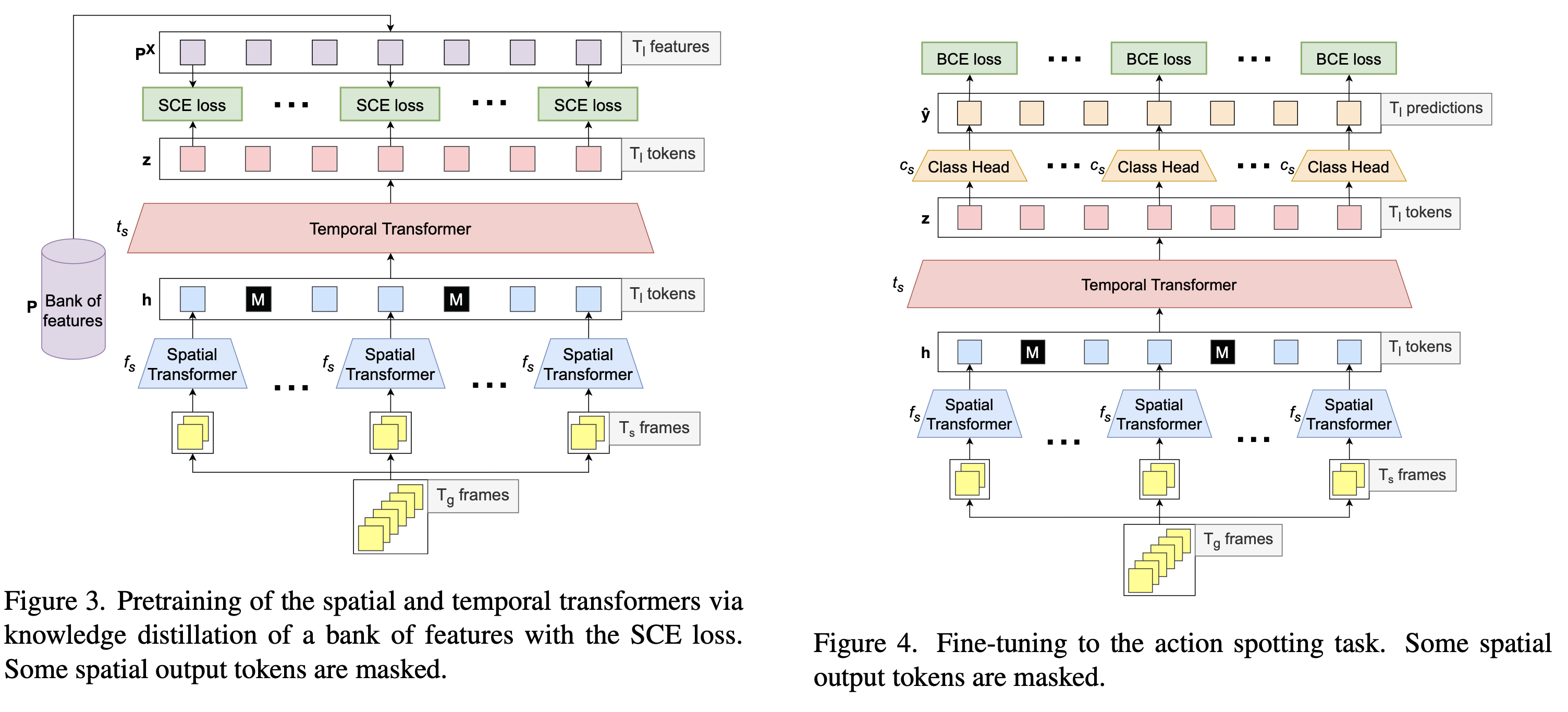
- 사전 훈련을 수행하기 위해, 우리는 SCE [15]를 따릅니다.
- 우리는 각 출력된 시간적 토큰 위에 프로젝터를 적용하고, 축소된 Baidu의 특징들로부터 정보를 추출
- 자세한 내용은 부가 자료에서 찾아볼 수 있습니다.
- 데이터 샘플링을 위해, 우리는 각 에포크마다 경기당 32초 또는 64 프레임의 150개 비디오를 무작위로 추출합니다.
Bank of features
- 우리는 Baidu [65]에서 사용된 특징들의 은행을 변경
- 이는 Kinetics400 [33]에서 사전 훈련된 5개의 모델을 Fine tuning 하여 얻는 것을 필요
- 이에는 두 가지 옵션이 있습니다:
- SCE [15]에서 사전 훈련된 R3D50의 추출된 특징들과,
- 그것의 액션 스팟팅 작업에 Fine tuning 된 버전
- R3D50에 사용된 클립들은 4초간 지속되며, 미세 조정은 중간 프레임에서 수행됩니다.
