1. 개요
강의 개요 및 비전의 진화
- 이번 강의는 CS231N 학기의 마지막 강의로, 알고리즘보다는 AI의 장기적인 연구 발전 방향과 오늘날 AI에서 중요한 인간의 관점(human perspective)에 대한 통찰을 제공한다.
- 강의 제목은 "우리가 보는 것과 우리가 소중히 여기는 것: 인간의 관점을 가진 AI" (What we see and what we value: AI with a human perspective)이다.
- 비전의 기원 (Origin of Vision): 5억 4천만 년 전, 동물 세계에 처음으로 빛이 도달했으며, 삼엽충(trilobytes)과 같은 동물들이 외부 세계를 파악하기 위한 감광성 세포(photosensitive cells)를 발달시켰다.
- 동물학자 앤드루 파커(Andrew Parker)에 따르면, 이 시각의 출현은 동물들이 진화하거나 죽는 진화적 군비 경쟁(evolutionary arms race)을 촉발시켰고, 이로 인해 폭발적인 동물 종 분화가 발생했는데, 이를 동물학자들은 캄브리아기 대폭발(Cambrian explosion) 또는 진화의 빅뱅(big bang of evolution)이라고 부른다.
- 오늘날에도 시각은 인간을 포함한 많은 동물에게 주요한 지능 시스템이며, 생존, 일, 엔터테인먼트, 학습 등 많은 활동에 사용된다.
- 컴퓨터 비전의 역사: 1960년대 '여름 시각 프로젝트(Summer Vision Project)'로 시작되었는데, 이는 인공지능 역사에서 흔히 나타나듯, 북극성(North Star)처럼 목표는 명확하지만, 그것을 달성하는 데 걸리는 시간을 과소평가한 시도였다.
- 현재 컴퓨터 비전은 자율주행차, 이미지 이해, 생성형 AI(Generative AI) 혁명에 이르기까지 핵심적인 역할을 수행하고 있다.
- 본 강의는 AI의 발전 방향을 다음 세 가지 측면에서 탐구한다:
- 인간이 보는 것을 AI가 보도록 구축하기 (Building AI to see what humans see)
- 인간이 보지 못하는 것을 AI가 보도록 구축하기 (Building AI to see what humans don't see)
- 인간이 보고 싶어 하는 것을 AI가 보도록 구축하기 (Building AI to see what humans would like to see)
2. 인간이 보는 것을 AI가 보도록 구축하기 (Building AI to See What Humans See)
1) 인간 시각 능력의 우수성 및 컴퓨터 비전의 영감
- 인간은 보는 것에 탁월하며, 영상을 10Hz(프레임당 100밀리초)로 재생해도 복잡한 장면 속 목표물(예: 사람)을 쉽게 감지할 수 있다.
- 신경심리학(Neurophysiology) 연구에 따르면, 인간은 복잡한 자극을 제시받은 후 150밀리초 만에 동물을 범주화하거나 식별할 수 있는 놀라운 속도를 보인다.
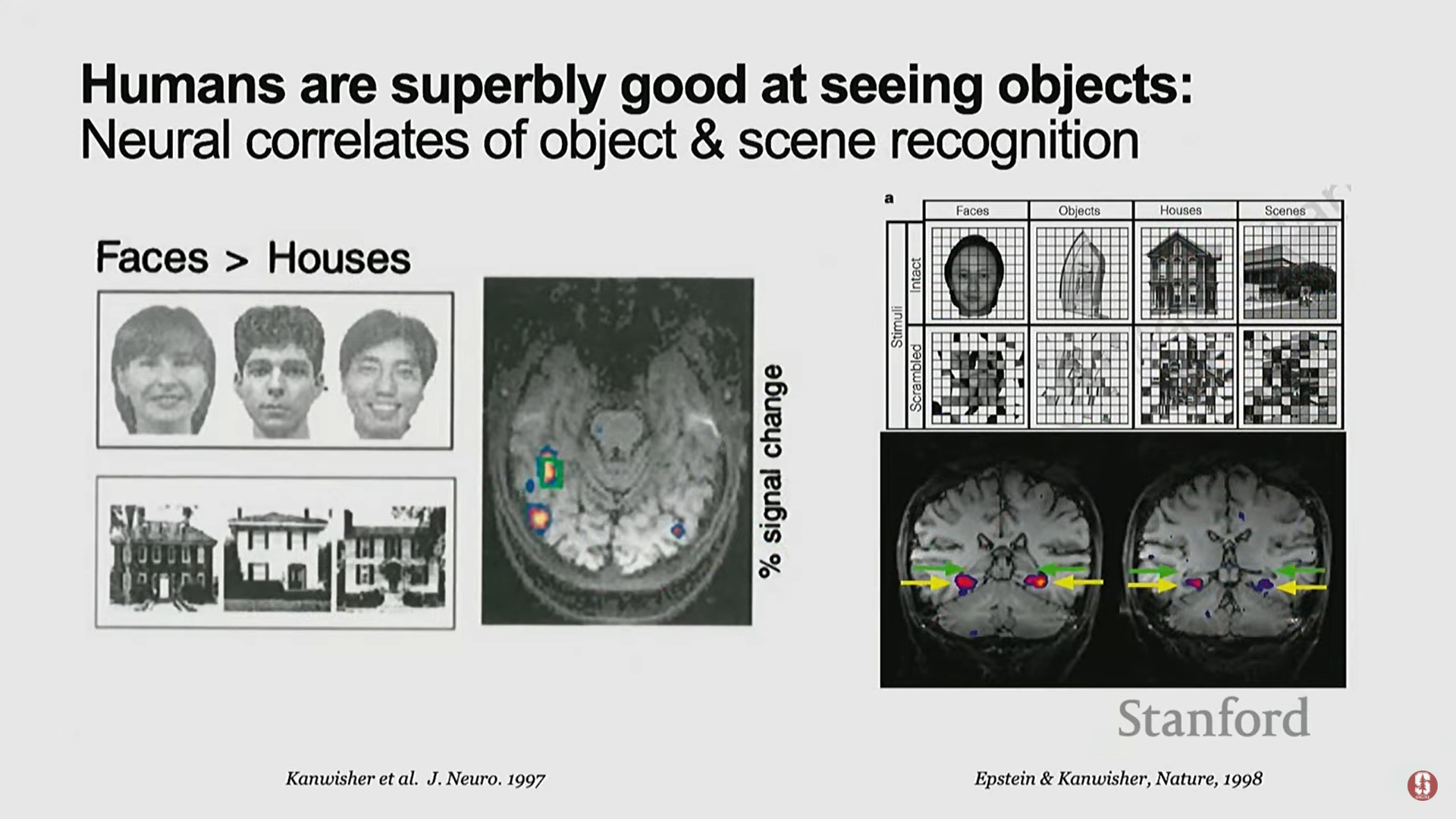
- 우리의 뇌에는 진화가 공을 들인 흔적으로, 얼굴 영역, 장소 영역, 신체 부위 영역 등 객체 이해(object understanding)에 전념하는 신경 상관관계 영역이 존재한다.
