1. 개요
1) 강의 소개 및 로봇 학습의 배경
- 본 강의는 Columbia 대학교 컴퓨터 과학과 조교수이자 Robotic Perception, Interaction, and Learning Lab을 이끄는 Yunju Lee 박사가 진행했다.
- Yunju Lee 박사는 2023년에 CS231N 강사로 활동했으며, 그의 연구는 로봇 공학, 컴퓨터 비전, 머신러닝의 교차점에 있으며, 특히 로봇의 인지 및 물리적 상호작용 능력을 확장하는 로봇 학습(Robot Learning)에 초점을 맞춘다.
- 이번 강의에서는 로봇이 물리적 세계를 더 잘 인지하고 상호작용할 수 있도록 돕는 흥미로운 고려 사항과, 이러한 고려 사항들이 일반적인 컴퓨터 비전 작업 및 방법과 어떻게 다른지 논의한다.
- 로봇 학습은 최근 학계와 산업계 모두에서 큰 주목을 받고 있으며, Physical Intelligence, Tesla bots, Figure와 같은 스타트업들이 옷 접기, 커피콩 조작 등 복잡한 작업을 수행하는 로봇에 투자하고 있다.
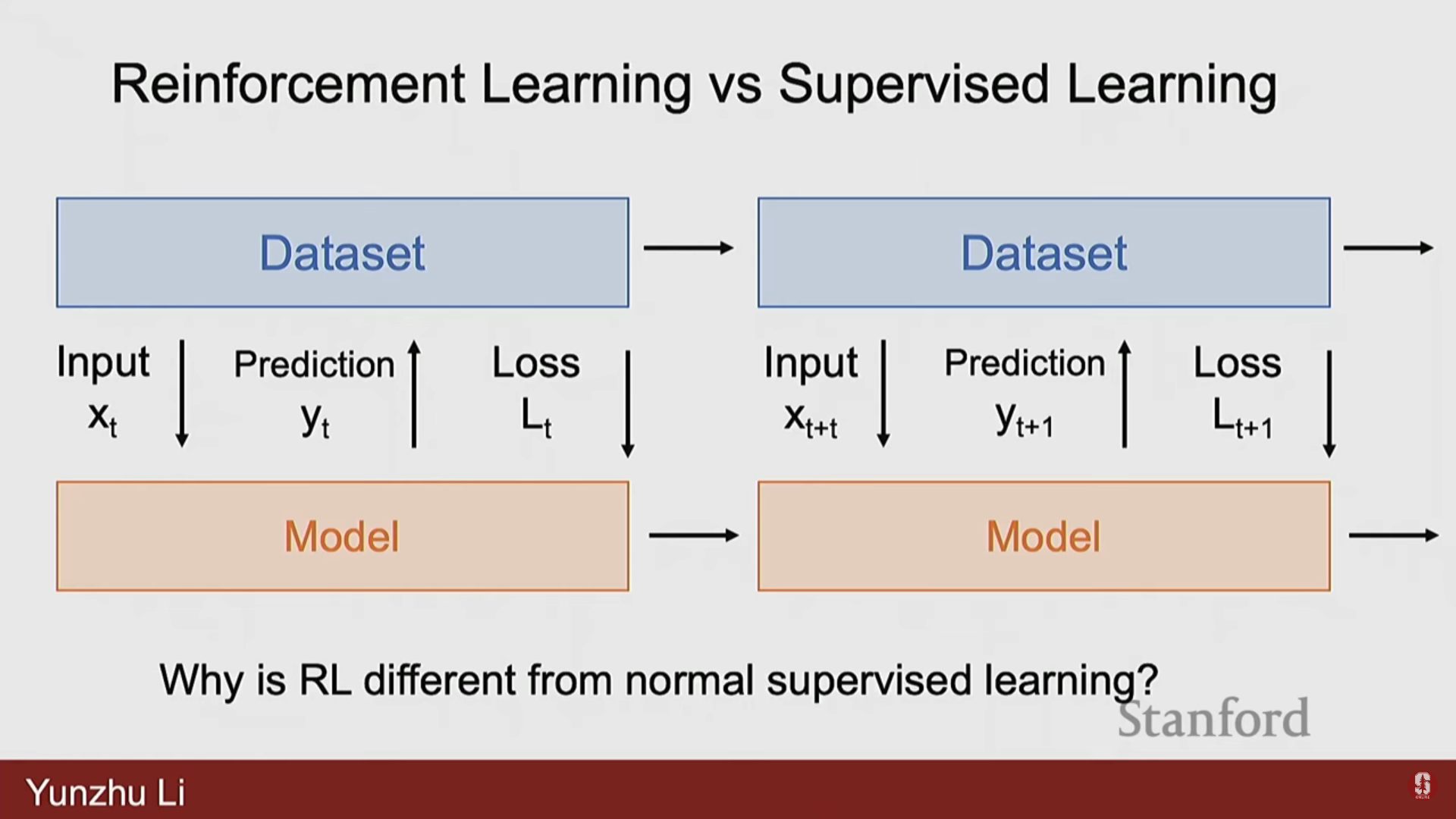
2) 지도 학습(Supervised Learning) 및 자기 지도 학습(Self-Supervised Learning)과의 차이점
-
지도 학습은 입력 와 레이블 가 주어졌을 때, 입력 를 출력 로 매핑하는 함수를 학습하는 방식이다 (예: 분류, 회귀, 객체 탐지).
-
자기 지도 학습/비지도 학습은 레이블 없이 데이터만 있을 때, 보조 손실(auxiliary loss) 설계를 통해 데이터의 내재된 숨겨진 구조를 추출하거나 식별하려고 시도한다 (예: 오토인코더(autoencoders)).
-
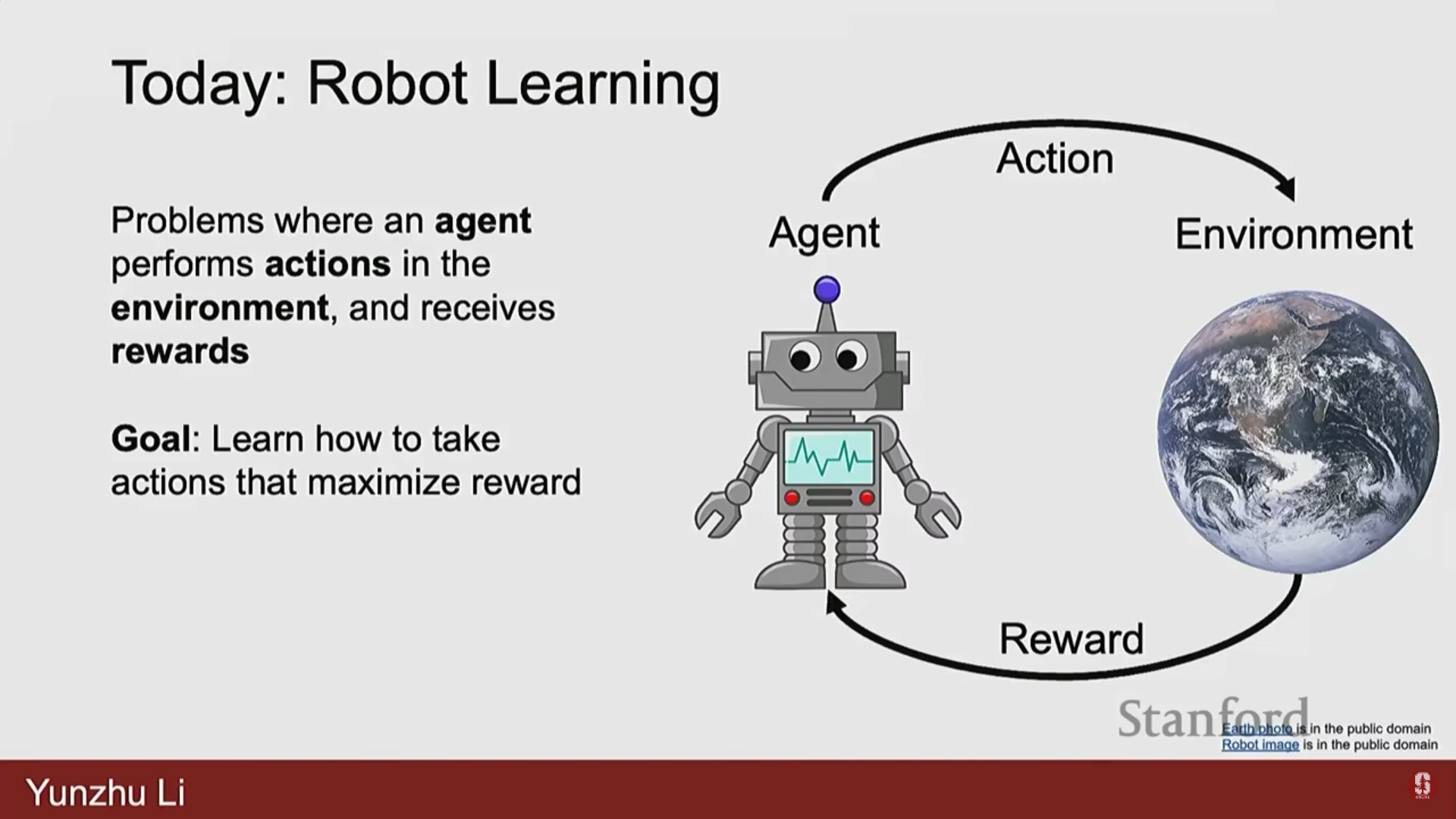
로봇 학습의 특수성: 로봇은 물리적 상호작용(physical interactions)을 수행해야 한다.
- 단순히 를 로 매핑하거나 잠재 표현을 학습하는 것이 아니다.
- 로봇이 취하는 모든 행동(action)은 환경의 변화(evolutions)에 영향을 미친다.
- 환경은 그 행동의 결과로 변화하며, 로봇에게 새로운 관찰(observations)이나 보상(reward)을 제공한다.
- 목표는 환경으로부터의 피드백을 통해 보상을 최대화하거나 비용을 최소화하는 일련의 행동을 찾는 것이다.

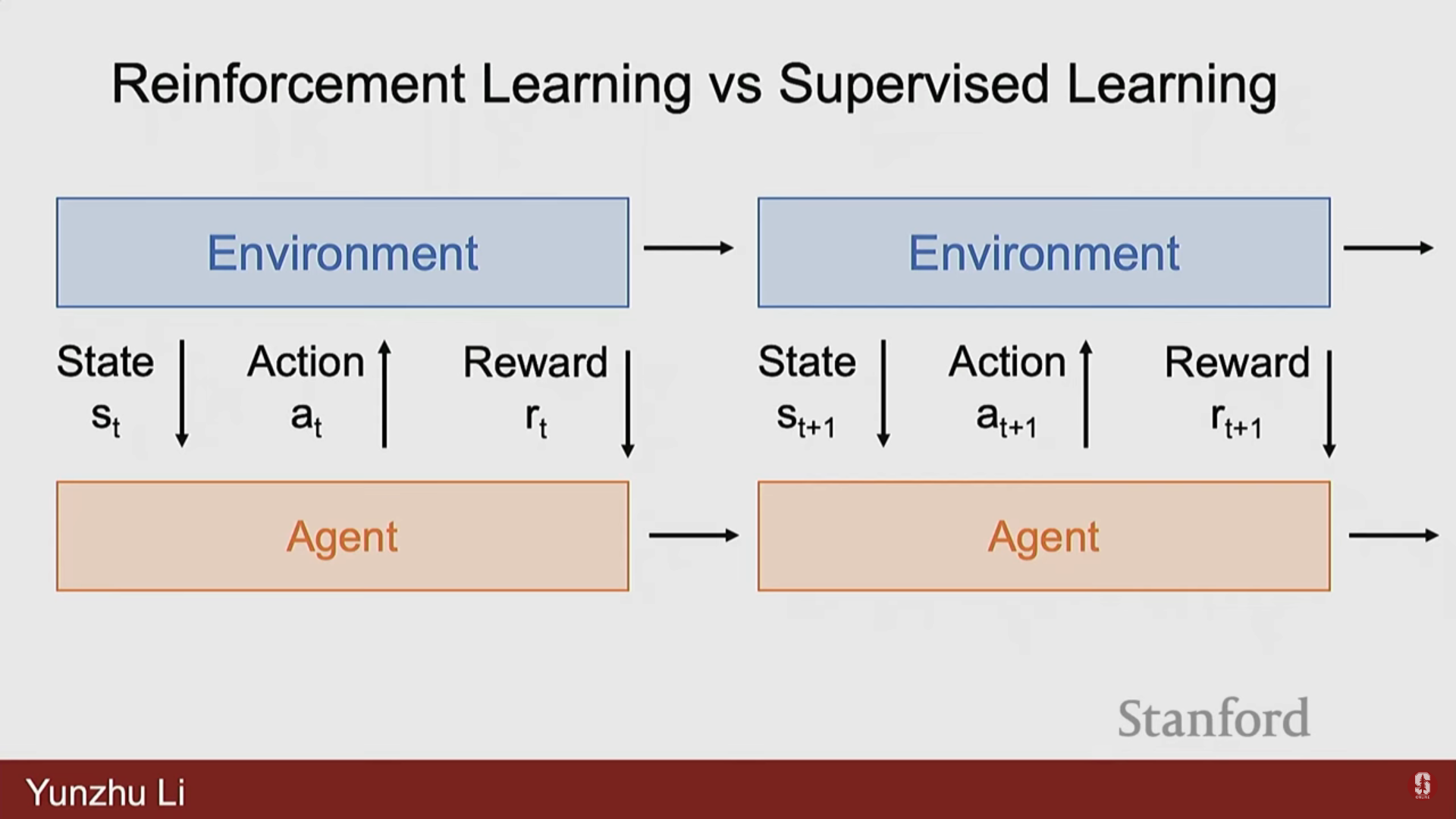
2. 로봇 학습 문제의 공식화 (Problem Formulation)
1) 일반적인 프레임워크
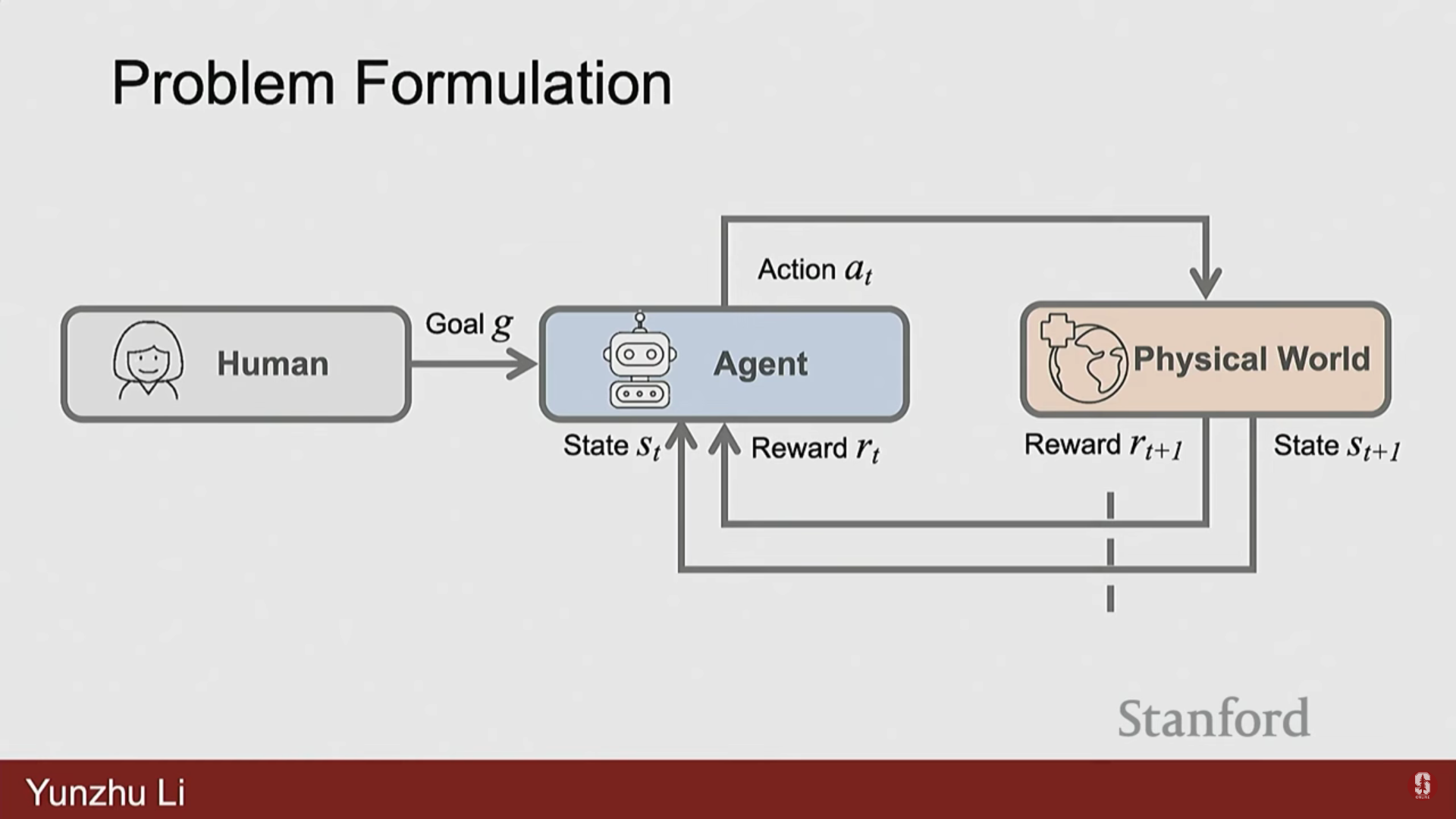
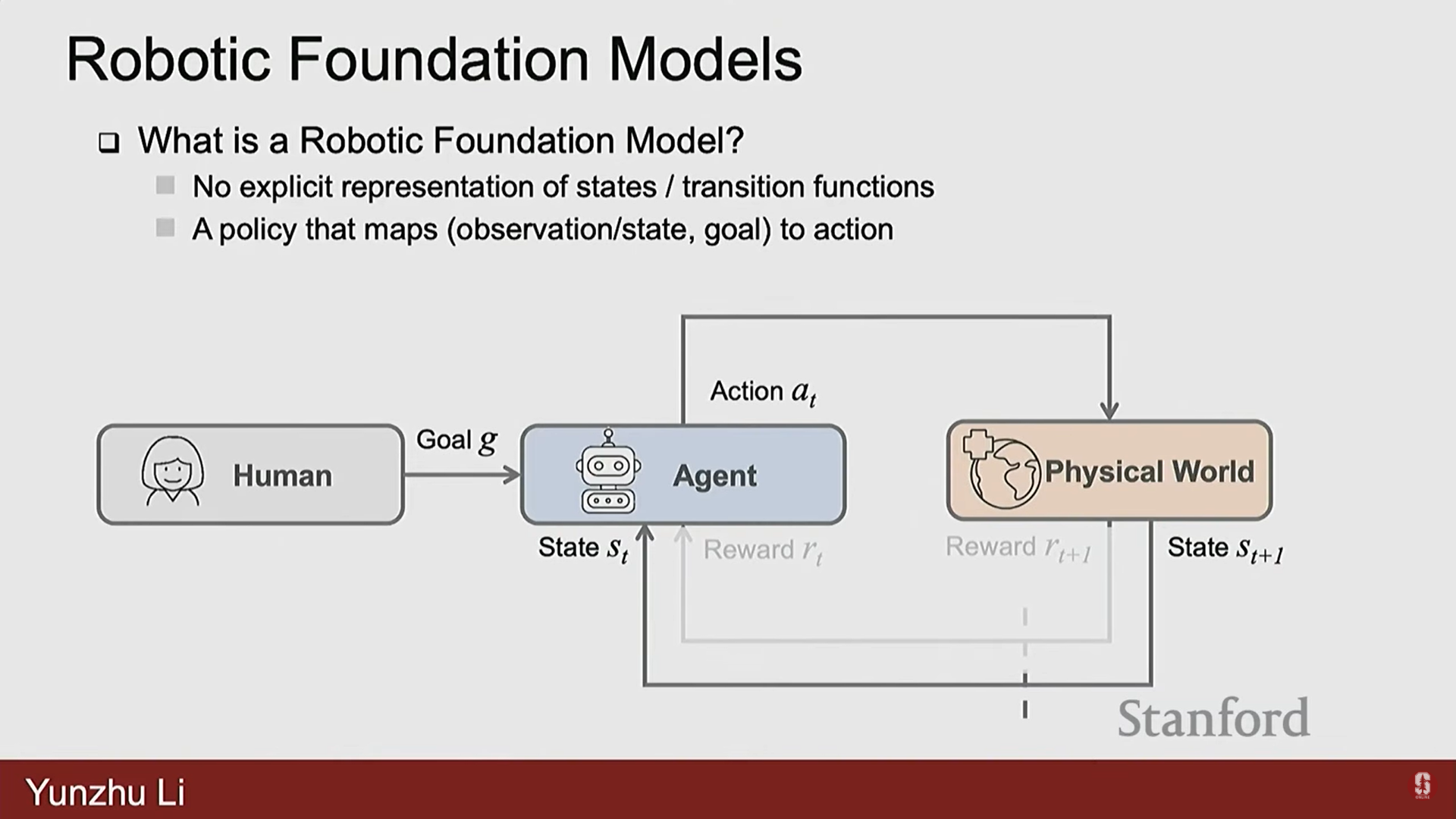
- 로봇 학습 프레임워크는 목표(goal), 상태(states), 행동(actions), 보상(rewards)으로 구성된다.
- 중앙에는 에이전트(Agent)가 있으며, 이는 인간의 언어 지침이나 목표 함수(objective function) 형태로 주어진 과제 목표(task objective)를 가지고 있다.
- 에이전트는 물리적 세계(환경)로부터 상태()를 받고, 물리적 세계에서 실행되어야 할 행동()을 결정한다.
- 물리적 세계는 업데이트되어 에이전트에게 새로운 상태 와 임무 수행의 성공 여부를 알려주는 보상(Rewards)을 제공한다.
- 핵심 차이: 컴퓨터 비전이 주로 입력에 기반한 환경의 표현을 학습하는 것이라면, 로봇 공학은 물리적 세계라는 제약 조건(constraints)과 목표에 의해 정의된 목표 함수(objective functions)를 가진 최적화 문제를 일련의 행동을 통해 푸는 것이다.
2) 구체적인 예시
- 카트 폴(CartPole):
- 목표: 움직이는 카트 위에 막대를 균형 있게 세우는 것.
- 상태: 시스템의 물리적 상태 (각도, 각속도, 위치, 수평 속도 등).
- 행동: 카트에 적용되는 수평 힘.
- 보상: 매 시간 단계마다 막대가 수직 상태로 유지되면 1.
- 로봇 이동(Robots Locomotion):
- 목표: 로봇이 앞으로 이동하게 하는 것.
- 상태: 로봇 내 모든 관절의 각도, 위치, 속도.
- 행동: 각 관절에 적용되는 토크(torque).
- 보상: 로봇이 한 걸음 앞으로 나아가고 똑바로 서 있을 때마다 1.
- 아타리 게임(Atari Games):
- 목표: 가능한 가장 높은 점수로 게임을 완료하는 것.
- 상태: 게임 화면의 원시 픽셀 입력.
- 행동: 게임 컨트롤 (상, 하, 좌, 우).
- 보상: 매 시간 단계마다 점수의 증감.
- 바둑(Go):
- 목표: 게임에서 이기는 것.
- 상태: 현재 바둑판 위의 모든 돌.
