
1편에 이어서, post방식의 비동기 크롤링을 끝장내보자.
JSON 파싱

위의 사진은 개발자도구에서 Response 탭을 캡쳐한 것이고, 이전 글에서 보았듯이 실제로 저렇게 들어온다. 당연한 얘기지만 인덴트도 안되어 있어서 알아보기 힘드니, 야무지게 파싱해보자
for route in routes:
for days in range(30, 40):
departureDate = (startTime + timedelta(days=days)).strftime("%Y%m%d")
response_json = getResponseJson(route[0], route[1], departureDate)
results = response_json["data"]["internationalList"]["results"]
schedules = results["schedules"][0] # dict obj
fares = results["fares"]
print("항공편 개수:", len(schedules))
if len(schedules) != len(fares):
print("항공편 개수와 fare개수가 다릅니다!")
for key, values in schedules.items():
fareSum = 0
for val in (fares.get(key))["fare"]["A01"][0]["Adult"].values():
fareSum += int(val)
crawled_data[key] = {
"id": key,
"departureAirport": route[0],
"arrivalAirport": route[1],
"departureDate": departureDate,
"airline": values["detail"][0]["av"], # 항공
"departureTime": values["detail"][0]["sdt"][-4:], # 출발 시각
"arrivalTime": values["detail"][0]["edt"][-4:], # 도착 시각
"fare": fareSum,
}
# print(json.dumps(crawled_data, indent=4))
print(len(crawled_data))이런 식으로 json에서 내가 필요한 정보만 골라서 새로운 json형태를 만들었다. 그리고 getResponseJson함수는 post요청의 response를 받는 함수로 분리하였다.
crawled_data로 이쁘게 모아놓은 데이터는 이렇게 생겼다!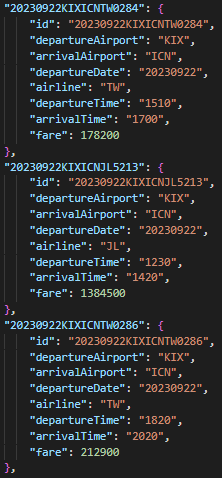
글은 쉽게 썼지만, json이 object안에 array안에 object안에... 이런식으로 되어 있어서 많이 헷갈렸다.
이제 가장 큰 문제점이었던 크롤링 시간을 줄이기 위해 멀티스레딩을 적용해보자.
멀티스레딩
현재 내 코드는 대충 아래랑 비슷한 형식이다.
def getResponseJson(departureAirport, arrivalAirport, departureDate):
first_payload = {}
first_response = requests.post(url, json=first_payload, headers=headers)
first_response_json = first_response.json()
time.sleep(5) # 핵심!
second_payload = {}
second_response = requests.post(url, json=second_payload, headers=headers)
second_response_json = second_response.json()
return second_response_json첫 번째 요청 후 서버에서 각종 항공사, 여행사로 데이터를 요청해야 하는 시간을 벌어주기 위해 약간의 시간이 필요하다고 생각했다. 그리고 실제로 여러가지를 더 분석해봤는데, 내 생각이 맞는 것 같았다. 충분한 시간이 지난 후 두 번째 post 요청을 하면 모든 데이터를 누락없이 받을 수 있다.
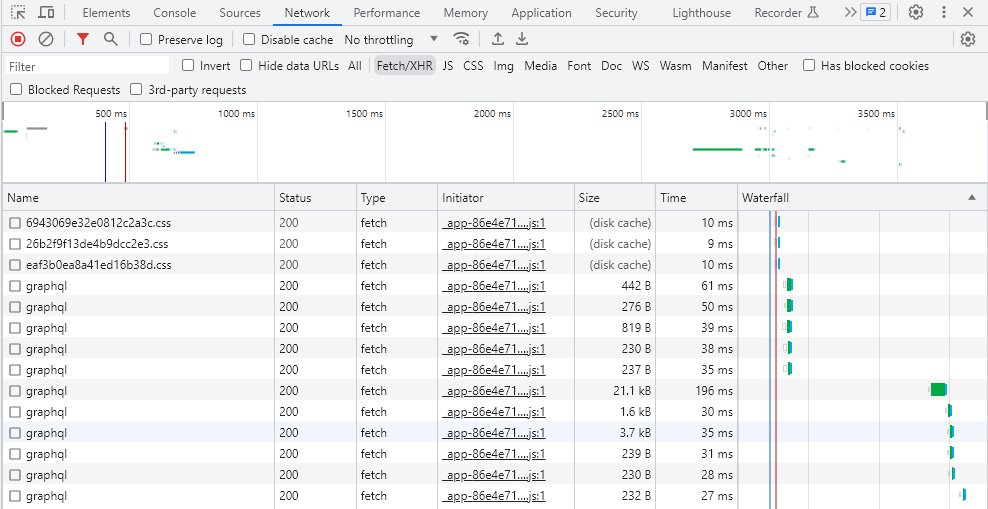
첫 번째와 두 번째 요청 이후에도 지속적으로 항공권 데이터를 요청하는 graphql이 길게는 10초까지 이어진다. 그리고 해당 request와 response를 분석해보니 이전의 요청에서 완료되지않은 데이터들이 계속 들어오고 있었다.