- 수십 년 전, 컴퓨터 비전 분야는 이러한 인간의 시각 지능을 기계에 부여하기 위해 객체 인식(Object Recognition)을 기본적인 구성 요소로 정의했다.
- 객체 인식의 근본적인 어려움: 인간에게는 쉬운 일이지만, 수학적으로 조명, 질감, 배경, 가려짐, 시야각, 스케일링 등으로 인해 어떤 객체를 인식하는 데 무한한 가능성이 존재하므로 근본적으로 어려운 과제이다.
2) 딥러닝 이전 시대의 객체 인식 역사
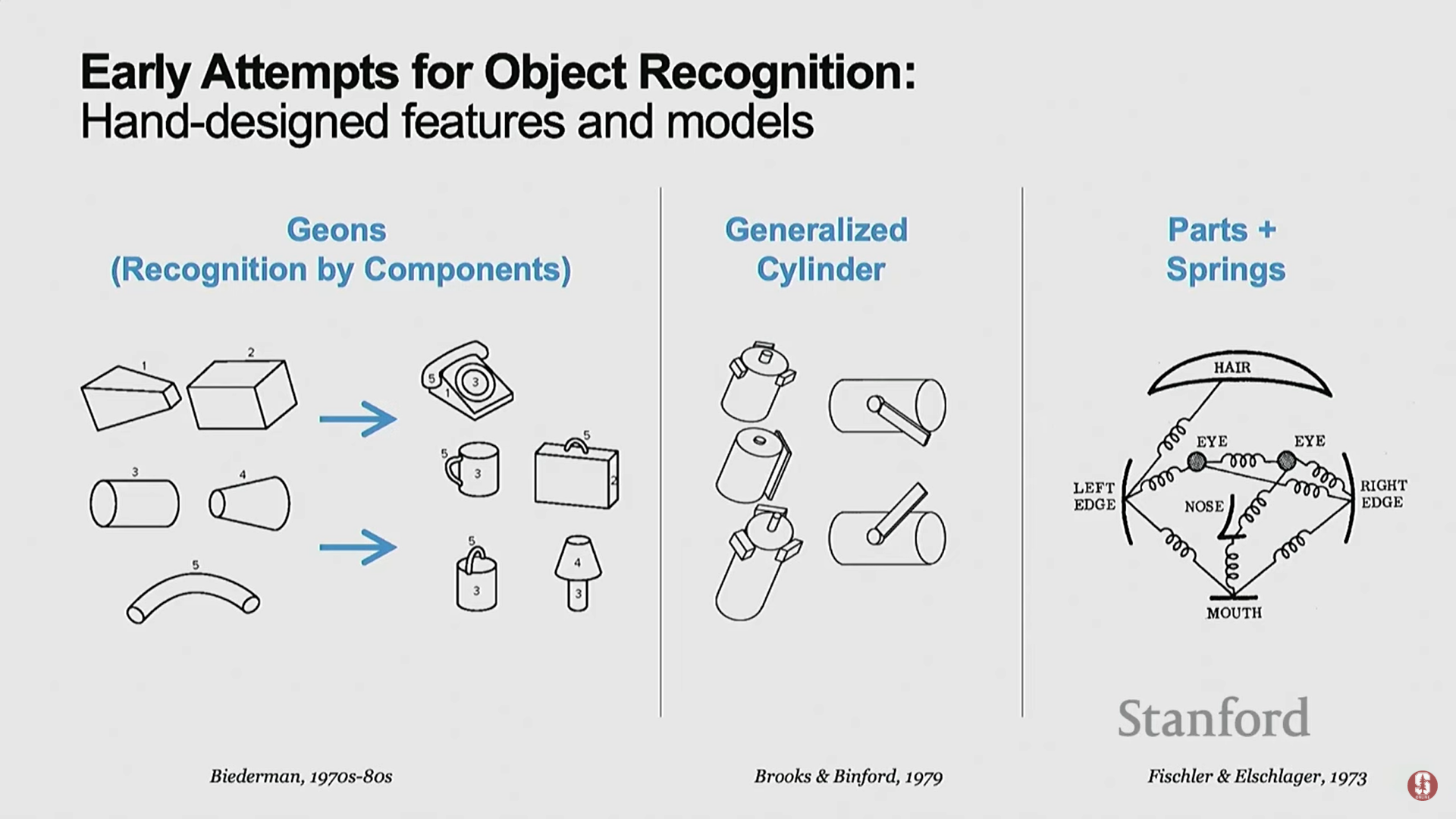
- 1차 시도 (1970~1990년대 초): 심리학 기반 파트 구성 모델.
- 인간이 객체를 기하학적 파트(geometric parts)로 보고, 이를 조합하여 객체를 인식한다는 자기 성찰적(self-introspect) 아이디어에서 영감을 받았다.
- 이 방식은 수학적으로 아름답고 단순했지만, 실제로는 작동하지 않았다.
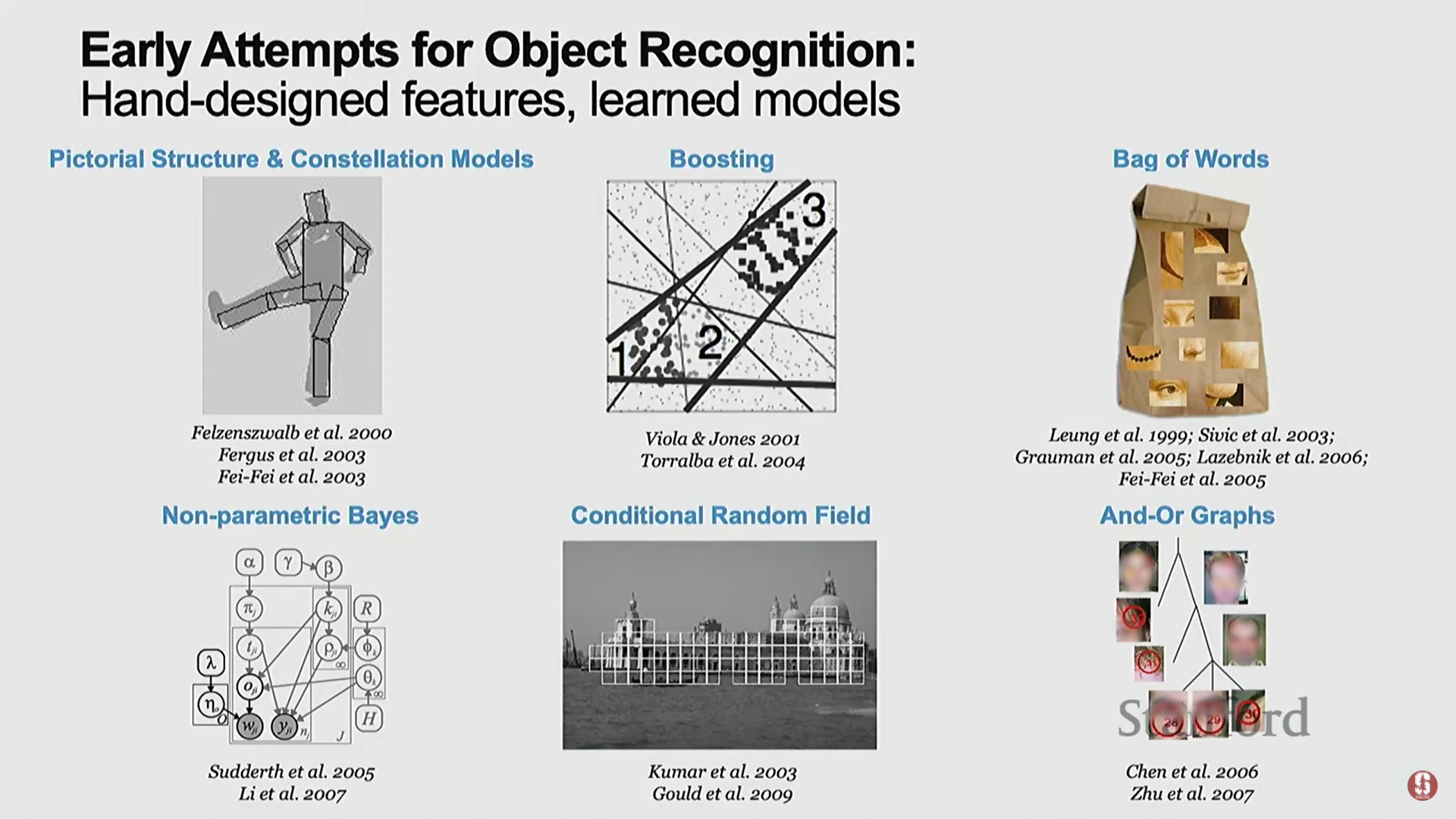
- 2차 시도 (2000년대 초): 통계적 기계 학습의 시작.
