전 포스트에 이어, Feature Engineering을 진행하며 머신러닝 모델에 들어갈 데이터를 가공한다
2. Feature Engineering
2.1 Column Definitions
- 가정 레벨과 개인 레벨 변수 나누기
- 개인 레벨의 데이터에서 적당히 합칠 수 있는 변수들 확인
- 순서를 확인할 수 있는 변수는 통계에 사용
- 참/거짓 변수 또한 통합할 수 있지만 순서 변수에 비해 메리트는 X
- 개인 변수들의 집합을 가정 레벨 데이터에 합친다
g = df_train.columns.to_series().groupby(df_train.dtypes).groups
g
- 변수 타입을 기준으로 정수 값, 실수 값에 대해 변수를 나누고 그 안에서 분류를 하고자 하였으나, 각 변수가 가진 의미를 기준으로 나눠야 하므로 필요 X
id_ = ['Id', 'idhogar', 'Target']# individual
ind_bool = ['v18q', 'dis', 'male', 'female', 'estadocivil1', 'estadocivil2', 'estadocivil3',
'estadocivil4', 'estadocivil5', 'estadocivil6', 'estadocivil7',
'parentesco1', 'parentesco2', 'parentesco3', 'parentesco4', 'parentesco5',
'parentesco6', 'parentesco7', 'parentesco8', 'parentesco9', 'parentesco10',
'parentesco11', 'parentesco12', 'instlevel1', 'instlevel2', 'instlevel3',
'instlevel4', 'instlevel5', 'instlevel6', 'instlevel7', 'instlevel8',
'instlevel9', 'mobilephone', 'rez_esc-missing']
ind_ordered = ['rez_esc', 'escolari', 'age']# household
hh_bool = ['hacdor', 'hacapo', 'v14a', 'refrig', 'paredblolad', 'paredzocalo',
'paredpreb','pisocemento', 'pareddes', 'paredmad',
'paredzinc', 'paredfibras', 'paredother', 'pisomoscer', 'pisoother',
'pisonatur', 'pisonotiene', 'pisomadera',
'techozinc', 'techoentrepiso', 'techocane', 'techootro', 'cielorazo',
'abastaguadentro', 'abastaguafuera', 'abastaguano',
'public', 'planpri', 'noelec', 'coopele', 'sanitario1',
