1. 개요
1) 대규모 분산 학습의 새로운 시대
- 오늘날 모든 신경망(Neural Networks)은 대규모 분산 방식으로 훈련되며, 대규모(Large Scale)는 딥러닝의 새로운 표준이 되었습니다.
- 10년 전만 해도 모델을 단일 GPU, 즉 하나의 디바이스에서 훈련하는 것이 일반적이었으나, 이제는 수십, 수백, 수천, 심지어 수만 개의 디바이스를 동시에 사용하여 훈련합니다.
- 따라서 이러한 대규모 훈련을 수행하기 위한 새로운 알고리즘과 사고방식이 필요합니다.
실행 예시: Llama 3 405B
- 이번 강의 전체를 관통하는 예시로 Llama 3 405B 모델의 훈련 방식을 집중적으로 다룰 것입니다.
- Llama 3가 현재 최고의 모델이라서가 아니라, 훈련 방식, 모델 아키텍처 등 구현 세부 정보(implementation details)를 많이 공개했기 때문에 주목할 만합니다.
- GPT-4 (2023년) 논문에서 경쟁 환경과 대규모 모델의 안전성 문제 때문에 아키텍처, 모델 크기, 하드웨어, 훈련 계산량, 데이터셋 구성 등 더 이상의 세부 정보를 포함하지 않는다고 명시한 이후, 대부분의 최첨단 모델은 세부 정보를 일체 공개하지 않는 추세입니다.
- 반면 Meta가 2024년 4월에 오픈 소스로 공개한 Llama 3는 훈련 시스템 인프라에 대한 많은 세부 정보를 공유하여, 대규모 거대 언어 모델(LLMs)이 실제로 어떻게 훈련되는지 엿볼 수 있게 해줍니다. (참고: 2025년 4월에 Llama 4 모델이 출시되었으나 아직 논문은 공개되지 않았습니다).

2. GPU 하드웨어와 클러스터 아키텍처

1) GPU의 기술적 배경
- GPU (Graphics Processing Unit)는 원래 컴퓨터 그래픽을 위해 개발된 특수 코프로세서(Co-processors)입니다.
- 그래픽 작업은 많은 픽셀을 생성하고 기하학적 요소를 병렬로 처리해야 하므로, GPU는 병렬 컴퓨팅에 매우 적합하다는 것이 밝혀졌습니다.
- 2000년대 초반 연구자들은 그래픽 카드를 일반 병렬 프로그래밍에 활용하는 방법을 찾았고, 2010년대에 들어 Nvidia는 이를 범용 병렬 프로세서로 개발하고 딥러닝 분야에 집중적으로 투자하여 오늘날 딥러닝 훈련의 주류가 되었습니다.
2) Nvidia H100 아키텍처 상세 분석
- 현재 딥러닝 훈련의 주류는 Nvidia H100입니다.
- H100 내부 구조:
- 중앙에 컴퓨트 코어(Compute Cores)가 위치합니다.
- 주변에 80GB의 HBM 메모리(High Bandwidth Memory)가 분리되어 있으며, 코어와 3TB/초의 속도로 데이터를 주고받습니다.

(1) 메모리 계층 구조 (Memory Hierarchy)
- GPU 내부에는 여러 계층의 메모리가 존재하며, 컴퓨트 코어에 가까울수록 용량은 작지만 속도는 훨씬 빠릅니다.
- 고성능 GPU 커널을 작성하려면 이 메모리 계층 간의 데이터 이동을 최적화하는 것이 매우 중요합니다.
- H100의 세 가지 주요 메모리 계층:
- HBM 메모리: 80GB (가장 느림, 가장 큼).
- L2 캐시: 약 50MB (HBM보다 빠르고 코어에 가까움).
- L1 캐시 및 레지스터 파일: 256KB (SM 내부, 가장 빠름).

(2) 스트리밍 멀티프로세서 (SM)와 코어

- H100의 핵심은 132개의 스트리밍 멀티프로세서(Streaming Multiprocessors, SM)입니다. 이는 독립적인 병렬 코어와 유사합니다.
- Binning (비닝): 제조 과정에서 완벽한 칩을 만들기 어렵기 때문에, 이론상 144개의 코어를 목표로 하더라도 실제로 작동하는 코어 수가 132개 이상인 칩을 상품화하는 프로세스입니다.
- FP32 코어:
- 각 SM 내부에 128개의 FP32 코어가 있습니다.
- 이 코어는 스칼라 연산을 클럭 사이클당 한 번 수행할 수 있습니다.
- 전체 SM은 클럭 사이클당 256회의 부동 소수점 연산(128 곱셈 + 128 덧셈)을 수행할 수 있습니다.
- Tensor Cores (텐서 코어):
- GPU 성능의 핵심이 되는 요소입니다.
- 각 SM 내부에 4개의 텐서 코어가 있으며, 이들은 행렬 곱셈(Matrix Multiply)만 수행하도록 설계된 특수 회로입니다.
- H100의 텐서 코어는 형태의 작은 행렬 곱셈 덩어리()를 클럭 사이클당 한 번 수행할 수 있습니다.
- 이 작은 행렬 곱셈은 1,024회의 부동 소수점 연산에 해당하며, 4개의 텐서 코어를 통해 전체 SM은 클럭 사이클당 4,096회의 부동 소수점 연산을 수행할 수 있습니다.
- 이는 FP32 코어의 256회 연산과 비교할 때 압도적으로 높습니다. 따라서 GPU를 최대한 활용하려면 이 텐서 코어를 사용해야 합니다.
(3) 혼합 정밀도 (Mixed Precision)
- 텐서 코어는 혼합 정밀도(Mixed Precision)로 작동합니다.
- 입력은 일반적으로 16비트 정밀도(16-bit)로 처리되지만, 곱셈을 수행한 후 덧셈/누적(accumulations)은 더 높은 정밀도인 32비트(32-bit)로 수행됩니다.
- 중요한 실용적 주의 사항: PyTorch에서 모델을 16비트로 형 변환(cast)하지 않으면 텐서 코어가 아닌 느린 FP32 코어에서 실행되어 예상보다 20배 느려질 수 있습니다.
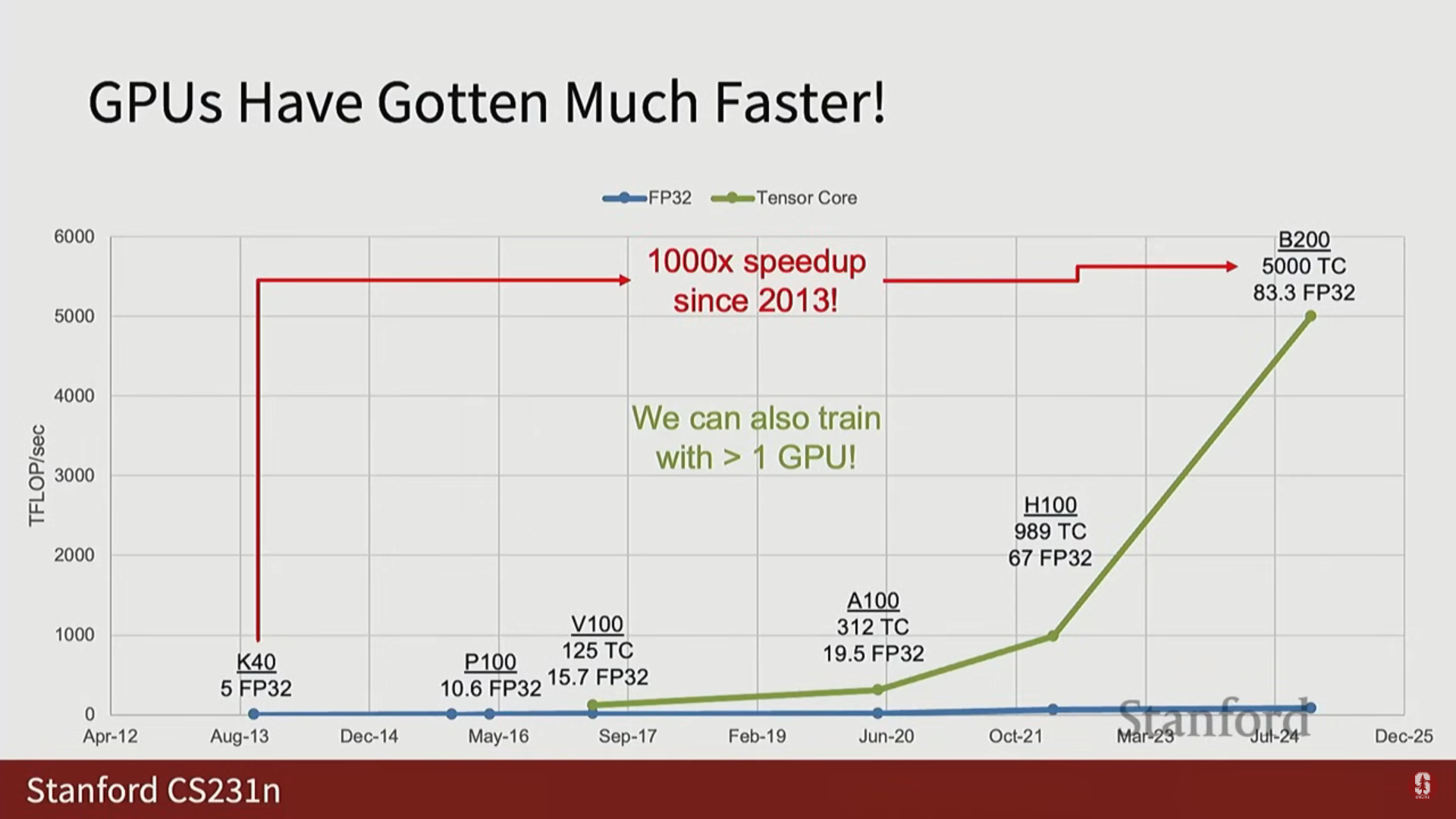
3) 컴퓨팅 처리량의 비약적 발전
- 2013년 K40 GPU는 5 TFLOPS의 FP32 컴퓨팅 능력을 가졌습니다.
- 2016~2017년에 출시된 V100은 텐서 코어를 처음 도입한 디바이스였으며, 이후 텐서 코어는 장치 영역의 더 많은 부분을 차지하게 되면서 처리량이 기하급수적으로 증가했습니다.
- 가장 최신 디바이스인 B200 (이론상)은 FP32 컴퓨팅에서 83.3 TFLOPS, 혼합 정밀도 텐서 코어 컴퓨팅에서 5,000 TFLOPS의 성능을 가집니다.
- 지난 12년간 개별 디바이스 수준에서 컴퓨팅 성능이 1,000배 향상되었으며, 이는 지난 10년간 딥러닝 분야의 발전(AI 성능 향상)을 이끈 주요 동인입니다.
4) GPU 클러스터 구성 및 규모
- 오늘날 모델은 하나의 GPU가 아닌 수천, 수만 개의 GPU를 사용하여 훈련됩니다.
- 클러스터 전체에서 메모리 계층 구조의 연속이 나타나며, 장치를 벗어날수록 통신 대역폭은 느려집니다:
- 단일 H100 내부 (HBM 코어): 3TB/초.
- 서버 내부 (GPU GPU, 8개 디바이스): 약 900GB/초 (3배 느림).
- GPU Pod 내부 (랙 간 GPU): 약 50GB/초 (20배 느림).
(1) Llama 3의 클러스터 예시 (Meta)
- Llama 3 기술 보고서는 클러스터 세부 정보를 공개했습니다.
- 서버 랙(Server Rack): 두 개의 서버가 스택되어 총 16개의 GPU로 구성됩니다 (약 6피트 높이).
- GPU Pod: 192개의 랙으로 구성되어 총 3,072개의 GPU를 포함합니다.
- 전체 GPU 클러스터: 8개의 GPU Pod를 결합하여 총 24,576개의 GPU로 구성되었습니다.
- 세상에는 5만 개, 10만 개 이상의 GPU를 가진 더 큰 클러스터도 존재합니다.
- 훈련 기간: 가장 긴 최첨단 모델 훈련은 보통 수개월 단위로 측정되며, GPT-4.5나 GPT-5 같은 초거대 모델은 1년 가까이 걸릴 수도 있습니다.
- 물리적 공간 및 운영:
- 클러스터는 일반적인 데이터 센터 표준인 서버 랙 단위로 조직됩니다.
- 랙은 사람들이 걸어 다닐 수 있도록 배치되며, 컴퓨팅 랙 외에도 네트워킹 하드웨어와 저장 하드웨어(Storage hardware)를 위한 전용 랙이 필요합니다.
- 이 클러스터(24,576 GPU)는 1.8 페타바이트의 HBM 메모리와 24 Exaflops (24 * 10^18 FLOPS)의 컴퓨팅 성능을 가집니다.
- 단일 게임용 GPU(예: 4090)도 방을 덥힐 수 있기 때문에, 수만 개의 GPU가 쌓인 데이터 센터는 심각한 냉각(Cooling) 요건을 가집니다.


