딥러닝으로 CV 시작!
- 목 차
Previous Chapter
- 컴퓨터 비전 task "상상 해보기"
- 다층 퍼셉트론(Multi-Layer-Perceptron) 구조
- CNN 이해하기 (1_Channel Convolution)
- CNN 이해하기 (3_Channel Convolution)
- CNN 이해하기 (Pooling)
previous Chapter
- 심화된 CNN 구조
- Transfer Learning 이해하기
Current Chapter
- Object Detection
- Segmentation
last chapter
- 모델들의 아이디어와 구조(코드)
8. Object Detection
8-1) Image Classification vs Localization vs Detection
<CV 전체과정 복습>
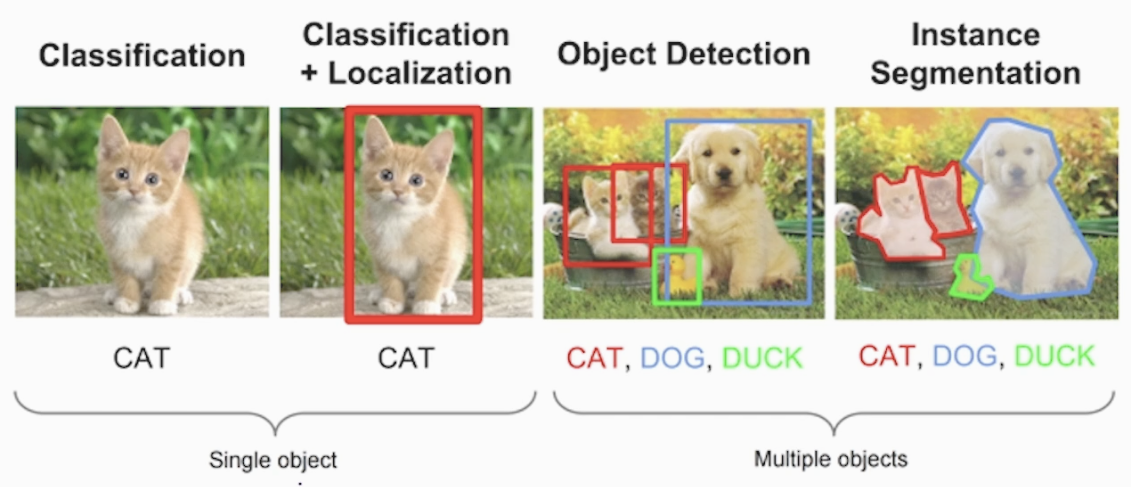
- Classification + Localization
객체(Object)를 BB(Bounding Box)를 통해 위치를 추적하고 분류 합니다 - Object Detection
여러개의 BB를 통해 개별개체(Instance)를 위치를 추적하고 분류 합니다 - Instance Segmentation
이미지의 픽셀 간의 관계성을 통해 개체(Instance)를 비선형적 영역으로 분류 합니다
일반적인 CNN 모델(VGG, AlexNe 등)만 사용해서 Object Detection은 이미지의 패턴을 추출은 했지만 개체들을 위치를 찾는 과정이 없어서 어렵습니다.
8-2) Object Detection 모델의 발전 과정
<연도 별 발전 과정>
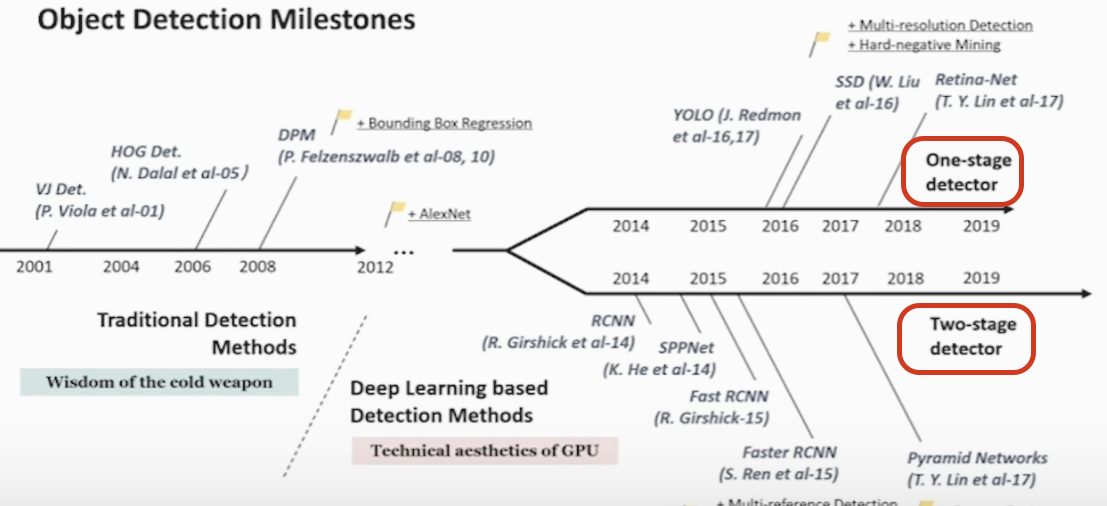
위 사진에서 빨간 네모 안에 One-stage detector & Two-stage detector 에 대해 설명 하겠습니다
