Kaggle Link : https://www.kaggle.com/code/yoontaeklee/spacex-falcon-9-firsts-stage-landing-prediction
import numpy as np
import pandas as pd
import missingno as msno
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import preprocessing
# Allows us to split out data into training and testing data
from sklearn.model_selection import train_test_split
# Allows us to test parameters of classification algorithms and find the best one
from sklearn.model_selection import GridSearchCV
# Logistic Regression classification algorithm
from sklearn.linear_model import LogisticRegression
# Support Vector Machine classification algorithm
from sklearn.svm import SVC
# Decision Tree classification algorithm
from sklearn.tree import DecisionTreeClassifier
# K Nearest Neighbors classification algorithm
from sklearn.neighbors import KNeighborsClassifierProcess
- 데이터셋 확인 (null data)
- EDA (Exploratory Data Analysis)
- Feature Engineering (one-hot encoding, class 나누기, 구간 나누기 등)
- Model 만들기
1. 데이터셋 확인 (null data)
df = pd.read_csv("https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DS0321EN-SkillsNetwork/datasets/dataset_part_1.csv")
df.head(10)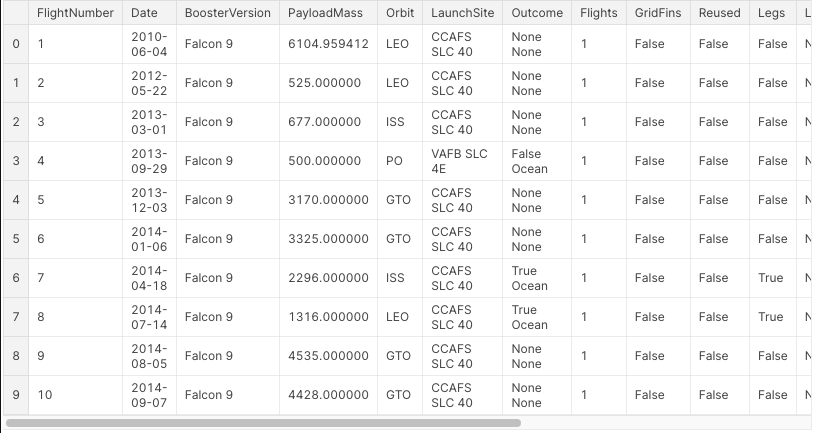
df.describe()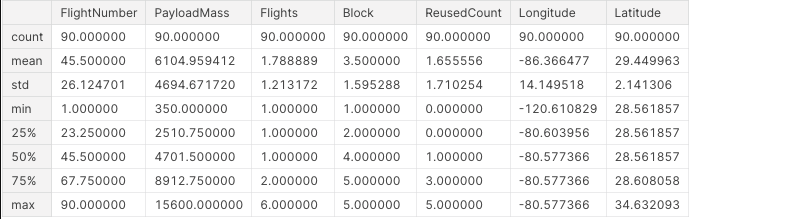
1.1 Null data 확인
for column in df.columns:
msg = 'column: {:>10}\t Percent of NaN Value: {:.2f}%'
.format(column, 100 * (df[column].isnull().sum()) / df[column].shape[0])
print(msg)

- missingno 라이브러리 통해 더 쉽게 null data 확인
