
1. 서론: 왜 자기 지도 학습이 필요한가?
-
지난 강의에서는 GPU 사용법, 대규모 훈련 확장, 그리고 이미지 분류, 의미론적 분할, 객체 탐지 등 핵심적인 컴퓨터 비전(CV) 태스크에 대해 다루었습니다.
-
초기에는 픽셀 공간에서의 최근접 이웃(Nearest Neighbor) 방식을 논했지만, 이는 효율적이지 않습니다.
-
대신, 임베딩 계층(embedding layers) 또는 특징 공간(feature space)에서 추출된 학습된 표현(Learned Representations)을 사용하는 것이 효과적입니다.
- 이러한 학습된 표현은 특징(features), 임베딩(embeddings), 또는 잠재 공간(latent space) 등으로 불리며 이미지의 훌륭한 대표자 역할을 합니다.
- 이 특징들을 활용하면 간단한 선형 모델을 통해 클래스 레이블을 얻을 수 있습니다.
-
주요 과제: 대규모 신경망을 훈련시키는 것은 항상 어렵습니다. 그 이유는 대규모 훈련을 위해서는 막대한 양의 수동 레이블링된 데이터가 필요하기 때문입니다.
- 예를 들어, 분할(Segmentation) 작업의 경우 이미지의 픽셀을 하나하나 수동으로 레이블링해야 하므로 매우 어렵습니다.

- 예를 들어, 분할(Segmentation) 작업의 경우 이미지의 픽셀을 하나하나 수동으로 레이블링해야 하므로 매우 어렵습니다.
-
자기 지도 학습(Self-Supervised Learning)의 등장: 수동으로 레이블링된 대규모 데이터 세트 없이도 신경망을 훈련하여 매우 좋은 특징을 얻을 수 있는 방법을 찾는 것이 목표입니다.
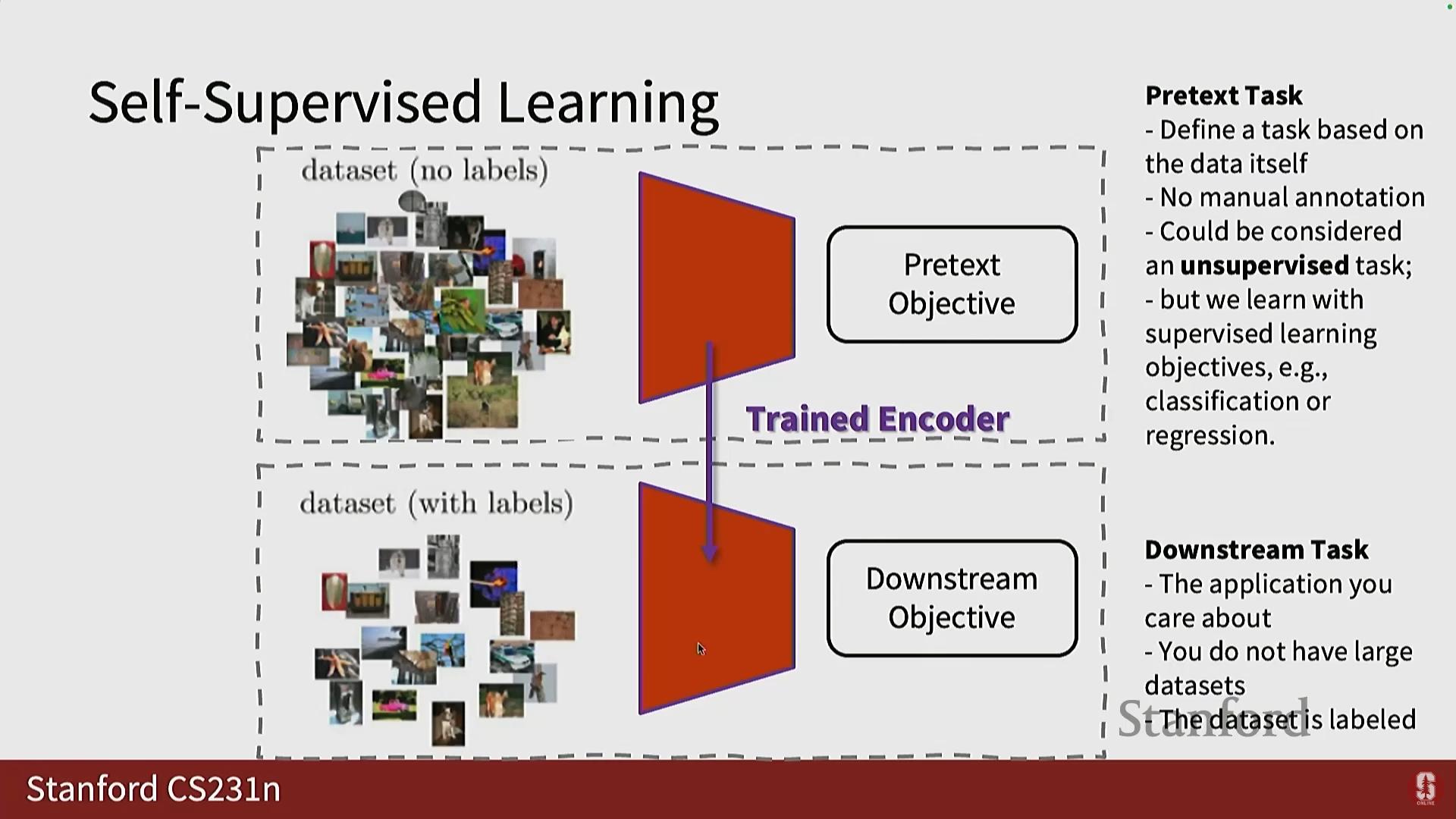
2. 자기 지도 학습의 기본 개념 및 구조
-
가설: 레이블이 없는 대규모 데이터 세트(예: 인터넷에서 다운로드한 자연 이미지)를 사용하여, 특징을 잘 학습할 수 있는 사전 작업(Pretext Task)을 정의하고, 이를 통해 신경망을 훈련할 수 있습니다.

-
지식 전이(Transfer of Knowledge): 사전 작업으로 훈련된 인코더(Encoder)를 추출하여, 레이블이 적은 특정 데이터 세트(예: 산업 또는 의료 애플리케이션)를 위한 다운스트림 태스크(Downstream Task)에 활용합니다.
-
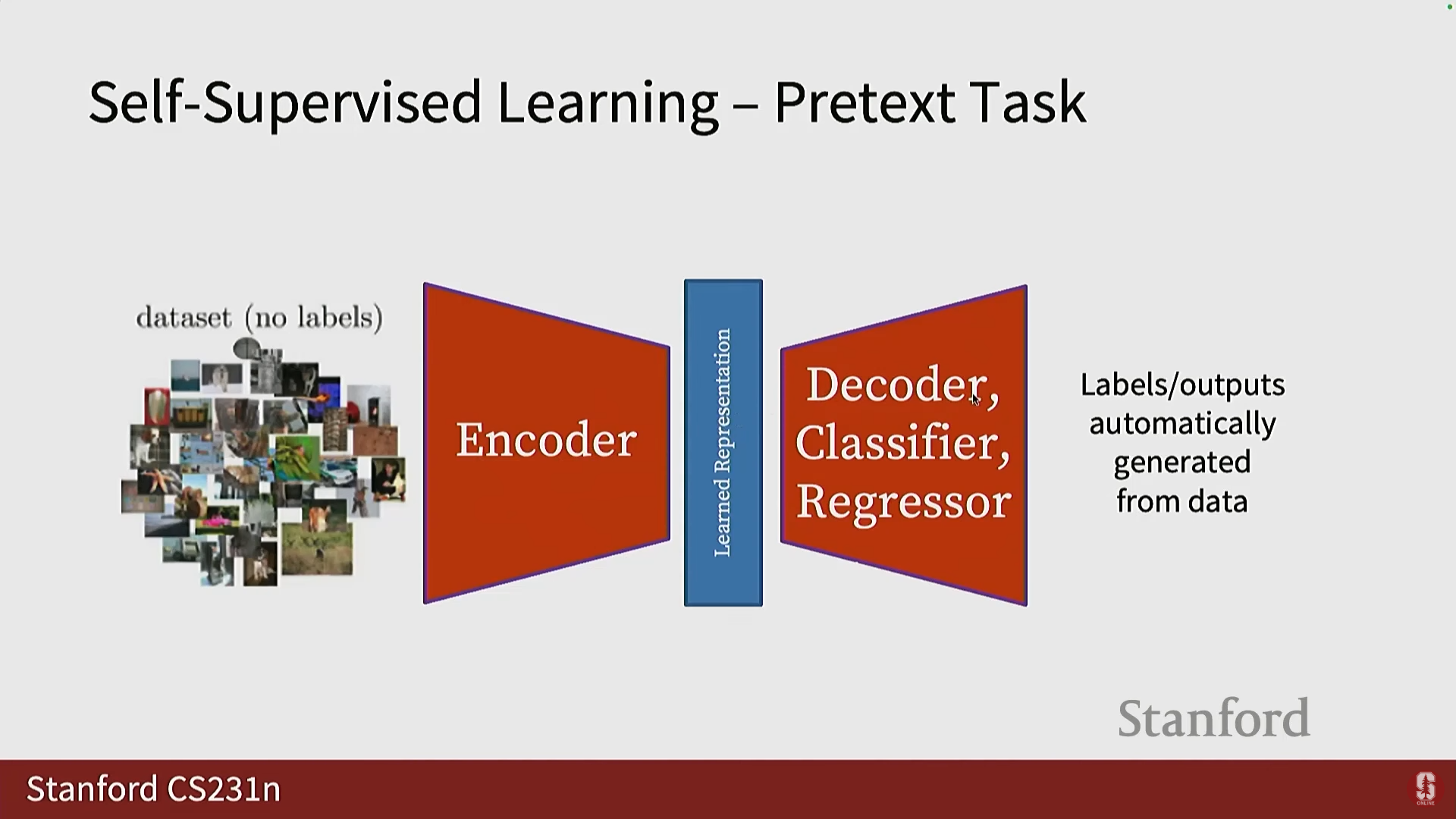
SSL의 구성 요소:
- 레이블이 없는 데이터 세트에 사전 작업을 정의합니다.
- 인코더가 학습된 표현을 얻습니다.
- 다른 모듈(예: 디코더, 분류기, 회귀 분석기)이 학습된 표현을 자동으로 데이터에서 생성된 출력 공간으로 변환합니다.
-
자동 레이블 생성: SSL의 핵심은 수동 주석(Manual annotations)이 아닌 데이터 자체에서 레이블을 자동 생성하는 것입니다.
-
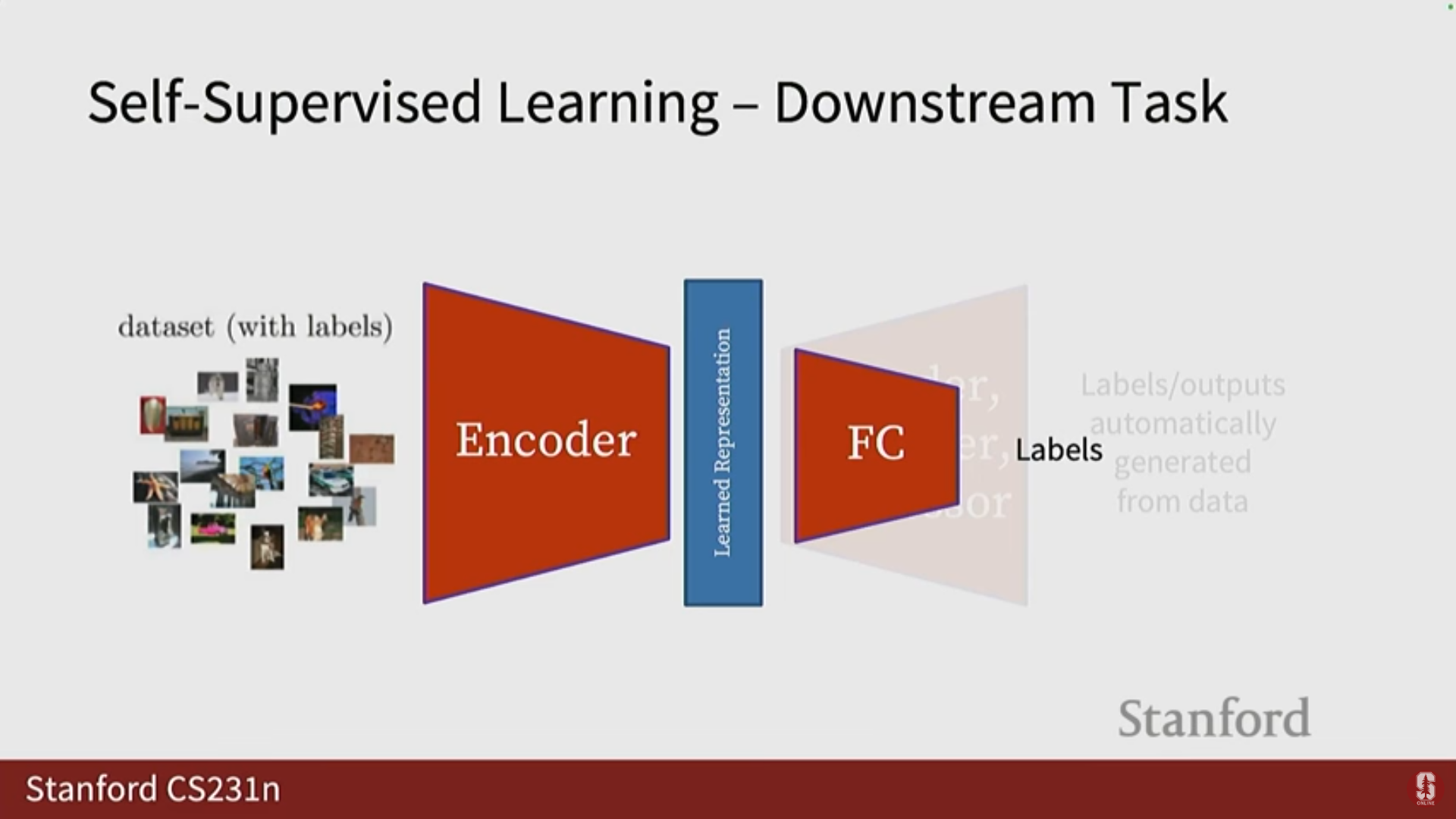
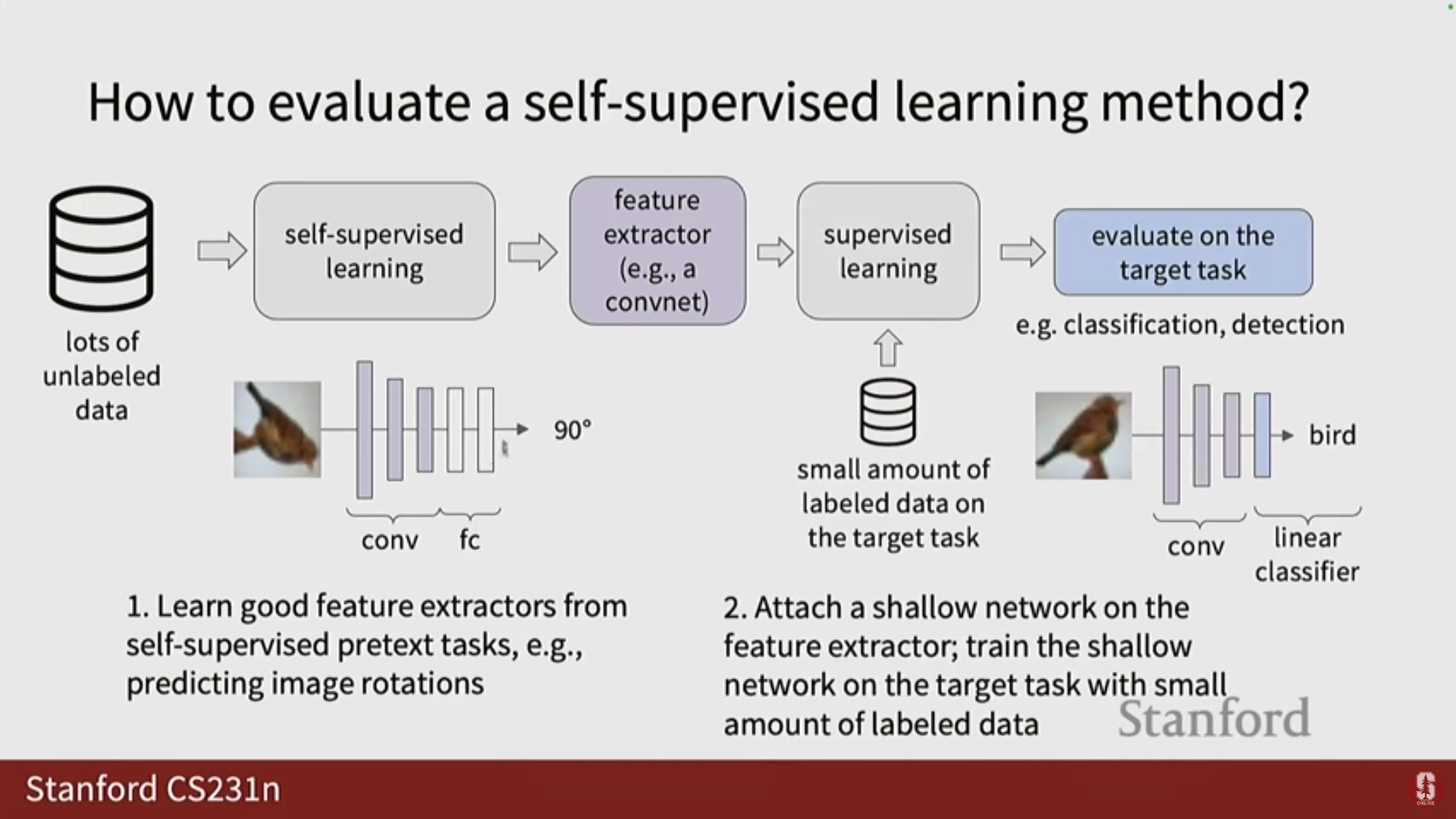
훈련 후 적용: 사전 작업으로 훈련이 완료된 후, 인코더는 동결되고 다운스트림 태스크를 위해 단일 계층(예: 선형 함수) 또는 완전 연결 신경망이 추가되어 레이블을 예측하는 데 사용됩니다.
- 특징이 충분히 좋다면, 클래스 레이블을 얻기 위해 많은 훈련이 필요하지 않으므로 얕은 네트워크(shallow network)를 사용합니다.

