1. GAN 복습 및 기본 개념
- Likelihood-free 학습: 생성적 적대 신경망(GAN)의 가장 큰 장점은 모델의 확률 밀도 함수를 명시적으로 정의하거나 연쇄 법칙(chain rule)에 따라 분해할 필요 없이, 우도(Likelihood)를 계산하지 않고도 모델을 학습시킬 수 있다는 점입니다.
- 판별자(Discriminator)의 역할: GAN은 분류기(Classifier), 즉 판별자를 사용하여 생성 모델의 분포와 데이터 분포를 비교합니다. 판별자는 입력된 샘플이 실제 데이터 분포에서 왔는지, 모델 분포에서 왔는지(가짜인지) 구분하도록 학습됩니다.
- Minimax 게임: GAN의 학습은 생성자(Generator)와 판별자 간의 Minimax 게임으로 구성됩니다. 생성자는 판별자가 구분하지 못할 만큼 정교한 샘플을 만들어 판별자를 속이려 하고, 판별자는 이를 정확히 구분하려 노력합니다.
- 최적 판별자와 JSD: 판별자가 최적화되었다고 가정할 때, GAN의 목적 함수는 데이터 분포와 모델 분포 사이의 Jensen-Shannon Divergence (JSD)를 최소화하는 것과 같습니다. 이는 기존의 최대 우도 학습(Maximum Likelihood Learning)이 KL Divergence를 최소화하는 것과 유사한 맥락입니다.
2. f-Divergence: 거리 개념의 확장
- f-Divergence의 정의: JSD뿐만 아니라 더 넓은 범주의 발산(Divergence) 개념인 f-Divergence를 GAN 학습에 적용할 수 있습니다. 두 확률 밀도 함수 와 사이의 f-Divergence는 다음과 같이 정의됩니다.
여기서 함수 는 볼록(convex)하고 하반연속(lower semicontinuous)이어야 하며, 을 만족해야 합니다.
-
f-Divergence의 성질:
- 비음수성(Non-negative): 가 볼록 함수이고 이라는 조건 덕분에, 젠슨 부등식(Jensen's inequality)에 의해 f-Divergence는 항상 0보다 크거나 같습니다.
- 일치성: 두 분포 와 가 동일하다면, 모든 에 대해 비율이 1이 되므로 발산 값은 0이 됩니다.

-
다양한 Divergence 유도: 함수 를 어떻게 정의하느냐에 따라 다양한 Divergence를 유도할 수 있습니다.
- KL Divergence:
- Reverse KL Divergence:
- Jensen-Shannon Divergence: (특정 형태 변형 시)
- Squared Hellinger Distance 등

3. f-GAN: 변분적 접근 (Variational Estimation)
-
밀도 비율(Density Ratio) 문제: f-Divergence를 직접 최적화하려면 라는 밀도 비율을 알아야 하는데, 우리는 실제 데이터 분포 를 알 수 없고 모델 분포 의 확률값조차 계산하기 어려운 경우가 많습니다. 따라서 이를 우도 계산 없이 샘플링만으로 추정할 수 있는 방법이 필요합니다.

-
펜헬 켤레(Fenchel Conjugate) 사용: 볼록 함수 에 대해 펜헬 켤레 함수 는 다음과 같이 정의됩니다.
또한 가 볼록하고 하반연속이면, 켤레의 켤레는 원래 함수로 돌아오는 성질()이 있습니다.
-
변분 하한(Variational Lower Bound) 유도:
이 성질을 이용하여 f-Divergence 식의 부분을 변분 형태로 바꿀 수 있습니다. 이를 통해 밀도 비율 항을 함수 밖으로 꺼내어 선형적인 의존성으로 바꿀 수 있습니다.
최종적으로 f-Divergence의 하한은 다음과 같이 두 기댓값의 차이로 표현됩니다.

-
GAN과의 연결: 위 식에서 는 GAN의 판별자(Discriminator) 역할을 하는 신경망으로 파라미터화할 수 있습니다. 즉, 를 최적화하여 하한을 최대화하는 과정은 GAN에서 판별자를 학습시키는 과정과 동일하며, 이를 통해 임의의 f-Divergence를 근사적으로 최소화할 수 있습니다.

