1. 멀티모달 파운데이션 모델 (Multimodal Foundation Models)
1. 개요 및 파운데이션 모델로의 전환
- 기존의 딥러닝 강의는 개별 태스크를 위한 개별 모델 구축에 중점을 두었습니다.
- 이 과정은 데이터셋 수집(훈련 및 테스트 세트), 특정 모델 훈련(예: 이미지 분류, 이미지 캡셔닝 모델), 그리고 테스트 세트에서의 평가 단계를 따릅니다.
- 최근 몇 년간 분야의 변화는 개별 모델 구축에서 파운데이션 모델 (Foundation Models) 구축으로 이동하고 있습니다.
- 파운데이션 모델은 광범위한 기술과 다양한 태스크에 대해 사전 훈련을 시도한 후, 필요에 따라 개별 태스크에 최소한의 데이터만으로 적응할 수 있도록 설계된 모델입니다.
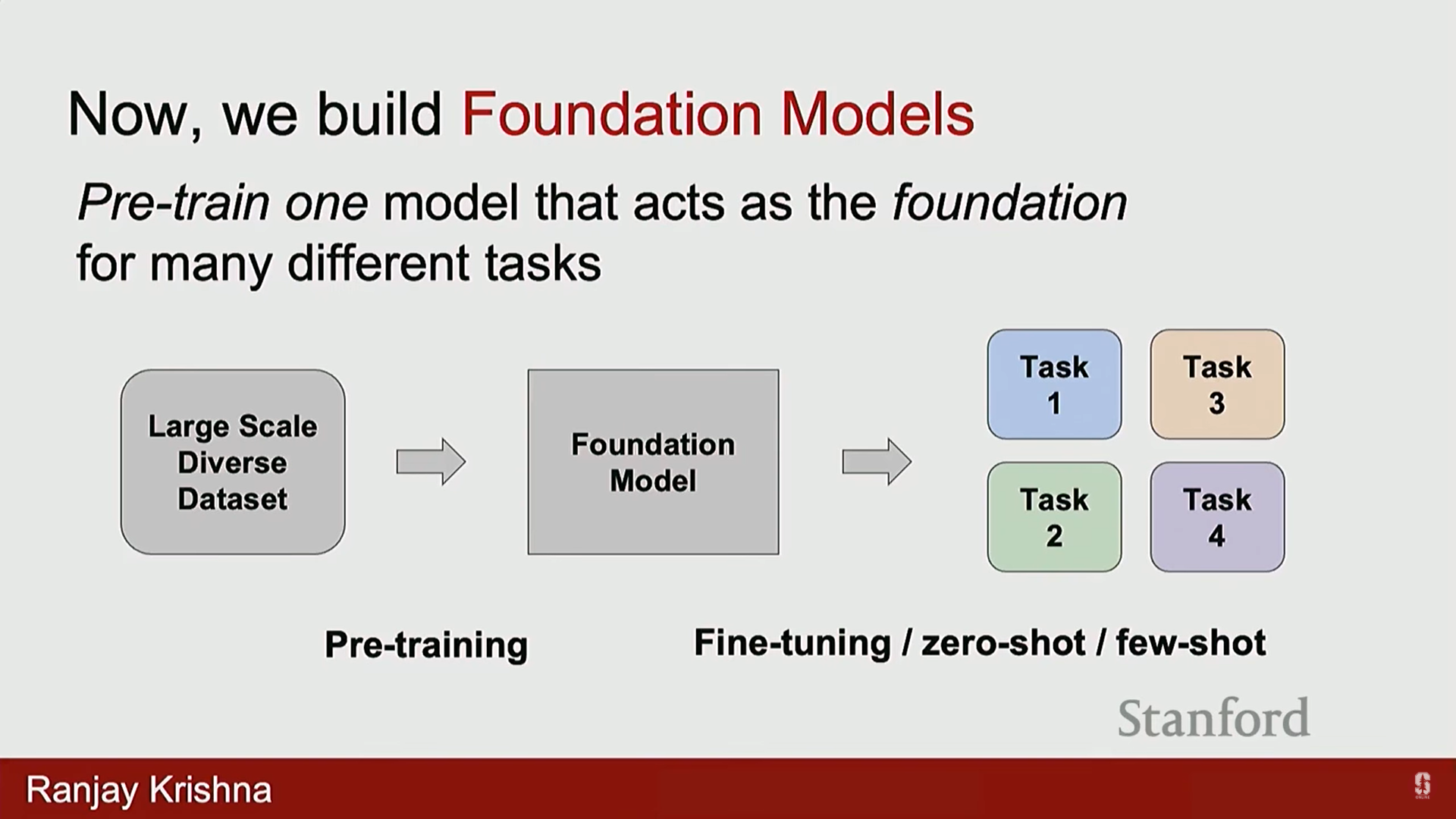
- GPT와 같은 대표적인 파운데이션 모델은 인터넷의 Common Crawl 데이터 등 방대한 양의 데이터로 훈련되었으며, 이후 수학 문제, 상징적 추론, 퀴즈 질문 등 다양한 개별 태스크에 맞게 파인 튜닝됩니다.
- 파운데이션 모델의 장점은 새로운 태스크에 적응할 때 최소한의 데이터만 필요하다는 것이며, 때로는 훈련 데이터를 전혀 수집하지 않고도 활용할 수 있습니다.
- 파운데이션 모델의 분류는 다양하지만, 일반적으로 견고성(robust)과 일반성(general)을 특징으로 하며 많은 매개변수, 대규모 훈련 데이터, 그리고 자기 지도 학습(self-supervised objective) 목표를 통해 훈련됩니다.

- 언어 분야의 주요 파운데이션 모델에는 Elmo, BERT, GPT, T5 등이 있으며, 이번 강의에서는 이미지 분류를 위한 멀티모달 파운데이션 모델인 CLIP 및 CoCa를 중점적으로 다룹니다.

2. 이미지 분류를 위한 파운데이션 모델
1) 자기 지도 학습에서 멀티모달로의 전환 (SimCLR -> CLIP)

- 기존의 자기 지도 학습 방식인 SimCLR에서는 대조 목표(contrastive objective)를 사용했습니다.
- 대조 목표는 변형된 동일 이미지의 표현(representation)은 가깝게 끌어당기고 (예: 고양이의 다른 증강들), 유사하지 않은 이미지의 표현(예: 강아지)은 멀리 밀어내는 방식입니다.
- 이러한 훈련의 희망은 표현이 충분히 일반적(general)이 되어 새로운 형태의 입력(예: 고양이 스케치)이 들어와도 쉽게 분류할 수 있도록 하는 것입니다.

- 멀티모달로 확장하기 위해, 텍스트 표현을 이미지 표현 공간에 추가합니다.
- 텍스트 표현(예: "a cute fluffy cat")도 이미지의 고양이 표현 가까이에 임베딩함으로써, 이미지와 텍스트 모두에서 질의할 수 있게 됩니다.

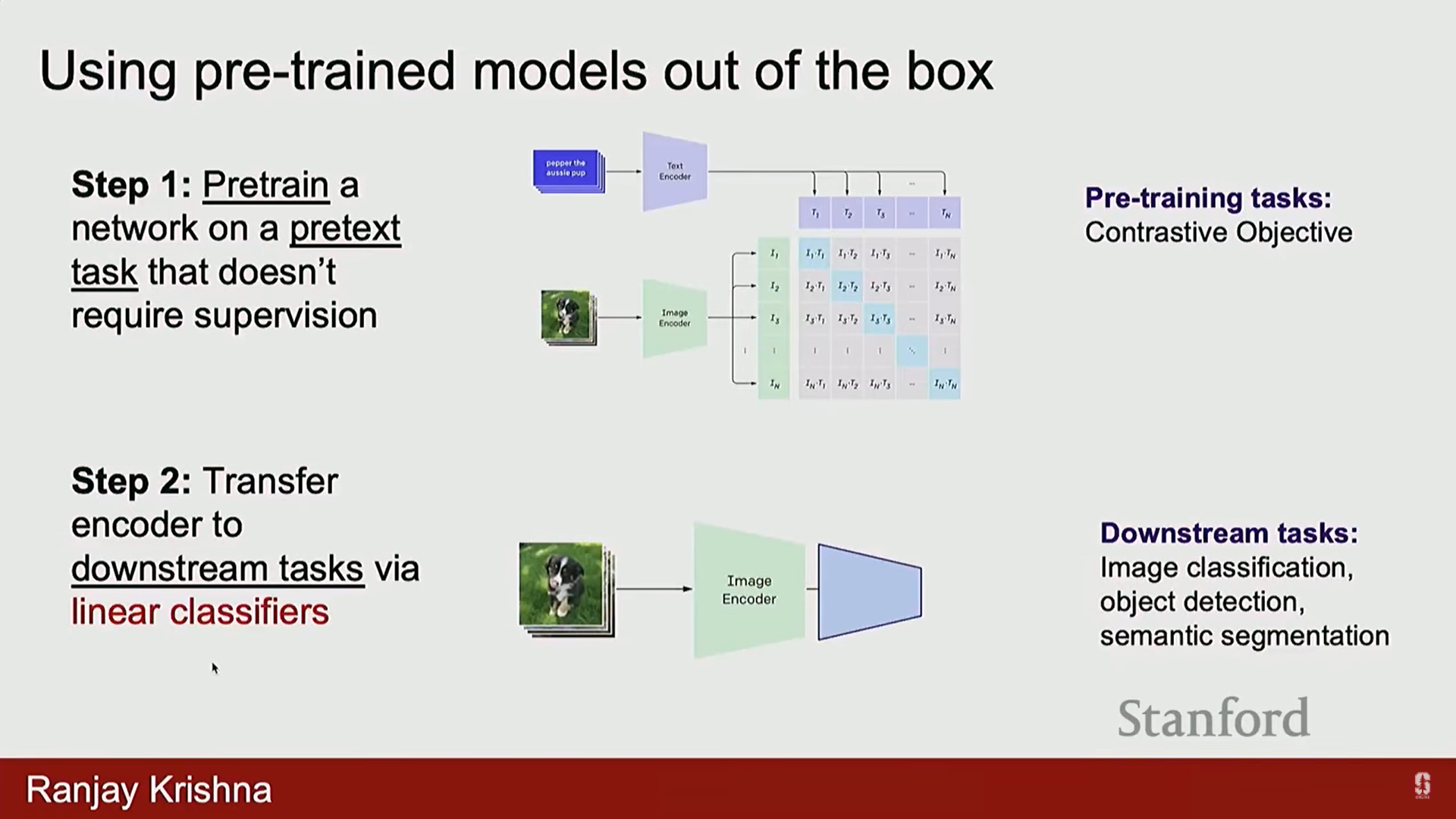
2) CLIP (Contrastive Language-Image Pre-training)의 구조 및 훈련

- CLIP 모델은 SimCLR의 아이디어를 기반으로 하며, 기존의 이미지 인코더 외에 텍스트 인코더 (Text Encoder)를 추가하여 해당 이미지의 설명을 임베딩합니다.
- 훈련 목표: 이미지(예: 강아지)는 해당 텍스트 설명(예: "my favorite dog is a golden retriever") 표현에 가까워지고, 다른 표현들(다른 이미지의 텍스트 설명)로부터는 멀리 떨어지도록 학습합니다.
- 수학적 목표 (Contrastive Objective):
- CLIP은 이미지-텍스트 쌍을 대규모로 수집하여 미니 배치로 모델에 공급하고 대조 손실(contrastive loss)을 사용합니다.
- 이 손실은 분자(Numerator)에서 유사한 것들의 표현을 끌어당기고, 분모(Denominator)에서 나머지 모든 것들의 표현을 밀어냅니다.
- 또한 대칭 손실 (Symmetric Loss)을 사용하여, 이미지가 해당 텍스트에 가장 가까워지는 것 외에도, 텍스트 역시 해당 이미지에 가장 가깝고 다른 이미지 설명으로부터 멀어지도록 합니다.


