[24,3][110] INTERNVIDEO2: SCALING FOUNDATION MODELS FOR MULTIMODAL VIDEO UNDERSTANDING
[video] foundation model
목록 보기
3/9
- https://arxiv.org/pdf/2403.15377v1
- https://github.com/OpenGVLab/InternVideo/tree/main/InternVideo2
- 1600 stars
-2. 교훈
-2.1. 논문의 한계
- internvideo2를 포함한 많은 video Foundation model은, input 이미지의 해상도로 224 by 224를 사용한다. 축구공이 보이지 않을까 걱정...
- 원본과 224 by 224는 차이가 엄청나다.
- 이 Foundation model을 쓸 수 있으려면
공을 detection/segmentation한 후, 공의 크기를 크게 변형한다.
-1. 논문 5줄 요약
- video foundation model / video language model(ViLM)을 학습하기 위해 ->
마스킹된 비디오 모델링,비디오-오디오-텍스트 대조 학습,다음 토큰 예측을 통합 프레임워크로 결합한 논문 - 비디오 인코더 뿐만 아니라,
오디오 인코더도 고려하여 학습하는 방법을 제시했고, ViLM에 유용함을 증명.speech(사람 말소리) encoder도 고려하여 학습하는 방법을 제시했지만, ViLM의 성능을 오히려 떨어뜨리는 것을 확인 - 멋진
비디오-text caption 데이터셋을 직접 만듦- 하나의 클립 안에서는 장면이나 내용이 급격하게 바뀌지 않는 데이터셋
- 비디오, 오디오, 스피치(말소리)를 모두 이용하여, 영상에 대한 (더 퀄리티 좋은) text caption을 생성하는 방법을 제시
0. abstract
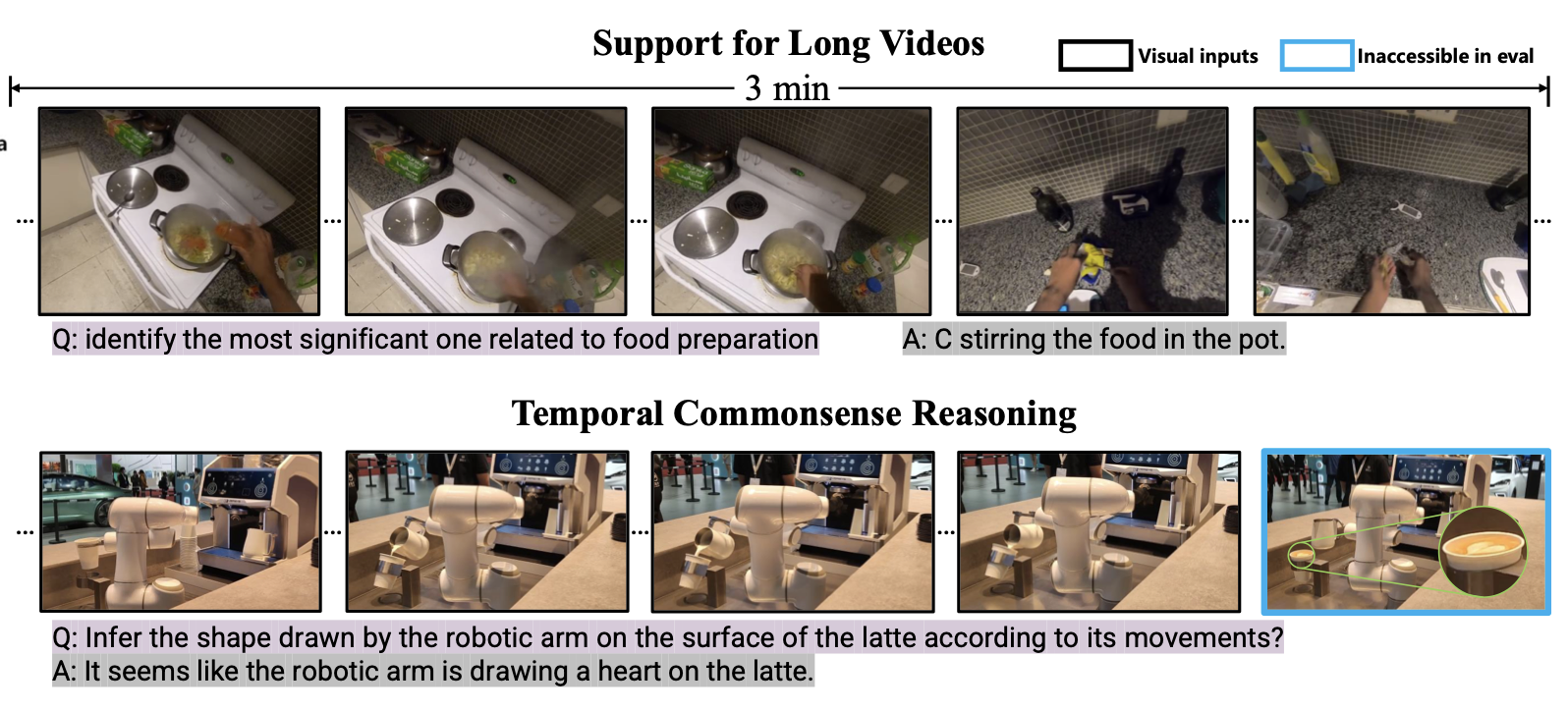
- 논문의 성과
- 3분 길이의 비디오를 처리 가능하다.