- 컴퓨터 프로그래밍과 통계적 모델링(statistical modeling)이 결합된 중요한 시대였다.
- 연구자들은 복잡한 지능 문제를 일반화하기 위해 데이터를 통해 매개변수를 학습해야 함을 깨닫기 시작했다.
- 이 시기에 랜덤 필드(Random Fields), 베이즈 넷(Bayes Nets), 서포트 벡터 머신(Support Vector Machines, SVMs)과 같은 통계 모델들이 발전했다.
- 이 시기 동안 객체 인식에서 상당한 진전이 있었으며, 작은 수의 객체 클래스를 대상으로 하는 국제 벤치마크가 등장했다.
3) 이미지넷과 딥러닝 혁명의 탄생
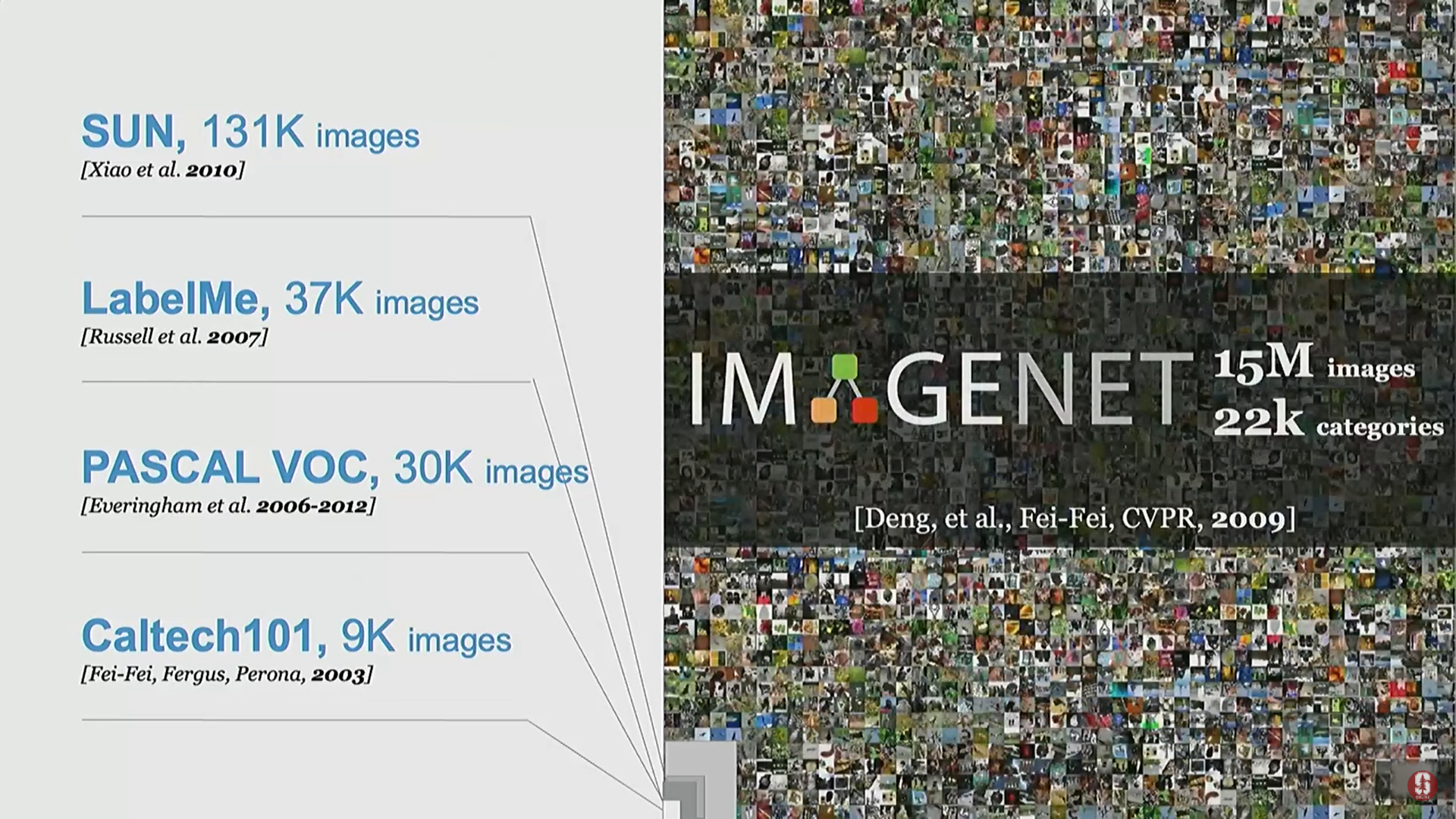
- 비어만 수(The Beerman Number): 심리학자 어브 비어만(Irv Beerman)은 인간이 (6~7세경) 약 3만 개에서 10만 개의 시각적 범주를 인식할 수 있다고 추측했다. 이는 사전을 분석하고 아동의 시각 연구를 결합한 수치였다.
- 이 압도적인 숫자는 컴퓨터 비전 분야에 큰 충격을 주었고, 당시 다루던 작은 규모의 이미지와 클래스 수에 대한 반성을 촉발했다.
- 이미지넷(ImageNet) 프로젝트: 비어만 수를 진지하게 받아들여, 약 22,000개의 객체 클래스와 1,500만 개 이상의 이미지를 포함하는 대규모 데이터셋으로 구축되었다.
