1. 생성 모델의 기존 접근법과 한계
기존 모델의 회고 (Recap)
- 지금까지 다룬 모델들(Autoregressive Model, VAE, Normalizing Flow)은 모두 최대 우도(Maximum Likelihood) 학습을 기반으로 했습니다.
- 이들은 데이터 분포()와 모델 분포() 사이의 KL Divergence를 최소화하는 것과 동일한 목표를 가집니다.
- 최대 우도 추정은 데이터 압축 관점에서 효율적이며, 이상적인 조건 하에서는 데이터를 가장 효율적으로 사용하는 방법임이 증명되어 있습니다.

Likelihood와 샘플 품질의 괴리
-

-
하지만 높은 우도(High Likelihood)가 반드시 좋은 샘플 품질(Good Sample Quality)을 보장하는 것은 아닙니다. 반대로 좋은 샘플 품질이 높은 우도를 의미하지도 않습니다.
-
높은 우도이지만 나쁜 샘플인 경우:
- 예를 들어, 99%의 확률로 '노이즈(garbage)'를 생성하고 1%의 확률로만 '실제 데이터'를 생성하는 혼합 모델을 가정해 봅니다.
- 이 모델은 대부분 나쁜 샘플을 만들지만, 로그 우도(Log-Likelihood)를 계산해보면 실제 데이터 분포의 엔트로피에 근접한 꽤 높은 값을 가집니다.
- 특히 고차원 데이터일수록 이 상수 차이는 전체 차원 수에 비해 미미해지므로, 나쁜 모델도 수치적으로는 좋은 모델처럼 보일 수 있습니다.

-
나쁜 우도이지만 좋은 샘플인 경우:
- 과적합(Overfitting) 된 모델은 훈련 데이터를 단순히 암기하여 완벽한 샘플을 생성할 수 있습니다.
- 하지만 훈련 데이터 이외의 테스트 데이터에 대해서는 0에 가까운 확률을 부여하므로, 일반화 성능(Test Likelihood)은 최악이 됩니다.

심화 내용: Likelihood의 맹점
- KL Divergence나 Likelihood는 두 확률 분포가 완벽하게 일치할 때만 최적(0 또는 최대값)에 도달합니다.
- 하지만 모델이 불완전하여 최적점에 도달하지 못한 상태(Gap이 있는 상태)에서는, Likelihood 수치가 샘플의 시각적 품질(Perceptual Quality)과 비례하지 않을 수 있습니다.
- 이는 우리가 모델을 평가하는 기준(Metric)을 Likelihood에서 다른 것으로 변경해야 할 필요성을 시사합니다.
2. 이표본 검정(Two-Sample Test)과 학습된 통계량

이표본 검정의 개념
- 우리는 Likelihood를 계산하는 대신, 두 집단의 샘플(: 실제 데이터, : 모델 생성 데이터)이 동일한 분포에서 나왔는지를 판별하는 이표본 검정(Two-Sample Test) 방식을 도입합니다.
- 귀무가설()은 (두 분포가 같다)이며, 대립가설()은 입니다.
- 두 샘플 집단을 구별할 수 없다면, 우리 모델이 데이터 분포를 잘 학습했다고 볼 수 있습니다.


검정 통계량(Test Statistic)의 선택
- 두 집단을 비교하기 위해 평균이나 분산 같은 고정된 통계량을 사용할 수 있습니다.
- 하지만 고차원 데이터(이미지 등)에서는 단순한 평균이나 분산이 같다고 해서 두 분포가 같다고 보장할 수 없습니다 (예: 평균과 분산이 같지만 모양이 다른 Gaussian과 Laplace 분포).
- 따라서 우리는 사람이 직접 통계량을 설계하는 대신, 두 분포를 구별하는 최적의 통계량을 학습하기로 합니다.

3. GAN의 구조: 판별자(Discriminator)와 생성자(Generator)

판별자 (Discriminator)
- 역할: 실제 데이터와 생성된 가짜 데이터를 구별하는 이진 분류기(Binary Classifier) 입니다.
- 학습 목표: 분류 오차를 최소화(정확도 최대화)하여 두 분포의 차이를 가장 잘 포착하는 특징(Feature)을 학습합니다.
- 판별자의 손실 함수(Loss)의 음수 값은 두 분포가 얼마나 다른지를 나타내는 통계량으로 사용됩니다.

최적의 판별자 (The Optimal Discriminator)
- 판별자 가 최적으로 학습되었을 때, 입력 데이터 에 대해 출력하는 값은 다음과 같습니다:
- 만약 모델 분포 가 데이터 분포 와 완벽히 일치한다면, 판별자는 구별할 수 없으므로 모든 에 대해 0.5를 출력합니다.