msno.matrix(df=df.iloc[:,:], figsize=(7,7), color=(0.3,0.3,0.3))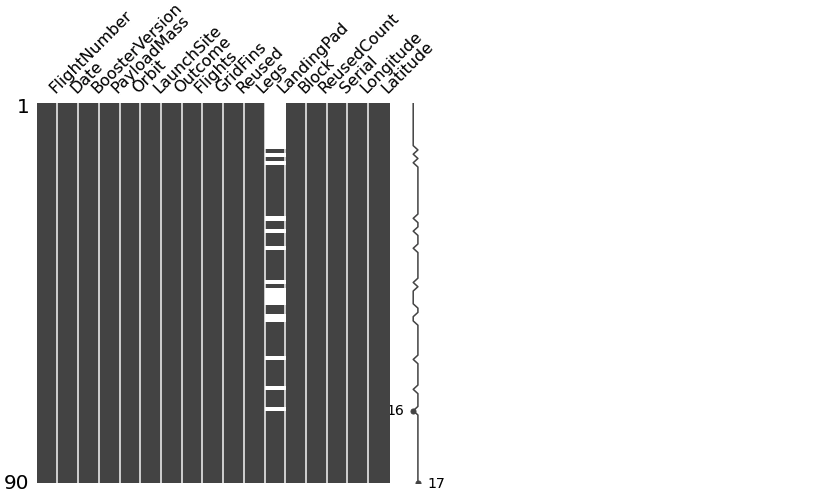
msno.bar(df=df.iloc[:,:], figsize=(7,7), color=(0.3,0.3,0.3))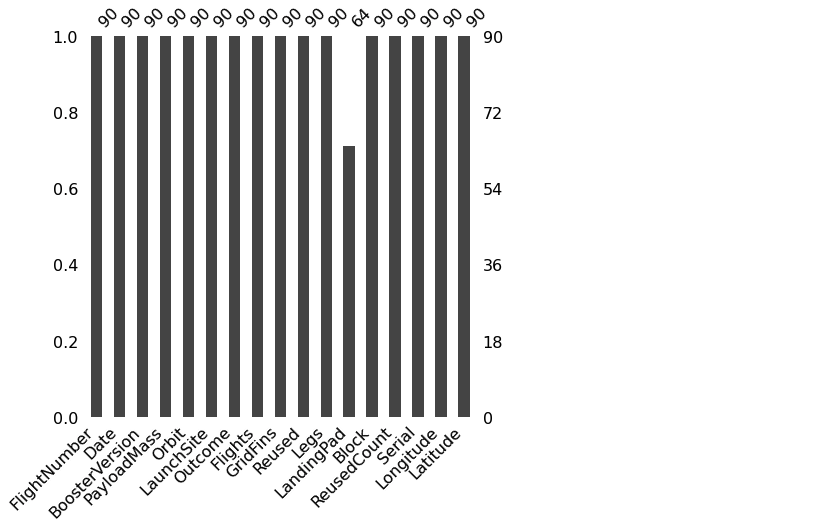
1.2 Target label 확인
- Outcome 의미
- True Ocean : 특정 바다에 성공적으로 착륙
- False Ocean : 특정 바다에 착륙 실패
- True RTLS : 특정 Ground Pad에 성공적으로 착륙
- False RTLS : 특정 Ground Pad에 착륙 실패
- True ASDS : 드론쉽에 성공적으로 착륙
- False ASDS : 드론쉽에 착륙 실패
- None ASDS, None None : 착륙 실패
landing_outcomes = df.Outcome.value_counts()
print(landing_outcomes)
for i, outcome in enumerate(landing_outcomes.keys()):
print(i,outcome)
- 이전의 타이타닉 프로젝트와 마찬가지로, 최종 결과만 중요 ⇒ 성공, 실패로만 분류
bad_outcomes = set(landing_outcomes.keys()[[1,3,5,6,7]])
landing_class = []
for outcome in (df['Outcome']):
if outcome in bad_outcomes:
landing_class.append(0)
else:
landing_class.append(1)
df['Class'] = landing_class
df[['Class']].head(10)
2. EDA (Exploratory Data Analysis)
- 모델에 쓸만한 feature 탐색
2.1 FlightNumber vs Payload
sns.catplot(y="PayloadMass",x="FlightNumber",hue="Class",data=df,aspect=5)
plt.xlabel("Flight Number", fontsize=22)
plt.ylabel("Pay load Mass (kg)", fontsize=22)
plt.show()
2.2 FlightNumber vs LaunchSite
sns.catplot(y="LaunchSite",x="FlightNumber",hue="Class",data=df,aspect=5)
plt.xlabel("Flight Number",fontsize=22)
plt.ylabel("Launch Site",fontsize=22)
plt.show()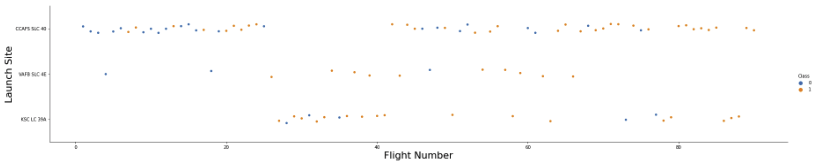
2.3 Payload vs LaunchSite
sns.catplot(y="LaunchSite",x="PayloadMass",hue="Class",data=df,aspect=5)