- 특징이 충분히 좋다면, 클래스 레이블을 얻기 위해 많은 훈련이 필요하지 않으므로 얕은 네트워크(shallow network)를 사용합니다.


3. 사전 작업 (Pretext Tasks): 이미지 변환 기반 방법
- 사전 작업은 다음 두 가지 조건을 충족해야 합니다: 1) 충분히 일반적(General)이어서 좋은 특징을 얻을 수 있을 것. 2) 수동 레이블링이 필요하지 않고 레이블이 데이터 자체에서 나올 수 있을 것.
이미지 변형 기반 사전 작업 개요
- 사전 작업의 예시 (오늘 다룰 4가지): 이미지 완성(Image Completion), 회전 예측(Rotation Prediction), 직소 퍼즐(Jigsaw Puzzle), 색상화(Colorization).
- 이러한 사전 작업을 해결함으로써 모델은 좋은 특징을 학습하게 됩니다.
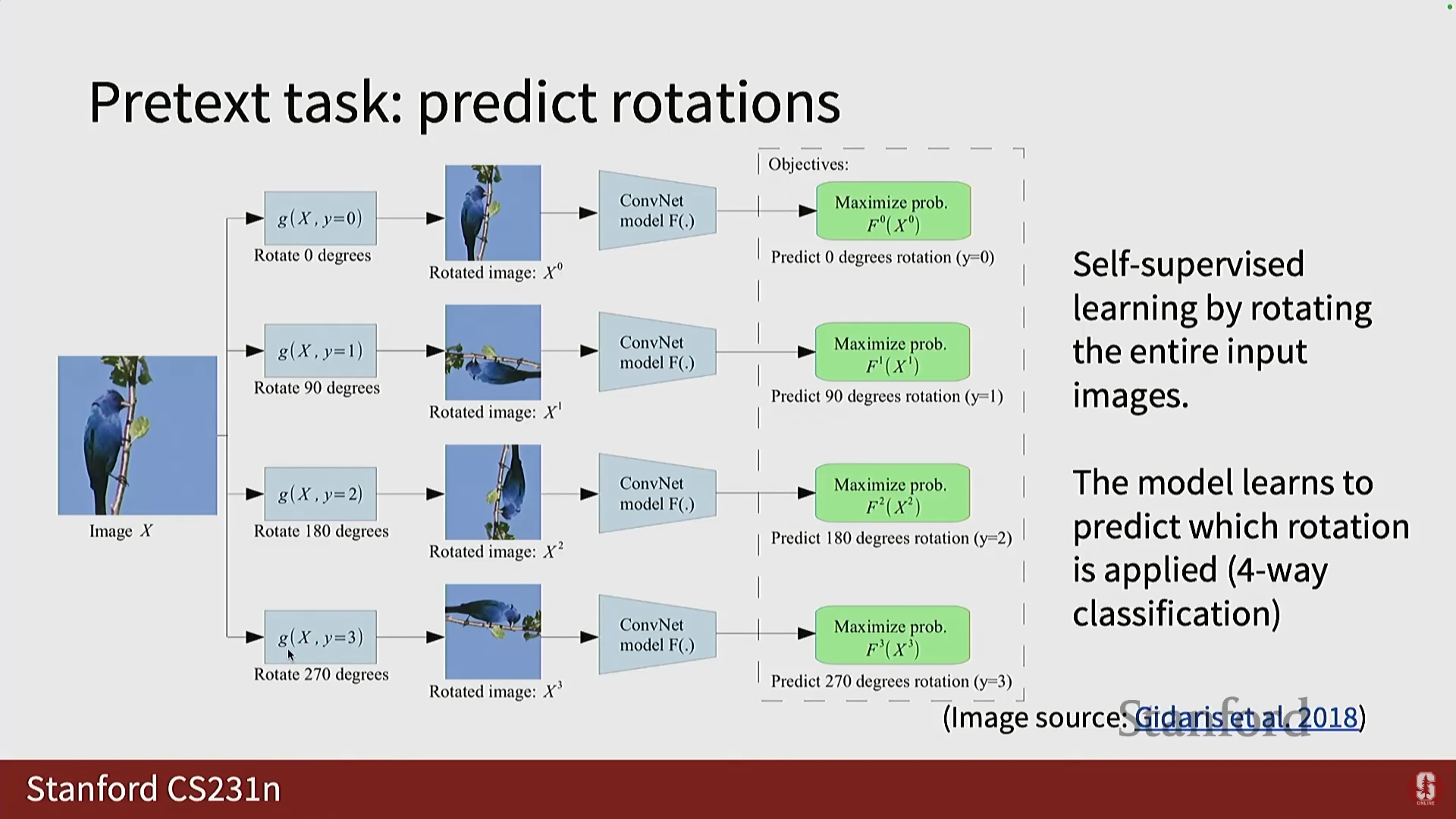
1) 이미지 회전 예측 (Rotation Prediction)
- 가설: 모델이 객체가 방해받지 않았을 때 어떻게 보여야 하는지에 대한 시각적 상식(visual common sense)을 가지고 있을 경우에만 올바른 회전을 인식할 수 있습니다.
- 모델이 이를 포착할 수 있다면, 이미지 전체를 유용한 특징으로 요약할 수 있음을 의미합니다.
- 구현: 2018년 논문에서 0°, 90°, 180°, 270°의 네 가지 회전 각도만 사용하여 이를 4-way 분류 태스크로 정의했습니다.

- 훈련 및 적용: 컨볼루션 계층과 끝단의 완전 연결 신경망(FC layers)을 사용하여 회전 각도를 예측합니다.
- 이후 FC 계층을 제거하고 객체 레이블을 예측하는 선형 함수(또는 여러 계층)를 추가하여 다운스트림 태스크를 수행합니다.
- 이후 FC 계층을 제거하고 객체 레이블을 예측하는 선형 함수(또는 여러 계층)를 추가하여 다운스트림 태스크를 수행합니다.
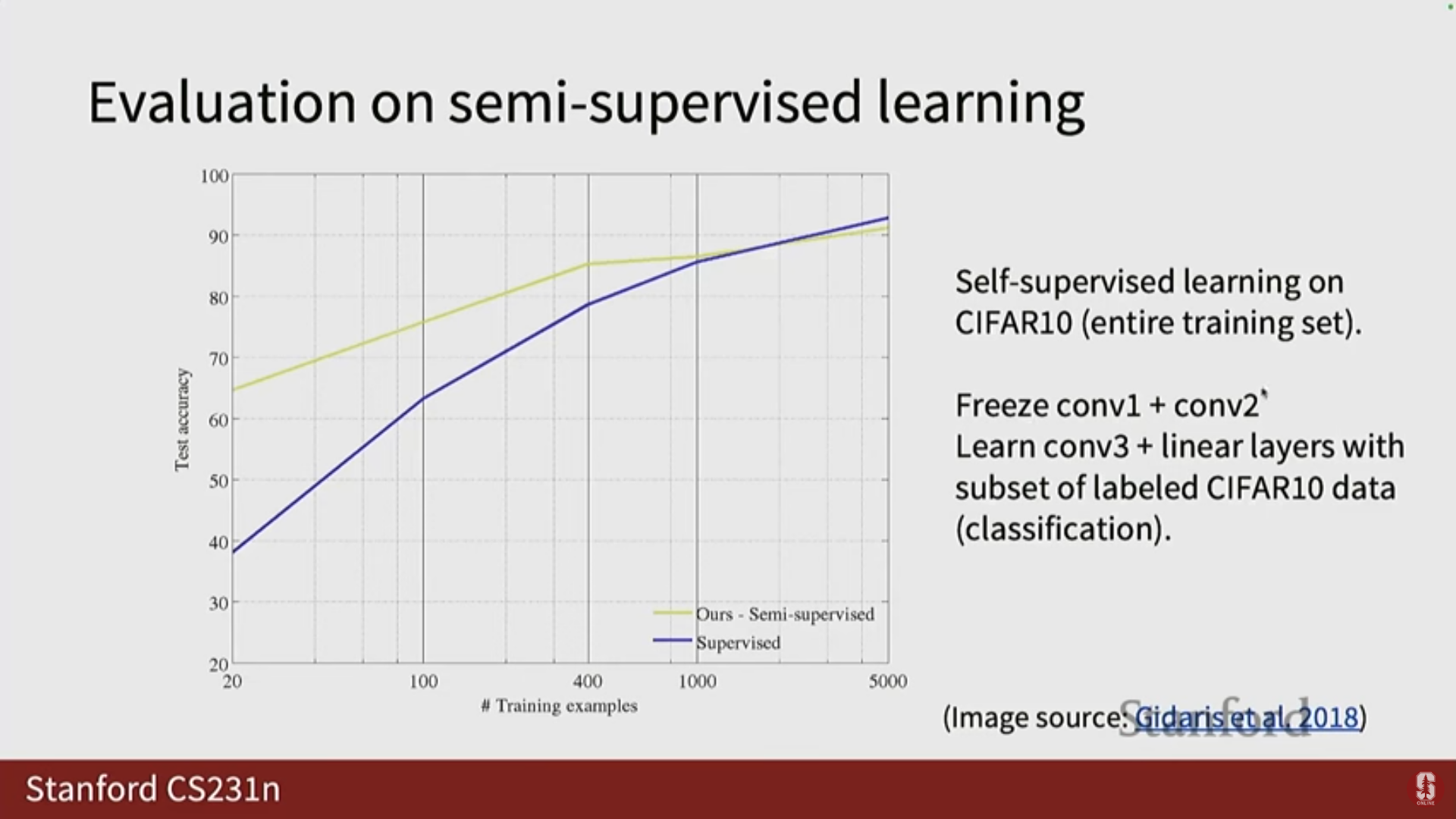
- 결과: CIFAR-10 데이터 세트에서 모델이 사전 훈련되면 초기 단계부터 좋은 정확도로 시작합니다.
- 특히 PASCAL VOC 2017 데이터 세트에서, 회전 기반 사전 훈련은 레이블이 있는 ImageNet으로 사전 훈련하는 것만큼은 아니지만, 랜덤 초기화와 비교했을 때 엄청난 차이를 보이며 뛰어난 성능을 보여주었습니다.
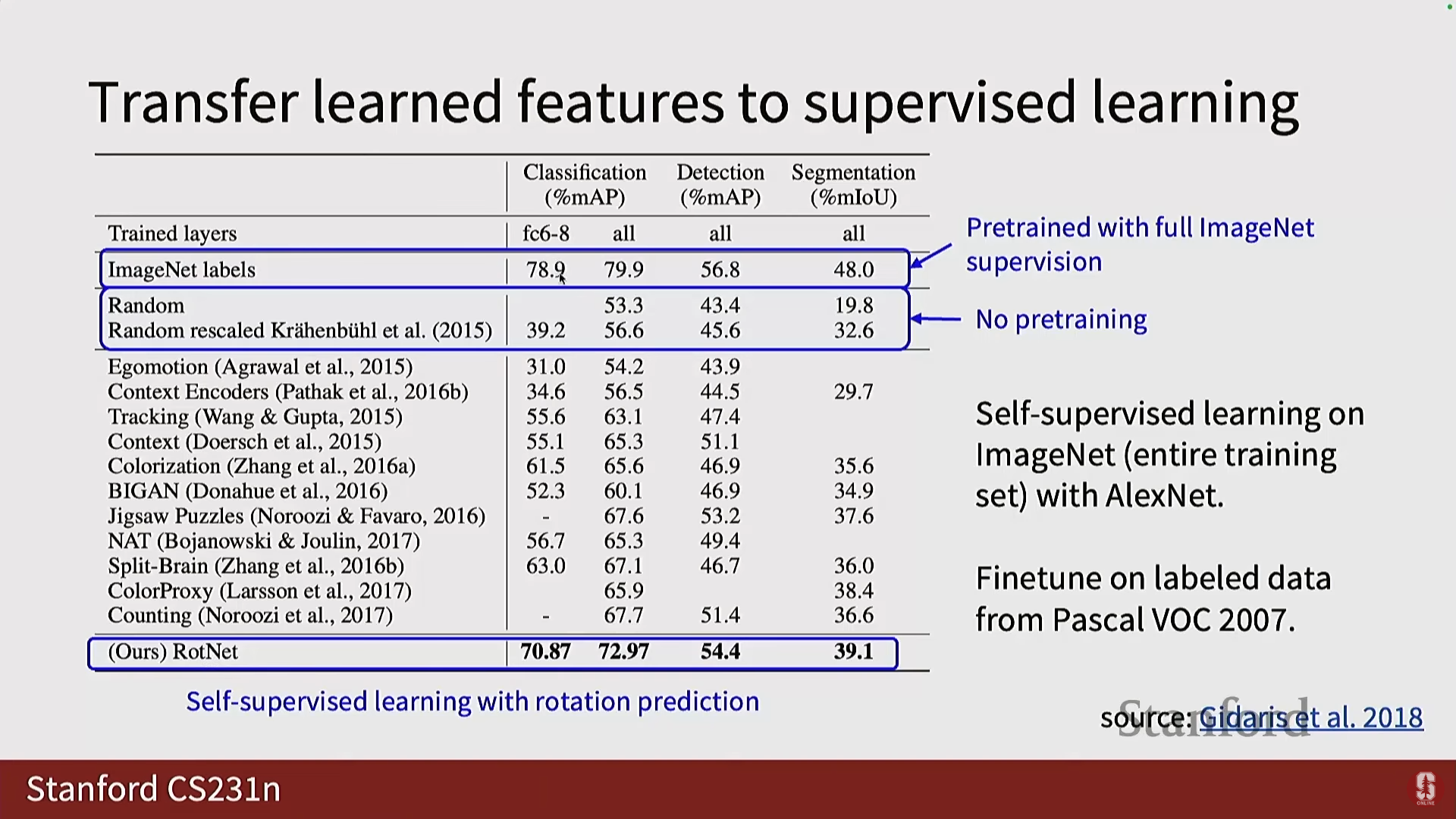
- 특히 PASCAL VOC 2017 데이터 세트에서, 회전 기반 사전 훈련은 레이블이 있는 ImageNet으로 사전 훈련하는 것만큼은 아니지만, 랜덤 초기화와 비교했을 때 엄청난 차이를 보이며 뛰어난 성능을 보여주었습니다.
- 특징 분석: 지도 학습 모델은 분류라는 단일 태스크에 집중하므로 종종 관심 영역(예: 눈)에 더 집중된 어텐션 맵을 갖는 반면, 자기 지도 학습은 다운스트림 태스크를 모르기 때문에 이미지에 대한 보다 전체론적인 이해(holistic understanding)를 포착하려 하므로 더 많은 영역을 포함합니다.