(2) 경쟁 하드웨어
- Google TPU (Tensor Processing Units): Nvidia의 가장 큰 경쟁자입니다.
- V5P TPU는 H100과 유사한 스펙을 가집니다.
- TPU는 Pod 형태로 배열되며, V5P는 최대 8,960개의 칩으로 구성될 수 있습니다.
- Google의 Gemini 모델은 거의 확실하게 TPU로 훈련되었을 것으로 예상됩니다.
- TPU는 Google 클라우드를 통해서만 접근 가능합니다 (Nvidia와 달리 구매 불가).
- 기타 경쟁자: AMD MI325X (스펙은 H100과 비슷하지만 영향력은 낮음), AWS의 Trainium (Anthropic 등이 사용).


3. 대규모 분산 학습 알고리즘
- 대규모 GPU 클러스터를 활용하는 핵심 전략은 계산 분할(Split up your computation)과 통신과 계산의 오버랩(Overlap the communication with the computation)입니다.
- 컴퓨터는 계산(Computation)과 통신(Communication, 비트 이동) 두 가지를 수행하며, 모든 GPU가 병렬로 유용하게 작업할 수 있도록 분배하는 것이 중요합니다.
1) 트랜스포머 아키텍처의 네 가지 병렬화 축

- 트랜스포머는 개의 레이어 스택으로 구성되며, 각 레이어는 미니 배치(Mini-batch), 시퀀스(Sequence), 차원(Dim)의 3차원 텐서에 대해 작동합니다.
- 이를 기반으로 네 가지 축을 따라 병렬화합니다:
- Layer 축: 파이프라인 병렬화 (Pipeline Parallelism)
- Batch 축: 데이터 병렬화 (Data Parallelism)
- Sequence 축: 컨텍스트 병렬화 (Context Parallelism)
- Dim 축: 텐서 병렬화 (Tensor Parallelism)
2) 데이터 병렬화 (Data Parallelism, DP)
- 기본 아이디어: 훈련 시 미니 배치의 각 샘플에 대한 손실 및 기울기 계산이 독립적이라는 점을 이용합니다.
- 개의 GPU가 있을 때, 총 크기의 대규모 미니 배치를 각 GPU에 개씩 분할하여 처리합니다.

(1) 수학적 정당성
- 기울기의 선형성(Gradients are linear) 덕분에 분산 처리가 가능합니다.
- 전체 손실 이 개별 손실의 평균()일 때, 가중치 에 대한 기울기 은 다음과 같이 분리됩니다:
$$ \nablaW L = \frac{1}{M \cdot N} \sum{i} \nabla_W L_i $$ - 이는 단일 GPU에서 대규모 배치를 처리하는 것과 수학적으로 정확히 동일한(exactly the same) 계산이며, 근사치가 아닙니다.
(2) DP 훈련 과정 (M=3 예시)
- 가중치 복사: 각 GPU는 모델 가중치, 옵티마이저 상태, 기울기의 독립적인 복사본을 유지합니다.
- 데이터 로드: 각 GPU는 서로 다른 미니 배치 데이터를 병렬로 로드합니다.
- 순전파 및 역전파: 각 GPU는 자신의 데이터에 대해 독립적으로 순전파와 역전파를 수행하여 국소 기울기(Local Gradient)를 계산합니다.
- 통신 (All Reduce): 모든 GPU는 자신의 국소 기울기를 다른 모든 GPU에 전송하고 수집하여 평균을 계산하는 All Reduce 연산을 수행합니다.
- 이 연산 후에는 모든 GPU가 동일하고 평균화된 기울기(identical copy of the averaged gradients)를 갖게 됩니다.
- 가중치 업데이트: 각 GPU는 동일한 평균화된 기울기를 사용하여 자신의 로컬 가중치를 업데이트합니다.

- 성능 최적화: 4단계(역전파)와 5단계(통신)는 실제로는 동시에 발생합니다.
- GPU가 레이어 의 역전파를 계산하는 동안, 이미 계산된 레이어 의 기울기는 All Reduce 통신을 시작합니다.
- 통신 비용을 숨기기 위해 계산과 통신을 오버랩하는 것이 중요합니다. PyTorch의 Distributed Data Parallel (DDP) 클래스가 이러한 공통 작업을 소프트웨어적으로 투명하게 처리해 줍니다.
(3) DP의 병목 현상 (Bottleneck)
- DP의 명확한 한계점은 모델 크기입니다.
- 각 GPU는 매개변수당 약 4~5개의 스칼라(가중치, 기울기, 옵티마이저 상태 등)를 추적해야 합니다.
- 16비트 정밀도 기준으로 매개변수당 약 8바이트가 필요하며, 이는 10억 개의 매개변수당 약 8GB의 GPU 메모리가 필요함을 의미합니다.
- H100이 80GB 메모리를 가졌으므로, 이 시나리오에서 훈련할 수 있는 가장 큰 모델은 약 100억 개의 매개변수(10 Billion Parameters)로 제한됩니다.