'sanitario2', 'sanitario3', 'sanitario5', 'sanitario6',
'energcocinar1', 'energcocinar2', 'energcocinar3', 'energcocinar4',
'elimbasu1', 'elimbasu2', 'elimbasu3', 'elimbasu4',
'elimbasu5', 'elimbasu6', 'epared1', 'epared2', 'epared3',
'etecho1', 'etecho2', 'etecho3', 'eviv1', 'eviv2', 'eviv3',
'tipovivi1', 'tipovivi2', 'tipovivi3', 'tipovivi4', 'tipovivi5',
'computer', 'television', 'lugar1', 'lugar2', 'lugar3',
'lugar4', 'lugar5', 'lugar6', 'area1', 'area2', 'v2a1-missing']
hh_ordered = [ 'rooms', 'r4h1', 'r4h2', 'r4h3', 'r4m1','r4m2','r4m3', 'r4t1', 'r4t2',
'r4t3', 'v18q1', 'tamhog','tamviv','hhsize','hogar_nin',
'hogar_adul','hogar_mayor','hogar_total', 'bedrooms', 'qmobilephone']
hh_cont = ['v2a1', 'dependency', 'edjefe', 'edjefa', 'meaneduc', 'overcrowding']# squared variables
sqr_ = ['SQBescolari', 'SQBage', 'SQBhogar_total', 'SQBedjefe',
'SQBhogar_nin', 'SQBovercrowding', 'SQBdependency', 'SQBmeaned', 'agesq']- 겹친 칼럼이 없는지 확인
x = ind_bool + ind_ordered + id_ + hh_bool + hh_ordered + hh_cont + sqr_
from collections import Counter
print('There are no repeats: ', np.all(np.array(list(Counter(x).values())) == 1))
print('We covered every variable: ', len(x) == data.shape[1])
Household Level Variables
heads = data.loc[data['parentesco1'] == 1, :]
heads = heads[id_ + hh_bool _ hh_cont + hh_ordered]
heads.shape
Redundant Household Variables
# 상관계수 행렬
corr_matrix = heads.corr()