- 훈련 규모 및 기술적 배경 (심화):
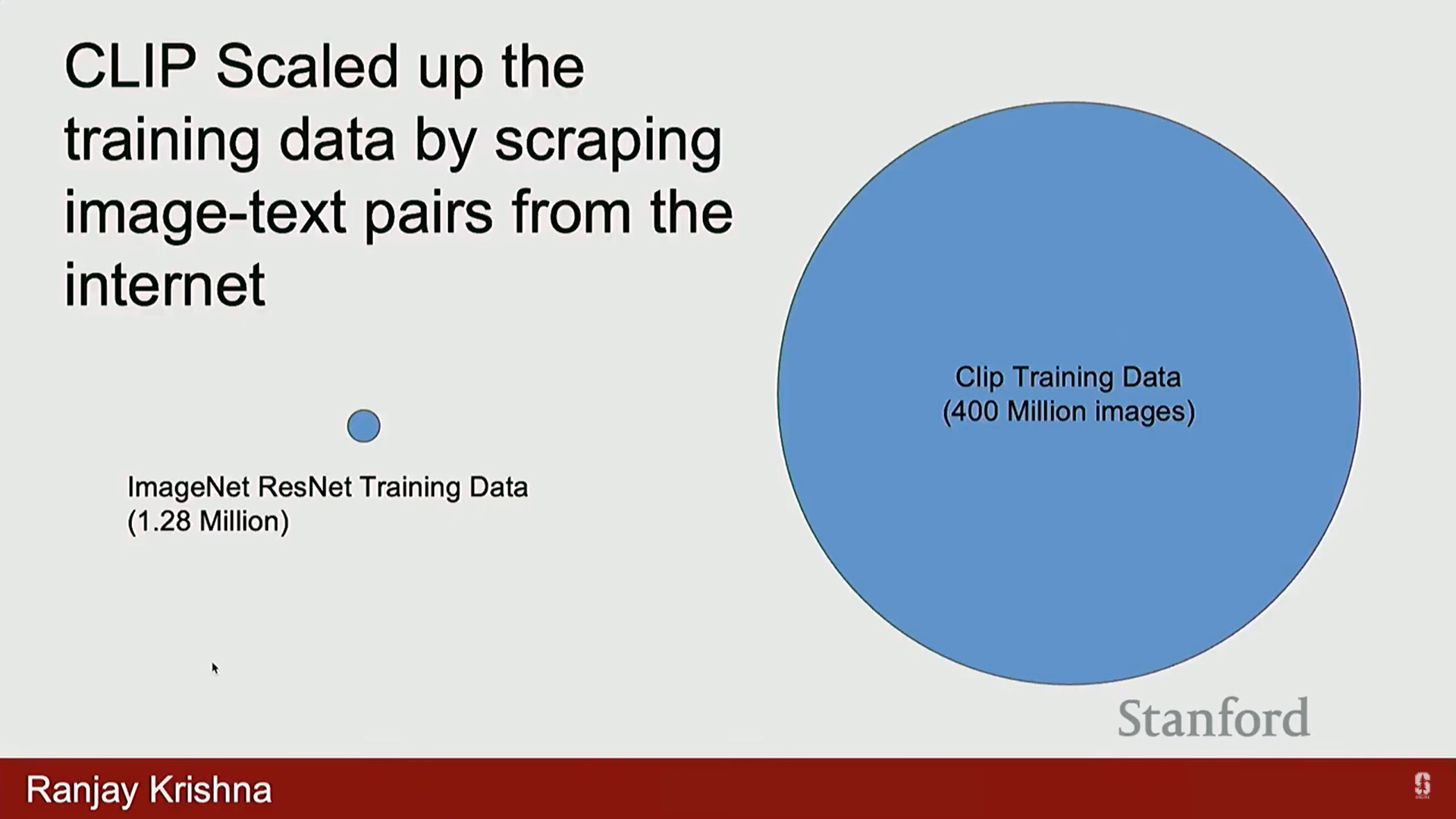
- OpenAI는 인터넷에서 수집한 방대한 양의 이미지-텍스트 쌍을 사용하여 CLIP을 훈련했습니다.
- 모델의 성능 향상을 위해 모델 크기를 키우고, 아키텍처를 ResNet에서 Vision Transformer (ViT)로 변경했습니다.
- ImageNet의 120만 개 이미지에 비해, CLIP은 약 4억 개의 이미지-텍스트 쌍으로 훈련되었습니다.
3) CLIP의 활용: 적응 및 제로샷(Zero-Shot) 일반화
-
적응 단계 (Linear Probe): 사전 훈련된 이미지 인코더 위에 선형 레이어를 추가하여 이미지 분류, 객체 감지, 또는 시맨틱 분할 등 새로운 태스크에 적응시킬 수 있습니다.
- CLIP 인코더 위에 선형 분류기를 추가하는 것만으로도 성능이 크게 향상되었습니다.
-
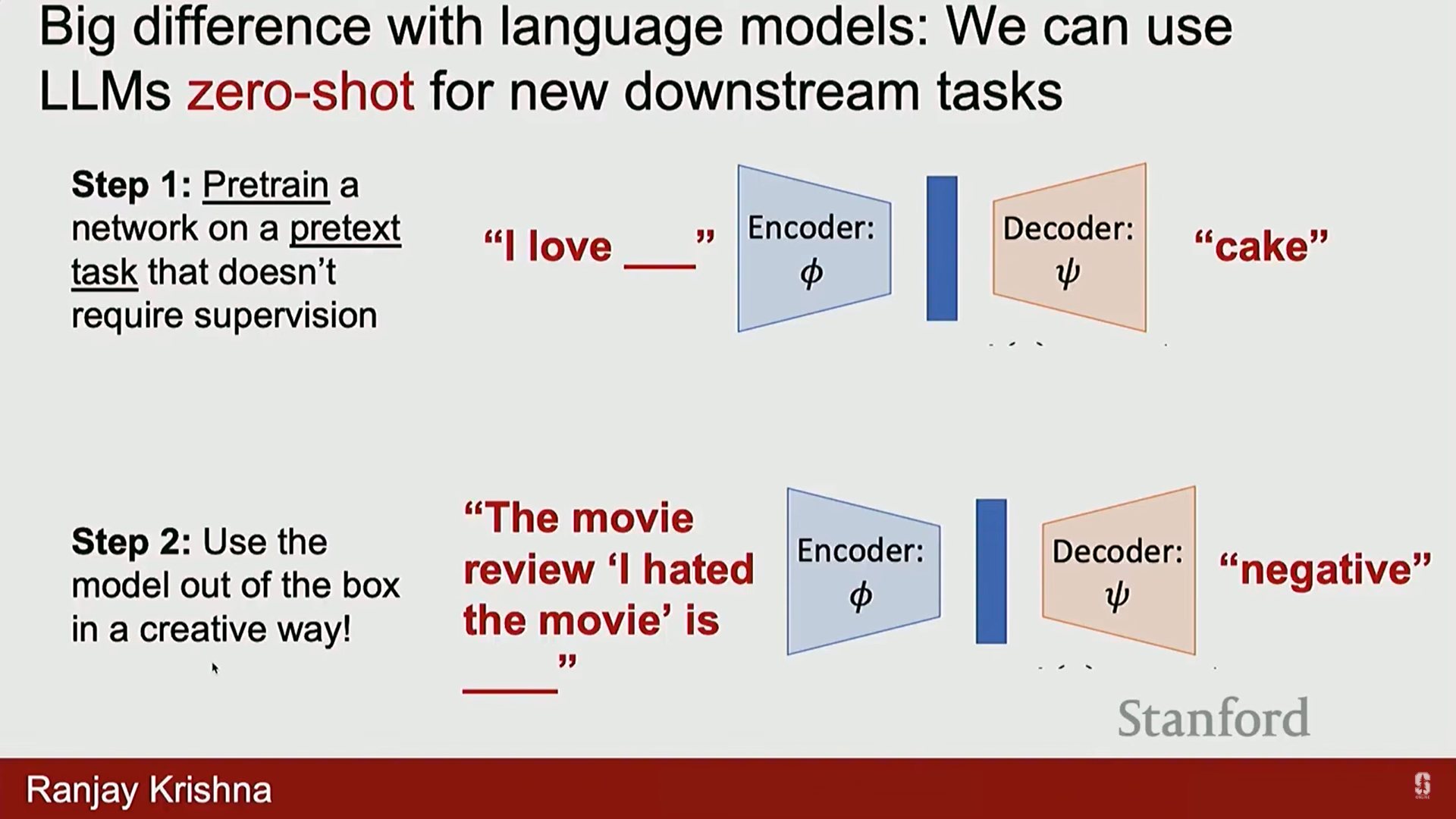
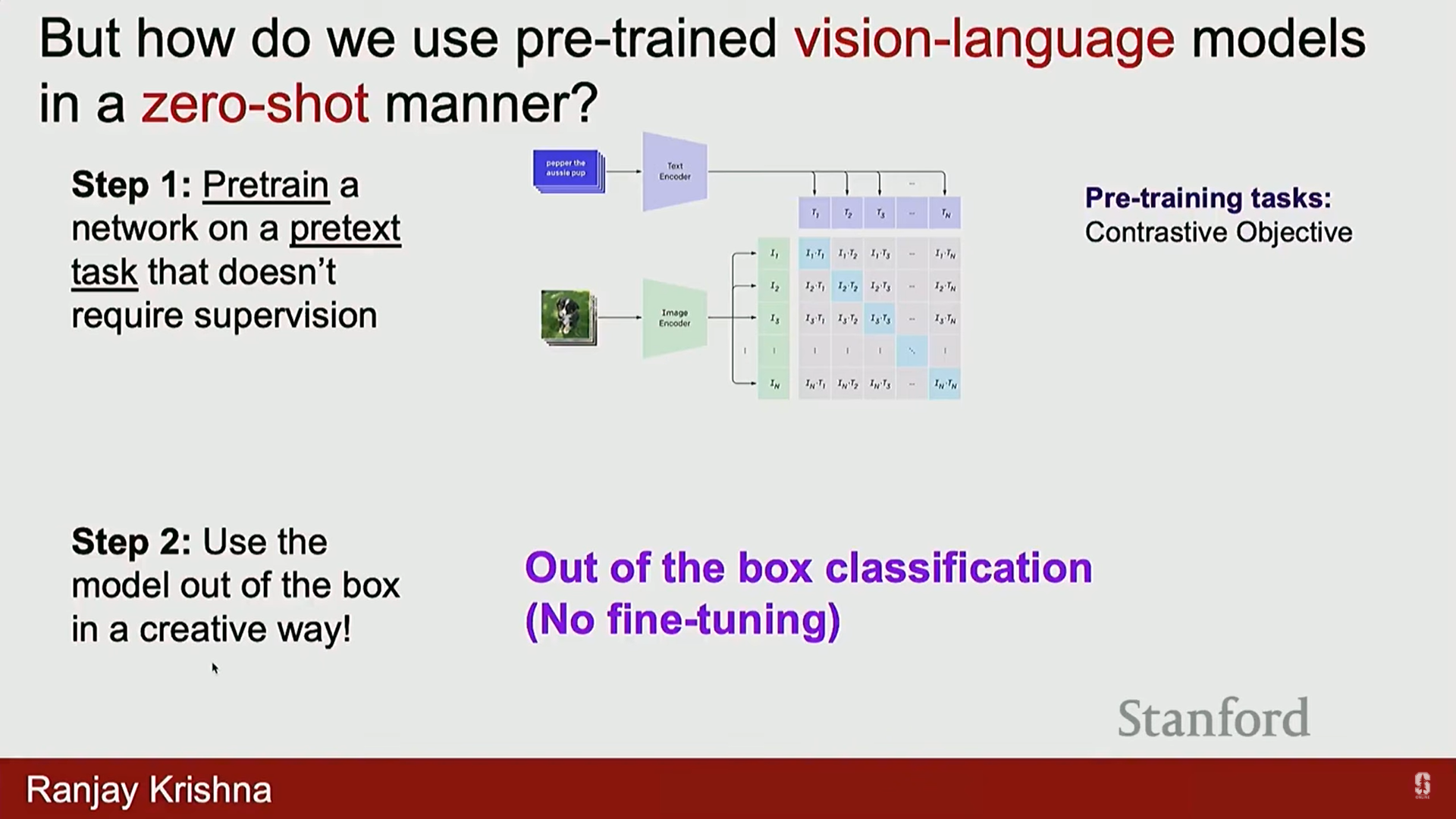
제로샷 일반화 (Out-of-the-Box Use): 재훈련 없이 CLIP 모델을 바로 사용하기 위한 방법입니다.
- 언어 모델은 모든 태스크를 자동 완성(autocomplete) 과정으로 취급하여 재훈련이 필요 없지만, CLIP은 대조 목표로 훈련되었기 때문에 새로운 태스크에 적응하기 위해 훈련 데이터나 선형 레이어가 필요했습니다.
- 영리한 트릭: 텍스트 인코더를 사용하여 분류를 유도합니다.
- 작동 방식 (1-Nearest Neighbor):
- 새 데이터셋의 모든 카테고리(예: plane, dog, bird)를 텍스트 인코더에 통과시켜 벡터를 생성합니다.
- 새로운 이미지가 들어오면 이미지 인코더를 사용하여 임베딩합니다.
- 이미지 임베딩과 가장 유사성 점수가 높은 가장 가까운 이웃(Nearest Neighbor) 텍스트 벡터를 찾아 해당 클래스로 분류합니다.
-
프레이즈 사용의 중요성:
- 단일 단어 대신 프레이즈 (예: "a photo of a plane")를 사용하면 더 좋은 벡터를 얻을 수 있으며, 이는 ImageNet에서 약 1.3%의 성능 향상을 가져왔습니다.
- 여러 프레이즈(예: "a photo of a dog", "a drawing of a dog")를 사용한 후, 각 카테고리의 평균 벡터를 계산하여 분류에 사용하면 더욱 효과적입니다.





4) CLIP의 일반화 능력 (심화)
-
강력한 일반화 성능: CLIP은 ImageNet으로 훈련된 모델보다 훨씬 뛰어난 일반화 능력을 보여줍니다.
- 특히, CLIP 출시 이후 수집된, 일반적인 형태가 아닌 객체들이 포함된 ObjectNet과 같은 도메인 외 데이터셋에서도 훌륭한 성능을 발휘합니다.
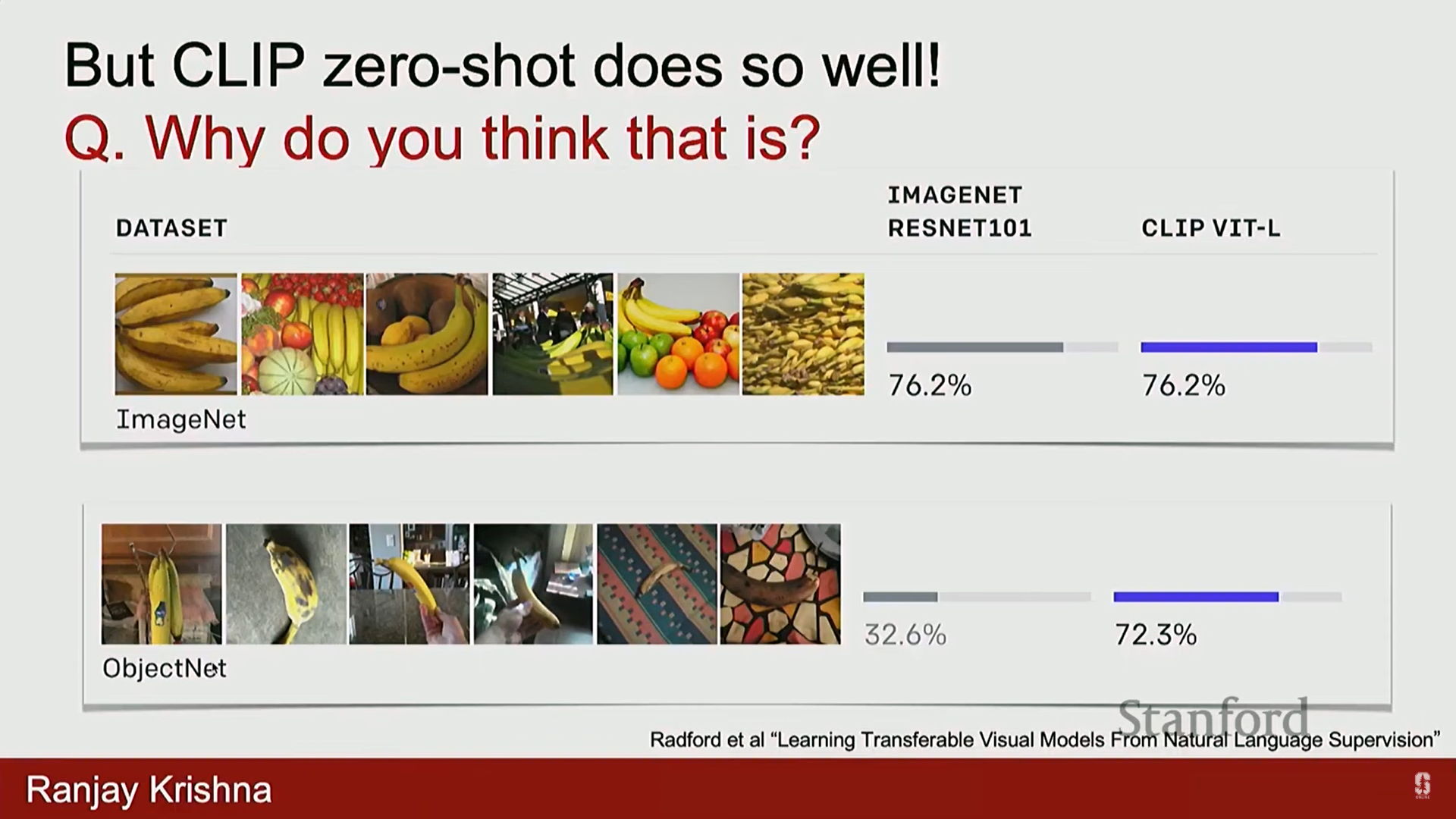

