[22, 12/317] InternVideo: General Video Foundation Models via Generative and Discriminative Learning
[video] foundation model
목록 보기
1/9
0. 들어가기 전에
0.1. 논문 정보
- https://arxiv.org/pdf/2212.03191
- 2022/12, 317회 인용
- internvideo 2: https://arxiv.org/pdf/2403.15377
- 2024, 63회 인용
- https://github.com/OpenGVLab/InternVideo
- 1500 stars
0. 논문 4줄 요약
masked self-supervised pre-training+multi-modal constrastive pre-training을 결합하여 Video Foundation model을 pre-training 시키는 방법을 제시- 학습에 사용한 데이터셋 모두, 각 프레임 간 시간 간격은 1/6.25 ~ 1/6 초로 거의 비슷함. ( 6 ~ 7.25 fps). 그리고 한번에 넣는 비디오가 커버하는 시간 길이도 2.2~2.66초로 거의 비슷함.
- 비디오 task 10개에 대해 검증했으며, 비디오 task를 비디오 동작 인식 및 탐지, 비디오와 텍스트 연결 작업, 그리고 오픈월드 비디오 애플리케이션의 3가지 분류로 나누어 평가함. 비디오 테스크 정리
- vision foundation model의 pretrained weight를 활용하여, Video Foundation model을 학습 시키는 방법론 제시 (Local & Global Spatiotemporal Modules)
1. abstract
-
기존 Vision Foundation 모델의 한계
- 대부분의 기존 비전 기반 Foundation 모델들은 이미지 데이터를 중심으로 학습하고 활용됩니다.
- 하지만 이런 접근 방식은 움직이는 장면과 복잡한 상황을 포함하는 비디오 데이터를 이해하는 데는 한계가 있습니다.
-
InternVideo의 제안
-
상호 보완적인 학습 방법
- InternVideo는 위 두 가지 학습 방식의 장단점을 결합하고 조정하는 방법을 논문에서 제시하여, 다양한 비디오 작업에서 필요한 정보를 효과적으로 학습할 수 있습니다.
-
InternVideo의 성과
- 비디오 동작 인식 및 탐지, 비디오와 텍스트 연결 작업, 그리고 오픈월드 비디오 애플리케이션과 같은 다양한 분야에서 성과를 냈습니다.
- 우리는
10개의 대표적인 비디오 작업과39개의 공개 데이터셋을 선택하여, 이를 세 가지 유형으로 분류- 총 39개의 비디오 데이터셋에서 기존의 최고 성능을 능가
- [참고] video task 정의: https://velog.io/@hsbc/Video-Task-전부-정리
- 한계점
- long-term video tasks 처리가 어렵다.
- 향후 연구 방향
- long-term + big scene foundation model의 연구가 필요
2. Introduction
- 이미지 Foundation model 연구는 활발한데, 비디오 Foundation Model 연구는 활발하지 않음
- 22년 12월 기준, 학계에서 비디오 Foundation Model의 연구가 활발하지 않은 이유 2가지
- 비디오 처리로 인한 높은 계산 부담
- 현재의 여러 비디오 벤치마크는, 이미지 백본에서 추출한 feature(Like CLIP)과 이에 따른 시간적 모델링을 활용하여 처리했더니 성능이 괜찮게 나왔기 때문
CLIP의 다양한 시간 변형 버전은 여러 비디오 벤치마크에서 좋은 성능을 제공 [5, 22].- [5]
- CLIP4Clip (2021년 논문, 500회 인용)
- https://arxiv.org/pdf/2104.08860
- https://github.com/ArrowLuo/CLIP4Clip
- 887 stars
- [5]
- 이러한 점에서,
simultaneous spatiotemporal learner(비디오 Foundation Model 학습을 의미)의 연구 수요가 적습니다.- 우리는 이러한 현상의 이유 중 하나로,
- 비디오 이해 능력을 측정할 수 있는 포괄적인 벤치마크의 부족에서 비롯되었다고 봄
- 다른 말로 하면, 사람들이 너무 쉬운 video task 벤치마크만 연구하고, 어려운 video task는 아직 연구하고 있지 않기 때문 (벤치마크가 없어서)
- 우리는 이러한 현상의 이유 중 하나로,
- 현재
비전 Foundation Model의 transfer ability는, 비디오 애플리케이션의 광범위한 스펙트럼을 고려할 때 비교적 제한적- 이러한 비전 Foundation Model들은 아래 task 정도만 집중하고 있음 [6, 8, 23, 24].
