읽은날짜 : 2020.11.16
2023.01.20 기준 citation : 415
Yoo, D., & Kweon, I. S. (2019). Learning loss for active learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 93-102).
이 당시에 active learning 조금 관심을 가지면서 근본 논문인 Settles, B. (2009). Active learning literature survey. 을 읽었음. 본 논문은 active learning 를 딥러닝에 완전히 신박한 방법으로 적용시킨 논문 이었음.
Active learning 이란
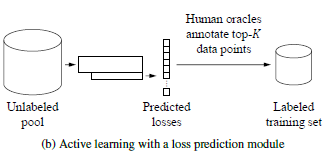
Active learning 은 머신러닝의 방법 중 하나로, 크기가 작은 initial labeled training dataset으로 모델을 학습하면서, 동시에 large unlabeled dataset 에서 가장 informative한 샘플을 반복적으로 선택하여 training set에 추가하는 방식이다.
목적은 모델 성능의 향상에 가장 큰 영향을 미칠 sample을 선택하여 annotation (limited resource)을 수행하고자 하는 것이다.
이때 선택 과정이 중요한데, uncertainty, diversity, expected model change, representativeness 등의 여러 approach가 있음.
정리하자면, 모델의 성능 향상을 하기 위해 가장 효과적인 sample을 선택하고 이를 annotation하는, 효율적인 방식으로 학습을 하는 것임.
Introduction
Active learning 의 필요성 등에 대한 설명과 기존 방법론의 한계를 설명함.
- Uncertainty-based
- constructing a committee is too expensive for current deep networks learned with large data
- Distribution-based
- may require extra engineering to design a location-invariant feature space for localization tasks
- Expected model change
- successful for small models but is computationally impractical for recent deep networks
본 논문은 딥러닝 모델들이 어떤 loss값(하나의 scalar)을 minimize하는 것을 목적으로 한다는 것에 초점을 맞춤.
또한 high loss를 가질 것이라고 예상되는 데이터가 모델에 informative 할 것이라는 가정을 함. (직관적이긴 함)
따라서 loss prediction module 을 통해 입력 데이터에 대한 loss를 예측하도록 함.
Related Work
생략
Method
3.1. Overview
그냥 active learning scenario에 대한 설명 및 notations
3.2 Loss Prediction Module
몇 문장으로 깔끔하게 정리가 될 정도로 매우 간단하고 신박한 방법임.
The loss prediction module aims to minimize the engineering cost of defining task-specific uncertainty for active learning.
We also want to minimize the computational cost of learning the module.
To this end, we design a module that is 1) much smaller than the target model, and 2) jointly learned with the target model.
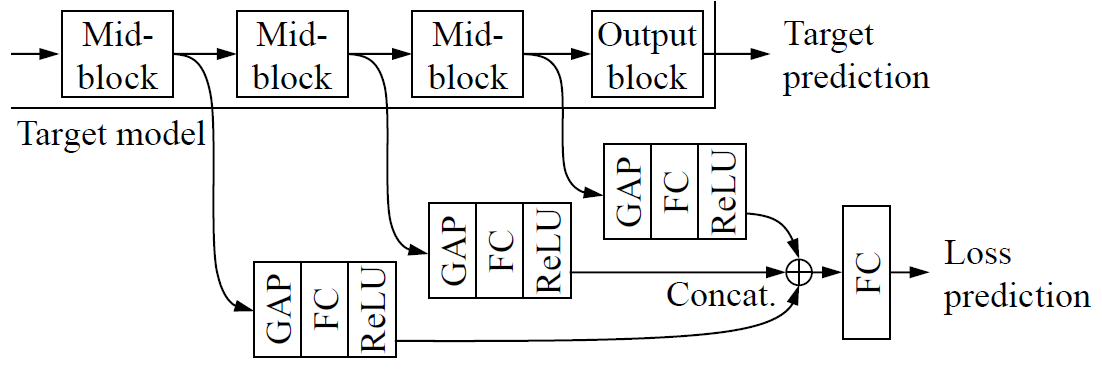
위의 그림과 같이 feature extractor 부분에서 나오는 feature 들을 를 통해 차원을 줄여준 다음에 해준 feature 를 사용하여 loss를 예측하도록 한다.
3.3 Learning Loss
Module 만큼이나 깔끔하고 간단함.