- 특히, CLIP 출시 이후 수집된, 일반적인 형태가 아닌 객체들이 포함된 ObjectNet과 같은 도메인 외 데이터셋에서도 훌륭한 성능을 발휘합니다.
-
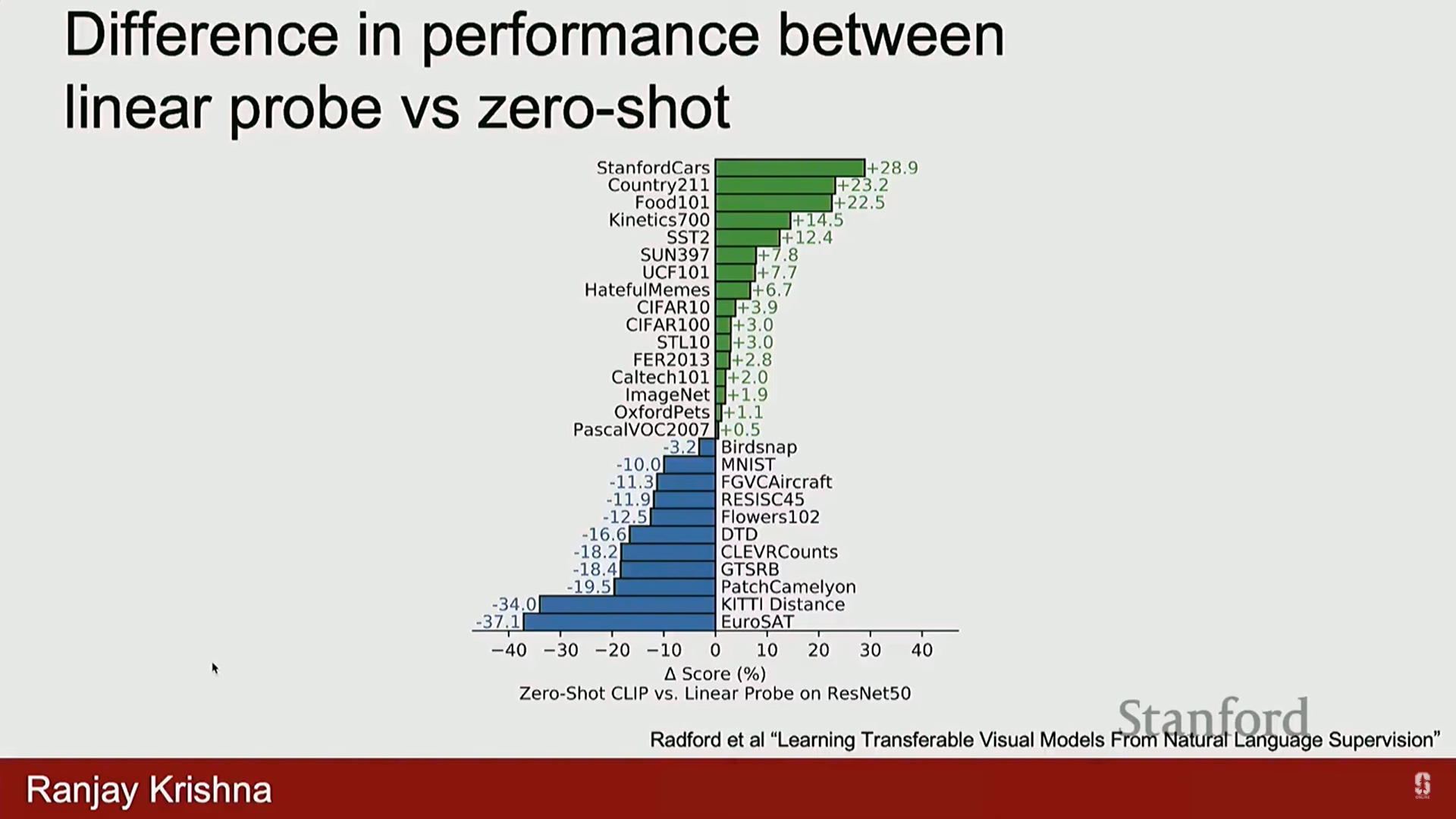
일반화 이유:
- 풍부한 지도 학습: 인터넷에서 다운로드한 텍스트에는 단순한 카테고리 레이블 이상의 구조적 정보(모양, 색상 등)가 포함되어 있어 모델 표현에 도움이 됩니다.
- 데이터 규모의 힘: ImageNet은 130만 개의 이미지인 반면, 인터넷에는 수십억 개의 이미지-텍스트 쌍이 존재하며, 이 방대한 데이터 규모 덕분에 적응이 훨씬 쉬워집니다.

-
CLIP은 자연 이미지 외에도 스케치 및 적대적 데이터셋에서도 견고한 성능을 보여주며, 많은 사람들은 CLIP을 이미지용 최초의 파운데이션 모델로 간주합니다.
5) CoCa (Captioning and Contrastive learning)
- 최신 동향: CLIP 이후 2022년에 등장한 CoCa는 CLIP의 대조 손실 목표에 추가적인 요소인 디코더를 추가했습니다.
- 구조: 이미지 인코더에서 추출된 이미지 특징을 교차 어텐션 (Cross Attention)을 통해 디코더에 제공하여 이미지를 캡셔닝합니다.
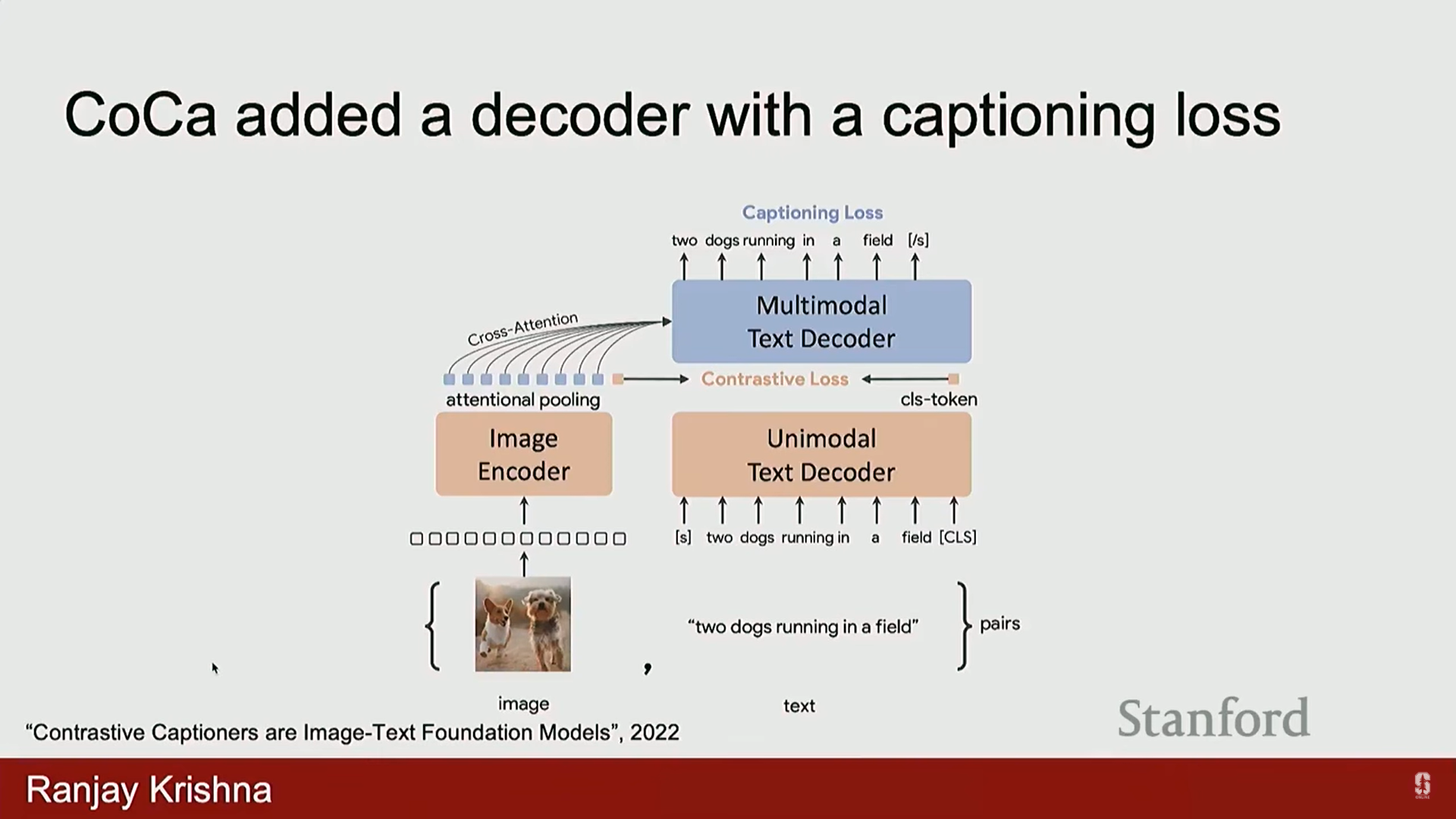
- 가설: 단순히 분류하는 것(고양이 대 강아지)을 넘어, 이미지를 텍스트로 자세히 설명하는 캡셔닝 과정은 모델이 훨씬 더 풍부한 정보를 학습하도록 강제하는 더 강력한 학습 목표라는 가설이었습니다.
- 결과: CoCa는 CLIP 대비 ImageNet 변형 데이터셋에서 약 10%의 성능 향상을 보였으며, 이는 파운데이션 모델이 지도 학습 모델을 능가하는 전환점이 되었습니다.
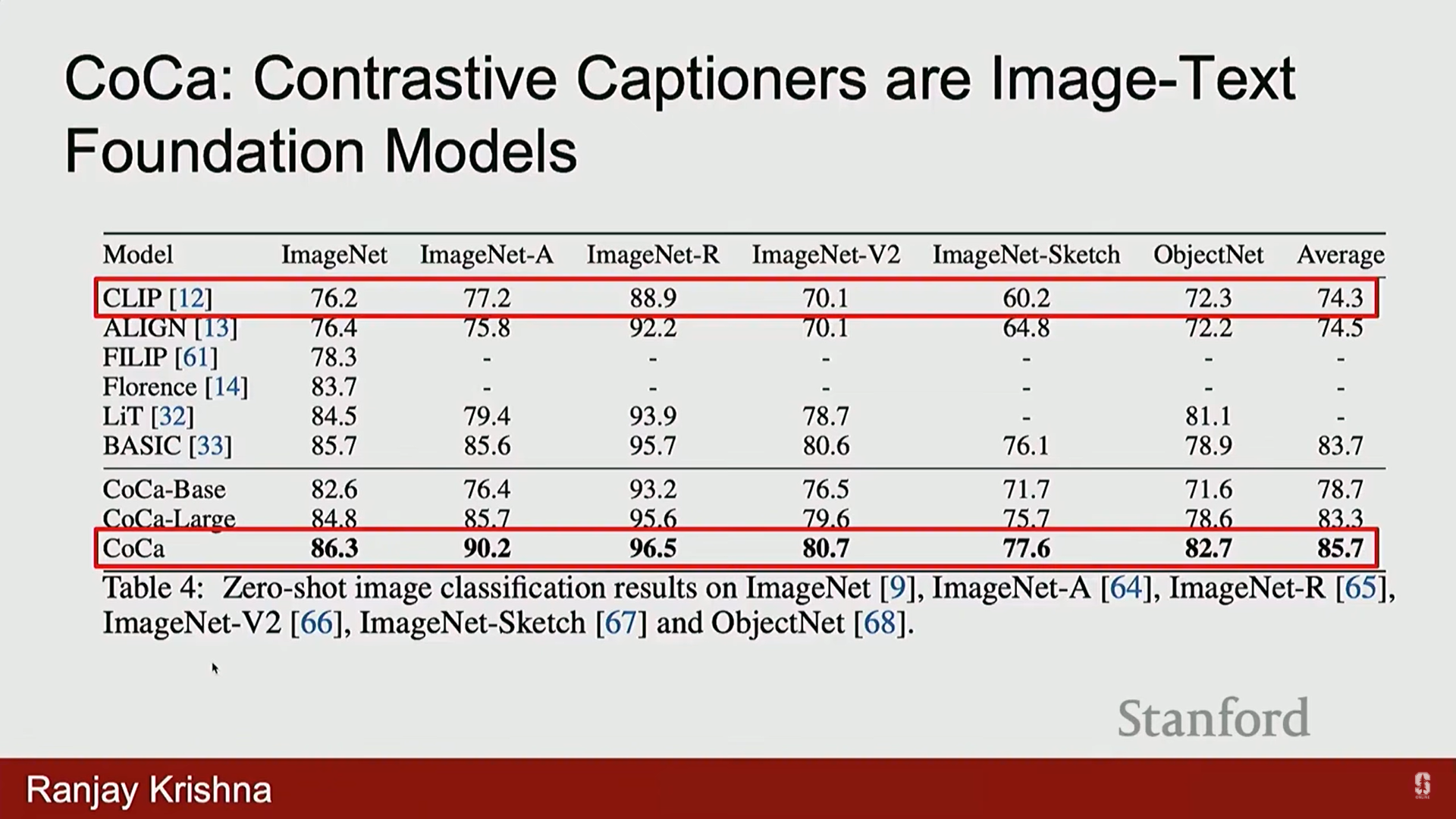
6) CLIP의 장점과 한계점 (심화)
- 장점:
- 훈련 용이성 및 빠른 추론 속도.
- 임베딩된 데이터셋에서 검색(Retrieval)이 쉬워 분류뿐 아니라 검색 태스크에도 유용.
- 개방형 어휘 (Open Vocabulary): 어떤 텍스트 설명이든 입력하여 적절한 이미지를 검색할 수 있습니다.
- 다른 모델과의 체인화(Chaining) 용이성.