- action understanding tasks (e.g. action recognition, spatiotemporal action localization, etc)
- video-language alignment ones (e.g. video retrieval, video question answering, etc)
- 이러한 비전 Foundation Model들은 아래 task 정도만 집중하고 있음 [6, 8, 23, 24].
- 연구 커뮤니티는 보다 넓은 응용 도메인을 가능하게 하는(어려운 task를 해결할 수 있는) video foundation model을 갈망하고 있습니다.
- 본 논문에서는
비용 효율적이고 다목적 모델인 InternVideo를 통해 비디오 Foundation Model 연구를 진전시키고자 함 - 실현 가능하고 효과적인 시공간적 표현을 수립하기 위해, 우리는
video masked modeling과multimodal contrastive learning을 연구 video masked modeling- 장점: 비디오의 동적인 변화를 포착(e.g. 행동 이해)하는 데 효과적
마스킹된 부분을 예측하기 위해서는, 모델이 비디오 내의 움직임과 변화를 잘 이해해야 하기 때문
- 장점: 비디오의 동적인 변화를 포착(e.g. 행동 이해)하는 데 효과적
multimodal contrastive learning- 서로 다른 modality (예: 비디오, 텍스트)의 데이터를 사용하여 표현(representation)을 학습하는 방법
- 장점: 다른 모달리티 정보를 활용하여 학습하므로, video representation에 rich semantics 을 담을 수 있다.
- 예: "고양이가 소파 위에 누워있다"라는 텍스트와 함께 학습된 비디오 표현은, 단순히 "움직임" 정보뿐만 아니라, "고양이", "소파", "눕다"와 같은 의미 정보도 포함하게 됩니다.
- 단점: 구체적인 시공간 모델링을 간과
- 주로 의미적인 정보를 학습하는 데 중점을 두기 때문에, 비디오의 구체적인 시공간적 변화를 포착하는 능력은 상대적으로 부족할 수 있습니다.
- 기존 비디오 Foundation 모델의 일반화 성능을 높이기 위해,
- 우리는 이 두 가지 self-supervised 학습 방식을 결합한 unified representation learning을 제안
- 이러한
일반화된 representation을 검증하기 위해, 체계적인 비디오 이해 벤치마크를 제안
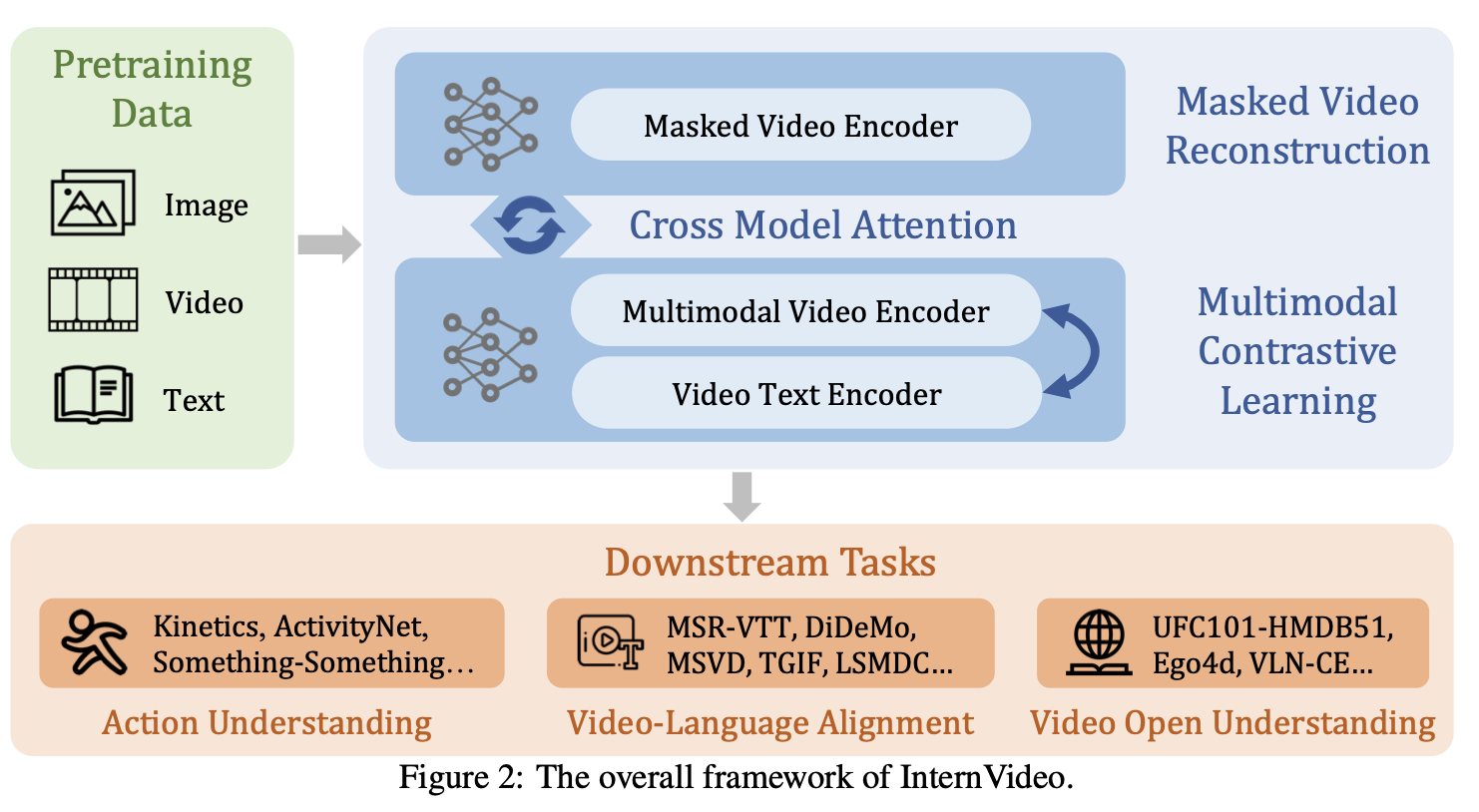
3. unified video representation (UVR) 학습 파이프라인
- InternVideo에서 우리는
unified video representation (UVR)학습 패러다임을 설계 (이제 구체적 방법에 대해 설명함!!) - 아래 3단계 파이프라인 학습 방법은, 학습 효율성 또한 높습니다.
3.0. 학습에 사용한 데이터셋
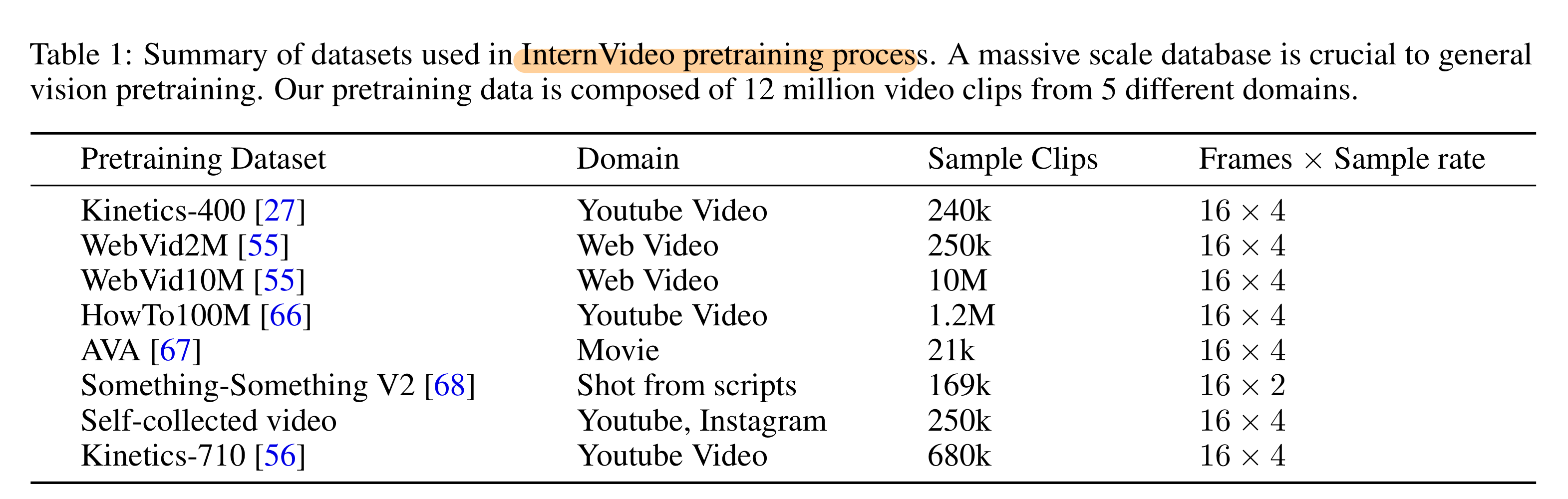
- SSV2는 16 frame 2stride로 학습했음을 주목하라!