- 딥러닝의 도래: 이미지넷이라는 대규모 데이터가 제공되면서, 초기에는 합성곱 신경망(Convolutional Neural Network, CNN)이, 현재는 트랜스포머(Transformers)와 같은 강력한 알고리즘이 빅데이터를 통해 힘을 발휘하기 시작했다.

- 2012년의 수렴점: 딥러닝 혁명의 탄생은 세 가지 핵심 요소의 수렴으로 이루어졌다.
- 데이터: ImageNet Challenge.
- 알고리즘: CNN (초기).
- 컴퓨팅: 2개의 GPU 사용.
- 이로 인해 객체 인식 문제는 산업 응용 분야에서 "성숙된(matured problem)" 문제로 여겨질 만큼 큰 진전을 이루었다.
4) 객체 인식을 넘어선 시각 지능
- 시각 지능에 대한 탐구는 단순히 장면의 객체에 레이블을 붙이는 것을 넘어섰다.
- 관계 이해의 중요성: 두 장면이 동일한 객체(예: 라마와 사람)를 포함하더라도, 객체 간의 관계(relationship)에 따라 스토리가 완전히 달라질 수 있다.
- 인지 과학자 제레미 울프(Jeremy Wolf)는 복잡한 자연 장면을 이해하려면 객체 간의 관계를 코딩해야 한다고 강조했다.
- Scene Graph (장면 그래프): 이러한 관계를 이해하기 위한 초기 작업으로, 런제이(Ranjay)의 박사 학위 논문에서 다뤄졌다.
- 장면 그래프는 객체인 엔티티 노드(entity nodes)와 노드 간의 연결성으로 정의되는 관계(relationships)로 구성된다.
- Visual Genome: 객체 관계, 속성 및 스토리 설명을 포괄하는 데이터셋이 구축되었다.
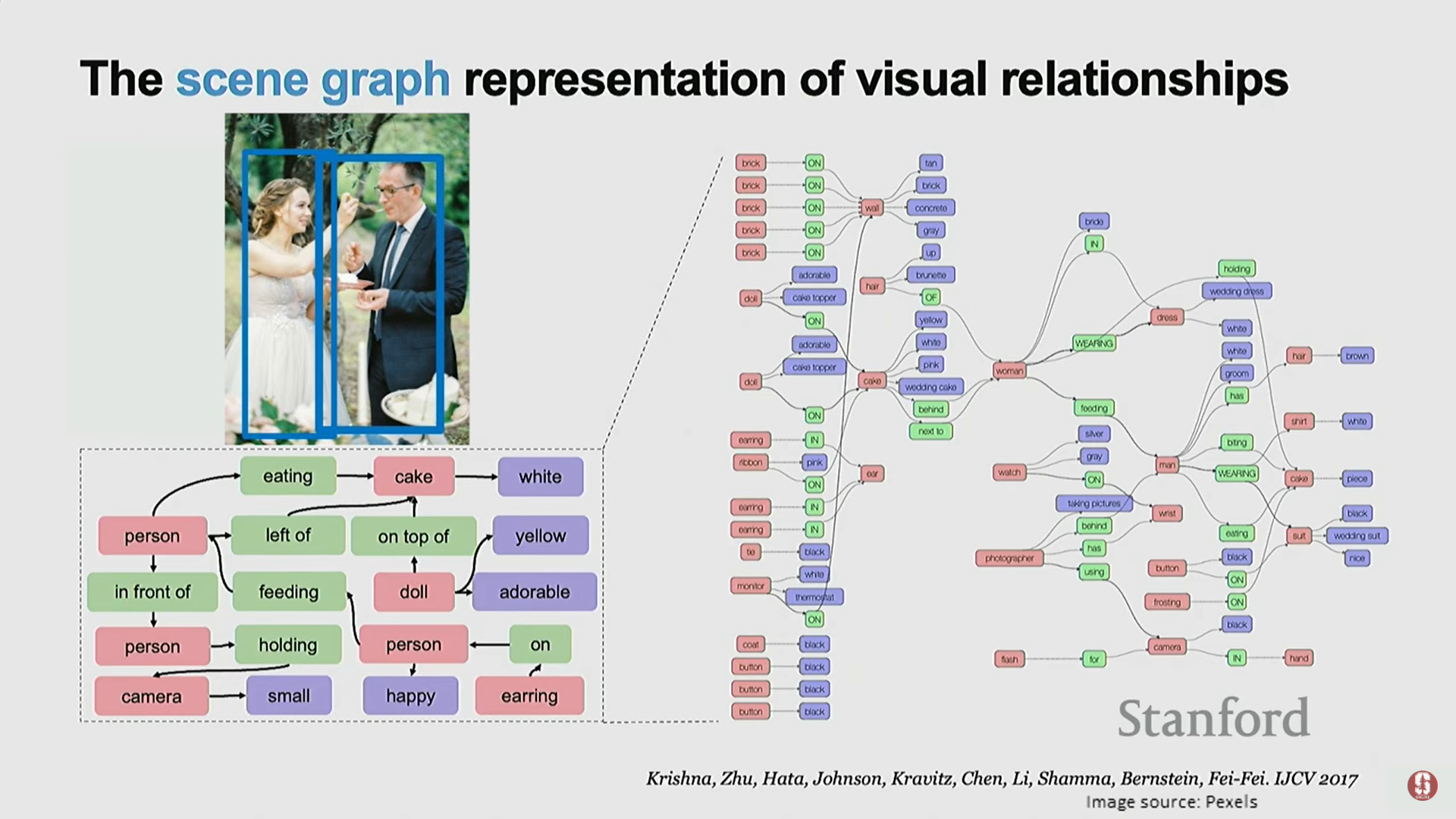
- 심화 내용 - 관계 학습의 이점:
- 관계 학습은 제로샷 학습(zero-shot learning)을 가능하게 한다. 예를 들어, '사람이 말을 탄다', '사람이 모자를 쓴다'는 흔하지만, '말이 모자를 쓴다'와 같은 흔치 않은 관계도 구성적인 장면 그래프 표현을 사용하여 학습된 공통 관계로부터 추론할 수 있게 된다.

- 관계 학습은 제로샷 학습(zero-shot learning)을 가능하게 한다. 예를 들어, '사람이 말을 탄다', '사람이 모자를 쓴다'는 흔하지만, '말이 모자를 쓴다'와 같은 흔치 않은 관계도 구성적인 장면 그래프 표현을 사용하여 학습된 공통 관계로부터 추론할 수 있게 된다.
-
이미지 캡셔닝 및 스토리텔링: 관계 이해 다음 목표는 자연어를 사용하여 훨씬 풍부한 이야기를 전달하는 능력이다.
- 2014년경부터 CNN과 LSTM(Long Short-Term Memory)이라는 언어 모델을 결합하여 이 문제에 접근하기 시작했다.
- 이는 Andrej Karpathy와 Justin Johnson 등의 연구로 시작되었으며, 현재는 멀티모달 LLM(Multimodal LLMs)을 사용하여 훨씬 높은 수준으로 발전했다.

-
동적 장면(Dynamic Scenes) 이해: 움직이는 장면에서는 더 복잡한 관계, 움직임, 카메라 이동이 발생한다.