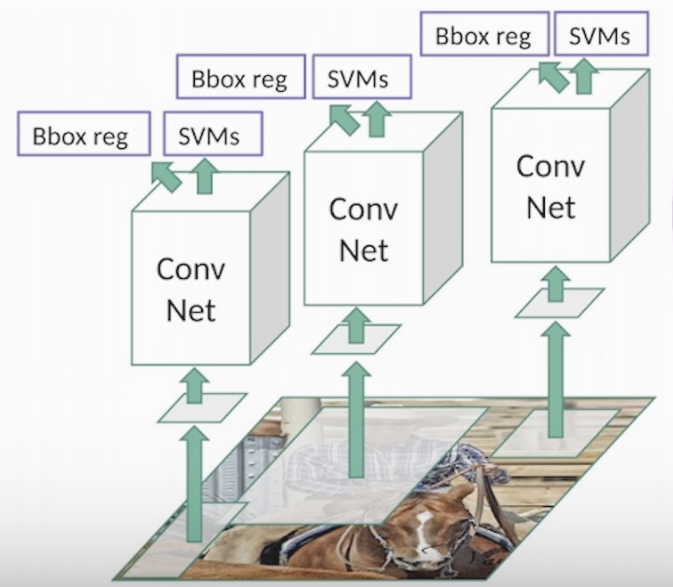
- Two-stage detector(R-CNN 계열, faster R-CNN, fast R-CNN)
<Two-stage Faster R-CNN 사진>
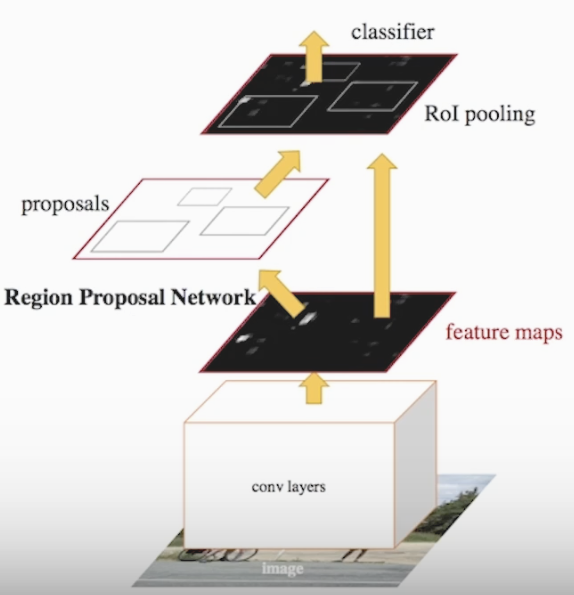
- Stage : Region proposal 이라는 개체가 있을 것 같은 영역을 뽑아주는 과정
- Stage : Classification을 하고 BB로 위치를 찾는 과정
Roi를 통해 있을 법한 개체의 패턴을 추출하고 분류,위치 지정함으로 정확도는 높지만 속도가 느린 단점이 있습니다
- One-stage detector(model YOLO 계열)
<One-stage YOLO 모델 사진>
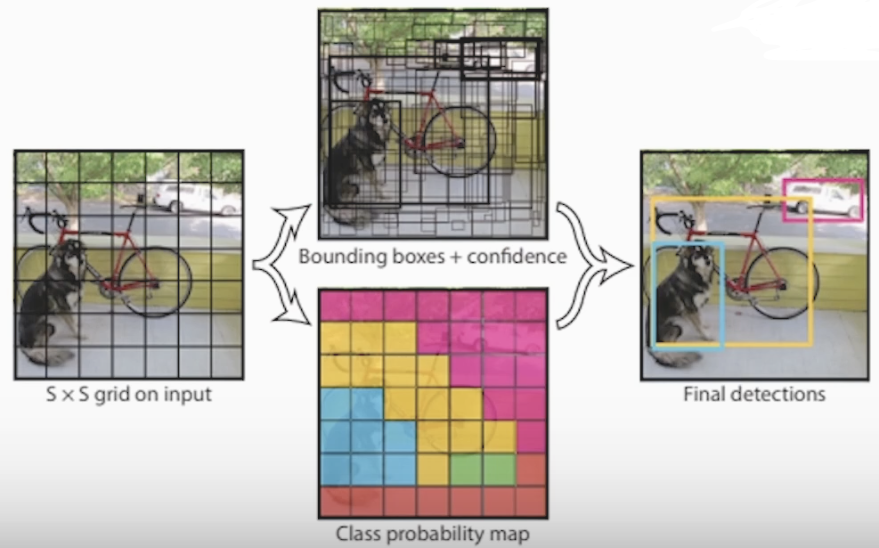
- Stage : 위 2가지 스테이지를 한번에 수행합니다
이미지 전체에서 특정 픽셀의 특징을 추출하여 바로 분류 합니다
속도는 빠른 장점을 갖고 있지만 정확도가 떨어집니다
8-3) R-CNN 모델을 통해 Object Detection 이해하기
<R-CNN의 전체 구조>
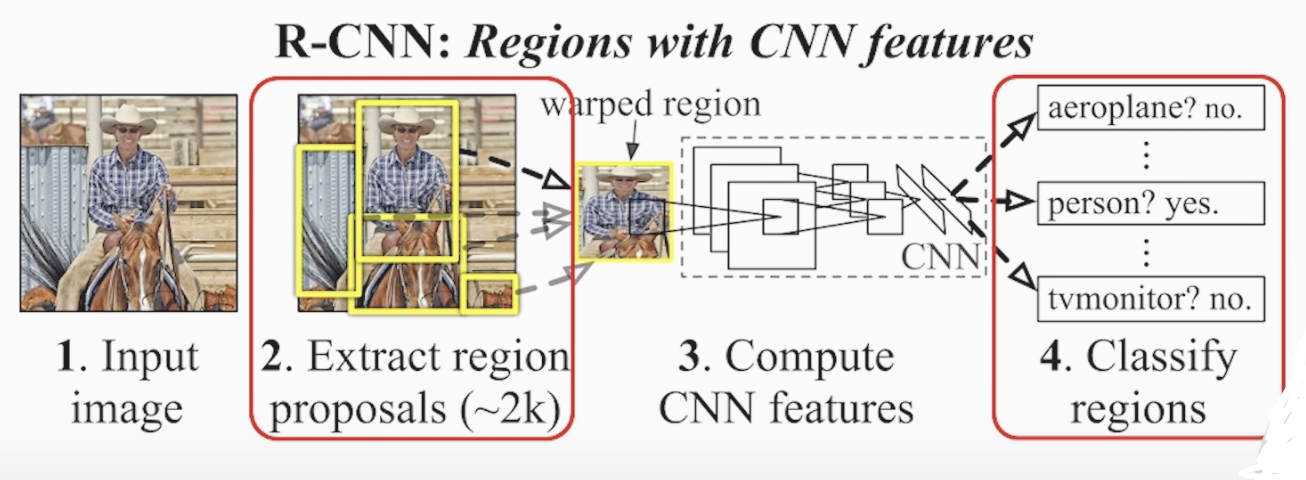
<R-CNN의 전체 구조2>
- R-CNN 모델의 동작 순서
- 후보가 될 수 있는 Roi 뽑기 (region proposal 동일 사이즈(227x227) Roi 2000개 추출)
Selective Search를 통해 Roi 추출 - Warped rigion 모양을 변경
- CNN Feature extraction > Classification > 4096차원의 벡터 변경
- pre-trained SVM Classification