2) 직소 퍼즐 (Jigsaw Puzzle)
- 초기 버전: 3x3 그리드를 만들고 중앙 패치에 대한 나머지 8개 패치의 위치를 예측하는 8-way 분류 태스크였습니다.
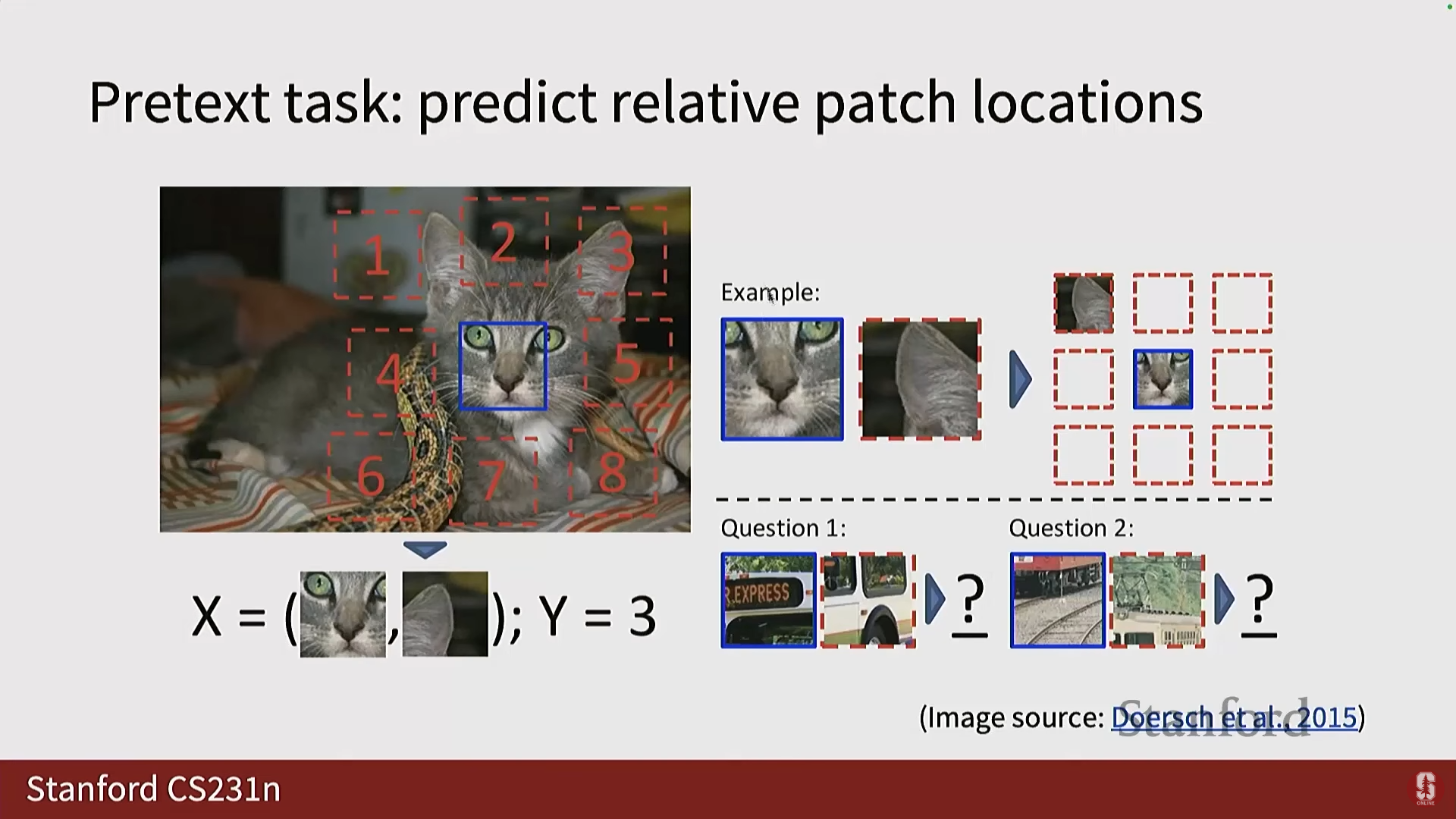
- Jigsaw Puzzle 프레임워크: 이미지를 3x3 그리드로 나누고 패치들을 무작위로 섞은 다음, 신경망이 올바른 순열(permutation)을 예측하도록 요구했습니다.
- 총 순열의 수는 (9 팩토리얼)로 매우 큰 숫자(300,000 이상)입니다.
- 심화 내용: 저자들은 이를 간단한 분류 문제로 풀기 위해, 모든 순열을 예측하는 대신, 변동성이 충분히 큰 64개의 그럴듯한(plausible) 순열만으로 제한하는 룩업 테이블을 생성했습니다.
- 따라서 이는 64개의 출력 클래스를 가진 분류 태스크가 됩니다.
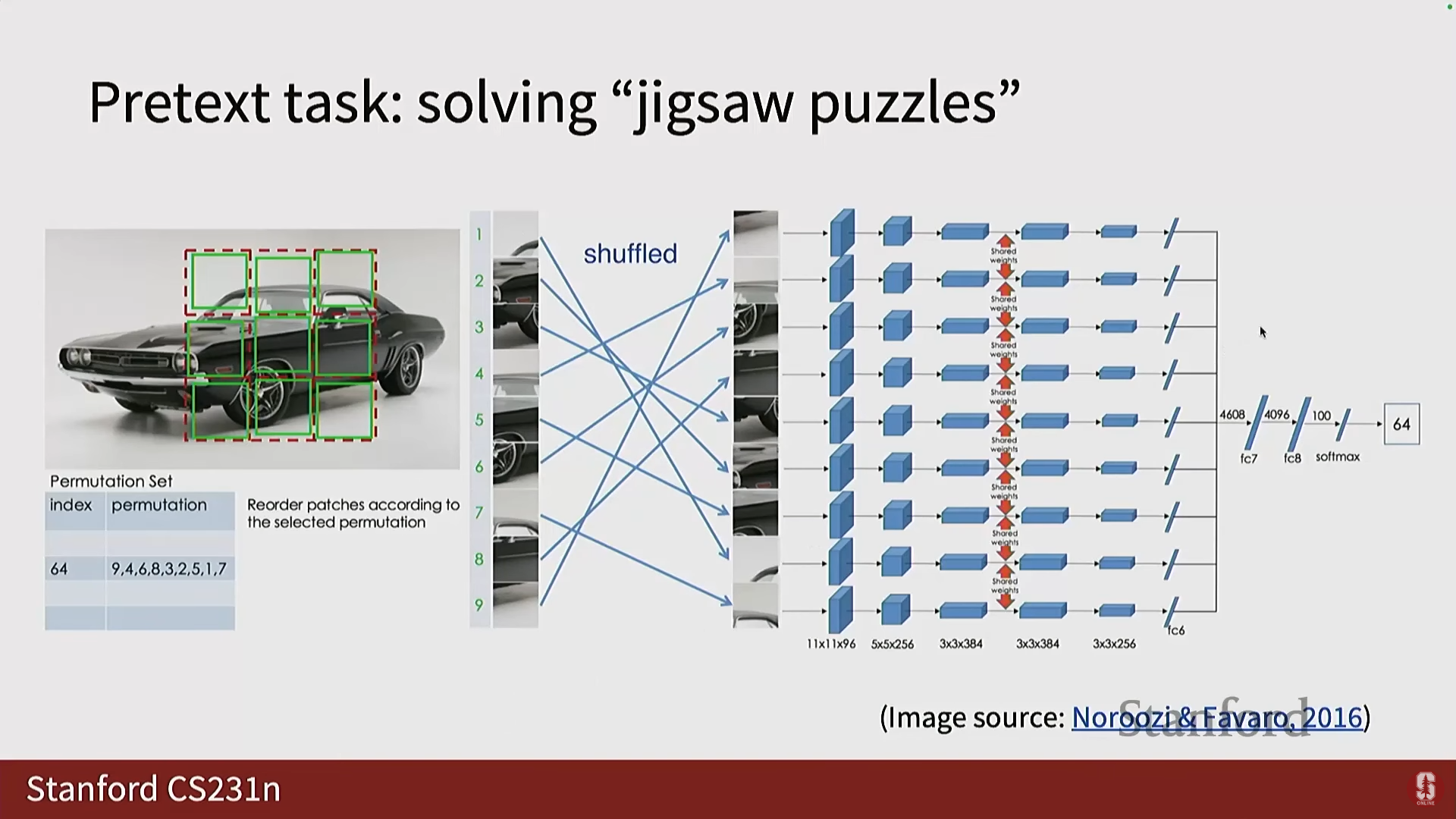
- 결과: 이 방법 또한 이전 모델보다 우수한 성능을 보여주었습니다 (2016년 발표).