- VideoMAE에서 적용한 것과 같음
- 참고
| Dataset | Input Resolution | FPS | 클립 길이 | 특징 |
|---|---|---|---|---|
| Kinetics‑400/600/700 | 원본 영상은 다양하지만, 모델 학습 시 일반적으로 224×224 (또는 256×256)로 리사이즈함 | 약 25 | 약 10초 | YouTube에서 추출된 액션 인식용 클립. 400~700개 클래스의 다양한 인간 활동이 포함됨 |
| Something‑to‑Something V2 (SSV2) | 원본은 다양하나, 후처리 시 224×224 또는 256×256으로 리사이즈하는 경우가 많음 | 약 12 | 평균 약 4초 (2~6초 범위) | 일상적인 사물 조작 및 상호작용과 같이 미세한 시간적 변화를 요구하는 액션 이해에 초점 |
| Charades | 원본 영상은 약 320×240이지만, 학습/평가 시 224×224 또는 256×256 등으로 리사이즈됨 | 약 30 | 평균 약 30초 | 실내에서의 일상 활동을 담은 긴 클립. 복잡한 활동과 상호작용을 포괄함 |
| AVA (Atomic Visual Actions) | 최신 연구에서는 높은 공간 해상도를 위해 448×448로 리사이즈하여 사용하는 경우가 많음 | 약 30 | 3초 (주석 프레임 중심, 전후 1.5초씩) | 영화와 같은 장편 영상에서 1초마다 주석이 달린 프레임을 중심으로, 3초 길이의 클립을 추출하여 행동 인식을 수행함 |
| WebVid‑2M / WebVid‑10M | 원본 비디오는 다양하나, 모델 학습 시 일반적으로 224×224 (또는 256×256)로 리사이즈함 | 원본은 다양 (학습 시 균일 샘플링) | WebVid‑2M: 평균 약 18초 WebVid‑10M: 유사 | 웹 스크래핑을 통해 수집된 대규모 비디오-텍스트 데이터셋. WebVid‑2M은 약 2.5M, WebVid‑10M은 약 10M 비디오-텍스트 쌍을 포함하며, retrieval 등 멀티모달 태스크에 활용됨 |
| HowTo100M | 원본 영상은 다양하지만, 모델 학습 시 일반적으로 224×224 (또는 256×256)로 리사이즈함 | 약 25–30 | 평균 약 4초 | YouTube 등에서 수집한 내레이션 영상 기반 데이터셋. ASR 전사 캡션을 활용하여 자동 생성된 텍스트로 구성되며, 대규모 instruction 데이터셋임 |
결론
- 표 1 데이터셋 모두, 각 프레임 간 시간 간격은 1/7.25 ~ 1/6 초로 거의 비슷함. ( 6~ 7.25 fps)
그리고 한번에 넣는 비디오가 커버하는 시간 길이도 2.2~2.66초로 거의 비슷함.