- 행동: 다음 돌을 놓을 위치.
- 보상: 마지막 턴에 이기면 1, 지면 0.
- 대규모 언어 모델(Large Language Models)의 순차적 생성:
- 목표: 다음 단어를 예측하는 것.
- 상태: 문장 내 현재 단어들.
- 행동: 넣고 싶은 특정 다음 단어.
- 보상: 정확하면 보상, 부정확하면 0.
- 챗봇(Chatbots):
- 목표: 인간 사용자에게 좋은 동반자가 되는 것.
- 상태: 현재의 대화.
- 행동: 인간 사용자에게 줄 다음 문장.
- 보상: 인간 평가에 따라 사용자가 만족하면 1.
- 로봇 도메인 (옷 접기):
- 목표: 옷을 깔끔하게 접는 것.
- 상태: 환경에서 로봇이 얻는 현재 관찰 (다중 뷰 RGB 또는 RGBD 관찰).
- 행동: 로봇의 이동 방향, 그리퍼를 닫거나 여는 등의 조작 방식.
- 보상: 인간 평가에 따라 옷이 제대로 접히면 1, 아니면 0.
3) 보상 설계의 복잡성
- 보상(Reward)은 매우 구체적으로 설계되어야 한다.
- 예를 들어, 자율 주행에서 보상은 '가능한 한 빠르게'일 수도 있고 '승객이 편안함을 느끼도록'일 수도 있다.
- 옷 접기의 경우에도 사용자의 선호도에 따라 '총면적이 가장 작게' 또는 '가능한 한 주름 없이 매끄럽게' 등 다양한 보상이 존재할 수 있다.
- 보상 설계에는 특정 애플리케이션의 요구 사항을 충족시키기 위한 많은 뉘앙스(nuances)가 있다.
3. 로봇 인지 (Robot Perception)
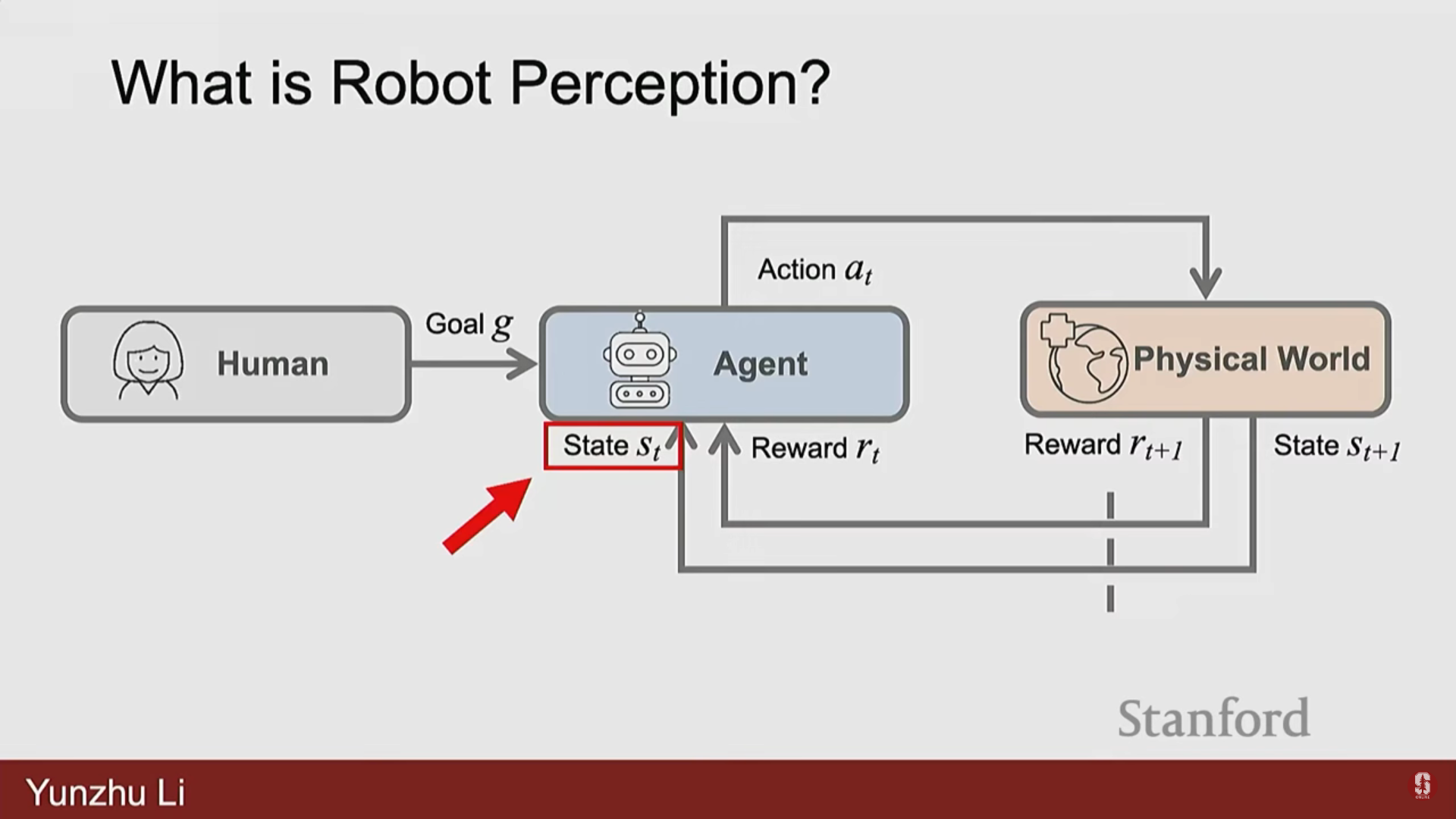
1) 컴퓨터 비전(CV)과의 차별성
- 로봇 인지 문제는 물리적 세계로부터 얻는 정보(고차원 RGB/RGBD, 촉각 센싱 등)에서 로봇의 다운스트림 의사 결정(downstream decision-making)에 유용한 구조화된 지식을 추출하는 것이다.
- 목표는 이 비정형적인 실제 세계(unstructured real world)를 파악하는 것이다.


2) 로봇 인지의 도전 과제
- 불완전한 지식: 환경으로부터 얻는 관찰에는 객체와 환경에 대한 불완전한 지식만이 포함될 수 있다 (가림/오류).
- 불완전한 행동: 불완전한 행동은 실패로 이어질 수 있으며 (예: 잡은 물체를 실수로 떨어뜨림), 이는 환경의 예기치 않은 변화를 초래한다.
- 역동적인 환경: 환경은 동적이며 단단한 물체뿐만 아니라 변형 가능한 물체(deformable object), 옷, 액체 등 다양한 요소를 포함하며, 다른 에이전트(사람, 개)도 존재할 수 있다.
3) 다중 센서 통합의 중요성
- 로봇 공학에서는 일반적으로 카메라 데이터 외에도 가능한 한 많은 유용한 정보를 제공하는 센서를 추가하려고 한다.
- 촉각 센싱(tactile sensing), 오디오 정보(audio information), 깊이 정보(depth informations) 등이 포함된다.
- 이러한 센서들이 어떻게 서로를 보완하며 함께 작동할 수 있도록 시스템을 설계하는 것이 매우 중요하다.
- 오디오는 물리적 접촉 정보를, 촉각은 파악의 안정성(grasp stability)을, 카메라는 환경의 전반적인 상태와 같은 고수준 정보를 제공한다.
4) 행동의 영향과 어포던스 이해
- 로봇 비전과 컴퓨터 비전의 매우 중요한 차이점은 행동의 영향(the effect of an actions)과 환경의 어포던스(affordance)를 이해하는 것이다.
- 일반적인 CV는 2D 이미지에서 인스턴스 분할(instance segmentation)을 수행하지만, 로봇은 환경을 더 잘 인지하기 위해 어떤 행동을 취해야 하는지 알아야 한다.
- 예를 들어, 로봇은 어떤 물체가 하나의 덩어리인지 여러 조각이 쌓여 있는지 알기 위해 능동적으로 상호작용하며 물체를 교란시키는(perturb) 행동을 할 수 있어야 한다.
5) 로봇 비전의 세 가지 특성 (Embodied, Active, Situated)
로봇 비전은 일반적인 CV와 달리 다음 세 가지 특성을 갖는다:
1. 구체화(Embodied): 로봇은 물리적 몸체를 가지고 있으며 물리적 세계를 직접 경험한다.
- 로봇의 행동은 세계와의 역동적인 부분이며, 자신의 감각에 즉각적인 피드백을 갖는다.
2. 능동적(Active): 로봇은 능동적인 지각자(active perceivers)이다.
- 로봇은 무엇을 감지하고 싶어 하는지 알고, 무엇을 인지할지 선택하며, 언제, 어디서 그 인지를 달성할지 결정한다 (예: 머리를 움직여 테이블 뒤를 확인).
- 이는 수동적으로 수집된 데이터 세트로 작업하는 일반적인 CV와 다르다.
3. 상황 기반(Situated): 로봇은 세계 안에 위치한다.