3) 완전 분할 데이터 병렬화 (Fully Sharded Data Parallelism, FSDP)
- 해결책: 데이터 배치뿐만 아니라 모델 가중치(Model Weights)도 GPU 간에 분할합니다.
- 네트워크의 각 가중치 행렬(보통 레이어 단위) 는 개의 GPU 중 하나의 소유자 GPU(Owner GPU)에게 할당되며, 이 GPU가 해당 가중치의 전역 기울기 및 옵티마이저 상태를 관리합니다.
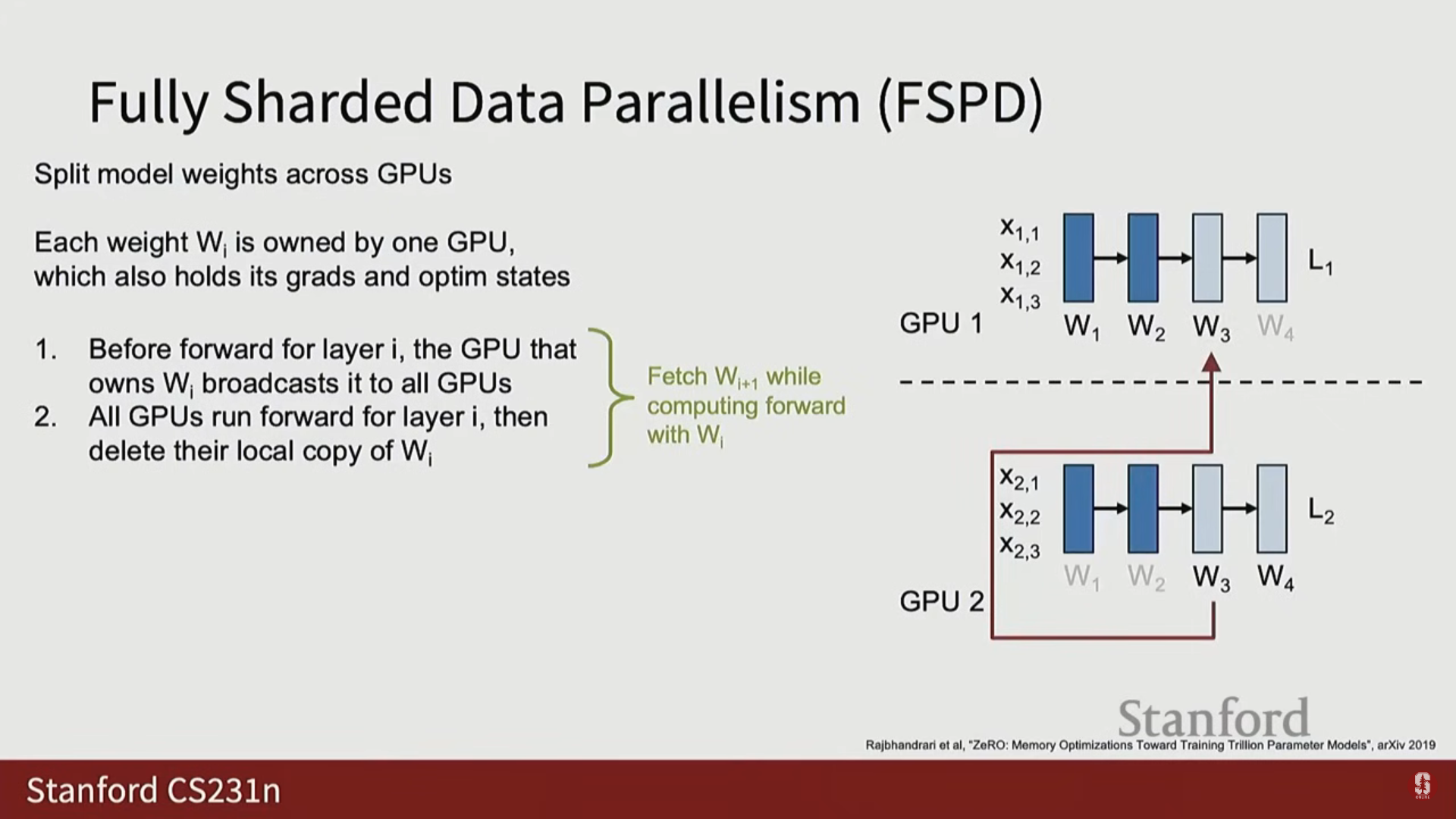
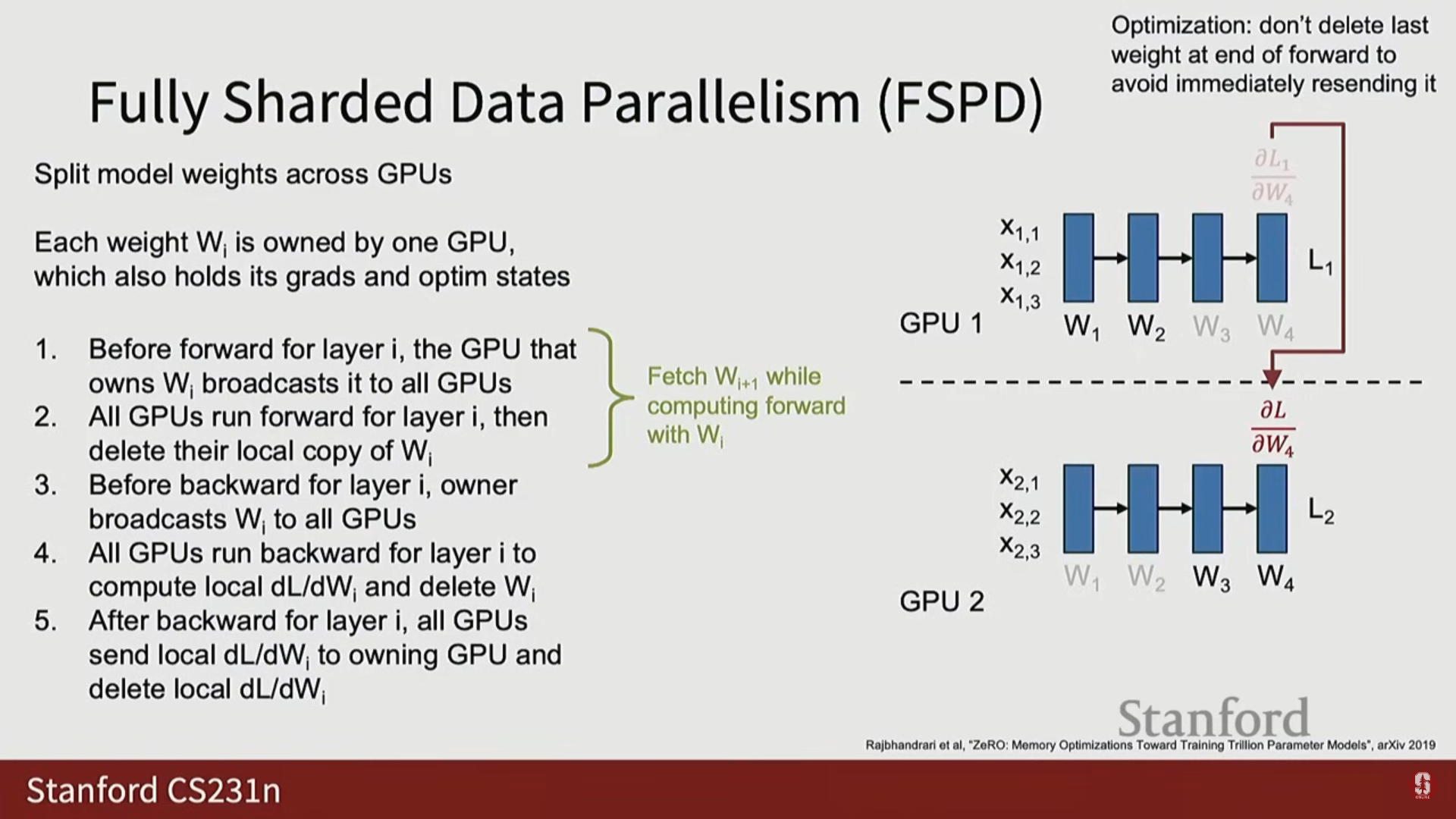
(1) FSDP 순전파 과정
- 가중치 브로드캐스트: 레이어 I의 순전파를 시작하기 전에 해당 가중치를 소유한 GPU가 이 가중치를 모든 다른 GPU에 브로드캐스트합니다.
- 계산 및 메모리 절약: 모든 GPU가 가중치를 받아 순전파를 수행합니다. 순전파 완료 후, 해당 가중치를 소유하지 않은 GPU는 메모리 절약을 위해 로컬 복사본을 즉시 삭제(Delete its local copy)합니다.
- 오버랩: 레이어 I의 순전파 계산이 진행되는 동안, 다음 레이어 I+1의 가중치를 미리 가져오는(pre-fetching) 통신을 병렬로 수행합니다.
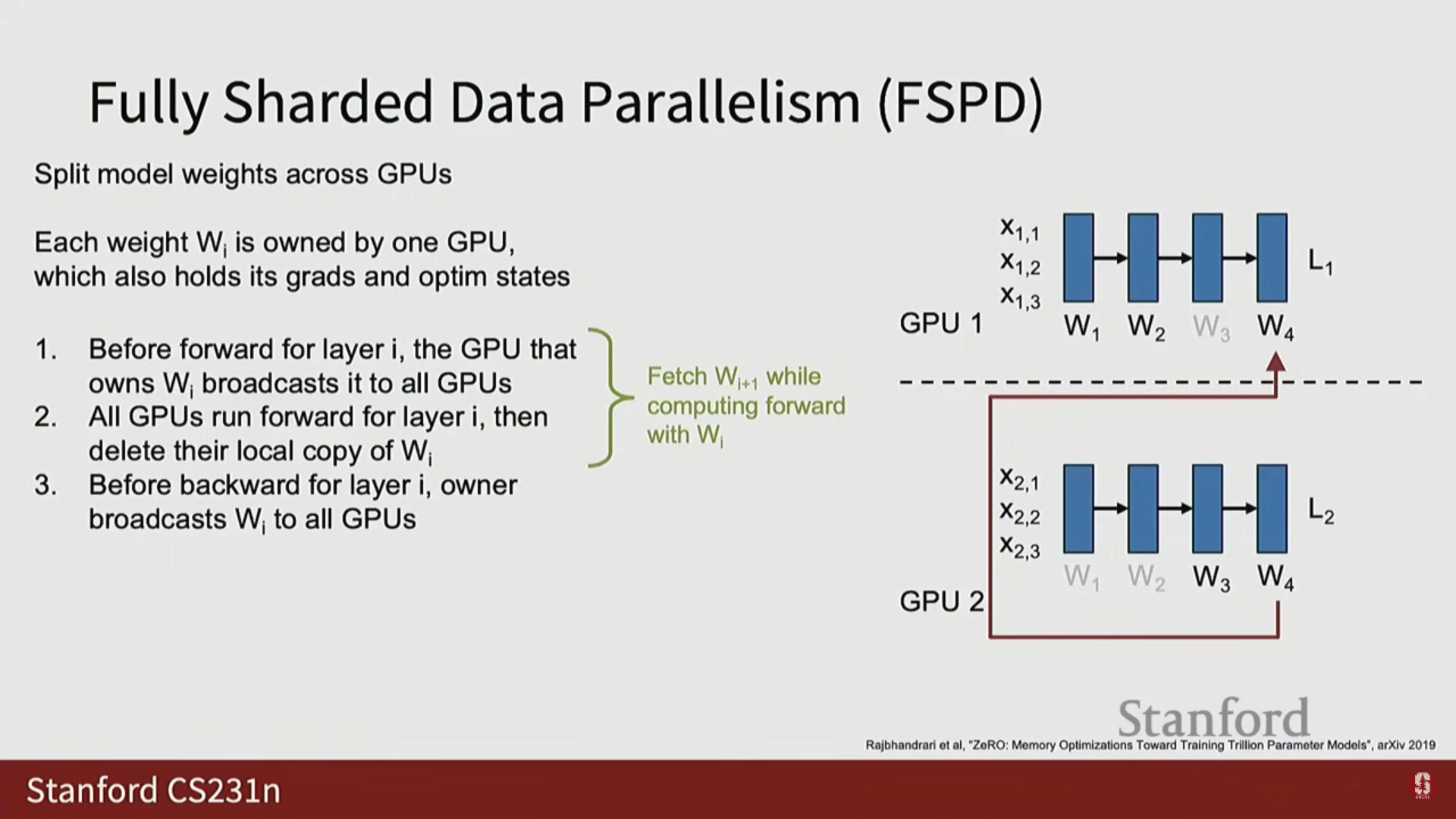
(2) FSDP 역전파 과정
- 가중치 브로드캐스트: 순전파와 유사하게, 역전파를 시작하기 전에 해당 레이어의 가중치를 브로드캐스트합니다. (단, 마지막 레이어의 가중치는 메모리 절약을 위해 삭제하지 않고 유지할 수 있습니다).