- 다중 객체 다중 행위자 활동 이해(Multiobject Multi-actor activity understanding)는 여전히 미해결 과제(unsolved problem)로 남아 있다.
- 응용 분야: 이 문제를 해결하는 것은 로봇이 우리 주변에서 일상적으로 작동하는 것을 꿈꾼다면 (예: 실리콘 밸리의 로봇 산업) 매우 중요하며, 로봇이 복잡한 장면을 이해하고 다음에 무엇을 할지 예측하는 데 필요하다.
-
섹션 요약 및 통찰:
- 현대 AI의 동력: 데이터, 컴퓨팅, 신경망 알고리즘이 약 10~13년 전 수렴하면서 딥러닝 혁명이 일어났다.
- 지속적인 영감: 우리가 다뤄온 많은 문제는 인지 과학(cognitive science), 심리학, 신경 과학에서 영감을 받았으며, 이는 앞으로도 계속될 것이다. AI는 뇌 연구를 돕고, 뇌 연구는 AI를 발전시키는 친밀한 관계를 가지고 있다.
3. 인간이 보지 못하는 것을 AI가 보도록 구축하기 (Building AI to See What Humans Don't See)
1) 인간 능력을 초월하는 AI (Superhuman Abilities)
- AI를 인간의 능력 이상으로 밀어붙이는 연구 분야이다.
- 세밀 객체 분류(Fine-grained Object Categorization): 인간은 공룡의 종, 수천 종의 새, 수많은 자동차 모델을 모두 식별하는 데 능숙하지 않다.
- 이는 현재 멀티모달 LLM 시대에 다소 소외되고 있지만 중요한 문제이다.
- 세밀한 조류 종 인식 데이터셋(4,000종) 연구 결과, 일반적인 명칭에서는 오류율이 낮지만, 종 수준의 세밀한(fine-grained) 레벨로 내려갈수록 알고리즘의 오류가 여전히 많음을 보여준다.

- 사회 분석을 위한 컴퓨터 비전:
- 1970년대 이후 수천 가지의 자동차 모델(제조사, 모델, 연도)을 분류하는 세밀한 자동차 분류기를 훈련시켰다.
- 이 분류기를 구글 스트리트 뷰 이미지에 적용하여 수백 개의 주요 도시에서 거리에 있는 자동차 패턴을 분석했다.
- 결과: 자동차 모델은 교육, 소득, 투표 패턴, 심지어 환경 패턴과도 매우 높은 상관관계를 보였다.
- 심화 내용: 어떤 개별 인간도 수많은 자동차 모델을 식별하고 수많은 도시의 패턴을 쉽게 분석할 수 없으므로, 이는 AI가 사회를 연구하는 렌즈로서 인간의 능력을 초월한(superhuman) 경계를 밀어붙이는 예시이다.
2) 인간의 한계와 편향성 보완
- 인간은 시각적으로 한계를 가지고 있다.
- 스트룹 테스트(Stroop test): 단어를 읽는 능력과 단어의 색깔을 인지하는 능력이 충돌하여, 인간의 시각적 주의력(visual attention)의 한계를 보여준다.

- 변화 맹시(Change Blindness): 두 이미지가 번갈아 나타날 때, 큰 변화(예: 엔진이 사라지는 것)를 즉시 알아차리지 못하는 현상으로, 인간의 주의력 제한을 보여주는 유명한 심리학 실험이다.
- 실제적 위험: 이러한 인간의 주의력 한계는 심각한 결과를 초래할 수 있다. 예를 들어, 의료 오류는 미국에서 세 번째 주요 사망 원인이다.
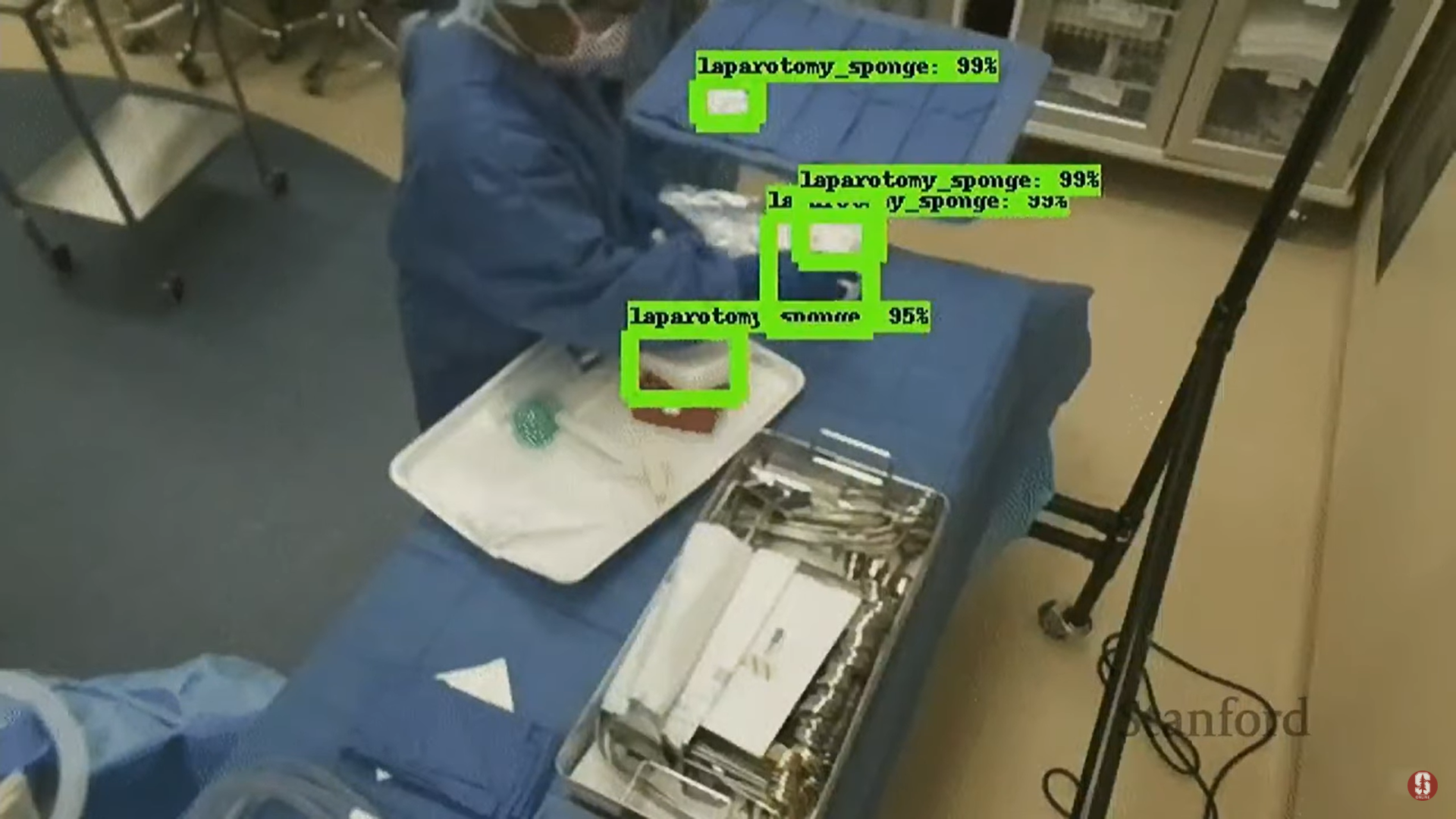
- 수술실에서 거즈나 봉합 바늘과 같은 작은 물체를 놓치는 실수가 발생하며, 이를 찾기 위해 수술을 중단하면 평균 1시간 가까이 지연되어 환자에게 위험(박테리아 노출, 출혈)을 초래한다.
