1. 생성 모델의 핵심 과제와 철학
- 고차원 신호의 이해: 컴퓨터 비전, NLP, 음성 인식 등 AI의 다양한 분야에서 직면하는 근본적인 과제는 이미지, 오디오, 텍스트와 같은 복잡한 고차원 신호(High-dimensional signal)를 처리하는 것입니다.
- 데이터의 표현: 컴퓨터 입장에서 이미지는 단순한 숫자 행렬에 불과하며, 이를 의사 결정에 유용한 표현으로 매핑하여 객체 간의 관계나 재질, 움직임 등을 파악하는 것이 중요합니다.
- 생성적 접근의 철학: 리처드 파인만(Richard Feynman)의 "내가 창조할 수 없는 것은 이해한 것이 아니다"라는 문구에서 영감을 얻어, 어떤 대상을 진정으로 이해한다면 그것을 생성할 수도 있어야 한다는 관점을 취합니다.
- 이해와 생성의 관계: 예를 들어 사과를 이해한다면 머릿속으로 사과를 그려낼 수 있어야 하고, 특정 언어를 이해한다면 그 언어로 문장을 구사할 수 있어야 합니다. 챗GPT와 같은 모델이 일관성 있는 텍스트를 생성한다는 것은 언어의 문법뿐만 아니라 세상에 대한 상식(Common sense)을 어느 정도 이해하고 있음을 시사합니다.
2. 생성 모델의 구조: 통계적 시뮬레이터
- 컴퓨터 그래픽스와의 차이: 그래픽스는 물리 법칙과 빛의 전달 특성 등을 활용한 렌더러를 통해 이미지를 생성하지만, 본 강의에서는 데이터 기반(Data-driven)의 통계적 모델에 집중합니다.
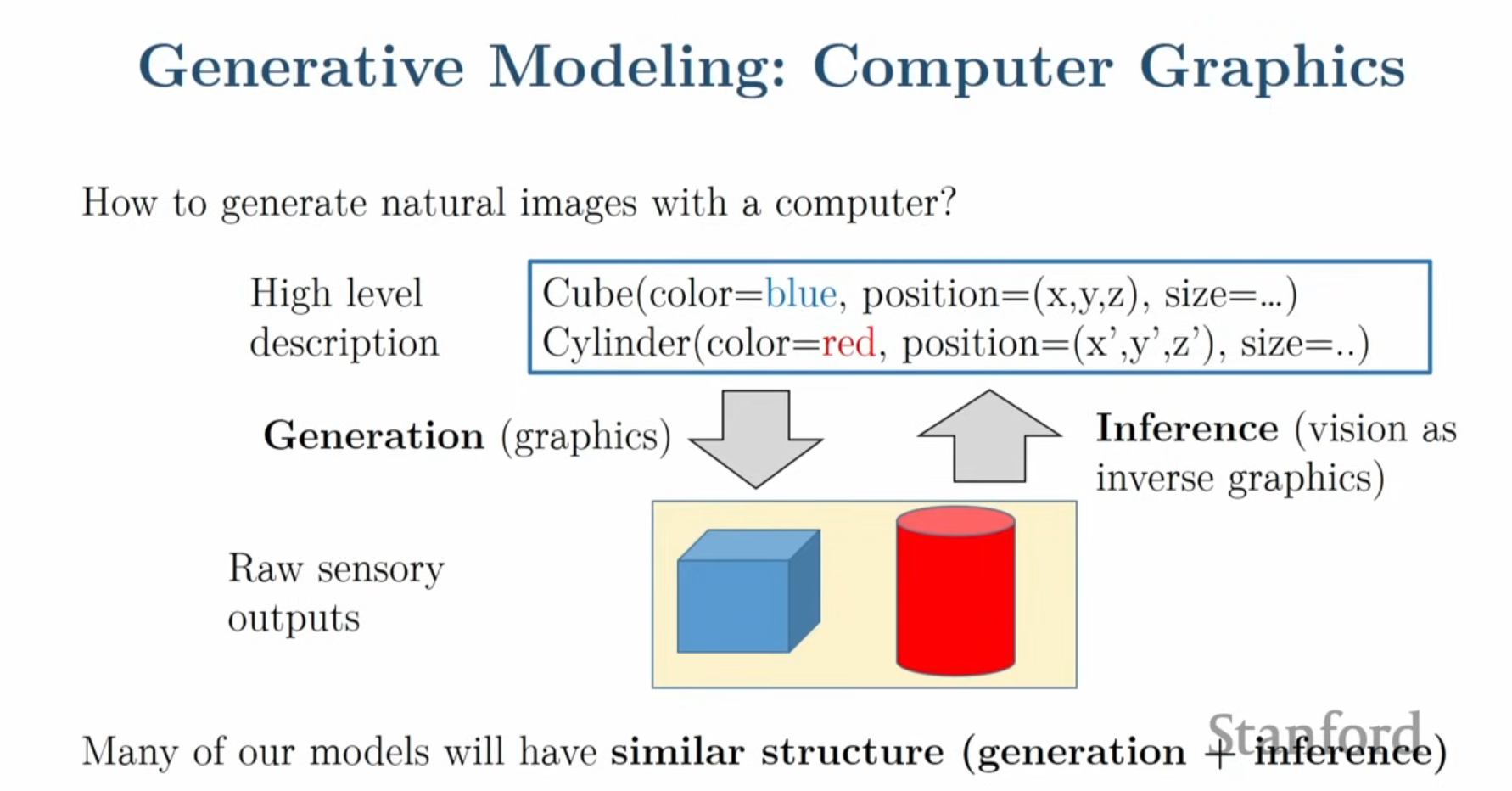
- 확률 분포로서의 모델: 생성 모델은 본질적으로 데이터 (이미지나 텍스트 등)에 대한 확률 분포(Probability distribution) 를 학습하는 것입니다.

- 학률적 데이터 생성: 모델이 학습한 확률 분포에서 샘플링(Sampling)을 수행함으로써 학습 데이터와 유사한 새로운 데이터를 생성해 낼 수 있습니다.