3.1. 개별 self-supervised training
- 이는
오토인코더(MAE)를 사용한 masked video modeling과multimodal contrastive learning의 두 가지 표현을 각각 pre-train 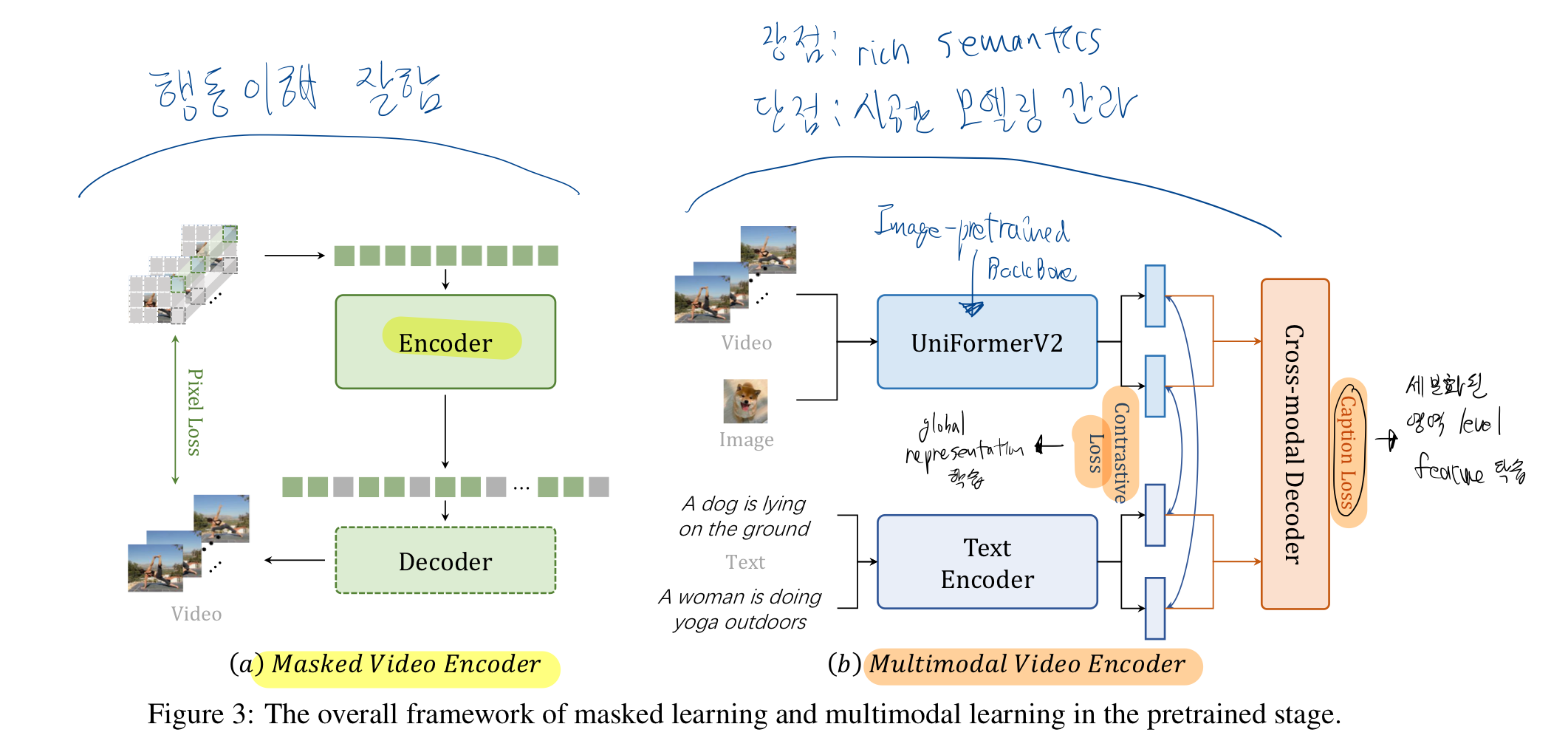
Masked Video pretraining
- UnlabeledHybrid 데이터셋 썼음: Kinetics 710, Something-Sometihng V2, AVA, WebVid2M, self-collected video
- 64개 A100 GPU로 학습함
MultiModal Pretraining
- Figure 3 (b)의 학습 과정이 잘 이해가 안되면?