- AI 적용: AI를 사용하여 수술 도구(예: 거즈)를 추적하는 기술은 인간의 주의력 문제를 보완하는 강력한 예시이다.
- 시각적 편향 (Visual Bias):
- 체크무늬 보드 위의 A와 B 두 사각형의 회색조(luminance)가 동일하다는 사실을 인지하기 어려운 유명한 착시 현상이 있다.
- 원인: 인간의 진화는 물체의 모양, 조명, 그림자가 생성되는 방식 등 세상에 대한 흔한 물리 법칙을 추론하도록 미리 연결되어(pre-wired) 있기 때문에, 다른 방식으로 보는 것이 어렵다.
- 이러한 진화적 구조나 사회적 경험에서 오는 편향은 AI 편향(AI bias)으로 이어질 수 있다.
- 유해한 편향: 몇 년 전 얼굴 인식 알고리즘은 특정 피부색이나 성별에 따라 인식률이 떨어지는 문제가 있었으며, 이는 자율주행차나 의료 분야에서 심각한 결과를 초래할 수 있다.
- 최신 동향: 2025년 현재, 학계와 산업계 모두에서 AI 편향 문제에 대한 인식이 크게 높아지고 있다.
3) 사생활 보호: 보고 싶지 않은 것을 보지 않도록 구축하기
- 때때로 보지 않는 것이 사생활 보호(privacy)를 위해 필요하며, AI가 도움을 주면서도 사람들이 원치 않는 것을 보지 않도록 만드는 것은 깊은 기술적, 인간적 문제이다.
- 기술적 해결책:
- 시각적 접근 방식: 흐림 처리(blurring), 마스킹(masking), 차원 축소(dimensionality reduction).
- 데이터 접근 방식: 모든 데이터를 서버로 보내지 않는 연합 학습(Federated Learning) 또는 암호화(encryption).
- 하드웨어 및 소프트웨어 하이브리드 접근:
- 홍 코엔(Hong Koen) 학생들의 연구에서는 특수하게 제작된 렌즈(handcrafted lens)를 카메라에 장착하여 시각 데이터를 특정 방식으로 필터링한다.
- 결과: 상단 이미지에서 보듯이 렌즈를 통해 캡처된 이미지는 사람의 얼굴이나 신체를 거의 보여주지 않아 프라이버시를 보호하지만.
- 동시에 특별히 설계된 소프트웨어와 결합하여 얼굴 정보는 복원하지 않으면서 사람이 무엇을 하고 있는지(움직임 정보/활동)는 파악할 수 있도록 한다.


- 섹션 요약 및 통찰:
- AI는 인간의 능력을 증폭시키는 강력한 도구이지만, 인간에게 편향이 있거나 문제가 있을 경우 AI 역시 이를 증폭시킬 수 있다.
- AI를 구축할 때 기술적 관점뿐만 아니라, 인간의 영향(human impact)을 연구하고 예측하며, 인간의 가치(human values)를 존중하는 인간의 관점을 가져야 한다.
4. 인간이 보고 싶어 하는 것을 AI가 보도록 구축하기 (Building AI to See What Humans Would Like to See)
1) AI를 증강 도구(Augmentation Tool)로 활용하기
- 노동에 대한 사회적 불안: AI가 일자리를 빼앗는다는 불안감이 크지만, 모든 기술 변화는 노동 시장 변화를 야기했으며, 이 그림은 복잡하다.
- 심화 내용 - 노동 시장의 변화:
- 과거에는 주로 육체 노동(physical labors) 위주로 위협이 논의되었으나, 최근 2년 동안 생성형 AI(GenAI)의 영향은 사무직(white collar jobs), 특히 소프트웨어 엔지니어링 및 분석 작업에 급격히 미치고 있다.
- 인간 노동력 부족: 현대 의학 발달로 기대 수명이 증가하면서 고령화 사회가 되었으나, 노인 돌봄 및 의료 분야에서는 근본적인 노동력 부족을 겪고 있다.
- 병원에서도 의료진, 특히 간호사의 이직(attrition)이 심각하여 환자를 도울 손, 귀, 눈이 부족하다.
- 대체(replace)가 아닌 증강(augment): AI를 인간의 부족한 부분을 채우는 증강 도구로 생각해야 한다.
2) 의료 분야를 위한 주변 지능 (Ambient Intelligence for Healthcare)
- 의료 분야의 암흑 공간(dark spaces) (수술실, 병실, 가정 등)에서는 눈(eye)의 부족 현상이 심각하다.
- 주변 지능: 스마트 센서를 기계 학습 알고리즘과 결합하여 의료 상황에서 건강에 중요한 통찰을 얻고, 환자/가족/의료진에게 적시에 알림을 제공하는 것을 목표로 한다.
- 1. 손 위생 프로젝트 (Hand Hygiene):
- 병원 획득 감염(hospital acquired infection, HAI)은 미국 환자 사망의 주요 원인 중 하나이며, 매년 자동차 사고로 인한 사망자보다 3배 이상 많다.
- 기존 방식의 한계: 인간 감사관(auditors)은 피로, 주의력 문제로 충분하지 않고, RFID 방식은 특정 위치(싱크대 옆)에 있다는 힌트만 줄 뿐 실제 행동을 보장하지 못한다.
- AI 적용: 프라이버시를 보호하기 위해 깊이 정보(depth information)만 제공하는 스마트 센서(파란색 화면)를 사용하고, 컴퓨터 비전 알고리즘을 사용하여 손 씻기 여부를 분류했다.
- 결과: 알고리즘이 인간의 감지 결과보다 훨씬 일관되고 정확함을 입증했다. AI만큼 정확한 결과를 얻으려면 거의 네 명의 인간이 필요하다.