3) 이미지 인페인팅 및 완성 (Image Inpainting/Completion)

- 목표: 이미지의 일부를 마스킹하고, 모델에게 마스킹된 부분을 복원하도록 요청합니다.
- 구현:
- 입력 이미지의 일부를 마스킹합니다.
- 인코더가 이를 특징 공간으로 변환합니다.
- 디코더가 누락된 부분을 디코딩합니다.
- 손실 함수는 디코더의 출력과 정답(Ground Truth) 간의 차이를 비교합니다.
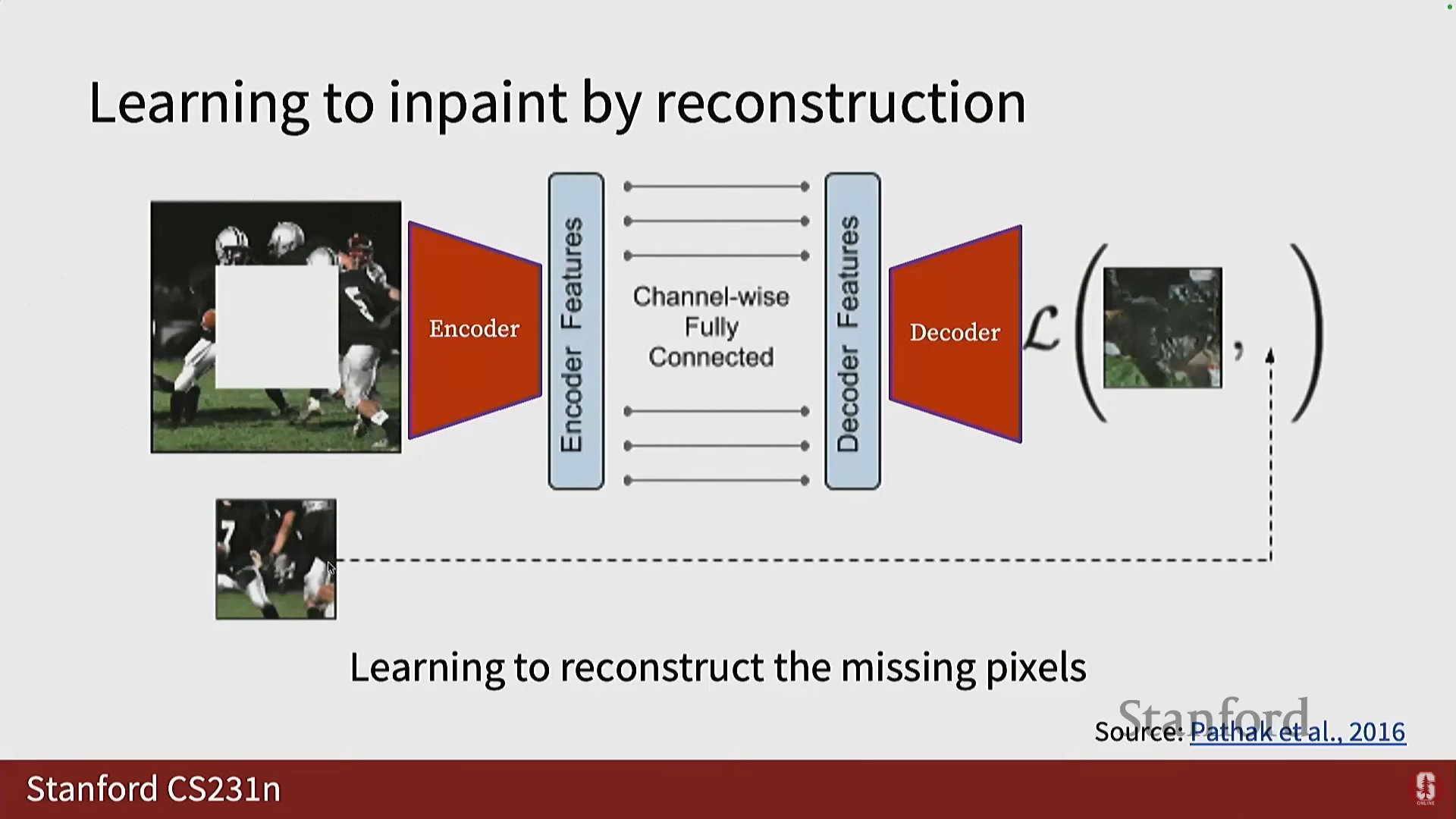
- 수학적 내용: 이는 누락된 픽셀을 재구성(Reconstruct)하는 것을 학습하는 것으로, 일종의 오토인코더(Autoencoder) 형태입니다.
- 재구성 손실 (Reconstruction Loss): 마스크 된 영역 에 대해서만 출력 과 원본 이미지 의 차이를 계산합니다.
(는 요소별 곱셈(element-wise multiplication)을 나타내며, 은 마스크 영역에 1, 나머지 영역에 0을 갖는 마스크입니다. 는 거리를 측정하는 데 사용되는 L2와 같은 놈(norm)입니다.)
- 재구성 손실 (Reconstruction Loss): 마스크 된 영역 에 대해서만 출력 과 원본 이미지 의 차이를 계산합니다.
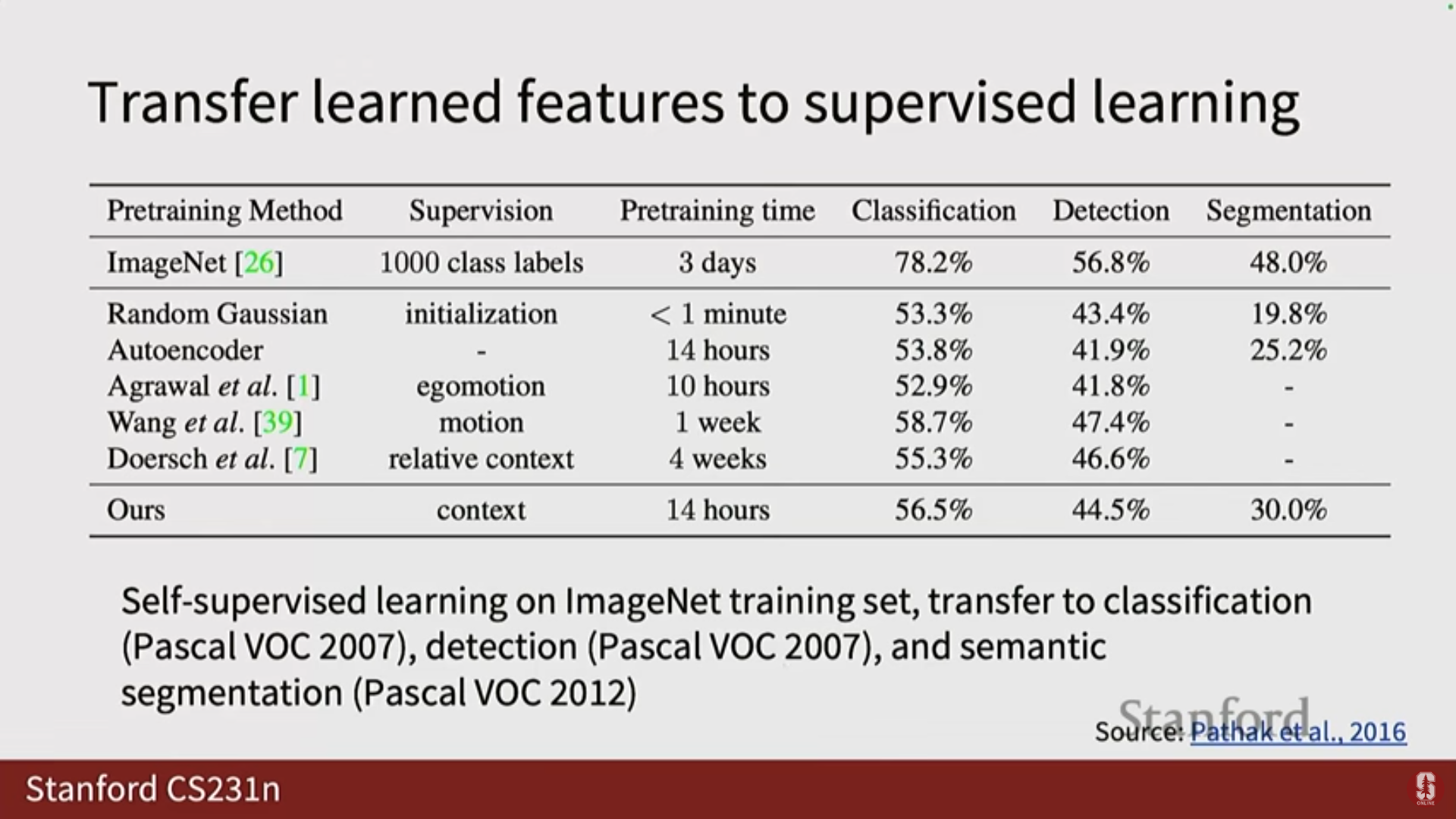
- 심화 내용 (Fuzzy Output 및 GAN): 초기 재구성 기반 프레임워크는 종종 흐릿하거나 부드러운(fuzzy or smooth) 결과물을 생성했습니다. 이 문제를 해결하기 위해, 해당 논문에서는 생성된 이미지가 실제처럼 보이도록 하는 적대적 목표 함수(Adversarial objective function)를 추가로 사용했습니다. (자세한 내용은 다음 강의인 생성 모델(Generative Models)에서 다룰 예정입니다).
- 활용: 이 재구성 프레임워크는 분류, 탐지 및 분할 작업에서도 추가적인 이점을 제공했습니다.

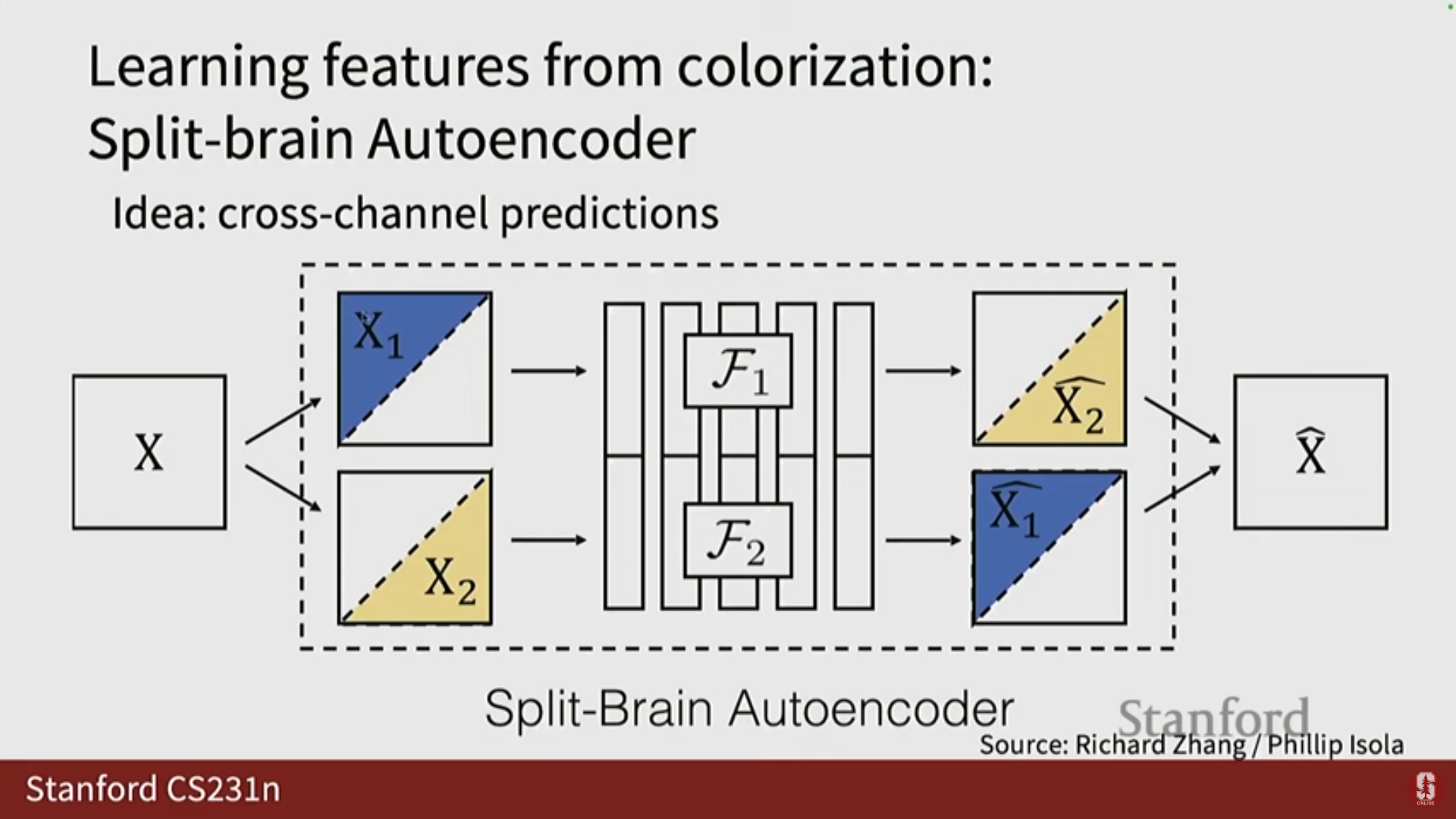
4) 이미지 색상화 (Image Coloring/Colorization)


- 색 공간: 컴퓨터 비전에서는 주로 RGB를 사용하지만, 밝기(lightness/illumination)와 색상을 분리하기 위해 Lab 색 공간이 사용됩니다.
- Lab 색 공간은 밝기 채널(L) 하나와 색상 채널(A, B) 두 개로 구성되며, 이 셋을 합치면 컬러 이미지를 얻습니다.
- 사전 작업: 밝기 채널(L)이 주어졌을 때, 색상 채널(A와 B)을 예측하는 것입니다. 이 역시 수동 주석이 필요 없습니다.
- Split-Brain Autoencoder: L 채널이 주어지면 A/B 채널을 예측하고, 반대로 A/B 채널이 주어지면 L 채널을 예측하는 두 개의 함수(신경망)를 훈련합니다.
- 결과를 병합하여 실제 이미지를 생성하고, L2 손실과 같은 거리 함수를 사용하여 네트워크를 훈련합니다.
- 일반화: 이 프레임워크는 색상 및 조명뿐만 아니라, RGB-D 센서(RGB 채널과 깊이(Depth) 채널)와 같은 데이터에도 적용하여, RGB 채널이 주어졌을 때 깊이를 예측하거나 그 반대로 예측하는 데 성공적으로 사용되었습니다.


- 심화 내용 (의미론적 이해): 색상화는 사전 훈련 외에도 그 자체로 유용했는데, 특히 요세미티 하프 돔(Half Dome) 이미지 색상화 결과에서 객체(돔, 나무, 다리)와 물속 반사(reflection) 간의 색상 일관성을 유지하는 능력을 보여주었습니다. 이는 모델이 대규모 데이터 훈련을 통해 반사 규칙을 암묵적으로 이해했음을 시사합니다.

5) 비디오 색상화 (Video Colorization)

- 목표: 비디오의 미래 프레임을 색상화하는 것입니다. 이 과정에서 모델은 픽셀과 객체를 추적하는 방법을 암묵적으로 학습할 것이라는 가설이 있습니다.
- 구현:
- 참조 프레임(Reference Frame)의 색상을 사용하여 입력 프레임을 색상화합니다.
- 입력 프레임의 각 픽셀에 대해 참조 프레임의 모든 픽셀과의 어텐션(Attention) 또는 유사도를 계산합니다.
- 이 어텐션 값에 기반하여 참조 프레임의 색상을 가중 평균하여 출력 색상을 얻습니다.