- 심화 내용: f-GAN의 의의: 기존 GAN은 JSD라는 특정 거리 척도에 국한되었으나, f-GAN 프레임워크를 통해 KL, Reverse KL 등 다양한 거리 척도를 목적에 맞게 선택하여 최적화할 수 있게 되었습니다. 이는 모델이 데이터를 '압축'하는 방식(KL)을 따를지 혹은 다른 특성을 따를지를 결정할 수 있는 유연성을 제공합니다.
4. Wasserstein GAN (WGAN)
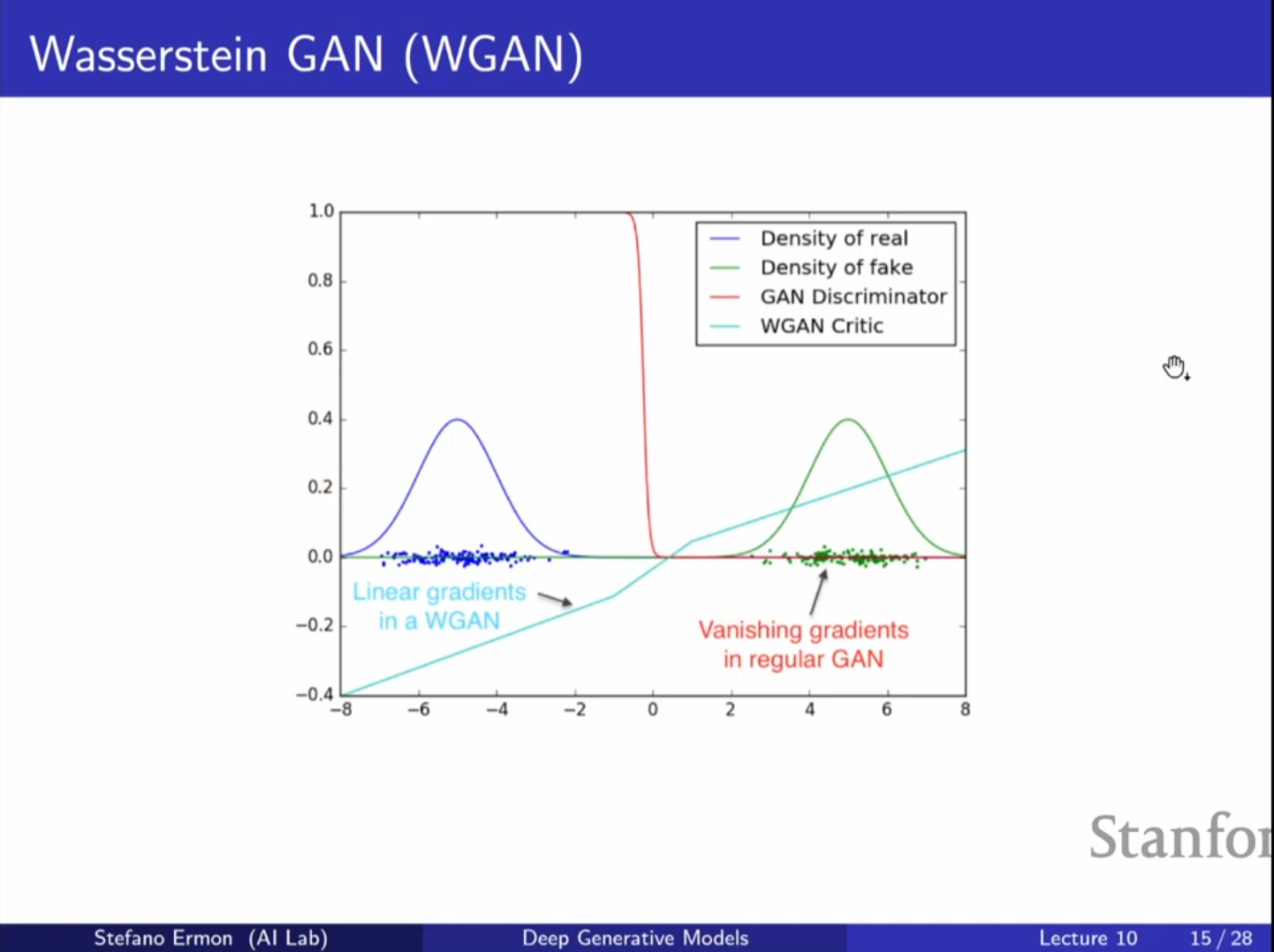
- f-Divergence의 한계: 두 분포의 지지 집합(Support, 확률 밀도가 0이 아닌 영역)이 서로 겹치지 않을 경우(Disjoint), KL Divergence나 JSD는 무한대 혹은 상수가 되어버립니다. 이 경우 기울기(Gradient)가 사라져서 생성자가 데이터를 실제 데이터 쪽으로 이동시킬 학습 신호를 받지 못하는 문제가 발생합니다.