plt.xlabel("Payload Mass (KG)", fontsize=22)
plt.ylabel("Launch Site",fontsize=22)
plt.show()
- 탑재량이 많은 경우 CCAFS SLC 40 혹은 KSC LC 39A 에서 발사함
- CCAFS SLC 40 에서 발사하는 로켓 중, 8000kg 미만을 탑재하는 경우 더 높은 실패율을 보임
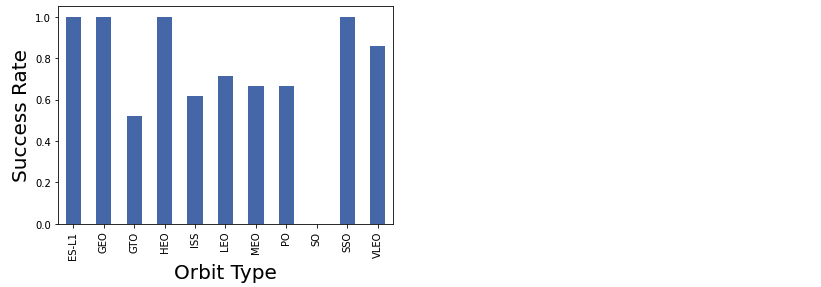
2.4 Orbit에 따른 성공률
df.groupby("Orbit").mean()["Class"].plot(kind='bar')
plt.xlabel("Orbit Type",fontsize=20)
plt.ylabel("Success Rate",fontsize=20)
plt.show()
2.5 FlightNumber vs Orbit Type
sns.catplot(y="Orbit",x="FlightNumber",hue="Class",data=df,aspect=5)
plt.xlabel("Flight Number",fontsize=20)
plt.ylabel("Orbit Type",fontsize=20)
plt.show()

- LEO의 경우 횟수와 성공이 비례
- GTO의 경우 횟수와 성공이 무관
2.6 Orbit Type vs Payload
sns.catplot(y="Orbit",x="PayloadMass",hue="Class",data=df,aspect=5)
plt.ylabel("Orbit type",fontsize=20)
plt.xlabel("Pay load (Kg)")
plt.show()
- GTO 궤도의 경우, 적재량이 많을수록 성공률이 떨어짐
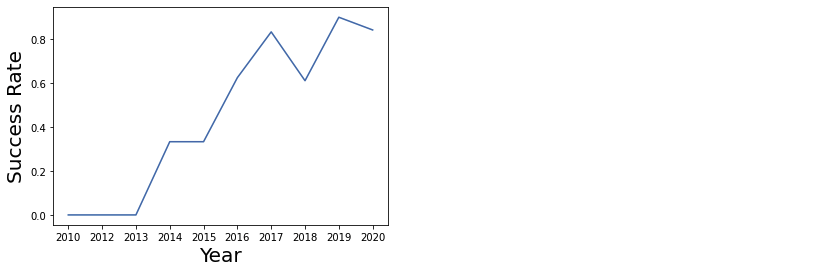
2.7 년도와 성공률과의 관계
- 현재 갖고있는 날짜 데이터에서 년도에 해당하는 부분만 추출
years = []
def Extract_year(date):
for i in df["Date"]:
years.append(i,split("-")[0]
return yearsdf1 = pd.DataFrame(Extract_year(df["Date"]), columns = ["year"])
df1["Class"] = df["Class"]
sns.lineplot(y=df1.groupby('year')['Class'].mean(),
x=np.unique(Extract_year(df['Date'])))
plt.xlabel("Year", fontsize = 20)
plt.ylabel("Success Rate", fontsize = 20)
plt.show()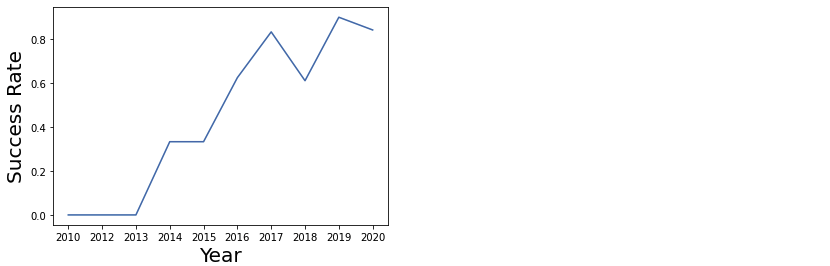
3. Feature Engineering
- 각 feature가 성공률에 얼마나 큰 영향을 미치는지 확인하고, 후에 모델에 사용