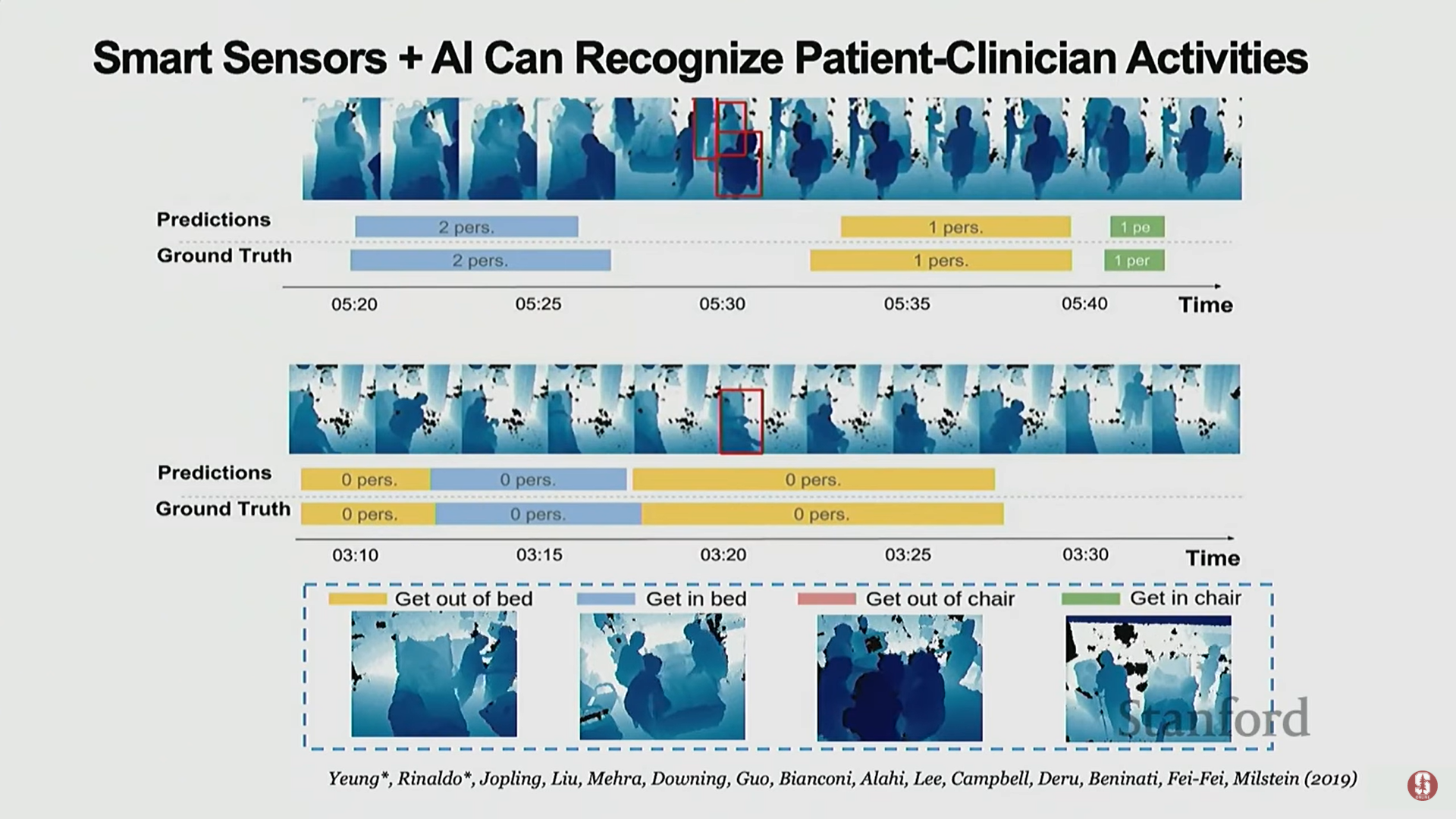
- 2. ICU 환자 이동 (ICU Mobilization):
- ICU(중환자실)는 US GDP의 1%가 지출되는 중요한 곳이며, 목표는 환자를 안전하게 퇴원시키는 것이다.
- 재활의 중요성: 환자의 회복을 위해 적절한 움직임(mobilization)을 돕는 것이 매우 중요하다.
- AI 적용: ICU에 스마트 센서를 설치하여 환자의 네 가지 중요한 움직임(침대에서 일어나기, 침대에 눕기, 의자에서 일어나기, 의자에 앉기)을 감지하고 예측할 수 있도록 돕는다. 이는 인력 부족 시기에 특히 유용하다.
- 3. 거주지 노화 지원 (Aging in Place):
- 노인들이 집에서 독립적이고 건강하게 생활할 수 있도록 지원하는 것은 매우 중요하다.
- 스마트 센서와 AI를 사용하여 열화상 카메라를 통한 감염 조기 감지, 이동성 모니터링, 수면 패턴, 식이 패턴 분석 등 다양한 가능성이 열려 있다.
3) 신체화된 AI: 로봇 공학 (Embodied AI: Robotics)
- 스마트 센서가 정보를 수집하는 데 그친다면, 로봇 공학(Robotics)은 환자의 자세를 바꾸거나 물/약물을 가져다주는 등 실제 행동을 수행할 수 있게 한다.
- 로봇 공학은 인지(perception)와 행동(action) 사이의 루프를 닫는 영역이다. 캄브리아기 폭발 때 시각의 출현이 동물의 움직임을 촉발했듯이, 보는 것(seeing)과 행동하는 것(doing)을 연결한다.
- 로봇의 현주소: 현재 로봇은 여전히 매우 느리고, 서투르며, 일반화된 상황에 적응하기 어렵다. 대부분의 연구는 제한된 환경(constrained setup)과 단기적 작업(pick and place)에 머물러 있다.

LLM/VLM을 활용한 일반화 학습
- '야생에서의 일반화(In-the-wild Generalization)' 문제: 작업 세트를 미리 정의해야 하는 기존 방식의 한계를 극복하고, 개방형 명령(open instruction)을 로봇에게 내릴 수 있도록 하는 것이 목표이다.
- 기술적 배경 및 방법: 최신 LLM(Large Language Model) 및 VLM(Visual Language Model)의 발전을 활용한다.
- LLM: 사용자의 개방형 명령(예: "맨 위 서랍을 열어")을 로봇이 실행할 수 있는 코드 또는 지침 세트로 변환한다.
- VLM: LLM으로부터 받은 지침(예: 서랍, 손잡이)을 사용하여 환경을 인식하고 장면에서 객체(서랍, 손잡이)를 감지한다.
- 모션 계획(Motion Planning): VLM의 정보를 기반으로 로봇 팔이 초점을 맞춰야 할 영역과 피해야 할 영역을 보여주는 히트맵(heat map) 형태의 모션 계획 맵을 업데이트한다.
- 제약 조건 처리: "꽃병에 주의하면서"와 같은 추가 명령이 들어오면, LLM/VLM은 꽃병을 감지하고 모션 계획 맵에 회피 영역(negative)을 업데이트하여 경로를 통합한다.