-
Wasserstein 거리 (Earth Mover Distance):
- 직관: 확률 분포를 '흙무더기'로 생각했을 때, 한 분포()를 다른 분포()로 모양을 바꾸기 위해 옮겨야 하는 흙의 양과 거리의 곱(일의 양)의 최솟값으로 정의합니다.
- 정의:
여기서 는 와 를 주변 분포(Marginal distribution)로 가지는 결합 확률 분포(Joint distribution)입니다.
-
장점: Wasserstein 거리는 지지 집합이 겹치지 않아도 거리가 부드럽게 변하므로, 생성자에게 유의미한 기울기(Gradient) 정보를 지속적으로 제공할 수 있습니다.

- Kantorovich-Rubinstein Duality: 위 정의의 하한(infimum) 문제는 계산이 어렵지만, 쌍대성(Duality)을 이용해 다음과 같은 최대화 문제로 변환할 수 있습니다.
여기서 조건은 함수 가 1-Lipschitz 연속(1-Lipschitz continuous)이어야 한다는 것입니다. 즉, 함수의 기울기가 어디서든 1을 넘지 않아야 합니다.
- 구현 방법 (Weight Clipping): 신경망으로 를 근사할 때 Lipschitz 조건을 강제하기 어렵습니다. WGAN 논문에서는 가중치(Weight)를 특정 범위(예: [-0.01, 0.01])로 잘라내는(Clipping) 방식을 사용하여 이를 대략적으로 만족시켰습니다. 또는 Gradient Penalty를 사용하는 방법도 있습니다.
- 심화 내용: WGAN Critic의 특성: 표준 GAN의 판별자는 가짜와 진짜를 완벽히 구분하면(Sigmoid 곡선이 가파름) 기울기가 거의 0이 되어 학습이 멈춥니다. 반면, WGAN의 Critic(함수 )은 선형적인 형태를 유지하여 생성자가 생성한 샘플을 실제 데이터 방향으로 밀어줄 수 있는 일정한 기울기를 제공합니다.
5. BiGAN: 잠재 표현(Latent Representation) 학습
- 문제 의식: 일반적인 GAN은 잠재 변수 에서 데이터 로 가는 생성자 만 학습하므로, 주어진 데이터 에 대응하는 특징(Feature)인 를 역으로 추론(Inference)할 수 없습니다.


-
구조: 데이터 를 잠재 변수 로 매핑하는 인코더(Encoder) 를 추가합니다. 이제 판별자는 데이터 만 보는 것이 아니라, 쌍(Pair)을 입력받아 구분합니다.
-
학습 목표: 판별자는 다음 두 종류의 쌍을 구분하도록 학습됩니다.
- 실제 데이터 기반 쌍:
- 생성 모델 기반 쌍:
생성자 와 인코더 는 판별자를 속이도록, 즉 두 결합 분포(Joint distribution)가 일치하도록 학습됩니다.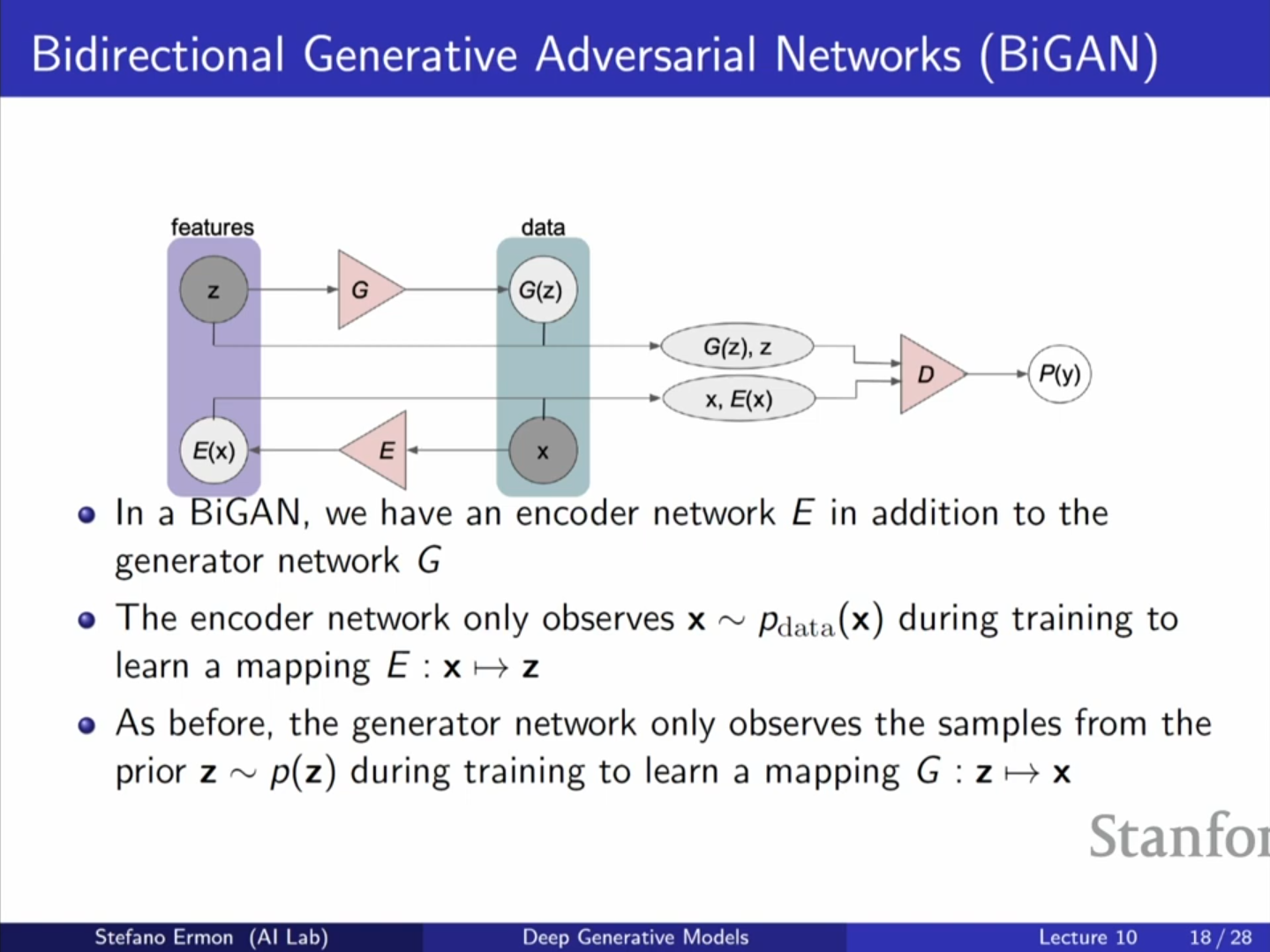
- 결과: 학습이 성공하면 인코더 는 생성자 의 역함수 역할을 하게 되며, 이를 통해 데이터의 유용한 잠재 표현을 추출하여 지도 학습이나 군집화 등의 다운스트림 작업(Downstream tasks)에 활용할 수 있습니다.