- CoCa 을 참고하라!
- 기존의 image-pretrained backbones을 비디오 대조 학습에 확장
- CLIP 네트워크로 초기화했음
- WebVid2M, WebVid10M, HowTo100M 으로 pre-training 함
- 비디오-텍스트 데이터셋의 양이 크지 않으므로,
- 우리는 image-text 데이터셋인 LAION-400M 도 학습에 썼음
- 128개 A100 GPU로 2주 학습시킴
3.2. 개별 supervised training
- 이를 각각
supervised action classification로 fine tuning supervised action classification이 뭐라고 물으신다면?- VideoMAE와 multimodal contrastive learning을 통해 학습된 initial representation을,
- Action Classification 데이터셋(Kinetics-710을 이용함)을 사용하여 fine-tuning
- VideoMAE와 multimodal contrastive learning의 인코더(encoder)를 self-supervised learning 후에, 추가적으로 supervised learning 시키는 것
- Action Classification 데이터셋(Kinetics-710을 이용함)을 사용하여 fine-tuning
- VideoMAE와 multimodal contrastive learning을 통해 학습된 initial representation을,
- multimodal contrastive learning 할 때,
- 이미지 input 해상도를 224 by 224로 했고,
sparse sampling을 선택함. - TSN[75] 기반
uniform(sparse) sampling- 영상 클립에서 고르게 떨어진 시간 간격으로 일부 프레임만 추출하는 방식. 이는 비디오 내의 빠른 동작 정보를 놓칠 가능성이 있습니다.
- 이미지 input 해상도를 224 by 224로 했고,
uniform(sparse) sampling
-
비디오 분할 (Segmentation):
긴 비디오를 총 K개의 동일한 길이의 구간(segments)으로 나눕니다. 예를 들어, 비디오가 L개의 프레임으로 구성되어 있다면, 각 구간의 길이는 약 L/K 프레임이 됩니다. -
스니펫 추출 (Snippet Extraction):