- 기울기 집계 (Gather and Sum): 각 GPU가 국소 기울기를 계산한 후, 데이터 병렬화에서처럼 All Reduce를 하는 대신, 해당 가중치를 소유한 소유자 GPU만이 모든 국소 기울기를 모아서 합산(Gather and Sum)하여 전체 매크로 배치에 대한 최종 기울기를 얻습니다.
- 가중치 업데이트: 오직 소유자 GPU만이 완전한 기울기를 가지고 자신의 가중치를 업데이트합니다.
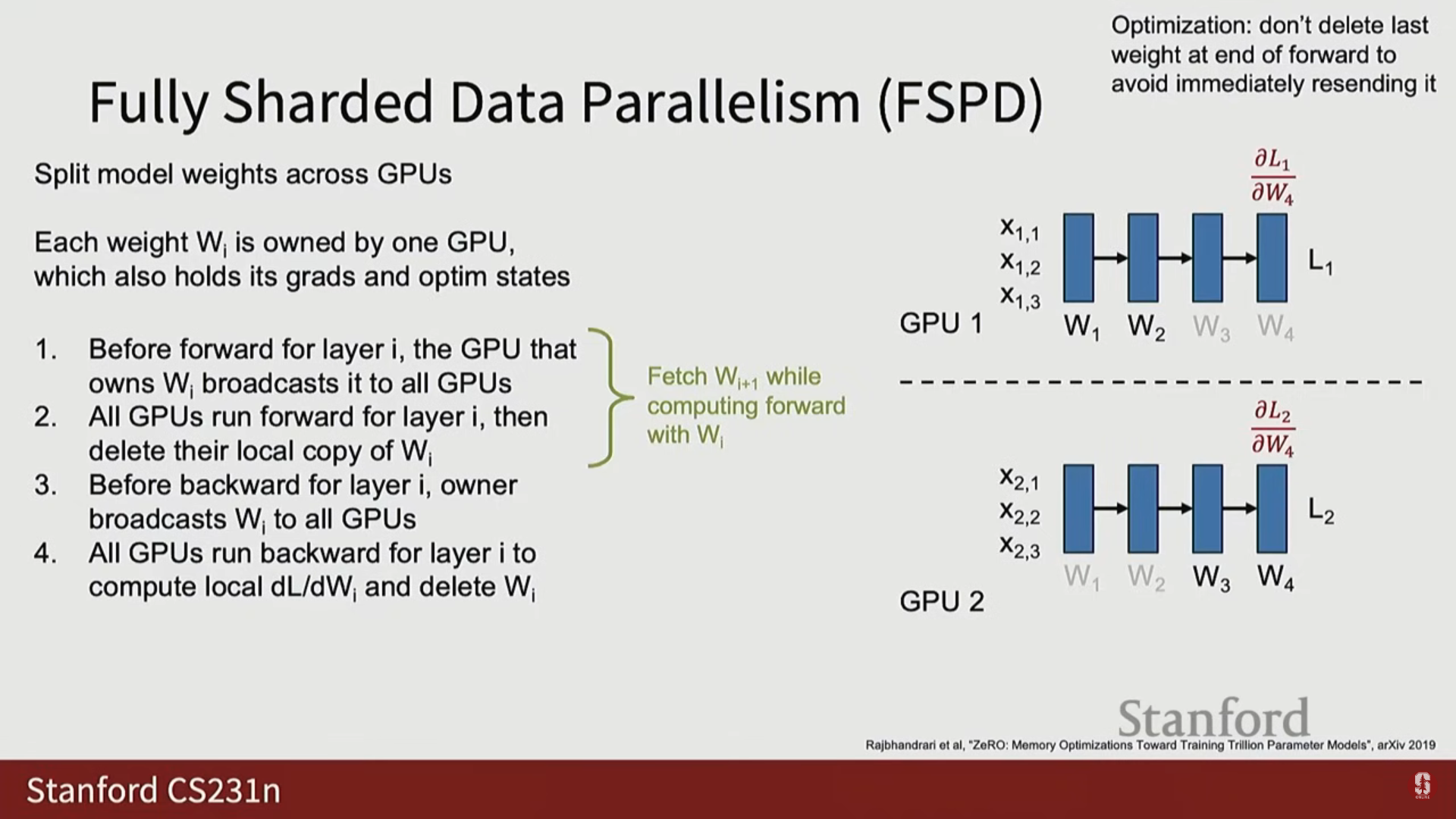
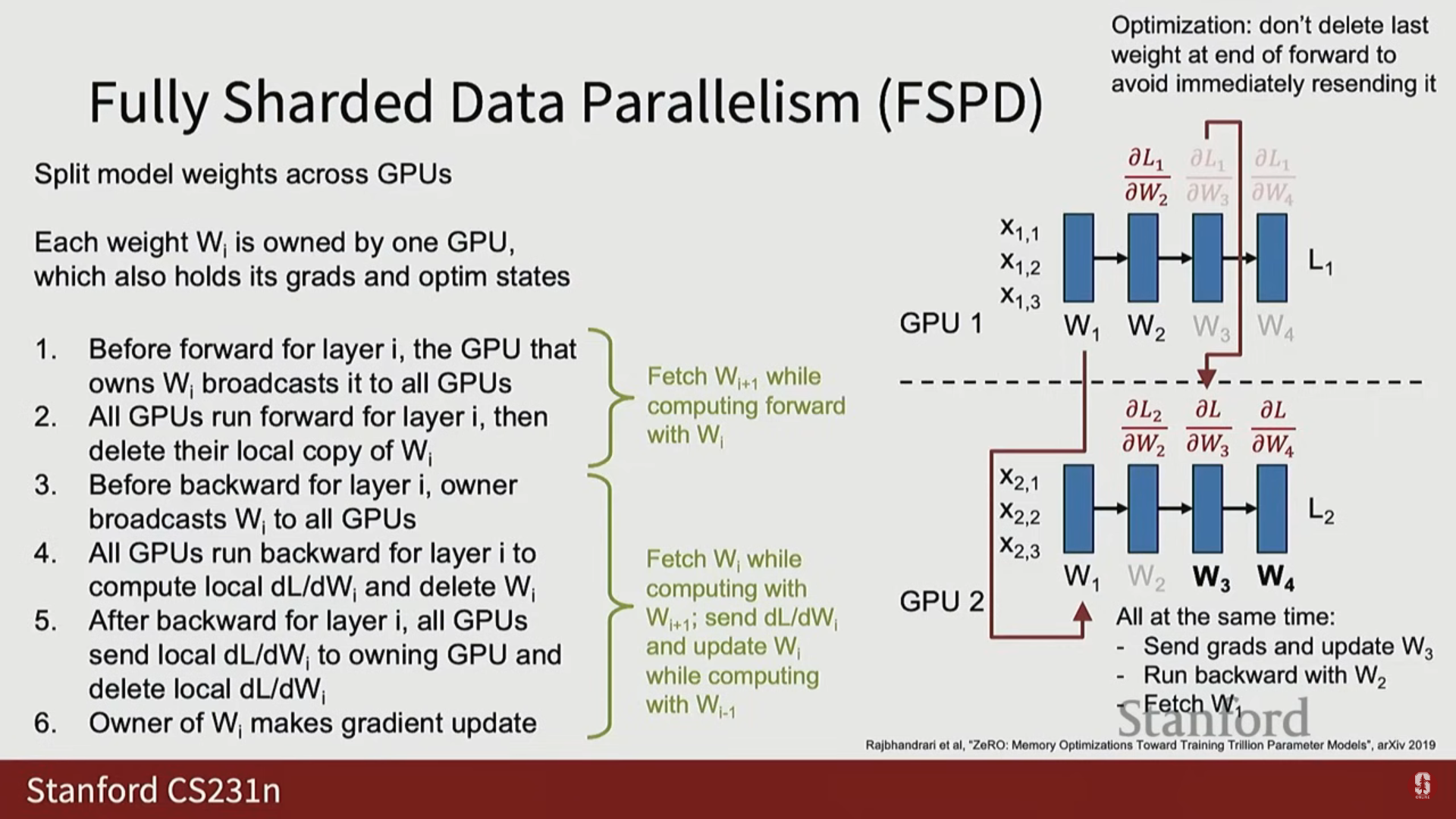
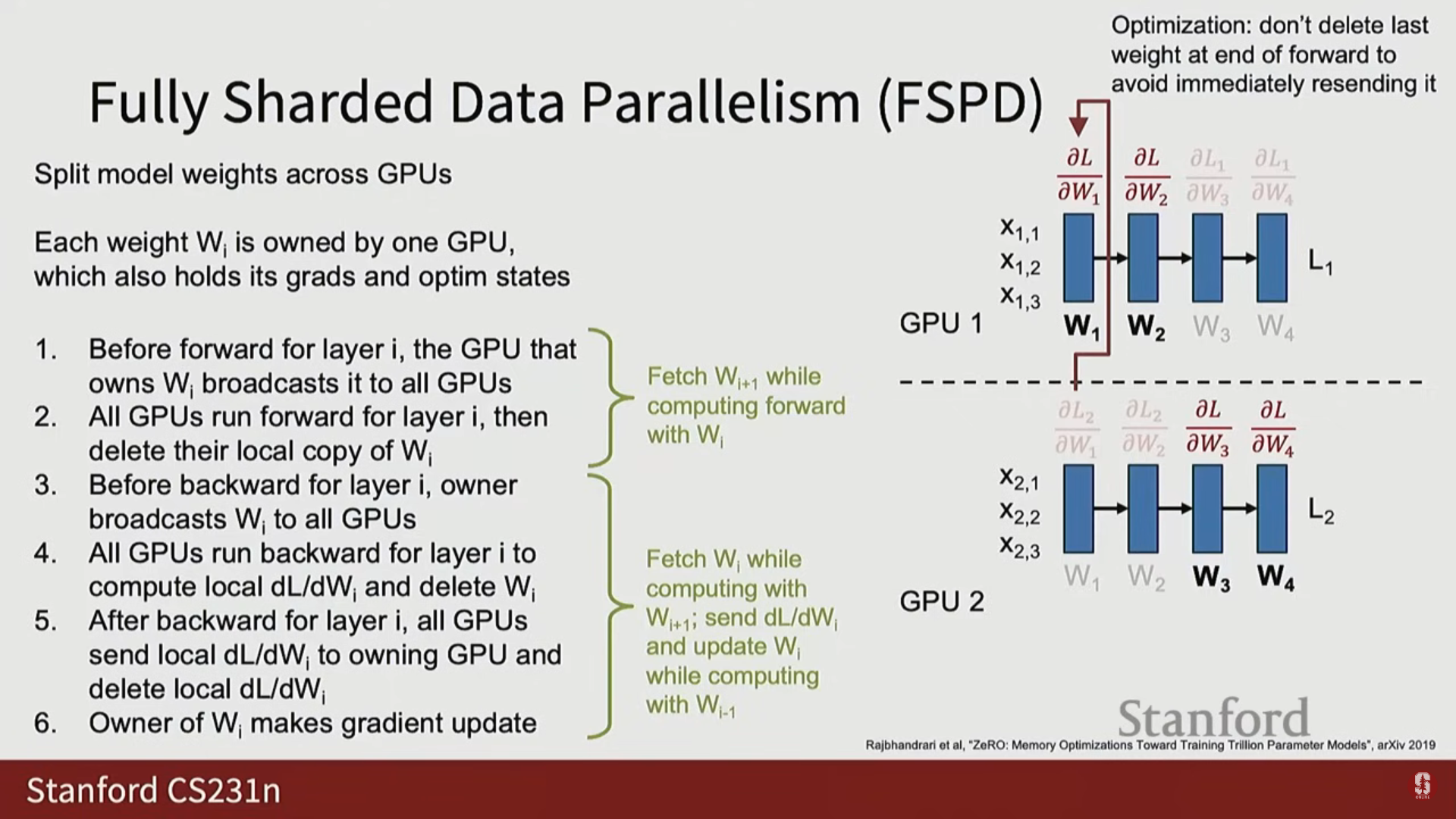
- FSDP 오버랩 (Steady State): 깊은 네트워크에서 역전파가 진행되는 동안 세 가지 작업이 동시에 발생합니다:
- 레이어 의 역전파 계산
- 레이어 의 기울기 집계 및 가중치 업데이트
- 레이어 의 가중치 프리페치
4) 하이브리드 분할 데이터 병렬화 (Hybrid Sharded Data Parallelism, HSDP)
- 개념: GPU를 2차원 그리드로 나누어 두 개의 병렬화 축을 동시에 사용합니다.
- 구조: 개의 GPU 그룹을 구성하고, 각 그룹 내에서는 FSDP를 수행하여 가중치를 분할합니다.
- 그룹 간 병렬화: 개의 그룹 전체에 걸쳐서는 기존의 데이터 병렬화(DP)를 수행합니다.
- 각 그룹은 순전파/역전파 후 자체적인 국소 기울기를 계산합니다.
- 역전파 후, 그룹 간에 All Reduce를 통해 전체 매크로 배치 기울기를 공유합니다.
- 활용 이유: FSDP는 잦은 통신(가중치 3배 통신)이 필요하고, DP는 적은 통신(기울기 1배 통신)이 필요합니다.
- 서버 내부(고속 통신)에서는 FSDP 그룹을 형성하고, 서버 간(저속 통신)에는 DP 그룹을 형성함으로써 클러스터 토폴로지의 이점을 활용하여 통신을 최적화할 수 있습니다.

