
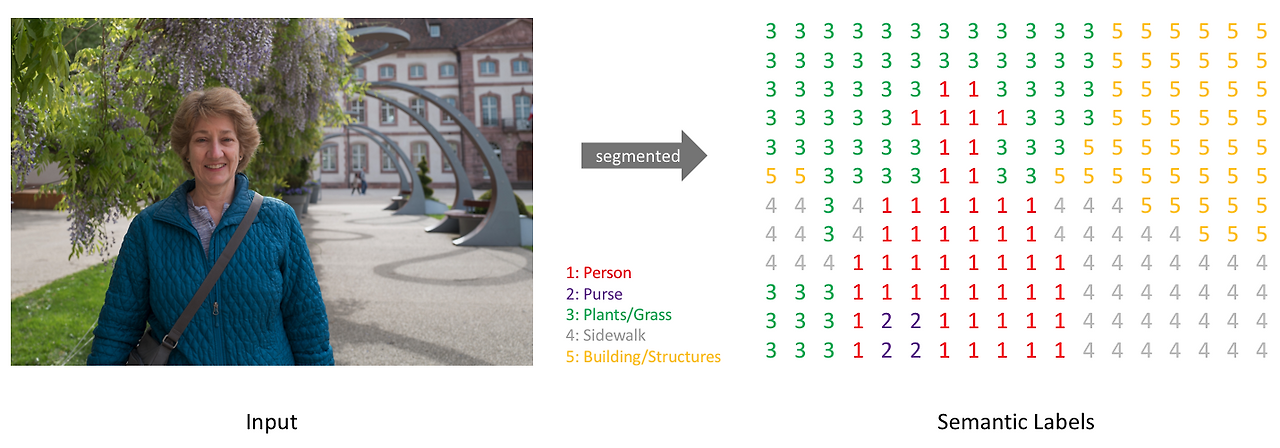
Segmentation
Segmentation은 컴퓨터 비전에서 이미지나 영상을 픽셀 단위로 분할하여 각 영역이 무엇을 나타내는지 구분하는 기술이다.
- Semantic Segmentation : 같은 종류의 객체를 동일한 클래스로 분류한다.
- Instance Segmentation : 같은 클래스 내에서도 개별 객체를 구분한다.
이를 통해 의료 영상 분석, 자율주행, 위성 이미지 처리 등 다양한 분야에서 정밀한 객체 인식을 수행할 수 있다.
Segmentation 모델로는 U-Net, DeepLab, Mask R-CNN 등이 널리 사용된다.
CVAT으로 스타벅스 이미지를 라벨링해서 로고랑 텍스트 부분만 따로 누끼 작업을 했다.
라벨은 COCO Segmentation(JSON) 포맷으로 뽑았고, YOLO 학습을 위해 YOLO txt 포맷으로 변환해서 데이터셋을 만들었다.
!pip install -q ultralytics opencv-pythonimport os
import random
import shutil
import ultralytics
from tqdm import tqdm
import cv2
import glob
import json
import matplotlib.pyplot as plt
import numpy as np
from pycocotools import mask as maskUtils
from torchvision import transforms# 작업 디렉토리 생성
!mkdir /content/starbucks# 압축된 스타벅스 데이터셋을 지정한 디렉토리에 해제
!unzip /content/starbucks.zip -d /content/starbucks/# 데이터 루트 경로 설정
data_root = '/content/starbucks/starbucks'# .jpg, .jpeg 확장자를 가진 이미지 파일 목록 불러오기
data_list = glob.glob(f'{data_root}/*.jpg') + glob.glob(f'{data_root}/*.jpeg')
data_listCOCO annotation JSON 로더 함수
def load_coco_annotations(json_path):
# JSON 파일 열어서 Python dict로 반환
with open(json_path, 'r') as f:
data = json.load(f)
return data# COCO 형식 라벨 파일 불러오기 (instances_default.json)
load_coco_annotations(f'{data_root}/instances_default.json')이미지 로드 함수
def load_image(image_path):
# OpenCV로 이미지 읽기 (기본은 BGR 포맷)
image = cv2.imread(image_path)
if image is None:
# 이미지가 없을 경우 에러 발생
raise FileNotFoundError(f'이미지를 찾을 수 없음: {image_path}')
# OpenCV → matplotlib 호환 RGB로 변환
return cv2.cvtColor(image, cv2.COLOR_BGR2RGB)# 이미지 리스트 중 3번째 이미지를 불러오기
load_image(data_list[2])
COCO annotation을 이미지 위에 그려주는 함수
def draw_annotations(image, annotations, image_id):
for ann in annotations:
# 특정 image_id와 일치하는 annotation만 선택
if ann['image_id'] == image_id and 'segmentation' in ann:
segmentation = ann['segmentation']
# segmentation이 여러 개일 수 있음 (하나의 객체가 여러 다각형으로 표현되는 경우)
for seg in segmentation:
# seg가 리스트이고, 최소한 점이 3개 이상 있어야 polygon 형성 가능
# (x, y) 좌표 하나는 원소 2개, 따라서 최소 6개 이상 → 점 3개
if isinstance(seg, list) and len(seg) >= 6: # (x, y) 점 하나는 seg가 2개라고 함. 따라서 최소 점 3개 이상일 때라는 뜻!
points = np.array(seg).reshape(-1, 2).astype(np.int32) # reshape(-1, 2) : 열은 2, 행은 자동으로 맞춰주라는 뜻
