Random forests is an ensemble learning method for classification, regression and other tasks that operates by constructing a multitude of decision trees at training time
여러개의 Decision Tree가 모여 더 좋은 결과를 내는 모델
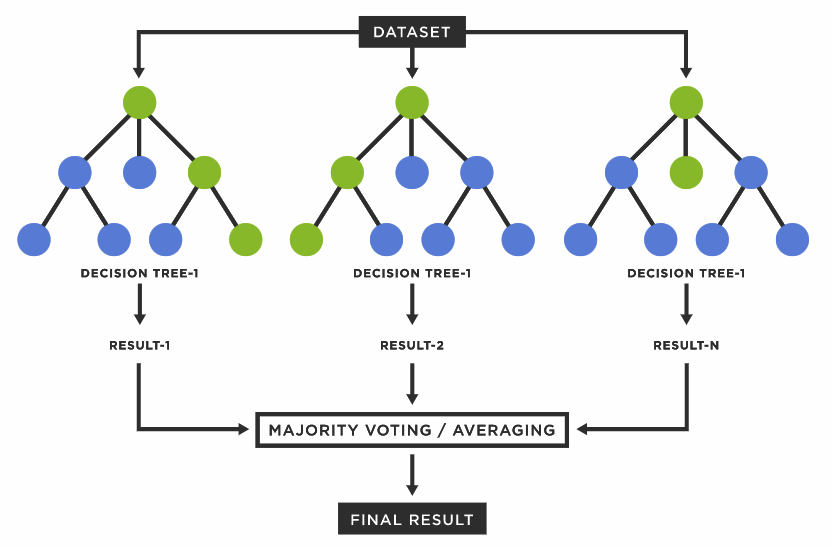
특징
- Random Forest는 CART 모델이 가지는 단점을 극복하기 위해 만들어진 모델이다
- Decision Tree 하나가 training data에 너무 쉽게 overfit되고 training data의 변화에 민감하다는 문제를 해결. Decision Tree 여러개를 사용하여 다수결을 하는 방식으로 기존의 단점 보완
- 단일 모델을 여러개 모아 더 좋은 판단을 하는 방법론을
Model Ensemble이라고 한다
'Random'이어야 하는 이유