생성자 (Generator)
- 역할: 간단한 분포(예: Gaussian)에서 추출한 잠재 변수 를 신경망을 통과시켜 데이터 로 변환합니다 ().
- 특징: Normalizing Flow와 달리 역변환이 가능할 필요가 없으며, 구조에 대한 제약이 거의 없습니다.
- 학습 목표: 판별자를 속이는 것, 즉 판별자가 실제와 가짜를 구별하지 못하도록(분류 손실이 커지도록) 만드는 것입니다.

4. Minimax 최적화 게임과 수학적 의미
Minimax Objective Function
GAN의 학습은 생성자()와 판별자()가 서로 경쟁하는 Minimax 게임으로 정의됩니다.
- 판별자(): 위 식을 최대화하려고 합니다. (진짜에는 높은 확률, 가짜에는 낮은 확률 부여).
- 생성자(): 위 식을 최소화하려고 합니다. (가짜 데이터가 진짜처럼 보이게 하여 를 1에 가깝게 만듦).
Jensen-Shannon Divergence (JSD)와의 관계
- 판별자가 매 순간 최적()이라고 가정하고, 이를 목적 함수에 대입하여 정리하면 다음과 같은 수식을 얻습니다.
- 여기서 Jensen-Shannon Divergence (JSD) 는 KL Divergence의 대칭적(Symmetric) 버전입니다.
- 결론적으로 GAN을 학습시킨다는 것은 데이터 분포와 모델 분포 사이의 JSD를 최소화하는 것과 수학적으로 동등합니다.
- JSD는 두 분포가 일치할 때 최솟값을 가지므로, 이론적으로 GAN은 데이터 분포를 완벽하게 학습할 수 있습니다.

심화 내용: GAN의 수학적 의의
- 기존 모델들은 KL Divergence를 최소화하는 반면, GAN은 판별자를 통해 간접적으로 JSD를 최소화합니다.
- JSD는 대칭적이며 항상 양수이고 상한이 있는 거리 측정 방식으로, KL Divergence와 다른 특성을 가집니다.
- 특히 우도(Likelihood)를 직접 계산할 필요 없이 샘플링만 가능하다면 어떤 형태의 생성 모델도 학습시킬 수 있다는 강력한 유연성을 제공합니다.

