https://velog.io/@humpose/Fundamental-of-Machine-Learning
이전 시간에 다뤘던 지도 학습, 비지도 학습에 이어 강화 학습을 설명해보려고 한다.
강화학습이란?🤔
지금까지 우리가 살펴본 딥러닝에는 항상 인간이 훈련 데이터와 정답 레이블을 제공해야 했다.
그에 반해 강화 학습은 에이전트가 스스로 행동해 학습한다.
그렇다면 강화학습의 목적은 무엇일까?
많은 시간 단계에서 미래 보상을 최대화하는 것이다.
강화학습의 구성
에이전트(agent): 강화 학습의 중심이 되는 객체
환경(Environment): 에이전트가 작동하는 물리적 세계
상태(state): 에이전트의 현재 상황
보상(reward) : 환경으로부터의 피드백
액션(action) : 에이전트의 행동
에이전트가 미래에 받을 보상은 약간 할인해서 계산한다.
미래의 보상은 불확실하므로 상대적으로 즉각적인 보상을 선호하게 만들어야 하기 때문이다.
ex)최단 경로 탐색 알고리즘
할인 계수는 λ(0에서 1 사이의 값)를 사용한다.
[강화학습의 종류는 크게 전통적인 Q-학습과 DEEP-Q학습으로 나눌 수 있다.]
전통적인 Q-학습
Q 함수란?
Q 함수는 상태 s에 있는 에이전트가 어떤 액션 a를 실행하여서 얻을 수 있는 미래 총 보상값의 기대값(확률적인 환경을 가정했을 경우)이다
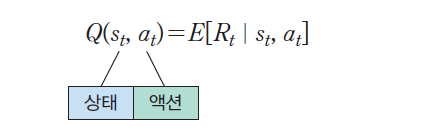
확률적인 환경이 아니라면 Q 함수는 상태 s에 있는 에이전트가 어떤 액션 a를 실행해서 얻을 수 있는 총 보상값이다.
(총 보상값 = 미래의 보상값 * λ)
정책이란?
현재 상태 s에서 가장 좋은 액션을 추론하기 위해서는 어떤 정책 r(s)을 필요로 한다. 가장 상식적인 정책은 미래 보상을 최대화할 수 있는 액션을 선택하는 것이다.
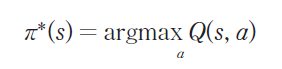
현재 상태에서 가능한 모든 액션 중에서 가장 Q 값이 높은 액션을 선택하면 된다.
Q 값 순환 관계식
결국 이러한 위 사항들을 고려했을때,
상태 s에서 액션 a를 실행하였을 때 받는 보상 r에, 다음 상태에서의 Q 값 중에서 최대값을 더하는 관계식이 나타난다.
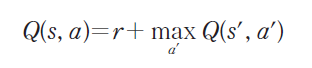
최종적인 Q 값 업데이트 방정식
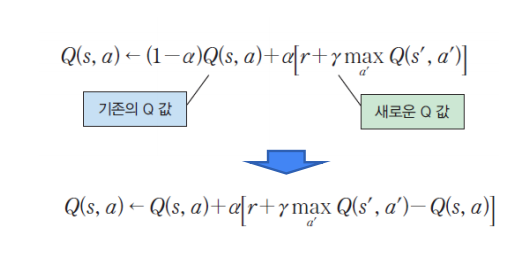
+학습 중 새로운 모험을 하고 싶다면?
지금까지 우리가 살펴본 Q-학습은 에이전트가 항상 동일한 경로만을 탐색하는 문제가 있다.
처음에는 Q 값이 작은 액션이라고 하더라도 시도해볼 필요가 있다. 이것을 탐사라고 한다.
강화 학습에서도 처음에는 모험을 할 필요가 있다. 이것은 e-greey 알고리즘으로 가능하다.
e-greey 알고리즘에서는 epsilon 의 확률로 새로운 액션을 선택한다. (1- epsilon ) 확률로 기존의 Q 값을 선택한다.
통상적으로 epsilon 은 처음에는 크게, 반복이 진행되면 점점 작게 설정한다.
Deep Q-학습
원래의 Q-Learning 알고리즘에 딥러닝을 결합하여 복잡한 환경에서도 효과적으로 학습할 수 있게 하는 방식이다.
왜 Deep-Q를 사용할까?
전통적인 Q-학습은 에이전트를 위한 치트 시트를 만드는 간단하지만 강력한 알고리즘이다.
하지만 이 치트 시트가 너무 길면 어떻게 될까?
해당 테이블을 저장하고 업데이트하는 데 필요한 메모리 양은 상태 수가 증가함에 따라 감당할 수 없을 만큼 증가한다.
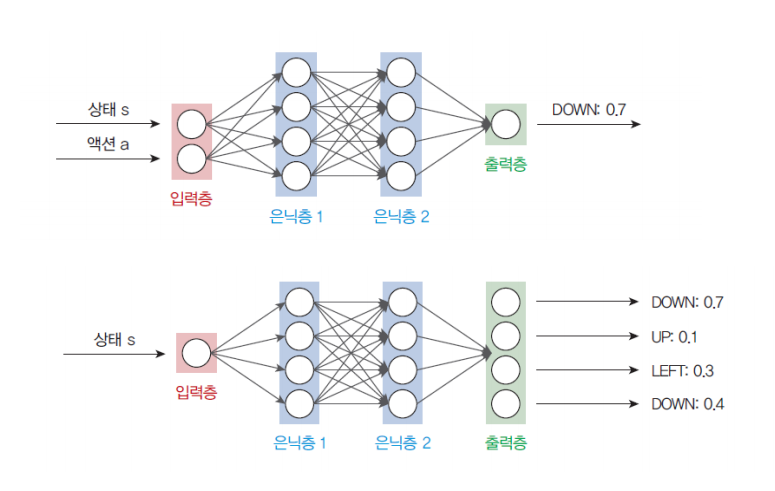
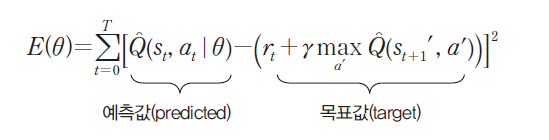
선형 회귀 신경망을 통하여 생성된 출력값을 예측값을 Q(s, a)일때, 특정한 액션 a를 실행한 후 신경망이 생성한 Q 값(목표값)과 비교하면서 차이를 줄이는 방향으로 가중치를 변경한다.
Deep Q-학습의 단점
- 액션 공간이 비연속적이고 작을 때는 가능, 하지만 연속적인 액션 공간은 처리가 불가능하다.
- 정책은 Q 함수로부터 결정적(determinsitic)으로 계산된다. 따라서 확률적(stochastic)인 정책을 학습할 수 없다.