- 시간적 추론 성능이 증가했다.
마스킹된 비디오 모델링,비디오-오디오-텍스트 대조 학습,다음 토큰 예측을 통합 프레임워크로 결합- 논문에서는 비디오 학습 데이터셋을 제공했는데, 그 구성을 보면
비디오를 의미론적으로 나누고- 즉, 하나의 클립 안에서는 장면이나 내용이 급격하게 바뀌지 않고 자연스럽게 이어집니다. (시공간적 일관성)
- 이를 위해, 논문에서는 AutoShot이라는 temporal boundary detection model 을 사용했습니다.
- AutoShot은 픽셀 단위의 변화뿐만 아니라, 시간적 의미 변화(temporal semantic variations) 를 기반으로 비디오의 경계를 예측
- 비디오에 대한 캡션을 생성할 떄,
비디오-오디오-음성을 전부 고려한 캡션을 생성하여 시공간적 일관성을 우선시- 이를 통해 비디오와 텍스트 간의 정렬이 개선됨
- 결론:
새 비디오 데이터셋과여러가지 pre-training방법을 적용하니,다양한 비디오 관련 대화및긴 비디오 이해 벤치마크에서 높은 성능
- InternVideo2는 특정한 새로운 아키텍처 설계를 도입하지는 않습니다.
- 기존의 학습 기술을 활용하여 비디오 파운데이션 모델을 확장
- InternVideo2는
데이터 처리를 개선하는 데 중점
0. Limitation
- 이전 연구와 유사하게,
고정된 입력 해상도(224 by 224),샘플링 속도및고도로 압축된 토큰에서 비롯되는 한계를 겪고 있음- 풍부한 비디오 정보를 표현하고 미세한 세부 사항을 포착하는 능력을 제한
- InternVideo2는
Visual Reasoning에 일관성을 보이는Implicit World Model을 보장할 수 없습니다. (포괄적이고 일관된 이해를 달성하기 어렵다.)- Implicit World Model?
데이터로부터 학습을 통해 내재적으로 형성된+모델이 세상에 대해 가지고 있는 내재적인 지식과 이해- 예시: "사과는 스스로 움직일 수 없다.". "축구 센터백은 윙어보다 느린 편이다."
- Visual Reasoning?
- 비디오 정보를 기반으로 추론하는 능력을 의미
- 예를 들어, "두 이미지 속 물체가 같은 물체인지 판단하기", "비디오에서 다음에 일어날 일을 예측하기"
- Implicit World Model?
3. Method
3.0. Video Encoder
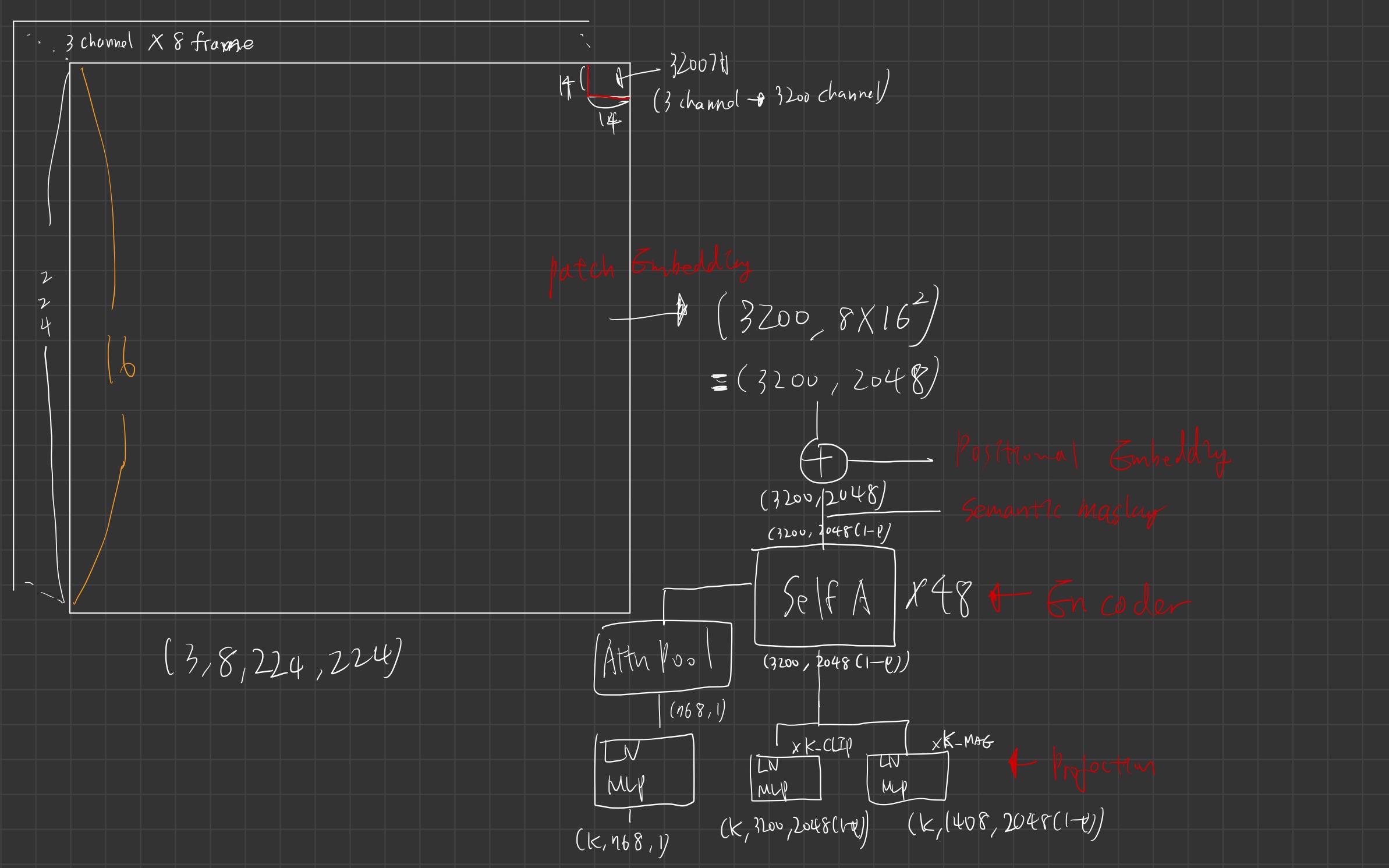