5. 학습 과정과 한계점
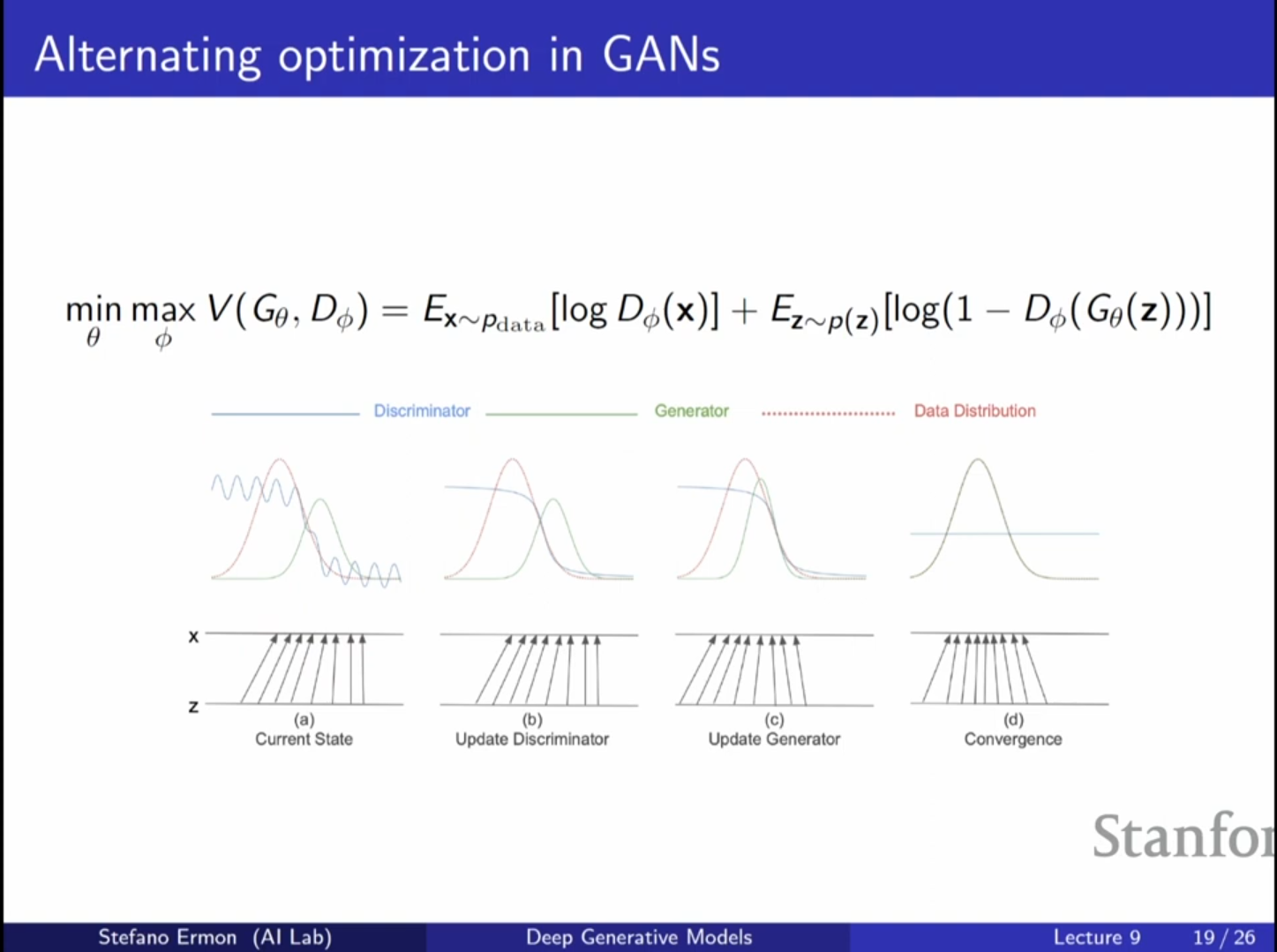
학습 알고리즘
- 판별자 업데이트: 실제 데이터와 생성된 데이터를 이용해 판별자의 분류 성능을 높이는 방향(Gradient Ascent)으로 파라미터를 업데이트합니다.
- 생성자 업데이트: 판별자를 속이는 방향(Gradient Descent)으로 생성자의 파라미터를 업데이트합니다. 이때 실제 데이터 항은 생성자와 무관하므로 무시됩니다.
- 이 과정을 반복하며 균형점(Equilibrium)을 찾아갑니다.