- 우리는 결과를 표 7에 보고합니다.
- Baidu의 특징들은 5개의 집합된 모델 덕분에 최고의 성능을 달성하지만,
- SCE 미세 조정된 것은 단 1개의 모델임에도 경쟁력 있는 성능을 달성하기에 충분
- 또한, 자기지도 학습 모델을 사용하는 것은 -2.1퍼센티지 포인트를 잃지만,
- 특징 추출을 위한 더 가까운 도메인에서 자기지도 학습 모델을 사전 훈련하는 쪽으로 흥미로운 전망을 열어줌.


abstract
라벨이 없는 비디오 데이터를 활용하여 트랜스포머의 초기화에 관련된 도전을 해결knowledge distillation로 프리트레이닝을 하는 것의 이점에 대한 종합적인 분석을 제공- 이는 비디오에서 특정 행동을 정확한 시간에 탐지하는 '액션 스팟팅' 작업을 위한
공간적-시간적 트랜스포머를 초기화하는 파이프라인 - COMEDIAN은 세 단계로 구성되어 있으며, 두 단계에서 트랜스포머를 초기화
- 1: 짧은 비디오를 입력으로 사용하여, 공간적 트랜스포머를 self-supervised manner으로 초기화
- 2: 사전 계산된 feature bank로부터의
knowledge distillation하여 공간적/시간적 트랜스포머를 초기화 - 마지막 단계에서는 이 트랜스포머들을 액션 스팟팅 작업에 맞게 fine-tuning
- COMEDIAN은 SoccerNet-v2 데이터셋에서 실험되었으며, 최고 수준의 성능을 보여주었습니다.
- 이 방법론은 pre-training 파이프라인의 여러 이점을 강조합니다.
- 예를 들어, 비 pre-training 모델보다 성능이 향상되고 학습이 더 빨리 진행됩니다.
- https://github.com/juliendenize/eztorch
1. Introduction
- 비디오 표현 학습을 위한 SSL: [15, 21, 52, 57] 읽어보자.
- 지식 전달(KD) [28]은 다른 네트워크나 모델 모음에서 지식을 전달함으로써
네트워크를 초기화하는 강력한 도구 네트워크가 어떻게 얻어지고 전달에 사용되는 손실에 따라,KD는 SL [53] 또는 SSL [22]로 간주될 수 있음
2. Related Work
Video Transformer
- 우리는 긴 비디오에서 장기적인 의존성뿐만 아니라, 짧은 기간 내에서의 양방향 의존성(즉, 가까운 시간대의 이벤트 간 관계)도 포착하고자 합니다.
- 따라서, 우리는 특별히 아키텍처를 변경하지 않고, 공간적-시간적 계층적 모델을 사용하여 이 두 가지 의존성을 모두 고려합니다.
계산량 적은 Transformer
- transformer의 계산량을 줄이기 위한 노력들
video transformer
- tokenizer을 조정함으로써 구현
- 역시, computationally heavy
- Vivit: http://openaccess.thecvf.com/content/ICCV2021/papers/Arnab_ViViT_A_Video_Vision_Transformer_ICCV_2021_paper.pdf
- http://proceedings.mlr.press/v139/bertasius21a/bertasius21a-supp.pdf
- https://openaccess.thecvf.com/content/CVPR2022/papers/Liu_Video_Swin_Transformer_CVPR_2022_paper.pdf
계산량 적은 video transformer
- https://openaccess.thecvf.com/content/ICCV2021W/CVEU/papers/Neimark_Video_Transformer_Network_ICCVW_2021_paper.pdf
- https://proceedings.neurips.cc/paper_files/paper/2021/file/6f2688a5fce7d48c8d19762b88c32c3b-Paper.pdf (우선순위 낮음)
긴 비디오 transformer
- 위 논문들은, 매우 짧은 input에 대한 트랜스포머들.
- 긴 비디오도 쓰고 싶으면, 아래 논문들을 봐라.