4. 메모리 병목 해결 및 최적화
1) 활성화 검사점 (Activation Checkpointing)

- 필요성: FSDP로 모델 크기 제약을 해결하더라도, 모델 활성화 값(Activations) 자체가 메모리를 가득 채우는 새로운 병목이 발생합니다.
- 예시: Llama 3 5B 같은 모델의 은닉 상태를 저장하는 데 엄청난 GPU 메모리가 필요합니다.
- 아이디어: 순전파 시 모든 활성화 값을 메모리에 저장하는 대신, 역전파 시 필요한 활성화 값을 재계산(Recompute)합니다.
(1) 계산 복잡도와 메모리 트레이드오프
- 일반적인 순전파/역전파(N개 레이어)는 계산량과 메모리가 필요합니다.
- 모든 활성화 재계산 시: 순전파 시 활성화 값을 모두 버리고, 역전파 시마다 모든 이전 활성화 값을 재계산합니다.
- 계산 복잡도: (이차 시간 복잡도).
- 메모리 복잡도: (상수 메모리). (딥 네트워크에서는 이차 복잡도가 매우 비효율적입니다).
- 체크포인트 활용: 개 레이어마다 활성화 값의 체크포인트를 저장하고, 그 블록 내에서만 재계산을 수행합니다.
- 계산 복잡도: .
- 메모리 복잡도: .
- 최적의 트레이드오프: 로 설정하면, 계산 복잡도는 , 메모리 복잡도는 이 되어 계산량과 메모리 사용량 사이의 균형을 맞출 수 있습니다.