- InternVideo2에 사용된 비디오 인코더는 ViT
- input
- input format에 대해 깊게 알고싶으면 ViViT 참고
- 8 frame을 sparse sampling
- 224 by 224 이미지를 14 by 14 patch embedding 수행
- input format에 대해 깊게 알고싶으면 ViViT 참고
- 참고: class token 도입
- 전체 비디오 input이 어떤 클래스인지 유추할 수 있도록 돕는 token을 도입함

3.1. stage 1: Reconstructing Unmasked Video Tokens
- 우리는 InternVL (멀티모달 모델)과 VideoMAEv2(움직임 인식 모델) 을 teacher 모델로 두고, 우리의 모델을 student의 모델로 두어, distilation 방식으로 학습합니다.
- 먼저 우리 모델 (student)의 input을 각 프레임 중 20% 토큰만 마스킹시키지 않은 채로 입력해줍니다. (인코더에 통과시킴)
- 전문가 teacher 모델과의 증류(distillation, stage 1)를 위한 추가 projection layer을 추가로 사용 (위 표의 projection 파트)
- projection 파트의 output이
K*3200(or 1408) * 2048 (1-p)
- projection 파트의 output이
- 우리는 InternVL의 마지막 6개 레이어, InternVL의 최종 출력 토큰, 그리고 VideoMAE의 마지막 4개 레이어을 정렬
- 그래서 위 K는 각각 6과 4가 됩니다.
- InternVL의 최종 출력 토큰은 아마 class token 같은게 될 것 같은데, 이것도 정렬시켜준다는 뜻입니다.

- 전문가 모델의 unmasked 20% 부분과, student 모델의 20% 토큰 부분이 유사해지도록 학습.
- (개인적 추측) 그리고, 디코더를 둬서 나머지 80% 토큰을 맞추는 학습 objective function도 함께 둘 것으로 추측해봅니다.
3.1.1. 학습 데이터 셋
- Kinetics, Something-Something, Moments in Time 등에서 수집한 다양한 시점·길이·캐릭터 비디오로,
레이블 없이 마스크드 비디오 토큰 복원을 학습 - 유튜브에서 선별한 84.4만 개 비디오를 추가해 다양성과 비지도 학습 범위를 확장하여 비디오 작업 성능을 높였다.