각 구간에서 하나의 스니펫(snippet)을 선택합니다. 스니펫은 단일 프레임일 수도 있고, 짧은 연속 프레임(예: 5프레임)일 수도 있습니다.
학습 단계에서는 보통 각 구간 내에서 랜덤하게 (randomly) 선택하여 다양한 temporal 변화를 학습하도록 하고,
테스트 단계에서는 보통 구간의 중앙값을 선택하는 방식(중심 샘플링)을 사용할 수 있습니다. -
Uniform Sampling의 장점:
- 전체 커버리지: 비디오 전체에서 고르게 샘플을 선택함으로써, 중요한 액션 단서가 어느 구간에 존재하더라도 포착할 수 있습니다.
- 고정된 계산 비용: 모든 비디오에서 샘플의 개수 K가 동일하므로, 비디오 길이에 상관없이 모델의 입력 크기와 계산 비용이 일정합니다.
3.3. 두 representation 간의 상호 학습
- 두 representation 간의 상호 학습(cross-representation learning)을 기반으로 보다 일반화된 표현을 생성
cross-representation learning이 뭐라고 물으신다면?- Cross-Model Attention (CMA)이라는 특별한 모듈을 사용
- CMA는 두 표현(VideoMAE의 출력과 MML의 출력)을 입력으로 받아, 각 표현의 중요한 부분에 attention을 주면서 상호 간의 정보를 교환
- CMA의 학습 방식 = supervised learning
- CMA의 학습에도 Action Classification 데이터셋과 레이블을 사용
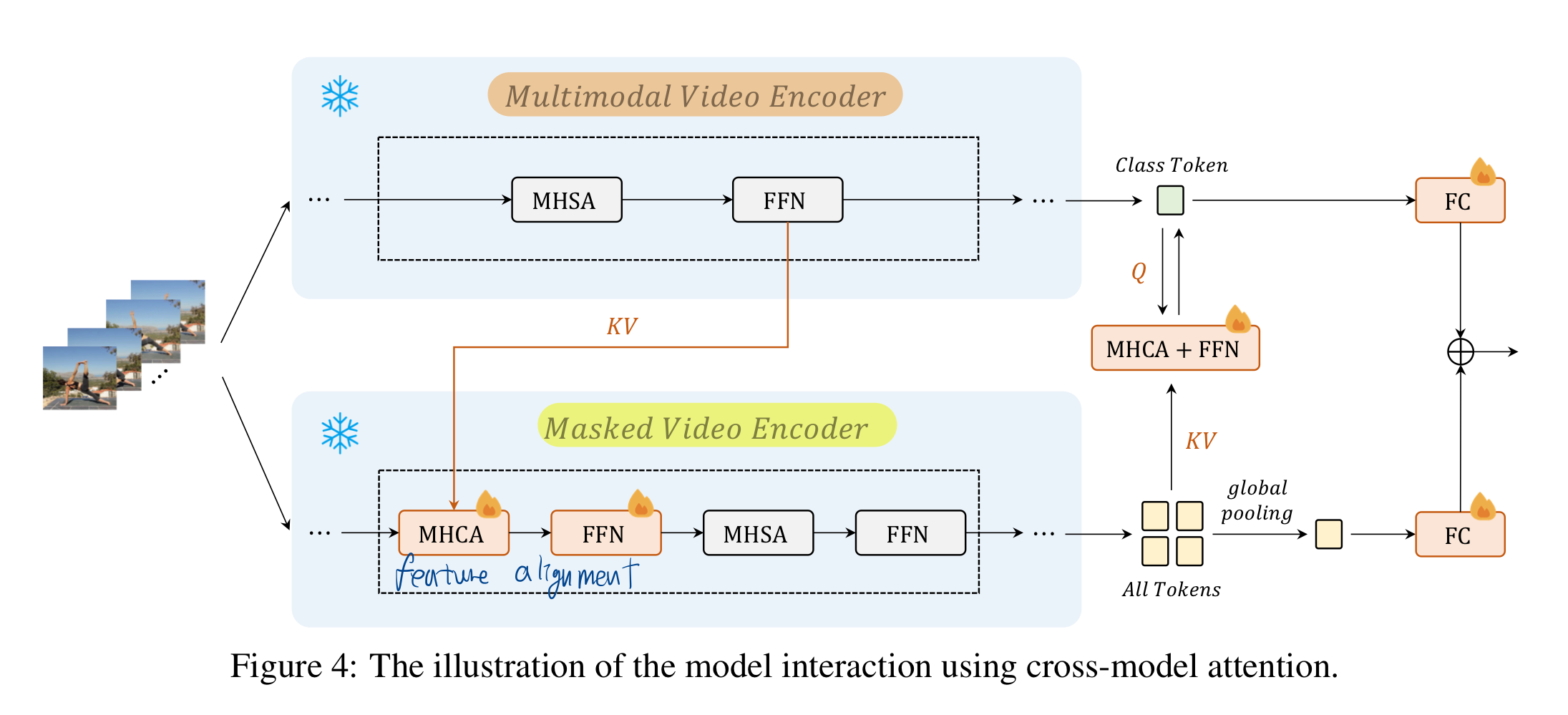
- 우리는 cross-model attention을 활용하여, 이 두 거의 고정된 인코더 사이에서 feature alignment을 수행
3.3.1. 왜 위와 같은 파이프라인을 가져가는가?
- MAE (Masked Video Encoder 학습에 사용)와 MML (Multimodal Video Encoder 학습에 사용)을 하나의 loss function으로 묶어서,
- 처음부터 동시에(jointly) 훈련하는 것은 여러 가지 이유로 어렵습니다.
- 이유
- 이 두 가지 학습 방식은 서로 다른 최적화 목표(optimization objective)를 가지고 있기 때문에,
- 하나의 loss function으로 묶어서 동시에 훈련하는 것이 비효율적이거나 성능 저하를 초래할 수 있습니다.
- 대규모 배치를 요구하는 MML:
- MML (특히, 대조 학습): 효과적인 학습을 위해서는 대규모 배치(large batch)가 필요합니다.