- 로봇은 추상적인 설명이 아닌, 세계의 '여기, 지금(here and now)'을 다루며, 이는 시스템의 행동에 직접적인 영향을 미친다.
- 로봇은 인지와 행동 루프를 닫기 위해 세계를 보고 목표를 이해하며 인지 기반으로 환경에서 행동할 수 있어야 한다.
- 때로는 환경의 전체 상태를 알 필요 없이, 작업 관련 영역(task relevant regions)에만 집중하여 인지와 행동 루프를 닫아야 한다.
4. 행동 학습 알고리즘: 강화 학습 (Reinforcement Learning, RL)
1) 강화 학습의 기본 아이디어
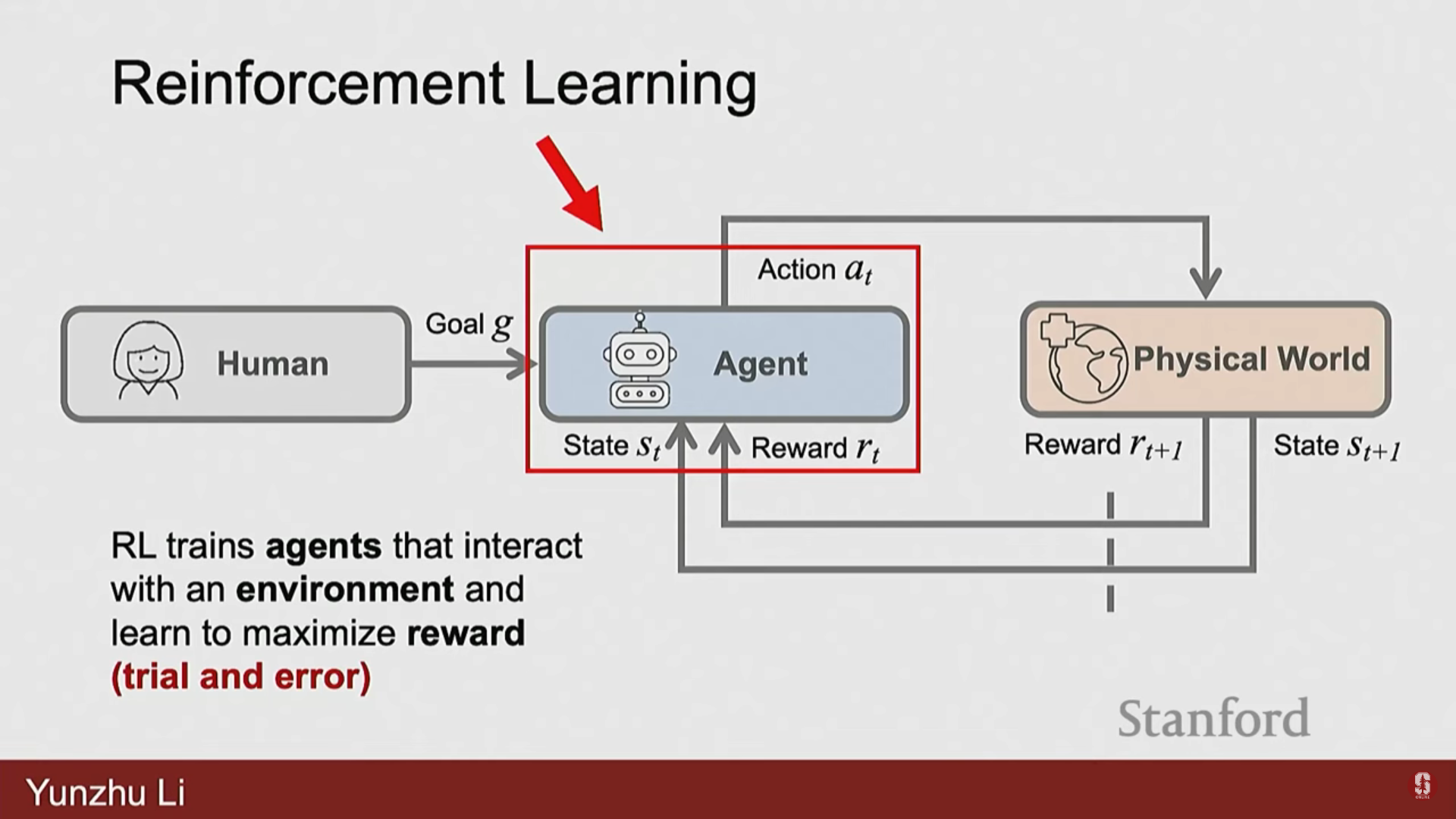
- RL은 에이전트가 환경과 광범위하게 상호작용하고 경험 데이터를 수집하여 시행착오(trials and errors)를 통해 행동이 더 높은 보상으로 이어진다는 것을 이해하게 하는 방식이다.
- 목표는 에이전트의 행동을 더 높은 보상을 주는 방향으로 조정하여 보상을 최대화하거나 비용을 최소화하는 것이다.
- RL은 에이전트가 순차적 의사 결정(sequential decisions)을 내려야 하는 시간적 순서(temporal sequence)의 문제이다.
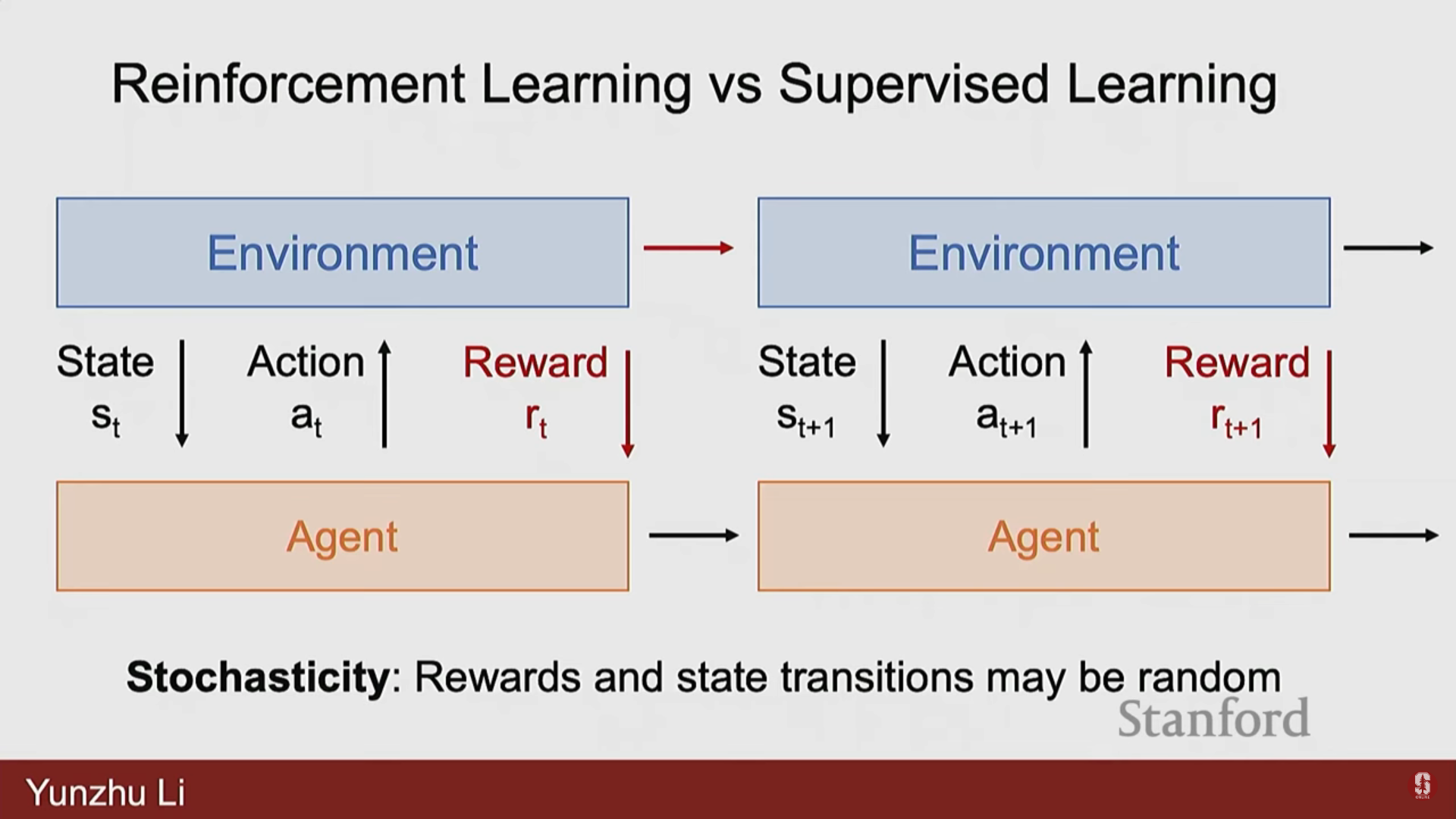
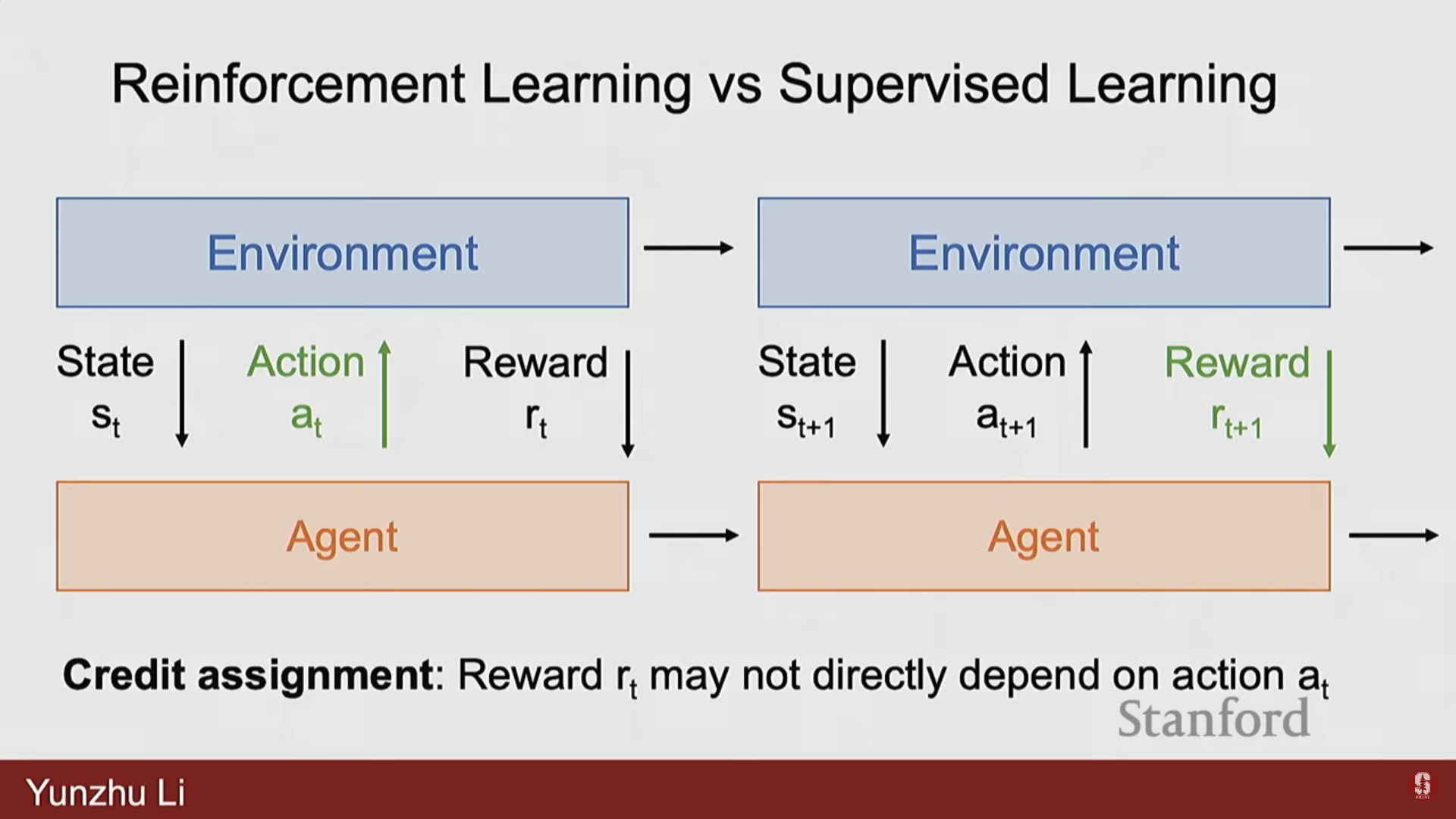
2) 지도 학습(SL)과의 핵심 차이점
| 특징 | 강화 학습 (RL) | 지도 학습 (SL) |
|---|---|---|
| 환경 동역학 | 확률적(Stochastic)이며 불확실한 역동적 시스템을 다룬다. 같은 행동이 다른 결과를 초래할 수 있다 (예: 상자를 미는 방향). | 환경은 확정적(Deterministic)이다. |
| 크레딧 할당 (Credit Assignment) | 보상이 지연될 수 있다 (Delayed Rewards). 에피소드가 끝날 때까지 보상을 알 수 없으며 (예: 바둑), 초기의 어떤 행동 때문에 보상이 발생했는지 파악하기 어렵다. | 입력에 대한 출력 예측 후 즉시 손실을 계산하여 실수와 오류를 직접 안다. |
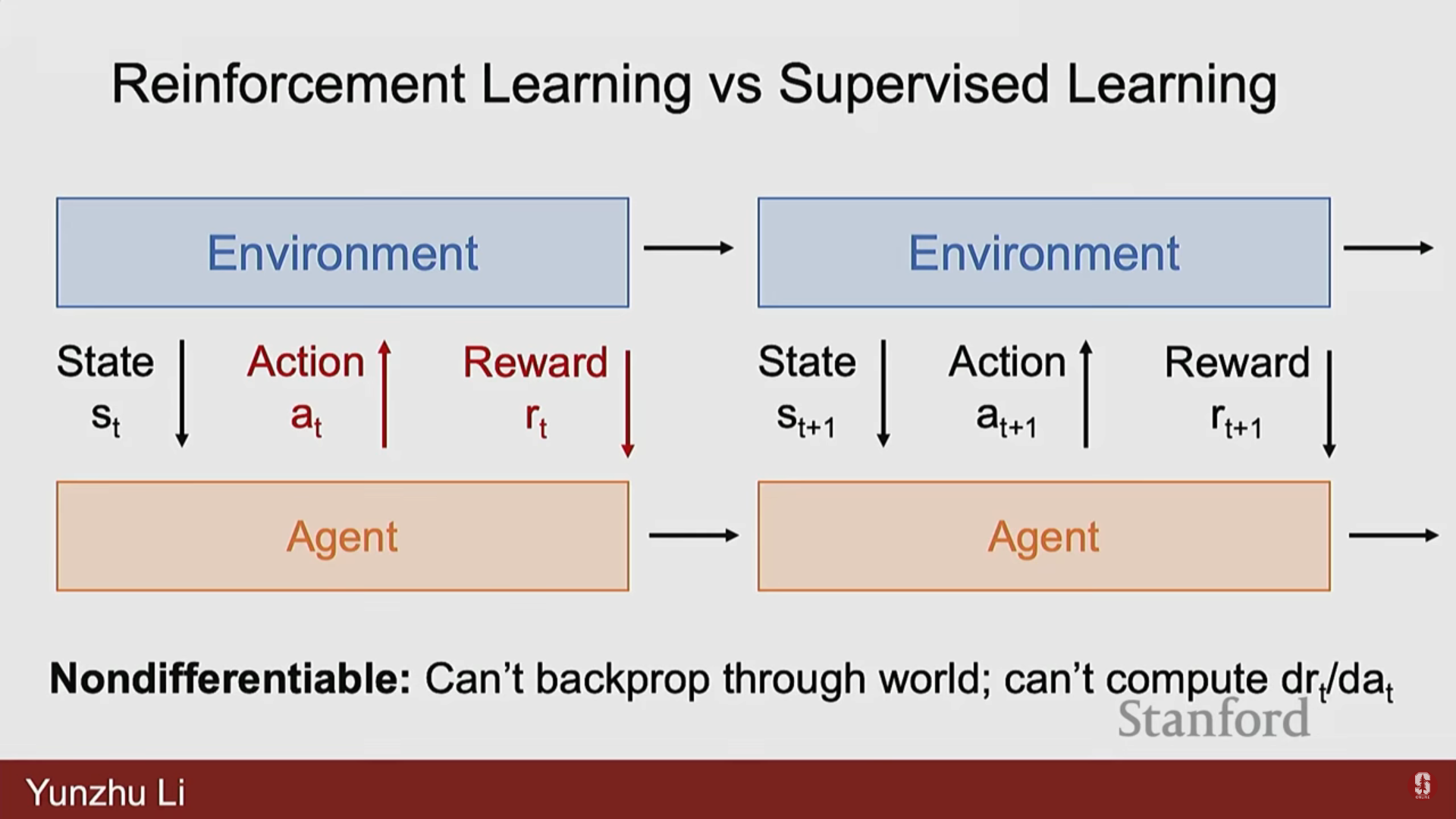
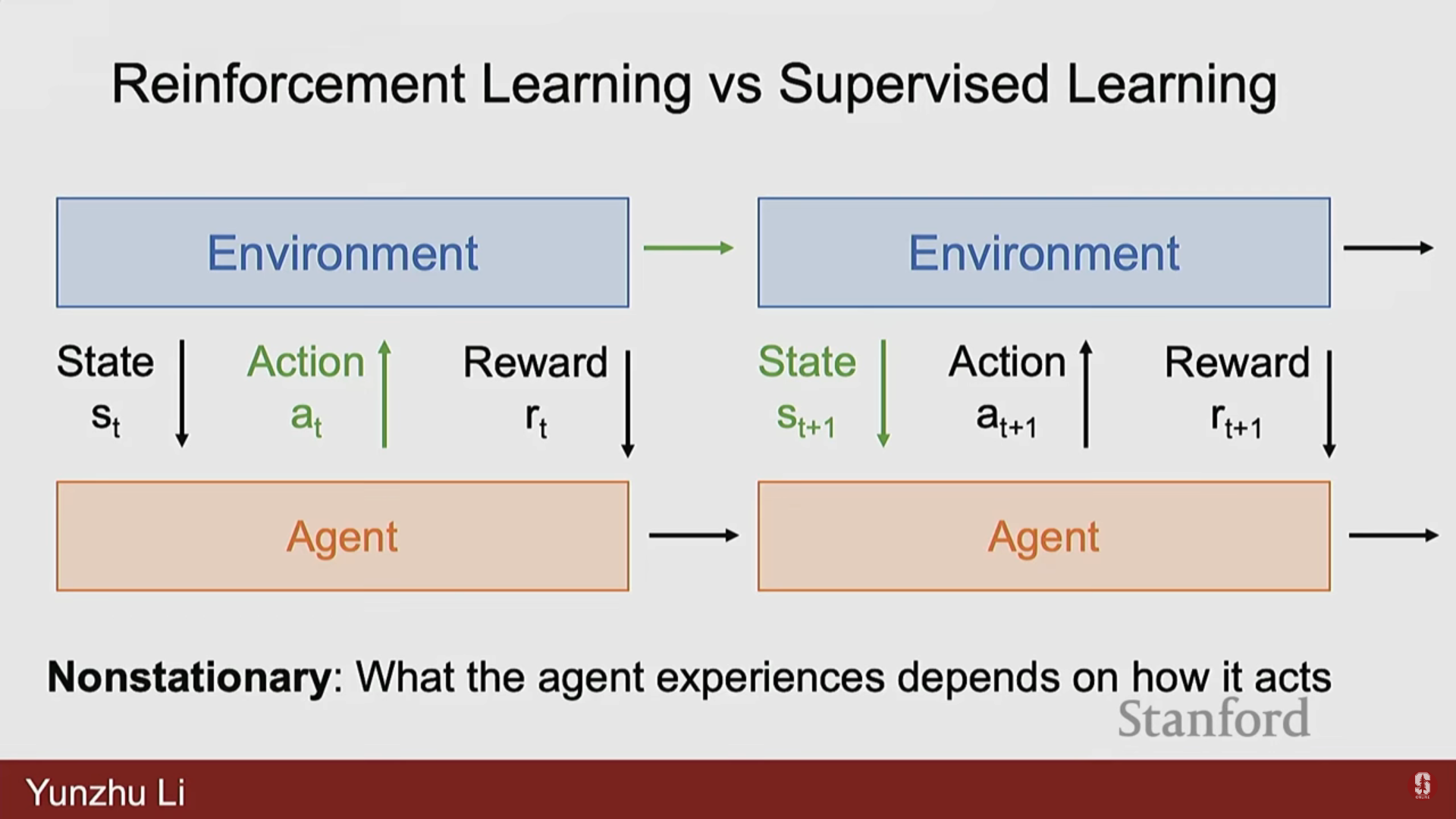
| 미분 가능성 (Differentiability) | 환경이 미분 불가능(non-differentiable)한 경우가 많아, 보상의 기울기를 행동에 대해 얻기 어렵다. 때로는 대규모 샘플링을 통한 0차 추정(zeros order estimations)에 의존해야 한다. | 전체 과정이 미분 가능하여 손실 함수를 모델 파라미터에 대해 직접 미분할 수 있다. |
| 정지성 (Stationarity) | 에이전트의 행동이 다음에 얻게 될 상태에 영향을 미치므로 비정상적(non-stationary)이다. | 에이전트의 예측이 다른 데이터 포인트에 영향을 미치지 않으므로 정지적이다. |
3) Q-함수와 수학적 개념 (Q-Function)
- 강화 학습 알고리즘 중 하나는 Q-함수(Q-function)를 학습하는 것이다.
- Q-함수는 특정 상태 에서 특정 행동 를 적용했을 때 얻을 수 있는 할인된(discounted) 예상 누적 미래 보상을 측정한다.
- Q-함수를 학습한 후에는, 주어진 상태에서 Q 값이 가장 높은 행동을 실행하여 의사 결정을 내린다.
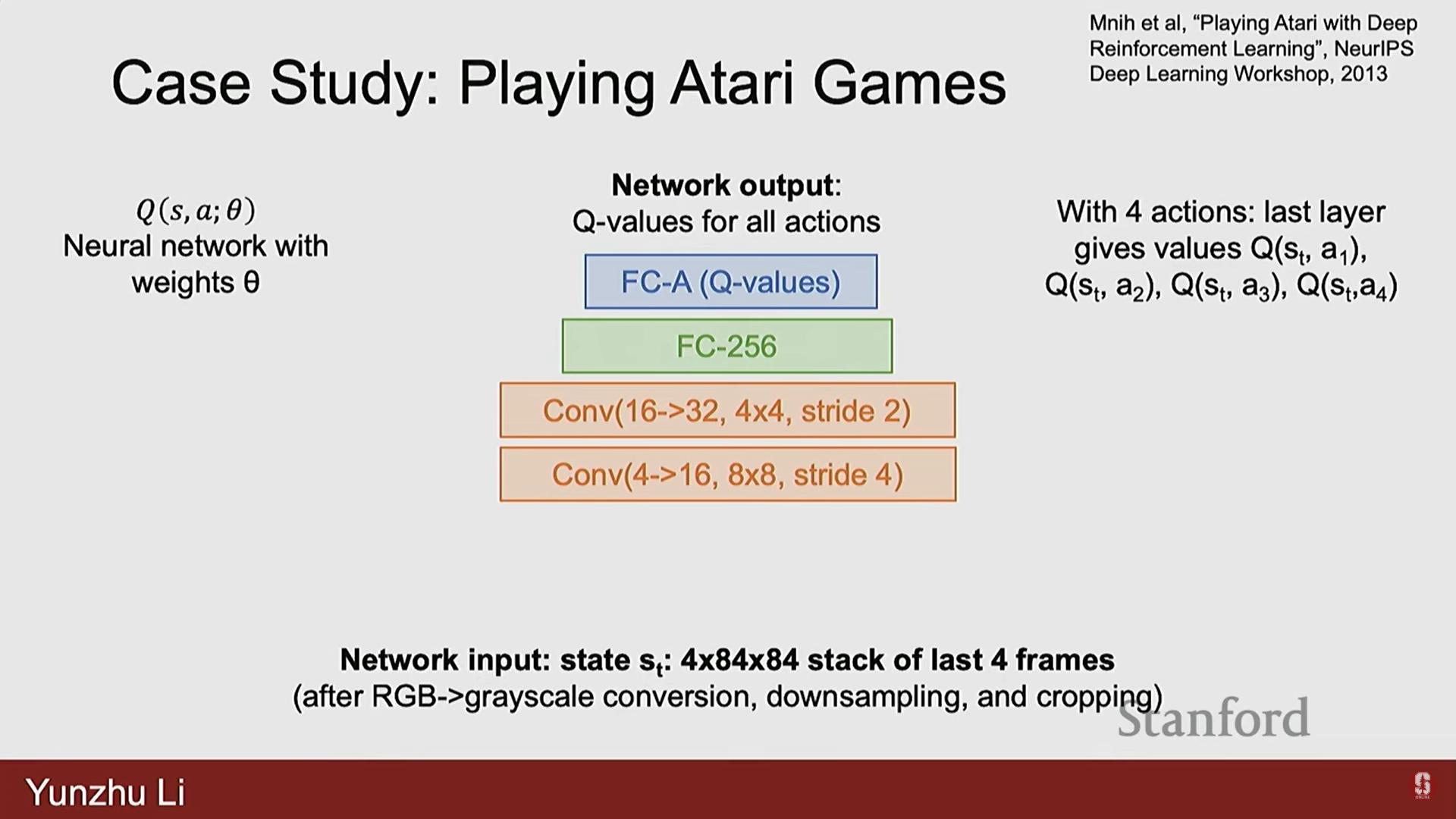
- Q-함수의 뉴럴 네트워크 구현:
- Q-함수는 뉴럴 네트워크로 구현된다.
- 입력: 상태 (예: 게임 화면의 원시 픽셀 입력 4프레임).
- 이미지 처리를 위해 합성곱 신경망(Convolutional Neural Networks, CNN) 레이어를 사용한 후, 완전 연결 계층을 통해 Q 값을 도출한다.