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k = 1).astype(np.bool)
# 상관계수가 0.95가 넘는 칼럼 확인
to_drop = [column for column in upper.columns if any(abs(upper[column]) > 0.95)]
to_drop
corr_matrix.loc[corr_matrix['tamhog'].abs() > 0.9, corr_matrix['tamhog'].abs() > 0.9]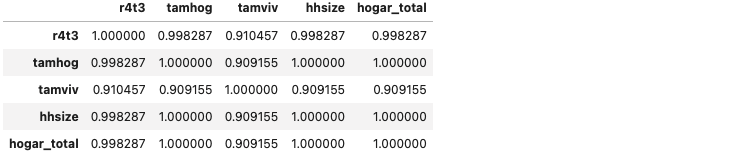
sns.heatmap(corr_matrix.loc[corr_matrix['tamhog'].abs() > 0.9, corr_matrix['tamhog'].abs() > 0.9],
annot = True, cmap = plt.cm.autumn_r, fmt = '.3f')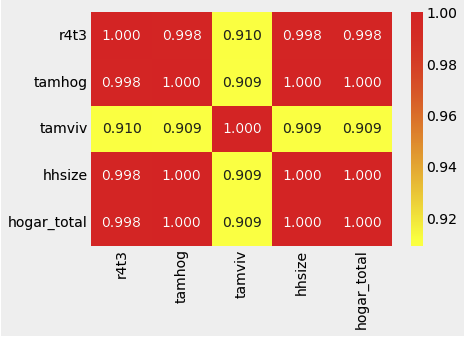
tamhog,hhsize,hogar_total모두 큰 상관관계를 가지므로 2개는 삭제한다- 또한
r4t3이hhsize와 거의 완벽한 상관관계이므로 함께 제거한다
heads = heads.drop(columns = ['tamhog', 'hogar_total', 'r4t3'])sns.lmplot('tamviv', 'hhsize', data, fit_reg = False, size = 78)
plt.title('Household size vs number of persons living in the household')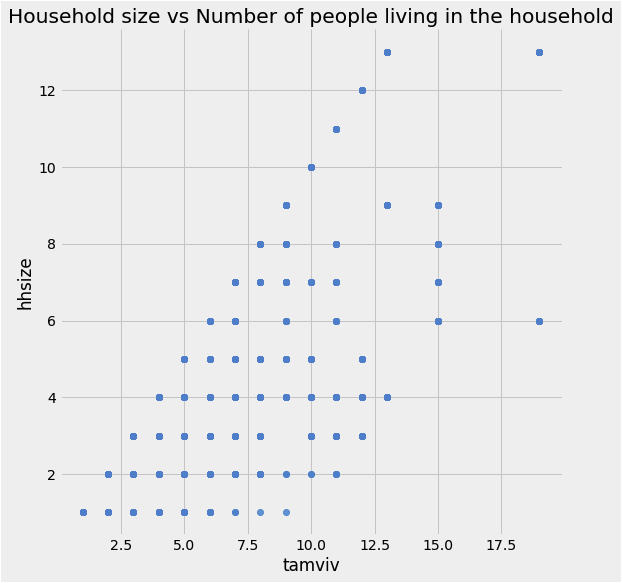
- 위의 그래프를 보아, 가족과 함께 사는 사람들보다 다른 동거인과 사는 사람이 많음을 확인할 수 있다
heads['hhsize-diff'] = heads['tamviv'] - heads['hhsize']
plot_categoricals('hhsize-diff', 'Target', heads)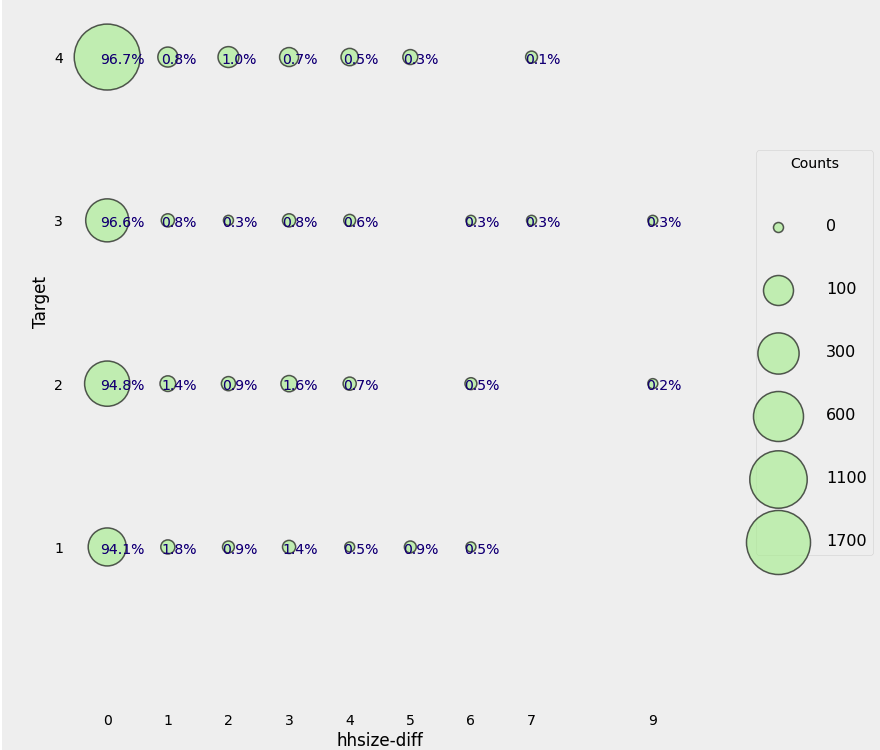
coopele: 외부에서 공용으로 끌어다 쓰는 전기
corr_matrix.loc[corr_matrix['coopele'].abs() > 0.9, corr_matrix['coopele'].abs() > 0.9]
Creating Ordinal Variable
- 0: No electricity
- 1: Electricity from cooperative
- 2: Electricity from CNFL, ICA, ESPH/JASEC
- 3: Electricity from private plant
elec = []
for i, row in heads.iterrows():
if row['noelec'] == 1:
elec.append(0)