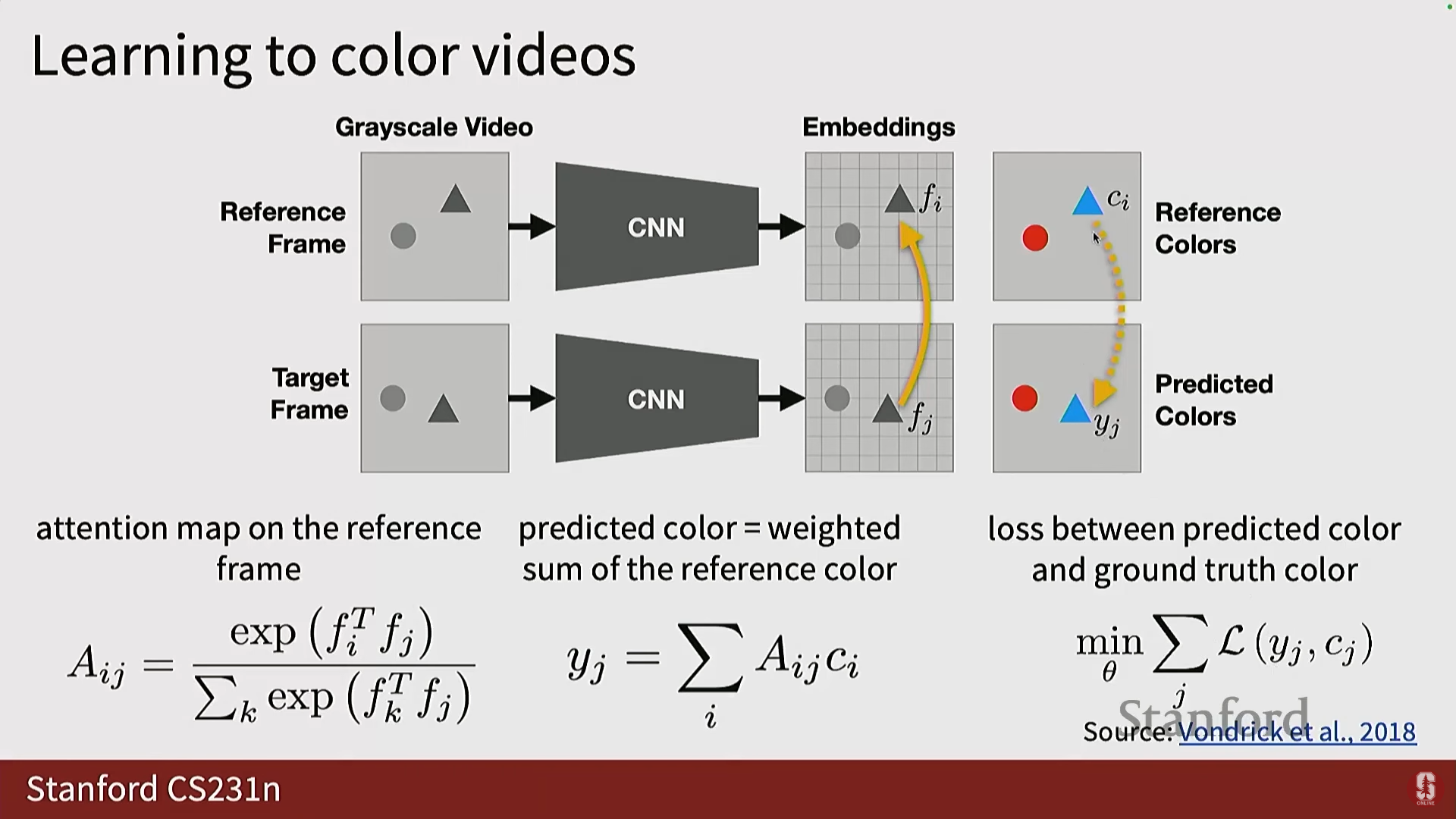
- 결과: 이 일관성 제약(consistency constraint) 덕분에 시간에 따른 색상 변화 없이 일관성 있는 색상화가 가능해집니다.
- 활용: 어텐션을 계산하는 과정 자체가 비디오 내에서 객체 추적이나 핵심 포인트 식별을 가능하게 합니다.


4. 마스크드 오토인코더 (Masked Autoencoders, MAE): 진보된 재구성 프레임워크

- 배경: MAE는 2021년에 발표된 재구성 기반 프레임워크로, 최근 대규모 데이터셋 사전 훈련에 널리 사용됩니다.
- 특징: 이전의 인페인팅과 달리 훨씬 더 공격적인 마스킹 비율(aggressive masking rates)을 사용합니다. 예를 들어, 75% 마스킹 비율을 사용합니다.
- 가설: 마스킹 비율이 높으면 예측 태스크가 매우 어려워지며, 이는 모델이 이미지로부터 의미 있는 특징을 학습해야만 재구성을 성공할 수 있음을 의미합니다.
- 높은 마스킹 비율은 또한 훈련 중에 동일한 이미지를 여러 번 재사용할 수 있게 하여 데이터를 대규모로 증강(augment)하는 효과를 낳습니다.
- 아키텍처: MAE는 Vision Transformer (ViT)를 기반으로 하며, 인코더와 디코더가 비대칭(asymmetric) 구조를 가집니다.
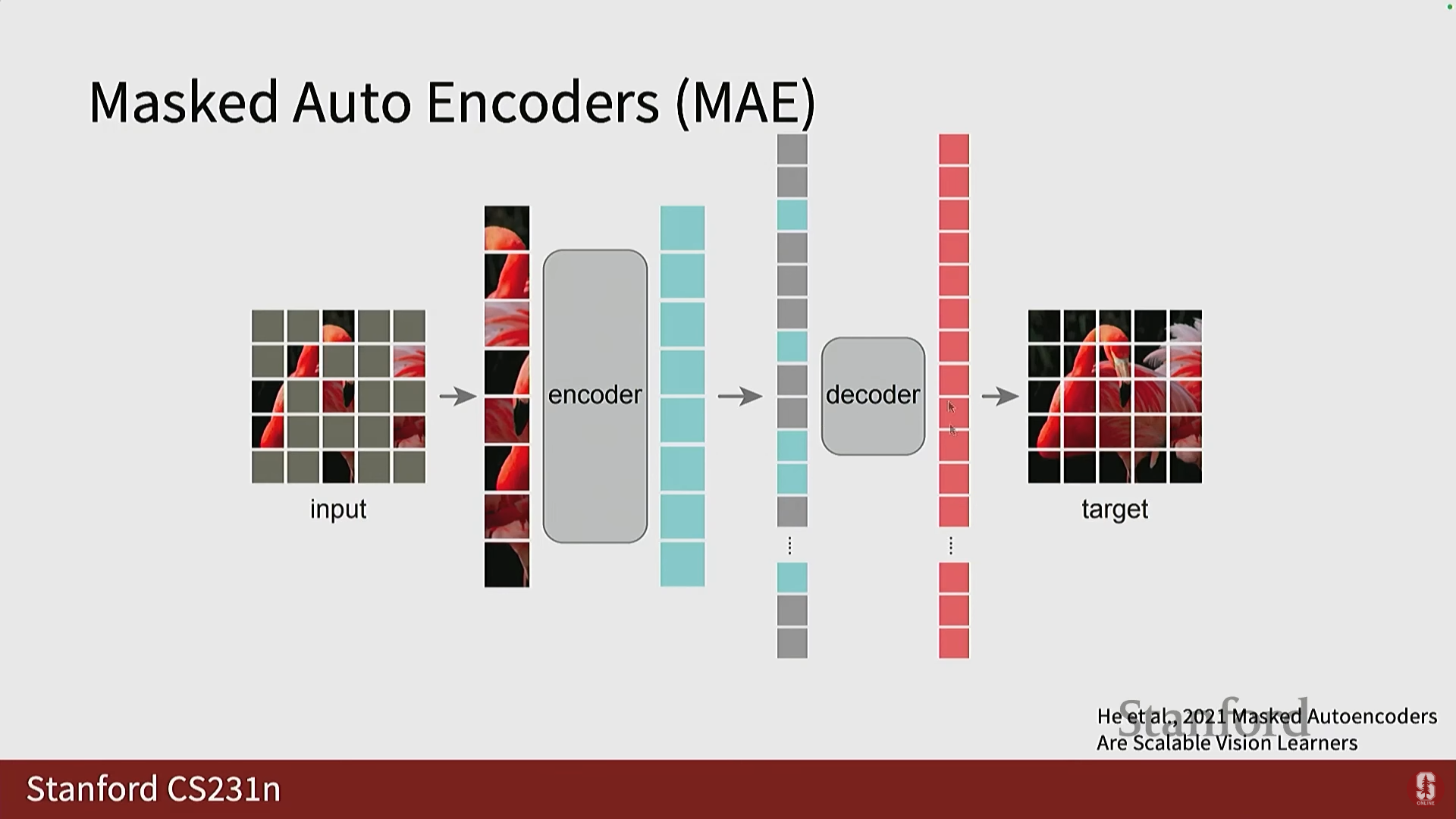

1) MAE 세부 구조
-
인코더 (Encoder):
- 입력 이미지는 패치로 분할됩니다.
- 75%의 패치가 마스킹됩니다 (균일 샘플링).
- 인코더는 마스킹되지 않은 25%의 패치만 입력으로 받습니다.
- 이 패치들은 선형 투영 후 위치 임베딩(positional embeddings)이 추가되며, 변환기(Transformer) 블록을 통과합니다. 인코더는 보통 매우 큽니다.

-
디코더 (Decoder):
- 인코더의 출력(존재하는 패치들의 임베딩)을 받습니다.
- 마스킹된 위치에는 공유 마스크 토큰(shared mask token)이라는 학습 가능한 파라미터가 삽입됩니다. 이는 일종의 평균 패치 표현으로 간주될 수 있습니다.
- 디코더는 이 전체 토큰 시퀀스를 받아 완전한 이미지 패치 값으로 변환합니다.
- 디코더는 인코더보다 작아도 됩니다.

-
손실 함수: 재구성 손실은 평균 제곱 오차 (MSE) 기반이며, 이전 인페인팅과 유사하게 마스킹된 패치에 대해서만 계산됩니다.
-
(여기서 은 마스크된 패치의 집합이며, 는 실제 픽셀 값, 는 재구성된 픽셀 값입니다.)

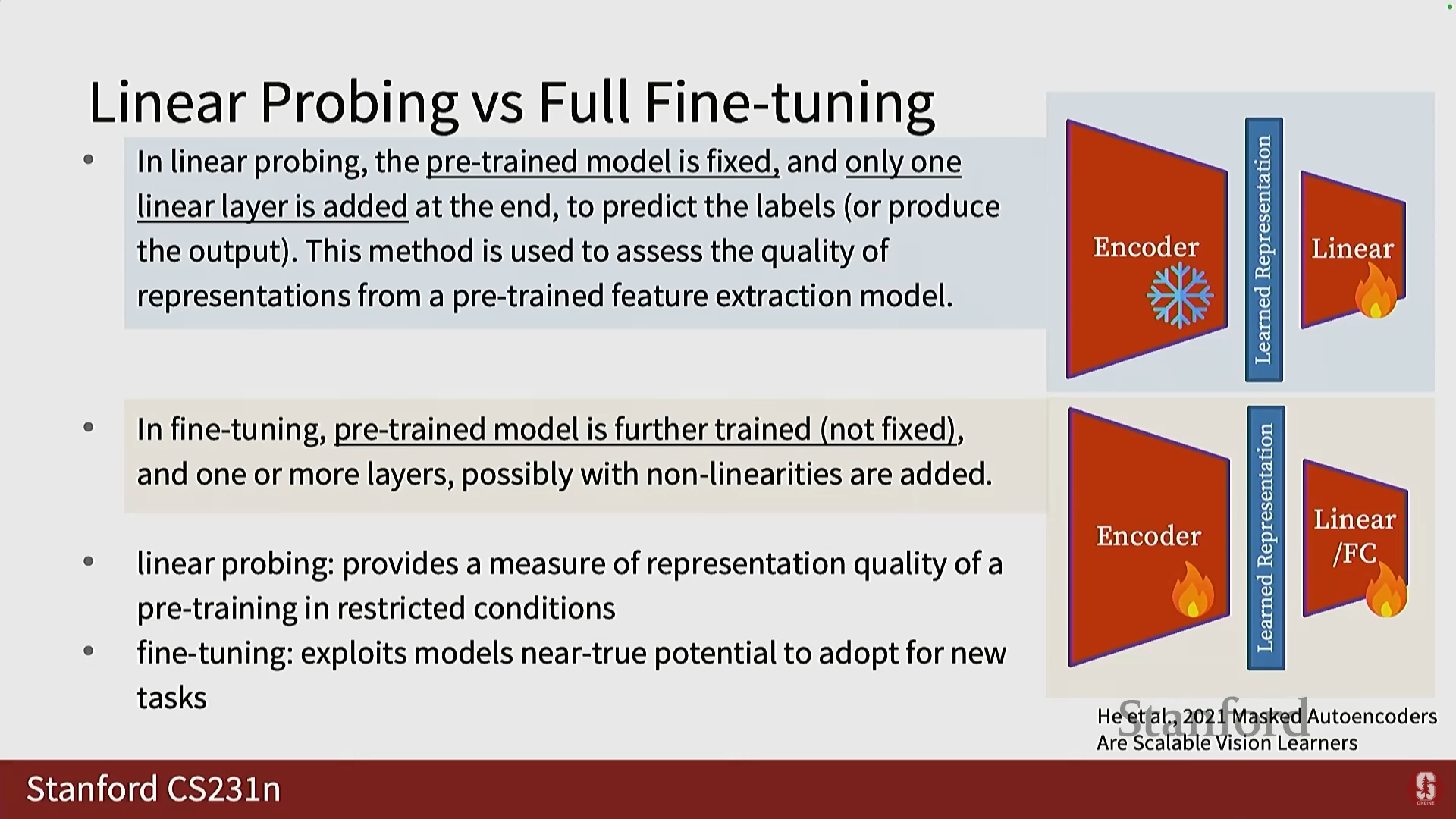
2) MAE 활용 전략
- 선형 프로빙 (Linear Probing): 인코더를 동결(frozen)시키고, 학습된 표현을 사용하여 최종 태스크를 위한 선형 함수만 훈련합니다. 이는 표현 품질(representation quality)을 측정하는 지표를 제공합니다.
- 전체 파인튜닝 (Full Fine-Tuning): 사전 훈련된 인코더의 전부 또는 일부 변환기 블록을 다운스트림 태스크에 맞게 미세 조정합니다. 이는 모델의 잠재력을 최대한 활용하여 새로운 태스크에 적응시키는 방법입니다.
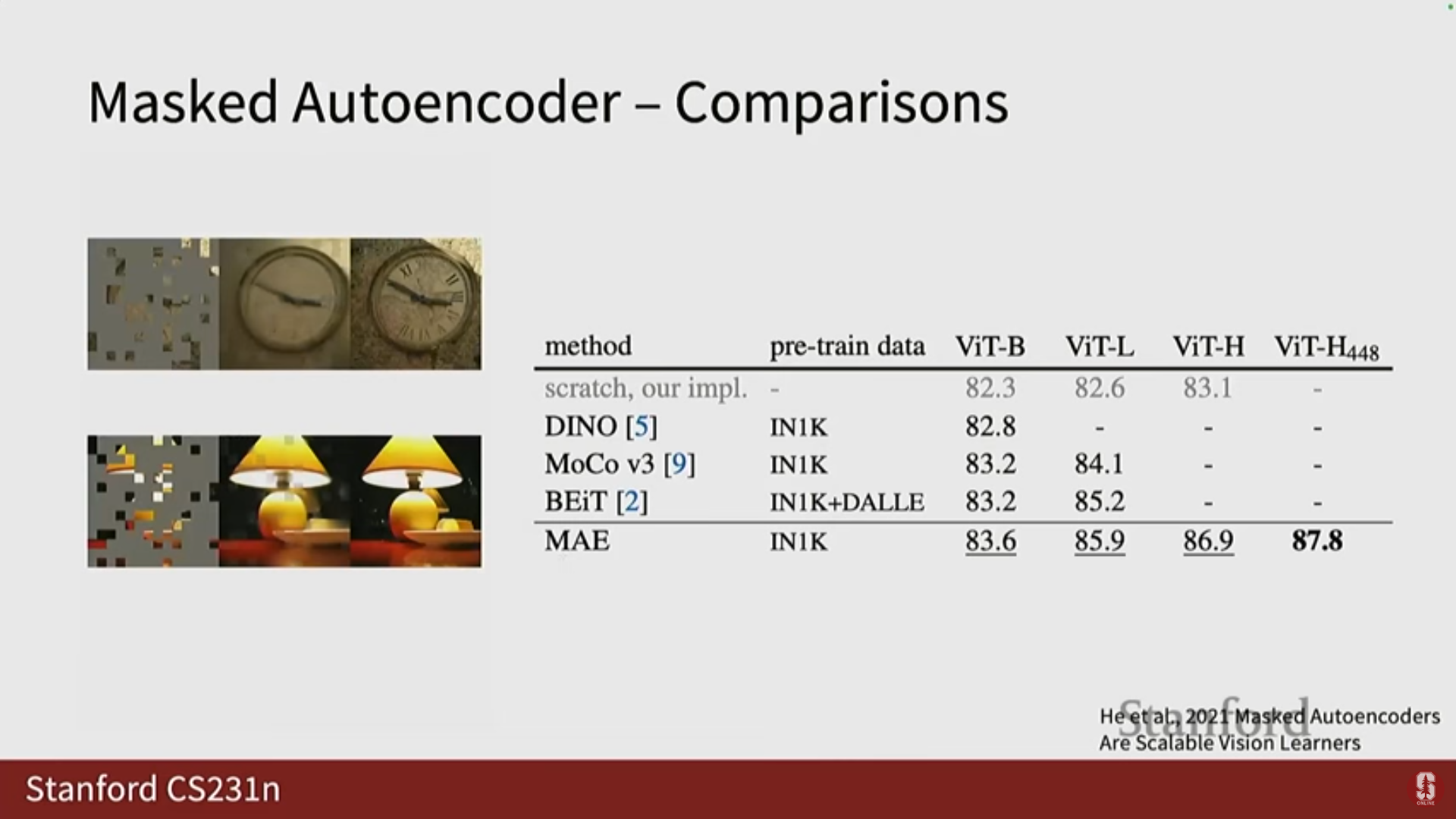
3) 심화 내용: MAE 디자인 선택
- 마스킹 비율: 실험 결과 75% 마스킹 비율이 가장 높은 정확도를 제공하는 것으로 나타났습니다.
- 마스크 샘플링 방법: 랜덤 마스킹이 블록(grid) 형태의 마스킹보다 더 나은 선택임이 입증되었습니다.
- 성능: MAE는 당시의 최첨단 대비 학습(Contrastive Learning) 방법론이었던 Dino나 MoCo V3에 비해 더 나은 성능을 보여주었습니다.