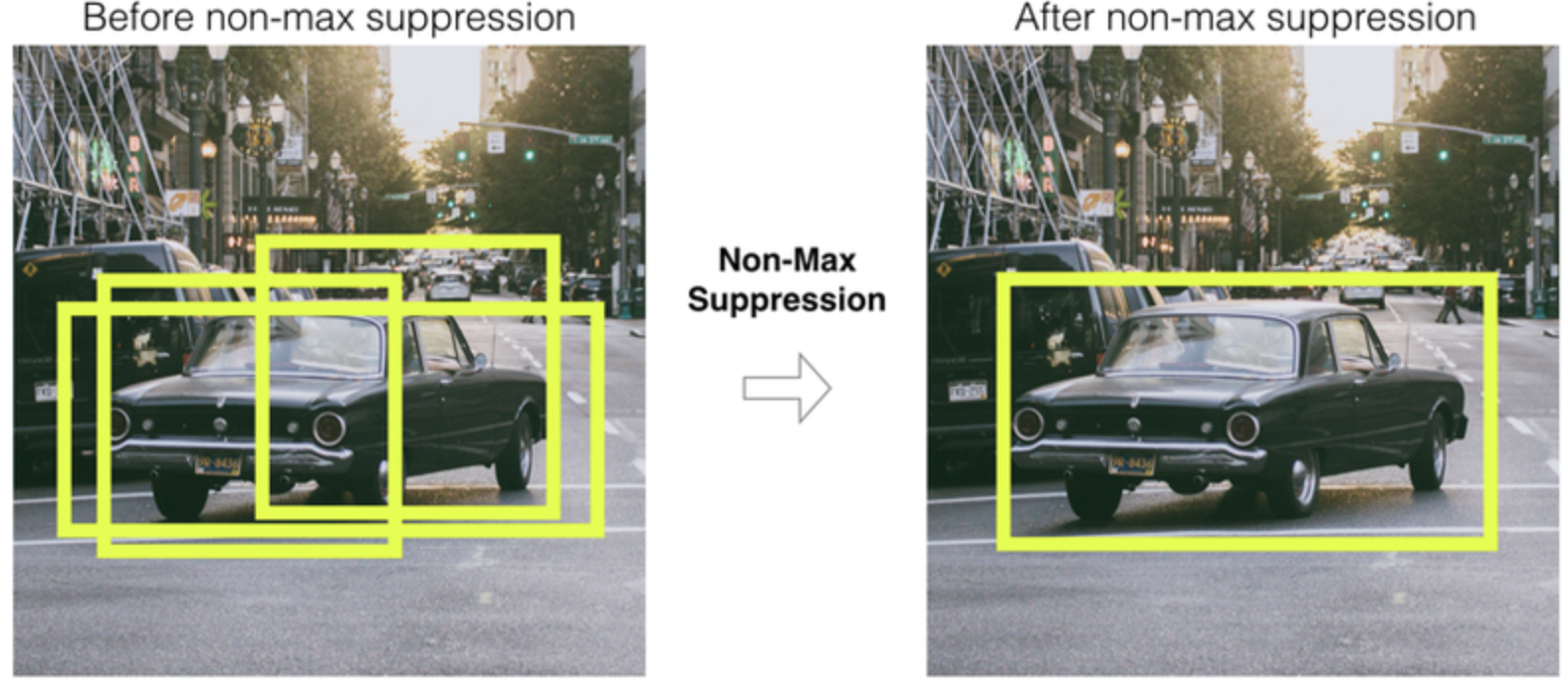
- 2000개 proposed region 중 'IOU'를 이용해 non-maximum suppression 적용
- BB의 위치를 정확하게 맞추기 위해 BB regression 수행
- Selective Search
- 색,무늬 크기, 형태를 바탕으로 주변 픽셀 값들로 유사도 계산
- 유사도를 바탕으로 Segmentation 진행 후 작은 Segment들을 묶어가며 세말하게 진행 (Over-segmentation)
- 유사도가 비슷한 Segment들을 반복적으로 계속 묶어갑니다
<Selective Search 사진>

8-4) R-CNN Classification 과정
SVM Classification 이후 BB로 위치를 정해 줍니다. 이 때 2가지 과정을 수행합니다
-
2000개의 Roi 중 상당수 필요없는 부분을 IoU를 통해 NMS(non-maximum suppression)를 활용해서 탈락 시킵니다
-
BB의 위치를 정확하게 맞추기 위해 bounding box regression을 실시 합니다
* IoU (Intersection over Union)
IoU는 모델이 예측한 bounding box와 실제 정답인 ground truth box가 얼마나 겹치는 지를 측정하는 지표입니다. 만약 100%로 겹치게 되면 IoU 값은 1이 됩니다
<IoU 사진>
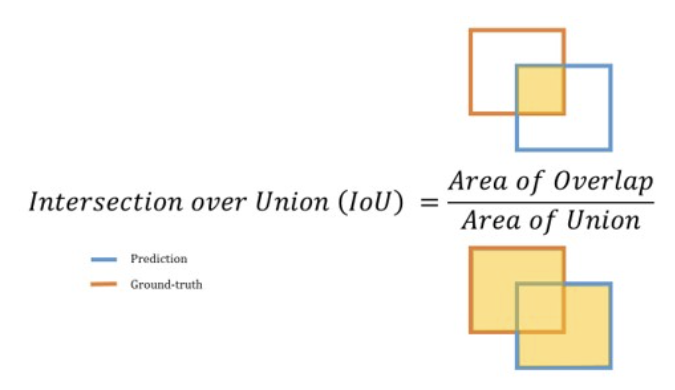
- Area of Union : 예측 BB와 True BB를 모두 포함하는 영역
- Area of Overlap : 예측 BB와 Ture BB가 겹치는 영역
* NMS (Non Maximum/maximal Suppression)
NMS은 수많은 bounding box 중 가장 적합한 box를 선택하는 기법입니다.