주요 문제점 (Challenges)
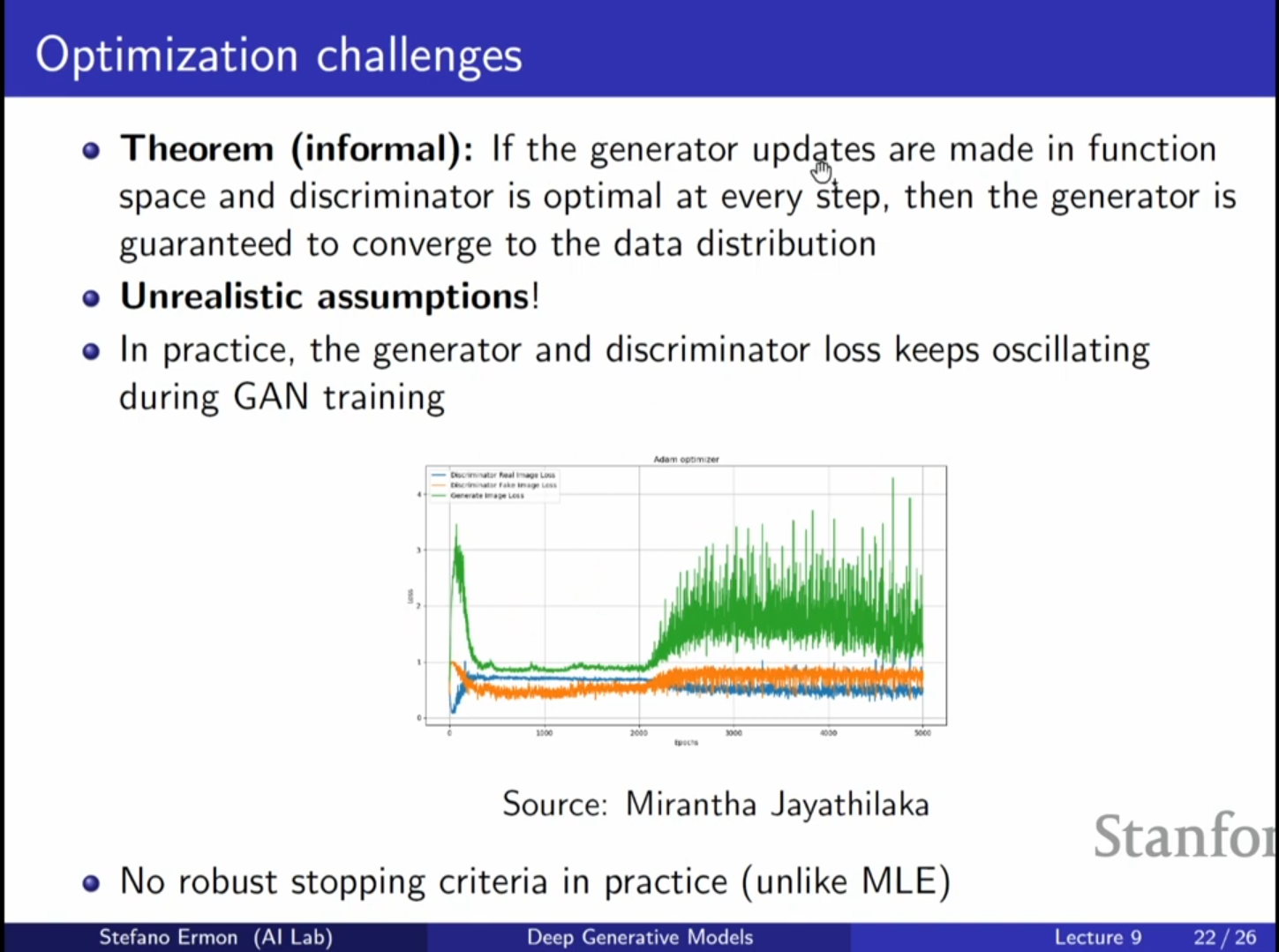
- 불안정한 최적화 (Unstable Optimization):
- 이론적으로는 수렴해야 하지만, 실제로는 두 신경망이 계속해서 서로를 이기려다 보니 손실 함수가 수렴하지 않고 진동(Oscillation)하는 경우가 많습니다.
- 명확한 종료 조건(Stopping Criteria)이 없어, 사람이 직접 샘플을 보고 학습 중단을 결정해야 합니다.
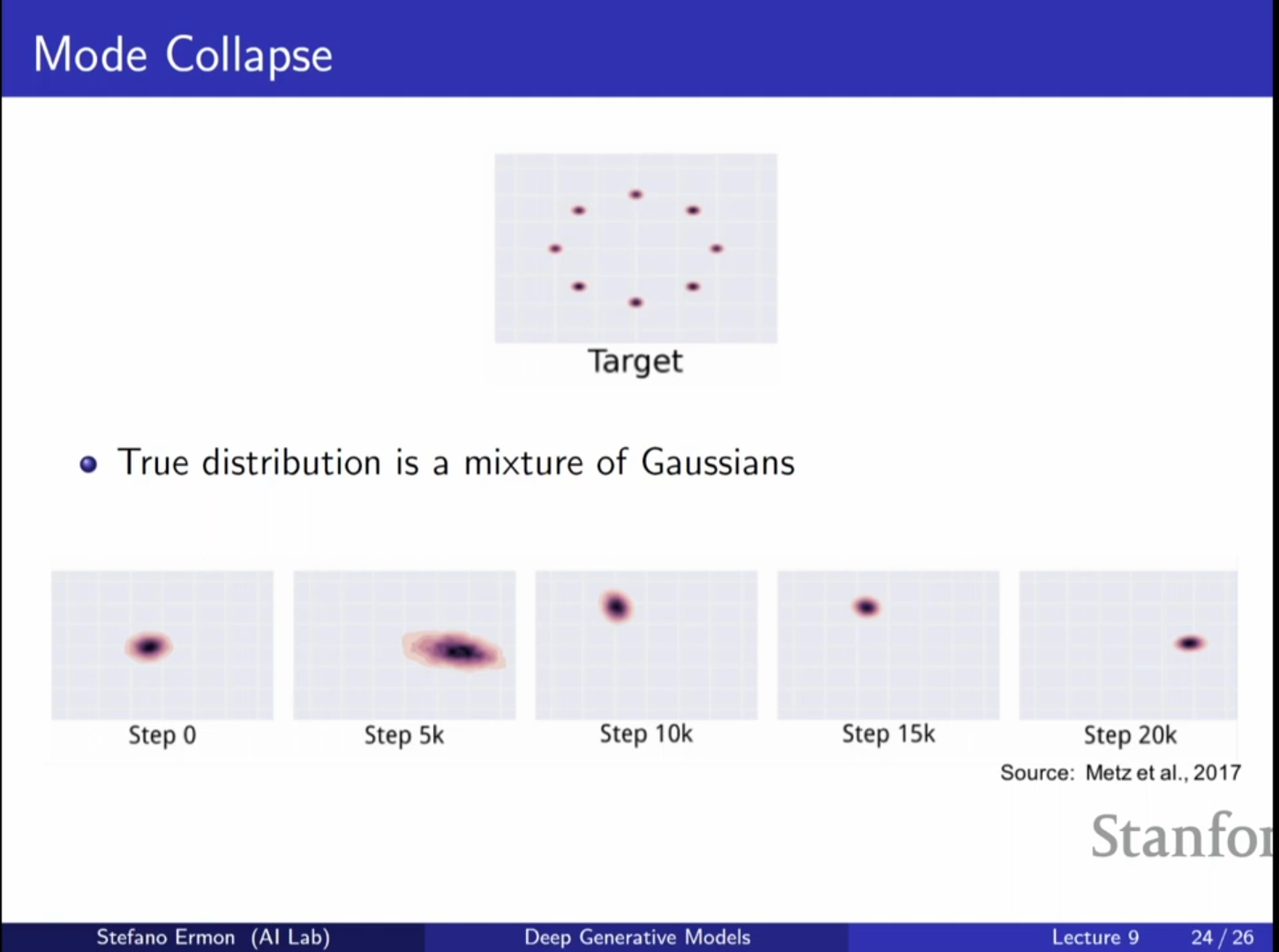
- 모드 붕괴 (Mode Collapse):
- 생성자가 데이터의 다양한 분포(Mode)를 모두 커버하지 못하고, 판별자를 속이기 쉬운 특정 형태의 샘플만 반복해서 생성하는 현상입니다.
- 예를 들어, MNIST 학습 시 특정 숫자만 계속 생성하거나, 얼굴 이미지에서 특정 특징만 반복되는 경우가 이에 해당합니다.
- 최신 동향:
- 이러한 학습의 어려움 때문에 최근에는 학습이 안정적이고 손실 함수가 명확한 Diffusion Model이 더 선호되는 추세입니다.
6. QnA
Q1: 나쁜 데이터나 노이즈를 걸러내는 데 GAN을 활용할 수 있습니까?
A: 네, 가능합니다. Likelihood 기반 모델에서는 무엇이 노이즈인지 정의하기 어렵지만, GAN에서는 '원하지 않는 데이터(Negative Data)'를 판별자에게 가짜(Fake) 예시로 제공하여 생성자가 이를 피하도록 학습시키는 것이 매우 직관적이고 쉽습니다. 예를 들어, 퍼즐 조각이 뒤섞인 이미지 등을 부정적 예시로 활용할 수 있습니다.
Q2: 생성자가 실제 데이터를 직접 보지 않는데 어떻게 학습이 되나요?