5. 대비 학습 (Contrastive Learning)
1) 기본 원리

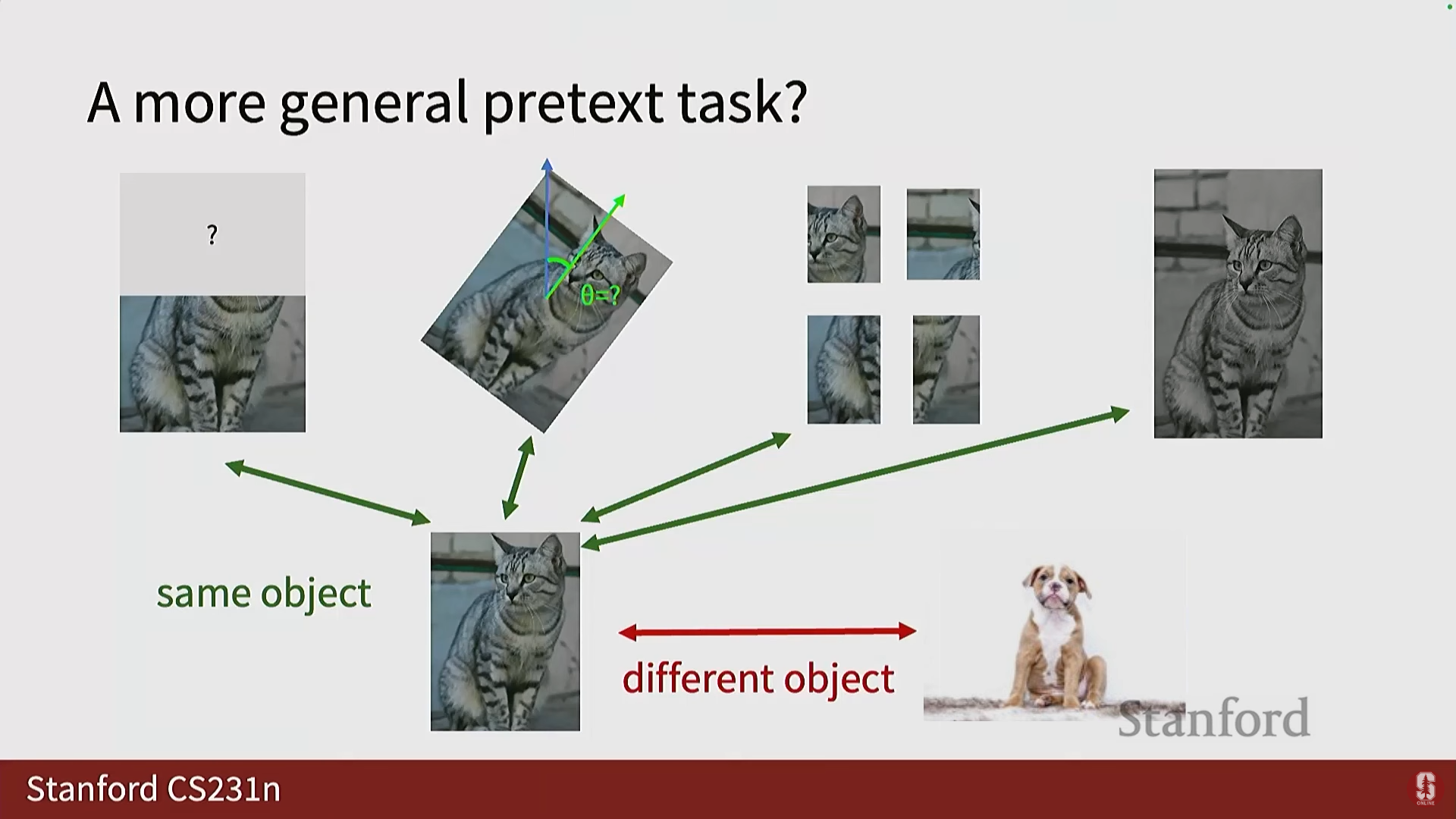
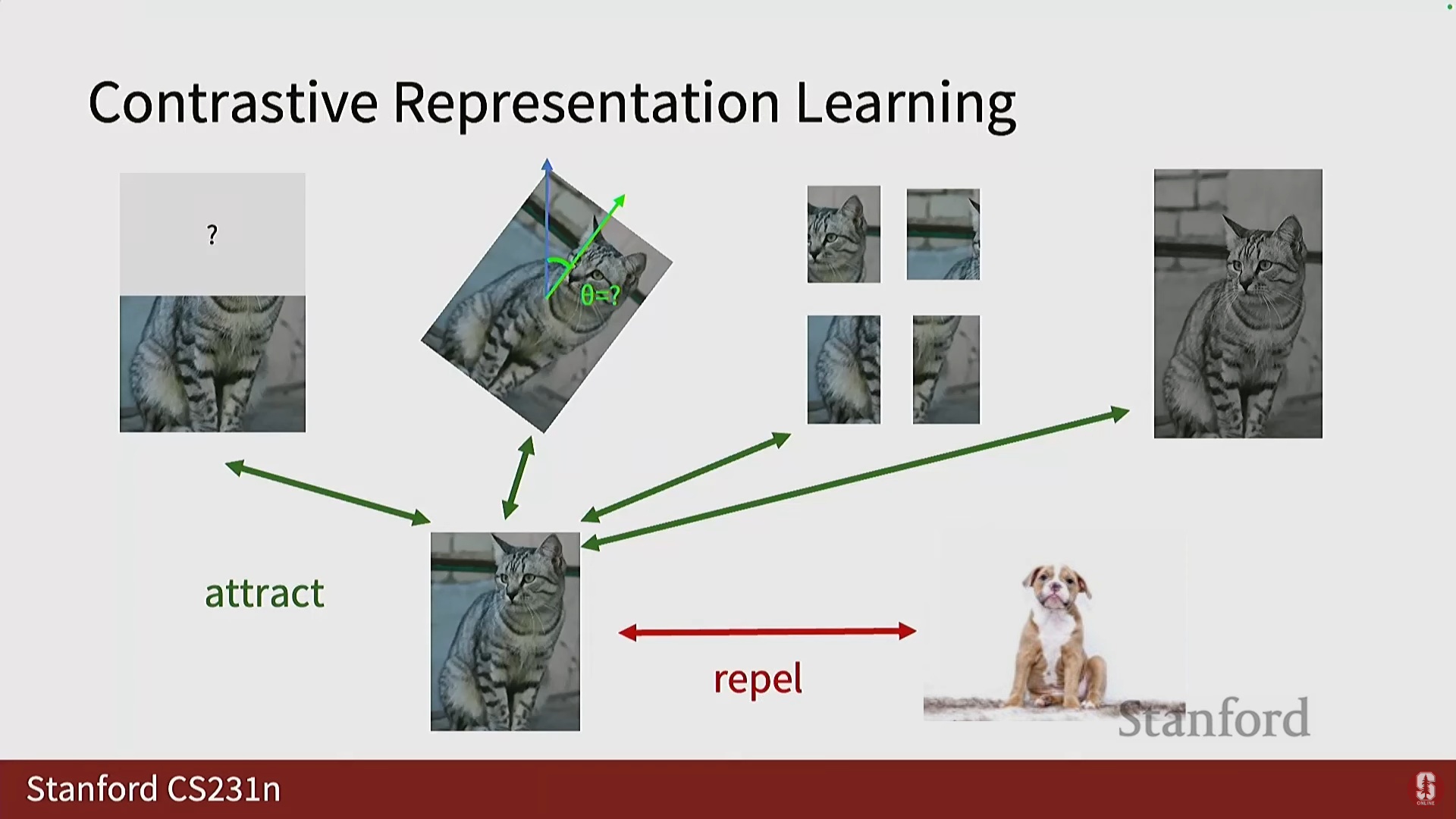
- 개념: 같은 객체에 속하는 변형된 표현들은 잠재 공간에서 서로 끌어당기고(Attract), 다른 객체에 속하는 표현들은 서로 밀어내도록(Repel) 모델을 정규화하는 태스크입니다.
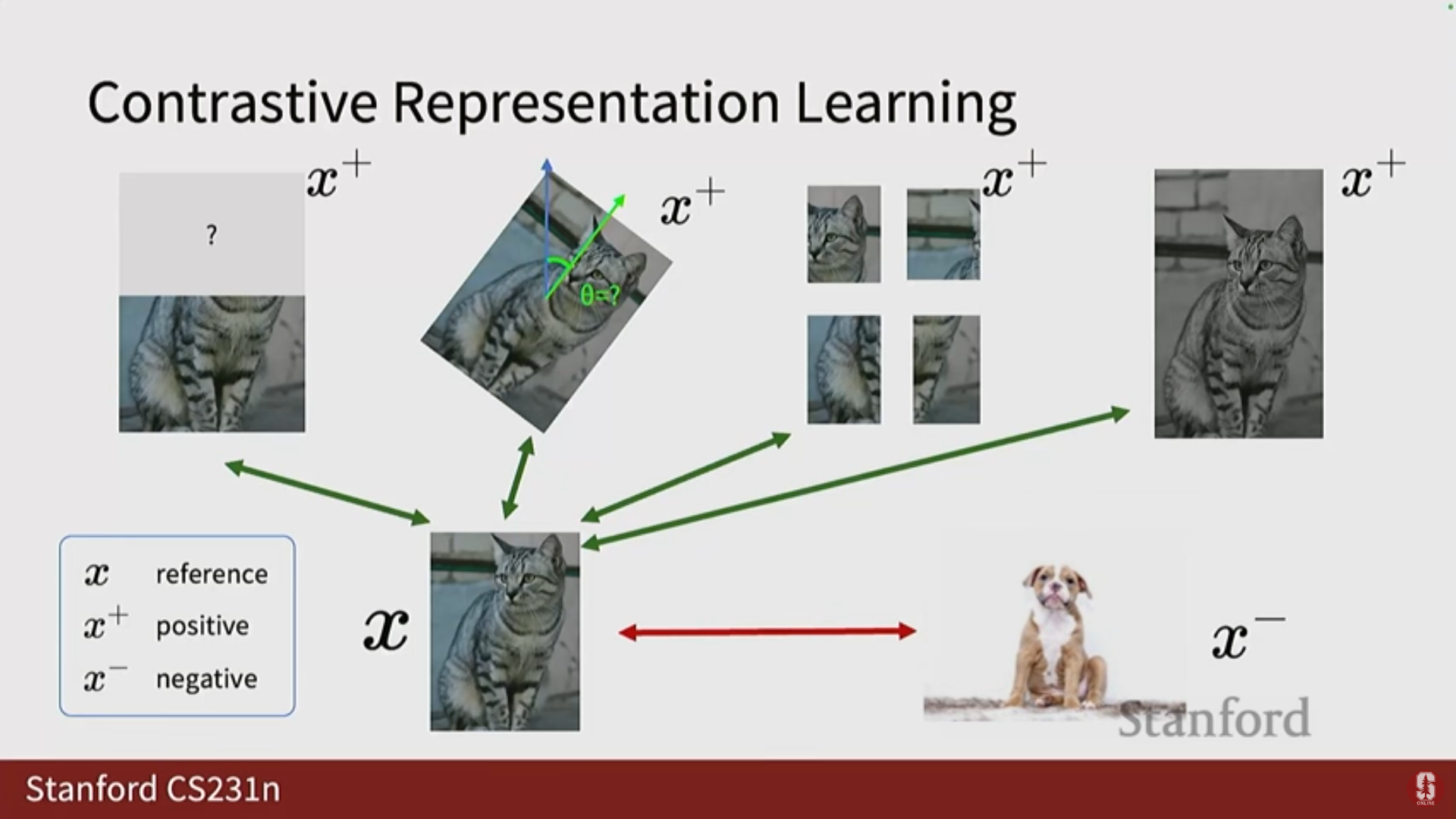
- 샘플 정의:
- 참조 이미지 ().
- 긍정 샘플 (): 참조 이미지의 변형(Transformation) 버전.
- 부정 샘플 (): 데이터 세트 또는 배치(Batch) 내의 다른 객체들.
- 목표: 참조 이미지의 특징과 긍정 샘플의 특징 간의 점수 가 참조 이미지와 부정 샘플 간의 점수 보다 크도록 만드는 것입니다.
2) InfoNCE 손실 (InfoNCE Loss)