NMS의 과정
-
모든 bounding box에 대하여 threshold(한계점) 이하의 confidence score를 가지는 bounding box는 제거합니다
-
남은 bounding box들을 confidence score 기준으로 내림차순 정렬합니다.
-
정렬 후 가장 confidence score가 높은 bounding box를 기준으로 다른 bounding box와 IoU를 구합니다
-
IoU가 특정 기준 값보다 높으면, confidence score가 낮은 bounding box를 제거합니다
해당 과정을 순차적으로 반복합니다
<NMS 적용 사진>
* mAP (mean Average Precision)
<mAP 그래프>
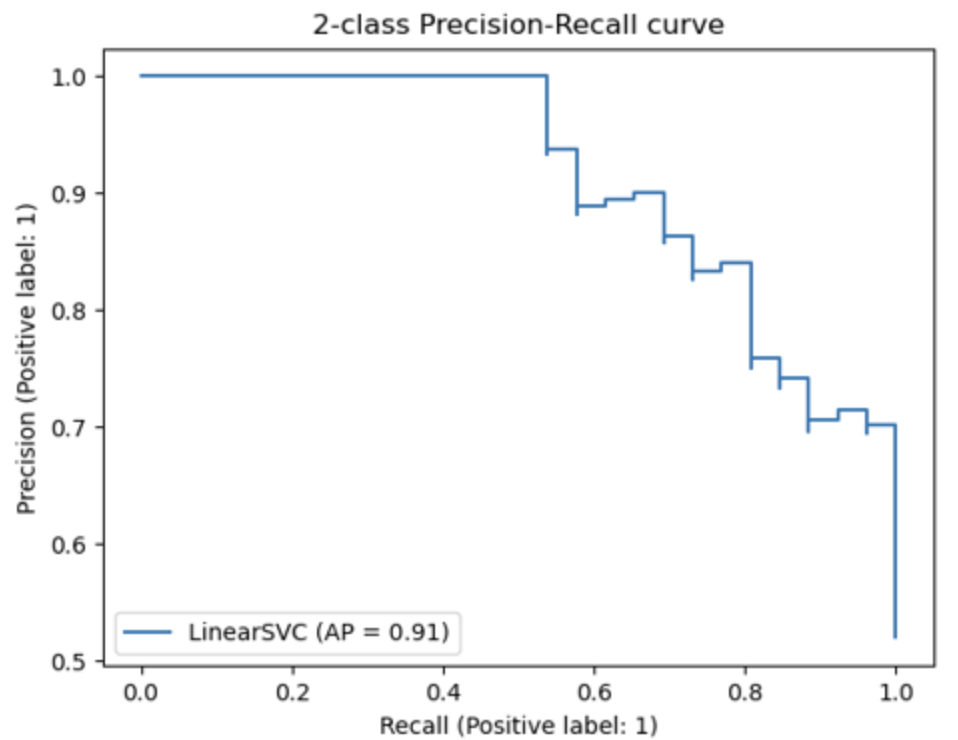
Precision-Recall Curve: confidence threshold 의 변화에 따른 정밀도와 재현율의 변화 곡선입니다.
- AP: Precision-Recall Curve의 아래 부분 면적을 의미합니다.
- mAP: AP는 하나의 object에 대한 성능 수치이며, mAP는 여러 object들의 AP를 평균한 값을 의미합니다. 따라서 Object Detection 모델의 성능 평가에 사용합니다
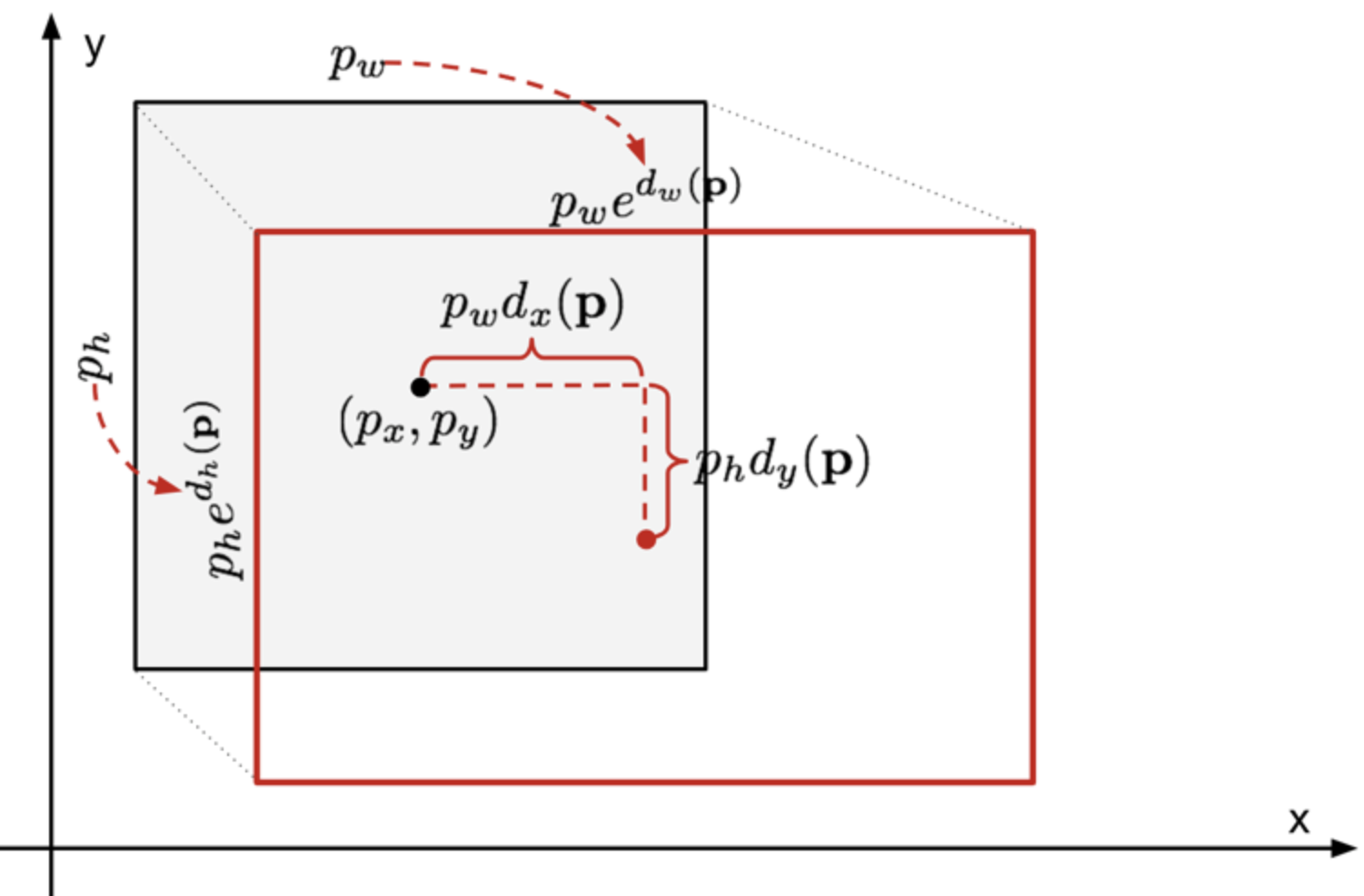
* Bounding Box Regression
BB의 위치를 정확하게 맞추기 위해서 하는 방법
BBR의 목표는 예측박스(Px,Py,Pw,Ph)를 True box(Gx,Gy,Gw,Gh)에 가깞게 만드는 것
<Bounding Box Regression 사진>
9. Segmentation
9-1) Semantic Segmentation vs Instance Segmentation
Segmentation : 이미지를 픽셀 단위로 나눠서 특정 픽셀이 무엇인지 파악하는 것
<Semantic vs Instance 사진>
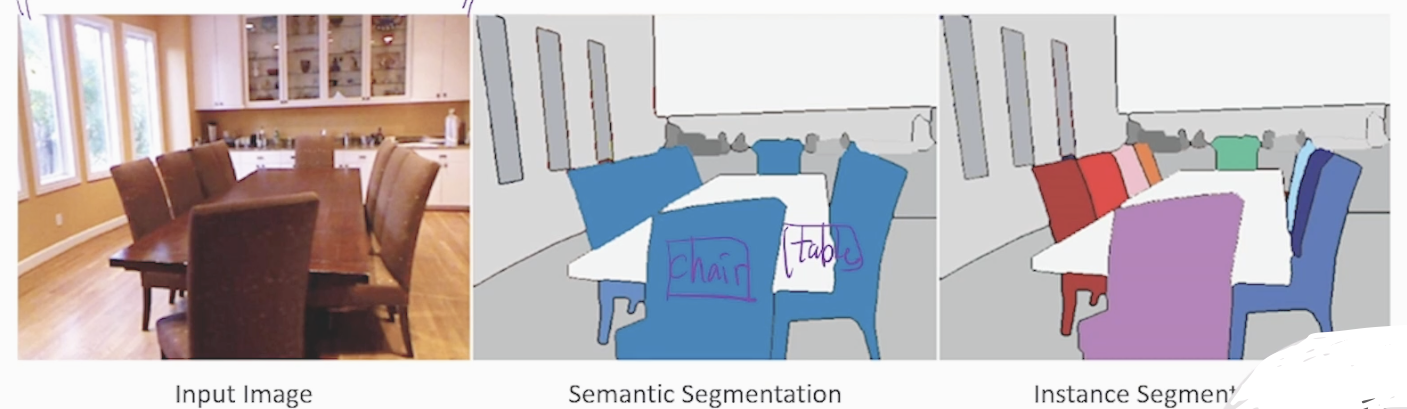
-
Semantic Segmentation : 하나의 객체를 분류하는 task (위 그림에서 의자, 테이블 등)
-
Instance Segmentation : 객체 안의 개체들을 분류하는 task (예시: 위 그림에서 각 의자들을 instance)