3.2. Stage 2: Aligning Video to Audio-Speech-Text
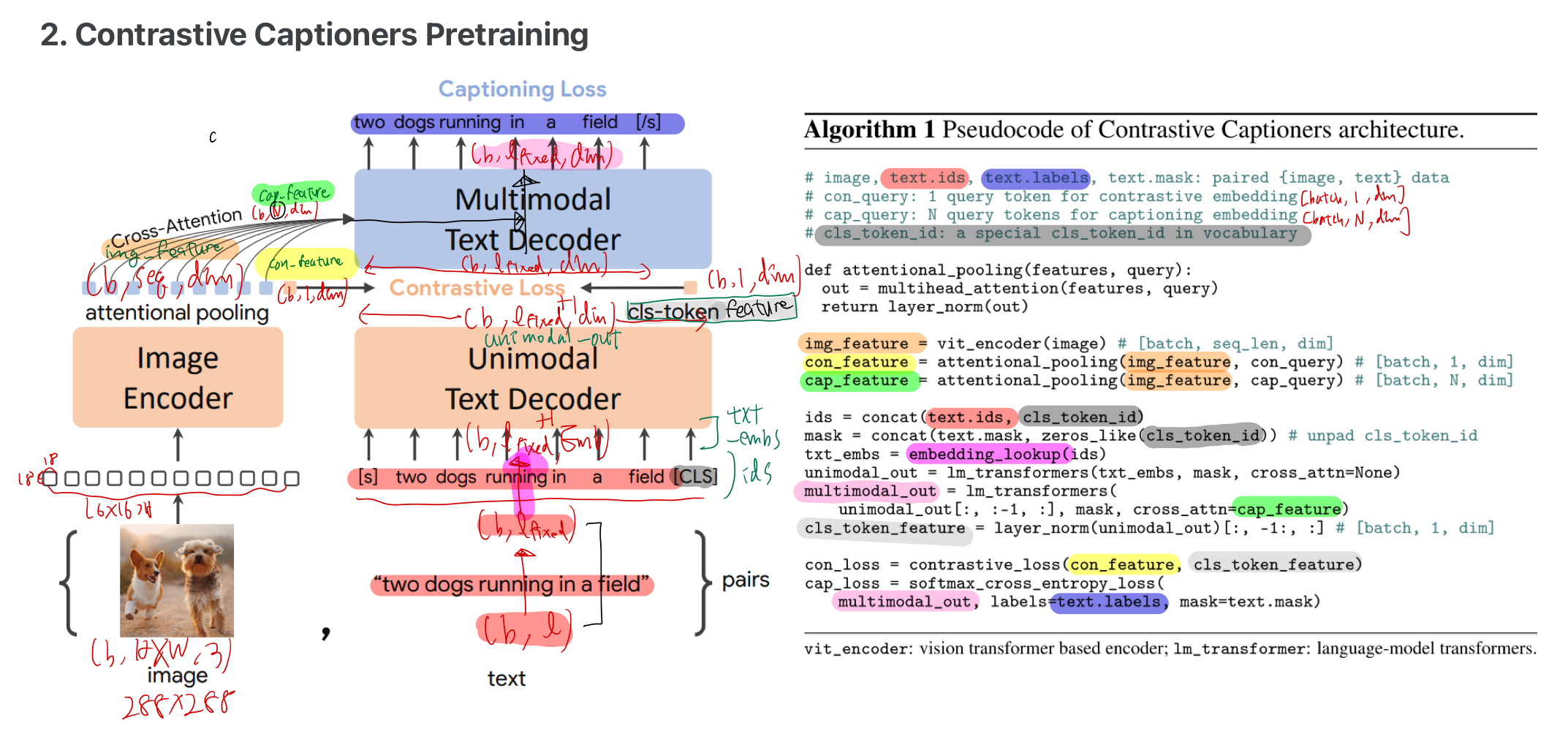
- 위 그림은 CoCa의
이미지-TEXT정렬 학습 방법을 나타낸 그림 - 본 논문에서, 위 그림과 완전 똑같이 학습하는건 아니지만, 유사하게 학습하기 때문에 그림을 공유해봤음
- 본 논문이 다른 점은
- 이미지 인코더 부분에 비디오 입력을 사용한다는 점
- 이미지 인코더 옆에 병렬적으로 오디오/스피치 인코더가 존재해서,
- multi-modal text decoder에서, 이미지/오디오/스피치 token 모두와 cross attention을 수행
- 위 그림은 CoCa의
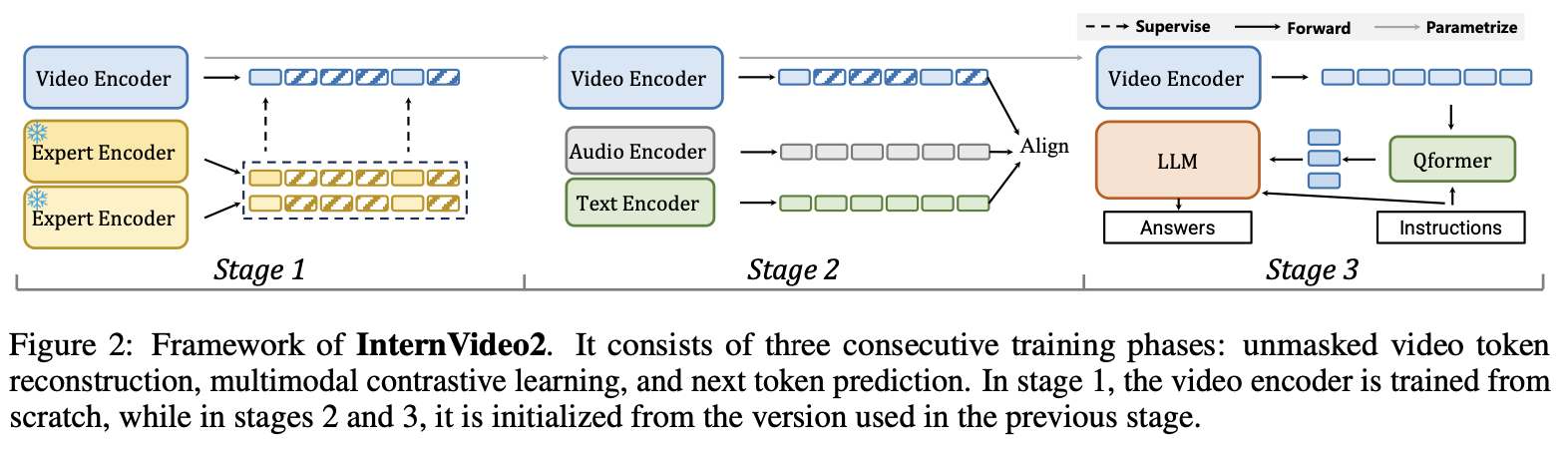
Multimodal Contrastive Learning- 우리는 텍스트를 매개로
비디오, 오디오, 이미지, 스피치를 포함한 여러 모달리티 간의 정렬과 융합을 목표로 함 - Video Encoder를 다른 모달리티(텍스트, 오디오, 스피치)와 연결하여,
- 비디오의 의미를 더 풍부하게 이해하도록 학습
- InternVideo2는 대규모 비디오 인코더를 사용하며, 그에 따른
오디오 및 텍스트 인코더는 상대적으로 경량화되어 있습니다.