- 이러한 '끌어당기기/밀어내기' 목표를 달성하기 위해 InfoNCE (Information Noise Contrastive Estimation) 손실 함수를 사용합니다.
- 수학적 내용: InfoNCE는 다중 클래스 분류에서 사용되는 교차 엔트로피(Cross-Entropy) 손실 함수와 매우 유사합니다. 이는 긍정 쌍에 대한 점수를 최대화하고 부정 쌍에 대한 점수를 최소화하려는 목표를 반영합니다.
- InfoNCE 공식의 구조:
(분자는 긍정 쌍의 점수를, 분모는 긍정 쌍과 모든 부정 쌍의 점수를 포함합니다.) - 상호 정보 (Mutual Information, MI): 이 손실 함수는 상호 정보의 하한(lower bound on mutual information)을 측정한다는 이론적 배경을 가집니다.
- 상호 정보는 두 이미지 (와 ) 사이의 종속성(dependencies) 또는 공유 정보(shared information)를 측정합니다.
- InfoNCE 손실의 음수()가 상호 정보의 하한이므로, InfoNCE를 최소화하는 것은 와 간의 상호 정보를 최대화하는 것을 의미합니다. 이는 원하는 목표입니다.
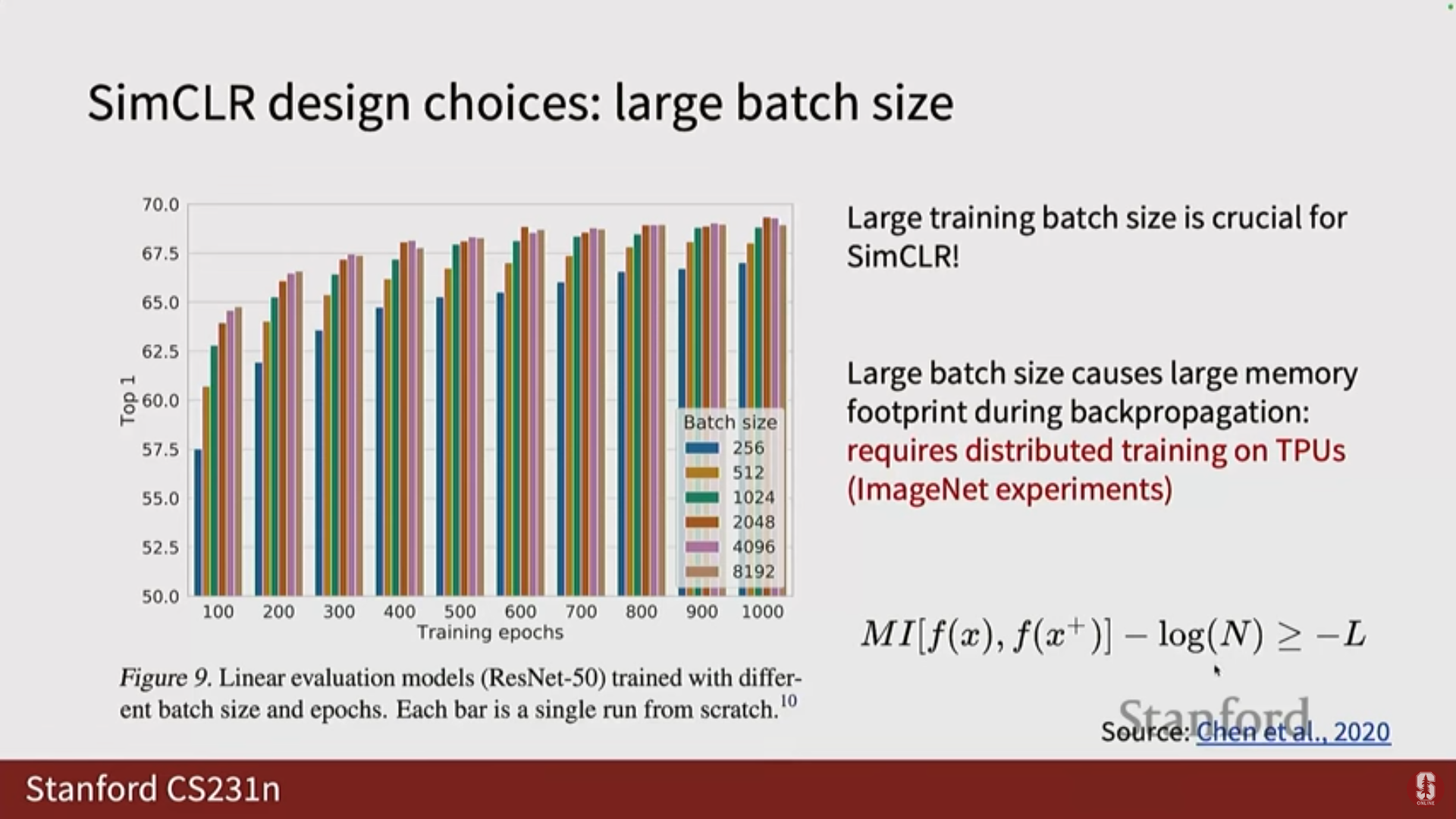
- 대규모 배치: InfoNCE 논문은 부정 샘플의 수가 많을수록 경계(bound)가 더 엄격해진다고 제안합니다. 따라서 대비 학습은 매우 큰 배치 크기(huge batch sizes)를 필요로 합니다.


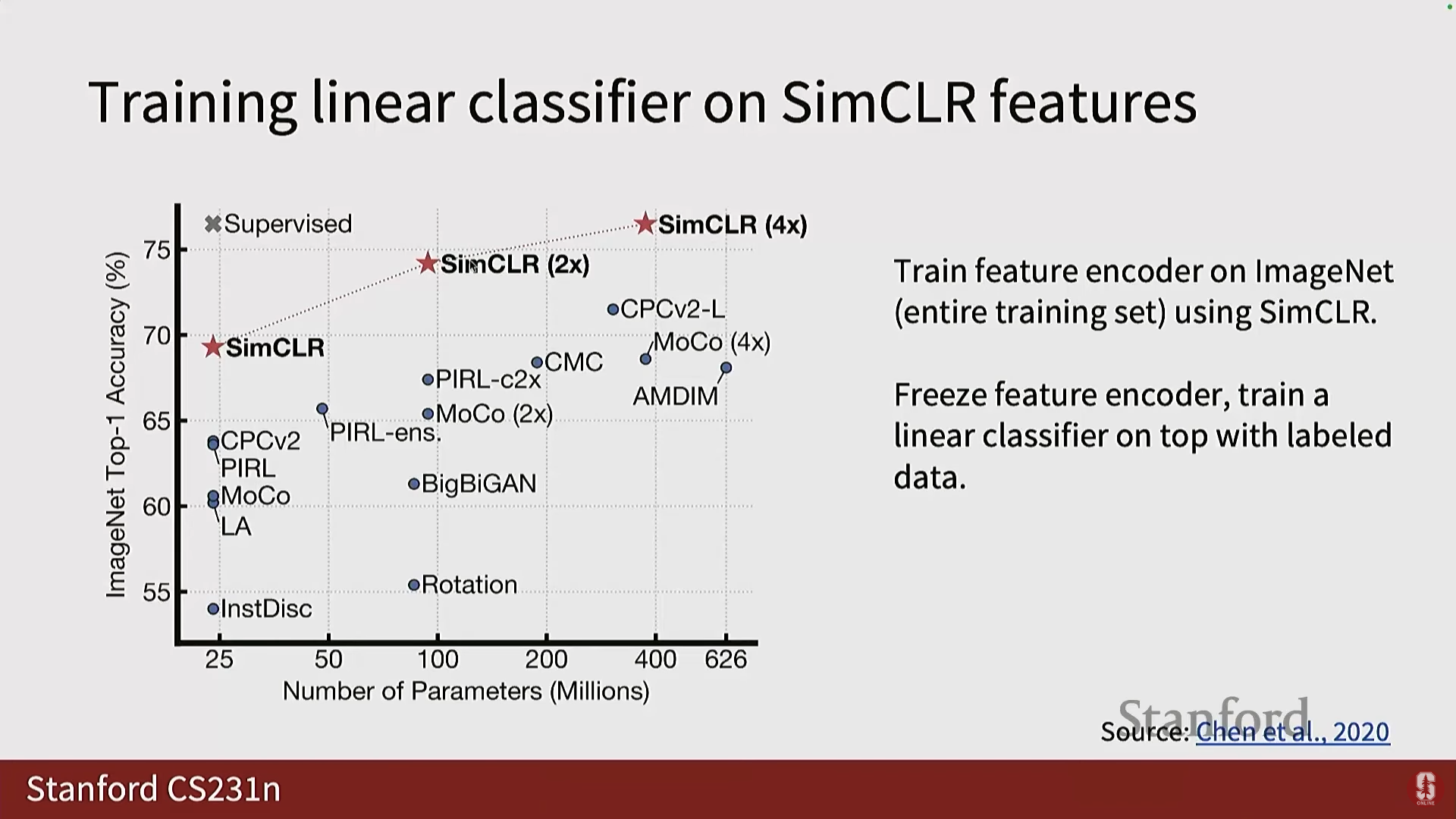
3) SimCLR (A Simple Framework for Contrastive Learning)

- 구현: 각 이미지에 대해 두 가지 변형(Transformation)을 생성하고, 이를 인코더를 통과시켜 표현 공간에 투영합니다.
- 미니 배치 내에서, 각 이미지의 변형된 버전은 긍정 샘플이고, 배치 내의 나머지 모든 샘플은 부정 샘플이 됩니다.
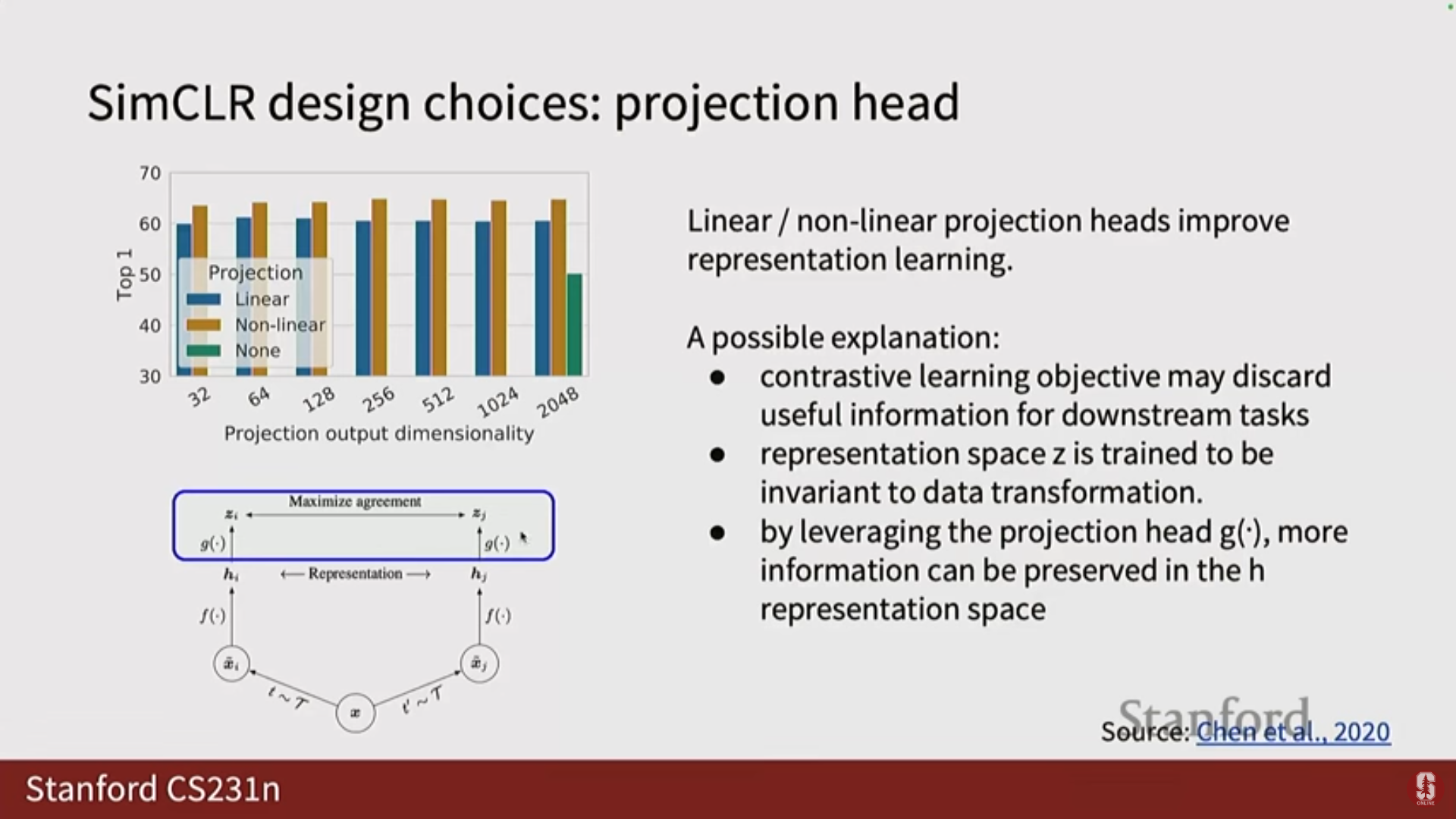
- 핵심 디자인 선택 (투영 헤드): SimCLR는 인코더의 출력()을 사용하지 않고, 선형 또는 비선형 투영 헤드(Projection Head)를 사용하여 새로운 특징 공간()으로 투영한 뒤 InfoNCE 손실을 계산합니다.
- 심화 내용: 이는 대비 학습 과정에서 발생하는 정보 손실을 방지하기 위함입니다. 대비 학습 목표는 대비에 도움이 되지 않는 추가 정보를 잃게 만들 수 있는데, 를 보존하고 공간에서만 손실을 계산하여 정보 손실을 막습니다.
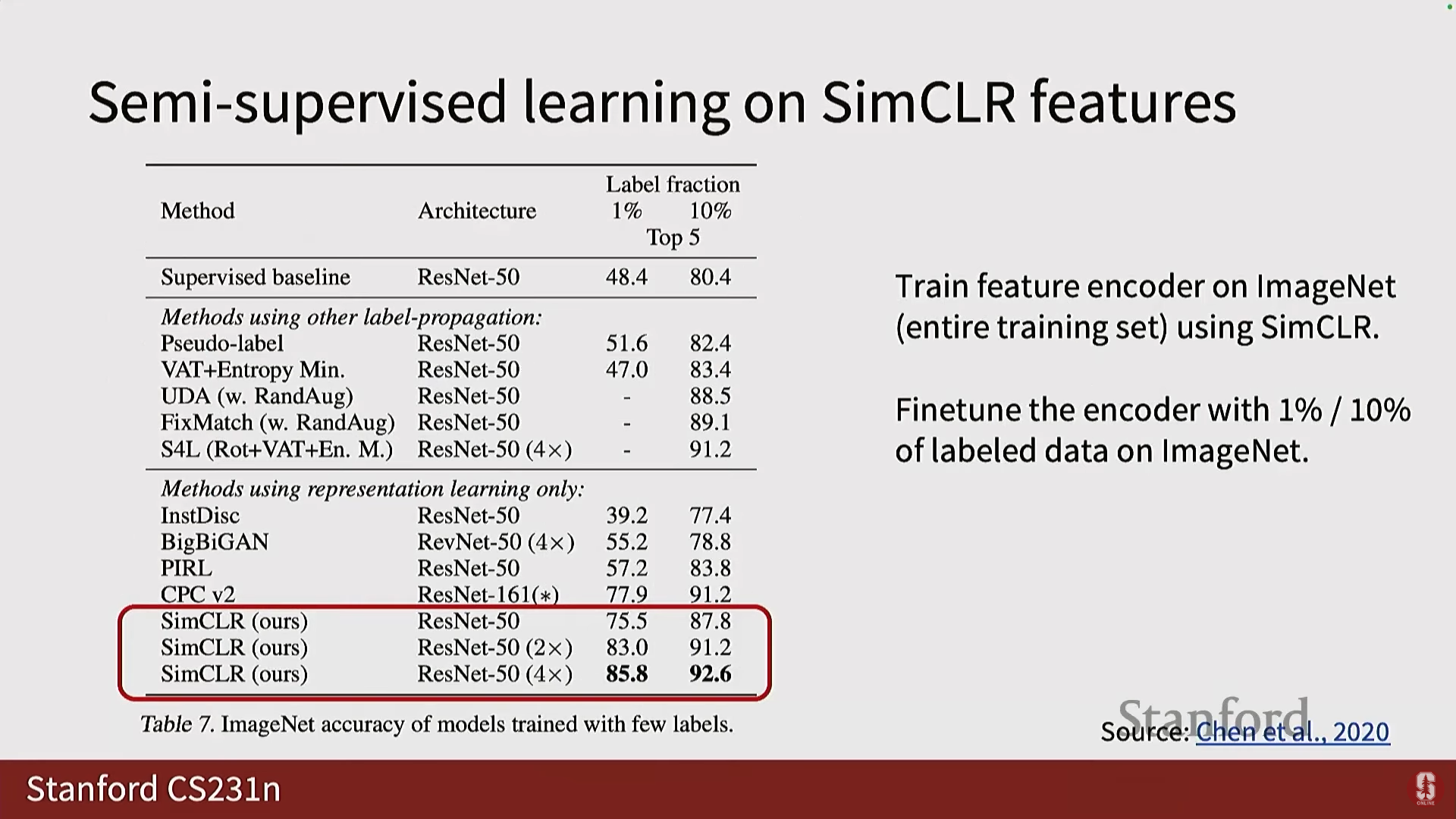
- 성능: SimCLR는 레이블을 사용하지 않고도 선형 분류기를 훈련했을 때, 이전 작업들을 능가했으며 지도 학습(fully supervised) 프레임워크와 비교 가능한(comparable) 결과를 생성했습니다.