- https://openaccess.thecvf.com/content/CVPR2022/papers/Meinhardt_TrackFormer_Multi-Object_Tracking_With_Transformers_CVPR_2022_paper.pdf
- https://openaccess.thecvf.com/content/CVPR2022/papers/Wu_MeMViT_Memory-Augmented_Multiscale_Vision_Transformer_for_Efficient_Long-Term_Video_Recognition_CVPR_2022_paper.pdf
- https://proceedings.neurips.cc/paper/2021/file/08b255a5d42b89b0585260b6f2360bdd-Paper.pdf
- https://openaccess.thecvf.com/content/CVPR2022/papers/Yang_Recurring_the_Transformer_for_Video_Action_Recognition_CVPR_2022_paper.pdf
Pre-training
- 이미지 [17]와 비디오 [1] 트랜스포머에 대한 프리트레이닝: 대규모 데이터셋 [17]에서의 지도 학습(SL)이나 자기주도 학습(SSL) [7, 10]을 통해 필수적임
- 대조 학습(Contrastive Learning) [54]은 이미지 [6, 9, 16, 18, 25, 27]에서의 최신 SSL로서 비디오 [13, 15, 21, 37, 45, 46]에 적용
- Contrastive Learning: https://velog.io/@hsbc/Contrastive-Learning
- 이는 입력에 기반한 긍정적인 뷰의 표현을 끌어당기고 다른 많은 표현을 밀어냄
- 최근 SCE [15]는 Contrastive Learning과 함께, 예상된 인스턴스 간 관계를 활용하여 성능을 향상시킨다는 것을 보여주었습니다.
- 트랜스포머와 함께 등장한 Masked Modeling 접근 방식은 대조 학습보다 지역적 특징을 학습하는 데 더 나은 성능을 보였습니다 [2,26,42,64].
- 이는 입력의 일부를 마스킹하고 픽셀 수준(MAE [20, 26, 52])이나 특징 수준 [22, 57], 또는 시각적 토큰 [50, 56]( 이미지를 작은 조각(토큰)으로 나누고, 이들 중 일부를 마스킹)을 예측하여 신호를 재구성
- https://velog.io/@hsbc/Masked-Modeling
- 그러나 이러한 방법들은 비디오에 많은 중복이 존재한다고 가정하는데, 이는 적은 뷰 변화가 있는 짧은 비디오에서는 맞지만, 축구 경기와 같은 복잡한 비디오에서는 성립하지 않습니다.
- 마지막으로, 지식 전달(KD) [28]은 선생님 또는 선생님 모델 모음에서 학생에게 정보를 전달하는 또 다른 프리트레이닝 접근 방법으로, 지도 학습(SL) [53] 및 자기주도 학습(SSL) [19, 22, 34, 43]에 성공적으로 적용
- 공간적 및 시간적 특징을 별도로 또는 해체하여 글로벌 표현을 학습하는 다양한 접근 방식이 등장했습니다 [30, 44].
- 특히 [63] proposes a multi-step pretraining method that decouples spatial and temporal information through two different networks recoupled via a self-distilled network.
- "self-distillation"은 모델이 자신의 출력을 사용하여 자기 자신을 재훈련하는 과정을 의미
- 여기서는, 공간적 및 시간적 정보를 모두 포함하는 하나의 통합된 모델을 만들기 위해 사용
- [62]는 모델 내에서 여러 계층에서 공간적 및 시간적 대조 학습을 수행하여 공간적 및 시간적 특징을 분리
- 우리의 작업에서는
- 공간적 트랜스포머: Contrastive Learning -> SSL 초기화로 계층적 모델을 프리트레이닝
- 같은 사진인데 각도만 다른거는 positive sample, 다른 사진은 negative sample
- 공간적 트랜스포머: Contrastive Learning -> SSL 초기화로 계층적 모델을 프리트레이닝
- 그 다음,
our global model is pretrained with a KD loss from an extracted bank of features aligned with all the output tokens.This KD-loss leverages temporal masking and soft contrastive learning to maintain local-temporal information enriched in a global context.비디오나 시퀀스 데이터의 세부적인 지역-시간적 정보를 전체적인 맥락에서 효과적으로 파악하도록
- 소프트 대조 학습과 KD:
KD에서는 교사 모델의 출력을 "소프트 타깃"으로 사용하여, 학생 모델이 이를 모방하도록 합니다.- 소프트 대조 학습을 적용하면, 학생 모델은 교사 모델의 출력과 유사한 출력을 생성하도록 학습되며, 이 과정에서 데이터의 미묘한 차이점을 더 잘 포착할 수 있습니다.
- Therefore, our goal is to learn multiple local-temporal representations, not one global.
- 모델이 전체적인 특성만을 추출하는 것이 아니라, 데이터의 세부적인 부분과 그 순간들의 특별한 특성들을 각각 파악하고 학습하는 것을 목표로 한다는 것

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것