2) 대규모 훈련을 위한 스케일링 레시피
- DP (최대 128 GPU, 10억 매개변수 이하): 일반적인 데이터 병렬화를 사용합니다. GPU당 로컬 배치 크기를 메모리가 허용하는 최대치로 설정하는 것이 일반적입니다.
- FSDP (10억 매개변수 초과): 모델 자체가 너무 커져 메모리 병목이 발생하면 FSDP로 전환합니다.
- 활성화 검사점 (Activations Bottleneck): FSDP로 모델 크기를 키웠으나 활성화 값 때문에 메모리가 부족해지면 활성화 검사점을 활성화합니다. (이것은 속도를 늦추지만 더 큰 모델 훈련을 가능하게 합니다).
- HSDP (수백 GPU 초과, 256~512 GPU 이상): FSDP의 통신 비용이 너무 비싸지면 HSDP로 전환하여 클러스터 토폴로지에 맞게 통신을 최적화합니다.
- 최종 단계: 1,000 GPU, 500억 매개변수, 10,000 이상의 시퀀스 길이를 초과하는 경우 컨텍스트/파이프라인/텐서 병렬화 같은 고급 전략이 필요합니다.

3) 핵심 최적화 지표: MFU
- 병렬화 설정(배치 크기, HSDP 차원, 재계산 정도 등)이 많아 길을 잃었을 때, 모델 FLOPS 활용률(Model Flops Utilization, MFU)이 최적화를 위한 지침이 됩니다.
(1) 하드웨어 FLOPS 활용률 (HFU)
- 정의: 장치의 이론적인 최대 처리량(theoretical maximum throughput) 대비 실제로 달성한 컴퓨팅 비율입니다.
- 예시: H100에서 대규모 행렬 곱셈을 벤치마크했을 때, 이론적 최대치의 약 80% HFU를 달성할 수 있습니다.

(2) 모델 FLOPS 활용률 (MFU)
- 정의: GPU의 이론적인 최고 FLOPS 중 모델의 순전파 및 역전파(forward backward)에 사용되는 FLOPS의 비율입니다.
- 계산:
- 모델 아키텍처와 배치 크기를 기반으로 순전파/역전파에 필요한 총 FLOPS를 계산합니다.
- 장치의 이론적 최고 처리량으로 나누어, 이론적으로 걸려야 할 최소 시간을 계산합니다.
- 실제 훈련 루프(데이터 로딩, 통신, 체크포인팅 등을 포함)에서 측정한 실제 시간을 이론적 최소 시간으로 나눕니다.
$$ \text{MFU} = \frac{\text{모델의 이론적 FLOPS}}{\text{실제 걸린 시간} \times \text{장치의 이론적 최고 FLOPS}} $$
- 최적화 목표: MFU를 최대화하는 것이 훈련 처리량 최적화의 핵심입니다.
- 일반적인 MFU 값: 일반적으로 30% 이상이면 양호하고, 40% 이상이면 매우 우수하며 최첨단(State-of-the-art)으로 간주됩니다.
- Llama 3 MFU: Llama 3 405B는 최종 훈련 단계(8,000~16,000 GPU)에서 30% 후반에서 40% 초반의 MFU를 달성했습니다.