- 명확한 한계점:
- 구성성 (Compositionality) 부족: 이미지 내 객체 간의 관계를 파악하지 못함 (예: "mug in grass"와 "grass in mug"를 구별하지 못함).
- 배치 크기 의존성: CLIP의 학습 목표는 배치 크기에 크게 의존합니다. 배치 크기가 충분히 크지 않으면 유용한 학습 신호를 얻기 어렵습니다.
- 하드 네거티브 (Hard Negatives): 미니 배치가 커지면 (예: 32,000) 웰시 코기와 다른 코기를 구별하는 등 미세한 개념 학습이 가능해집니다. 이는 모델이 학습하도록 강제하는 충분히 유사한 부정적 예시(Hard Negatives)가 필요하기 때문입니다.
- Hard Negatives의 역효과: 커뮤니티에서는 Hard Negatives를 사용하여 배치를 수동으로 구성하려 했으나, 오히려 일반화 성능을 저하시키고 의미론(semantics)에 대해 학습한 내용을 잊어버리게 만드는 (unlearning) 현상이 관찰되었습니다. 이 현상에 대한 이론적 이해는 아직 부족합니다.
- 그라운딩 정보 부족: 이미지 수준의 캡션(image-level captions)만으로는 객체의 위치나 관계 같은 그라운딩(Grounding) 정보가 완전히 누락됩니다.
- 데이터 한계: 50억 개의 이미지를 수집하더라도 모든 중요한 정보를 담기에 불충분하며, 현재 연구는 데이터 필터링 및 큐레이션에 초점을 맞추고 있습니다.


3. 비전-언어 모델 (Vision and Language Models)
1) 멀티모달 언어 모델의 부상 (LAVA)

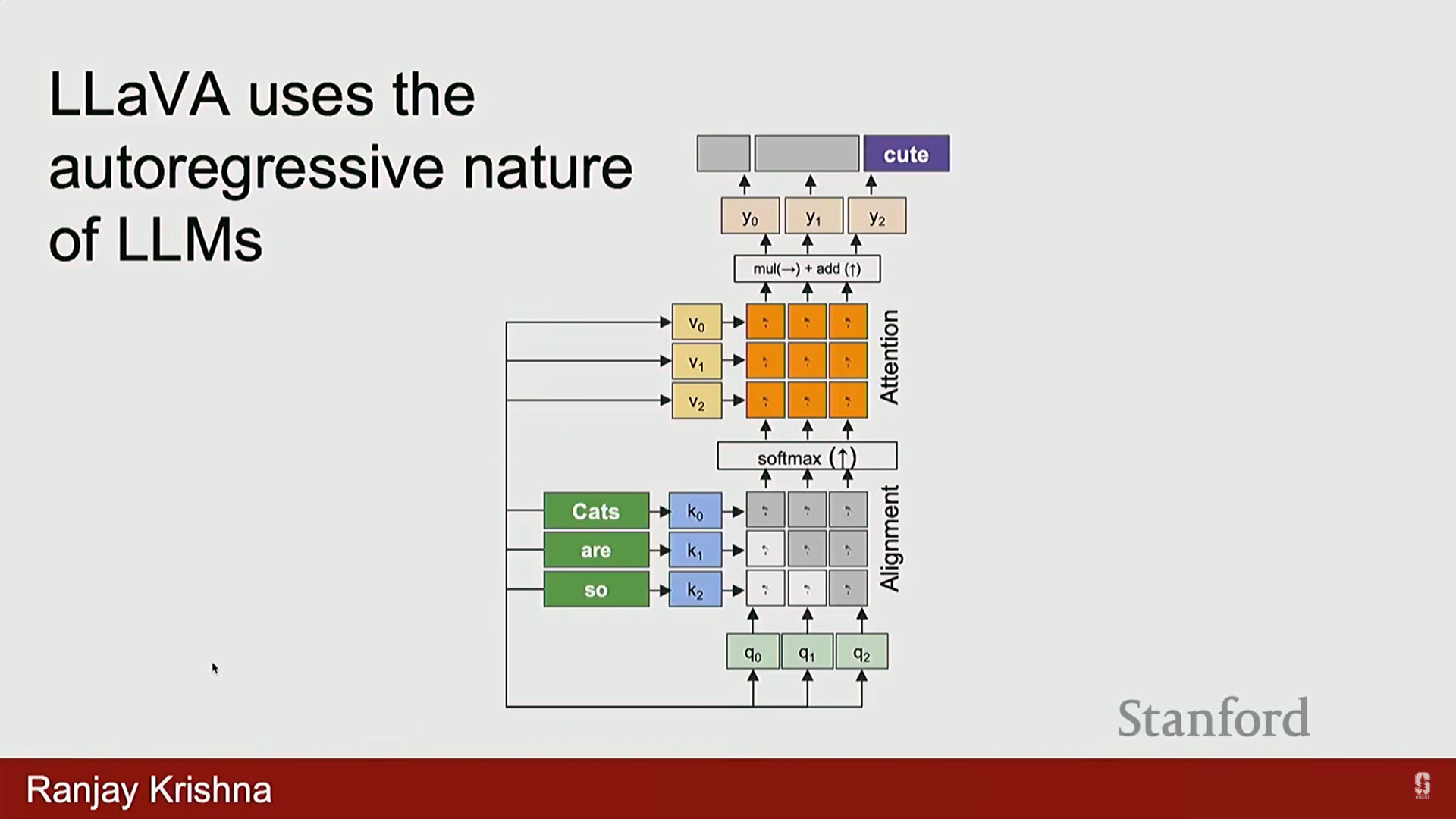