A: 맞습니다. 생성자는 실제 데이터를 직접 보지 않습니다. 대신 실제 데이터를 본 판별자로부터 나오는 그래디언트(Gradient) 신호(즉, 판별자가 데이터를 어떻게 구별하는지에 대한 정보)를 통해 간접적으로 데이터의 특징을 학습합니다. 이는 매우 좁은 신호(Narrow Signal)이기 때문에 학습이 불안정한 원인이 되기도 합니다.
Q3: VAE 같은 모델로 생성자를 사전 학습(Pre-train) 시키는 것이 좋은가요?
A: 일반적으로는 충분한 데이터가 있다면 처음부터(Scratch) 학습시키는 것이 보통입니다. 하지만 최근 연구들에서는 Diffusion 모델 등에 판별자를 결합하여 성능을 높이는 식의 하이브리드 접근법도 사용되고 있습니다.
7. 핵심 내용
- Likelihood-Free Training: GAN은 Likelihood를 직접 계산하지 않고, 이표본 검정(Two-Sample Test) 원리를 이용하여 실제 데이터와 모델 생성 데이터가 구분 불가능해지도록 학습합니다. 이는 모델 구조의 제약을 크게 줄여줍니다.
- Adversarial Minimax Game: 생성자(Generator)와 판별자(Discriminator)가 서로 경쟁하는 구조를 가집니다. 판별자는 구별하려고 하고, 생성자는 속이려고 하며, 이 과정에서 수학적으로는 Jensen-Shannon Divergence를 최소화하게 됩니다.
- Trade-offs: 높은 품질의 샘플을 생성할 수 있고 샘플링 속도가 빠르지만, 학습의 불안정성(Instability) 과 다양성을 잃어버리는 모드 붕괴(Mode Collapse) 라는 치명적인 단점이 존재합니다.