<Semantic Segmentation의 목적>
Label(Class) 값들을 픽셀 단위로 구분 하는 것이 목표 입니다. Segmentation map을 Output으로 출력하는 것
9-2) U-Net 구조를 통해 Segmentation 이해하기
Semantic Segmentation을 통해 U-Net 구조를 이해해보자
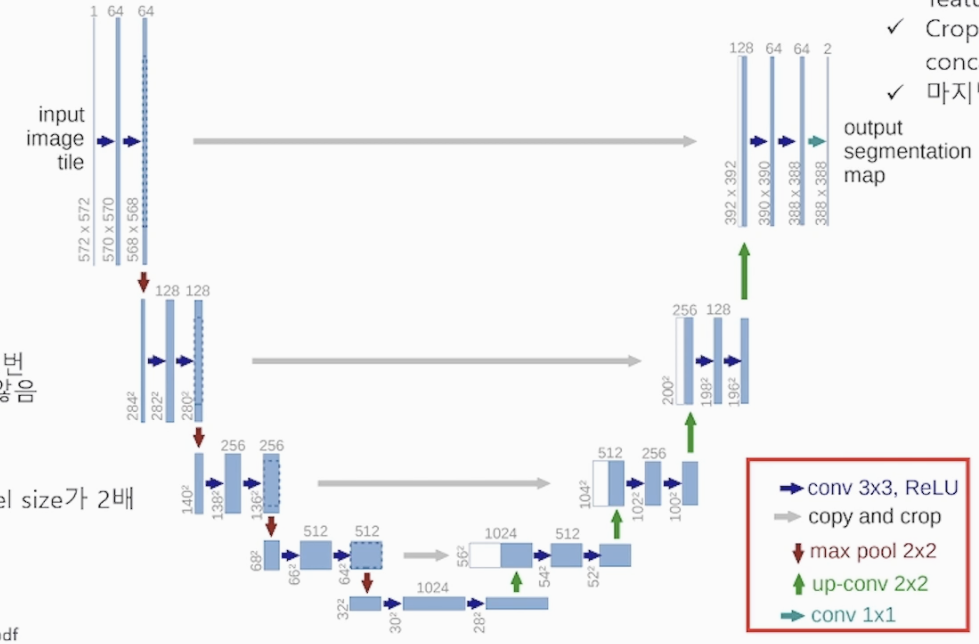
- U-Net 모델의 구조
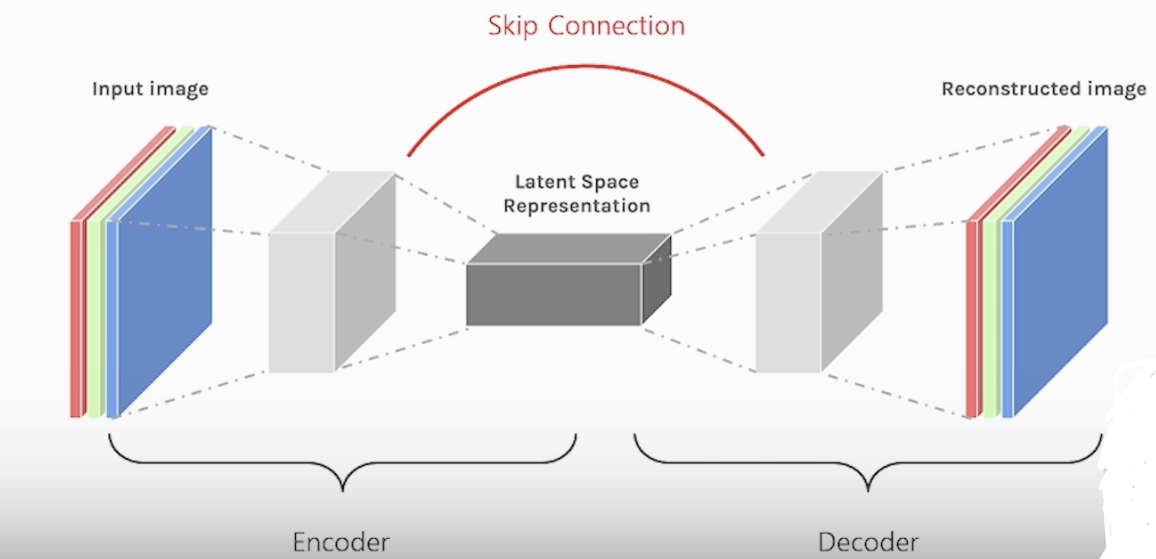
U-Net 모델은 Encoder-Decoder 모델에 skip connection을 추가한 모델
Encoder 안에 Contracting path : 이미지를 Conv, Pooling 계층을 지나면서 feature extraction을 수행하고 이미지를 압축 합니다(패턴이 소실)
채널을 늘리고 사이즈를 줄여가면서 압축하는 과정 입니다. (Down-sampliing)
Decoder 안에 Expanding path : Contraction path 에서 압축된 feature map을 Segmentation을 하기 위해 high resolution 하는 과정 입니다
U-Net은 input image와 output image의 크기가 다릅니다 (논문 확인 예정)
croped feature map을 skip connection을 통해 더 해주면서 소실된 패턴을 보충 합니다
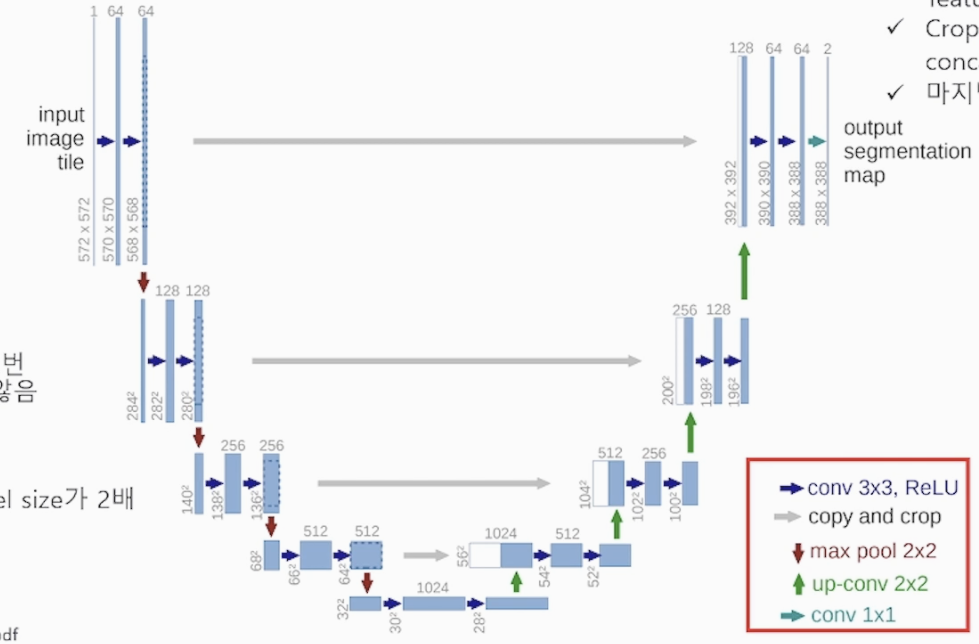
* Contraction path (Encoder)
2x2 Pooling을 사용합니다
3x3 Conv를 2번 연산 합니다
(Encoder, Down-sampling, Down-Convolution) 다양한 패턴을 추출할 수 있습니다
* Expanding path (Decoder)
Transposed + Cropping => Concatenation 을 통해 정보 소실을 방지하고 사이즈를 키워갑니다
(Decoder, Up-sampling, Up-Convolution)
Decoder 과정에서 Transposed Conv를 통해 압축된 feature map의 채널수를 줄이면서 사이즈를 키워 high resolution을 합니다 (Up-sampling, Up-Convolution)