- 동기: 언어 모델의 다음 토큰 예측 (Next Token Prediction) 과정이 새로운 태스크에 적응하는 데 유용하므로, 이미지 모델에도 이 자동 회귀 (autoregressive) 방식을 적용하고자 했습니다.
- 역사: 2019년 Vilbert가 비전 모델과 언어 모델을 결합하여 일반화를 시도했으나, 이는 트랜스포머 이전 시대의 모델이었습니다.
- 비전 언어 모델의 기본 아이디어: 이미지 토큰을 언어 모델에 공급하여, 기존 텍스트 컨텍스트와 함께 다음 단어를 자동 완성하도록 합니다.
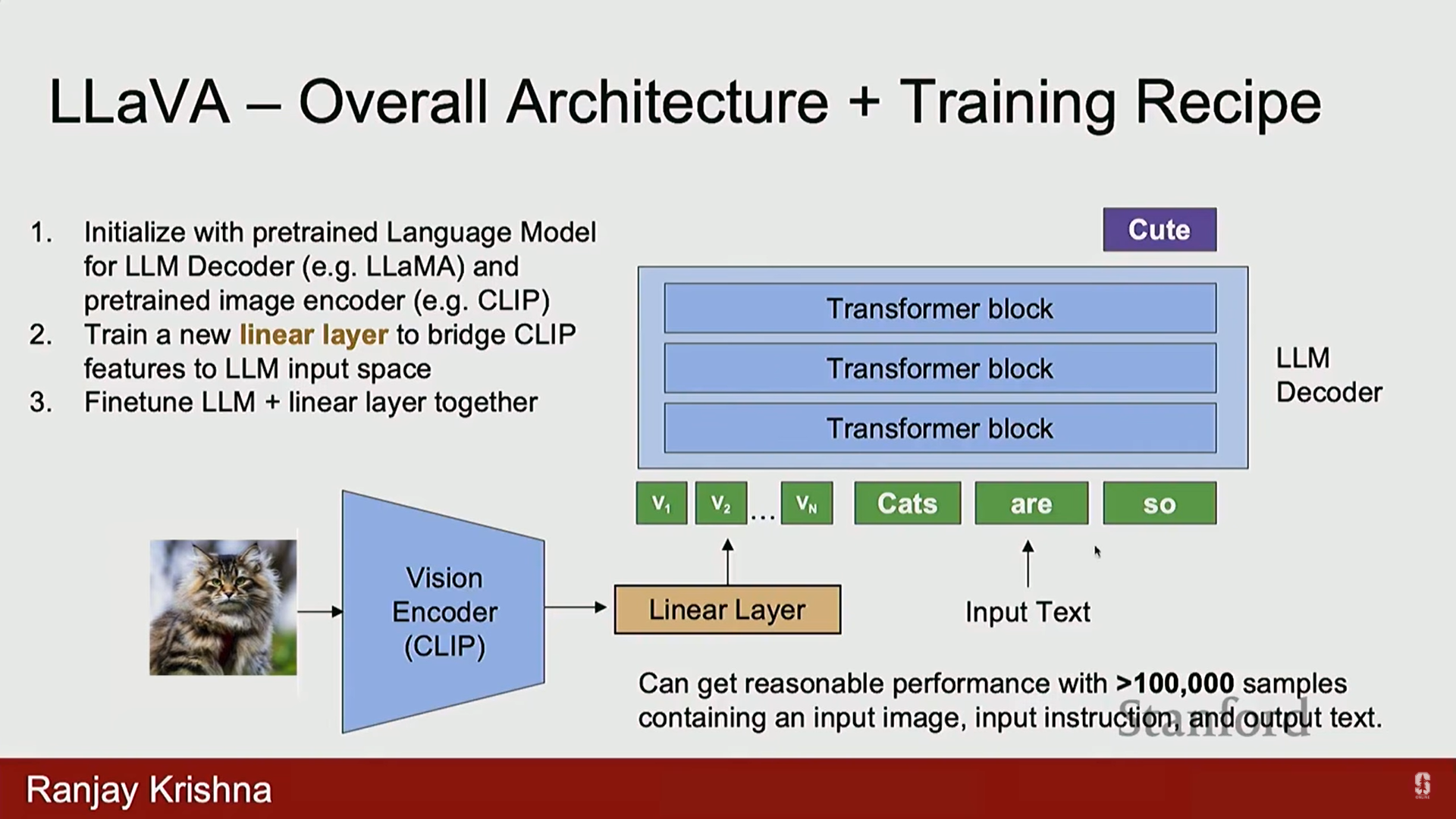
- LAVA (Visual Language Model):
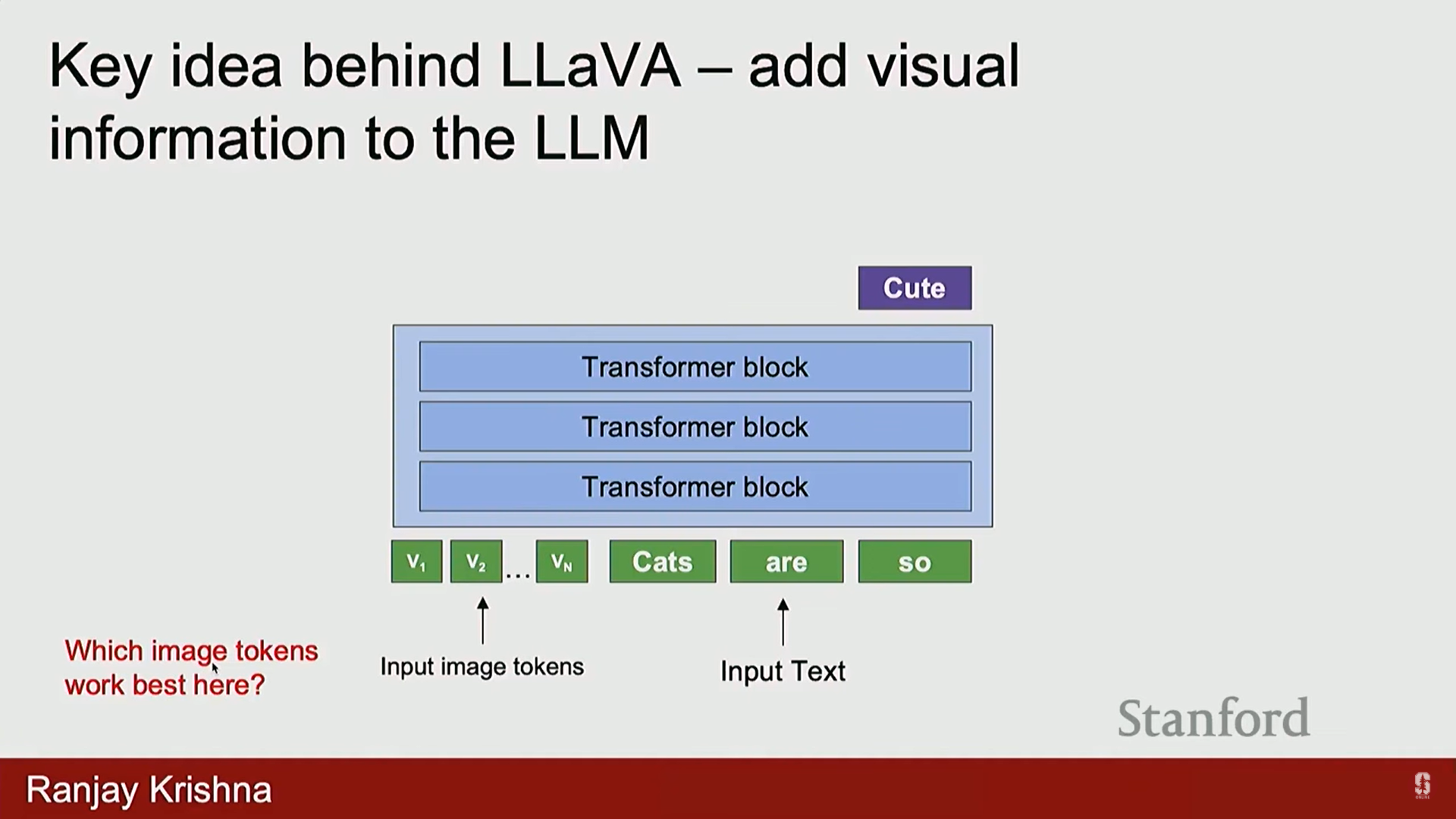
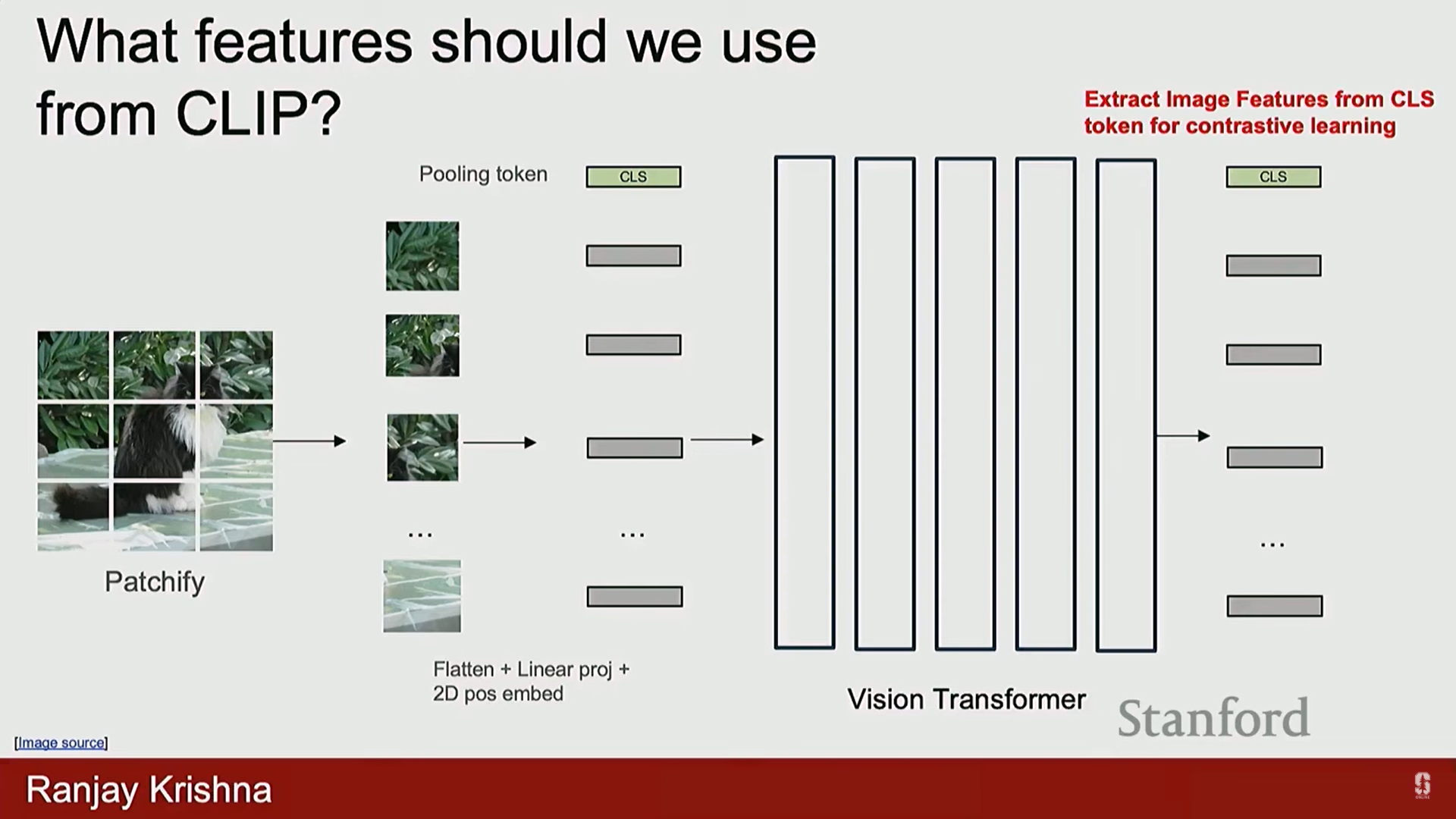
- 이미지 토큰 정의: CLIP의 이미지 인코더를 사용하여 토큰을 추출합니다.
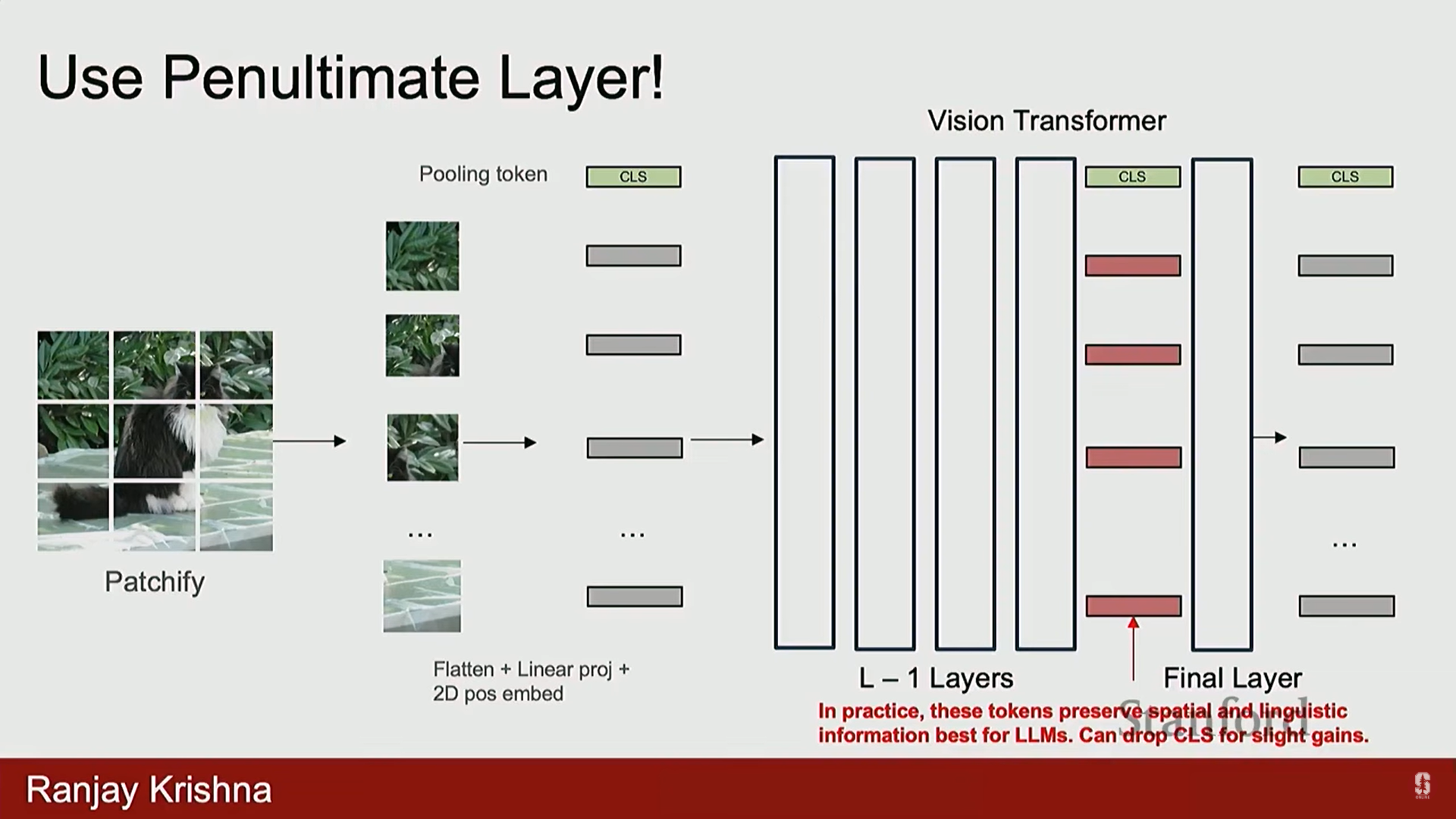
- 특징 선택: 기존에는 CLS 토큰을 분류에 사용했으나, 이는 공간 정보(spatial information)가 부족합니다. 대신, CLIP 인코더의 직전 레이어 (penultimate layer) 특징을 사용합니다. 이 특징들은 객체의 위치에 대한 공간 정보를 많이 포함하고 있어 유용합니다.
- 아키텍처: 이미지를 사전 훈련된 CLIP 인코더에 통과시켜 특징을 추출한 후, 선형 레이어 (Linear Layer)를 통해 LLM이 이해할 수 있는 토큰으로 변환합니다. 이 토큰들은 LLM에 입력되어 이미지에 대한 대화를 생성합니다.