- 데이터 시뮬레이터: 기존의 머신러닝이 데이터를 입력으로 처리했다면, 생성 모델은 데이터를 출력으로 내보내는 '데이터 시뮬레이터' 역할을 합니다.
- 제어 신호(Control Signal): 사용자는 캡션, 스케치, 혹은 다른 언어의 텍스트와 같은 제어 신호를 입력하여 생성 과정을 조절할 수 있습니다.
3. 주요 응용 분야 및 기술적 발전
- 이미지 생성 및 편집:
- GAN(Generative Adversarial Networks): 초기 이미지 생성 발전을 주도하며 해상도와 사실감을 크게 높였습니다.
- 확산 모델(Diffusion Models): 스탠포드에서 제안된 점수 기반 확산 모델(Score-based diffusion models)은 현재 Stable Diffusion, DALL-E 3, Midjourney 등의 핵심 기술로 자리 잡았습니다.
- 역문제 해결(Inverse Problems): 저해상도를 고해상도로 바꾸는 초해상도(Super-resolution), 흑백 사진의 채색(Colorization), 지워진 부분을 채우는 인페인팅(Inpainting) 등이 가능합니다.
- 의료 영상: MRI나 CT 스캔 시 측정 횟수를 줄여 환자의 방사선 노출을 최소화하면서도 고품질 영상을 복원하는 데 기여합니다.
- 오디오 및 언어:
- 음성 합성: 구글의 WaveNet을 거쳐 현재는 감정 표현이 가능한 훨씬 사실적인 음성 합성이 가능해졌습니다.
- 대규모 언어 모델(LLM): 인터넷의 방대한 텍스트로 학습하여 문맥을 이해하고 질문에 답하며, 코드 생성 및 기계 번역에서도 뛰어난 성능을 보입니다.
- 비디오 및 로보틱스: 텍스트를 비디오로 변환하거나, 인간의 행동을 모방하여 자동차 운전 및 물체 쌓기와 같은 작업을 수행하는 모방 학습(Imitation learning)에 활용됩니다.