elif row['coopele'] == 1:
elec.append(1)
elif row['public'] == 1:
elec.append(2)
elif row['planpri'] == 1:
elec.append(3)
else:
elec.append(np.nan)
heads['elec'] = elec
heads['elec-missing'] = heads['elec'].isnull()plot_categoricals('elec', 'Target', heads)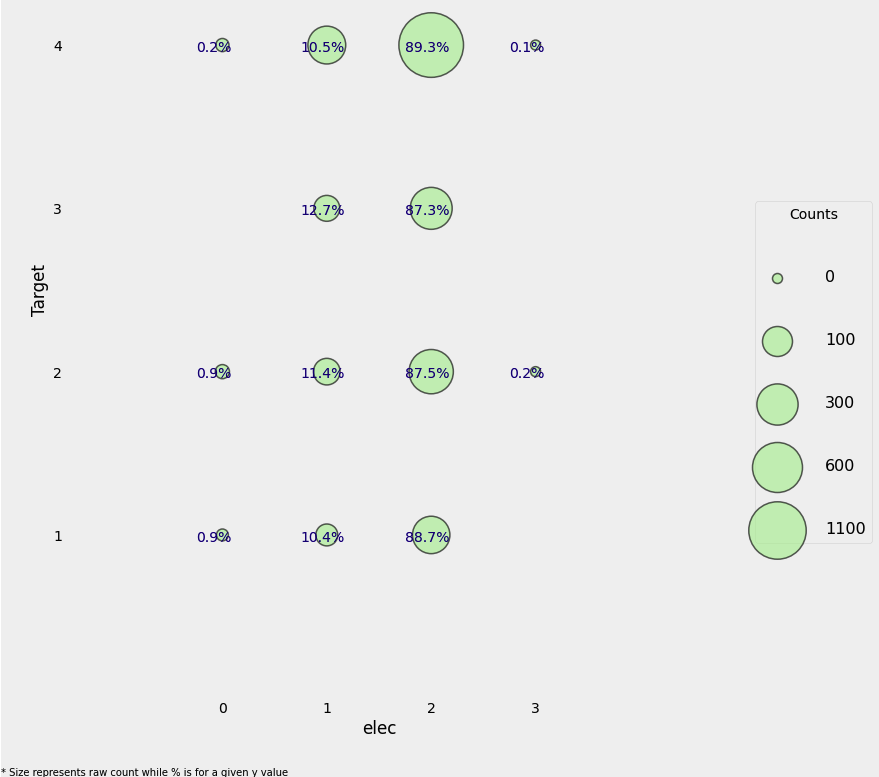
area2: 이미 해당 가구가 도시 지역에 있는지, 시골 지역에 있는지 알 수 있는 칼럼이 있으므로 불필요
heads = heads.drop(columns = 'area2')
heads.groupby('area1')['Target'].value_counts(normalize = True)
Creating Ordinal Variables
- 각 집마다 벽, 지붕, 바닥에 대한 칼럼이 존재 -> bad, regular, good
- 이를 ordinal 변수로 만들어 전환
heads['walls'] = np.argmax(np.array(heads[['epared1','epared2','epared3']]), axis = 1)
heads = heads.drop(columns = ['epared1', 'epared2', 'epared3'])
plot_categoricals('walls', 'Target', heads)
# 지붕
heads['roof'] = np.argmax(np.array(heads[['etecho1', 'etecho2', 'etecho3']]), axis = 1)
heads = heads.drop(columns = ['etecho1', 'etecho2', 'etecho3'])
# 바닥
heads['floor'] = np.argmax(np.array(heads[['eviv1', 'eviv2', 'eviv3']]), axis = 1)
heads = heads.drop(columns = ['eviv1', 'eviv2', 'eviv3'])2.2 Feature Construction
Ordinal feature로 매핑하는 것 대신, 갖고있는 데이터를 가지고 새로운 feature를 만들 수도 있다
heads['walls+roof+floor'] = heads['walls'] + heads['roof'] + heads['floor']
plot_categoricals('walls+roof+floor', 'Target', heads, annotate = False)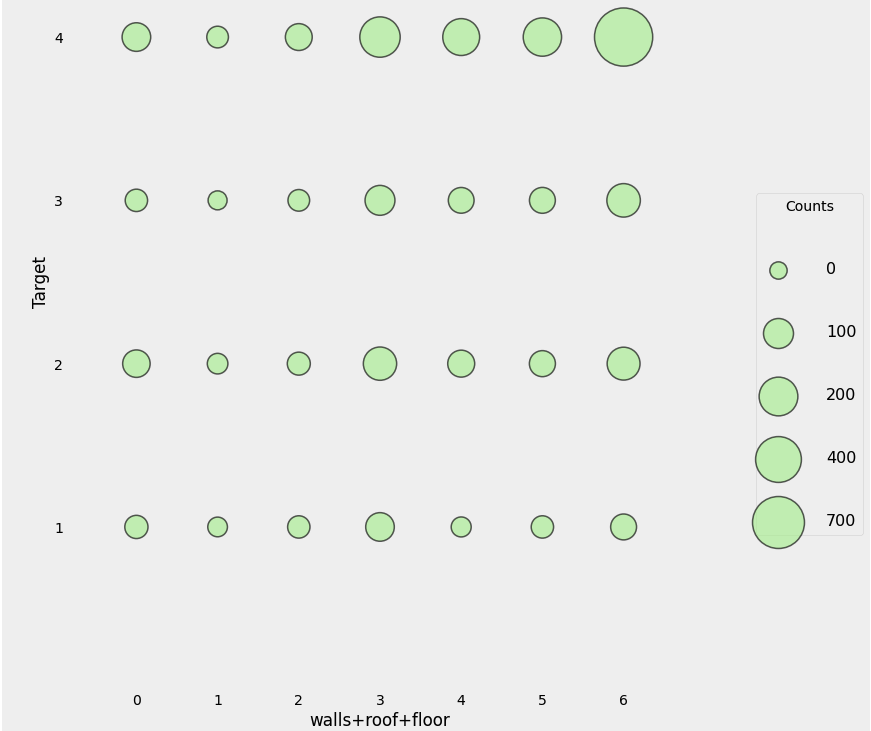
counts = pd.DataFrame(heads.groupby(['walls+roof+floor'])['Target'].