2) Flamingo의 혁신 (Google)
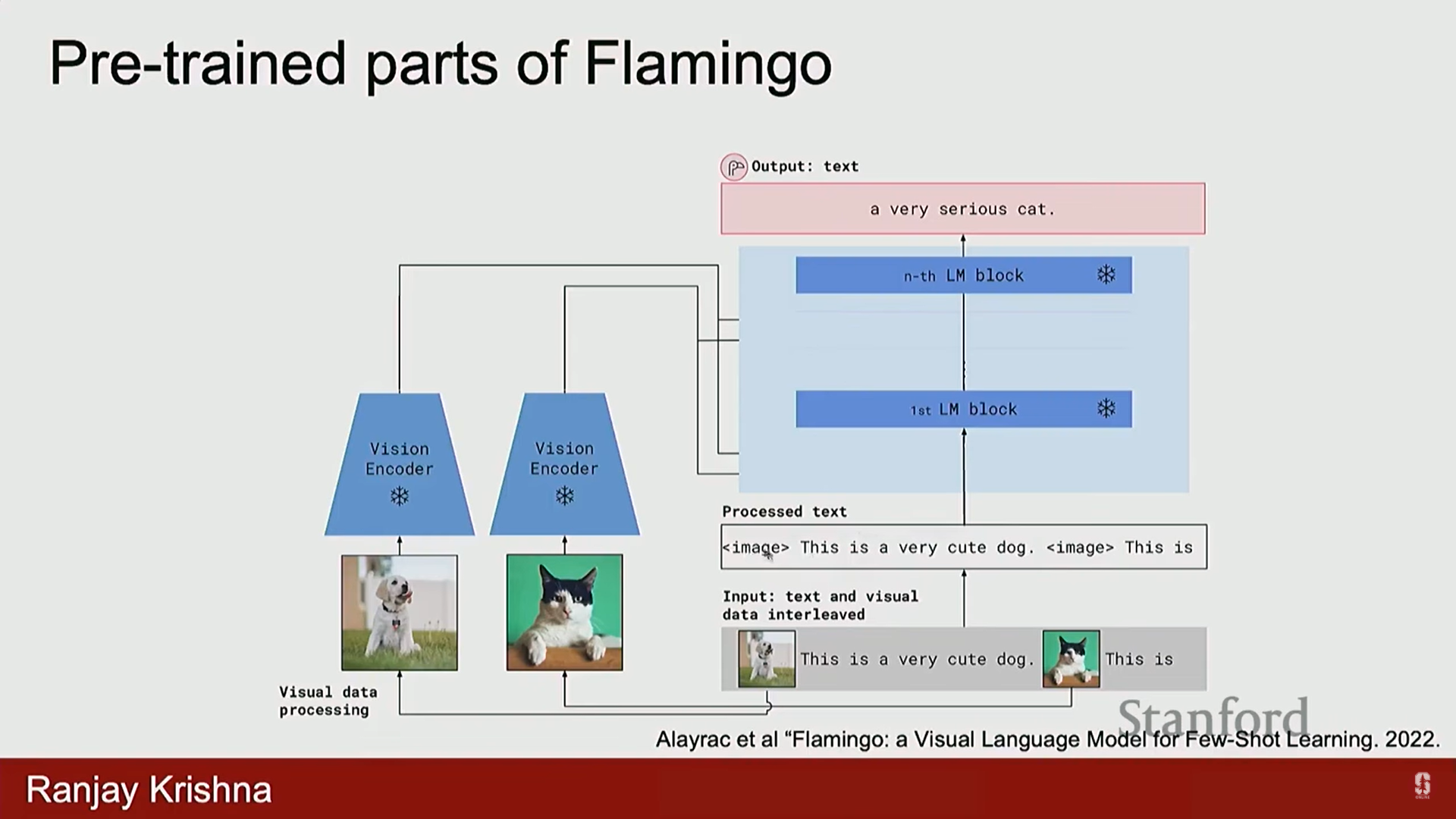
- Flamingo는 Lava와 유사하게 비전 인코더 특징을 LLM과 결합했지만, 특징을 통합하는 방식에 혁신을 가져왔습니다.
- 특징 융합: 이미지 특징을 LLM의 입력으로만 제공하는 Lava와 달리, Flamingo는 비전 인코더의 특징을 LLM의 모든 레이어에 공급했습니다.
- 훈련 데이터: 이미지와 텍스트가 번갈아 나오는 긴 시퀀스 (Image-Text-Image-Text) 형태로 구성된 데이터로 훈련되었습니다.
- 아키텍처 변경:
- LLM의 모든 레이어에 게이트형 X 교차 어텐션 모듈 (Gated X Cross Attention Module)을 추가했습니다.
- 퍼시버 샘플러 (Perceiver Sampler)를 추가하여 이미지 표현을 다운샘플링하고, 모든 레이어에 고정된 수의 작은 차원 토큰을 제공합니다.
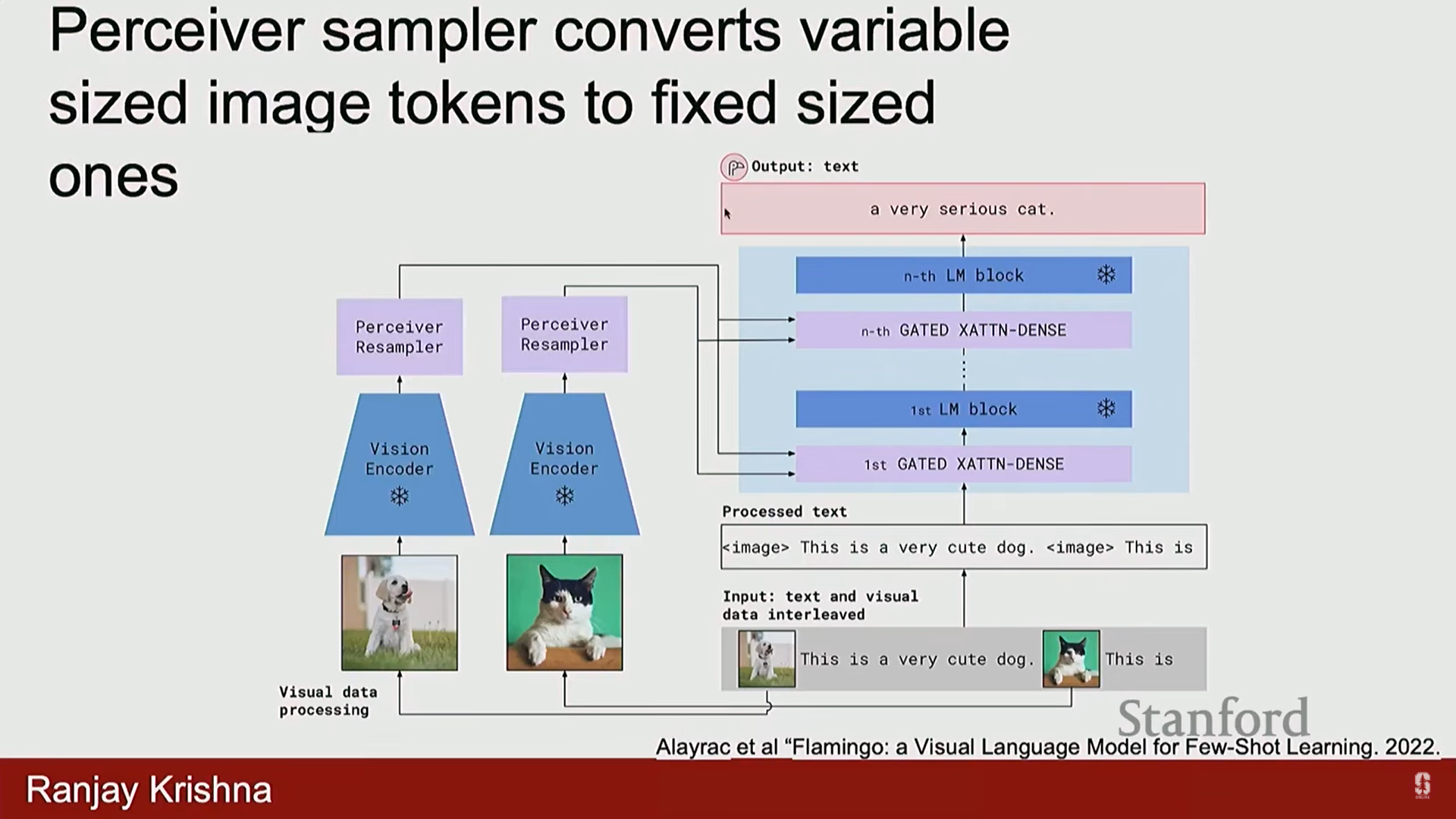
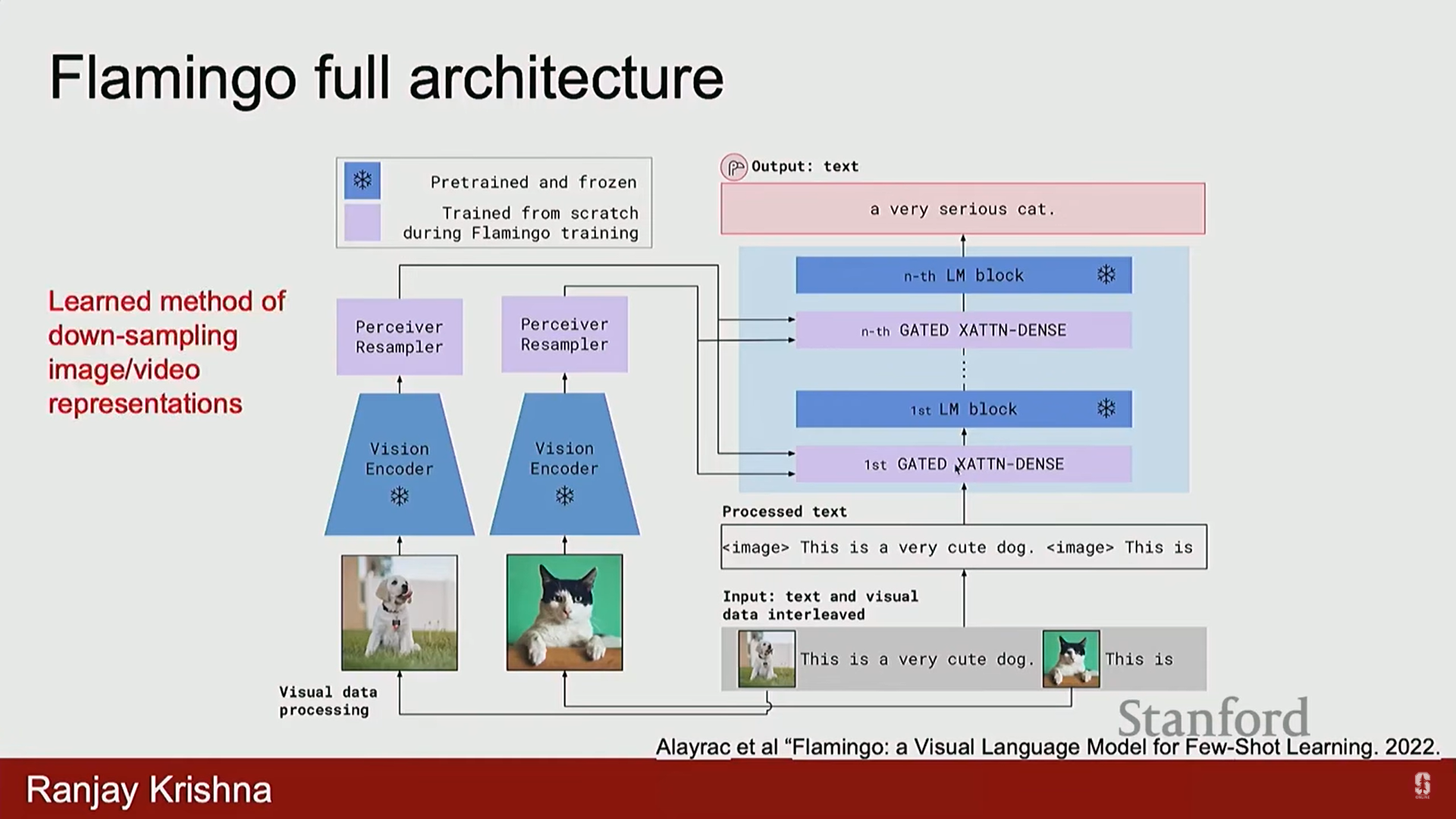
- 훈련 주체: 언어 모델과 비전 모델 가중치는 대부분 동결(frozen)되며, 퍼시버 샘플러와 교차 어텐션 레이어만 훈련됩니다.
- 교차 어텐션의 역할: 이미지 특징을 보고 언어 모델에 유용하다고 판단되는 부분만 유지하고 나머지는 잊어버리도록 결정하는 역할을 합니다.
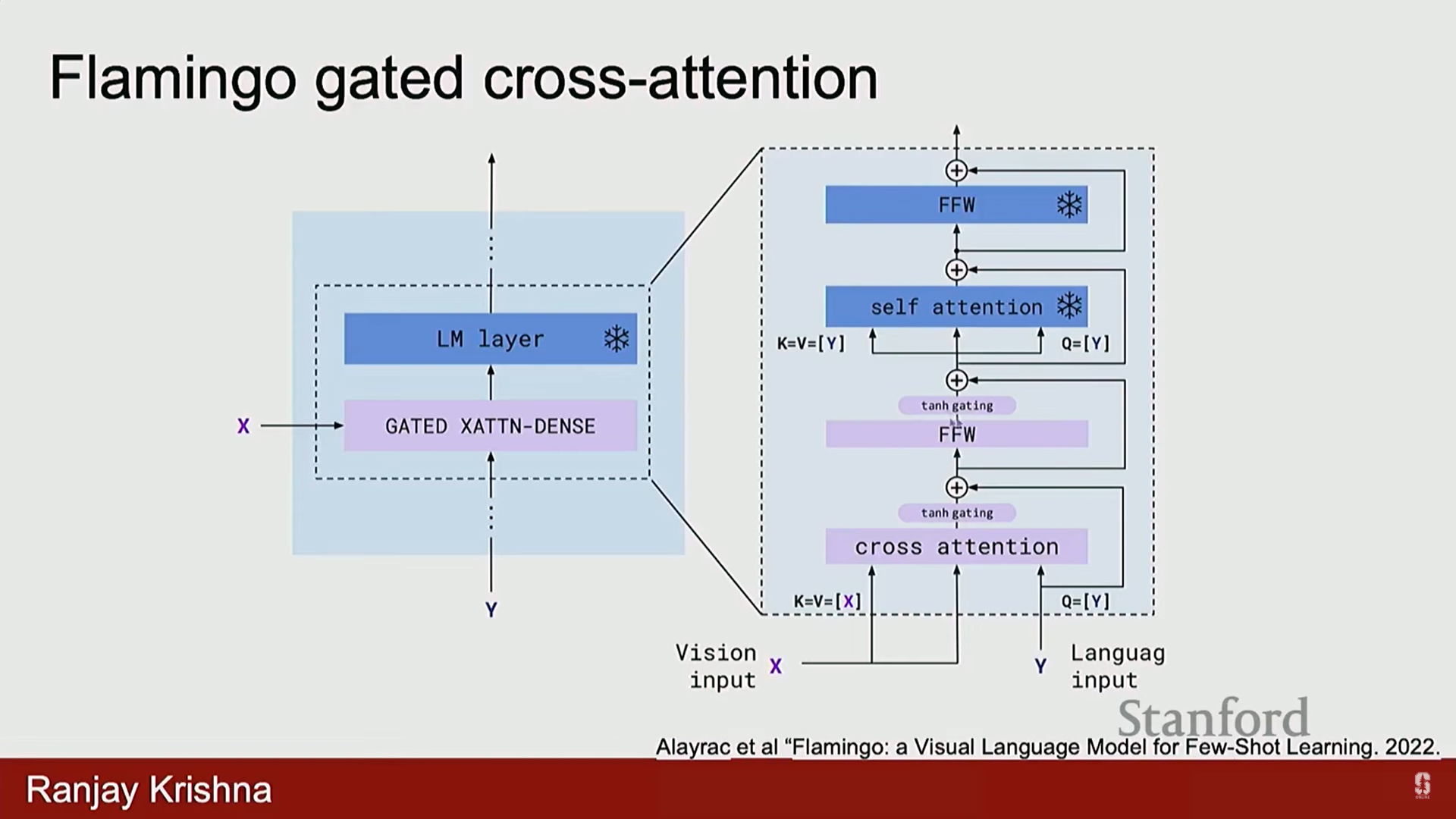
- 훈련 방식: 생성 시, 모델이 해당 이미지의 특징만을 보도록 하는 마스킹 스킴을 사용하여, 긴 시퀀스 훈련 중에도 특정 이미지에 대한 설명을 생성할 때는 그 이미지에만 집중하도록 했습니다.