오디오 인코더
- 사용된 오디오 인코더는 12개 레이어로 이루어진 트랜스포머이며, BEATs(90M)로 초기화
- 오디오 인코더를 사용하니, 성능이 무척 좋아졌다고 함
오디오 데이터를 네트워크의 input 값으로 넣는 법

- 사용된
오디오 인코더는 BEATs [Chen et al., 2023a]로 초기화된 12-레이어 트랜스포머- 오디오 인코더는 10초 길이의 오디오 클립을 입력
- 입력 오디오 클립이 10초보다 짧을 경우, 10초가 되도록 나머지 부분을 0으로 채웁니다.
- 사용된 오디오 인코더는 BEATs [Chen et al., 2023a]를 초기화한 12-레이어 트랜스포머입니다.
- 이는 25ms 해밍 윈도우를 사용하여 10초 길이의 클립(제로 패딩 처리)을 입력받아 64차원의 로그 Mel 필터뱅크 스펙트로그램을 생성합니다.
- 해밍 윈도우: 윈도우 함수는 프레임의 경계에서 발생할 수 있는 불연속적인 신호를 부드럽게 처리하기 위해 사용
64차원의 로그 Mel 필터- 각 윈도우에 대해, 시간과 주파수를 두 축으로 가지는 스펙트로그램 1개를 생성하는 것
- 깊은 이해를 위한 설명
- 이는 25ms 해밍 윈도우를 사용하여 10초 길이의 클립(제로 패딩 처리)을 입력받아 64차원의 로그 Mel 필터뱅크 스펙트로그램을 생성합니다.
- 텍스트 및 음성 인코더의 경우, 우리는 Bert-Large 를 텍스트 인코더와 멀티모달 디코더로 초기화합니다.
스피치 인코더
- 스피치 인코더를 쓰니까, 오히려 성능이 떨어졌다고 함.
텍스트 인코더
- Bert-Large [Devlin et al., 2018]를 사용
- 구체적으로, Bert-Large의 초기 19개 레이어를 텍스트 인코더로 활용
멀티모달 디코더
- Bert-Large [Devlin et al., 2018]를 사용
- 구체적으로, 19번쨰 이후의 5개 레이어를 크로스어텐션 레이어로 장착하여 멀티모달 디코더 역할

- 학습 효율성을 높이기 위해, 우리는 두 단계로 구성된 "마스킹 학습" 방식을 사용합니다. 이 방식은
- 일부 데이터를 숨기고 나머지 데이터를 정렬한 뒤,
- 숨기지 않은 전체 데이터를 복원하는 과정으로 이루어집니다.
- 구체적으로 다음과 같은 두 가지 단계가 포함됩니다:
1. Aligning Masked Visual-Language-Audio
- 먼저
마스킹된 비디오 토큰을 다른 모달리티의 토큰들과 정렬 - 오디오(소리) 인코더 고정(학습에 참여하지 않음):
주로 비디오(영상)와 텍스트(설명 문장)의 관계를 정리하는 데 집중 - 모든 데이터 활용:
여기서 이미지 - 설명, 비디오 - 설명, 그리고 "오디오와 비디오 - 설명"가 결합된 데이터를 사용하여 학습합니다.
예를 들어:- 이미지와 설명 문장: 사진과 그에 대한 설명.
- 비디오와 설명 문장: 동영상과 그에 대한 설명.
- 오디오-비디오 데이터와 설명 문장: 소리가 포함된 동영상과 그에 대한 설명.
이 모든 데이터 조합을 하나로 묶어 분석합니다.
2. Unmasked Visual-Audio-Language Post-Pretraining
- 전체 비디오 토큰 재구성을 수행
- 영상 처리 고정:
이번에는 비디오 인코더를 고정(freeze)하고,영상, 소리, 텍스트 간의 관계를 정리합니다. - 일부 데이터만 활용:
- 예를 들어: 2500만 개의 이미지/비디오, 50만 개의 오디오, 5000만 개의 오디오-비디오 데이터를 사용합니다.