- 과학적 탐구: 특정 성질을 가진 분자나 단백질 구조를 설계하여 신약 개발 및 촉매 설계에 혁신을 가져오고 있습니다.
4. 생성 모델의 3가지 핵심 요소 (수학적 기초)
강의에서는 모델을 구축하기 위해 다음 세 가지 관점을 깊이 있게 다룹니다.
① 표현 (Representation)
- 수많은 픽셀이나 단어들 사이의 복잡한 상호관계를 모델링하기 위해 신경망(Neural Networks)을 사용하여 확률 분포 를 표현합니다. 단순한 가우시안 분포로는 고차원의 복잡한 데이터를 담아낼 수 없기 때문에 정교한 아키텍처가 필요합니다.
② 학습 (Learning)
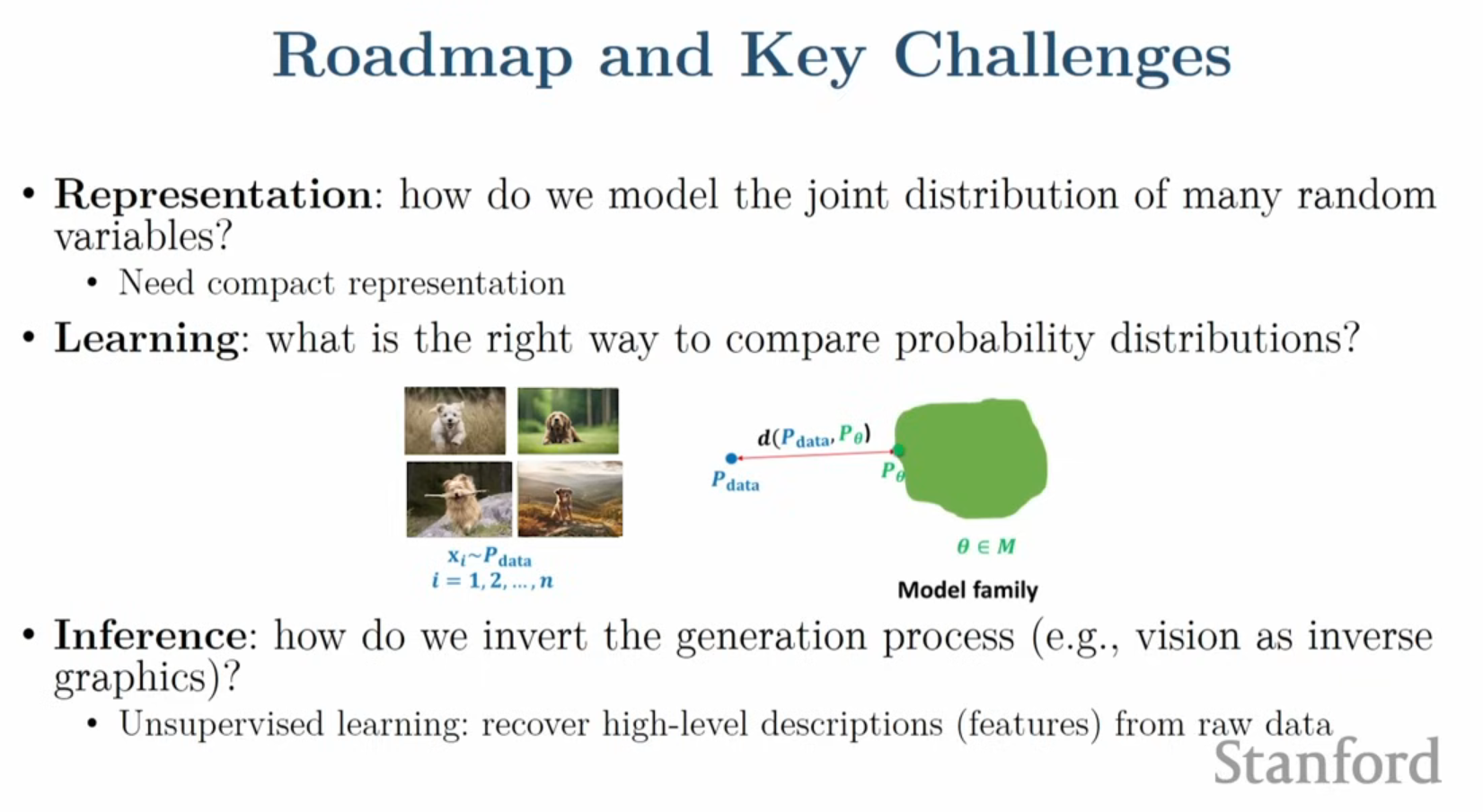
- 데이터 분포()와 모델 분포() 사이의 유사도를 측정하고, 이를 가깝게 만드는 손실 함수(Loss function)를 최적화합니다.
