읽은 날짜 : 2020.10.26
2023.01.12 기준 citation : 16355
Lin, T. Y., Dollár, P., Girshick, R., He, K., Hariharan, B., & Belongie, S. (2017). Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2117-2125).
그 전에 발표해왔던 세미나가 모두 비전 관련이였고, 특히 object detection이 재밌게 느껴져서 관련 논문들을 찾아보다가 읽었던 것으로 기억남.
그리고 이거 발표준비를 하면서 RCNN, Fast-RCNN, Faster-RCNN, SPP-Net 등 object detection 계보 논문들을 쭉 읽었었던 기억이 남.
Introduction
첫문장부터 문제를 정의하고 들어가는데
Recognizing objects at vastly different scales is a fundamental
challenge in computer vision.
기존 방법들은 아래 그림과 같은데 각각 한계를 가짐
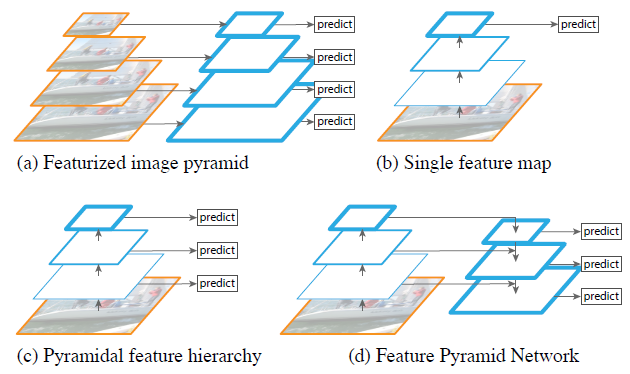
(a)
- computationally expensive both in inference and memory usage
- Inconsistency between train and test-time inference
(b)
- not robust to variance in scale
(c)
- large semantic gaps between different depth
harms the representation capacity for object detection
본 논문은 위의 문제들을 다 해결하면서 서로 다른 scale의 객체들도 잘 탐지할 수 있게하는 FPN을 제안.
간략하게는 low-resolution (semantically strong)과 high-resolution (semantically weak) 한 feature 들을 합치는 top-down pathway 와 lateral connection 을 통해 다양한 레벨의 semantic 들을 얻을 수 있음
Related work
Hand-engineered feature and early neural network
옛날에 사용하던 SIFT, HOG와 같은 manual feature 들에 대한 설명.
Deep ConvNet object detector
객체탐지가 발전해온 과정에 대한 설명인데 그냥 최근 나온 survey 논문 보는 것이 더 좋을 듯.
[출처 : ObjectDetectionin20Years : ASurvey]
Methods using multiple layers
옛날 것
Feature Pyramid Network
Bottom-up pathway
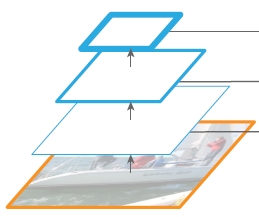
그냥 feedforward computation 을 통해서 여러 scale 의 feature 를 뽑는 것.
Top-down pathway and lateral connection
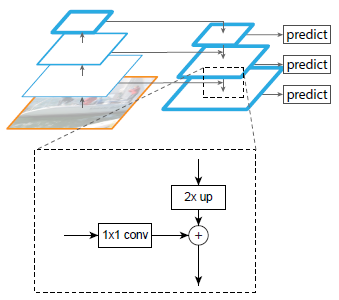
-
Bottom-up 에서 마지막에 얻어진 low-resoltuion + high semantic feature 를 upsampling. 이때 upsampling 은 nearest neighbor upsampling 을 사용함.

-
Upsampled 된 feature map 과 그 크기와 같은 크기를 가지는 bottom-up 에서 얻어진 feature map을 elementwise 하게 더 함. 이때 channel reduction 을 위해 bottom-up feature는 1 1 convolution 을 거침.
여기 있는 철학이 low-resolution의 feature를 upsampling 하더라도, high-semantic 한 정보가 있을 것이고, 같은 크기를 같는 bottom-up feature는 higher-resolution이라서 high-semantic은 없지만 localization에 대한 정보는 더 많이 가지고 있을 것. 따라서 이를 잘 융합하여 feature 를 생성하면 여러 크기의 객체도 잘 탐지할 수 있을 것.
Critics
- High-resolution feature map에 엄청나게 많은 anchor를 다는 것보다 효율적이면서 효과적인 방법
- ResNet의 skip-connection과 유사하게 정보를 보존할 수 있는 방식으로 풍부한 feature를 얻게함
- Plug-in manner 로 쉽게 적용할 수 있음
- 실험을 매우 잘 구성함.
-
지금 생각해보면 간단하게 element-wise하는 것보다 attention을 추가해도 흥미로웠을 것 같음.
-
실험에 대한 불친절한 설명.
- 처음에 잘 모를 떄 읽으면서 RPN에 어떻게 적용했는지, segmentation에는 어떻게 적용하여 실험한 것인지가 불분명했음. 지금은 그냥 코드를 먼저 보고 이해할 것 같다.
