1. 생성 모델 평가의 어려움과 중요성
생성 모델(Generative Models)의 평가는 매우 까다로운 주제이며, 현재까지 완벽한 합의(Consensus)가 이루어지지 않은 분야입니다.
모델링 방법론(Autoregressive, Flow, VAE, GAN, Score-based 등)과 훈련 목적함수(KL 발산, 두 샘플 검정, Score matching 등)는 다양하지만, 특정 데이터셋에 대해 어떤 모델을 선택해야 하는지 결정하기 위해서는 모델 간의 성능 비교가 필수적입니다.
- 평가의 필요성: 연구 관점에서는 새로운 아이디어가 기존보다 나은지 정량화해야 하며, 실용적 관점에서는 특정 문제에 가장 적합한 모델을 선택하기 위해 평가가 중요합니다.
- 판별 모델과의 차이: 분류(Classification)와 같은 판별 모델은 정확도(Accuracy)와 같이 명확한 손실 함수와 평가 지표가 존재하여 비교가 용이합니다. 반면, 생성 모델은 사용 목적(Task)이 무엇이냐에 따라 평가 기준이 달라지기 때문에 평가가 훨씬 어렵습니다.
- 다양한 사용 목적:
- 밀도 추정(Density Estimation): 확률 계산의 정확성.
- 압축(Compression): 데이터의 효율적 표현.
- 샘플링(Sampling): 미적으로 훌륭한 이미지 생성.
- 표현 학습(Representation Learning): 비지도 학습을 통한 특징 추출 및 다운스트림 태스크 활용.

2. 우도(Likelihood)와 압축(Compression) 기반 평가
모델이 확률 밀도 함수를 명시적으로 다루는 경우(예: Autoregressive, Flow), 우도(Likelihood)는 가장 자연스러운 평가 지표입니다.
2.1. 우도와 압축의 관계
- 로그 우도와 코드 길이: 데이터의 로그 우도를 최대화하는 것은 데이터를 표현하는 코드의 평균 길이를 최소화하는 것, 즉 압축과 동일합니다. 자주 등장하는 데이터에는 짧은 코드를, 드문 데이터에는 긴 코드를 할당하는 원리입니다.
- 수학적 의미: 데이터 포인트 에 할당된 코드의 길이는 대략 에 비례하므로, 음의 로그 우도(Negative Log-Likelihood)를 최소화하는 것은 평균 코드 길이를 줄이는 것과 같습니다.