- 마스킹 방식 제거:
이 단계에서는 데이터를 숨기는 방식(마스킹)을 사용하지 않습니다. 대신 모든 데이터를 그대로 사용해 학습합니다.
3.2.3. 학습 데이터 셋 (이들이 직접 만든 것들임)
- MVid 멀티모달 데이터: 오디오, 비디오, 스피치 정보가 동기화된 1억 1천만 개 이상의 비디오와 텍스트 설명이 포함되며, 멀티모달 정렬 학습을 위해 사용
- AutoShot으로 분할: FFMPEG SceneDet 대신 의미 기반 모델인 AutoShot으로 클립을 생성해 불필요한 장면 혼합을 줄이고 캡션 오류를 최소화
3.2.3.1. multi-modality 를 활용한 caption 생성하기!
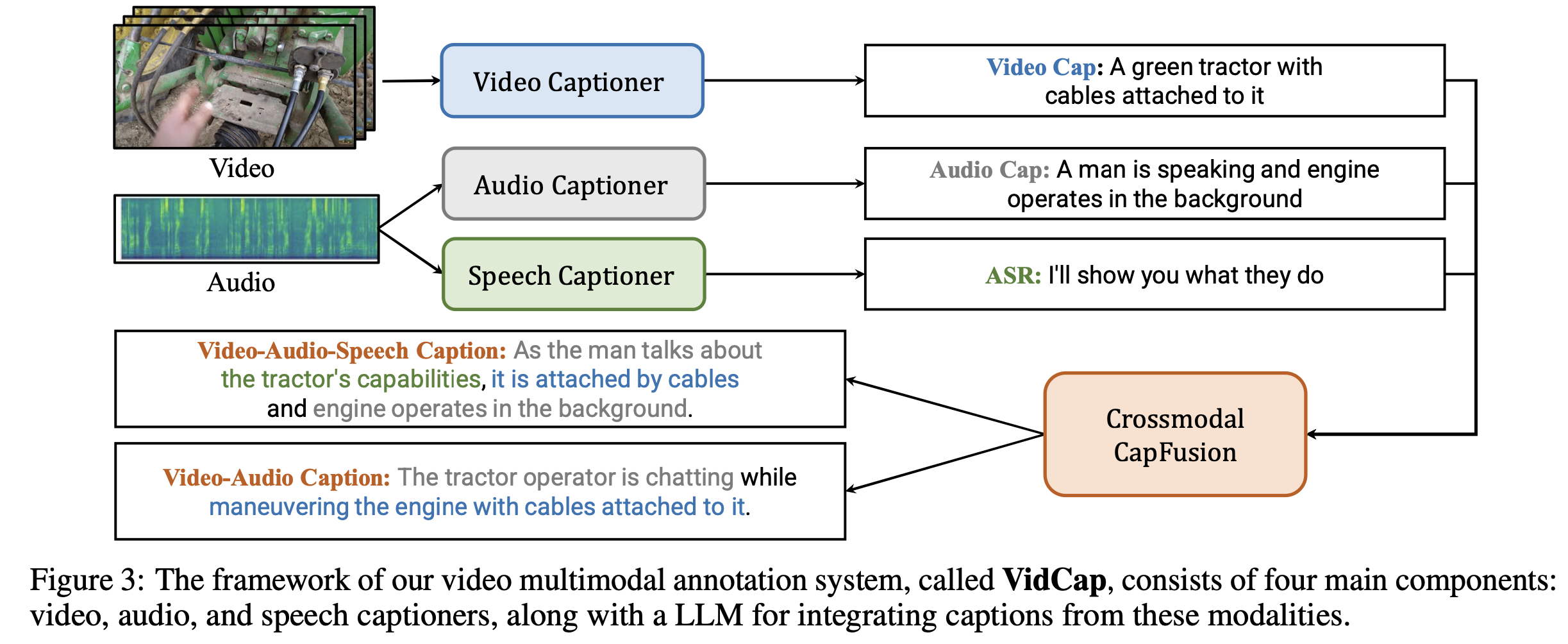
- 위 그림은
비디오-caption데이터셋을 생성하는 방법을 설명하고 있다. 분할된 각 비디오 클립에 대해 캡션을 생성하는데, 이때 비디오(video), 오디오(audio), 음성(speech) 세 가지 모달리티(modality)를 모두 활용하여 캡션을 생성- 예를 들어, "고양이가 뛰어다니는 영상"에 대한 캡션을 생성할 때, 영상만 보고는 "고양이가 움직인다"라고만 캡션을 생성할 수 있지만,
- 오디오 정보에서 "야옹"하는 소리를 인식하면 "고양이가 야옹 소리를 내며 뛰어다닌다"와 같이 더 구체적인 캡션을 생성할 수 있습니다.
- 이를 위해, 논문에서는 VidCap이라는
video multimodal annotation system을 사용- VidCap은 비디오, 오디오, 음성 각각에 대한 캡션을 생성하고, 이를 융합하여 최종 캡션을 생성합니다.