features = df[['FlightNumber','PayloadMass','Orbit','LaunchSite','Flights','GridFins','Reused','Legs','LandingPad','Block','ReusedCount','Serial']]
features.head()
3.1 One hot encoding
features_one_hot = pd.get_dummies(features, columns = ['Orbit','LaunchSite','LandingPad','Serial'])
features_one_hot.head()
features_one_hot.astype('float64')
4. Building Machine Learning Model and prediction using the trained model
- 기본 df에 있는 ‘Class’ feature’에서 새로운 numpy array를 만든다
Y = df['Class'].to_numpy()
Y
transform = preprocessing.StandardScaler()
X = transform.fit_transform(features_one_hot)- train_test_split 이용하여 트레이닝 데이터와 테스트 데이터 나누기
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,test_size=0.2, random_state=2)
print('Train set: ',X_train.shape, Y_train.shape)
print('Test set: ',X_test.shape, Y_test.shape)
- GridSearchCV 로 파라미터 최적화
parameters = {'C':[0.01,0.1,1], 'penalty':['l2'], 'solver':['lbfgs']}
lr = LogisticRegression()logreg_cv = GridSearchCV(lr,parameters,cv=10)
logreg_cv.fit(X_train,Y_train)
print('best parameters : ',logreg_cv.best_params_)
print('accuracy : ',logreg_cv.best_score_)
print('test set accuracy : ',logreg_cv.score(X_test, Y_test))
yhat = logreg_cv.predict(X_test)
plot_confusion_matrix(Y_test,yhat)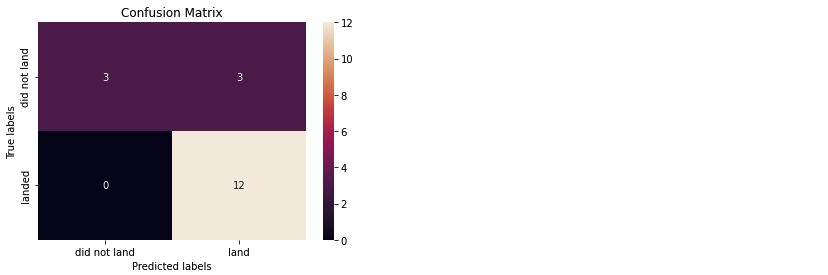
- 여기서 중요한 것은, 성공 실패가 아님 ⇒ 성공할 것이라고 예측했으나 실패한 경우가 주목해야 하는 부분
parameters = {'kernel':('linear','rbf','poly','rbf','sigmoid'),'C':np.logspace(-3,3,5),'gamma':np.logspace(-3,3,5)}
svm = SVC()svm_cv = GridSearchCV(svm, parameters, cv=10)
svm_cv.fit(X_train, Y_train)