<U-Net 모델의 대략적 구조>
<U-Net 모델의 연산 구조>
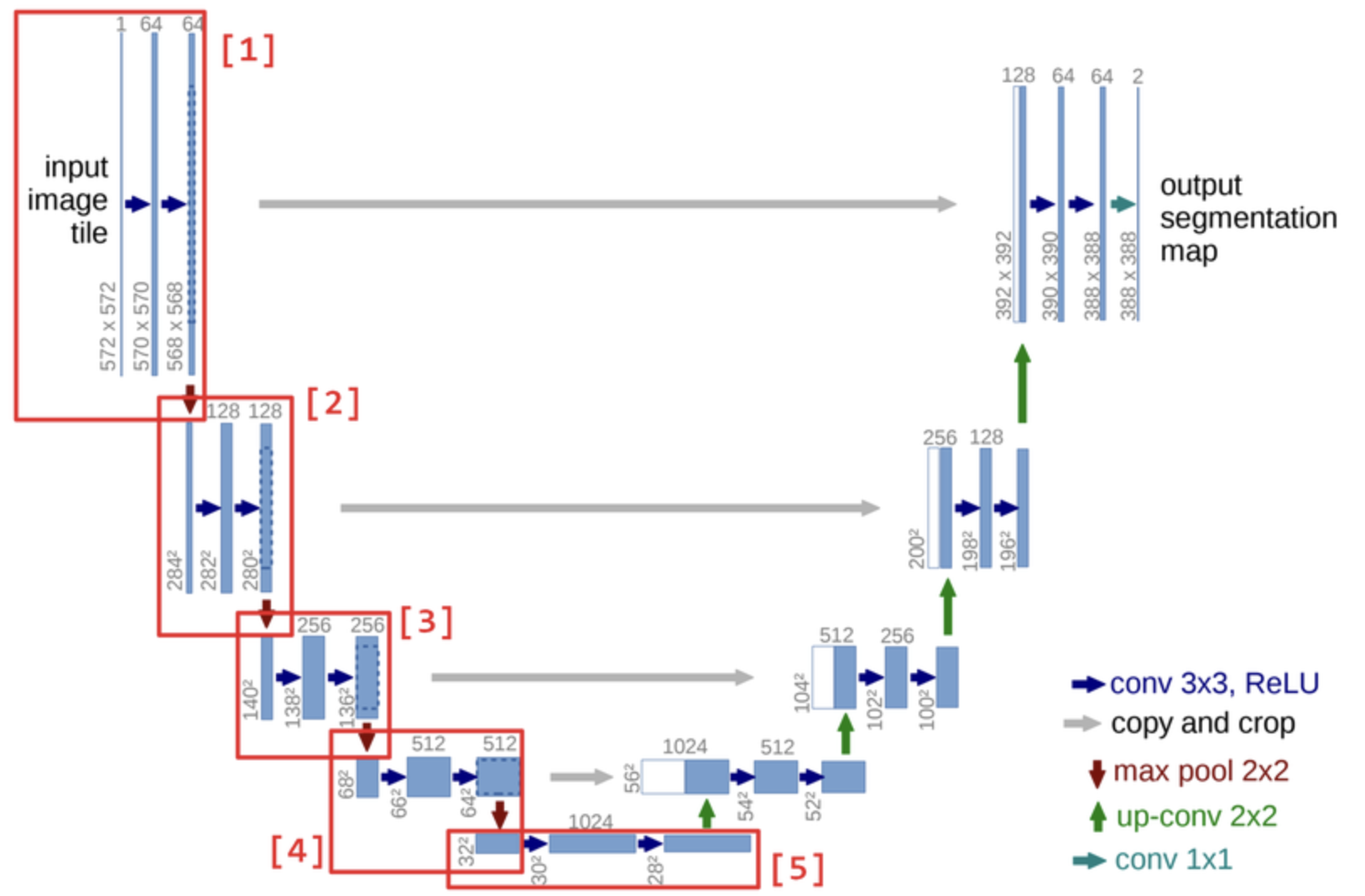
9-3) U-Net 코드를 통해 이해하기
<코드 구조 이미지>
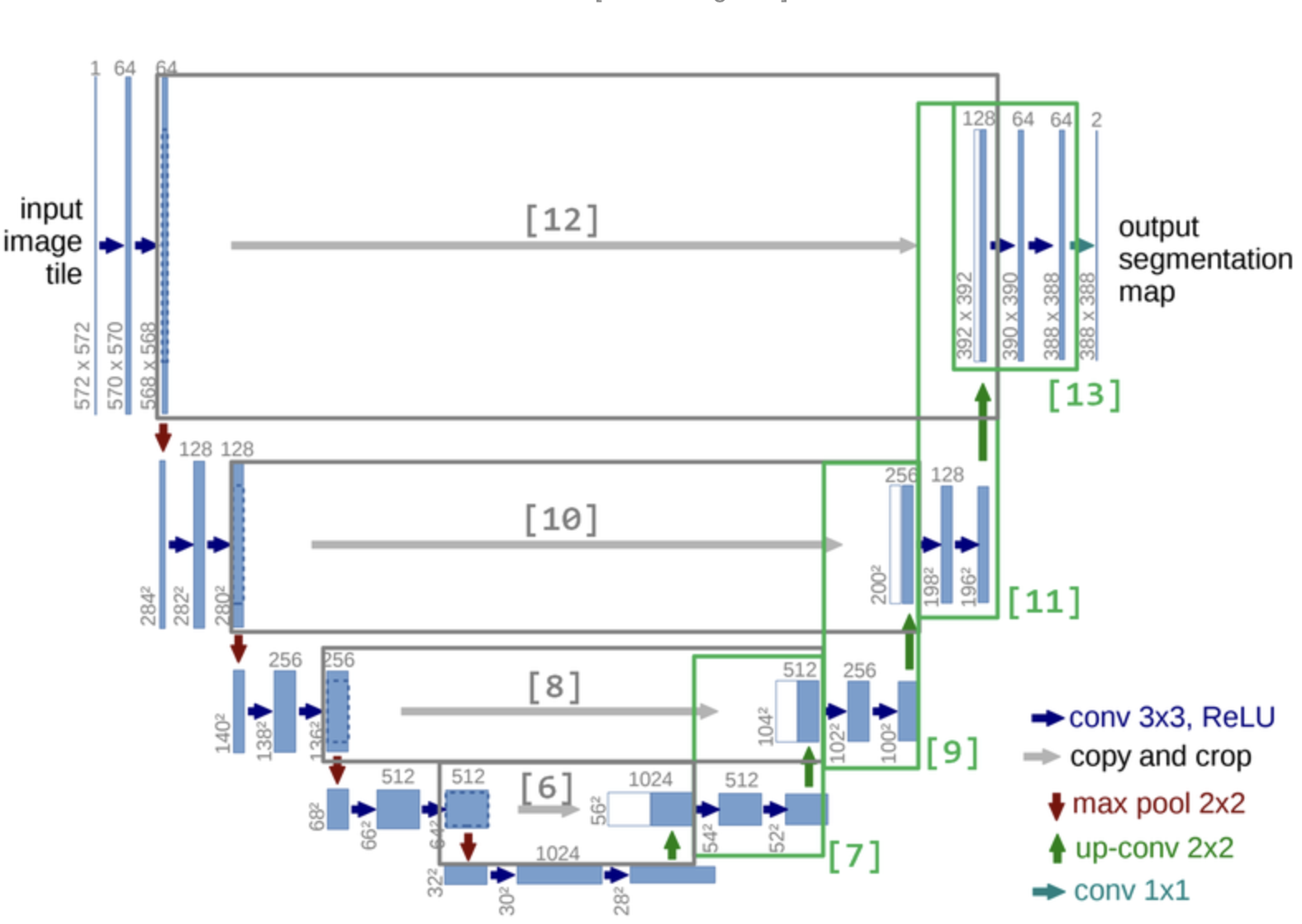
!pip install graphviz
!pip install pydot
import tensorflow.keras.layers as layers
import tensorflow as tf
# U-Net 레이어 구조 설정 (Functional API)
inputs = layers.Input(shape=(572, 572, 1))
# Contracting path 시작
# [1]
conv0 = layers.Conv2D(64, activation='relu', kernel_size = 3)(inputs)
conv1 = layers.Conv2D(64, activation='relu', kernel_size=3)(conv0) # Skip connection으로 Expanding path로 이어질 예정
conv2 = layers.MaxPool2D(pool_size=(2, 2), strides=(2, 2))(conv1)
# Q.위 이미지를 보고 [2]번 블럭을 구현해 봅시다. (filter 수를 주의하세요!)
conv3 = layers.Conv2D(128, activation='relu', kernel_size=3)(conv2)
conv4 = layers.Conv2D(128, activation='relu', kernel_size=3)(conv3)
conv5 = layers.MaxPool2D(pool_size=(2,2), strides=(2,2))(conv4)
# Q.위 이미지를 보고 [3]번 블럭을 구현해 봅시다. (filter 수를 주의하세요!)
conv6 = layers.Conv2D(256, activation='relu', kernel_size=3)(conv5)
conv7 = layers.Conv2D(256, activation='relu', kernel_size=3)(conv6)
conv8 = layers.MaxPool2D(pool_size=(2,2), strides=(2,2))(conv7)