- 출력: 이산적인 행동(예: 상, 하, 좌, 우 4개)에 대한 Q 값 예측.
4) RL의 성공 사례 및 심화 내용
- Atari Breakout 게임: 훈련 4시간 후 에이전트가 벽 왼쪽 상단에 터널을 만들어 효율적으로 벽돌을 제거하는 새로운 전략을 발견하는 등, RL은 광범위한 탐색을 통해 인간 플레이어보다 나은 전략을 발견할 수 있다.
- AlphaGo와 강화 학습의 발전:
- 2016년 AlphaGo의 등장은 많은 연구자들을 의사 결정 문제(Decision-Making problems)로 이끌었다.
- 이후 AlphaGo Zero는 초기화에 모방 학습(Imitation Learning)을 사용하지 않고도 당대 최고의 인간 플레이어를 이겼다.
- 심화: 이는 Rich Sutton의 "Bitter Lesson"이라는 교훈을 보여준다. 때로는 스케일링에 가장 잘 호환되는 가장 단순한 레시피를 찾는 것이 더 나은 성능을 제공할 수 있다. 인프라를 활용한 스케일링의 힘을 활용하는 것이 중요하다.
- Alpha Zero는 동일한 알고리즘 세트를 바둑뿐 아니라 체스, 쇼기 같은 다른 게임으로 일반화했다.
- Muzero는 모델 프리(model free) RL을 넘어 잠재 공간 역학 모델(latent space dynamics models)을 학습하여 계획(planning)을 수행하여 더 나은 성능을 보였다.
- 2019년 이세돌 9단이 은퇴하며 인간 플레이어가 최고의 AI 에이전트를 이기는 것이 불가능하다는 점을 인정했다.
- 최신 동향: 스타크래프트나 도타 2와 같이 바둑보다 훨씬 복잡한 게임에서도 충분한 컴퓨팅 자원과 잘 설계된 알고리즘이 투입되면 강력한 게임 에이전트를 만들 수 있음이 입증되었다.
- 실제 물리적 세계에서의 RL:
- ETH의 2020년 연구는 시뮬레이션에서 훈련된 RL 에이전트가 눈이나 미끄러운 표면 같은 현실 세계 환경에서 매우 강건한 성능(robust performance)을 보일 수 있음을 입증하며, Sim-to-Real 갭이 때로는 중요하지 않을 수 있다는 가능성을 보여주었다.
- Unitree의 최근 영상은 매우 험난한 지형을 탐색하는 등 로봇 이동(locomotion) 분야에서 RL을 통해 Sim-to-Real 전이가 매우 성공적임을 보여주었다. 로봇 이동 영역은 RL을 통해 거의 해결된 문제로 간주된다.
- 조작(Manipulations): OpenAI의 2019년 루빅스 큐브 조작 시스템은 RL과 Sim-to-Real 전이를 사용했지만, 성공률이 매우 낮았다. 이후 발전이 있었지만, 여전히 격리된 환경 내에서 작동하는 경우가 많다.
5) 모델 프리 RL의 한계점
- 광범위한 상호작용 필요: 환경과의 시행착오를 통해 학습하기 때문에, 광범위한 상호작용이 필요하다.
- AlphaGo Zero는 40일 만에 3,000년의 인간 지식에 해당하는 컴퓨팅 시간을 요구했다.
- Sim-to-Real 갭이 커서 실제 세계에서 학습해야 하는 경우, 이는 엄청난 병목 현상이 된다.
- 안전 문제: 실제 물리 로봇에 적용할 경우, 학습 과정 중에 매우 이상한 행동을 보이며 치명적인 실패로 이어질 수 있는 안전 문제(safety concerns)가 발생한다.
- 제한된 해석 가능성 및 수정의 어려움: 잘못되었을 때 수정하기가 매우 어렵고 해석 가능성(interpretabilities)이 제한적이다.

5. 모델 학습 및 모델 기반 계획 (Model Learning and Model-Based Planning)
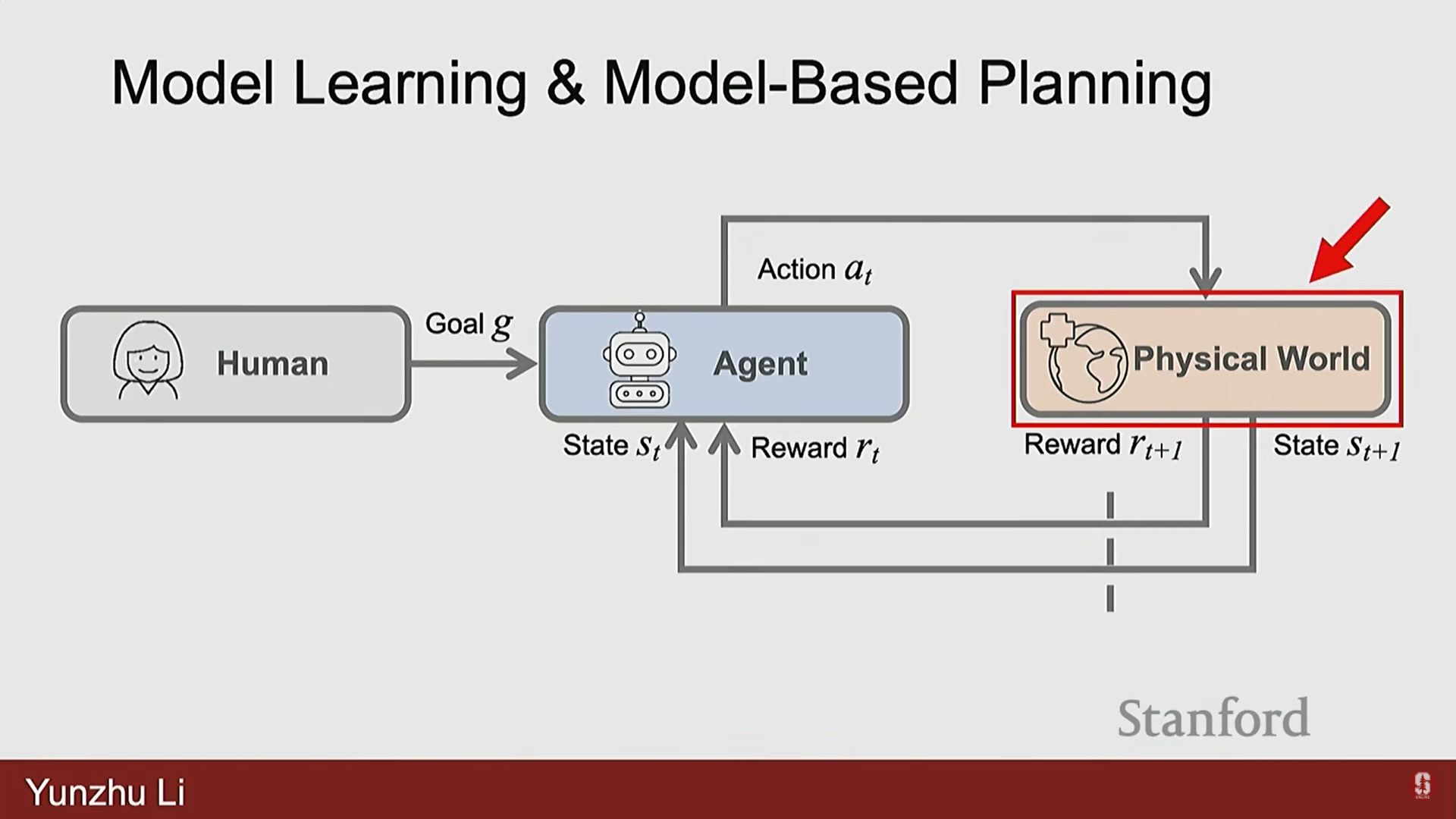
1) 내부 모델 구축 및 계획의 필요성
- 인간은 단순히 시행착오를 통해 배우는 것이 아니라, 직관적인 환경 이해를 바탕으로 내부 모델(internal model)을 구축하여 특정 행동을 적용했을 때 환경이 어떻게 변할지 상상하고 행동을 계획한다.
