TEMPORALLY PRECISE ACTION SPOTTING IN SOCCER VIDEOS USING DENSE DETECTION ANCHORS
action recognition in videos
목록 보기
8/24
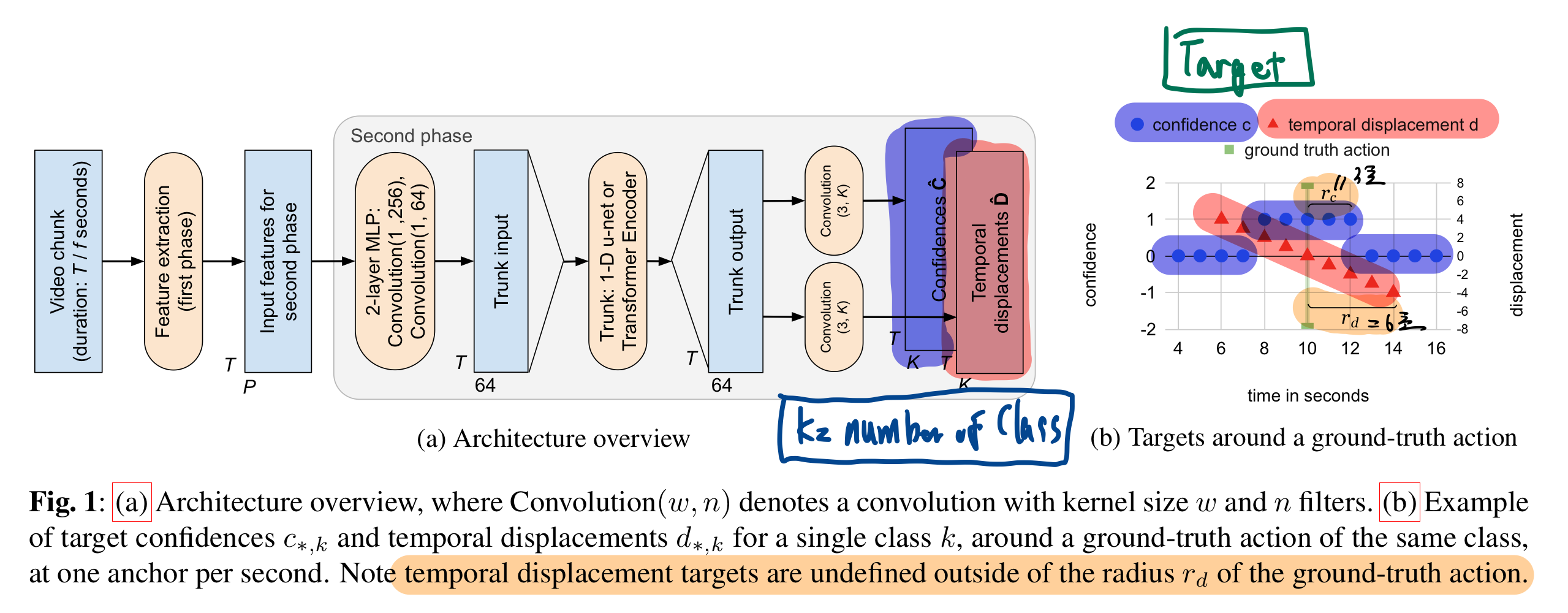
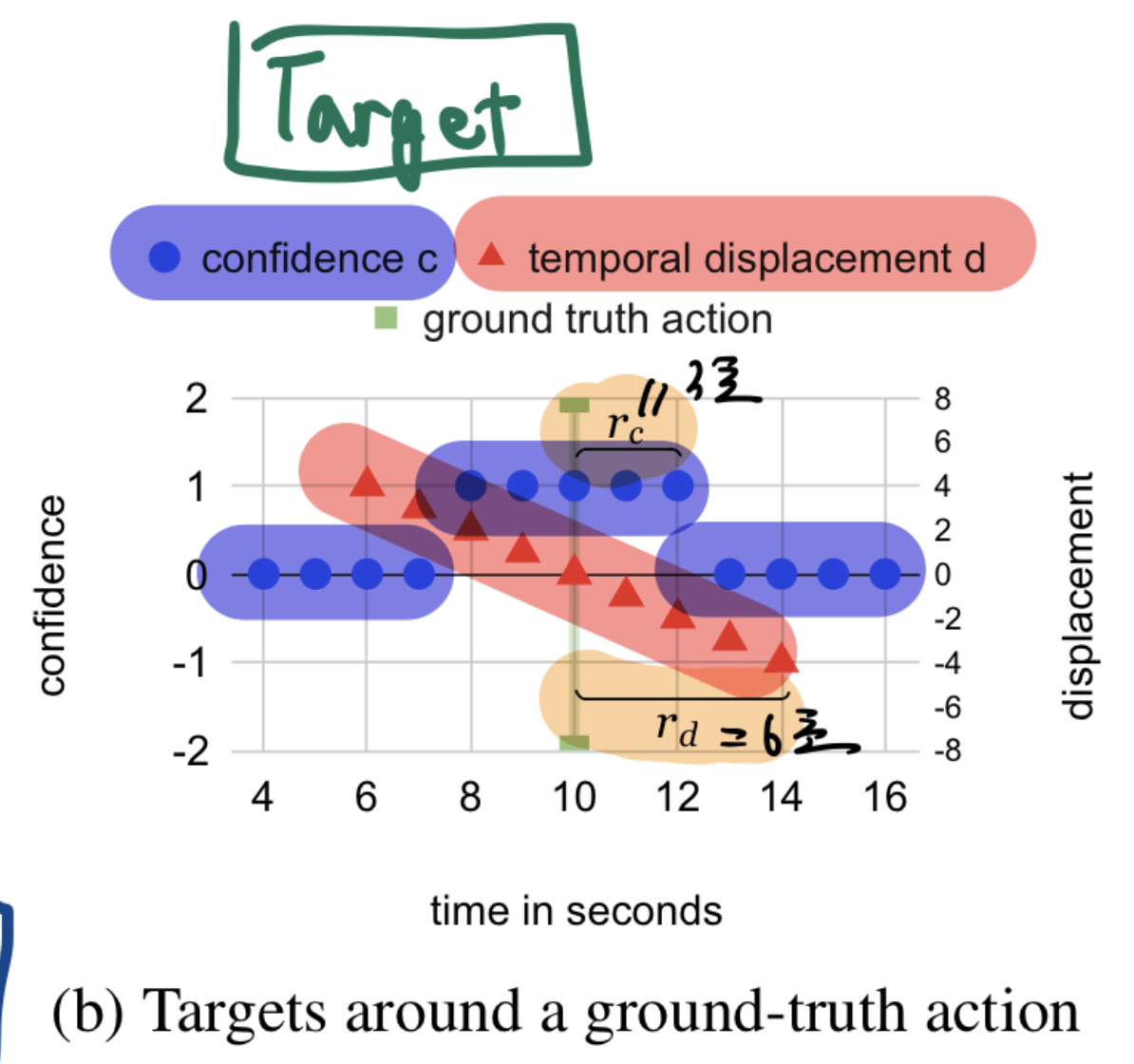
- 학습 시, 모든 anchor predictions 출력값을 이용해서, (후처리 없이) 바로 loss를 구했음.
1.1. pretrained feature 준비
- "RESNet-152 + PCA" features 준비
- "Combination"
- SoccerNet-v2에서 fine-tuned 된 모델들을 합침
- https://arxiv.org/pdf/2106.14447.pdf
- f = 1fps
1.2. 학습
- 학습 과정
- 1000 epoch
- 1 epoch = 32 iteration = 8192/256
- 8192개의 sampling된 video chunk를 사용
- 1 video chunk = 112초
- batch size = 256 video chunk
- 1000 epoch
- 학습은 2번 진행
- 이유? (내가 추론)
- 골일 것 같은 순간들 후보군 찾기를 먼저 수행 한 후,
- 찾은 후보군 중에서, 좀 더 정밀하게 goal 위치를 찾으려고 한듯
- 이유? (내가 추론)
1.2.1. 첫번째
- mixup data augmentation 수행
- https://velog.io/@hsbc/Mixup-Data-Augmentation
- 예: 골 장면과, 아무것도 아닌 장면을 7:3 비율로 섞은 이미지-라벨 pair을 생성
- Confidence Loss만 먼저 학습 시킴
1.2.1.1. Confidence Loss (L_c)
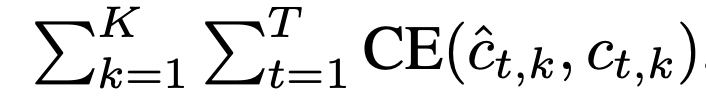
- cross entropy loss: https://velog.io/@hsbc/cross-entropy-loss
1.2.2. 두번쨰
- 그 후 Temporal displacement Loss 만 따로 학습시킴.
