Movielens 데이터를 이용하여 추천시스템만들기
데이터 준비
Movielens 데이터는 rating.dat 안에 인덱싱까지 완료된 사용자-영화-평점 데이터가 정리되어있습니다.
import pandas as pd
import os
rating_file_path=os.getenv('HOME') + '/aiffel/recommendata_iu/data/ml-1m/ratings.dat'
ratings_cols = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_csv(rating_file_path, sep='::', names=ratings_cols, engine='python', encoding = "ISO-8859-1")
orginal_data_size = len(ratings)
ratings.head()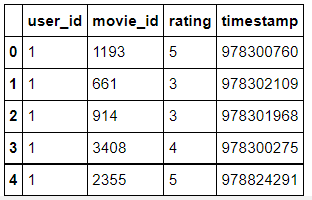
전처리
3점 이상의 점수를 받은 데이터를 이용하겠습니다.
# 3점 이상만 남깁니다.
ratings = ratings[ratings['rating']>=3]
filtered_data_size = len(ratings)
print(f'orginal_data_size: {orginal_data_size}, filtered_data_size: {filtered_data_size}')
print(f'Ratio of Remaining Data is {filtered_data_size / orginal_data_size:.2%}')orginal_data_size: 1000209, filtered_data_size: 836478
Ratio of Remaining Data is 83.63%
# rating 컬럼의 이름을 count로 바꿉니다.
ratings.rename(columns={'rating':'count'}, inplace=True)ratings['count']
위 데이터는 숫자로 이루어져 있어서 어떤 영화를 의미하는지 알 수 없습니다. 그래서 그 정보를 가지고 있는 파일을 불러옵니다.
# 영화 제목을 보기 위해 메타 데이터를 읽어옵니다.
movie_file_path=os.getenv('HOME') + '/aiffel/recommendata_iu/data/ml-1m/movies.dat'
cols = ['movie_id', 'title', 'genre']
movies = pd.read_csv(movie_file_path, sep='::', names=cols, engine='python', encoding='ISO-8859-1')
movies.head()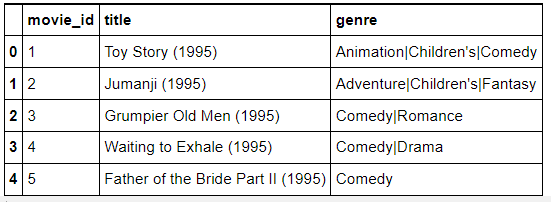
사용할 모델을 미리 불러옵니다.
from implicit.als import AlternatingLeastSquares
import os
import numpy as np
# implicit 라이브러리에서 권장하고 있는 부분입니다. 학습 내용과는 무관합니다.
os.environ['OPENBLAS_NUM_THREADS']='1'
os.environ['KMP_DUPLICATE_LIB_OK']='True'
os.environ['MKL_NUM_THREADS']='1'각 movie_id에 해당하는 영화가 무엇인지 딕셔너리로 만듭니다.
# 고유한 유저, 아티스트를 찾아내는 코드
movies_unique = movies['title'].unique()
# 유저, 아티스트 indexing 하는 코드 idx는 index의 약자입니다.
title_to_idx = {k:v for k,v in enumerate(movies_unique)}분석
- ratings에 있는 유니크한 영화 개수
- rating에 있는 유니크한 사용자 수
- 가장 인기 있는 영화 30개(인기순)
# 영화개수
print(ratings['movie_id'].nunique())
print(ratings['user_id'].nunique())
# 인기 많은 영화 30개
movie_count = ratings.groupby('movie_id')['user_id'].count()
movie_count.sort_values(ascending=False).head(30)3628
6039

제가 선택한 영화 5가지를 rating에 추가합니다!
제 아이디는 9999로 했습니다. 영화는 아무거나 다섯개 했습니다
# 본인이 좋아하시는 아티스트 데이터로 바꿔서 추가하셔도 됩니다! 단, 이름은 꼭 데이터셋에 있는 것과 동일하게 맞춰주세요.
my_favorite = ['1193' , '661' ,'914' ,'3408' ,'2355']
# 'zimin'이라는 user_id가 위 아티스트의 노래를 30회씩 들었다고 가정하겠습니다.
my_playlist = pd.DataFrame({'user_id': ['9999']*5, 'movie_id': my_favorite, 'count':[5]*5,'timestamp':[0]*5})
if not ratings.isin({'user_id':['9999']})['user_id'].any(): # user_id에 'zimin'이라는 데이터가 없다면
ratings = ratings.append(my_playlist) # 위에 임의로 만든 my_favorite 데이터를 추가해 줍니다.