- 모델 기반 계획(Model Based Planning)은 로봇에게 이러한 예측 능력(predictive capabilities)을 부여하여 행동의 영향을 상상하고 계획하는 것을 목표로 한다.

2) 포워드 모델(Forward Model)과 역 최적화(Inverse Optimization)
- 포워드 모델 학습: 현재 상태 와 행동 가 주어졌을 때, 환경의 상태가 어떻게 다음 상태 로 변할지 예측하는 모델을 학습한다.
- 계획 (역 문제): 포워드 모델을 사용하여 계획(planning)을 수행한다. 이는 현재 상태와 목표 상태가 주어졌을 때, 목표 상태에 도달할 수 있는 행동() 시퀀스를 찾는 것이다.
- 최적화:
- 초기 행동 시퀀스를 추측한다.
- 학습된 모델은 상태의 진화 궤적을 예측한다.
- 이 예측된 궤적과 목표 상태 사이의 거리(distance)를 측정한다.
- 경사 하강법(gradient descent)이나 기타 최적화 기법을 사용하여 궤적을 따라 모든 행동에 대한 거리의 기울기를 역전파하거나 최적화하여 목표에 더 가까이 다가갈 행동을 결정한다.
- 실행 및 재최적화: 모델이 정확하지 않을 수 있으므로, 일반적으로 첫 번째 행동만 실행하고 새로운 상태를 얻은 다음, 행동 시퀀스를 재최적화(reoptimize)한다.
- 장점: GPU와 뉴로다이내믹스 모델(neurodynamics model)을 사용하여 대규모 병렬 샘플링 및 최적화가 가능해 효율적이다.
3) 상태 표현(State Representation) 조사
모델 학습에서 핵심 질문은 가장 효과적인 상태 표현이 무엇인지, 그리고 이 표현을 기반으로 모델을 어떻게 학습할 것인지이다.
- 픽셀 역학 (Pixel Dynamics):
- 상태 표현으로 2D 이미지(픽셀)를 사용한다.
- Deep Visual Foresight와 같은 초기 연구는 특정 행동을 적용했을 때 이미지가 어떻게 변할지 학습하여, 객체 회전이나 밀기 같은 작업을 수행했다.
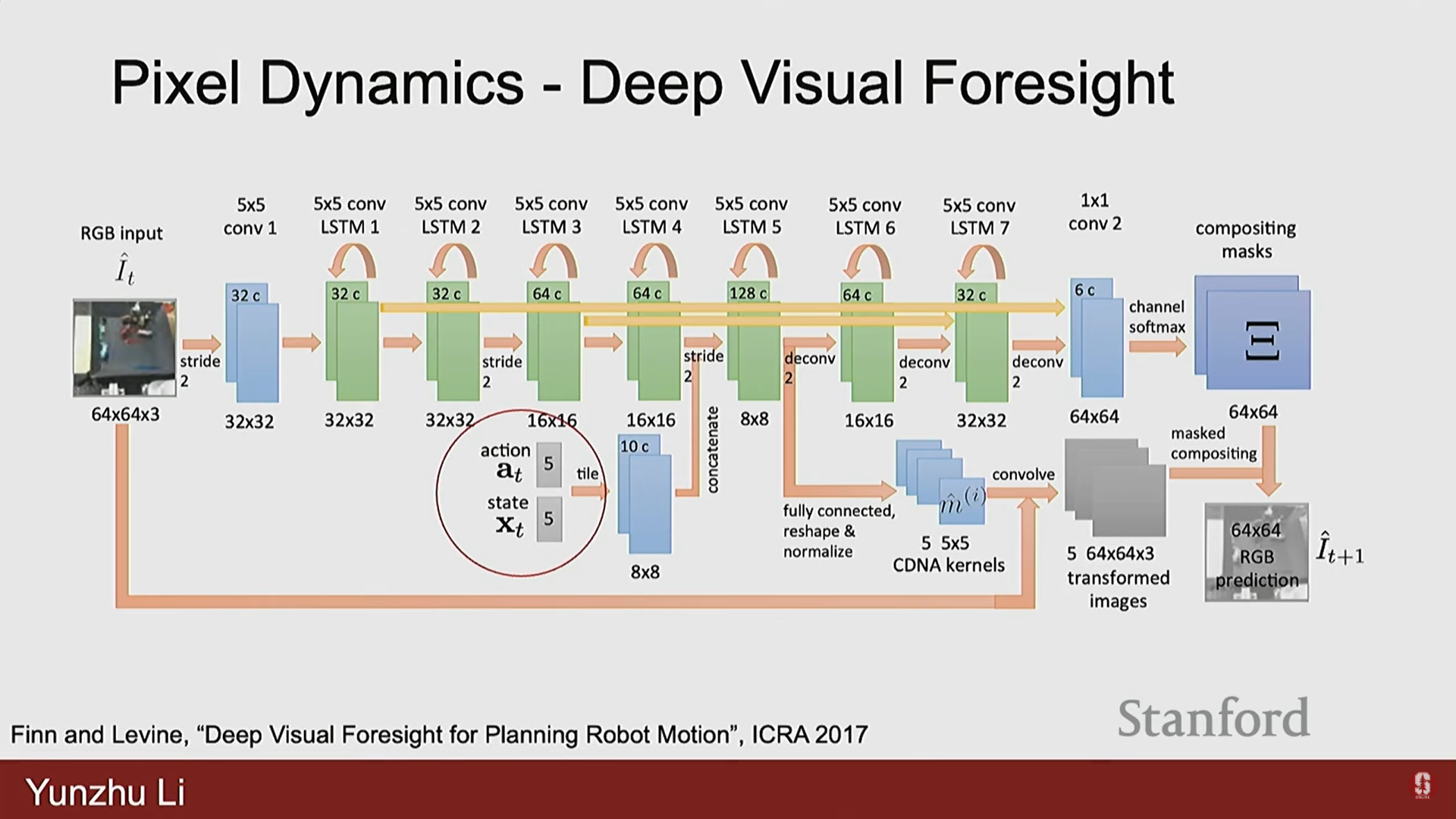
- 키포인트 역학 (Key Points Dynamics):
- 환경의 표현으로 키포인트를 사용한다.
- 3D 공간에서 상자 위에 있는 키포인트의 움직임을 추적하고, 특정 밀기 행동의 결과로 키포인트의 뉴럴 역학 모델(neural dynamics model)을 학습하여 로봇이 목표 구성에 도달하도록 계획한다.

- 파티클 기반 역학 (Particle-based Dynamics):
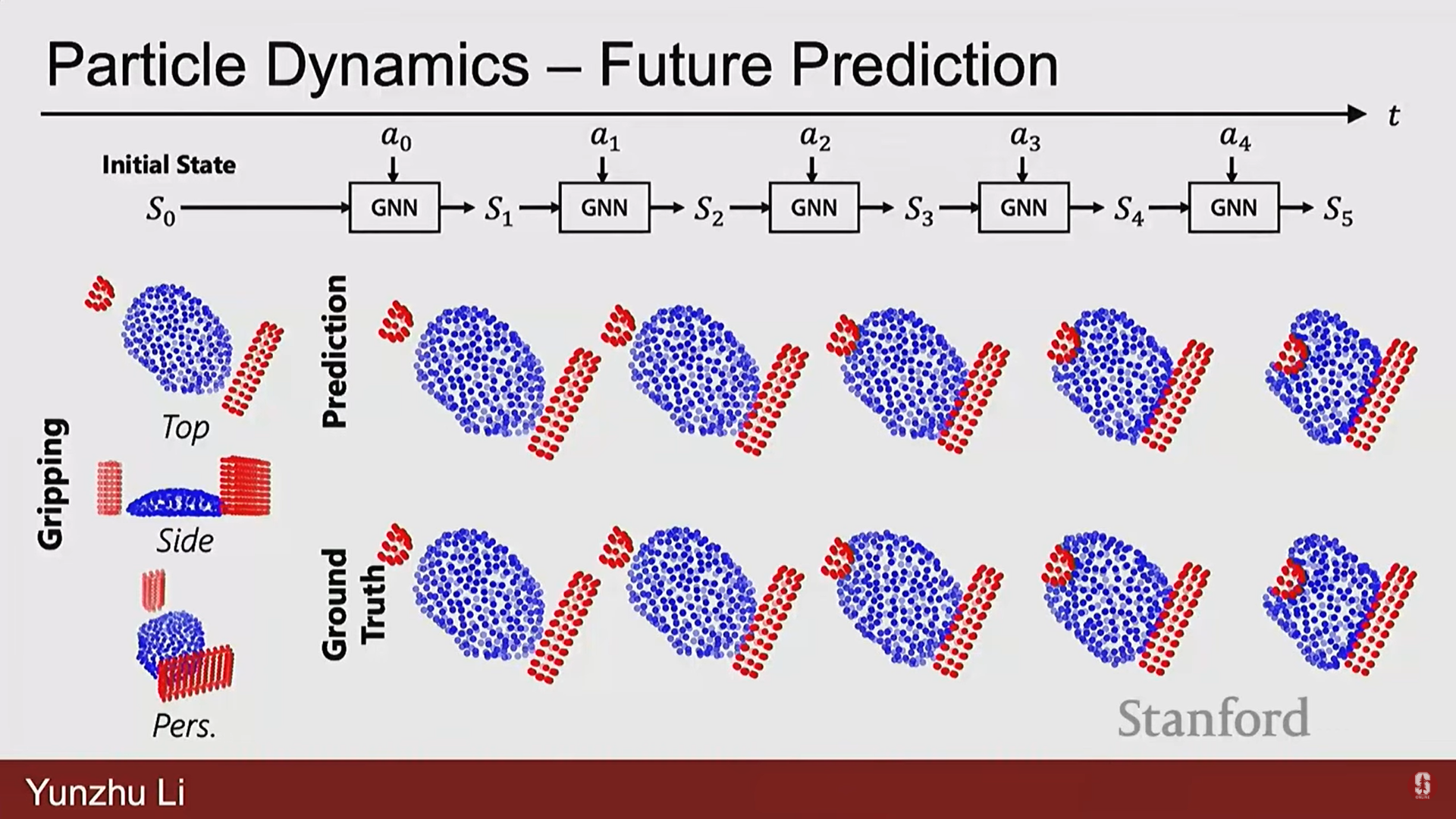
- 높은 자유도(degrees of freedom)를 가진 객체를 파티클(입자) 세트로 표현한다.
- 과립형 조각(granular pieces)을 입자 세트로 표현하고, 특정 행동을 적용했을 때 이 입자들이 어떻게 움직일지 예측한다.
- 이 포워드 모델을 사용하여 로봇은 다양한 크기의 과립형 물체를 조작하고 목표 영역으로 모으는 역 결정(inverse decision-making)을 수행할 수 있다.
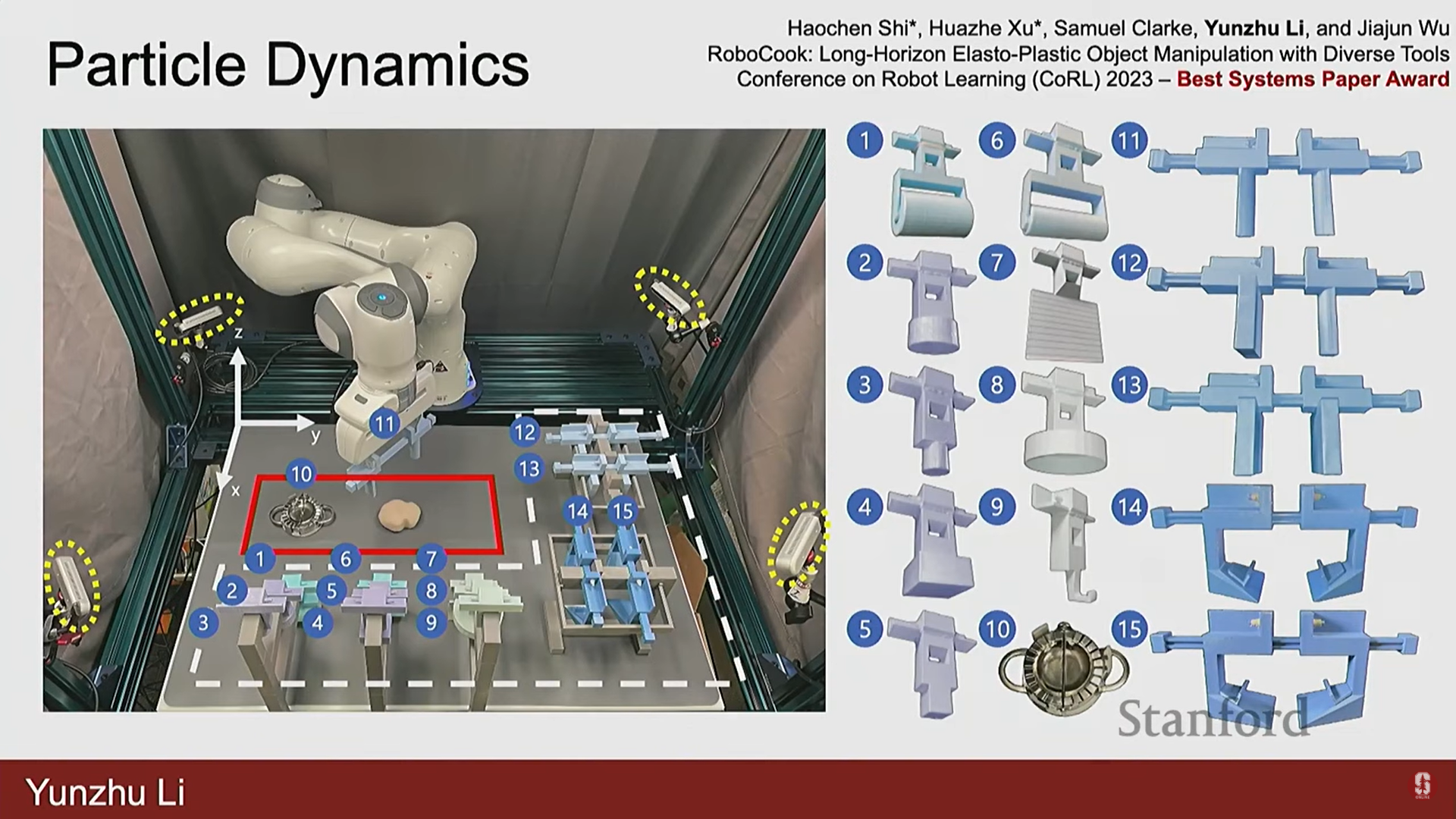
- 심화 (만두 만들기 로봇): Stanford에서 진행된 연구에서는 15가지 3D 프린팅 도구를 장착한 로봇이 입자 기반 포워드 예측 모델을 사용하여 만두를 만드는 작업을 수행했다.