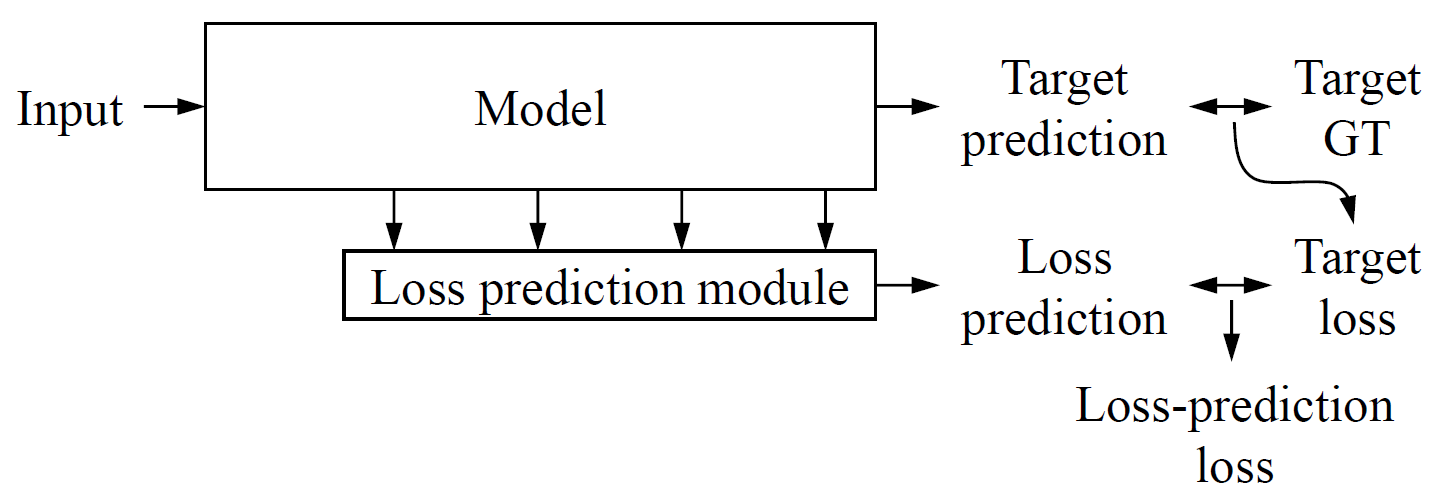
애초에 task를 수행하면서 target loss가 나오게 되는데 이를 loss prediction moduel의 ground truth로 이용하는 것임.
논문의 수식을 따라 최종 loss function을 아래와 같은데,
이때, 모델이 학습됨에 따라 real loss 자체는 계속 작아질 것이기 때문에 MSE loss로 학습하는 것은 적절하지 않다고 함. 실험했을 때도 성능이 별로였다고 함.
Epoch이 진행될수록 loss는 작아지는데 당연히 간단한 MLP 몇층의 구조인 loss prediction module이 이러한 경향을 파악해서 예측하는 것이 불가능.
아마 실험 몇 번 해보고 잘 안되니깐 다른 방법을 강구하지 않았을까
MSE loss를 대체하기 위해 본 논문에서는 다음과 같은 loss를 제안함.
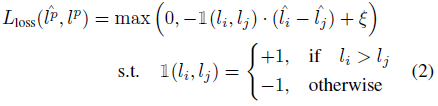
우선 하나의 배치 내에 개의 pair를 만들고, loss 를 측정
위의 식에서 제약조건을 통해 의 대소를 판별하고, loss prediction module 에서 나온 도 대소 관계가 알맞게 나왔는지 측정함
사실 본 논문에서 하려고 하는 것은 최종적으로 active learning 임. 본 논문에서의 관점은 이기 때문에 사실상 active learning을 위해서는 정확한 loss를 계산하지 않고, data point 들 중에 어떤 것이 가장 정보가 많은지, 즉 loss가 어떤 것이 제일 큰지만 판별하면 되기 때문에 논리적으로 적절하다는 생각.
Experiment
실험은 active learning 관련 실험이 조금 빈약함.
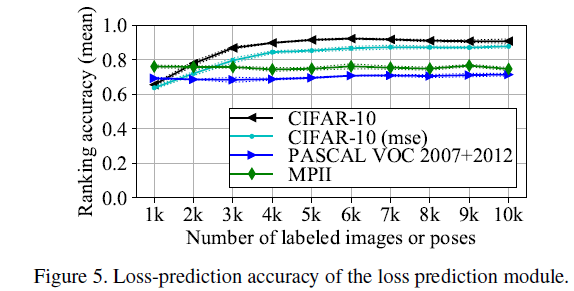
True loss에서 ranking이 높은 sample 들에 대해 실제로 얼마나 잘 맞추었나를 본 실험.
Loss 값 자체가 아니라 뭐가 더 어려운지 판별가능한지를 측정한 실험임.
Critics
- 아이디어가 매우 참신함. DNN에서 data point가 모델에게 줄 수 있는 정보량과 loss가 비례하다라는 직관을 통해 active learning에 적용한 점.
- Classification, object detection, pose estimation 등의 task에 대해 실험하여 task-agnostic하게 잘 작동한다는 것을 보임
- 개의 sample을 선택할 때, 기존 연구에서 특정 class가 많이 선택될 수도 있다는 문제가 있어서, 이를 random subset을 구성하는 걸로 해결함. (diversity를 만족하기 위한 노력)
- LPM에서 feature map을 좀 더 다양하게 합성할 수 있지 않았을까
- 비교 방법론이 너무 적음
- Core-set과 비교했는데, 실제 core-set 논문의 실험결과와는 너무 차이가 남
- LPM loss를 그냥 common하게 사용되는 다양한 ranking loss들로 설정했으면 어땠을까 하는 생각.
- 다양한 loss function, 다양한 구조적 변화로 더 재미있는 결과를 이끌어 낼 수 있었을 것 같은데 실험적인 측면에서 다소 아쉬운 부분이 있음.
Pytorch Implementation
- Loss의 대소관계 말고 ranking 자체를 예측하거나, LPM의 구조를 바꾸는 등의 다양한 variant를 만들어봄.
- Github