- 그냥 Decision Tree들을 모으기만 하면 더 좋은 결과를 낼 수 없다
- 같은 데이터에 대해 만들어진 Decision Tree는 매번 같은 결과를 출력하기 때문 - 다양성을 위한 2가지 전략
1. Bagging(Bootstrap Aggregating) : Data sampling (모집단 자체를 바꿈)
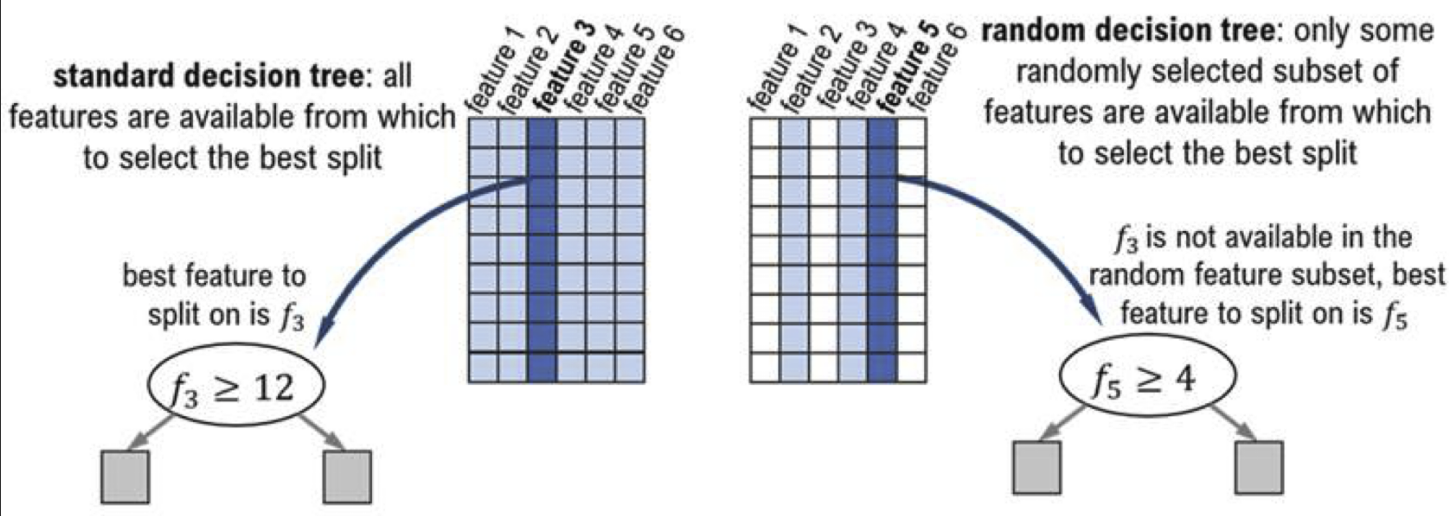
2. Random Subspace Method : Feature sampling (Decision Tree가 뽑는 feature 바꿈)
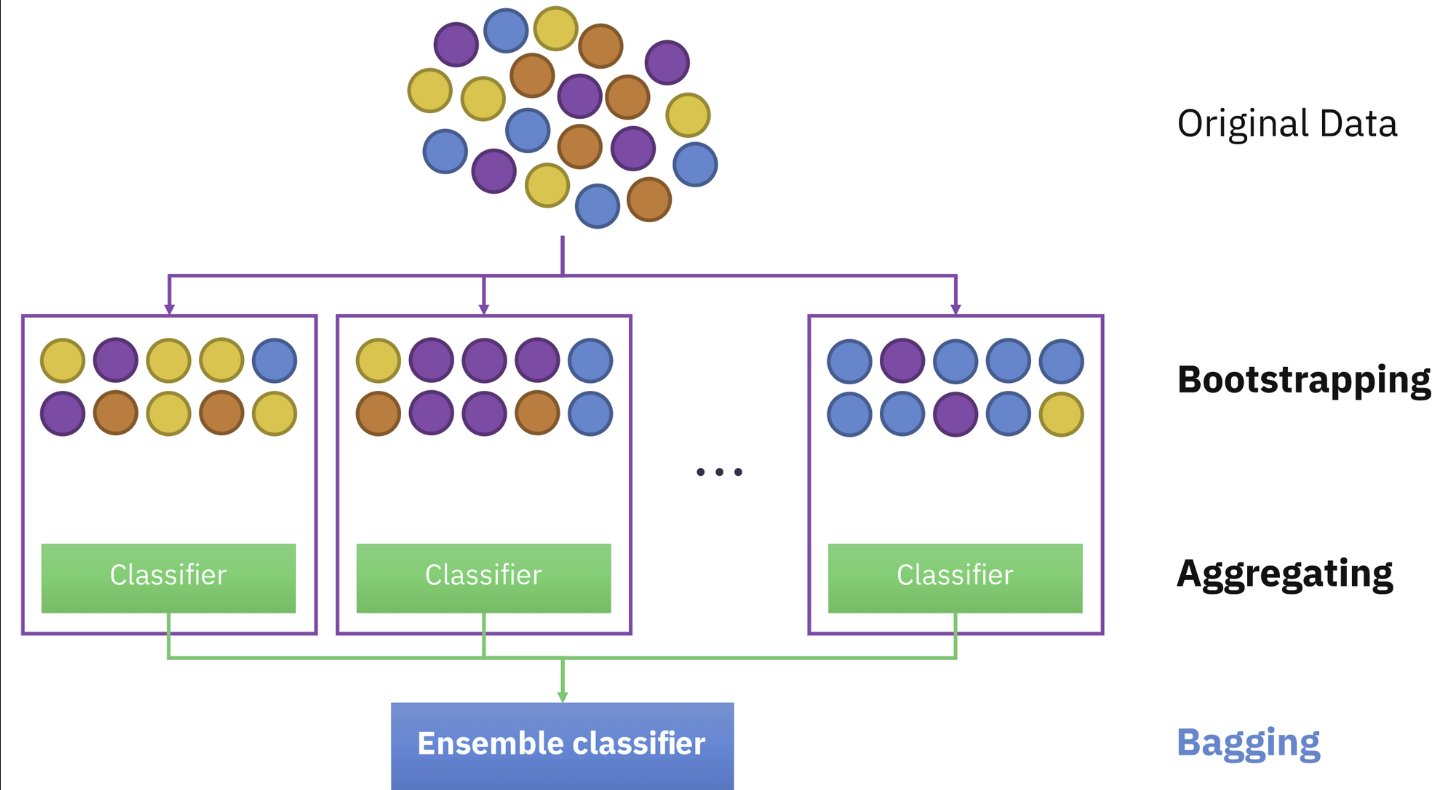
- Data sampling + Feature sampling을 통해 만들어진 각 Decision Tree에 다양성 제공
- 몇 개의 Decision Tree를 모을지는 hyper-parameter로 설정
- 만들어진 Decision Tree들의 결론을 다수결로 평가함으로써 집단 지성을 구현할 수 있음

데이터 엔지니어로 전향중인 백엔드 개발자입니다