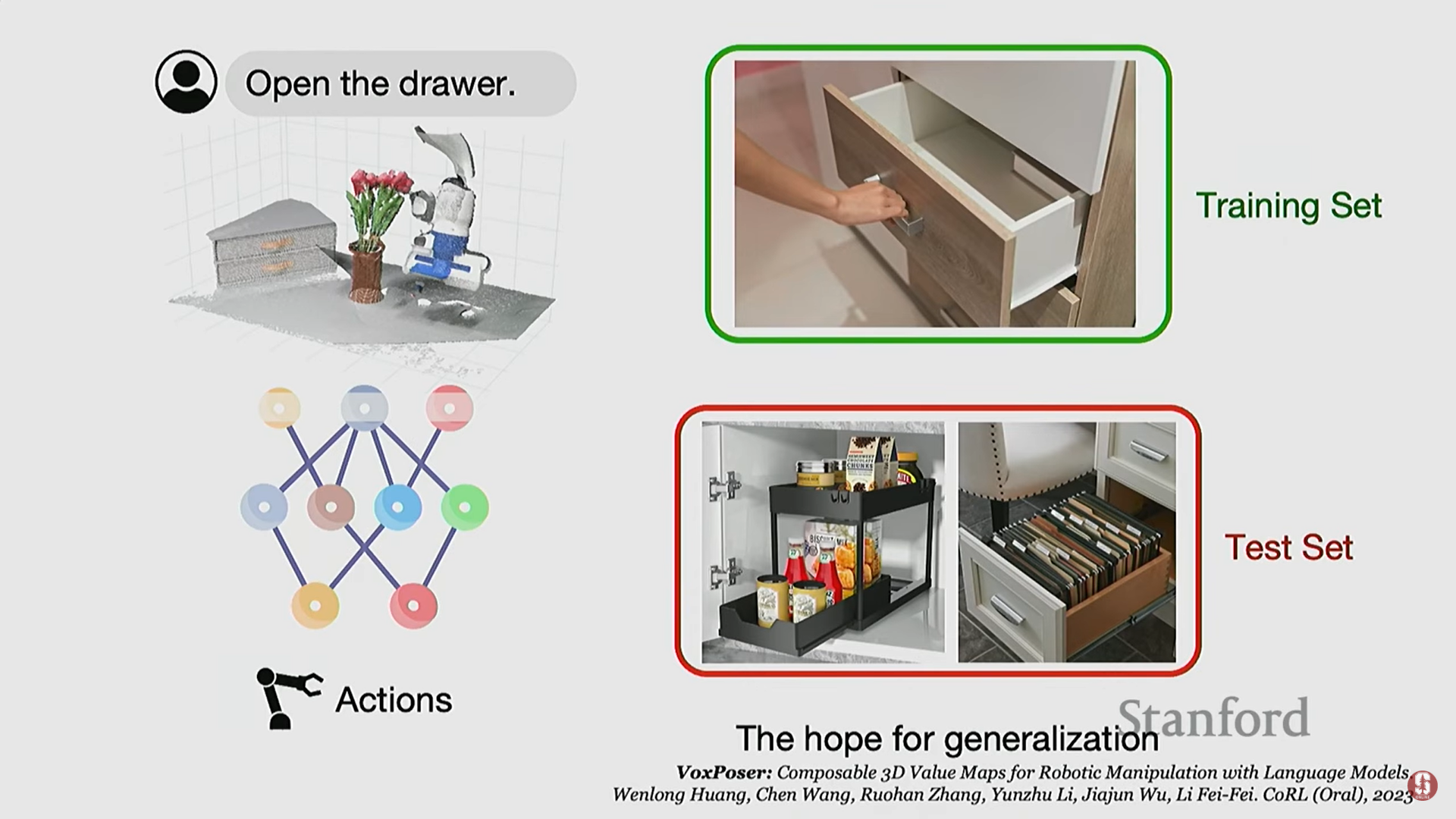

- 심화 내용 - LLM/VLM의 역할: 이 접근 방식을 통해 로봇은 닫힌 세계(closed world)에서만 훈련해야 하는 문제에서 벗어나, 더욱 일반화 가능하고 예측하지 못한 환경에서도 작업을 수행할 수 있게 되었다.
4) BEHAVIOR 벤치마크: 인간 중심의 작업 선택

-
로봇 공학 연구는 여전히 우수한 벤치마크가 부족하며, 실제 세계는 복잡성, 불확실성, 상호작용성, 멀티태스킹 측면에서 실험실보다 훨씬 복잡하다.
-
BEHAVIOR (Benchmark for Everyday Household Activity in Virtual Interactive and Ecological Environments) 프로젝트: 일상적인 가정 활동에 대한 대규모의 다양한 활동 벤치마크를 구축하여 생태학적 로봇 학습을 장려한다.

-
로봇이 수행해야 할 작업 결정 (인간 중심 조사):
- 로봇이 어떤 작업을 수행해야 할지 연구자가 임의로 결정하는 대신, 인간에게 로봇의 도움을 받고 싶은 작업이 무엇인지 묻는 인간 중심의 설문조사를 실시했다.
- 정부 조사 및 노동청 데이터를 취합하여 수천 가지 일상 활동 목록을 만들고, 1,400명의 다양한 사람들에게 선호도를 물었다.
- 결과: 사람들은 화장실 청소, 바닥 청소, 빨래 개기 등 청소 관련 작업에서 로봇의 도움을 가장 선호했다.
- 인간이 원치 않는 작업: 그러나 스쿼시 경기, 결혼반지 구입, 아기 시리얼 섞기 등 정서적, 사회적으로 인간에게 중요한 많은 작업에 대해서는 로봇의 도움을 원하지 않았다.
- BEHAVIOR 목표: 이 설문조사를 통해 인간이 도움을 선호하는 수천 가지 작업을 로봇 훈련 목표로 삼았다.

-
가상 환경 구축:
- 연구자들은 물리적, 인지적, 상호작용적으로 높은 품질의 시뮬레이션 환경을 구축했다.
- 50개의 실제 환경(식당, 아파트, 사무실 등)에서 스캔하거나 확보한 3D 장면을 사용했다.
- 변형 가능성(deformability), 열(thermal), 투명도와 같은 물리적 효과를 고려했다.
-
현재의 한계:
- 오늘날의 알고리즘은 BEHAVIOR 벤치마크의 복잡한 작업을 여전히 수행하지 못한다.
- 로봇에게 어떠한 특권 정보도 주어지지 않은 상태(가장 어려운 시나리오)에서 벤치마크를 수행했을 때, 현재 로봇 알고리즘의 성능은 거의 0에 가깝다.
- 이는 연구자들에게 성장할 여지가 매우 많음을 시사한다.

- 뇌파 제어 로봇 (Brain-Controlled Robotics):
- 뇌 연구자 및 의사들과 협력하여 뇌파를 사용하여 로봇을 제어하는 연구를 진행하고 있다.
- 데모: 학생이 EEG 캡(뇌전도 캡)을 착용하고, 비침습적인 전기 신호를 통해 로봇 팔에게 미리 훈련된 지침(들기, 놓기 등)을 보내 일본식 식사를 요리하도록 할 수 있다.
- 미래 전망: 이는 시각, 인지, 로봇 공학의 결합을 통해 심각한 마비 환자를 돕는 데 중요한 미래 기술이 될 것이다.
5. 결론: 인간을 증강하는 AI
- 마지막 핵심 메시지: AI를 단순히 어떤 일을 하거나 보는 도구로 만드는 것을 넘어, 인류를 위한 증강 도구(augmentation tool) 또는 향상 도구로 구축하는 것이 매우 중요하다.
- AI는 우리를 대체하는(replace) 도구가 아닌, 향상시키는(enhancing) 도구가 되어야 한다.

AI 공부합니다