1.2.2.1. Temporal displacement Loss (L_d)
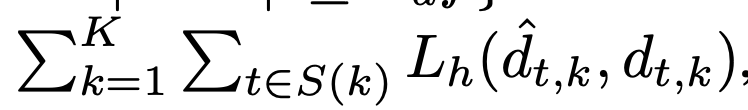
- Huber regression loss
- 오차가 적을 때는 MSE Loss
- 정답에 근접했을 때, 보다 더 정밀하게 예측하기 위해 MSE
- 오차가 클 때는 MAE Loss
- 잘못 예측된 outlier를 민감하게 고치려는 것을 방지하기 위해 MAE 적용
- 오차가 적을 때는 MSE Loss
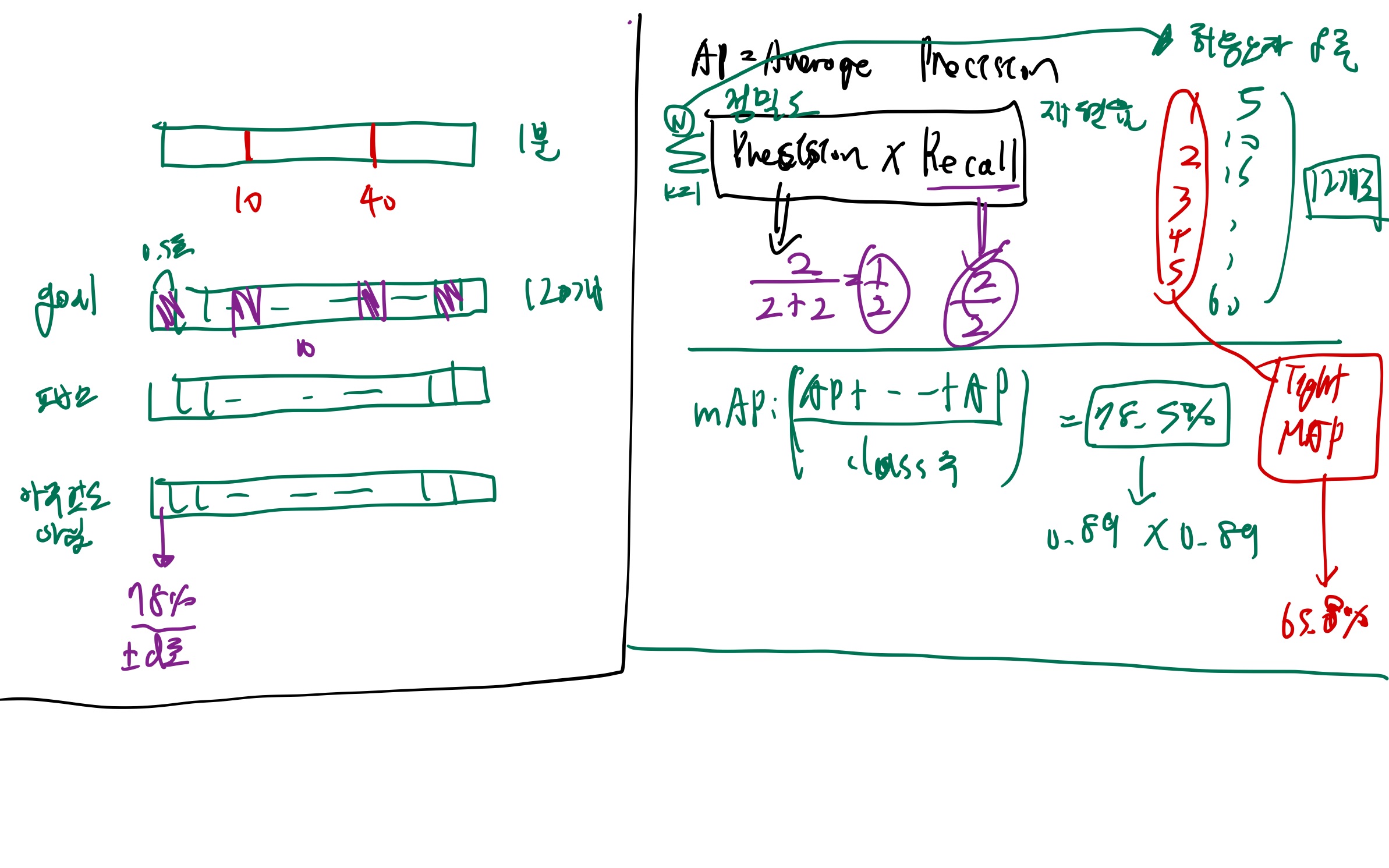
1.3. test
- test시, 2가지 post-processing 했음
- 1번: 첫 번째 단계에서는 각각의 신뢰도
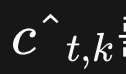 를 해당하는 이동량
를 해당하는 이동량 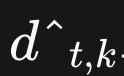 으로 이동시키며, 두 개 이상이 동일한 시간 위치로 이동될 경우 최대 신뢰도를 유지합니다.
으로 이동시키며, 두 개 이상이 동일한 시간 위치로 이동될 경우 최대 신뢰도를 유지합니다. - 2번:
각 클래스에 대해, 나눠서 NMS 적용합니다.- NMS window = 20초
- 1번: 첫 번째 단계에서는 각각의 신뢰도
- Adam OPtimizer + Sharpness-Aware Minimization (SAM) 적용
- decoupled weight decay.
1.4 실험 결과
- TE가 u-net의 정확도에 도달하기 위해 훨씬 더 많은 계산 비용을 필요로 한다는 것을 보여줍니다.
- SAM
- ResNet+PCA 특성에 SAM을 적용했을 때 큰 개선이 있지만, 이미 동일한 데이터셋에서 파인 튜닝된 Combination 특성에 적용했을 때는 매우 작은 개선만 있었습니다.
- Mixup
- 두 특성 유형 모두에서 작은 개선

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것