print("best parameters : ",svm_cv.best_params_)
print("accuracy : ",svm_cv.best_score_)
print("test set accuracy : ",svm_cv.score(X_test, Y_test))
yhat = svm_cv.predict(X_test)
plot_confusion_matrix(Y_test,yhat)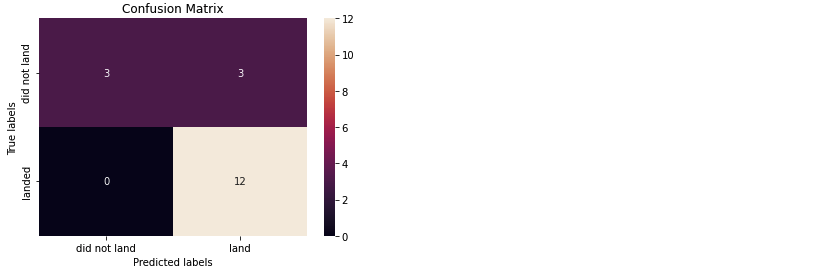
parameters = {'criterion': ['gini','entropy'],
'splitter':['best','random'],
'max_depth':[2 * n for n in range(1,10)],
'max_features':['auto','sqrt'],
'min_samples_leaf':[1,2,4],
'min_samples_split':[2,5,10]}
tree = DecisionTreeClassifier()tree_cv = GridSearchCV(tree, parameters, cv = 10)
tree_cv.fit(X_train, Y_train)
print("best parameters : ",tree_cv.best_params_)
print("accuracy : ",tree_cv.best_score_)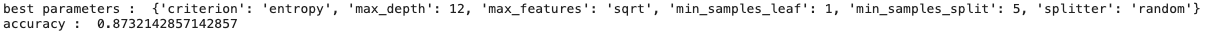
print("test set accuracy : ",tree_cv.score(X_test,Y_test))
yhat = tree_cv.predict(X_test)
plot_confusion_matrix(Y_test,yhat)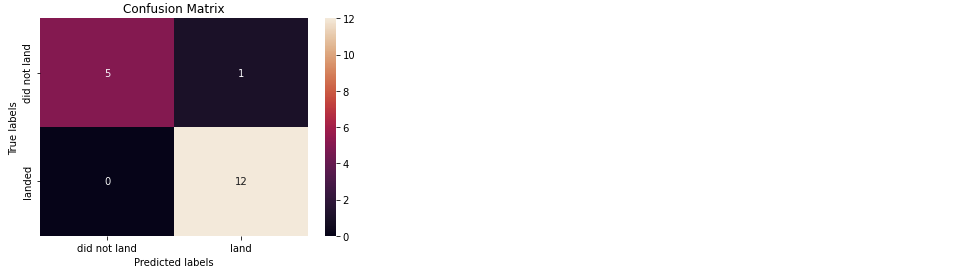
parameters = {'n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'algorithm': ['auto', 'ball_tree', 'kd_tree', 'brute'],
'p': [1,2]}
KNN = KNeighborsClassifier()knn_cv = GridSearchCV(KNN,parameters,cv=10)
knn_cv.fit(X_train, Y_train)
print("best parameters : ",knn_cv.best_params_)
print("accuracy : ",knn_cv.best_score_)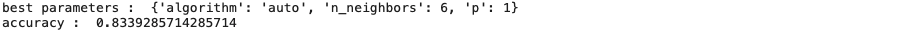
print("test set accuracy : ",knn_cv.score(X_test,Y_test))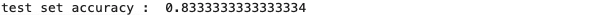
yhat = knn_cv.predict(X_test)
plot_confusion_matrix(Y_test,yhat)
- 모든 테스트 결과, Decision Tree Classification 의 방법이 가장 높은 정확도를 보였다

데이터 엔지니어로 전향중인 백엔드 개발자입니다