value_counts(normalize = True)).rename(columns =
{'Target': 'Normalized Count'}).reset_index()
counts.head()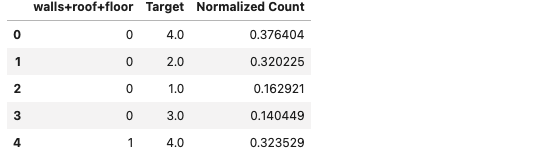
warning: 집의 퀄리티. 음수로 나타나며 화장실, 전기, 바닥, 천장을 지표로 계산
heads['warning'] = 1 * (heads['sanitario1'] + (heads['elec'] == 0) +
heads['pisonotiene'] + heads['abastaguano'] + (heads['cielorazo'] == 0))plt.figure(figsize = (10, 6))
sns.violinplot(x = 'warning', y = 'Target', data = heads)
plt.title('Target vs Warning Variables')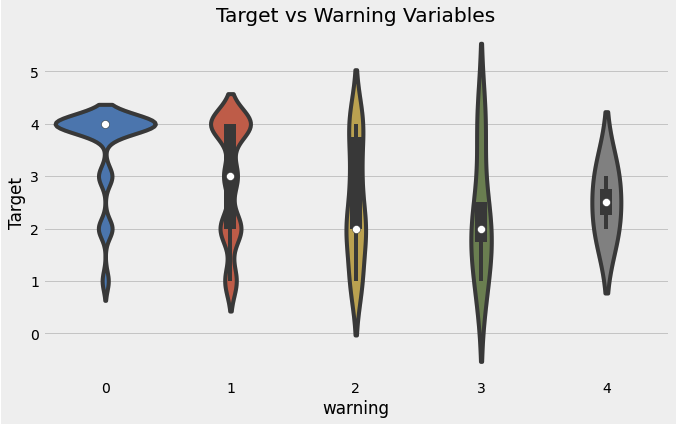
plot_categoricals('warning', 'Target', data = heads)
bonus: 해당 가구에서 냉장고, 컴퓨터, 태블릿 혹은 TV를 갖고있으면bonus
heads['bonus'] = 1 * (heads['refrig'] + heads['computer'] + (heads['v18q1'] > 0) + heads['television'])
sns.violinplot('bonus', 'Target', data = heads, figsize = (10, 6))
plt.title('Target vs Bonus Variable')Per Capita Features
각 가구와 전자기기와의 비율 계산
heads['phones-per-capita'] = heads['qmobilephone'] / heads['tamviv']
heads['tablets-per-capita'] = heads['v18q1'] / heads['tamviv']
heads['rooms-per-capita'] = heads['rooms'] / heads['tamviv']
heads['rent-per-capita'] = heads['v2a1'] / heads['tamviv']Exploring Household Variables