# Q.위 이미지를 보고 [4]번 블럭을 구현해 봅시다. (filter 수를 주의하세요!)
conv9 = layers.Conv2D(512, activation='relu', kernel_size=3)(conv8)
conv10 = layers.Conv2D(512, activation='relu', kernel_size=3)(conv9)
conv11 = layers.MaxPool2D(pool_size=(2,2), strides=(2,2))(conv10)
# [5]
conv12 = layers.Conv2D(1024, activation='relu', kernel_size=3)(conv11)
conv13 = layers.Conv2D(1024, activation='relu', kernel_size=3)(conv12)
# Contracting path 끝
# Expanding path 시작
# [6]
trans01 = layers.Conv2DTranspose(512, kernel_size=2, strides=(2, 2), activation='relu')(conv13)
crop01 = layers.Cropping2D(cropping=(4, 4))(conv10)
concat01 = layers.concatenate([trans01, crop01], axis=-1)
# [7]
conv14 = layers.Conv2D(512, activation='relu', kernel_size=3)(concat01)
conv15 = layers.Conv2D(512, activation='relu', kernel_size=3)(conv14)
trans02 = layers.Conv2DTranspose(256, kernel_size=2, strides=(2, 2), activation='relu')(conv15)
# [8]
crop02 = layers.Cropping2D(cropping=(16, 16))(conv7)
concat02 = layers.concatenate([trans02, crop02], axis=-1) # axis 채널 순서 맞추기
# Q.위 이미지를 보고 [9]번 블럭을 구현해 봅시다. (filter 수를 주의하세요!)
conv16 = layers.Conv2D(256, activation='relu', kernel_size=3)(concat02)