- 지능과 압축: 위키피디아와 같은 방대한 지식을 잘 압축할수록 모델이 더 높은 지능을 가졌다는 가설(Hutter Prize)이 존재합니다.
2.2. 인간 vs 모델 압축 성능 비교
- 샤논의 실험(Shannon's Experiment): 인간이 텍스트의 다음 글자를 예측하는 능력을 측정한 결과, 글자당 약 1.2~1.3 비트의 엔트로피를 보였습니다.
- 모델의 성능: 최신 대규모 언어 모델(LLM)은 글자당 약 0.94 비트 수준으로 인간보다 더 뛰어난 압축 성능을 보이기도 합니다.
[심화 내용] 압축 기반 평가의 한계점
우도(또는 Perplexity) 기반 평가는 "모든 비트가 동등하다"고 가정한다는 치명적인 한계가 있습니다. 예를 들어, 이미지에서 배경 픽셀의 미세한 색상 변화를 예측하는 것(덜 중요한 정보)과 객체의 종류를 맞추는 것(중요한 정보)이 우도 관점에서는 동일한 비트 수로 취급될 수 있습니다. 따라서 우도가 높다고 해서 반드시 우리가 중요하게 생각하는 다운스트림 태스크나 샘플 품질이 좋다는 것을 보장하지는 않습니다.
3. 암시적 모델(Implicit Models)의 밀도 추정