다행히, 10초이상의 시간이 지난 후 두번째 요청을 보내면 해당 시간동안의 누적된 데이터가 한번에 들어오는 것을 확인할 수 있었다!
멀티스레딩을 적용한 코드는 다음과 같다.
def fetch_data(route, days):
departureDate = (startTime + timedelta(days=days)).strftime("%Y%m%d")
response_json = getResponseJson(route[0], route[1], departureDate)
return response_json
crawled_data = {}
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
futures = []
for route in routes:
for days in range(30, 40):
futures.append(executor.submit(fetch_data, route, days))
for future in concurrent.futures.as_completed(futures):
response_json = future.result()
results = response_json["data"]["internationalList"]["results"]
schedules = results["schedules"][0] # dict obj
fares = results["fares"]
print("항공편 개수:", len(schedules))
if len(schedules) != len(fares):
print("항공편 개수와 fare개수가 다릅니다!")
for key, values in schedules.items():
fareSum = 0
for val in (fares.get(key))["fare"]["A01"][0]["Adult"].values():
fareSum += int(val)
crawled_data[key] = {
"id": key,
"departureAirport": route[0],
"arrivalAirport": route[1],
"departureDate": values["detail"][0]["sdt"][:8], # 출발 날짜
"airline": values["detail"][0]["av"], # 항공
"departureTime": values["detail"][0]["sdt"][-4:], # 출발 시각
"arrivalTime": values["detail"][0]["edt"][-4:], # 도착 시각
"fare": fareSum,
}
# print(json.dumps(crawled_data, indent=4))
print(len(crawled_data))
print("All threads have finished")max-workers가 프로세스의 최대 스레드 갯수이다. 현재 10개로 설정하고, 4개노선*10일 = 40개의 요청을 멀티스레딩을 적용한 코드와 적용하지 않은 코드 두 가지로 성능 비교를 해 보겠다.
멀티스레딩 동작 확인
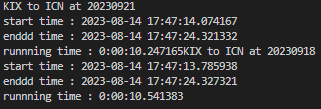
위의 사진을 보면, 잘 알아보기 힘들겠지만, 각 스레드(1개의 post 요청)의 시작과 끝 시각을 체크했다.
KIX to ICN at 20230921 요청이 14.07초에 이루어졌고, 24.321초에 끝났다.
KIX to ICN at 20230918 요청이 13.78초에 이루어졌고, 24.327초에 끝났다.
각 스레드마다 10초동안 공백이 존재했고, 해당 멈춤 시간동안 다른 스레드를 실행했다는 뜻이다.
실행시간 비교
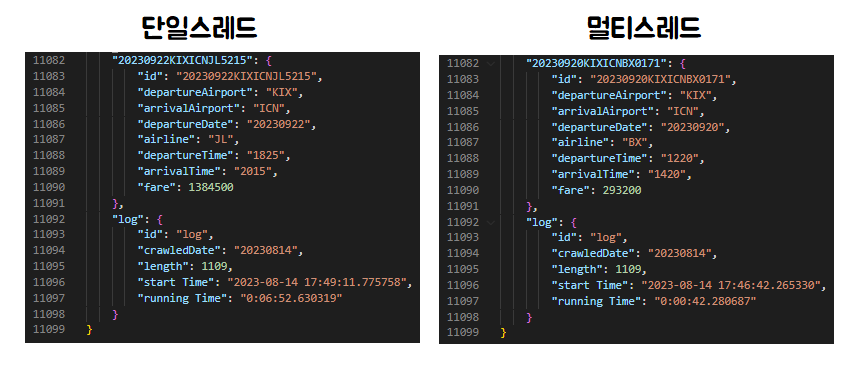
단일스레드 방식으로 실행한 왼쪽의 결과는 6분52초(40*10초)가 걸렸고
멀티스레드 방식으로 실행한 오른쪽 결과는 42초(40/10*10초)가 걸렸다!
겨우 10개의 스레드만을 사용했는데 매우 성공적인 결과가 나왔다. 그리고 open-api가 아닌 api의 작동 방식을 유추하여 사용한 것이 들어맞아서 참 다행이다.
이제 크롤링 시간 문제를 해결했으니, 수집 데이터를 어떻게 다룰 지 고민을 해야 한다.

좋은 글 감사합니다.
혹시 routes 변수는 어디서 어떻게 생성하는지 알려주실 수 있나요?!