(3) 심화 내용: MFU의 한계와 최신 동향
- H100의 역설: 최신 장치인 H100이 이전 장치인 A100보다 때때로 MFU가 낮게 나올 수 있습니다.
- 기술적 배경: GPU는 지난 세대에 비해 이론적 컴퓨팅 처리량은 약 3배 향상되었지만, 이론적 메모리 대역폭(통신 속도)은 약 2배 향상에 그쳤기 때문입니다.
- 결론: 컴퓨팅 속도가 통신 속도보다 훨씬 빠르게 증가함에 따라, 통신이 병목이 되어 MFU가 상대적으로 낮아지는 경향이 있습니다.
5. 고급 병렬화 전략
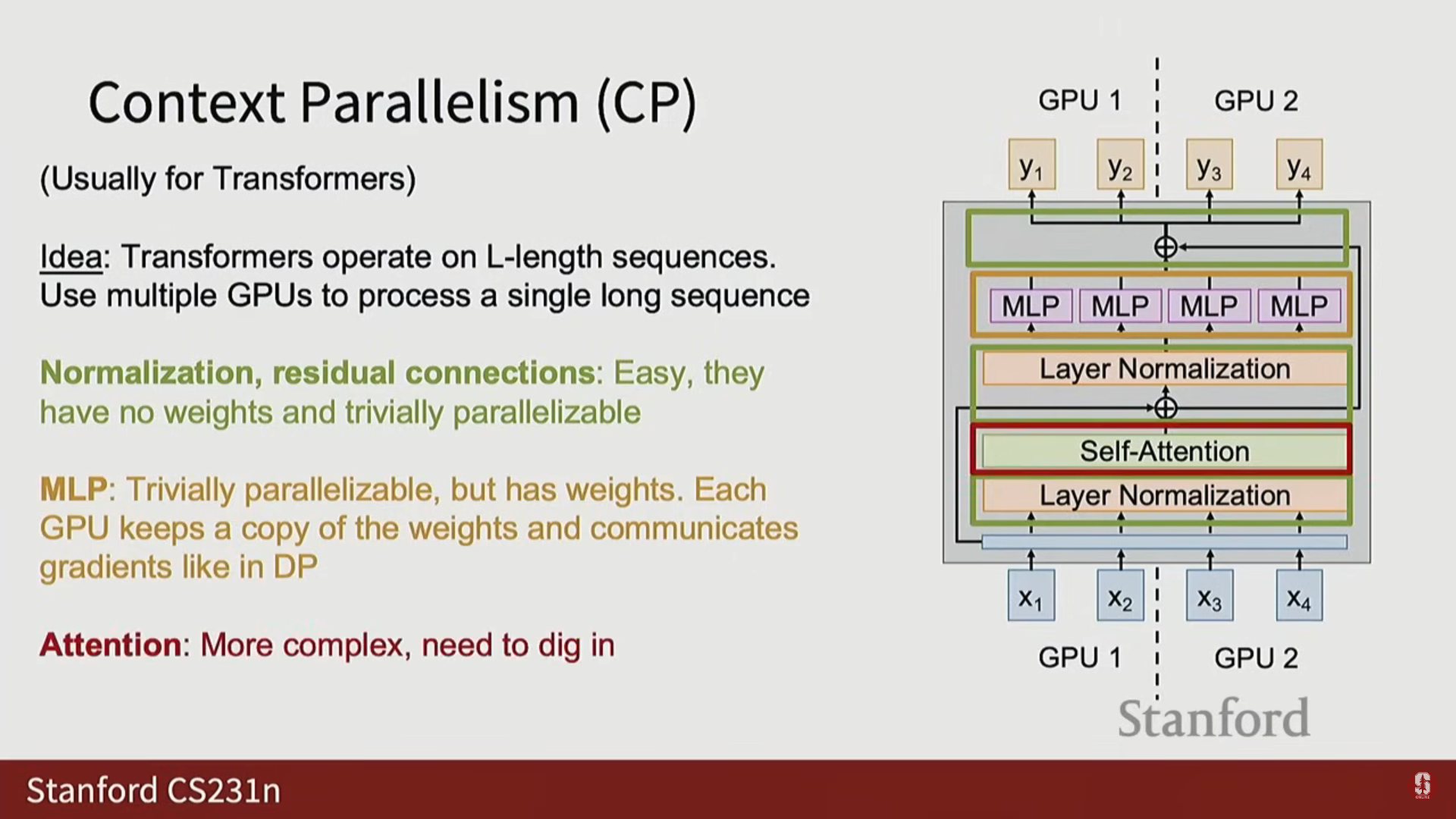
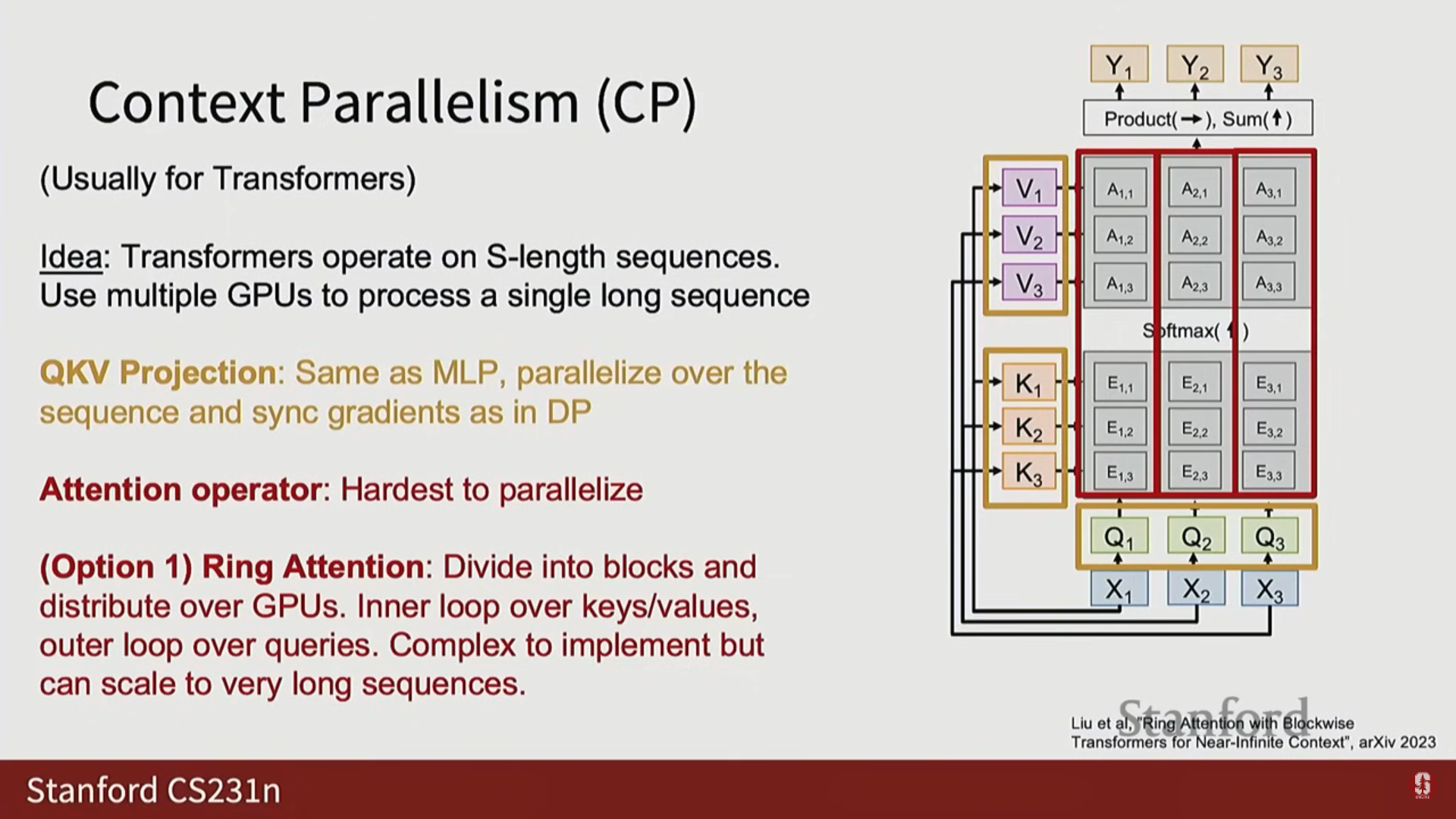
1) 컨텍스트 병렬화 (Context Parallelism, CP)
- 분할 축: 시퀀스 차원(Sequence Dimension)을 따라 분할합니다.
- 활용: 레이어 정규화(Layer Norm), MLP(FFN), 잔차 연결(Residual Connections)은 시퀀스 전반에 걸쳐 독립적으로 작동하므로 병렬화가 비교적 쉽습니다.
- 난제: Attention: 시퀀스의 모든 요소 쌍 간의 상호 작용을 계산해야 하는 어텐션 행렬이 병렬화하기 까다롭습니다.
- Ring Attention: 전체 어텐션 행렬을 블록으로 나누어 GPU들이 순서대로 블록을 병렬 처리하는 방식이 개발되었습니다.
- Ulysses Attention: 멀티 헤드 어텐션(Multi-head attention)의 헤드(Heads) 축을 따라 어텐션 연산자를 병렬화하고, 나머지 트랜스포머 부분은 시퀀스 차원을 따라 병렬화하는 방식입니다.
- Llama 3 예시: Llama 3는 13만 개의 매우 긴 시퀀스 길이로 2단계 훈련을 수행할 때, 16-way 컨텍스트 병렬화를 사용했습니다.


2) 파이프라인 병렬화 (Pipeline Parallelism, PP)
- 분할 축: 레이어 차원(Layer Dimension)을 따라 네트워크의 레이어를 GPU에 분할합니다.
- 문제점: 순차적 의존성 (Sequential Dependencies): 순전파는 이전 GPU의 활성화 값이 필요하고, 역전파는 상위 레이어의 기울기가 필요하여 GPU들이 대부분 유휴 상태가 되는 버블(Bubble) 구간이 발생합니다.
- 개의 GPU를 사용할 경우 최대 MFU가 로 매우 낮아집니다 (예: 8-way 병렬화 시 MFU 12%).
- 해결책: 마이크로 배치 (Micro Batches): 여러 개의 마이크로 배치(MB)를 동시에 실행하여 버블을 줄입니다.
- 마이크로 배치를 순차적으로 파이프라인하여 MFU를 높입니다.
- 예시: 4-way PP에서 4개의 마이크로 배치를 사용하면 최대 MFU는 57%까지 증가합니다.
- 트레이드오프: 마이크로 배치가 많아질수록 MFU는 높아지지만, 활성화 값을 메모리에 저장해야 하므로 활성화 검사점이 필요해집니다. 최적의 MFU를 위해 이 요소들을 조정해야 합니다.