GAN과 같이 우도를 직접 계산할 수 없는 모델의 경우, 샘플만을 이용하여 기저 확률 밀도를 추정해야 합니다.
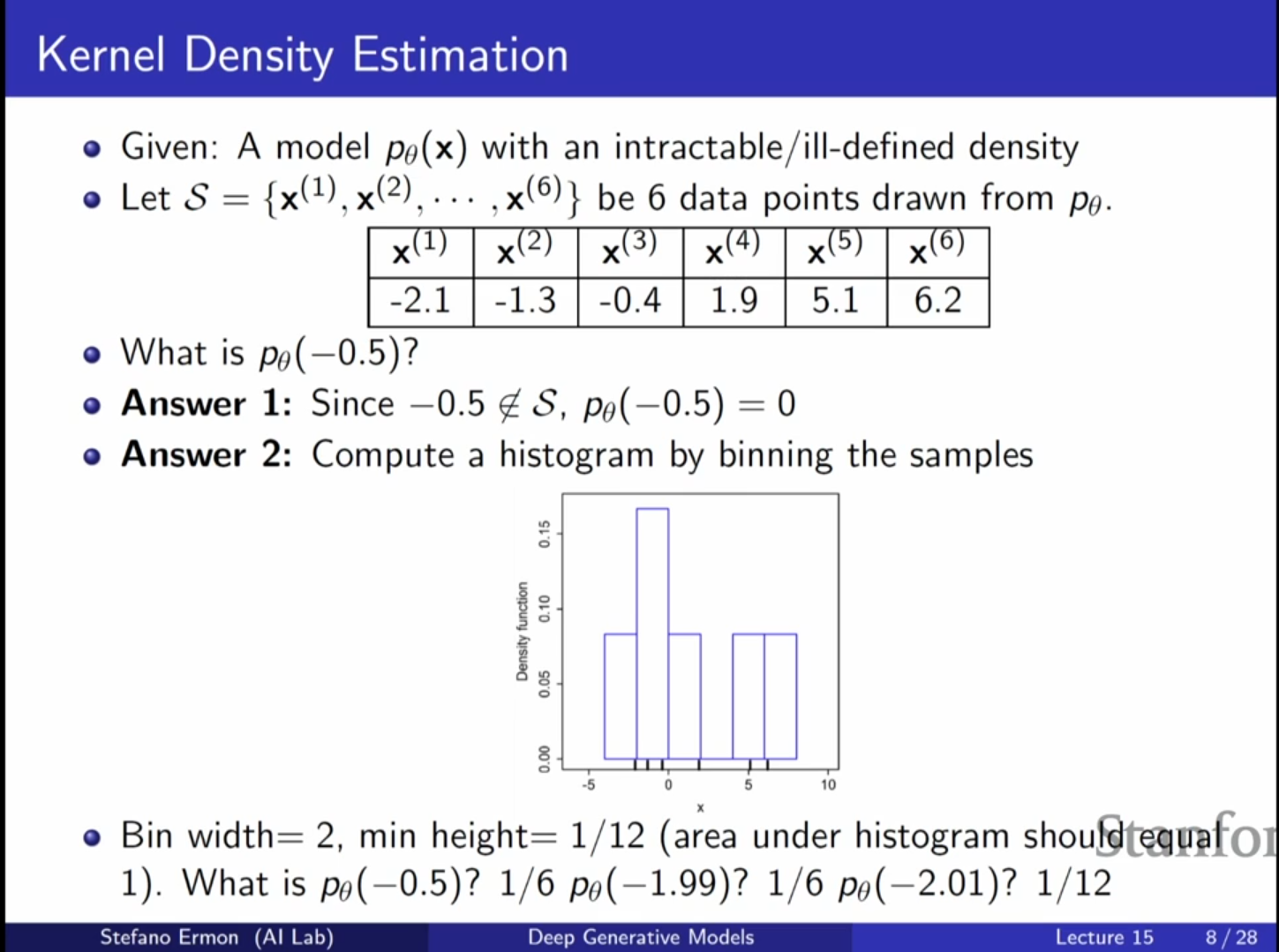
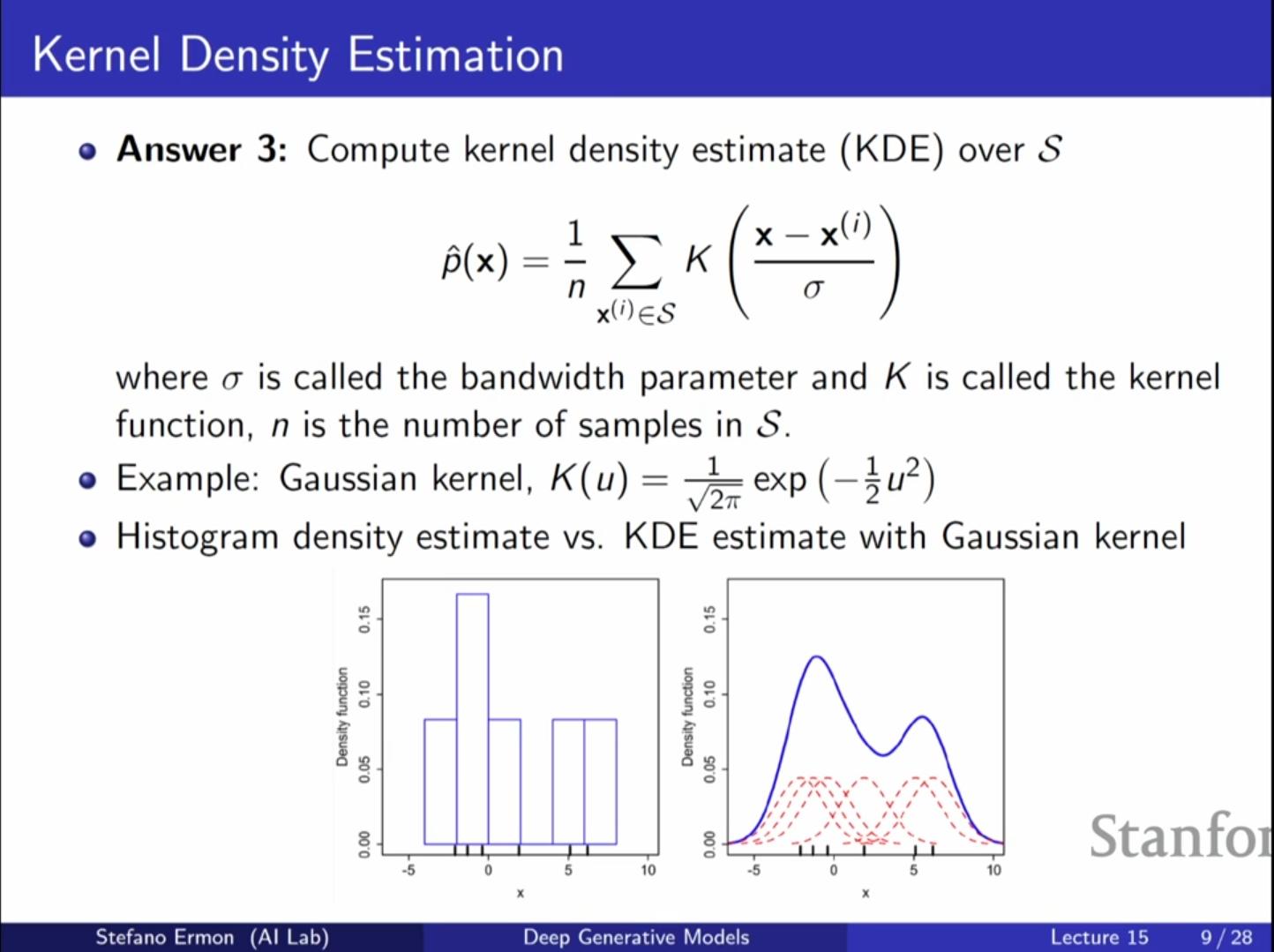
3.1. 커널 밀도 추정 (Kernel Density Estimation, KDE)
- 개념: 생성된 샘플들을 중심으로 커널 함수(주로 가우시안)를 배치하고 이를 합하여 전체 확률 밀도 함수를 근사하는 방법입니다.
- 수식적 표현: 개의 샘플이 있을 때, 데이터 포인트 의 확률은 다음과 같이 추정합니다.
여기서 는 커널 함수, 는 대역폭(Bandwidth)입니다. - 대역폭()의 영향:
- 가 너무 작으면 분포가 뾰족하고 거칠어집니다(Undersmoothed).
- 가 너무 크면 분포가 지나치게 뭉뚱그려집니다(Oversmoothed).
[심화 내용] KDE의 한계와 고차원 문제
KDE에서 최적의 를 찾기 위해 교차 검증(Cross-validation)을 사용할 수 있지만, 고차원 데이터(예: 이미지)에서는 '차원의 저주(Curse of Dimensionality)'로 인해 신뢰할 수 없는 결과를 낳습니다.