- 예를 들어, "고양이가 뛰어다니는 영상"에 대한 캡션을 생성할 때, 영상만 보고는 "고양이가 움직인다"라고만 캡션을 생성할 수 있지만,
- 이를 위해, 각각의 모달리티(Modality)에서 캡션을 생성하는 모듈과 이를 통합하는 모듈로 구성
- 단일 모달·크로스모달 캡션: 비디오·오디오·스피치 정보를 각각 캡셔닝한 후 LLM(Vicuna-1.5)으로 통합해 5가지 형태의 캡션(A, V, S, AV, AVS)을 자동 생성한다.
- 캡션 생성 모듈들:
- 비전 캡셔너: InternVid 파이프라인,
- 오디오 캡셔너: (직접 개발 후 학습) 아래 설명 따로 했음
- 스피치 캡셔너:
- Whisper 모델(스피치 -> text)
- 최종적으로, 비디오-text에 대해,
- CLIP 필터링: 6천만 개 상위 샘플만 MVid로 선정해 품질 유지, LAION-2B도 CLIP 유사도 기반으로 상위 1억 5800만 개 추출.
Audio Captioner 별도로 개발하고 학습함!
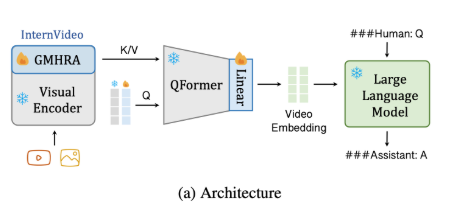
- 새로운 시도: 기존에 오디오 캡셔닝에 특화된 공개 모델이 거의 없었으므로, 이 논문에서는 VideoChat의 구조를 오디오용으로 확장했다.
- 비디오 인코더를 오디오 인코더로 대체하여, 비디오 input 대신 audio input을 받는 구조로 바꾸엇다.
- Beats 활용: 오디오 피처 추출은 Beats 모델로 처리하고,
- QFormer만 튜닝: 대규모 오디오-텍스트 코퍼스(WavCaps)를 이용해 QFormer를 파인튜닝함으로써, 오디오 입력을 대형 언어 모델이 이해할 수 있는 형태로 매핑.
- 낮은 파라미터 수정: 오디오 인코더와 LLM은 그대로 두고, QFormer만 학습하므로 효율성이 높음.
Speech Captioner 은 어떤거 사용했어?
1. “스피치 캡셔너(Speech Captioner)”가 필요한 이유
비디오에는 일반적으로 두 가지 형태의 오디오 정보가 있습니다:
1) 비언어적 오디오(음향, 배경음, 효과음 등),
2) 음성(사람이 말하는 언어 정보).
이미 앞서 설명된 오디오 캡셔너(Audio Captioner)는 1)번 분야—소리 전반(음악·환경 소리 등)을 텍스트로 묘사하는 역할을 합니다.
스피치 캡셔너(Speech Captioner)는 2)번 영역—말소리를 문자로 전사(Transcription)하고, 필요하면 번역까지 수행하여 텍스트 형태로 얻는 역할을 하게 됩니다.
논문에서는 Whisper-large [Radford et al., 2023]라는 모델을 사용해 비디오 속 음성을 텍스트로 변환(Transcription)합니다.
2.2. 비디오->오디오->텍스트 변환
- 기본적으로 비디오에서 오디오 스트림을 추출한 다음, Whisper 모델이 이를 입력으로 받아 음성(사람 말)을 텍스트로 전사합니다.
3. 데이터 출처와 처리 과정
3.1. YT-Temporal-180M
- 논문에서는 “YT-Temporal-180M”이라는 데이터 출처를 언급합니다.
- 이는 이미 “잘 정렬된 타임스탬프와 말소리 인식 결과가 조정된(speech recognition content)” 데이터셋이라고 합니다.
- 즉, 해당 데이터셋은 “비디오 구간별로 어떤 사람이 무슨 말을 언제 했는지”가 정밀하게 정렬되어 있음.
- 이런 데이터는 Whisper가 이미 적용되었거나, 혹은 고급 전처리가 적용된 형태로 추정됩니다.
3.2. 나머지 데이터 처리
YT-Temporal-180M 이외에 다른 비디오 데이터에 대해서는 다음 과정을 거칩니다:
-
언어 식별 (Language Identification)
- Fasttext-lid [Joulin et al., 2016] 모델을 이용해, 오디오가 어떤 언어인지 판단.
- 이 때 언어 판별(confidence)이 0.95 이상이면 해당 언어로 확정하고, 아니면 추가 조치가 필요.
-
비영어 텍스트를 영어로 전환
- 비영어 발화로 판명되면, Seamless M4T [Communication et al., 2023] 모델을 사용해 영어로 번역.
- Seamless M4T 역시 다양한 언어 간 음성·텍스트 번역을 다루는 강력한 모델로 알려져 있음.
- 언어 식별 신뢰도가 낮을 경우(0.95 미만), 추가적인 번역 대안으로 Vicuna-1.5를 사용해 번역.
- Vicuna-1.5는 원래 LLM(대형 언어 모델)이지만, “번역” 또는 “다른 자연어 처리 작업”에도 활용 가능.