# OpenCV polyline(다각형 외곽선) 그리기
cv2.polylines(image, [points], isClosed=True, color=(0, 255, 0), thickness=2)
return image메인 실행 함수: COCO 시각화
# 메인 실행 함수
def visualize_coco(json_path, image_folder, image_id):
# 1. COCO JSON 로드
coco_data = load_coco_annotations(json_path)
# 2. 이미지 ID에 해당하는 메타데이터 찾기
image_info = next((img for img in coco_data['images'] if img['id'] == image_id), None)
if not image_info:
raise ValueError(f'Image ID {image_id} not found in COCO JSON file')
# 3. 실제 이미지 파일 경로 생성
image_path = os.path.join(image_folder, image_info['file_name'])
# 4. 이미지 로드 (RGB 변환됨)
image = load_image(image_path)
# 5. 해당 이미지에 annotation polygon 겹쳐 그리기
annotated_image = draw_annotations(image, coco_data['annotations'], image_id)
# 6. 시각화 (matplotlib 사용)
plt.figure(figsize=(8, 6))
plt.imshow(annotated_image)
plt.axis('off')
plt.title(f'Image ID: {image_id} with Annotations')
plt.show()실행 예시
visualize_coco(f'{data_root}/instances_default.json', f'{data_root}', 20)
visualize_coco(f'{data_root}/instances_default.json', f'{data_root}', 21)
visualize_coco(f'{data_root}/instances_default.json', f'{data_root}', 29)
coco_json_path = f'{data_root}/instances_default.json'
yolo_output_folder = f'{data_root}'
image_folder = f'{data_root}'
# COCO JSON 로드
with open(coco_json_path, 'r') as f:
coco_data = json.load(f)
# 이미지 ID → 이미지 메타정보(dict) 매핑 (빠른 접근용)
image_dict = {img['id']: img for img in coco_data['images']}
image_dict# COCO -> YOLO 변환
for ann in coco_data['annotations']:
image_id = ann['image_id']
category_id = ann['category_id'] - 1 # YOLO는 class_id가 0부터 시작
segmentation = ann['segmentation']
# 해당 annotation의 이미지 정보 가져오기
image_info = image_dict.get(image_id)
if not image_info:
continue
img_width, img_height = image_info['width'], image_info['height']
# os.path.splitext: 파일 경로에서 확장자를 분리
yolo_label_path = os.path.join(yolo_output_folder, f"{os.path.splitext(image_info['file_name'])[0]}.txt")
yolo_lines = []
for seg in segmentation:
# seg가 다각형 형태이고 최소 3점 이상 있어야 polygon 가능
if isinstance(seg, list) and len(seg) >=6:
# 좌표를 (x/width, y/height) 형태로 정규화
normalized_points = [
(seg[i] / img_width, seg[i+1] / img_height) for i in range(0, len(seg), 2)
]