- 빨간 점은 도구의 모양, 파란 점은 반죽의 모양을 나타낸다.
- 학습된 모델은 반죽의 모양 변화를 매우 정확하게 예측했으며, 이는 로봇이 도구를 선택하고(고수준 결정), 특정 동작을 적용하는(저수준 결정) 통합된 시스템을 가능하게 했다.
- 이 시스템은 실시간 시각 피드백과 학습된 역학 모델을 사용하여 사람이 지속적으로 방해해도 매우 강건하게(robustly) 작업을 계속했다.

6. 모방 학습 (Imitation Learning, IL)
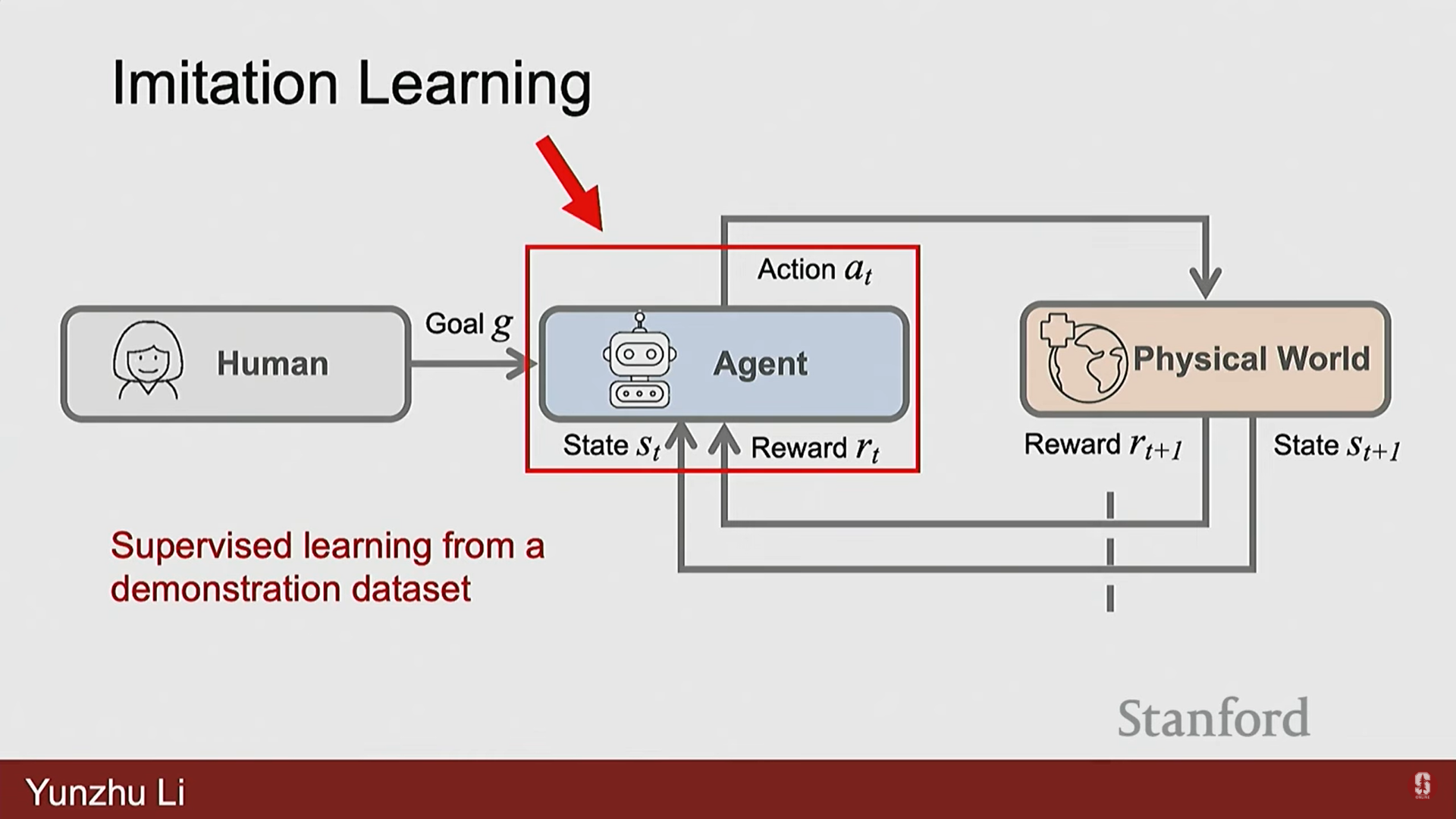
1) 모방 학습의 기본 개념
- 모방 학습은 로봇의 시행착오(RL) 대신, 모델 학습처럼 지도 학습을 정책에 적용하는 아이디어다.
- 작업이 어떻게 수행되어야 하는지를 보여주는 대규모 데이터 세트를 사용하여 정책을 훈련한다.
- 정책()은 상태 를 입력으로 받아 행동 를 예측하도록 학습되며, 이 학습은 인간이 로봇에게 작업을 시연한 대규모 데이터를 통해 이루어진다.
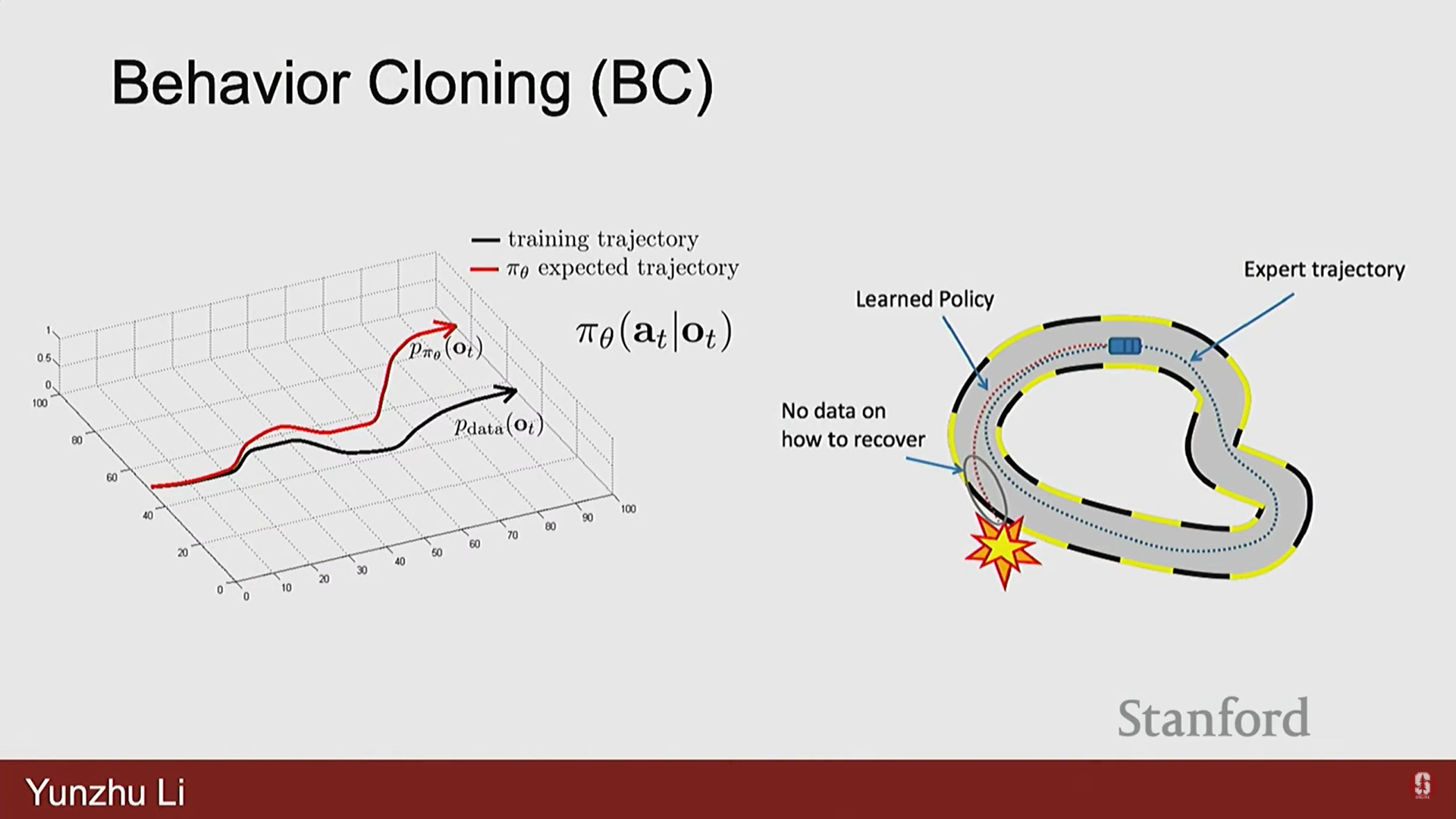
2) 비헤이비어 클로닝(Behavior Cloning, BC)과 한계
- 비헤이비어 클로닝은 가장 고전적인 IL 알고리즘으로, 현재 관찰 를 행동 로 매핑하는 것을 학습한다.
- 한계점: 캐스케이딩 에러 (Cascading Error)
- 로봇 학습은 순차적 의사 결정 문제이기 때문에 오류가 시간에 따라 축적되고 증폭될 수 있다.
- 초기에 작은 오류가 발생하면, 로봇의 상태가 훈련 데이터 분포에서 약간 벗어나게 된다.
- 이로 인해 정책이 다음 단계에서 더 큰 오류를 만들게 되고, 이러한 오류가 시간적 지평(temporal horizons)에 걸쳐 증폭되어 시연 궤적에서 크게 이탈하게 된다.
- IL 개발 라이프사이클: BC의 한계를 극복하기 위해, 전문가 시연 데이터로 정책을 훈련한 후, 실제 환경에서 실패 사례를 관찰하여 추가 데이터나 교정 행동(corrective behaviors)을 수집하는 반복적인 데이터 수집 파이프라인을 따른다.
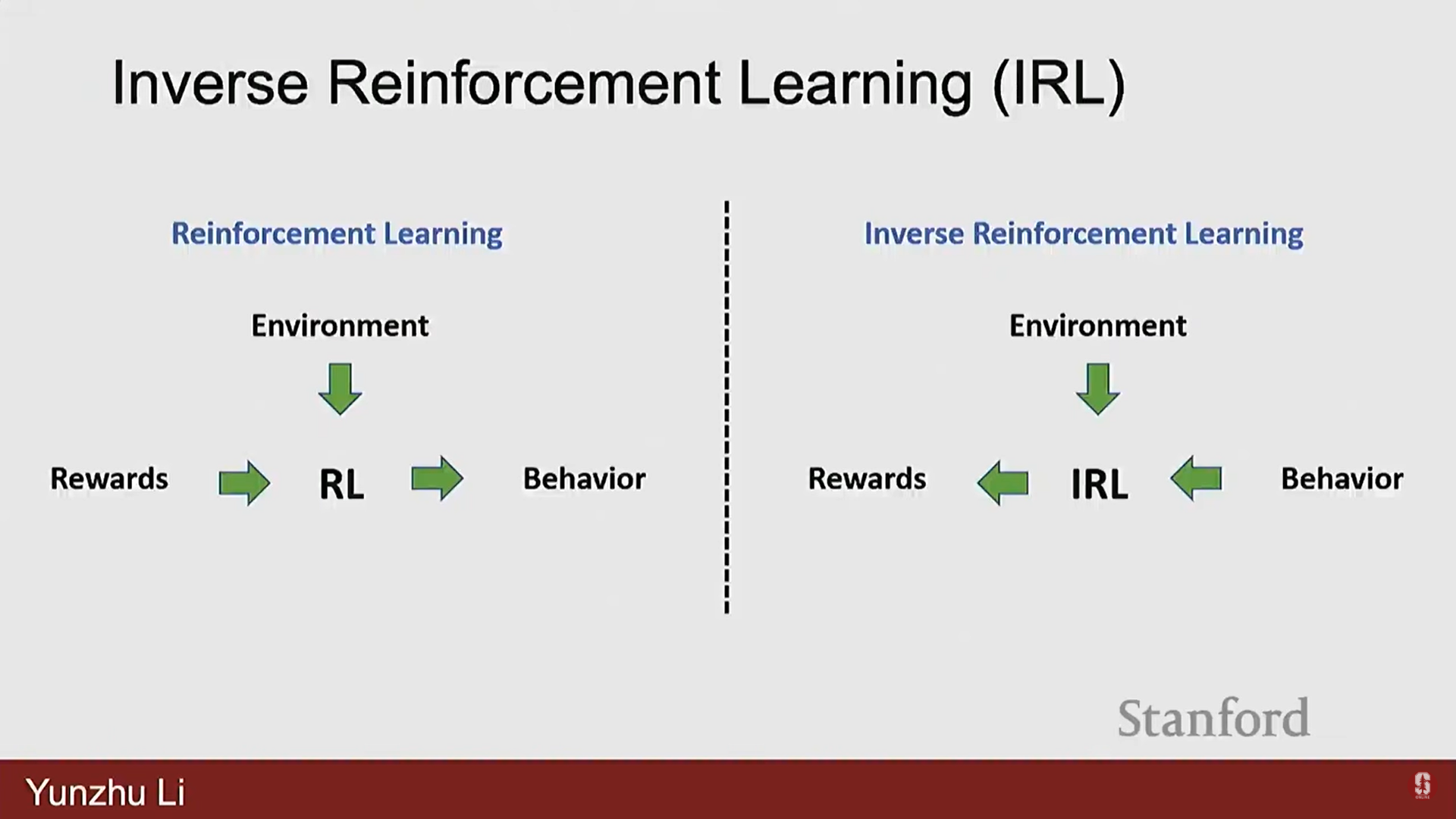
3) 역 강화 학습 (Inverse Reinforcement Learning, IRL)
- 시연(demonstrations)에는 과제에 대한 명시적인 정의가 없으며, 과제는 시연 내에 암묵적으로 숨겨져 있다.
- IRL은 시연으로부터 보상을 요약(summarize the rewards)하는 것을 목표로 하며, 이 보상을 사용하여 일반적인 RL을 수행하여 알고리즘을 학습시킨다.
- 이는 헬리콥터 제어와 같은 복잡하고 민첩한 행동을 달성하는 데 성공적으로 사용되었다.