공간을 채우기 위해 기하급수적으로 많은 샘플이 필요하기 때문에, 실제 이미지 데이터에 대해 KDE로 우도를 비교하는 것은 매우 부정확할 수 있습니다.
4. 샘플 품질(Sample Quality) 평가
우도보다 생성된 이미지나 텍스트의 품질 자체가 중요한 경우 사용되는 평가 지표들입니다.
4.1. 인간 평가 (Human Evaluation)
- 방식: 사람이 직접 샘플을 보고 진짜인지 가짜인지 판별하거나 선호도를 평가합니다. 가장 확실한 기준(Gold Standard)으로 간주됩니다.
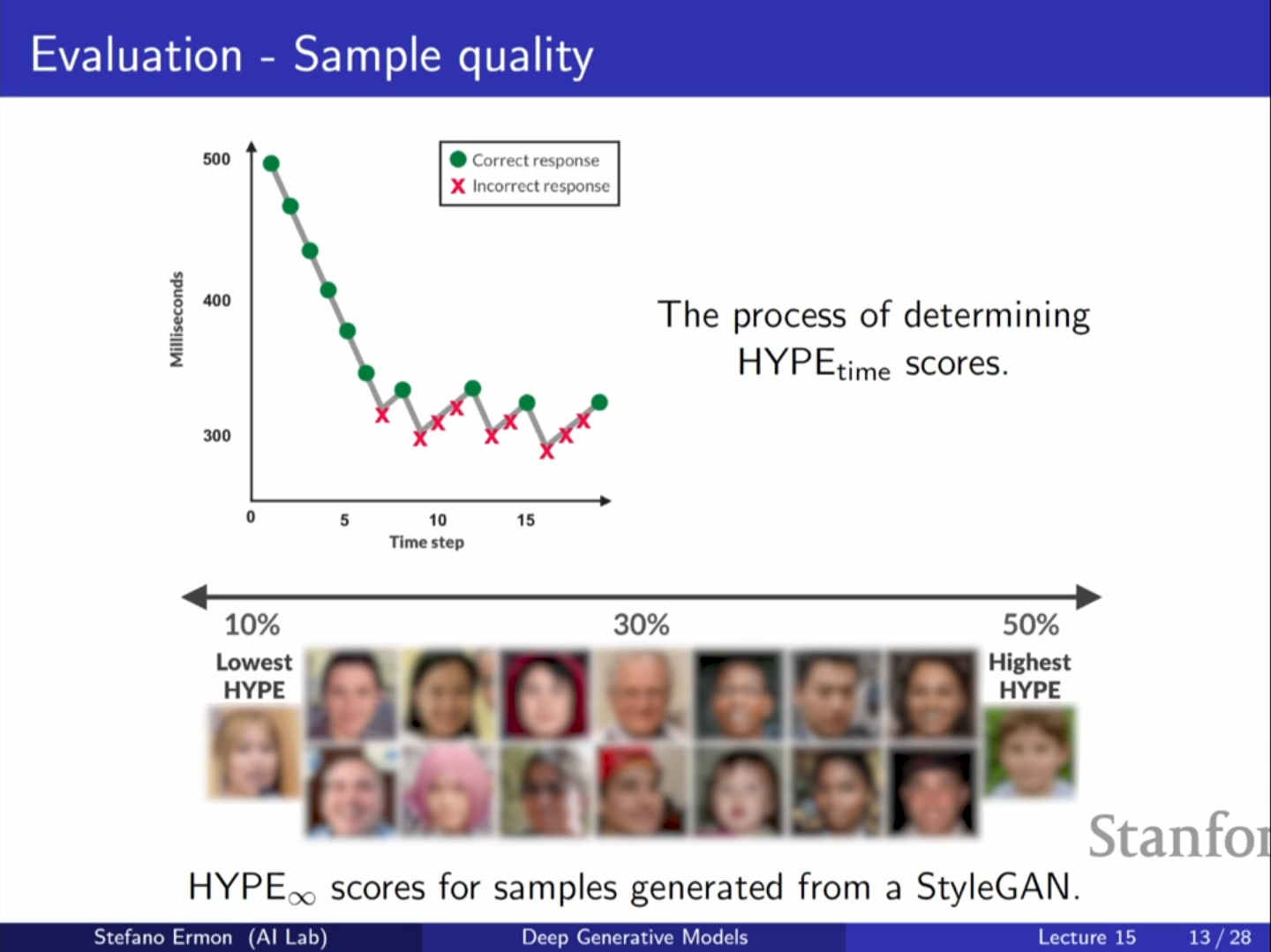
- Hype Time: 사람이 이미지가 진짜인지 가짜인지 판별하는 데 걸리는 시간을 측정합니다. 시간이 오래 걸릴수록(판별하기 어려울수록) 좋은 샘플입니다.
- 한계: 비용이 많이 들고, 실험 설계에 따라 결과가 달라지며 재현이 어렵습니다. 또한 모델이 훈련 데이터를 단순히 암기(Memorization)했는지 파악하기 어렵습니다.