# YOLO 포맷: class x1 y1 x2 y2 ...
yolo_line = f'{category_id} ' + ' '.join([f'{x:.6f} {y:.6f}' for x, y in normalized_points])
yolo_lines.append(yolo_line)
# 변환된 라벨 저장
if yolo_lines:
with open(yolo_label_path, 'w') as f:
f.write('\n'.join(yolo_lines))
print('coco -> yolo 변환 완료!')coco -> yolo 변환 완료!데이터셋 분할 (train/valid/test)
random.seed(2025)
data_list = glob.glob(f'{data_root}/*.jpg') + glob.glob(f'{data_root}/*.jpeg')
random.shuffle(data_list)
test_ratio = 0.2
num_data = len(data_list)
num_data # 총 30장30# 20% test, 20% valid, 나머지 train
test_list = data_list[:int(num_data*test_ratio)]
valid_list = data_list[int(num_data*test_ratio):int(num_data*test_ratio)*2]
train_list = data_list[int(num_data*test_ratio)*2:]
len(test_list), len(valid_list), len(train_list)(6, 6, 18)데이터셋 디렉토리 생성
file_root = f'{data_root}'
train_root = f'{data_root}/train'
valid_root = f'{data_root}/valid'
test_root = f'{data_root}/test'
for folder in [train_root, valid_root, test_root]:
if not os.path.exists(folder):
os.makedirs(folder)이미지 & 라벨 복사 함수
def copy_files(file_list, dest_folder):
for file_path in file_list:
file_name = os.path.basename(file_path)
file_base, ext = os.path.splitext(file_name)
# 이미지 복사
dest_path = os.path.join(dest_folder, file_name)
shutil.copy(file_path, dest_path)
# 해당 이미지와 동일한 이름의 YOLO 라벨(txt)도 복사
txt_file_path = os.path.join(os.path.dirname(file_path), f'{file_base}.txt')
if os.path.exists(txt_file_path):
dest_txt_path = os.path.join(dest_folder, f'{file_base}.txt')
shutil.copy(txt_file_path, dest_txt_path)# 데이터 분할에 맞게 파일 복사
copy_files(train_list, train_root)
copy_files(valid_list, valid_root)
copy_files(test_list, test_root)YOLO 데이터셋 YAML 작성
train_root = f'/content/starbucks/starbucks/train'
valid_root = f'/content/starbucks/starbucks/valid'
test_root = f'/content/starbucks/starbucks/test'import yamldata = dict()
data['train'] = train_root
data['val'] = valid_root
data['test'] = test_root
data['nc'] = 2 # 클래스 수
data['names'] = ['logo', 'text'] # 클래스 이름
# starbucks.yaml 파일 저장
with open(f'./starbucks/starbucks/starbucks.yaml', 'w') as f:
yaml.dump(data, f)YOLO 모델 학습
from ultralytics import YOLOmodel = YOLO('yolov8s-seg.pt')# 학습 실행
results = model.train(
data='./starbucks/starbucks/starbucks.yaml', # 데이터셋 정의 파일
epochs=10, # 학습 epoch 수
batch=4, # 배치 크기
imgsz=224, # 입력 이미지 크기
device=0, # GPU 0번 사용
workers=2, # 데이터 로딩 워커 수
amp=False, # 자동 mixed precision 비활성화
name='starbucks_s' # 결과 저장 폴더명
)학습된 모델로 추론
# 가장 성능 좋은 가중치(best.pt) 불러오기
model = YOLO('runs/segment/starbucks_s3/weights/best.pt')# test 이미지에서 예측 수행
results = model.predict(
source='./starbucks/starbucks/test', # 테스트 이미지 폴더
imgsz=224, # 입력 크기
conf=0.30, # confidence threshold
device=0, # GPU 0번
save=True, # 예측 결과 이미지 저장
save_conf=True # confidence 값도 저장
)
The light shines in the darkness.