4) MoCo (Momentum Contrast)
- 배경: SimCLR가 큰 배치 크기를 요구하는 문제(메모리 제약)를 해결하기 위해 제안되었습니다.
- 구현: MoCo는 배치 내의 부정 샘플에만 의존하는 대신, 시간 경과에 따라 부정 샘플의 히스토리를 저장하는 대기열(Queue)을 사용합니다.
- 구조: 대기열에 있는 샘플들은 현재 배치에 없으므로 역전파(Backpropagation)가 불가능합니다. 따라서 MoCo는 인코더를 두 개로 분리합니다:
- 쿼리 인코더 (Query Encoder): 긍정 샘플(Query)에 대해 훈련됩니다.
- 키 인코더 (Key Encoder): 부정 샘플(Key)을 담당합니다. 훈련 중에는 직접 역전파되지 않고, 모멘텀()을 사용하여 쿼리 인코더로부터 가중치를 업데이트합니다.
- 후속 버전: MoCo 버전 2(MoCo V2)는 SimCLR의 비선형 투영 헤드와 데이터 증강 기법을 도입하여 성능을 크게 향상시켰습니다.
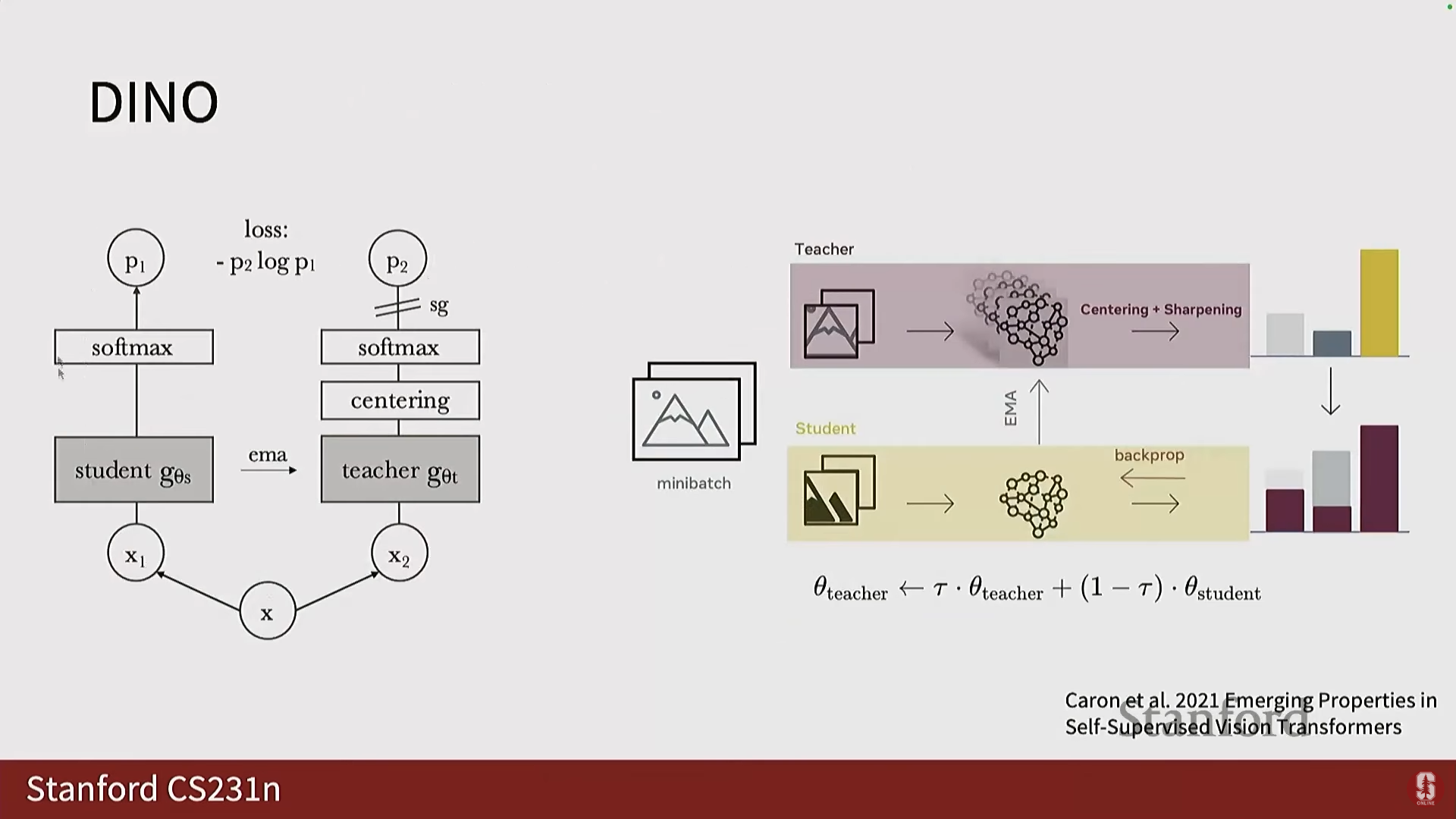
- Dino: MoCo와 유사한 아키텍처를 가지지만, 학생(Student) 및 교사(Teacher) 네트워크를 사용하여 대비 학습으로 분류되지는 않는, 널리 사용되는 또 다른 프레임워크입니다.



6. 질문 및 답변 (Q&A)
Q1. 사전 작업은 어떻게 인코더를 훈련시키나요?
- A: 저희가 제시하고 정의한 모든 사전 작업들은 디코딩, 분류, 회귀 등을 통해 출력을 생성하려고 합니다.
- 만약 원본 이미지가 ImageNet이나 인터넷에서 가져온 자연 이미지라면, 사전 작업을 통해 그 유형의 이미지로부터 특징을 추출할 수 있는 인코더를 학습하게 됩니다.
- 이후 디코더(또는 사전 작업 특정 FC 계층)를 제거하고 다운스트림 분류기를 추가하면, 이 분류기 부분만 훈련하면 됩니다. 왜냐하면 인코더는 이미 사전 훈련 태스크를 통해 훈련되었기 때문입니다.
Q2. 인코더 훈련을 위한 레이블이 디코더에서 나오나요?
- A: 네, 그렇습니다. 이것이 우리가 사전 작업을 정의하는 이유입니다. 우리는 일종의 레이블이나 출력이 필요하며, 이 출력(예: 회전 각도, 색상 채널)을 기반으로 전체 네트워크를 훈련시키고, 그 과정에서 인코더도 훈련됩니다.
Q3. 인코더와 디코더는 하나의 큰 신경망인가요, 아니면 다른 네트워크인가요?
- A: 논문이나 작업에 따라 완전히 다릅니다.
- 예를 들어 회전 각도 예측의 경우, 디코더는 단순히 FC 계층일 뿐이며 이는 하나의 전체 네트워크로 간주될 수 있습니다.
- 오토인코딩 프레임워크(이미지를 인코딩하고 다른 이미지를 디코딩하는 경우)에서는 종종 두 개의 신경망(인코더와 디코더)이 엔드투엔드(end-to-end)로 훈련됩니다.
- 마스크드 오토인코더(MAE)의 경우처럼, 인코더와 디코더 사이에 대칭성(symmetry)이 전혀 없는 두 개의 다른 프레임워크일 수도 있습니다. 이는 태스크와 사전 작업에 매우 의존적입니다.
Q4. (회전 예측에 대해) 이러한 단순한 태스크(90도 예측)가 모든 것을 해결할 수 있나요?
- A: 이 방법들은 자기 지도 학습의 초기 방법론이었기 때문에 모든 것을 해결할 수는 없습니다.
- 하지만 핵심 가설은, 모델이 "이것이 90도 회전되었다"고 말할 수 있다면, 암묵적으로 올바른 방향과 오리엔테이션을 이해하고 있음을 의미하며, 이는 회전되지 않은 이미지에서 객체를 인식하는 데 도움이 될 것이라는 것입니다.
Q5. 직소 퍼즐에서 왜 64개의 순열을 사용했나요?
- A: 총 순열은 9! (30만 이상)로 매우 큰 숫자이며, 이 모든 것을 예측하도록 하는 것은 의미가 없습니다.
- 저자들은 순열들 중 충분한 변동성(enough variation)을 가진 일부만을 선택하기로 결정했습니다. 많은 순열은 단지 하나의 패치만 바뀌는 것과 같이 유사하기 때문입니다.
- 64라는 숫자는 임의적인(arbitrary) 선택에 가깝지만, 저자들이 분류 문제로 해결하기 위해 가장 큰 차이를 보이는 순열 64개를 선택한 것입니다.
Q6. Split-Brain Autoencoder에서 모델이 다른 채널을 예측하는 방법을 어떻게 아나요?
- A: 이는 지도 학습에서 모델이 레이블을 예측하기 위해 어떤 특징을 추출해야 하는지 아는 것과 같은 원리입니다.
- 우리가 클래스 예측 대신 픽셀의 색상(다른 채널)을 예측하도록 태스크를 정의했을 뿐입니다.
- 데이터에는 이미 다른 채널의 실제 값(정답)이 존재합니다. 따라서 손실 함수를 계산하고 역전파하여 네트워크를 훈련시킬 수 있습니다.
Q7. MAE에서 디코더는 어떻게 마스킹된 패치를 입력으로 받나요?
- A: MAE는 ViT 변환기 스타일의 프레임워크입니다.
- 인코더는 마스킹되지 않은 입력 패치들을 토큰으로 변환합니다.
- 마스킹된 패치들을 위해서는 공유 마스크 토큰(shared mask token)이라는 학습 가능한 매개변수가 훈련됩니다. 이는 일종의 평균 토큰과 유사하다고 해석될 수 있습니다.
- 이 학습된 마스크 토큰이 누락된 위치에 삽입되어 긴 시퀀스를 형성하고, 디코더(또 다른 변환기 프레임워크)는 이 긴 토큰 시퀀스를 입력받아 출력 픽셀 값으로 투영합니다.

너무 잘 보고 있습니다!
이제 AI 공부를 처음 시작하게 됐는데 CS231n 강의를 정말 의미없이 흘리게 되는 것 같은 느낌이 들어서 혹시 해당 수업 정리를 어떻게 하시는지 여쭤봐도 괜찮을까요?
강의를 다 듣고 복기하면서 정리하시는지, 강의를 들으며 정리하는지 알고 싶습니다.