# 잘 추가되었는지 확인해 봅시다.ratings.tail(10)
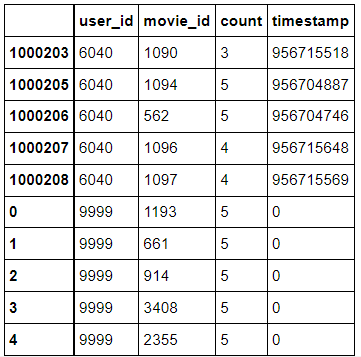
user_id와 movie 개수를 봅니다.
from scipy.sparse import csr_matrix
num_user = ratings['user_id'].nunique()
num_movie = ratings['movie_id'].nunique()
print(num_user)
num_movie데이터를 수정하면서 str과 int가 섞여있습니다. 그렇기 때문에 모두 int로 변환합니다. 이때 문자열도 '5'이런식으로 숫자로 변경할수 있어야합니다.
ratings=ratings.astype('int64')ratings.head(3)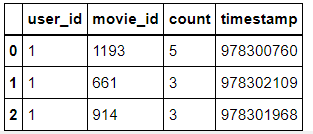
CSR matrix를 만듭니다.
csr_data = csr_matrix((ratings["count"], (ratings.user_id, ratings.movie_id)))
csr_dataals_model = AlternatingLeastSquares 모델을만듭니다
# Implicit AlternatingLeastSquares 모델의 선언
als_model = AlternatingLeastSquares(factors=100, regularization=0.01, use_gpu=False, iterations=15, dtype=np.float32)# als 모델은 input으로 (item X user 꼴의 matrix를 받기 때문에 Transpose해줍니다.)
csr_data_transpose = csr_data.T
csr_data_transposeals_model을 훈련시킵니다!
# 모델 훈련
als_model.fit(csr_data_transpose)모델에서 만든 벡터값을 찾습니다
name_vector, movie_vector = als_model.user_factors[9999], als_model.item_factors[1193]
벡터의 곱을 구합니다.
나온 값은 선호도를 의미합니다.
np.dot(name_vector, movie_vector)0.6661142
내가 선호하는 5가지 영화 중 하나와 그 외의 영화 하나를 골라 훈련된 모델이 예측한 나의 선호도를 파악해 봅니다.
similar_artist = als_model.similar_items(1193, N=15)
similar_artist1에 가까울수록 제가 선호하는 영화와 비슷하다는 의미인데 0.5 조차도 넘기 힘드네요... 사용한 데이터 기반으로 했는데도 힘들면.. 늘릴방법은 데이터 양을 늘리는 것일까요?
나의 선호도에서 숫자를 딕셔너리를 통해 어떤 제목인지 확인합니다.
[title_to_idx[i[0]] for i in similar_artist]
내가 가장 좋아할 만한 영화들을 추천받아 봅시다.
artist_recommended = als_model.recommend(9999, csr_data, N=20, filter_already_liked_items=True)
artist_recommended
추천받는게 더 낮네요,,, ㅜㅜ 1과 가까운 비슷한 영화를 추천받는 것은 생각보다 어려운 것일지도 모르겠습니다.
추천받은 숫자를 딕셔너리를 통해 영화를 추천받아봅니다.
[title_to_idx[i[0]] for i in artist_recommended]
Matrix Factorization
위에서 진행한 것처럼 M명의 사용자 N개의 영화에 대해 평가한 데이터를 포함한 m,n사이즈의 평가행렬을 만듭니다.
- 사용자는 사용자의 특성벡터가 되고 영화는 영화의 특성벡터가 됩니다.
- 벡터간 내적으로 얻어지는 값이 바로 선호도라고 합니다.
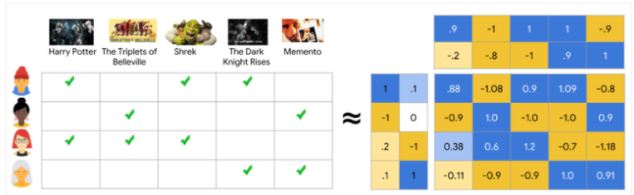
사용자가 영화를 좋게 평가했더라도 모델이 근사하고자 하는 것이 영화를 선호하는지 안하는지 이기 때문에 두 벡터의 곱은 count의 최고치인 5가 아니라 1에 가까워져야 합니다.
모든 사용자가 모든 영화를 보고 평가하는 것이 아니기 때문에 정확한 답을 내지는 못하지만 실제로 처음 영화를 보는데 있어서 어느정도 선호도를 평가해서 추천할 수 있다는 것에 의미가 있을 것 같습니다.