결론적으로, Whisper -> Fasttext-lid -> Seamless M4T/Vicuna-1.5의 파이프라인을 통해,
“어떤 언어로 말했든 최종적으로 영어 텍스트 형태”로 일관되게 확보하게 됩니다.
3.3. Stage3: Predicting Next Token with Video-Centric Inputs
- Video Encoder를 LLM과 연결하여, 비디오에 대한 질문에 답하거나 비디오를 설명하는 등, 더 복잡한 작업을 수행할 수 있도록 학습시키는 단계
- Qformer: Video Encoder의 출력을 LLM이 이해할 수 있는 형태로 변환하는 역할
- LLM은
Qformer로부터 받은 비디오 특징 벡터와 질문(Instructions)을 입력받아,- 다음 토큰(Next Token)을 예측하는 방식으로 답변(Answers)을 생성
- 우리는 InternVideo2를 비디오LLM이라는 시스템에 통합하여 fine tuning
- 비디오LLM 시스템: LLM(대규모 언어 모델)과 비디오 BLIP기술(Q-former)을 함께 사용
- InternVideo2는 비디오를 분석하는 도구(비디오 인코더)로 활용되며,
- 공개된 언어 모델과 소통할 수 있도록 비디오 BLIP를 학습시킵니다.
- 학습 과정 중, InternVideo2의 비디오 분석 기능도 업데이트됩니다.
3.3.1. dataset
- 비디오 지시 튜닝(MVBench): 이미지·비디오 190만 샘플에서 대화, 캡션, QA, 추론, 분류 등 핵심 영상 이해 작업에 대한 지시 데이터를 정리
4. Multimodal Video Data
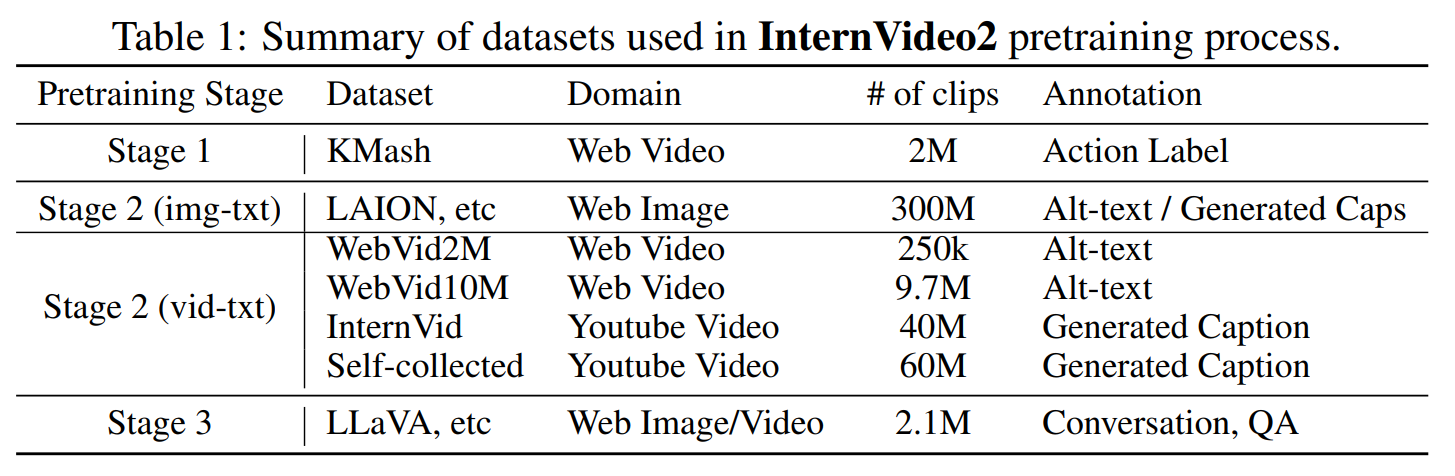
- 훈련 데이터 구성: 비디오 전용, 멀티모달 비디오 버전, 시각적 지침 데이터를 표 1에 맞춰 준비한다.
- stage 1
- K-Mash 소개: 레이블, 텍스트가 없는 대규모 비디오 컬렉션으로, 다양한 시점·길이·캐릭터를 다룬다.
- K-Mash2M 확장: 유튜브에서 엄선한 84만4천 개 비디오를 추가해 행동 인식 파인튜닝 성능을 높였다.
- stage 2
- MVid 구축: 비디오·오디오·스피치 정보가 결합된 1억 1천만 개 규모의 멀티모달 비디오 데이터셋.
- 시간적 분할 강조: AutoShot 모델로 의미 기반 경계 탐지, SceneDet 대신 의미적으로 완전한 클립 생성.
- VidCap 시스템: 비디오, 오디오, 스피치 캡션을 자동 생성·수정·융합해 비디오를 텍스트화하는 멀티모달 주석 프레임워크.
- stage 3
- MVBench 사용: 200만 건의 이미지·비디오 샘플(34개 소스)로부터 대화·캡션·시각 질의응답·추론·분류 등 핵심 기능을 포괄.

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것