4.2. 자동화된 평가 지표 (Inception Score & FID)
비용이 드는 인간 평가를 대체하기 위해 사전 훈련된 분류기(예: Inception Net)를 활용하는 방법입니다.
Inception Score (IS)
- 두 가지 기준:
- 선명도(Sharpness): 생성된 이미지가 특정 클래스로 명확히 분류되어야 합니다. (조건부 확률 분포 의 엔트로피가 낮아야 함).

- 다양성(Diversity): 생성된 이미지들이 가능한 모든 클래스를 골고루 포함해야 합니다. (주변 확률 분포 의 엔트로피가 높아야 함).

- 선명도(Sharpness): 생성된 이미지가 특정 클래스로 명확히 분류되어야 합니다. (조건부 확률 분포 의 엔트로피가 낮아야 함).
- 계산: 위 두 가지 엔트로피 정보를 결합하여 점수를 산출합니다. 점수가 높을수록 좋습니다.
Fréchet Inception Distance (FID)
- 개념: 실제 데이터와 생성된 데이터의 특징(Feature) 벡터 분포를 비교합니다. Inception Net의 중간 레이어에서 추출한 특징들이 다변량 가우시안 분포(Multivariate Gaussian)를 따른다고 가정하고, 두 분포 간의 거리를 측정합니다.
- 수식적 의미: 두 가우시안 분포(실제 vs 생성 ) 사이의 Wasserstein-2 거리를 계산합니다.
값이 낮을수록 실제 데이터 분포와 유사함을 의미합니다. - 장점: 픽셀 단위 비교보다 인간의 지각 능력과 더 잘 일치하며, 널리 사용되는 표준 지표입니다.

Kernel Inception Distance (KID)
- 개념: FID와 유사하지만, MMD(Maximum Mean Discrepancy)를 기반으로 커널 트릭을 사용하여 두 분포의 차이를 측정합니다.
- 특징: 편향되지 않은(Unbiased) 추정량을 제공하므로 샘플 수가 적을 때 FID보다 유리할 수 있지만, 계산 비용이 더 높을 수 있습니다.

[심화 내용] Inception Score의 맹점
IS는 클래스 간 다양성은 측정하지만, 클래스 내(Intra-class) 다양성은 고려하지 못합니다. 예를 들어, 모델이 각 숫자(0~9)에 대해 완벽하게 동일한 이미지 하나씩만 생성하더라도, 전체 클래스 분포가 균일하고 각 이미지가 선명하다면 매우 높은 IS 점수를 받을 수 있습니다. 이는 'Mode Collapse'의 일부 형태를 감지하지 못하는 한계가 있습니다.
5. 기타 평가 영역 및 최신 트렌드
5.1. 텍스트-이미지 모델의 전체론적 평가 (Holistic Evaluation)
- 단순한 이미지 품질뿐만 아니라, 캡션과의 정합성(Alignment), 바이어스, 독성(Toxicity), 미적 점수 등 다양한 사회적/윤리적 지표를 포함하여 평가해야 합니다.
- 스탠포드에서 제안한 HEIM 벤치마크 등이 이에 해당합니다.
5.2. 표현 학습과 잠재 공간 (Latent Space) 평가

- 군집화(Clustering): 잠재 공간에서 같은 클래스의 데이터가 잘 뭉쳐 있는지 평가합니다 (Completeness, Homogeneity scores).