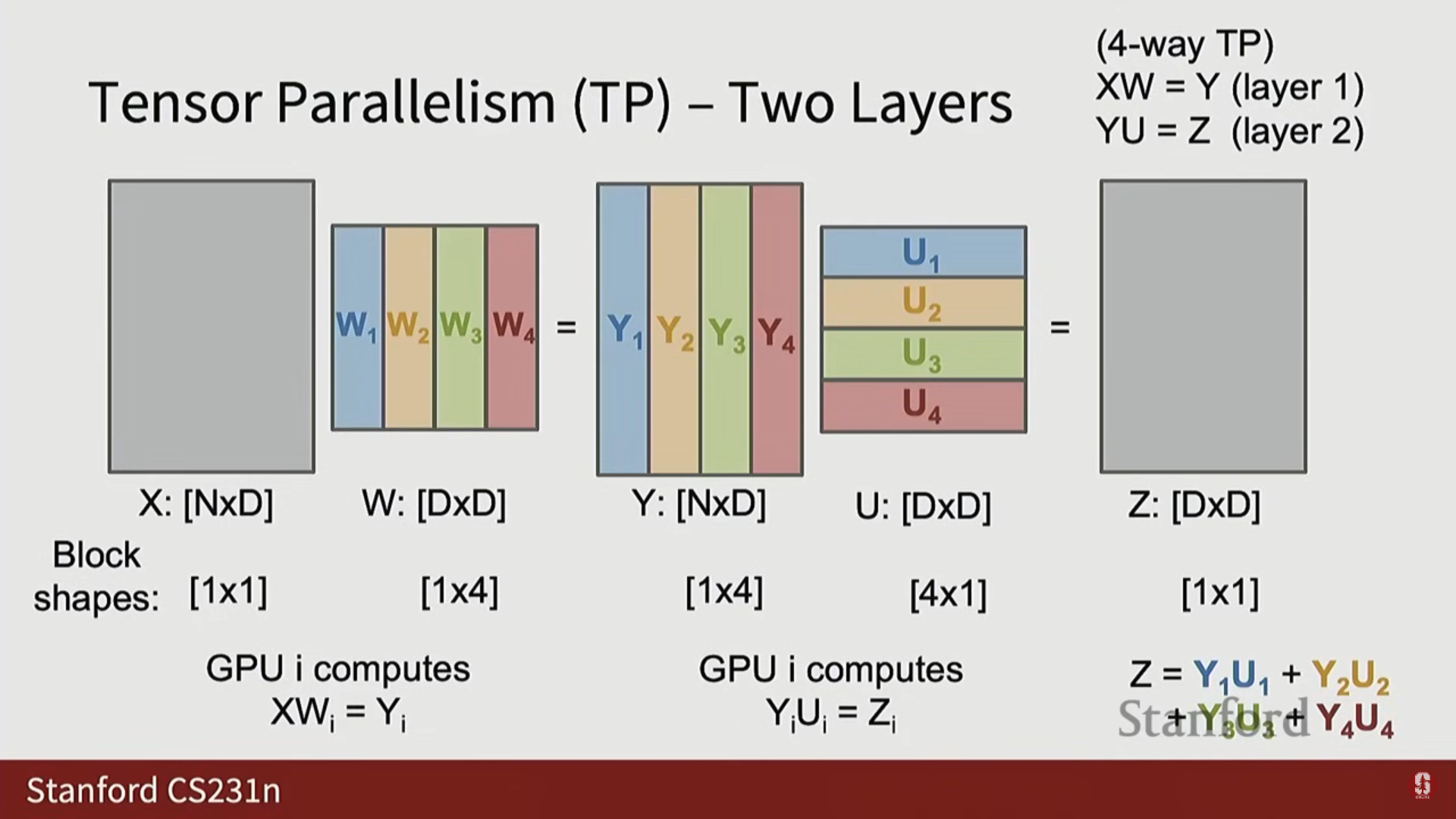
3) 텐서 병렬화 (Tensor Parallelism, TP)
- 분할 축: 모델 차원(Dim Dimension)을 따라 분할합니다.
- 아이디어: 모델 내부의 각 가중치 행렬을 GPU 간에 분할합니다 (FSDP와 달리, 단일 행렬을 쪼개어 분할).
- 구현: 행렬 곱셈 에서, 가중치 행렬 를 조각(Slice)으로 나누어 각 GPU가 입력 에 대해 해당 조각을 계산하여 출력 의 조각을 계산합니다.
- 문제: 다음 순전파를 위해 활성화 값 를 모든 GPU에서 모아야(Gather) 합니다.
- 최적화 트릭 (2-Layer Trick): 가중치 행렬을 두 개의 레이어가 연속될 때 (예: 트랜스포머의 FFN MLP), 첫 번째 행렬을 열(Column) 형태로 분할하고 두 번째 행렬을 행(Row) 형태로 분할하면, 두 레이어마다 한 번만 통신해도 됩니다.
- 이 트릭은 트랜스포머가 항상 2-Layer MLP를 가지고 있기 때문에 대규모 트랜스포머에서 텐서 병렬화를 사용하는 일반적인 방법입니다.

- 이 트릭은 트랜스포머가 항상 2-Layer MLP를 가지고 있기 때문에 대규모 트랜스포머에서 텐서 병렬화를 사용하는 일반적인 방법입니다.
6. 통합 병렬화 전략 및 QnA 정리
1) N차원 병렬화 (N-Dimensional Parallelism)

- 실제 최첨단 훈련에서는 단일 병렬화 방식이 아니라 모든 병렬화 방식을 결합한 N차원 병렬화가 사용됩니다.
- Llama 3의 최종 구성 (4차원 병렬화):
- 16,000 GPU를 사용하여 8-way 텐서 병렬화, 16-way 컨텍스트 병렬화, 16-way 파이프라인 병렬화, 8-way 데이터 병렬화를 동시에 사용했습니다.
- 이러한 다양한 병렬화 축의 통신 요구 사항이 다르기 때문에, 클러스터의 통신 속도 차이에 맞춰 축을 배열함으로써 성능을 극대화합니다.

7. QnA
Q: 가장 긴 훈련 실행 기간은 얼마입니까?
A: 가장 긴 모델 훈련은 일반적으로 몇 달 단위로 측정되며, GPT-4.5나 GPT-5처럼 매우 큰 모델은 1년에 가까울 수도 있습니다.
Q: 왜 서버를 포드보다는 랙으로 조직합니까?
A: 랙은 수십 년 동안 데이터 센터의 표준 단위였습니다. GPU 서버가 등장했더라도, 데이터 센터 전체를 하룻밤에 재설계할 수 없으므로 랙을 표준 단위로 사용합니다.
Q: 클러스터는 얼마나 많은 물리적 공간을 차지합니까?
A: 서버 랙 하나는 연단이나 사람 키 정도(6~8피트)의 크기입니다. 192개의 랙이 포드를 구성하며, 컴퓨팅 랙 외에도 네트워킹 및 스토리지 랙이 필요하므로 상당한 공간을 차지합니다.
Q: 대규모 클러스터에서 작은 단위의 컴퓨팅은 더 높은 처리량을 유지합니까?
A: 네, 유지합니다. 시스템 설계의 도전 과제는 빠른 통신을 최대한 활용하되, 더 큰 단위에서 느린 통신으로 우아하게 대체하는 것입니다.
Q: 클러스터는 얼마나 뜨거워집니까?
A: 매우 뜨겁습니다. 4090 GPU 하나만으로도 방이 더워질 수 있기 때문에, 수만 개의 GPU가 쌓인 데이터 센터에는 심각한 냉각(Cooling) 요건이 필요합니다.
Q: 통신과 계산을 겹치기 위해 코드를 직접 작성해야 합니까? 하드웨어가 자동으로 처리합니까?
A: 클러스터 레벨에서는 소프트웨어(예: PyTorch DDP)로 오케스트레이션 해야 합니다. 개별 디바이스 레벨에서는 CUDA를 사용하여 프로그래밍 할 때 하드웨어가 비동기 전송을 자동으로 처리해주는 경우가 많습니다.
Q: DP에서 통신과 계산 중 어느 것이 병목이 됩니까?
A: 상황에 따라 다릅니다. 이는 장치의 속도, 모델 크기, 미니 배치 크기, 장치 간 인터커넥트 속도 등 전적으로 환경에 따라 달라지며, 벤치마킹이 필요합니다.
Q: 왜 각 GPU에서 번의 독립적인 기울기 단계를 수행하지 않습니까?
A: 이는 비동기 SGD(Asynchronous SGD)라는 아이디어로, 과거에 사용되기도 했으나 일반적으로 더 불안정하고 디버깅 및 재현이 매우 어렵습니다. 동기식 업데이트가 가능한 경우 더 나은 성능을 보장합니다.
8. 결론 및 주요 학습 내용
- 개별 GPU는 범용 병렬 컴퓨팅 머신입니다.
- GPU 클러스터는 수만 개의 개별 GPU를 가진 거대한 병렬 머신이며, 우리는 이를 하나의 거대한 단위로 프로그래밍하려고 합니다.
- 주요 전략: 데이터 병렬화(DP, FSDP, HSDP), 메모리 절약을 위한 활성화 검사점, 그리고 고급 병렬화(CP, PP, TP) 메커니즘을 통해 대규모 클러스터에서 계산을 병렬화합니다.
- 최대화 지표: 이러한 파이프라인을 설계할 때 항상 최적화해야 하는 하나의 지표는 MFU (Model Flops Utilization)입니다.