- Pearson Correlation : 두 변수 사이의 선형 관계를 -1 ~ 1 까지 측정한 계수
- Spearman Correlation : 두 변수 사이의 관계를 -1 ~ 1 까지 측정한 계수
from scipy.stats import spearmanr
def plot_corrs(x, y):
spr = spearmanr(x, y).correlation
pcr = np.corrcoef(x, y)[0, 1]
data = pd.DataFrame({'x': x, 'y': y})
plt.figure(figsize = (6, 4))
sns.regplot('x', 'y', data = data, fit_reg = False)
plt.title(f'Spearman: {round(spr, 2)}; Pearson: {round(pcr, 2)}')Target혹은 교육기간과 같은 ordinal 변수에서는 Spearman 상관계수가 더 자주 사용된다- 실제 데이터에서는 두 변수 사이에 선형 관계를 이루는 경우는 거의 없다. Pearson 상관계수가 어느정도 가늠을 하게 해줄 순 있지만, 비교함에 있어 가장 좋은 방법은 아니다
train_heads = heads.loc[heads['Target'].notnull(), :].copy()
pcorrs = pd.DataFrame(train_heads.corr()['Target'].sort_values()).rename(columns =
{'Target': 'pcorr'}).reset_index()
pcorrs = pcorrs.rename(columns = {'index': 'feature'})
print('Most negatively correlated variables:')
print(pcorrs.head())
print('\nMost positively correlated variables:')
print(pcorrs.dropna().tail())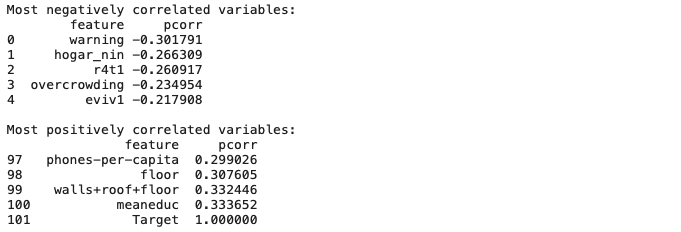
import warnings
warnings.filterwarnings('ignore', category = RuntimeWarning)
feats = []
scorr = []
pvalues = []
for c in heads:
# 숫자일 때에만 유효
if heads[c].dtype != 'object':