- 응용 (추론 능력 상속): LLM의 추론 능력을 상속받아 멀티턴 대화, 여러 이미지에 대한 추론, 인컨텍스트 학습 (In-Context Learning, Few-shot)(예: 분류, OCR, 수학) 등 다양한 응용이 가능해졌습니다.

3) 오픈 소스 모델의 추격: Molmo (심화)
- 성능 격차: GPT-4V, Gemini, Claude 3 Opus와 같은 독점 모델들이 개방형 소스 모델(예: Lava)보다 벤치마크에서 훨씬 높은 정확도(~80% 대 vs. ~43%)를 기록하며 큰 격차가 있었습니다.
- 문제점: 오픈 소스 커뮤니티는 고성능 VLM을 만드는 핵심 비결을 알지 못하며, Qwen 같은 일부 모델은 GPT에서 증류(distilled)되었기 때문에 재현성이 불확실합니다.
- Molmo의 목표: 연구 커뮤니티의 격차 해소를 위해 개발되었으며, 완전히 오픈 소스 (가중치, 데이터, 코드)로 공개되었습니다.
- Molmo의 성능: 대규모 사용자 연구 (870명, 325,000쌍 비교)에서 GPT-4o와 유사한 ELO 평점 (2위)을 기록하며, Gemini 1.5 Pro와 Claude 3.5를 능가했습니다.
- 하드웨어 접근성: 70억 매개변수 모델은 단일 GPU에서도 실행 가능하여 광범위한 활용을 가능하게 합니다.
- 핵심 혁신: 픽셀에 의사 결정 근거를 두는 그라운딩:
- Momo는 단순히 숫자를 출력하는 대신, 세는 대상(예: 보트)을 실제 픽셀에 포인트한 다음 최종 숫자를 출력합니다. 이는 환각(hallucination)을 줄이는 데 도움이 되는 것으로 보입니다.
- 데이터 품질의 중요성: Meta가 60억 개의 이미지-텍스트 쌍으로 훈련한 반면, Momo는 단 70만 개의 수작업으로 선별된 (hand-curated) 고밀도 데이터로 훈련되었습니다.
- 인터넷 데이터는 주관적이거나 부수적인 내용을 담는 경우가 많습니다.
- Molmo 데이터는 이미지의 실제 내용, 공간 관계(좌/우), 크기(large), 모양(rectangular), 재질(polished), 이미지 내 위치 등 인터넷에서는 잘 언급되지 않는 밀도 높은 (dense) 정보를 포함합니다.
- 데이터 수집 시, 주석가들에게 설명을 타이핑이 아닌 말로 하도록 유도하여 관습적인 언어 습관(그라이스 격률)을 깨고 숨겨진 정보를 이끌어냈습니다.
- 아키텍처: LLava와 동일한 기본 구조 (CLIP 인코딩 선형 커넥터 LLM)를 사용합니다. 핵심 차이는 데이터의 품질과 밀도였습니다.
- 응용: 메뉴 항목, 검색 옵션, 버스 노선 번호 등 미세한 세부 사항에 포인팅할 수 있으며, 깊이 이미지, 오버헤드 이미지, 복잡한 군중 장면 등에서도 추론이 가능합니다.
4. 출력 공간 일반화: SAM (Segment Anything Model)

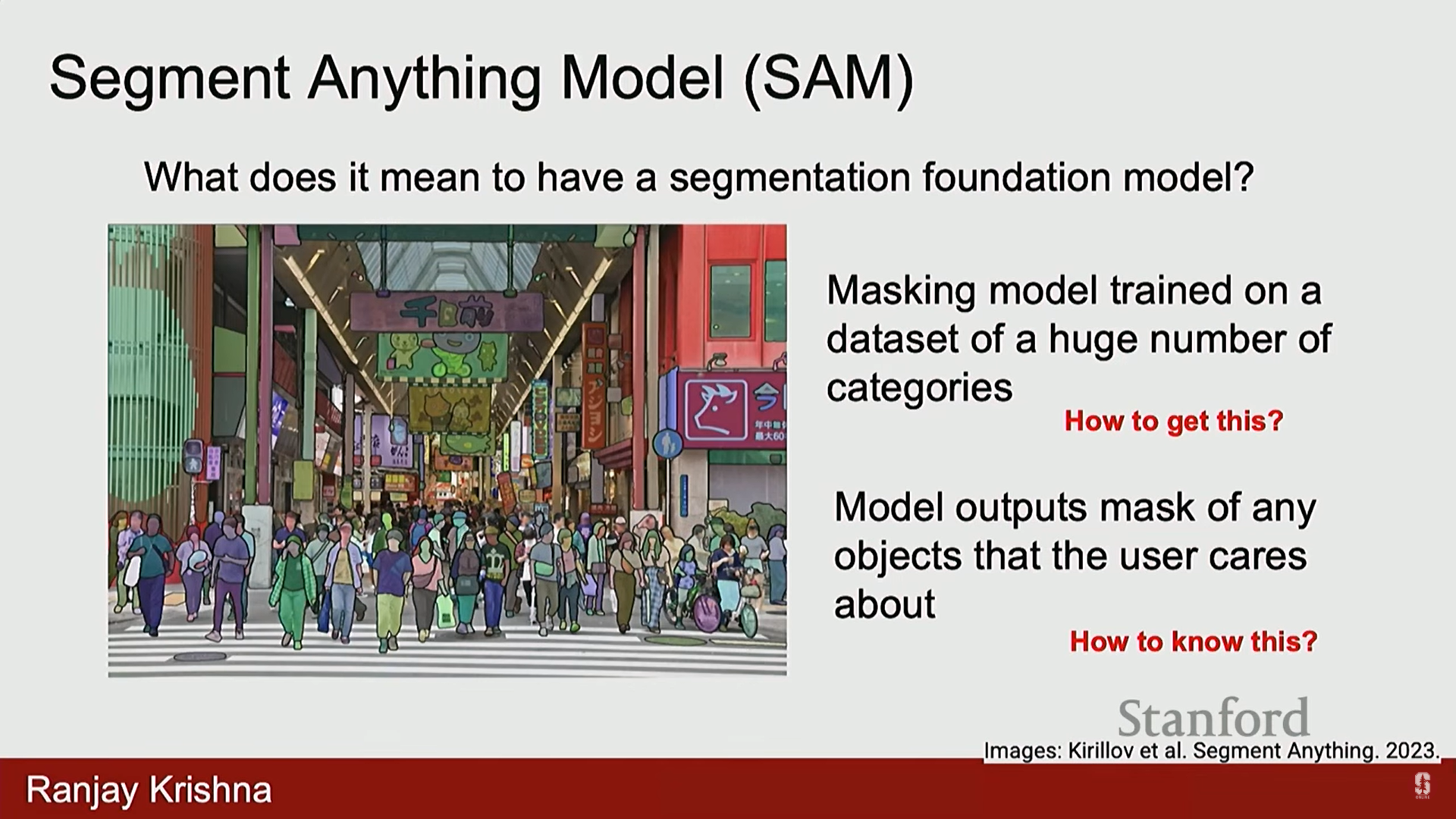
- 목표: 모든 분할(Segmentation) 태스크를 위한 파운데이션 모델 구축.
- 필요 능력: 고정된 카테고리가 아닌, 사용자가 원하는 모든 카테고리에 대해 마스크를 출력하는 능력.
- 아키텍처의 설계 과제: 사용자가 원하는 바를 정확히 핀포인트(pinpoint)하여 출력하도록 설계하는 것.
- 모호성 해결: 사용자의 요청(예: "고양이의 분할을 원한다" 또는 "가위의 마스크를 원한다")은 모호할 수 있습니다. 한 점을 찍어도 전체 객체인지, 일부인지 명확하지 않습니다.
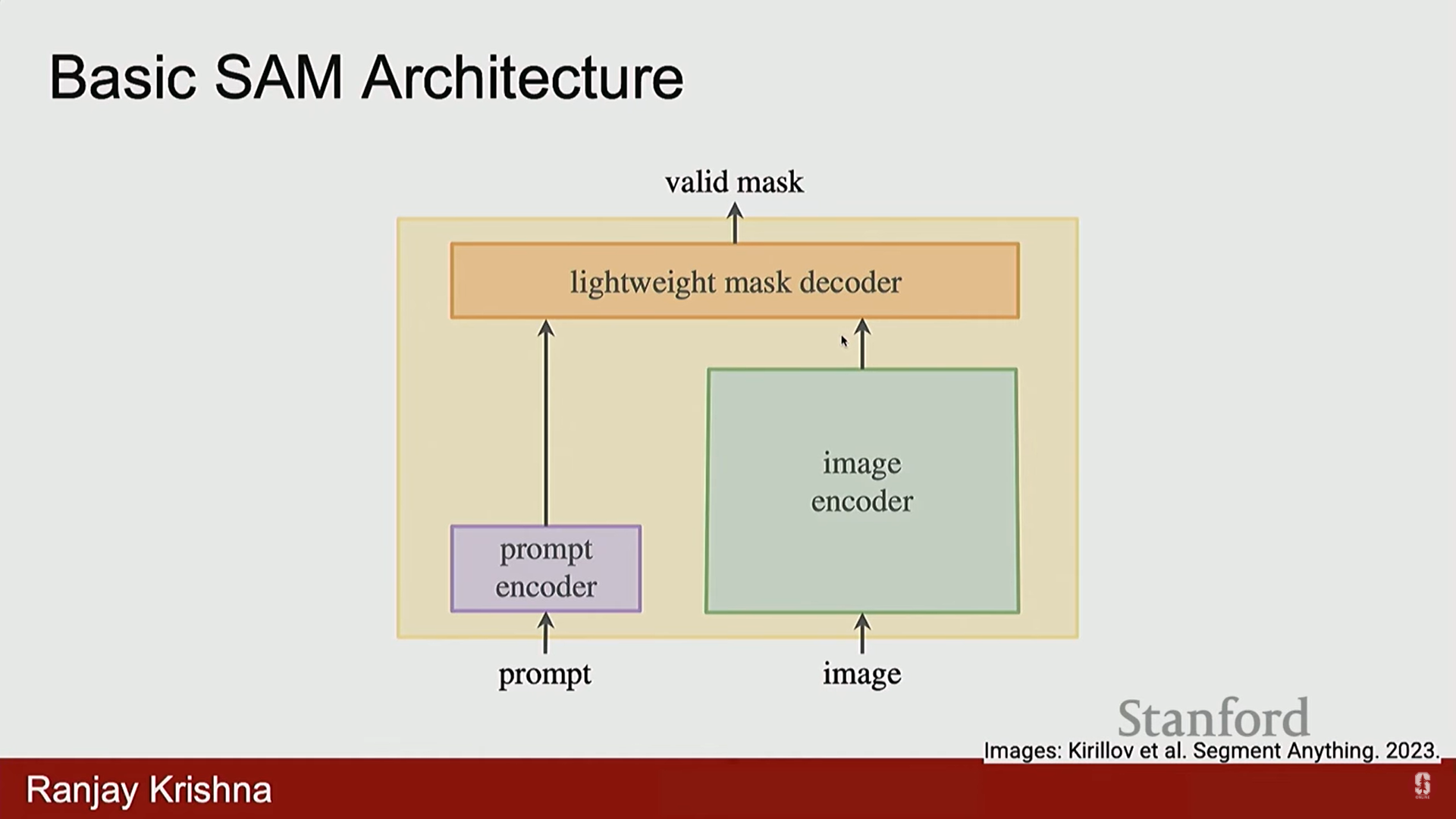
- SAM (Segment Anything Model) 구조:
- 이미지 인코더 (Image Encoder): 이미지 인코딩 (예: CLIP 인코더).
- 프롬프트 인코더 (Prompt Encoder): 사용자가 원하는 것을 명시하는 수단 (텍스트, 점, 경계 상자 등)을 인코딩합니다.
- 경량 디코더 (Lightweight Decoder): 마스크를 출력합니다.
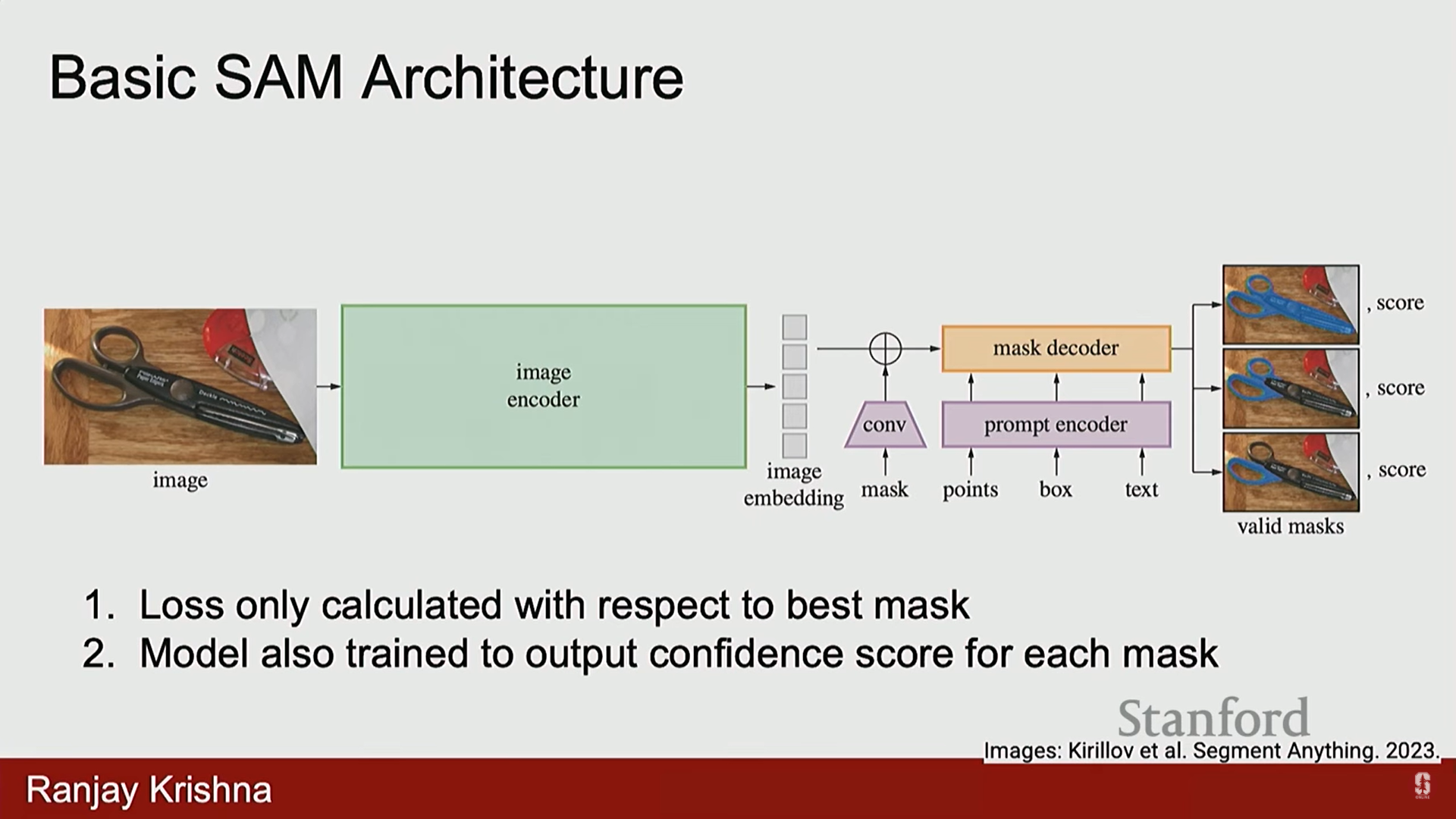
- 손실 계산 방식: 모호성을 해결하기 위해 서로 다른 세분성 (granularity) 수준의 마스크 세 개를 출력합니다. 이 중 정답(ground truth)에 가장 가까운 마스크를 선택하여 손실을 계산하고, 나머지 마스크에 대해서는 페널티를 주지 않습니다.
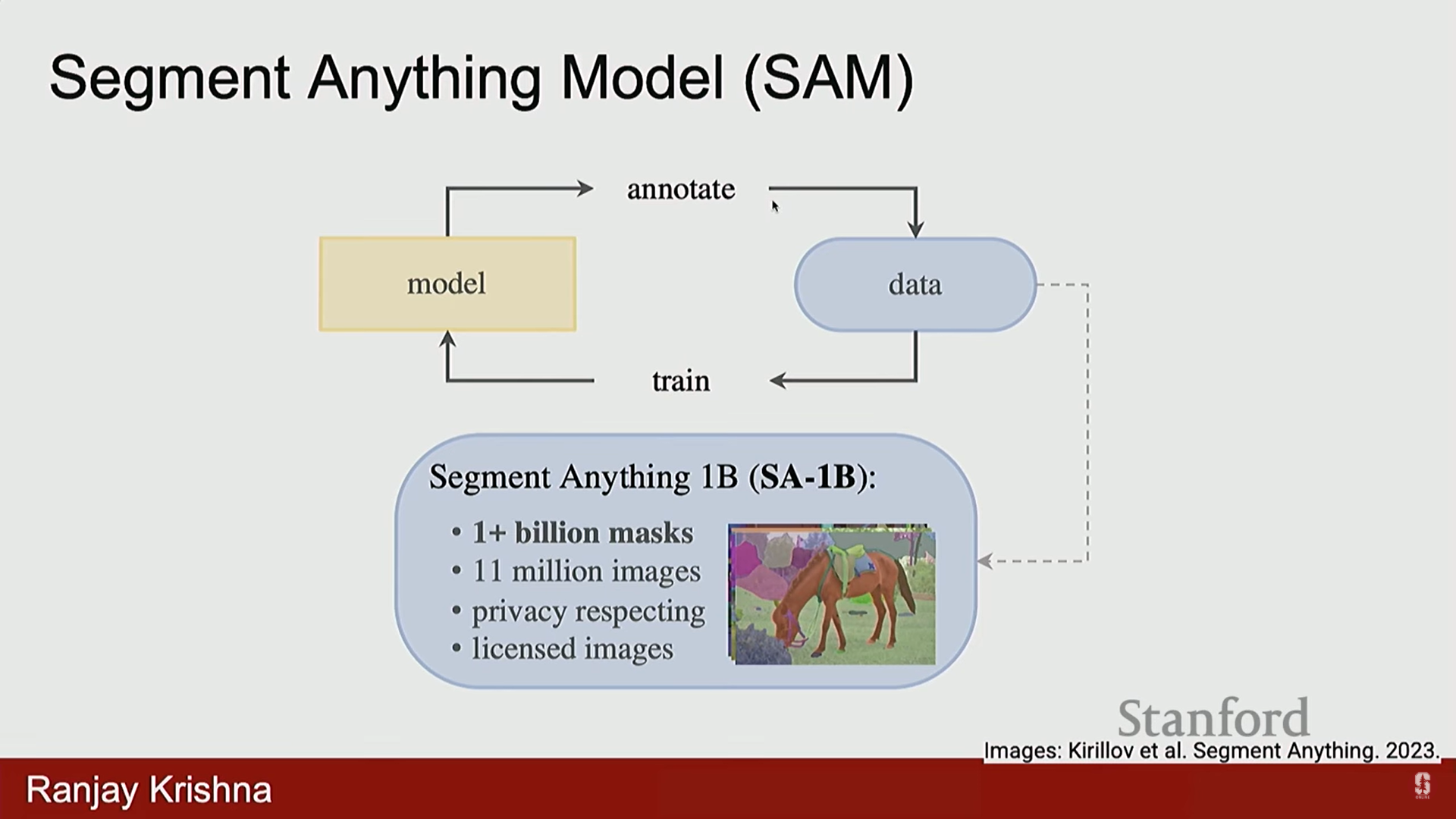
- 데이터 규모의 확보: SAM 출시 이전까지 분할 데이터셋은 매우 작았습니다. SAM 저자들은 이미지 수를 약 6배, 분할 마스크 수를 약 400배 (수백만 개의 이미지) 증가시켰습니다.
- 데이터 수집 방법: Human-in-the-Loop 프로세스를 사용하여 처음에는 주석이 달린 데이터를 기반으로 모델을 훈련하고, 이 모델이 제안한 세그먼트를 인간 주석가가 수정하는 방식으로 데이터를 반복적으로 정제했습니다.
- 핵심 메시지: 비전 태스크의 경우 인터넷에서 구할 수 없는 고품질의 데이터를 수집하는 것이 파운데이션 모델 성공에 필수적입니다.