- MAE와의 결합으로 인한 구현 문제:
- MAE는 비디오의 일부를 마스킹해야 하기 때문에, 데이터 처리 파이프라인이 더 복잡해짐
- MML과 MAE를 동시에 훈련하려면,
- 두 가지 학습 방식에 맞는 데이터 로더(data loader), loss function, optimizer 등을 모두 고려해야 하기 때문에,
- 구현이 복잡해지고 오류가 발생할 가능성이 높아짐
- 이 두 가지 학습 방식은 서로 다른 최적화 목표(optimization objective)를 가지고 있기 때문에,
- 대신, 본 논문에서는,
- 이러한 잠재적인 훈련 대립 관계를 고려하여, 우리는 MAE와 MML을 별도로 훈련
- 두 모델의 훈련이 수렴한 후, 제안된 교차 모델 어텐션(CMA) 모듈을 사용하여 이들의 표현을 동적으로 결합합니다.
- 이는 MAE와 MML의 중간 수준 특징 간 교차 어텐션을 구현하며, 고수준 특징을 예측을 위해 적응적으로 융합합니다.
- 모델 수준의 표현 상호작용 단계에서는 MAE와 MML로 훈련된 백본을 고정(freeze)한 채, supervised learning에서 몇 에포크 동안 CMA만 업데이트
- 실험 결과, 이는 MAE와 MML 특징을 활용하는 데 있어 계산적으로 실용적이고 효율적인 방법임을 보여줌
3.4. 학습 실천 가이드라인
- 단순히 통합된 비디오 representation 학습 패러다임에 그치지 않고,
- 우리는
대규모 비디오 Foundation 모델을 효율적이고 실용적인 방식으로 훈련하기 위한 실천적 가이드라인을 제안
- 우리는
- 우리의 작업은 다음을 포함:
- 1)
VideoMAE를 확장 가능하게(scalable): 모델 및 데이터 크기에서의 확장 가능성을 탐구 - 2) existing image-pretrained backbones을 활용하는 효율적이고 효과적인 멀티모달 아키텍처 설계와 훈련 지침 제공
- 3) VideoMAE와 multimodal contrastive models에서 학습된 특징이 상호 보완적임을 실험적으로 확인하고, 기존 모델들을 조정(coordinating)하여 보다 강력한 비디오 표현을 도출하는 방법 연구
- 1)
- 구체적으로 설명해보면,
3.4.1. VideoMAE의 확장 가능성 연구:
- 우리는
훈련 비디오에서 적절한 다양성과 크기 확장이사용된 비디오 인코더의 scalability을 향상할 수 있음을 보여줌
3.4.2. vision foundation model의 비디오-텍스트 멀티모달 학습 학습을 위한 재사용:
- 출발점: Image-Pretrained ViT은 이미지의 공간적 특징(spatial features)을 포착하는 데 매우 효과적
- 목표: 이 ViT 모델을 비디오-텍스트 멀티모달 학습에 활용하여, 비디오의 시공간적 특징(spatio-temporal features)과 텍스트와의 의미적 연관성(semantic relationship)을 학습하는 것
- 이점
- 대규모 이미지 데이터셋으로 이미 학습된 지식을 활용하기 때문에, 비디오-텍스트 데이터가 적더라도 효과적으로 학습할 수 있습니다.
- 도전과제: 단순한 Transfer Learning 이상의 것이 필요
- Image-Pretrained ViT를 비디오-텍스트 멀티모달 학습에 그대로 적용하기는 어려움
- 이유
- 차원의 불일치: ViT는 이미지를 입력으로 받도록 설계되었지만, 비디오는 시간(temporal)이라는 추가적인 차원을 가지고 있습니다.
- Image-Pretrained ViT를 가져와서 MML pre-training 하는 방법 제시
- 구조적 및 최적화 customization을 적용하고, Local & Global Spatiotemporal Modules를 도입
- Local Module:
공간 어텐션 수행 한 후 -> 시간 어텐션을 수행하여, 계산 효율적으로 시공간적 특징을 학습 (ViViT의 2번쨰 아키텍쳐 처럼) - Global Module: 모든 프레임의 모든 패치 간의 관계를 고려하여, 장거리 의존성을 포착하고, 전체적인 맥락을 이해
- 이를 통해 학습 부담을 줄이고, 더 나은 다운스트림 성능을 제공

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것