feats.append(c)
# Spearman correlation 계산
scorr.append(spearmanr(train_heads[c], train_heads['Target']).correlation)
pvalues.append(spearmanr(train_heads[c], train_heads['Target']).pvalue)
scorrs = pd.DataFrame({'feature': feats, 'scorr': scorr, 'pvalue': pvalues}).sort_values('scorr')- Spearman 상관계수는
pvalue와 함께 나오는데, 이는 관계의 중요성을 나타내는 지수이다
print('Most negative Spearman correlations:')
print(scorrs.head())
print('\nMost positive Spearman correlations:')
print(scorrs.dropna().tail())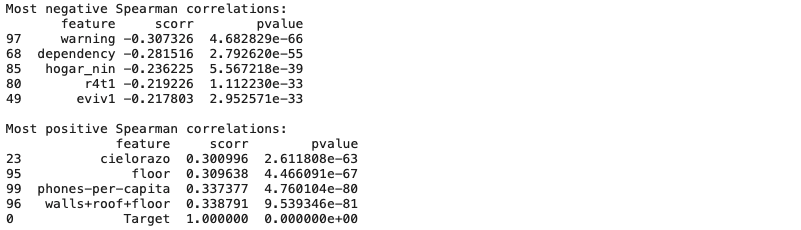
corrs = pcorrs.merge(scorrs, on = 'feature')
corrs['diff'] = corrs['pcorr'] - corrs['scorr']
corrs.sort_values('diff').head()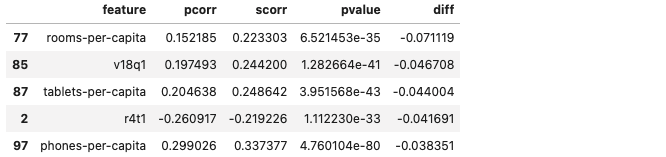
corrs.sort_values('diff').dropna().tail()
Targetvsdependency
sns.lmplot('dependency', 'Target', fit_reg = True, data = train_heads, x_jitter = 0.05, y_jitter = 0.05)
plt.title('Target vs Dependency')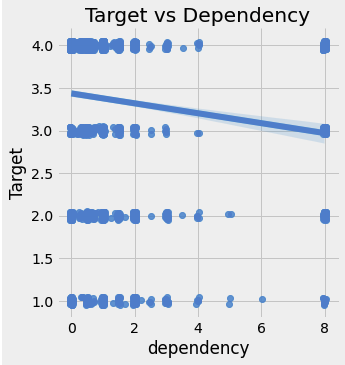
- 언뜻 보면 연관성이 없는 것처럼 보이지만,
dependency가 증가할수록Target값이 감소한다
sns.lmplot('rooms-per-capita', 'Target', fit_reg = True, data = train_heads,
x_jitter = 0.05, y_jitter = 0.05)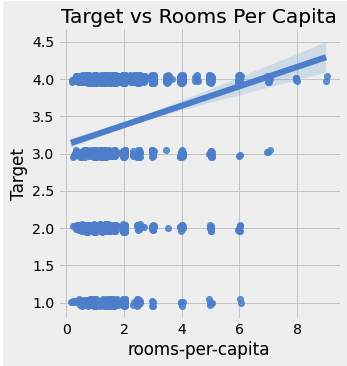