6. 질의응답 (QnA)
Q1: f-GAN 식에서 함수는 어떻게 파라미터화하나요?
A1: 는 모든 가능한 함수 집합에서 최적의 함수를 찾아야 하지만, 실제로는 신경망과 같은 함수 집합(Family of neural networks)을 사용하여 근사합니다. 이 경우 f-Divergence의 하한(Lower bound)을 구하게 되며, 신경망의 표현력이 좋을수록 더 정확한 근사값을 얻을 수 있습니다.
Q2: WGAN에서 1-Lipschitz 제약이 왜 필요한가요?
A2: 만약 제약 조건이 없다면, 판별자 함수 는 와 가 다른 확률을 가지는 지점에서 값을 무한히 키우거나 줄일 수 있어 목적 함수가 발산하게 됩니다. Lipschitz 제약은 함수가 너무 급격하게 변하지 않도록 제한하여 안정적인 거리 측정을 가능하게 합니다.
Q3: BiGAN의 인코더는 추론(Inference) 시에 어떻게 사용되나요?
A3: VAE와 유사하게, 학습이 끝난 후 실제 데이터 에 대한 특징 표현(Representation)을 얻고 싶을 때 인코더 에 를 입력하여 잠재 변수 를 얻습니다. 생성자 는 사용하지 않습니다.
7. 핵심 내용
- f-GAN의 일반화: GAN은 단순히 JSD를 최소화하는 것을 넘어, f-Divergence라는 더 넓은 제품군을 최소화하는 프레임워크로 확장될 수 있으며, 이는 변분적 하한(Variational Lower Bound)과 펜헬 켤레(Fenchel Conjugate)를 이용해 구현됩니다.
- Wasserstein 거리의 우수성: 지지 집합이 겹치지 않는 분포 간에도 안정적인 기울기(Gradient)를 제공하는 Wasserstein 거리를 도입함으로써, 기존 GAN의 학습 불안정성 문제를 해결하고 더 나은 학습 신호를 생성자에 제공할 수 있습니다.
- BiGAN을 통한 특징 학습: 생성자 외에 인코더(Encoder)를 도입하고 데이터와 잠재 변수의 결합 분포(Joint Distribution)를 맞추는 방식을 통해, GAN 구조에서도 데이터의 잠재 표현(Latent Representation)을 효과적으로 학습할 수 있습니다.