- 최대 가능도 추정(Maximum Likelihood Estimation) 등의 기법을 사용하며, 고차원 공간에서 두 분포의 유사성을 측정하는 것은 수학적으로 매우 도전적인 과제입니다.
③ 추론 (Inference)
- 학습된 모델로부터 효율적으로 샘플을 생성하거나, 데이터로부터 잠재 변수(Latent variables)를 추론하여 데이터의 특징을 추출하는 과정을 포함합니다.
5. 모델 분류 및 심화 학습
강의에서 다루는 주요 모델들의 계보와 특징은 다음과 같습니다.
- 우도 기반 모델 (Likelihood-based Models):
- 자기회귀 모델(Auto-regressive Models): 텍스트의 다음 토큰을 이전 토큰들을 기반으로 예측하는 방식으로, GPT와 같은 LLM의 근간이 됩니다.
- 흐름 기반 모델(Flow-based Models): 연속적인 가역 변환을 통해 데이터를 모델링합니다.
- 잠재 변수 모델 (Latent Variable Models):
- VAE(Variational Autoencoders): 잠재 변수를 활용하여 모델의 표현력을 높이며, 변분 추론을 통해 학습합니다.
- 암시적 생성 모델 (Implicit Generative Models):
- GAN: 확률 분포를 직접 정의하지 않고 샘플링 프로세스 자체를 학습합니다. 우도(Likelihood)에 접근할 수 없어 최대 가능도 추정 대신 차별자와의 경쟁을 통해 학습합니다.
- 에너지 기반 및 확산 모델 (Energy-based & Diffusion Models):
- 최신 이미지 및 오디오 생성의 핵심 기술로, 잠재 변수 모델과의 연결성을 가집니다.
6. QnA 섹션
Q: 비디오 생성 시스템(예: 강의에서 보여준 영상)은 순수하게 텍스트 캡션만으로 생성되나요? 아니면 시작 이미지를 제공해야 하나요?
A: 강의에서 보여준 예시 중 일부는 순수하게 텍스트 캡션만으로 생성된 것입니다. 하지만 시스템에 따라 캡션과 함께 시드 이미지(Seed image)를 제어 신호로 사용하여 특정 캐릭터를 애니메이션화하는 등의 방식도 가능합니다. 이는 생성 과정을 제어하는 다양한 방법 중 하나입니다.
심화 기술 정보:
강의에서 언급된 자기회귀 모델(Auto-regressive Models)은 이전 단계의 출력이 다음 단계의 입력이 되는 구조를 가집니다. 이는 특히 NLP에서 문장의 문맥을 유지하는 데 강력하지만, 생성 속도가 순차적이라는 기술적 한계가 있습니다. 반면, 확산 모델은 데이터에 노이즈를 점진적으로 추가했다가 이를 다시 제거하는 과정을 학습함으로써 GAN의 학습 불안정성 문제를 해결하고 고품질의 결과물을 만들어내는 최신 동향을 보여줍니다.
학습 비유: 생성 모델을 학습시키는 것은 마치 '보이지 않는 조각상'을 공기의 흐름(확률 분포)만으로 재구성하는 것과 같습니다. 데이터라는 조각상을 직접 만질 수는 없지만, 그 주변의 공기 흐름을 완벽히 이해하고 시뮬레이션할 수 있다면 결과적으로 똑같은 형태의 조각상을 만들어낼 수 있는 원리입니다.

AI 공부합니다