k-means clustering is a method of vector quantization, originally from signal processing, that aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean (cluster centers or cluster centroid), serving as a prototype of the cluster
주어진 데이터를 k개의 클러스터로 묶는 알고리즘이다
- 대표적인 클러스터링 모델이다
- 직관전이고 간단하며, 빠르다
알고리즘
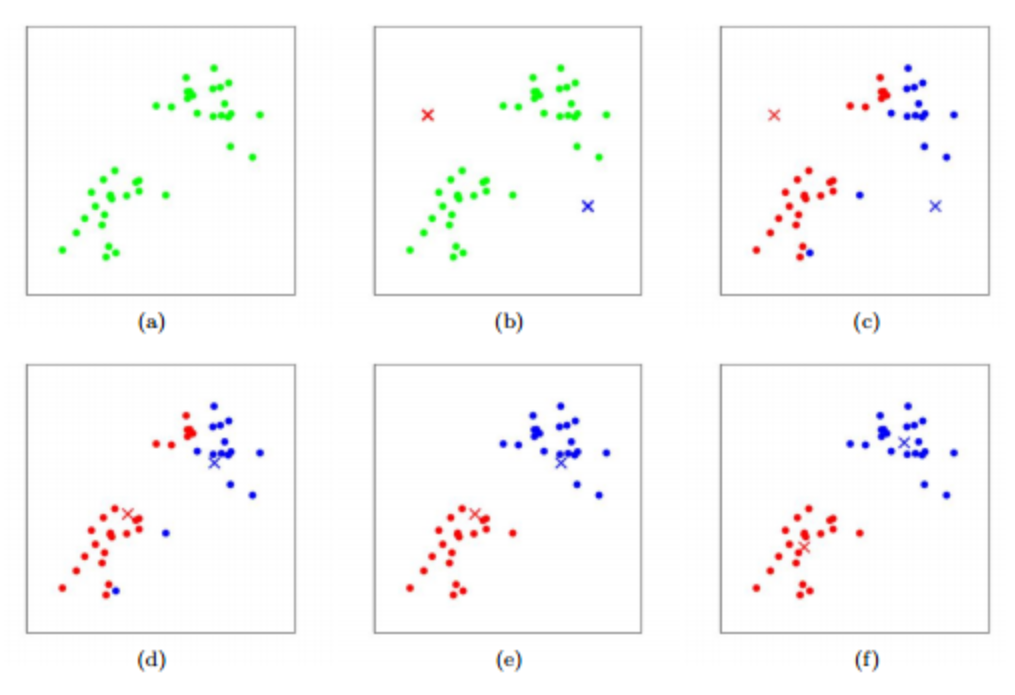
이미지 출처: https://hleecaster.com/ml-kmeans-clustering-concept/
- 주어진 데이터에서 랜덤으로 K개의 데이터를 기준점(
centroid)로 잡는다. 각 centroid에 0번 부터 차례대로 번호를 부여한다 - 각 데이터는 K개의 centroid 중 가장 가까운 centroid를 찾아 같은 번호를 부여받는다
- 같은 번호인 데이터들끼리 평균을 구한다
- 각 평균을 새로운 centroid로 지정한다
- 2번부터 반복하여 더 이상 cluster label이 바뀌는 데이터가 없다면 알고리즘 종료
장단점
장점
- 빠르다 => O(nk)
- 모델 수행 원리가 간단하여 해석이 쉽다
=> Unsupervised learning들은 해석이 굉장히 중요하다 - objective function이 볼록하여 무조건 수렴한다 (답은 결국 나옴)
단점
- 평균이 기준이기 때문에 outlier에 취약하다
- 데이터의 모양이 원형의 모양이 아니면 잘 묶이지 않는다
- 처음 centroid를 어떻게 고르느냐에 따라 성능이 천차만별이다
- K가 하이퍼 파라미터이다
=> 차원이 높다면 직관적으로 알기 힘들다

데이터 엔지니어로 전향중인 백엔드 개발자입니다