5. 파운데이션 모델의 체인화 (Chaining Foundation Models)

- 개념: 단일 모델이 할 수 없는 기능을 구현하기 위해 여러 파운데이션 모델이나 소형 모델들을 결합하는 아이디어입니다.
- 예시 1 (제로샷 분류 강화): CLIP이 본 적 없는 전문적인 카테고리(예: 특정 꽃 종류, 견종)가 주어졌을 때, GPT가 해당 카테고리에 대한 설명을 생성하게 합니다. CLIP은 이 설명을 분류 가이드로 사용하여 정확도를 크게 향상시킬 수 있습니다.
- 예시 2 (복합 질문): "배에 세 사람이 있는가?" 와 같은 복잡한 질문에 답하기 위해, 객체 감지 모델과 같은 수백 개의 전문화된 비전 모델을 순차적으로 호출할 수 있습니다.


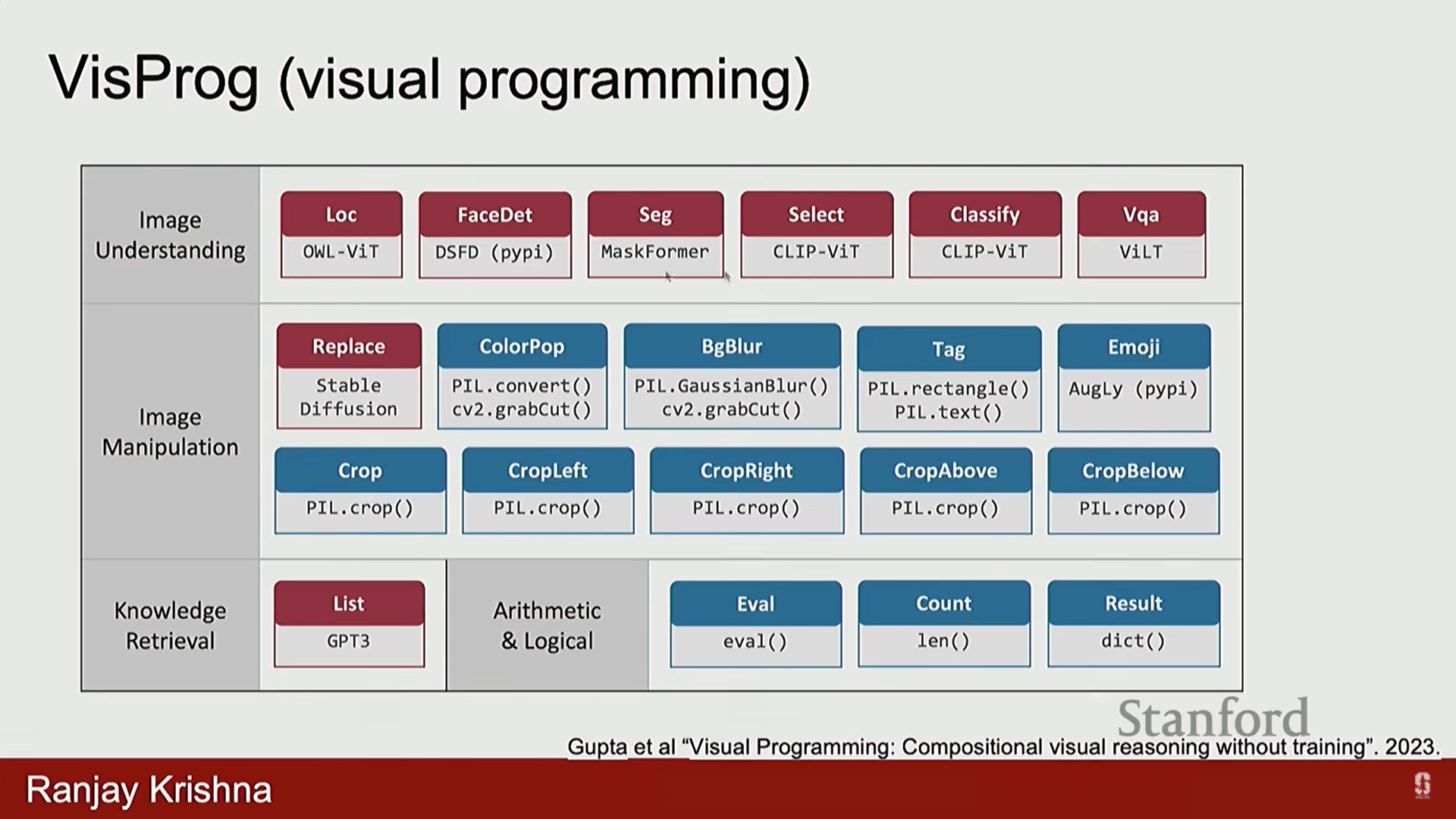
VisProg (Visual Programming)

- 개요: 작년도 Best Paper Award를 수상한 VisProg (Visual Programming)는 체인화를 대중화했습니다.
- 작동 방식: 이미지나 질문이 주어지면, LLM이 해당 질문에 답하기 위한 프로그램 (예: Python 함수)을 생성합니다.
- 이 프로그램은 이미 학습된 다른 모델들의 개별 함수 호출 (예:
localize_things,localize_faces)을 포함하며, 그 결과를 결합하여 최종 답변을 도출합니다.

- 이 프로그램은 이미 학습된 다른 모델들의 개별 함수 호출 (예:
- LLM의 역할: LLM에게 미리 객체 감지기, 얼굴 감지기 등 다른 모델이 제공하는 기능(함수)을 알려주면, LLM은 이를 활용하여 새로운 질문에 일반화된 프로그램을 생성합니다.
- 프로그램 생성 방식:
- 정적 방식: 다양한 예시를 제공하고 일반화를 기대합니다.
- 동적 방식: 질문에 따라 가장 적절한 인컨텍스트 예시를 검색(retrieval)하여 제공하고 프로그램 생성을 요청합니다. 이는 일반적으로 더 나은 성능을 보입니다.
- 한계점 (계산 복잡성): VisProg는 GPT 호출(API)과 개별 모델들을 순차적으로 메모리에 로드하고 실행해야 하므로 계산 비용이 매우 높습니다. 현재 연구는 이러한 기능을 단일 모델로 증류하는 데 집중하고 있습니다.
- 비유: VisProg는 주어진 질문에 대해 도움을 줄 다른 모델을 결정하고, 이들을 연결하는 에이전트 (Agent)와 같습니다.
- 응용 (로보틱스 및 이미지 편집): Momo의 포인팅 출력을 SAM 2의 입력으로 체인화하여 특정 객체의 분할을 얻거나, 로봇을 제어하는 복합 명령을 자동화할 수 있습니다. 또한 이미지 편집 시, 분할 모델로 사막 영역을 식별하고 해당 픽셀만 잔디로 대체하여 이미지를 합성할 수 있습니다.

6. 질의응답 (Q&A) 섹션
Q. CLIP이 ImageNet으로 훈련되었기 때문에 성능이 좋은 것인가요?
- A. ImageNet에서 잘 작동하는 것도 흥미롭지만, 더 흥미로운 점은 ObjectNet과 같이 CLIP이 이전에 보지 못했던, 도메인 외의 새로운 데이터셋에 잘 적응하고 일반화하는 능력입니다.
Q. 이미지 인코더의 출력 벡터는 무엇인가요?
- A. 사용하는 아키텍처에 따라 다릅니다. ResNet을 사용하는 경우 최종 벡터 표현을 취하고, VIT 또는 트랜스포머인 경우 일반적으로 CLS 토큰을 사용합니다.
Q. CLIP이 ImageNet으로만 훈련된 모델보다 더 잘 일반화하는 이유는 무엇인가요?
- A. 인터넷에서 다운로드한 텍스트에는 단순한 카테고리 레이블보다 훨씬 많은 구조적 정보(모양, 색상 등)가 포함되어 추가적인 지도 학습 효과를 제공하기 때문입니다. 또한 ImageNet보다 훨씬 큰 데이터 규모도 중요한 역할을 합니다.
Q. Flamingo에서 이미지는 연결(concatenated)되나요?
- A. 이미지가 직접 연결되지는 않습니다. 이미지 토큰은 퍼시버 샘플러를 통해 LLM의 모든 단일 레이어에 전달됩니다. 텍스트만 연결되어 입력으로 제공되며, 모델은 언제 어떤 이미지 부분에 주의를 기울일지 선택합니다.
Q. VisProg를 사용하는 것은 계산 비용이 많이 드나요?
- A. 그렇습니다. GPT 호출(API)뿐만 아니라, 각 개별 모델을 메모리에 로드하고 순차적으로 실행해야 하므로 비용이 많이 들 수 있습니다. 현재 연구는 이러한 기능을 단일 모델로 증류하는 방법을 모색하고 있습니다.
Q. Momo의 포인팅 기능이 환각(hallucinations)을 줄이는 데 도움이 되나요?
- A. 포인팅은 모델이 자신의 생성에 대한 증거를 찾도록 강제하므로 환각을 다소 줄이는 것으로 보입니다. 그러나 그것이 항상 올바른 것을 가리킨다는 보장은 없습니다. 대규모 모델을 사용하는 회사들은 보통 출력 후 이를 검증하는 검증기(verifiers)를 사용하여 이 문제를 완화합니다.
Q. 필요한 도구가 없을 때, 이 모델들이 새로운 도구를 구축할 수 있나요?
- A. 예, 초기 실험 단계에서는 모델이 필요한 도구가 무엇인지 인식하고, 자동으로 훈련 데이터를 수집하고 특정 사용 사례를 위한 도구를 구축하는 시스템을 만들 수 있습니다. 다만 이 연구는 아직 초기 단계에 있습니다.
Q. Momo는 포인팅 시 이미지 해상도가 변동하는 것을 처리할 수 있나요?
- A. 예. Flex ViT와 같은 메커니즘을 사용하면 가변 크기의 이미지 입력을 허용할 수 있습니다. 이미지 크기에 따라 모델의 위치 임베딩이 변경되며, 모델은 새로운 공간에서도 잘 일반화하는 경향이 있습니다.

AI 공부합니다