- 재구성(Reconstruction): 원본 데이터를 얼마나 잘 복원하는지 평가합니다. 압축 용도로 중요합니다.

- 요소 분리(Disentanglement): 잠재 변수의 각 차원이 독립적인 의미(예: 색상, 크기, 각도 등)를 가지는지 평가합니다.
- 이론적 한계: 레이블이 없는 완전 비지도 학습 환경에서는 완벽한 Disentanglement 학습이 불가능함이 증명되었습니다.

- 이론적 한계: 레이블이 없는 완전 비지도 학습 환경에서는 완벽한 Disentanglement 학습이 불가능함이 증명되었습니다.
5.3. 언어 모델과 프롬프팅 (Prompting)
- 새로운 패러다임: 언어 모델을 단순한 압축기가 아니라, 자연어 지시(Prompt)를 통해 다양한 태스크를 수행하는 도구로 평가합니다.
- 평가 방식: 감성 분석, 질의응답 등 다양한 태스크를 프롬프트로 구성하여 모델의 출력을 평가합니다 (예: HELM, Big-Bench).
- 미세 조정(Fine-tuning) 대 프롬프팅: 프롬프팅은 훈련 없이 사용 가능하지만 모델이 강력해야 하고, 미세 조정은 비용이 들지만 성능을 특화할 수 있습니다.

6. 강의 QnA
Q1: GAN은 우도를 계산할 수 없는데, 다른 모델(예: Autoregressive)과 어떻게 우도를 비교합니까?
A1: 직접적인 비교는 불가능합니다. GAN은 우도를 명시적으로 모델링하지 않기 때문입니다. 만약 우도 비교가 꼭 필요하다면 KDE와 같은 근사법을 써야 하지만 고차원에서는 부정확합니다. 따라서 GAN은 주로 샘플 품질(FID 등)로 평가합니다.
Q2: KDE에서 커널의 분산(Variance, )은 어떻게 선택하나요?
A2: 교차 검증(Cross-validation)을 통해 홀드아웃(Hold-out) 데이터의 우도를 최대화하는 값을 찾는 것이 일반적입니다. 하지만 고차원 데이터에서는 이 방법도 차원의 저주 때문에 잘 작동하지 않을 수 있습니다.
Q3: Inception Score의 다양성(Diversity) 지표는 클래스 내부의 다양성도 측정하나요?
A3: 아닙니다. IS는 전체 생성된 샘플들이 여러 클래스에 걸쳐 분포하는지(Marginal Distribution의 엔트로피)만 확인합니다. 따라서 한 클래스 내에서 똑같은 이미지만 계속 생성되어도 이 지표는 높게 나올 수 있는 맹점이 있습니다.
Q4: FID에서 왜 하필 다변량 가우시안 분포를 사용하나요?
A4: 두 가우시안 분포 사이의 Wasserstein-2 거리(Fréchet Distance)를 닫힌 형태(Closed form)의 수식으로 계산할 수 있기 때문입니다. 완벽한 가정은 아니지만 계산 효율성과 실용성 때문에 선택되었습니다.
7. 핵심 내용
- 평가의 복잡성: 생성 모델 평가는 판별 모델과 달리 단일한 정답이 없으며, 밀도 추정, 샘플 품질, 표현 학습 등 모델의 사용 목적(Task)에 따라 적절한 평가 지표를 선택해야 합니다.
- 우도 vs 샘플 품질: 우도(Likelihood)는 압축 성능과 직결되지만, 이것이 반드시 시각적으로 우수한 샘플 품질을 보장하지는 않습니다. 반대로 우도를 계산할 수 없는 모델(GAN)은 FID와 같은 특징 기반 거리 척도를 주로 사용합니다.
- 지속적인 발전: Inception Score나 FID 같은 자동화 지표들이 널리 쓰이지만 완벽하지 않으며, 최근에는 편향성, 윤리성 등을 포함한 전체론적(Holistic) 평가와 프롬프팅 능력을 검증하는 방향으로 평가 방법론이 진화하고 있습니다.