conv17 = layers.Conv2D(256, activation='relu', kernel_size=3)(conv16)
trans03 = layers.Conv2DTranspose(128, kernel_size=2, strides=(2, 2), activation='relu')(conv17)
# Q.위 이미지를 보고 [10]번 블럭을 구현해 봅시다. (cropping=(40, 40))
crop03 = layers.Cropping2D(cropping=(40,40))(conv4)
concat03 = layers.concatenate([trans03, crop03],axis=-1)
# Q.위 이미지를 보고 [11]번 블럭을 구현해 봅시다. (filter 수를 주의하세요!)
conv18 = layers.Conv2D(128, activation='relu', kernel_size=3)(concat03)
conv19 = layers.Conv2D(128, activation='relu', kernel_size=3)(conv18)
trans04 = layers.Conv2DTranspose(64, kernel_size=2, strides=(2, 2), activation='relu')(conv19)
# Q.위 이미지를 보고 [12]번 블럭을 구현해 봅시다. (cropping=(88, 88))
crop04 = layers.Cropping2D(cropping=(88,88))(conv1)
concat04 = layers.concatenate([trans04, crop04],axis=-1)
# [13]
conv20 = layers.Conv2D(64, activation='relu', kernel_size=3)(concat04)
conv21 = layers.Conv2D(64, activation='relu', kernel_size=3)(conv20)
# Expanding path 끝
outputs = layers.Conv2D(2, kernel_size=1)(conv21)
model = tf.keras.Model(inputs=inputs, outputs=outputs, name="u-netmodel")