Correlation Heatmap
variables = ['Target', 'dependency', 'warning', 'walls+roof+floor', 'meaneduc', 'floor', 'r4m1', 'overcrowding']
# 연관성 계산
corr_mat = train_heads[variables].corr().round(2)
# 상관계수 히트맵
plt.rcParams['font.size'] = 18
plt.figure(figsize = (12, 12))
sns.heatmap(corr_mat, vmin = -0.5, vmax = 0.8, center = 0, cmap = plt.cm.RdYlGn_r, annot = True)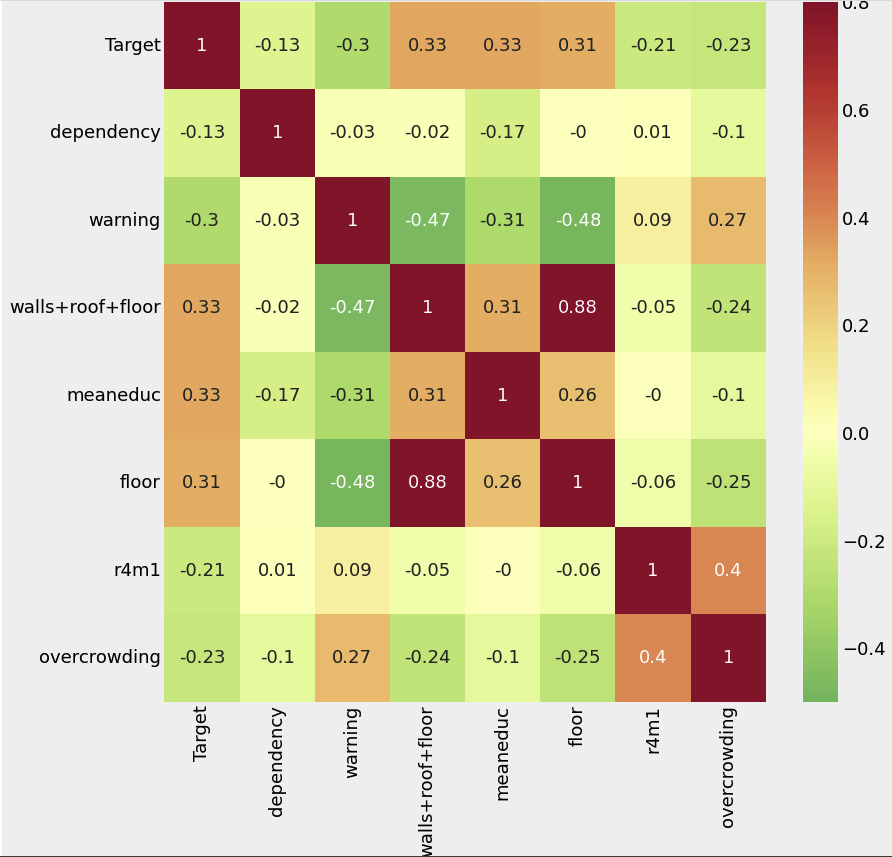
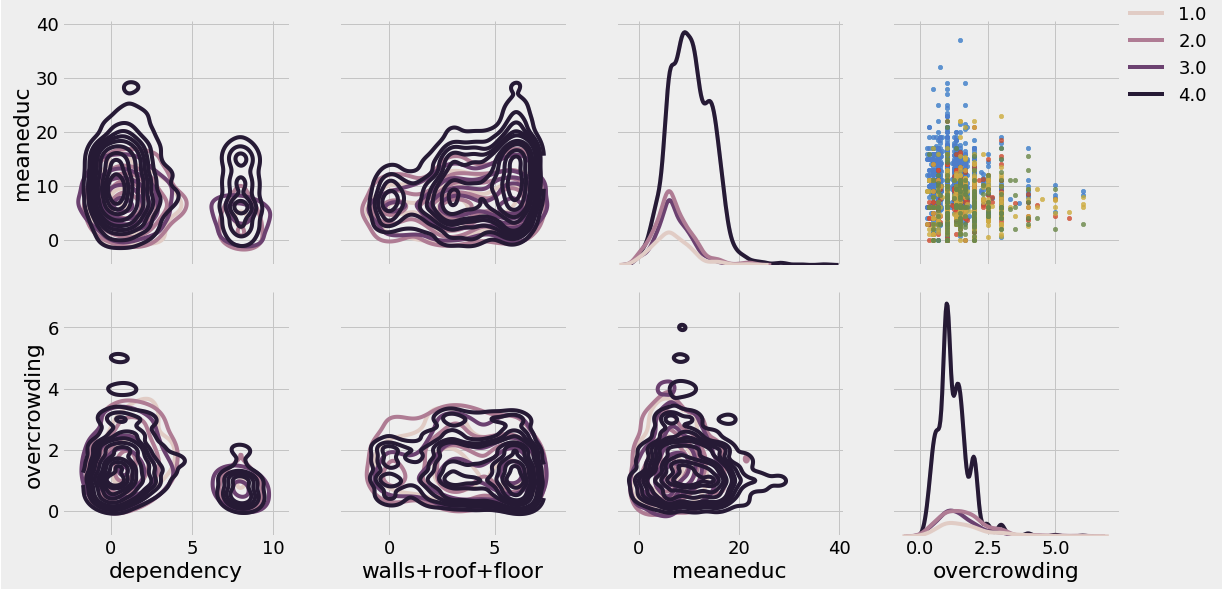
Features Plot
import warnings
warnings.filterwarnings('ignore')
# Plotting 위한 데이터 복사
plot_data = train_heads[['Target', 'dependency', 'walls+roof+floor', 'meaneduc', 'overcrowding']]
# Pairgrid object 생성
grid = sns.PairGrid(data = plot_data, size = 4, diag_sharey = False, hue = 'Target',
hue_order = [4,3,2,1], vars = [x for x in list(plot_data.columns) if x != 'Target])
grid.map_upper(plt.scatter, alpha = 0.8, s = 20)
grid.map_diag(sns.kdeplot)
grid.map_lower(sns.kdeplot, cmap = plt.cm.OrRd_r)
grid = grid.add_legend()
plt.suptitle('Feature Plots Colored By Target', size = 32, y = 1.05)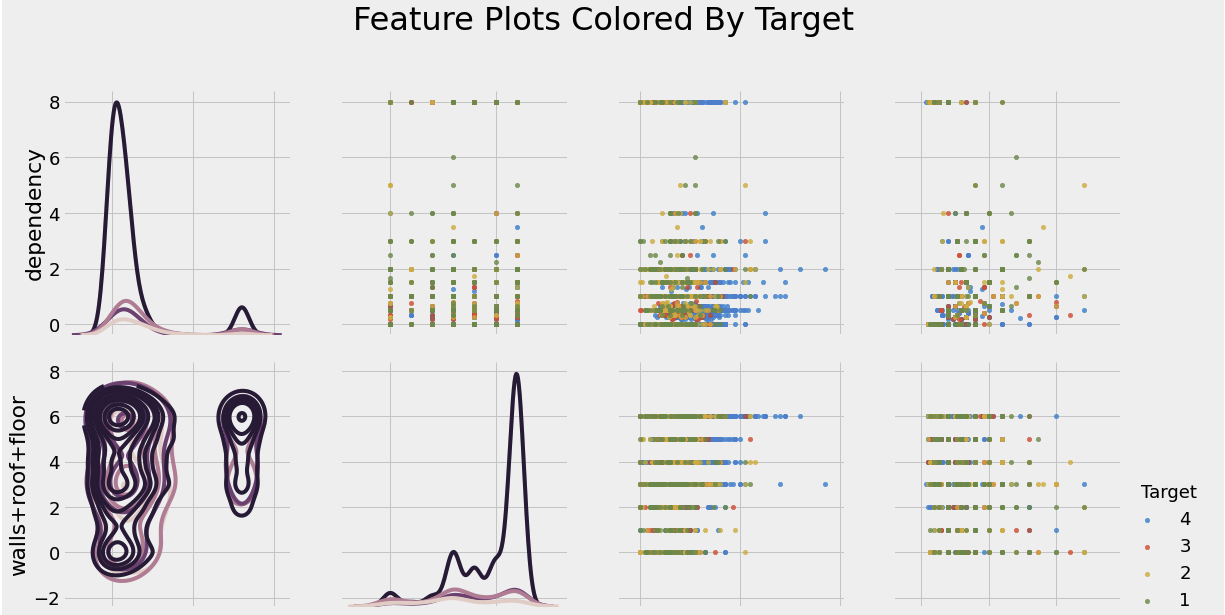
household_feats = list(heads.columns)
데이터 엔지니어로 전향중인 백엔드 개발자입니다