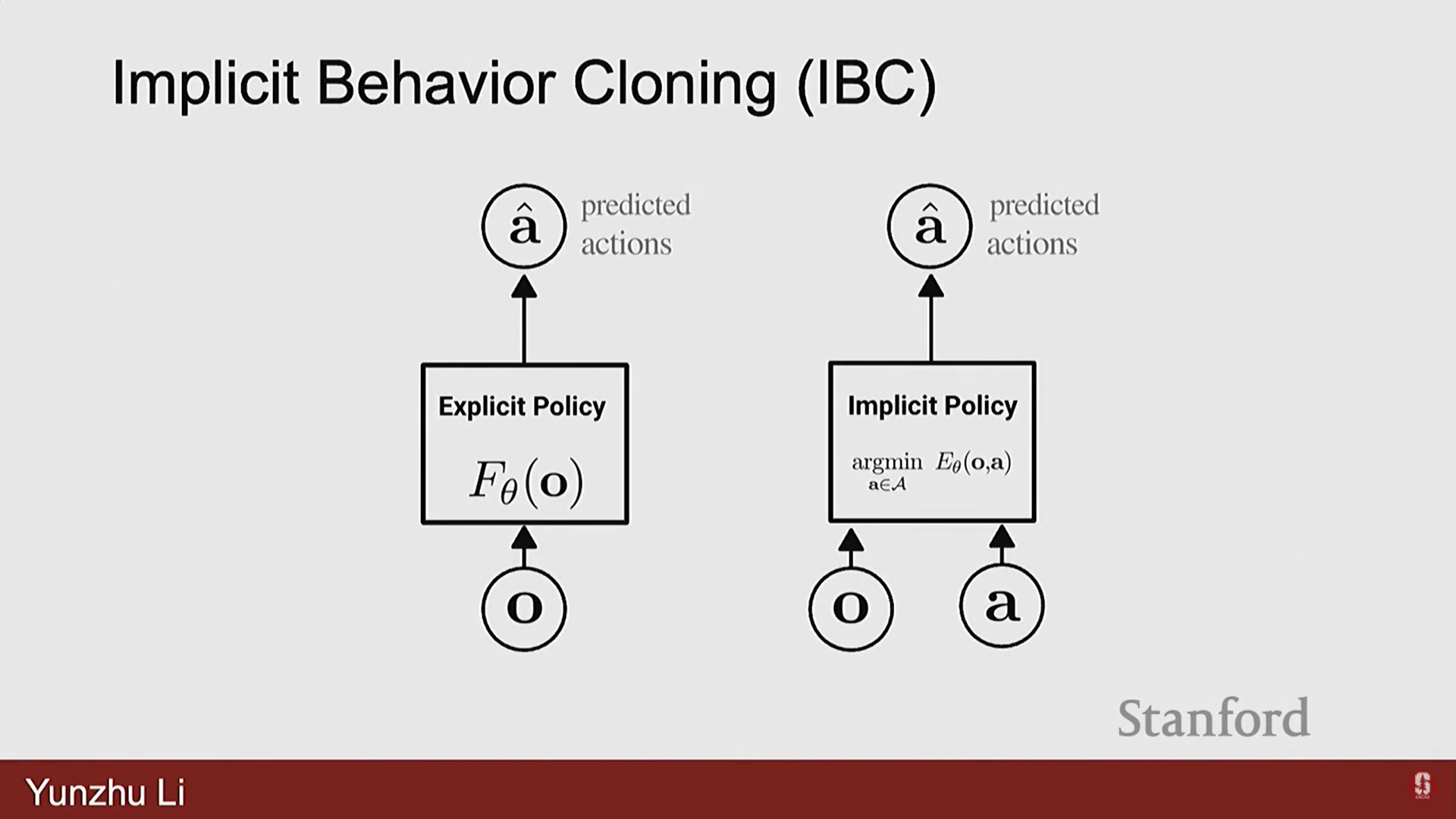
4) 최신 IL 트렌드: 생성 모델 기반 정책
- 에너지 기반 모델 (Energy Based Models):
- 명시적인 정책 대신, 관찰과 행동을 취하여 점수(score)를 예측하는 암묵적인 정책(implicit policies)을 학습하는 데 사용된다.
- 이는 최적화 환경이 매끄럽지 않거나 시연이 다중 모드(multimodals)인 시나리오를 처리하는 데 도움이 된다.
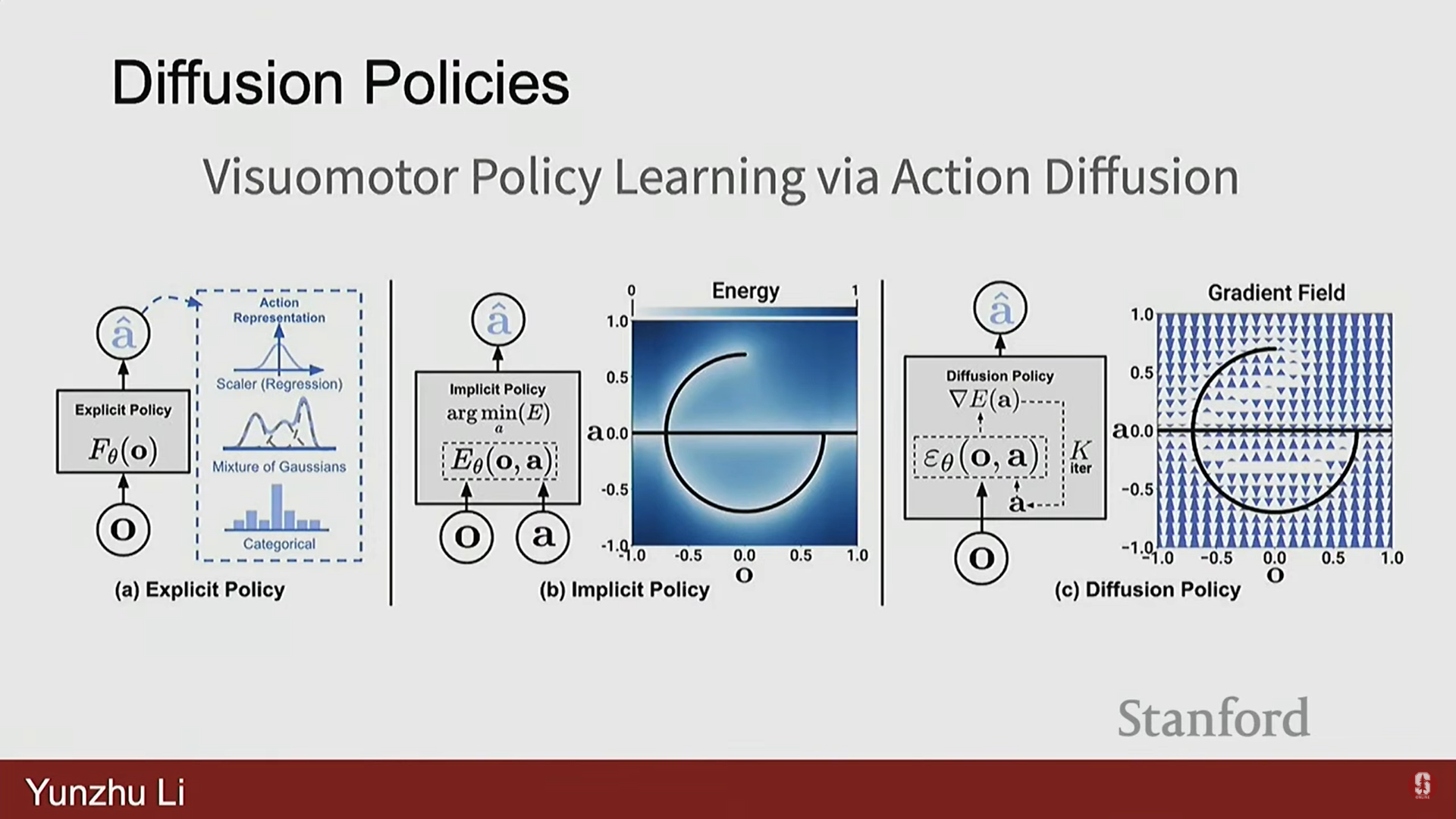
- 확산 정책 (Diffusion Policy):
- 확산 모델(Diffusion models), 즉 딥러닝 커뮤니티의 강력한 생성 모델로부터 영감을 받아 정책 함수 클래스로 사용되었다.
- 이 방식은 콜롬비아에서 시작되었으며, 다양한 미세 조작 작업(예: 버터 바르기, 감자 깎기, 계란 스크램블)에서 매우 효율적이며 현실 세계에서 작동하는 정책을 얻을 수 있음을 보여주었다.
- 효율성: 아침에 데이터를 수집하고, 오후에 정책을 훈련하면, 당일 작동하는 정책을 현실 세계에서 얻을 수 있다.
- 심화: 모방 학습은 실제 물리적 세계에서 흥미로운 일을 할 수 있는 정책을 얻기 위한 가장 효율적인 방법이다. 하지만 정책의 신뢰성과 일반화 가능성을 높이기 위해서는 실세계의 변화에 강건해지도록 반복적인 데이터 수집이 필요하다.
7. 로봇 파운데이션 모델 (Robotic Foundation Models, RFM)
1) RFM의 정의 및 목표
- RFM은 기능 클래스(function class) 면에서 RL이나 IL과 유사하다. 환경 모델을 명시적으로 학습하지 않고, 관찰과 목표를 입력으로 받아 행동을 매핑하는 정책(policy)이다.
- 특수성: 일반적인 정책보다 훨씬 더 잘 일반화되어야 한다.
- 언어 관련 파운데이션 모델이나 비전 언어 관련 파운데이션 모델의 발전에서 뿌리를 찾는다.
- RFM의 목표: 합성된 행동이 항상 최적의 행동은 아닐지라도, 실제 물리적 세계에서 실행하기에 아름답고 합리적인(beautiful and reasonable) 궤적을 생성해야 한다.
- 아름다움: 떨리는 움직임(jiggling motions) 없이 부드럽고 연속적이어야 한다.
- 합리성: 주어진 언어 지침을 따라야 한다.
- 다른 이름: Vision Language Action Models (VLA), Large Behavior Models 등으로도 불린다.

2) RFM의 발전 현황 및 PI-0
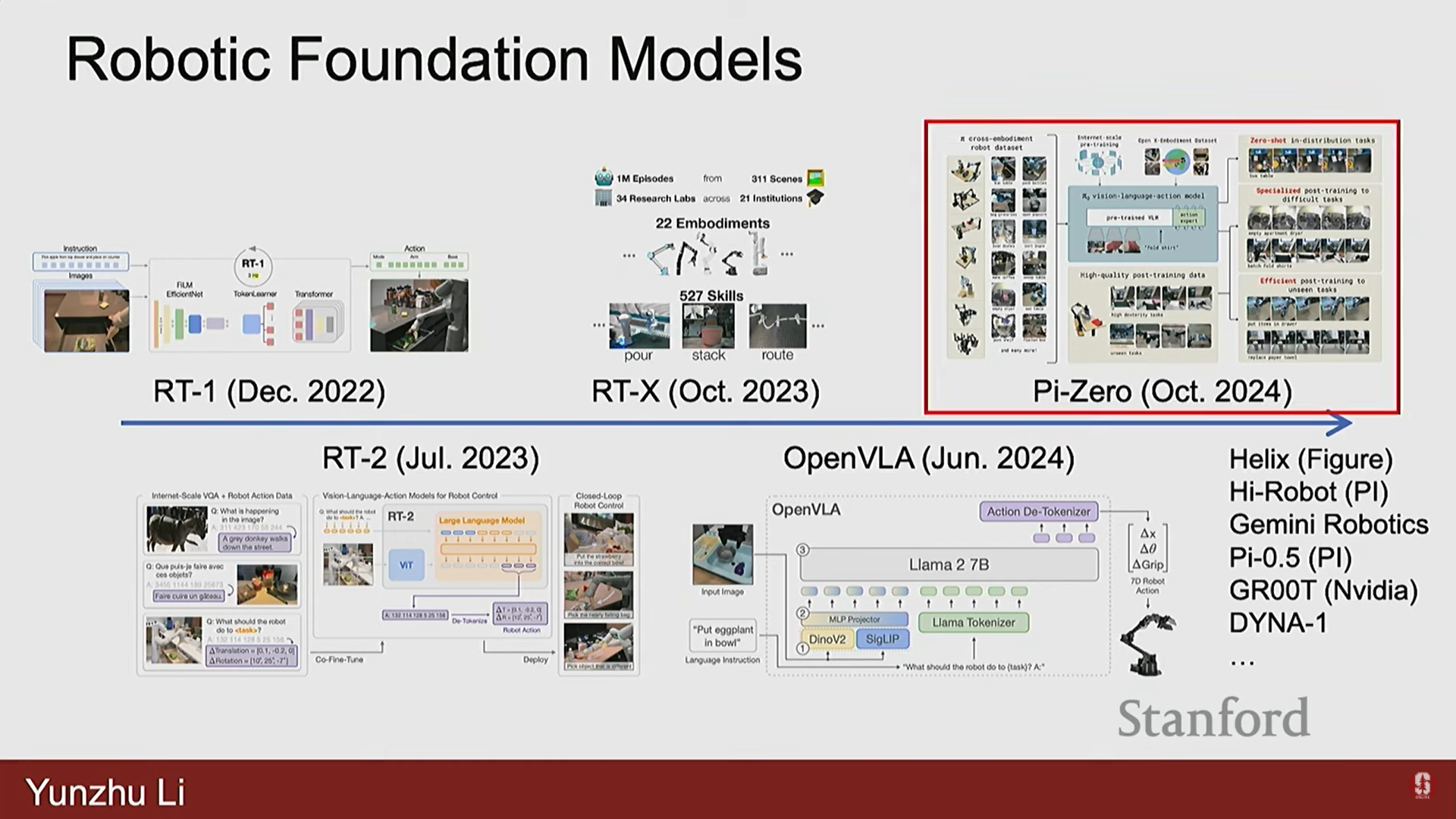
-
RFM 분야는 매우 시끄럽다(noisy). 광범위한 시나리오에 걸쳐 일반화를 기대하기 때문에, 그 진전을 정량적으로 측정하고 평가하기가 매우 어렵다.
-
발전 타임라인: 2022년 12월 RT-1 출시 이후, 약 6개월마다 RT-2, RTX, Open VA 등의 새로운 모델이 출시되고 있다. 2024년에는 Helix, Hi-Robot, Gemini Robotics 등 많은 모델이 등장했다.
-
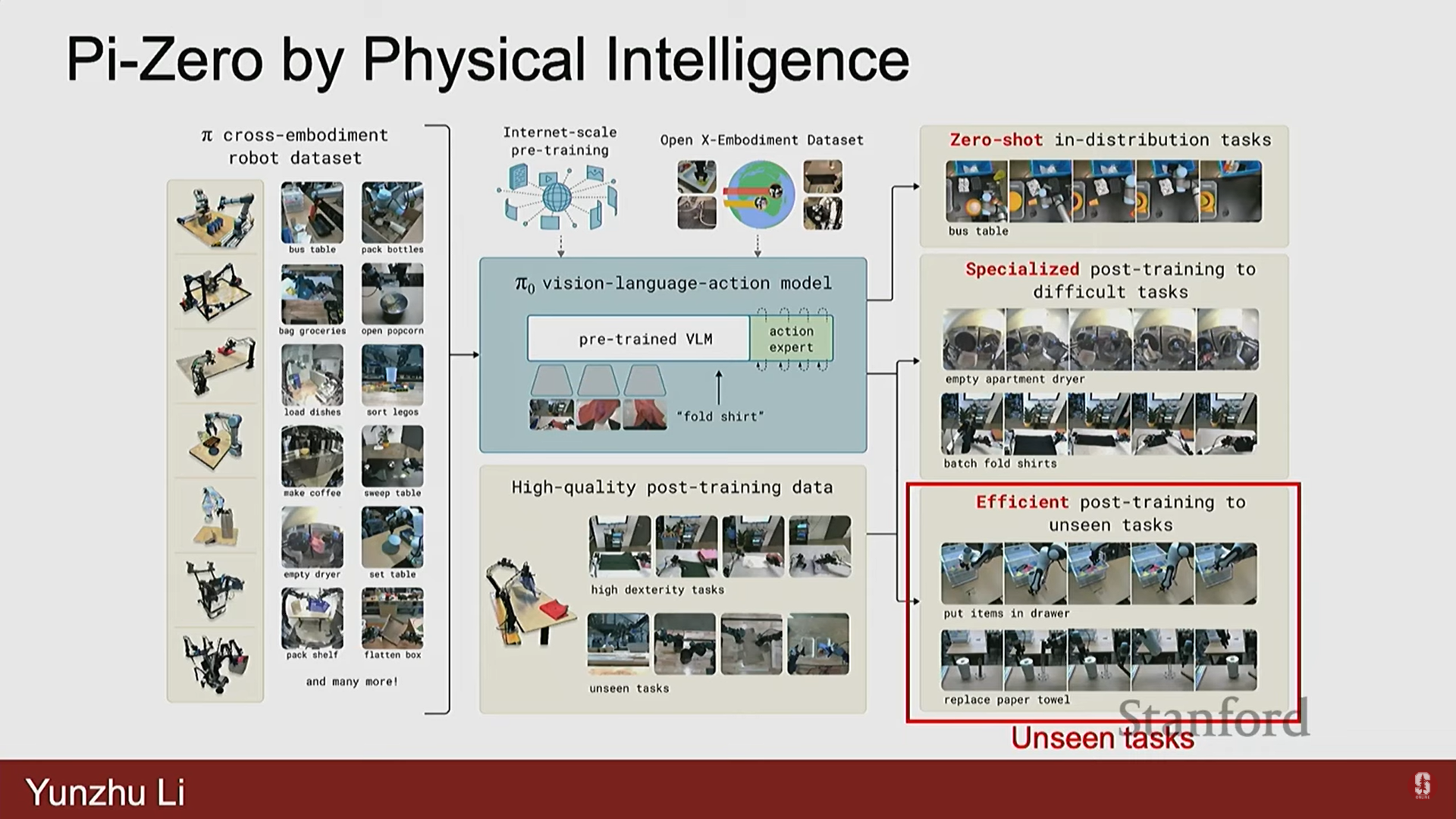
PI-0 (2024년 10월 출시):
- 이 모델은 천 접기(cloth folding), 상자 접기(box folding) 등 다양한 조작 작업을 매우 신뢰성 있게 처리할 수 있음을 보여주었다.
- 프레임워크 구성:
- 데이터: 학계 데이터와 자체 수집 데이터를 포함하여 다양한 구현체(embodiment)에 걸친 대규모 데이터를 수집한다.
- 사전 훈련 (Pre-training):
- 사전 훈련된 VLM (Vision Language Models)로 시작하는 것이 중요하다.
- VLM은 방대한 양의 비전-언어 데이터로 훈련되어 의미론적 지식(semantic knowledge)을 자연스럽게 적응시킬 수 있다.
- 행동 예측 목표(action predictions objective)와 VQA(Vision Question Answering) 같은 작업에서 차용한 목표를 모두 사용하여 공동 미세 조정(co-fine tuning)을 수행한다.
- 이는 모델 내의 의미론적 지식을 보존하는 동시에 로봇 행동을 예측할 수 있게 한다.
- 후속 훈련 (Post-training):
- 대규모 언어 모델에서 영감을 받은 매우 중요한 단계.
- 기본 모델(base model)은 합리적인 성능을 제공하지만, 특정 작업에서 성능을 매우 높이려면 작업별 데이터를 수집하여 모델을 미세 조정해야 한다.
- 평가 범주: 기본 모델(단순한 In-distribution 작업), 후속 훈련된 모델(약간 복잡한 In-distribution 작업), 후속 훈련된 모델(미지의 Unseen 작업).
- PI-0는 의미론적 수준에서 놀라운 수준의 일반화를 보이며, 로봇 데이터로 미세 조정하여 행동 수준에서도 일반화되도록 한다.
8. 남아있는 주요 도전 과제 (Remaining Challenges)
1) 평가 (Evaluation)
- 로봇 학습 커뮤니티가 인식하는 주요 과제 중 하나는 평가(Evaluation)이다.
- 현재 평가는 주로 실제 세계에서 이루어진다.
- 구글 로보틱스(Google Robotics)의 예시처럼 실제 세계 평가는 비용이 많이 들고(costly) 노이즈가 많다(noisy).
- 초기 구성, 조명 조건, 심지어 제조사의 마찰 파라미터와 같은 작은 변화도 정책의 강건성에 큰 영향을 미칠 수 있다.
- 결과가 나오기까지 이틀을 기다려야 할 수도 있다.
- 훈련 손실과 성공률 간의 약한 상관관계:
- 지도 학습에서는 훈련 손실이 모델의 성능을 직접 측정하지만, 정책 학습에서는 훈련 손실이 단일 단계 예측(one-step prediction)의 품질만 측정한다.
- 이는 장기적인 작업 지평(long task horizons)에 걸친 정책의 성능을 나타내지 못하는 경우가 많다.
- 시뮬레이션에서의 평가:
- Behavior, Habitat 3.0와 같은 시뮬레이션 환경을 사용하여 정책을 평가하려는 노력이 있다.
- 문제점: Sim-to-Real 갭 (강체, 변형체, 옷 등의 정확한 시뮬레이션), 자산(assets) 문제 (현실적이고 다양한 자산의 대규모 생성), 실제 세계의 디지털화 등이 있다.
- Embodied AI를 위한 ImageNet: 컴퓨터 비전에서 ImageNet이 진보의 지표였던 것처럼, 로봇 학습에서도 벤치마크나 플랫폼에서의 진보가 로봇 학습의 진보를 의미하는 플랫폼을 구축하는 것이 필요하다.


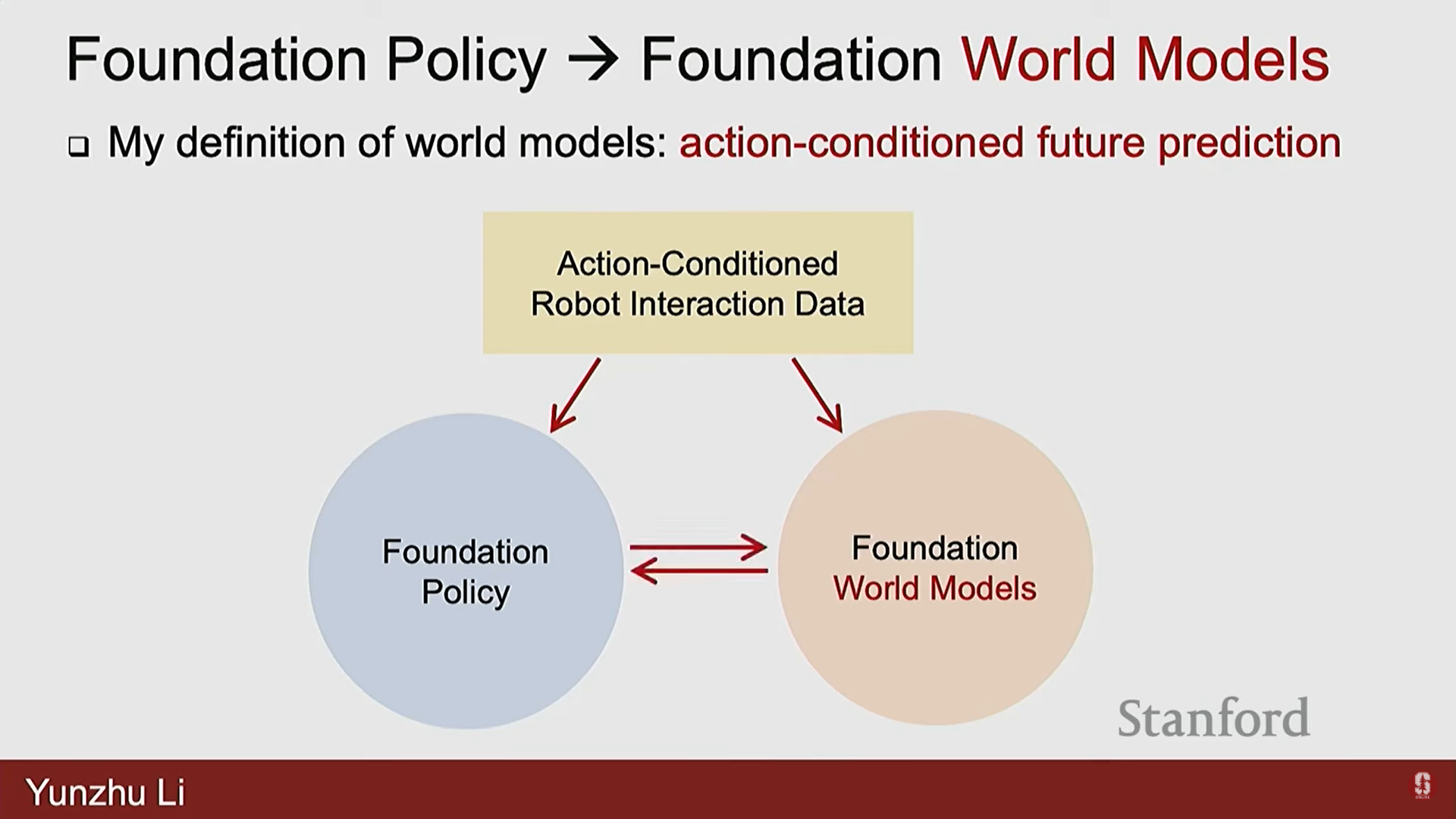
2) 근간이 되는 월드 모델 (Foundational World Models)
- 현재는 대규모 행동 조건 로봇 상호작용 데이터(action-condition robot interaction data)를 수집하여 파운데이션 정책을 훈련하는 데 집중하고 있지만, 이 데이터에는 많은 역학 지식(dynamics knowledge)이 내장되어 있다.
- 이 데이터를 단순히 정책 학습에만 사용하는 것은 낭비이므로, 이 데이터를 사용하여 근간이 되는 월드 모델(foundational word models)을 훈련하고, 이 모델과 파운데이션 정책이 상호 작용하는 방법을 연구해야 한다.
- 고려해야 할 특징: 3D 구조, 구조적 사전(structural prior) 사용 여부, 학습(learning) 대 물리(physics)의 비율, 실제 물리적 세계와의 상관관계 등이다.
9. Q&A (질의응답)
1) 보상 설계 및 로봇의 계획 능력
- Q1: 보상은 얼마나 구체적으로 설계되어야 하는가?
- A1: 매우 구체적이어야 한다. 자율 주행의 '속도'나 '승객 편안함', 옷 접기의 '면적 최소화' 또는 '매끄러움'처럼, 특정 애플리케이션의 요구 사항을 충족시키기 위한 미묘한 차이(nuances)가 있다.
- Q2: 시뮬레이션에서 충분히 무작위화하면 (Randomization) 시뮬레이션이 완벽할 필요가 없다는 것이 로봇 조작 도메인에도 일반화되는가?
- A2: 로봇 이동(locomotion)에서는 시뮬레이션의 무작위화가 매우 강건하게 일반화된다는 교훈을 얻었지만, 조작(manipulation) 도메인에서는 아직 완전히 일반화되지 않았다. 조작 도메인에서는 Sim-to-Real 갭이 중요한 영역이 있고 그렇지 않은 영역이 있다. 예를 들어, 물체를 잡는 것이 시뮬레이션에서는 성공했지만 현실에서는 물체가 손가락 사이로 미끄러져 날아가는 경우 등은 문제가 된다. 시뮬레이션이 가장 신뢰할 수 있는 Sim-to-Real 전이를 위해 가져야 할 가장 중요한 특성이 무엇인지 여전히 연구 중이다.
- Q3: 로봇이 인간보다 더 나은 계획을 세울 수 있는가?
- A3: 현재 많은 멋진 시연 영상들에도 불구하고, 실제로는 인간 조작자(human operators)가 로봇에게 고수준 명령(high level commands)을 제공하여 어떤 경로로 가야 할지 선택하게 한다. 예를 들어, 인간은 로봇에게 바위를 넘도록 시도해 보라고 명령하거나, 실패하면 우회하라고 명령할 수 있다. 인간은 이 로봇의 능력과 한계를 이해하며 경로를 선택하기 때문에 영상이 멋져 보일 수 있다. 로봇이 자율적으로 더 나은 계획을 세우는 것은 현재 활발히 연구되는 매우 흥미로운 질문이다.
2) 강화 학습 알고리즘 및 AlphaGo
- Q4: Q-함수는 구체적으로 어떻게 작동하는가?
- A4: Q는 상태 와 행동 를 입력으로 받는다. 이 Q 함수는 뉴럴 네트워크로 인스턴스화되며, 네트워크의 파라미터가 Q 함수를 정의한다. 이미지 입력(예: 게임 화면)이 주어지면, CNN 레이어와 완전 연결 레이어를 거쳐 각 이산 행동(예: 4가지 행동)에 대한 Q 값 추정치를 직접 도출한다. 가장 높은 Q 값을 제공하는 행동을 실행하여 의사 결정을 내린다.
- Q5: AlphaGo 출시 이후의 발전은 무엇인가?
- A5: AlphaGo 이후, 모방 학습을 사용하지 않고 스케일링에 최적화된 AlphaGo Zero가 개발되었다. 이는 "Bitter Lesson"을 보여주는데, 때로는 단순한 레시피가 스케일링 파워와 결합하여 더 나은 성능을 낸다. 이후 AlphaZero는 알고리즘을 체스, 쇼기 등으로 일반화했고, MuZero는 잠재 공간 역학 모델을 학습하여 성능을 개선했다.
3) 모델 기반 계획의 세부 사항
- Q6: (만두 만들기 로봇에서) 이는 강화 학습인가, 모델 기반 계획인가?
- A6: 이 작업은 모델을 학습하고 그 모델을 사용하여 계획을 수행하는 모델 기반 계획(Model Learning and Model Based Planning)이다. 이는 정책으로 증류(distill)될 수 있지만, 모델 기반 강화 학습(Model Based Reinforcement Learning)이라고 부를 수도 있다. 핵심 아이디어는 현실 세계 상호작용으로부터 모델을 학습하고, 그 모델을 사용하여 행동을 결정하는 것이다.
- Q7: (만두 만들기 로봇에서) 고수준 계획과 저수준 의사 결정은 두 개의 다른 모델에 의해 수행되는가?
- A7: 그렇다. 고수준에서는 현재 상태와 목표가 주어지면 어떤 도구를 사용할지 분류(classify)하는 분류기(classifier)가 있다. 이 분류된 도구 레이블을 조건으로 하여, 다음 과제 단계로 진행하기 위해 어떤 특정 행동을 취할지 결정하는 저수준 정책이 있다.
- Q8: (만두 만들기 로봇에서) 고수준 분류기는 어떻게 훈련되었는가?
- A8: 당시(2023년)에는 비전 언어 모델이 강력하지 않았기 때문에, 인간 조작자가 작업을 10회 시연한 데이터를 수집하여 어떤 도구를 사용할지 분류하는 분류기를 훈련했다. 이 분류기는 로봇이 외부 방해로부터 복구하기 위해 현재 관찰에 맞는 이전 단계로 되돌아갈 수 있게 돕는다.
- Q9: (만두 만들기 로봇에서) 행동은 순수한 샘플링 기반 궤적 최적화인가 아니면 정책 학습인가?
- A9: 샘플링 기반 궤적 최적화와 정책 학습의 조합이다. 현재 상태가 주어지면 포워드 예측 모델을 사용하여 다양한 행동과 도구를 샘플링하고, 반죽 모양의 진화를 예측한다. 예측을 목표와 비교하여 가장 효과적인 행동을 선택한다.
- 테스트 시 샘플링은 시간이 많이 걸리기 때문에, 이 샘플링을 오프라인 방식으로 수행하여 대규모 데이터 세트를 생성한다.
- 그 다음, 이 데이터 세트를 사용하여 테스트 시 매우 짧은 시간 내에 추론할 수 있는 정책(policy)을 훈련한다. 이 정책은 여전히 뉴럴 네트워크이다.
- Q10: (만두 만들기 로봇에서) 물리 기반 시뮬레이션을 사용했는가?
- A10: 이 특정 작업에서는 물리 기반 시뮬레이션을 전혀 사용하지 않았다.
- 당시 최신 기술이었던 변형 가능한 객체 시뮬레이터(MPM)를 사용한 기준선(baseline)이 있었지만, 실제 세계 상호작용에서 직접 학습된 모델이 훨씬 더 정확했다.
4) 로봇 파운데이션 모델의 효율성 및 일반화
- Q11: 로봇 정책이 인간보다 느린 이유는 무엇인가?
- A11: 정책이 인간보다 느린 주요 이유 중 하나는 데이터 수집 방식이다.
- 많은 시나리오에서 인간이 해당 로봇을 원격 조작(tele-operating)하여 시연 데이터를 수집하는데, 인간이 자기 손으로 작업을 수행하는 것보다 로봇을 원격 조작하는 것이 더 느리다.
- 또한, 로봇 팔이 인간과 떨어져 있어 가림(occlusion)이 발생하고, 다음 작업 단계로 진행할 시점을 이해하기 위해 시야각을 변경해야 하는 등 데이터 수집 체제의 비효율성이 있다.
- 인간 속도에 맞추어 데이터를 수집하는 방법은 매우 활발한 연구 방향이다.
- Q12: PI-0 같은 단일 정책이 집과 같은 광범위한 시나리오에 걸쳐 일반화될 수 있는가?
- A12: 상자 접기와 같은 긴 지평(long horizon) 작업은 인상적이지만, 로봇이 집에서 옷을 접고, 침대를 정리하고, 바닥의 모든 잡동사니를 치우는 더 큰 시나리오에서는 하나의 거대한 정책만으로는 적응하기 어렵다고 개인적으로 생각한다.
- 이러한 경우, 비전 언어 행동 모델이 효과적이고 유용하게 작동하고 더 복잡한 작업으로 확장되려면, 고수준 추상화(higher level obstructions)나 지식 그래프(knowledge graph), 상징적 표현(symbolic representations)과 같은 조건이 마련되어야 한다.
